jina-embeddings-v5-text: Task-Targeted Embedding Distillation
Abstract: Text embedding models are widely used for semantic similarity tasks, including information retrieval, clustering, and classification. General-purpose models are typically trained with single- or multi-stage processes using contrastive loss functions. We introduce a novel training regimen that combines model distillation techniques with task-specific contrastive loss to produce compact, high-performance embedding models. Our findings suggest that this approach is more effective for training small models than purely contrastive or distillation-based training paradigms alone. Benchmark scores for the resulting models, jina-embeddings-v5-text-small and jina-embeddings-v5-text-nano, exceed or match the state-of-the-art for models of similar size. jina-embeddings-v5-text models additionally support long texts (up to 32k tokens) in many languages, and generate embeddings that remain robust under truncation and binary quantization. Model weights are publicly available, hopefully inspiring further advances in embedding model development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains how the authors built two small but powerful AI models that turn text into numbers called “embeddings.” Think of an embedding like a set of coordinates on a map that capture the meaning of a sentence or document. With these coordinates, computers can quickly find similar texts, group related documents, answer questions by searching, and more. The new models are called jina-embeddings-v5-text-small and jina-embeddings-v5-text-nano.
What questions were the researchers trying to answer?
The team set out to solve a simple problem: can small models be trained to understand meaning almost as well as big, expensive models, and still work across many languages and long documents? In particular, they asked:
- Can a “student” model learn from a bigger “teacher” model to get strong results (this is called distillation)?
- If we mix that teacher-student learning with task-focused training (like training specifically for search or similarity), will small models get even better?
- Can these small models handle many languages, very long texts, and still work well even when their outputs are heavily compressed?
How did they build and train the models?
The authors combined two training ideas and added smart “plug-ins” to specialize for different jobs.
- Embeddings in everyday terms:
- Imagine every sentence is a point on an “idea map.” Similar meanings sit close together. The model learns to place texts on this map so “find similar things” becomes easy.
- Two-stage training (student learns from a teacher, then specializes):
- A large, well-trained “teacher” model (Qwen3-Embedding-4B) shows examples of good embeddings.
- A much smaller “student” model practices until its embeddings line up with the teacher’s, like a student copying the teacher’s drawing until it matches.
- The authors keep “instructions” simple to avoid confusion (e.g., marking inputs as “Query:” or “Document:” rather than complex prompts).
- They use a technique called RoPE (rotary positional embeddings) to help the model keep track of word order, tuned so the model works well on longer texts than it saw during training.
- They also added a “long-text practice” phase so the model doesn’t get lost in long documents.
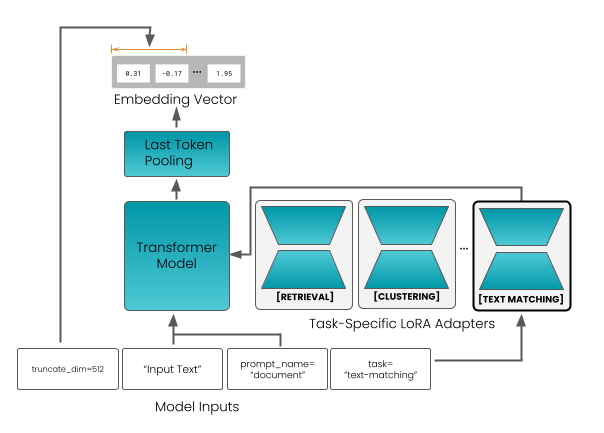
2) Task-specific adapters (small plug-ins called LoRA adapters): - Instead of forcing one model to be perfect at everything at once, they attach tiny add-ons tuned for different jobs: - Retrieval (search) - Semantic similarity (how alike two texts are) - Clustering (grouping similar documents) - Classification (assigning labels like topic or sentiment) - You can think of these adapters like different soles for a shoe: same shoe, swap the sole for running on track, trail, or road.
- Special tricks that help:
- “Query:” vs. “Document:” prefixes: The model treats search questions and documents differently, which improves retrieval (because queries are usually short and phrased differently from the documents they match).
- Contrastive learning: The model is trained to pull matching texts closer together on the idea map and push non-matching ones apart—like telling friends to sit together and strangers to sit apart.
- Spread-out regularizer: A gentle push to make the model use the whole map evenly, which helps speed and compression.
- Matryoshka Representation Learning: Like nesting dolls—if you chop off the end of an embedding to make it shorter and faster, it still keeps most of the meaning.
- Binary quantization robustness: Even when embeddings are compressed down to very compact forms (using 0s and 1s), they still work well.
What did they find?
- Small models can perform great:
- Their two models (v5-text-small and v5-text-nano) matched or beat other models of similar size on popular benchmarks (MTEB in many languages and English, plus retrieval tests like BEIR and LongEmbed).
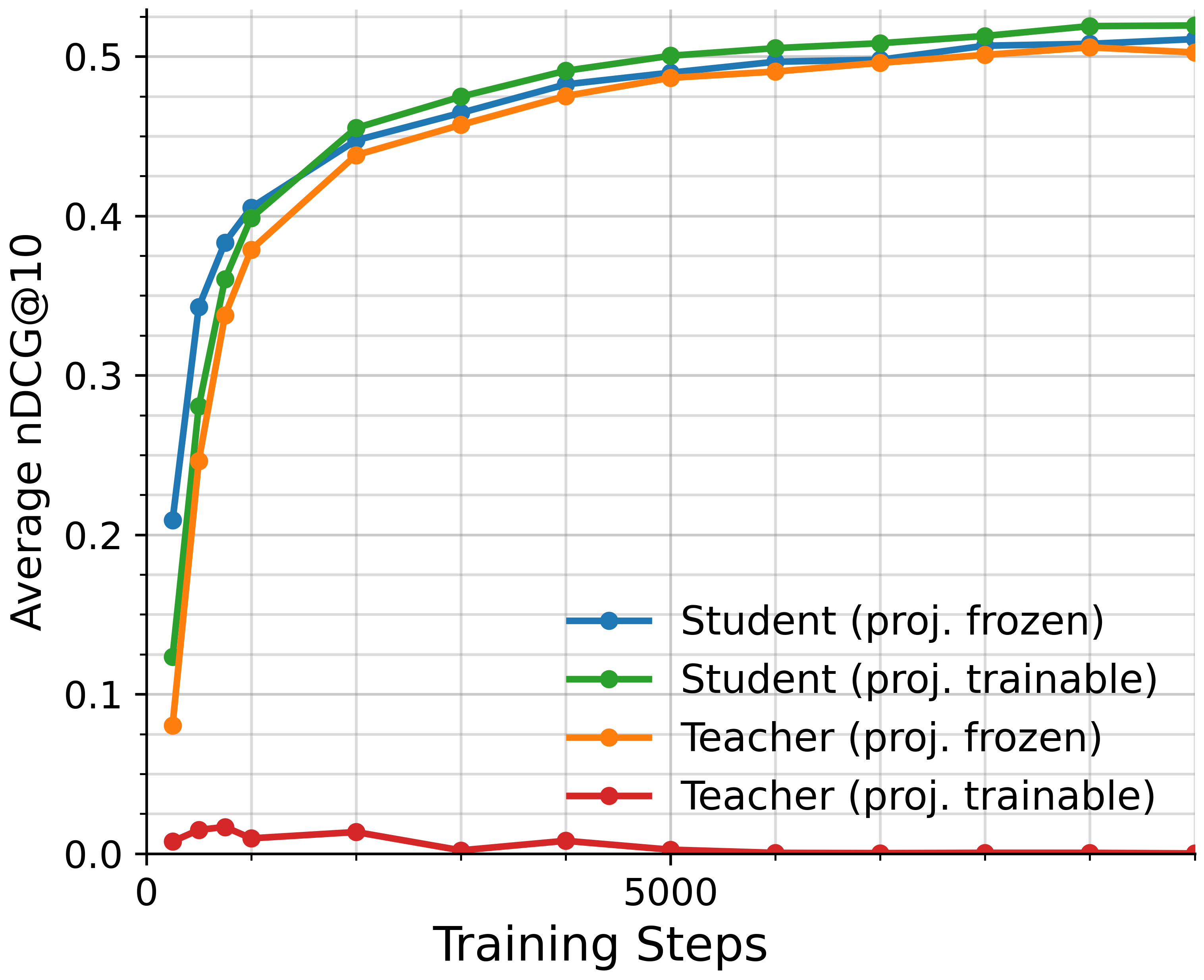
- The very large teacher model still scores highest overall, but the small models come surprisingly close considering their size.
- The training recipe matters:
- Distillation (teacher-student learning) worked better for small models than just contrastive learning alone.
- Combining distillation with task-specific training worked best of all.
- A technical detail—projecting the student’s embeddings up to the teacher’s size (instead of shrinking the teacher) made distillation more effective.
- They handle many languages and long texts:
- The models support lots of languages and can process very long documents (up to around 32,000 tokens).
- Extra long-text training improved performance on long documents.
- They stay strong when compressed or shortened:
- Thanks to the “spread-out” regularizer and the “Matryoshka” idea, the embeddings still work well when shortened or heavily compressed.
Why does this matter?
- Faster, cheaper, and broadly useful:
- These small models are efficient and do not need big computers to run well, which makes them practical for startups, apps on a budget, or on-device use.
- Because they support many languages and very long texts, they’re useful for global search, question answering, grouping documents, recommendations, and more.
- Flexible and simple to use:
- You can switch adapters based on your task without retraining the whole model, making it easy to get good performance in different scenarios.
- Simple “Query:” and “Document:” tags give strong gains without complicated prompting.
- Open and reusable:
- The authors released the model weights publicly, encouraging others to build on their work, improve it, or adapt it to new tasks.
In short, this paper shows a smart way to train small, multilingual embedding models that punch above their weight: teach them with a strong teacher, then fine-tune small plug-ins for each job. The result is fast, flexible models that work well across many tasks, languages, and document lengths.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be directly actionable for future research.
- Data transparency and decontamination
- The “300+ datasets in 30+ languages” training mixture is not enumerated; dataset identities, language distribution, and domain proportions are unclear, hindering reproducibility and contamination auditing against MTEB/BEIR/RTEB.
- No decontamination protocol is described to ensure training–evaluation separation, especially for STS and retrieval datasets; quantify possible leakage and its effect on reported gains.
- Long-context generalization beyond training lengths
- Long-context training uses 1k–4096-token texts but the models claim 32k-token support; provide systematic evaluation curves (e.g., nDCG vs length) up to 32k across languages/domains to validate extrapolation under high-θ RoPE.
- Only v5-small receives explicit long-context training; assess whether v5-nano maintains retrieval quality for ≥8k–32k tokens and quantify the drop-off.
- Positional encoding choices and stability
- The use of lower θ during training and higher θ at inference is asserted to help long-texts; ablate θ schedules, frequency interpolation strategies, and their stability across languages and tasks (including failure modes like attention drift).
- Provide sensitivity analysis for maximum sequence length, rotary base frequency, and tokenizer-induced position distribution.
- Pooling strategy and encoder architecture
- The model uses last-token pooling without justification; compare last-token vs mean/max/attention pooling across tasks (retrieval, STS, clustering) and lengths, including interactions with RoPE and prefixes.
- Evaluate single-tower with prefixes versus dual-tower (query/document) encoders for asymmetric retrieval.
- Prefixes and multilingual behavior
- Query/Document prefixes are fixed in English; test whether prefix language affects performance and whether learned multilingual tokens or language-specific prefixes outperform English-only prefixes in non-English tasks.
- Explore automatic prefix selection or prompt-free asymmetry mechanisms to reduce operational complexity.
- Distillation design and projections
- The projection direction is fixed (student→teacher dimension) and linear; ablate teacher→student projection, nonlinear mappings (MLP, orthogonal constraints), and shared projection heads per task to quantify trade-offs in convergence and final scores.
- Theoretical justification for linear projection sufficiency is absent; analyze representational geometry alignment (e.g., Procrustes analysis, CCA) to explain empirical outcomes.
- Instruction usage during distillation
- Distillation uses minimal teacher instructions; measure how richer task/domain instructions (or learned instruction prompts) impact student performance and whether instruction-conditioned distillation helps adapters.
- Compare single-teacher distillation with multi-teacher ensembles (e.g., instruction-tuned vs generic teachers) to reduce teacher bias.
- Adapter training details and placement
- LoRA adapter ranks, layer placements, and target modules are not disclosed; provide design specifics and ablation on adapter ranks/locations for each task to guide reproducibility and optimization.
- Investigate interference among adapters and potential composition (stacking, routing, weight averaging beyond final two checkpoints) to enable multi-task inference without manual adapter switching.
- Loss weighting and objective scheduling
- Combined objectives use fixed weights (e.g., λ_NCE:λ_D:λ_S); ablate weight schedules, adaptive weighting (e.g., uncertainty-based), and curriculum strategies across datasets for more robust convergence.
- For STS, the switching logic between CoSENT and NCE+distillation is fixed; test mixed-batch multi-objective training and dynamic routing by data properties (score quality, domain, language).
- Hard negative mining strategy
- Hard negative mining is mentioned but the sourcing, mining procedure (in-batch vs external corpus), and difficulty calibration are not detailed; quantify its impact on retrieval with controlled mining pipelines and difficulty stratification.
- Quantization and Matryoshka truncation robustness
- Claims of robustness under binary quantization and truncated embeddings (MRL) are not accompanied by quantitative results; report accuracy/recall vs bit-width (binary/2-bit/4-bit/8-bit) and vs truncation sizes for multiple ANN indices (HNSW, IVF-PQ).
- Measure ANN speed/recall trade-offs with and without GOR regularization to validate claims about improved efficiency.
- Efficiency and deployment metrics
- No measurements of inference latency, memory footprint, throughput, or GPU/CPU performance under 32k-token inputs; report end-to-end retrieval pipeline costs (embedding time, indexing time, query time) for typical corpora sizes.
- Compare embedding dimensionality (768 vs 1024) impact on downstream index size and retrieval recall/speed curves.
- Language coverage and low-resource performance
- Training and evaluation emphasize major languages; systematically evaluate low-resource languages (e.g., Amharic, Khmer) and scripts beyond Latin/CJK, including cross-lingual retrieval and bitext mining robustness.
- Analyze the effect of machine-translated STS data on model biases and semantic drift; quantify performance gaps between human-annotated vs MT-derived labels.
- Domain robustness and failure modes
- RTEB public tasks, BEIR, and LongEmbed provide partial coverage; include adversarial/noisy retrieval (typos, code-mixed text), specialized domains (legal, biomedical), and high-entropy corpora to uncover failure modes.
- Calibrate similarity scores (e.g., reliability diagrams, ECE) for pair classification/STS to assess score interpretability.
- Summarization and reranking alignment
- Summarization performance is lower than Gemma-300M; assess whether adapter training improves summarization embeddings or if a specialized adapter/ranker is needed.
- For “Instruction Reranking” tasks, study whether instruction-aware adapters or cross-encoder hybrids yield gains over pure bi-encoder embeddings.
- Classification adapter limitations
- Multilabel datasets are converted to single-label; test native multilabel training (e.g., margin/label-smoothing losses) and its effect on zero-shot classification.
- The relational KD teacher is the base model without adapters; evaluate stronger teachers (e.g., instruction-tuned LLMs) and alternative relational objectives (triplet distances, angular margins).
- Safety, bias, and fairness
- No analysis of demographic or topical biases, harmful content, or fairness across languages/domains; include standard bias/fairness audits and evaluate mitigation (debiasing losses, data reweighting).
- Assess privacy and licensing compliance for training corpora, especially for enterprise deployment.
- Reproducibility and training compute
- Key hyperparameters are referenced but not fully enumerated in the paper body (learning rates, batch sizes per dataset, optimizer settings, warmup, LoRA ranks); publish complete configurations and seeds.
- Report training compute budgets (GPU types, hours, energy) and scaling behavior to inform cost–performance trade-offs.
- Alternative architectures and techniques
- Compare the proposed approach against model-soup merging of task-specific checkpoints, mixture-of-experts gating, or adapter routers for unified multitask performance.
- Explore learned instruction generation (auto-prompts) and lightweight per-dataset adapters as alternatives to manual prefixes.
- Teacher dependence and generalization
- The approach relies on a single teacher (Qwen3-4B); investigate generalization when distilling from different teachers (Gemma, E5, Arctic) and whether improvements transfer across teacher families.
- Analyze how teacher embedding geometry (norms, anisotropy) shapes student representations; test normalization schemes and anisotropy corrections during distillation.
Glossary
- Approximate nearest neighbor (ANN) search: Fast, approximate methods for nearest-neighbor retrieval in high-dimensional embedding spaces. "enables more efficient retrieval under approximate nearest neighbor (ANN) search."
- Asymmetric retrieval: Encoding queries and documents differently to improve retrieval when their form and content differ. "Asymmetric retrieval is based on the insight that queries and retrieval targets are usually very different from each other."
- BEIR: A benchmark suite for evaluating information retrieval models across diverse datasets. "BeIR contains very large English datasets, demonstrating the models' performance on million document-scale corpora."
- Binary quantization: Compressing embeddings into binary representations to reduce storage and speed up similarity search. "remain robust under truncation and binary quantization."
- Bitext mining: The task of finding parallel sentence pairs across languages for multilingual alignment. "BM:~Bitext Mining"
- CoSENT Ranking Loss: A ranking-based loss that optimizes the ordering of predicted similarities to match ground-truth scores. "CoSENT Ranking Loss:"
- Contrastive learning: Training paradigm that brings semantically similar pairs closer and dissimilar pairs apart in embedding space. "are trained using contrastive learning."
- Contrastive loss (InfoNCE): A temperature-scaled loss used to maximize similarity of positives over negatives within a batch. "We use InfoNCE loss~\cite{oord2018representation} with hard negatives~\cite{karpukhin2020dense}."
- Cross-lingual dense retrieval: Retrieval models that operate across languages by learning shared embedding spaces. "train cross-lingual dense retrieval models using machine translation."
- Distillation (model distillation): Training a smaller “student” model to mimic a larger “teacher” model using specialized losses. "Model distillation is an approach to creating compact LLMs that has been used to create models like DistilBERT~\cite{sanh2019distilbert}."
- Distillation loss: A loss function that aligns student outputs (or relations) with the teacher to transfer knowledge. "We retain the same knowledge distillation loss used during the first stage of training (Equation~\eqref{eq:distill-loss})."
- Gaussian kernel-based loss: A loss component using Gaussian kernels to improve multi-teacher distillation alignment. "add a Gaussian kernel-based loss component for multi-teacher distillation."
- Global Orthogonal Regularizer (GOR): A regularizer encouraging embeddings to spread uniformly, improving expressiveness and quantization robustness. "we apply a global orthogonal regularizer (GOR)~\citep{zhang2017learning} that encourages embeddings to be distributed more uniformly across the embedding space"
- Hard negatives: Non-matching examples that are semantically close to the query, used to make contrastive learning more challenging. "additional mined hard negatives, i.e., semantically related but incorrect documents."
- In-batch negatives: Using other items in the batch as negatives to scale contrastive learning without explicit negative labels. "For parallel datasets lacking explicit negatives, we use in-batch negatives."
- InfoNCE loss: A specific contrastive objective that maximizes the log-likelihood of positives over negatives. "We use InfoNCE loss~\cite{oord2018representation} with hard negatives~\cite{karpukhin2020dense}."
- Instruction tuning: Fine-tuning models with task-specific instructions to resolve task conflicts and improve performance. "Instruction tuning has been proposed to resolve task conflicts in both text~\cite{su2023one} and image~\cite{zhang2024magiclens} retrieval models."
- Last-token pooling: Producing a single sequence embedding by taking the embedding of the final token. "via last-token pooling, i.e., it uses the embedding of the end-of-sequence token produced by the transformer layers."
- LongEmbed: A benchmark evaluating retrieval on long documents, beyond passage-level tests. "LongEmbed contains tests on relatively long documents when most benchmarks only contain passages."
- LoRA adapters: Low-Rank Adaptation modules that enable parameter-efficient, task-specific fine-tuning. "the model includes LoRA adapters to support multiple tasks that are difficult to optimize for jointly."
- Matryoshka Representation Learning: A training approach that makes embeddings robust under truncation by nesting representational capacity. "enabled by using Matryoshka Representation Learning during training~\cite{kusupati2022matryoshka}."
- Mean Squared Error (MSE): A loss measuring average squared differences, here used between softmax-normalized similarity matrices. "Specifically, we compute the Mean Squared Error (MSE) between the softmax-normalized similarity matrices:"
- Model averaging: Averaging parameters from multiple checkpoints to improve stability and generalization. "employing model averaging to improve performance and robustness."
- Model soup: Merging weights from multiple fine-tuned models to improve performance across tasks. "merging their weights using “model soup” methods has proven productive~\cite{vera2025embeddinggemma}."
- Multi-teacher distillation: Distilling a student from multiple teachers to combine strengths via alignment and score-based methods. "introduce techniques for multi-teacher distillation, using both embedding alignment and score-based distillation methods, applied over multiple training stages."
- nDCG@10: Normalized Discounted Cumulative Gain at rank 10, evaluating the quality of ranked retrieval. "All retrieval tasks were evaluated using nDCG@10, except for Passkey and Needle, which used nDCG@1."
- Projection layer: A learned linear mapping to align student embeddings with the teacher’s embedding space. "We also re-used the projection layer weights trained in the first stage."
- Relational knowledge distillation: Matching pairwise relations (distances) between embeddings rather than raw outputs to prevent collapse. "We also added a relational knowledge distillation regularizer~\citep{park2019relational}"
- Retrieval-augmented generation (RAG): Using retrieved documents to augment inputs for downstream generative tasks. "retrieval-augmented generation"
- Reranker: A model that re-sorts retrieved candidates using more precise scoring for improved ranking quality. "\citet{chen2021simplified} follow up on this work by developing a reranker model using the same technique with additional labeled data."
- RoPE (rotary positional embeddings): A positional encoding method that injects position via rotations in attention, enabling better long-context scaling. "We use rotary positional embeddings (RoPE)~\cite{su2024roformer} to inject positional information during attention calculation."
- RTEB: A multilingual retrieval benchmark emphasizing enterprise use cases. "we used three additional benchmarks: RTEB (Multilingual)\footnote{This benchmark contains a mixture of publicly-available tasks and additional private tasks.}"
- Score-based distillation: Distilling by matching the distribution of similarity scores rather than embedding vectors directly. "we evaluated a score-based distillation loss that aims to match the distribution of pairwise similarities produced by the teacher and student models."
- Self-attention: The transformer mechanism where tokens attend to each other; can be mimicked during distillation. "MiniLM models~\cite{wang2020minilm} are distilled by mimicking the self-attention behavior of the parent model."
- Semantic Textual Similarity (STS): Tasks measuring the semantic similarity between text pairs with graded labels. "We designed the text-matching adapter for semantic text similarity (STS) tasks"
- Spearman correlation coefficient: A rank-based statistic used to evaluate STS and summarization correlations. "For semantic textual similarity (STS) and summarization tasks, we calculated the Spearman correlation coefficient."
- Spread-Out Regularizer: A regularizer encouraging embeddings to be uniformly spread to increase capacity and robustness. "Spread-Out Regularizer"
- Student–teacher model: The distillation setup where a small student learns to imitate a larger teacher. "Distillation requires a “student” model, a “teacher” model, and training data for both to process."
- Temperature parameter: A scalar controlling smoothness/sharpness in softmax or similarity scaling within contrastive losses. "where is a learnable temperature parameter."
- Triplet datasets: Training data with (query, positive, negative) tuples used for contrastive retrieval training. "Training data for this adapter consists of triplet datasets containing queries, relevant documents, and hard negatives"
- V-measure: A clustering evaluation metric (harmonic mean of homogeneity and completeness). "For clustering tasks, we used the V-measure to evaluate the quality of the embeddings."
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that can be implemented today using the paper’s released models, training regimen, and adapters.
- Multilingual enterprise search and knowledge bases (software, enterprise) — Deploy dense retrieval with jina-embeddings-v5-text-small/nano across intranets, wikis, and document stores in many languages, including long documents (32k tokens). — Tools/Workflow: Vector DBs (FAISS, Milvus, Weaviate, Elastic, Pinecone), “Query:”/“Document:” prefixing, retrieval adapter, ANN indexes; Matryoshka truncation for tiered storage. — Dependencies/Assumptions: Correct adapter selection, consistent prefixing; multilingual coverage varies by language and domain; long-context performance depends on hardware and RoPE scaling.
- Retrieval-Augmented Generation (RAG) for customer support and chatbots (software, customer service) — Improve grounding and recall with robust, small embeddings, and asymmetric retrieval; long-context enables grounding from manuals and policies. — Tools/Workflow: LlamaIndex/LangChain + vector DB; retrieval adapter; truncation to match latency budgets. — Dependencies/Assumptions: Prompting of the LLM is separate; ensure adapter/prefix discipline; quantization-aware ANN configuration.
- Legal and policy eDiscovery on long-form documents (policy, legal, compliance) — Efficiently retrieve clauses, precedents, and regulations from lengthy statutes, contracts, and filings across languages. — Tools/Workflow: Long-document retrieval adapter; domain-specific indexing (section-level chunks); ANN search; document provenance tracking. — Dependencies/Assumptions: Proper chunking strategy; performance on very long texts benefits from long-context training but may vary beyond training distribution.
- Academic literature search and deduplication (academia) — STS adapter enables paraphrase detection, duplicate removal, and high-quality similarity scoring for literature reviews. — Tools/Workflow: STS adapter; CoSENT ranking; citation graph + embedding-based similarity; vector search for abstracts and full texts. — Dependencies/Assumptions: For low-resource languages, quality relies on translated data; adapter selection must match symmetric tasks.
- E-commerce semantic search and product recommendations (commerce) — Improve query-to-product matching with asymmetric retrieval; cluster catalogs for navigation and related-product surfacing. — Tools/Workflow: Retrieval and clustering adapters; ANN indices; offline clustering jobs for taxonomy enrichment; Matryoshka for budget-aware embeddings. — Dependencies/Assumptions: Domain data quality and schema; multilingual product metadata variability; handle near-duplicate items via STS.
- Automated ticket routing and intent classification (software, ITSM, contact centers) — Classification adapter for categorizing tickets, intents, and complaints; multilingual support for global ops. — Tools/Workflow: Classification adapter; bi-directional InfoNCE; relational KD; downstream rules/thresholding. — Dependencies/Assumptions: Label set quality and balance; negative sampling strategy; potential need for domain fine-tuning.
- Knowledge graph and topic taxonomy building (media, publishing, enterprise knowledge) — Cluster documents/titles to discover themes and build taxonomies; feed tagging pipelines. — Tools/Workflow: Clustering adapter; batch clustering (e.g., HDBSCAN, KMeans) over embeddings; periodic re-indexing. — Dependencies/Assumptions: Clustering quality depends on domain representativeness; instruction used for teacher during clustering distillation matters.
- Content moderation and risk triage (policy, trust & safety) — Classify and prioritize reports/comments; retrieve exemplars to aid human review across languages. — Tools/Workflow: Classification adapter; retrieval adapter for precedent cases; thresholding and human-in-the-loop queues. — Dependencies/Assumptions: Sensitive domains require careful calibration and fairness evaluation; multilingual consistency may vary.
- Personal knowledge management and offline search (daily life, productivity) — On-device or NAS-backed vector search over notes, emails, books; binary quantization + small models reduce footprint. — Tools/Workflow: Local embedding service + vector DB; Matryoshka truncation to save storage; “Document:” prefix for uniform encoding. — Dependencies/Assumptions: Device memory/CPU constraints; privacy safeguards; correct adapter selection (retrieval vs. STS).
- Bitext mining for MT and localization pipelines (software, localization, academia) — Use STS/bitext mining tasks to find parallel sentence/document pairs across languages. — Tools/Workflow: STS adapter; cosine similarity ranking; batch mining + human verification loop. — Dependencies/Assumptions: Translation quality of training resources influences performance; domain drift in specialized texts.
Long-Term Applications
The following applications are promising but benefit from further research, scaling, domain adaptation, or productization.
- Adapter marketplace and auto-router for task/domain selection (software, platform) — Orchestrate multiple LoRA adapters (retrieval, STS, clustering, classification) with a router that auto-selects per request, reducing misconfiguration risk. — Tools/Workflow: Adapter registry, task detection, metadata-aware routing, telemetry. — Dependencies/Assumptions: Requires robust task detection and monitoring; adapter conflicts need resolution policies.
- Domain-specialized adapters (healthcare, finance, legal) with compliance controls (healthcare, finance, legal) — Train and publish task-specific LoRA adapters for clinical notes retrieval, SEC filings analysis, contract classification, etc. — Tools/Workflow: PEFT/LoRA training on domain corpora; controlled vocabularies; evaluation suites; audit logs. — Dependencies/Assumptions: Access to high-quality labeled domain data; rigorous validation (HIPAA/GDPR/SOX); bias/fairness audits.
- Privacy-preserving, on-device RAG assistants (software, mobile, edge) — Combine small models, robust quantization, and Matryoshka embeddings for offline assistants that search local content across languages. — Tools/Workflow: On-device vector DB; memory-aware truncation; incremental indexing; secure enclaves. — Dependencies/Assumptions: Edge hardware readiness; app-level UX for adapter choice; on-device power/performance trade-offs.
- Cross-lingual compliance and policy monitoring at scale (policy, enterprise risk) — Continuous monitoring of multilingual regulations, press, and disclosures; retrieve and classify risk-relevant passages. — Tools/Workflow: Streaming ingestion; retrieval + classification adapters; reviewer dashboards; escalation workflows. — Dependencies/Assumptions: High recall across languages; gold-standard labeling for risk categories; operational governance.
- Federated, multilingual data lake search across billions of documents (enterprise, cloud) — Elastic, ANN-aware indexing with spread-out regularizer for uniform embedding utilization and efficient sharding. — Tools/Workflow: Sharded vector DBs; tiered Matryoshka storage; query routing; caching; cost-aware retrieval. — Dependencies/Assumptions: Distributed systems engineering; consistent adapter use throughout pipelines; operational SLOs.
- Adaptive budget-aware retrieval tiers (software, platform) — Dynamically trade off latency vs. accuracy by switching embedding dimensionality (Matryoshka) and ANN precision per user/session. — Tools/Workflow: Policy engine; telemetry-driven dimension selection; progressive reranking. — Dependencies/Assumptions: Careful evaluation of truncation impacts per task; user experience design for tier transitions.
- Low-resource language expansion and fairness benchmarking (academia, public sector) — Extend training with more languages and domain texts; build fairness and robustness suites for multilingual IR and classification. — Tools/Workflow: Data collection partnerships; synthetic + human-validated corpora; standardized fairness tests. — Dependencies/Assumptions: Data availability; cultural/linguistic nuances; open benchmarks and community validation.
- Regulatory-grade analytics on financial and ESG disclosures (finance, policy) — Classify and retrieve statements linked to risk factors, greenwashing, and compliance metrics across long filings. — Tools/Workflow: Domain adapters; long-document retrieval; auditor workflows; model governance. — Dependencies/Assumptions: Regulator acceptance; labeled exemplars; explainability for audit trails.
- Clinical decision support retrieval and cohort discovery (healthcare) — Retrieve relevant guidelines, studies, and patient cohorts from long EHR notes; cross-lingual public health surveillance. — Tools/Workflow: Secure deployment; domain adapters; PHI handling; clinician-in-the-loop validation. — Dependencies/Assumptions: Strict privacy/compliance; clinical annotation availability; safety and efficacy studies.
- Global plagiarism and integrity detection across educational content (education) — STS-driven similarity checks across languages and long documents; detect paraphrase-based evasion. — Tools/Workflow: Institution-scale indexing; reviewer workflows; calibration per discipline. — Dependencies/Assumptions: Institutional policies; false positive/negative management; multilingual edge cases.
Notes on Feasibility, Assumptions, and Dependencies
- Adapter discipline is crucial: select the correct LoRA adapter per task (retrieval, STS, clustering, classification); otherwise performance degrades.
- Prefix usage matters: use “Query:” for queries and “Document:” for targets; STS/clustering/classification commonly use “Document:” only.
- Vector infrastructure is required: adopt ANN libraries and vector databases; tune for quantization and spread-out regularization benefits.
- Long-context behavior depends on RoPE settings and hardware; performance on very long documents may vary outside training distribution.
- Multilingual coverage is strong but not uniform; less-resourced languages may need domain adaptation or additional data.
- Matryoshka truncation enables elastic storage/latency trade-offs but requires careful evaluation per task.
- Binary quantization robustness is improved via GOR regularization, but pipeline changes (indexing strategy, ANN parameters) affect outcomes.
- Licensing/usage terms for released weights must be reviewed on Hugging Face; integration may require compliance checks.
Collections
Sign up for free to add this paper to one or more collections.