Dex4D: Task-Agnostic Point Track Policy for Sim-to-Real Dexterous Manipulation
Abstract: Learning generalist policies capable of accomplishing a plethora of everyday tasks remains an open challenge in dexterous manipulation. In particular, collecting large-scale manipulation data via real-world teleoperation is expensive and difficult to scale. While learning in simulation provides a feasible alternative, designing multiple task-specific environments and rewards for training is similarly challenging. We propose Dex4D, a framework that instead leverages simulation for learning task-agnostic dexterous skills that can be flexibly recomposed to perform diverse real-world manipulation tasks. Specifically, Dex4D learns a domain-agnostic 3D point track conditioned policy capable of manipulating any object to any desired pose. We train this 'Anypose-to-Anypose' policy in simulation across thousands of objects with diverse pose configurations, covering a broad space of robot-object interactions that can be composed at test time. At deployment, this policy can be zero-shot transferred to real-world tasks without finetuning, simply by prompting it with desired object-centric point tracks extracted from generated videos. During execution, Dex4D uses online point tracking for closed-loop perception and control. Extensive experiments in simulation and on real robots show that our method enables zero-shot deployment for diverse dexterous manipulation tasks and yields consistent improvements over prior baselines. Furthermore, we demonstrate strong generalization to novel objects, scene layouts, backgrounds, and trajectories, highlighting the robustness and scalability of the proposed framework.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Dex4D, a way to teach a robot hand to handle many different objects and tasks without needing a special program for each one. Instead of learning “how to pour,” “how to stack,” or “how to hammer” as separate skills, the robot learns one general skill: move an object from wherever it is now to wherever you want it to be. The robot practices this in a simulator and then uses that skill in the real world.
What questions did the researchers ask?
- Can a robot hand learn a single, general skill that works across many everyday tasks, instead of learning each task separately?
- Can we train that skill entirely in simulation and still have it work on a real robot without extra fine-tuning?
- Is there a simple way to describe “what the robot should do” that works across tasks?
- Can we use modern video-generating AI to plan tasks and turn those plans into instructions a robot can follow?
How did they do it?
The team’s big idea is to teach a robot to change an object’s pose (its position and rotation) from “any pose” to “any other pose.” They call this “Anypose-to-Anypose” (AP2AP). Here’s how they made that work in a way a real robot can use.
A simple goal format: point tracks (think “connect-the-dots”)
- Imagine placing a few dots on an object and then showing where each dot should go next. Those dots form a “point track,” like breadcrumbs that say “move the object so these dots end up here.”
- This is a universal way to describe goals: it works for pouring, stacking, rotating, and more, without special instructions for each task.
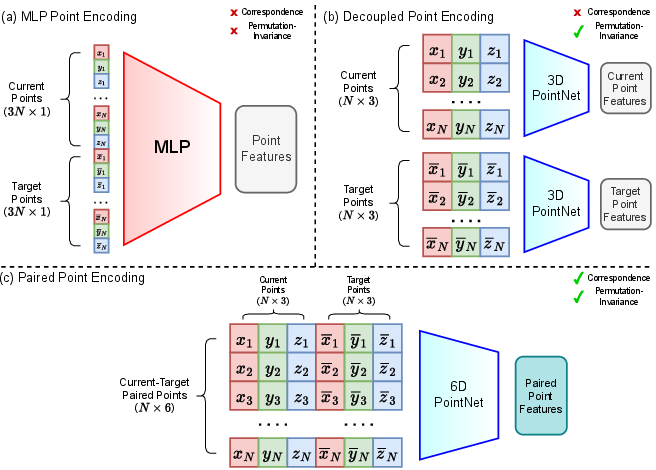
A smart way to read the goals: Paired Point Encoding
- The robot doesn’t just see “current dots” and “target dots” separately; it sees them as pairs. Think: each current dot is directly matched to its future spot.
- This pairwise matching helps the robot understand rotation and movement better, because it knows which point becomes which.
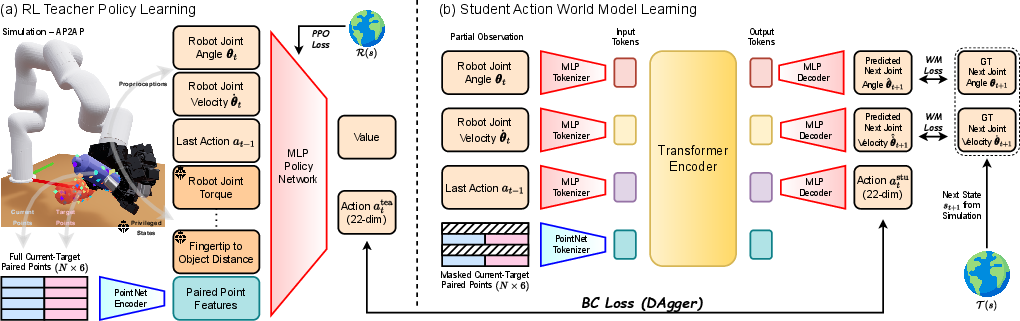
Train in simulation with a teacher–student setup
- Teacher: In the simulator, a “teacher” policy learns by trial and error (reinforcement learning) with extra information only available in simulation (like perfect object measurements).
- Student: Then a “student” policy learns to copy the teacher using only the kinds of data a real robot would have (joint sensors and a partial view of the object). The student uses a transformer model that predicts both the next action and how the robot will move, making it more stable and predictable.
To make the student robust in the real world:
- They randomly hide parts of the object in training (to mimic camera occlusions).
- They add noise and vary physics (to handle messy, unpredictable reality).
Planning with AI videos, then acting in the real world
- Planning: Given a task description (like “pour water into a bowl”), they ask a video model to “imagine” a short video of the task being done.
- From that video, they track a few points on the object through time and lift those to 3D. That becomes the goal “point tracks.”
- Acting: The real robot uses its camera to track the object’s current dots, compares them to the target dots, and continuously moves to make them match—step by step, in a closed loop. When it matches one mini-goal, it moves on to the next.
What did they find?
- It works across many tasks: In simulation and on real robots, Dex4D could handle different tasks like lifting, pouring, stacking, rotating, and moving objects to plates or bowls, even with objects it hadn’t seen before.
- No real-world training required: The policy was trained only in simulation but still worked on the real robot (“zero-shot” transfer).
- Better than planning-only baselines: Compared to methods that plan motion from point matches and rely on open-loop or arm-only control, Dex4D was more reliable. It improved success rates and made more progress on tasks because:
- It uses closed-loop feedback (keeps adjusting as it goes).
- It controls both arm and fingers together, so objects don’t slip.
- It handles noisy or few visible points better.
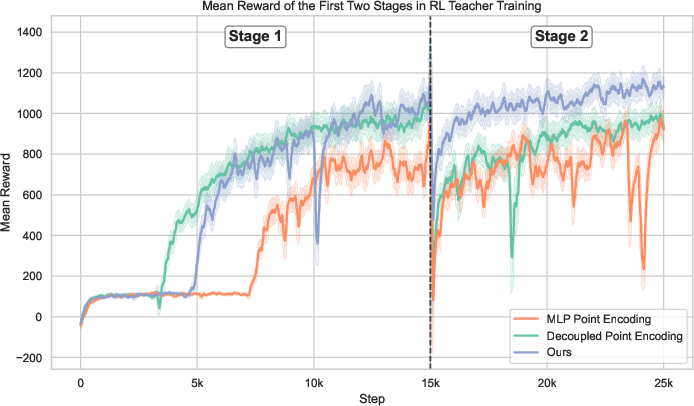
- Key ingredients matter:
- Paired Point Encoding made learning easier and results better than treating current and target points separately.
- The transformer “action world model” that predicts both actions and next robot state improved stability and performance.
- Closed-loop tracking and control were crucial, especially for tricky, finger-heavy tasks.
In real-world trials across four tasks, Dex4D succeeded on almost twice as many attempts as a strong baseline that used pose estimation plus motion planning.
Why does this matter?
- Fewer hand-crafted tasks: Instead of engineering each task with custom rules, one general “move object from A to B” skill can cover many situations.
- Faster, cheaper training: Training in simulation avoids collecting huge amounts of real robot data, which is slow and expensive.
- Better use of AI videos: Video models can imagine plans for a wide range of tasks; Dex4D turns those plans into simple “point tracks” a robot can reliably follow.
- More robust dexterity: By learning to control the hand and arm together with feedback, the robot can handle real-world messiness, like occlusions, sensor noise, and small mistakes.
What’s next?
The authors note some limitations and future directions:
- Tracking points can still fail when the object moves fast or fingers block the view; better, faster trackers would help.
- The method currently focuses on single objects; extending to articulated or multi-object tasks is a natural next step.
- Adding touch (tactile) sensing and using human hand data could further improve dexterity.
Overall, Dex4D shows a clear path toward more general, reliable robot hands by combining simulation training, a universal goal format (point tracks), and AI-generated video plans.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Robustness of Paired Point Encoding to correspondence errors: The method assumes consistent current–target point correspondences from trackers; quantify sensitivity to index drift, reordering, and partial mismatches, and explore correspondence-agnostic or soft-matching encoders.
- Failure handling for severe occlusions: While masking is used in training, there is no systematic analysis of performance vs. visibility (e.g., below 5–10 visible points); characterize failure thresholds and develop occlusion-aware perception-policy fusion.
- Tracker reliability under contact-rich manipulation: CoTracker3 often loses points during large motions or occlusions; evaluate integrated re-initialization, outlier rejection, and multi-hypothesis tracking to prevent catastrophic plan derailment.
- Depth calibration from generated videos: The “median-ratio” relative-to-metric depth calibration is heuristic; quantify depth scale error, drift across long horizons, and failure cases (e.g., perspective changes, non-rigid backgrounds), and test alternative metric reconstruction methods.
- Validation of plan feasibility from video models: Generated videos can propose physically infeasible or embodiment-incompatible motions; add constraint-aware feasibility checks, contact/kinematics validation, or plan repair modules before policy execution.
- Sensitivity to planner quality: No ablation on how different video generators, prompt choices, or plan errors impact success; systematically evaluate dependence on planner quality and introduce recovery strategies when plans degrade.
- Single-view sensing limitation: Only a single RGB-D view is used; study multi-view fusion, active view selection, or egomotion-aware reconstruction to reduce occlusion-induced failures and improve metric accuracy.
- Lack of tactile sensing: No tactile feedback is used; evaluate integration of tactile cues for slip detection, contact localization, and force regulation, especially for heavy, slippery, or deformable objects.
- Limited control modality: Actions are in joint space with PD control; investigate torque/impedance control and hybrid force/motion strategies to improve robustness in contact-rich tasks and compliant interactions with the environment.
- Generalization beyond single-object tasks: AP2AP is restricted to single-object manipulation; extend to multi-object scenes, bimanual coordination, and tasks that require tool-use or sequential object interactions.
- Articulated and deformable objects: The framework does not address articulated mechanisms (hinges, sliders) or highly deformable objects; develop representations and rewards that capture joint constraints and deformation-aware targets.
- Non-prehensile and complex contact strategies: AP2AP emphasizes pose-to-pose transformations; explore pushing, pivoting, in-hand rolling, and other non-prehensile actions with dynamic stability and contact planning.
- Explicit object-state estimation: The student world model predicts only robot joint state, not object pose/dynamics; study joint robot–object state prediction to enable model-based safety checks and better closed-loop control.
- Uncertainty estimation and risk-aware control: No predictive uncertainty is used to adapt action aggressiveness or trigger replanning; incorporate uncertainty-aware perception and control to handle noisy points and latency.
- Latency and control frequency characterization: Real-time performance (perception + policy latency, control rates) is not reported; quantify latency budgets and their effect on success, and explore asynchronous pipelines or preview control.
- Hand embodiment dependence: Results are shown for a LEAP hand and xArm6; assess transfer to other dexterous hands/arms with different kinematics, sizes, and actuation, and study policy adaptation or retargeting.
- Domain randomization sufficiency: The paper lists many randomizations but does not ablate which are necessary/sufficient for transfer; perform sensitivity analyses to prioritize effective sim-to-real factors (e.g., depth noise, friction, lighting).
- Point selection and outlier handling: The real-world pipeline lacks robust outlier rejection and segmentation sanity checks; evaluate RANSAC/bi-directional tracking, confidence weighting, and background suppression for point-track quality.
- Goal progression heuristics: Advancement between target waypoints uses a fixed distance threshold; analyze threshold sensitivity, design adaptive progress criteria, or learn waypoint timing to prevent oscillation and premature switching.
- Evaluation breadth and fairness: Real-world evaluation covers 4 tasks with 10 trials each and compares to a single adapted baseline; extend to larger, more diverse task suites and compare against additional dexterous RL/IL baselines with closed-loop policies.
- Physical property variation: Effects of mass, friction, compliance, texture, and transparency on depth/tracking and manipulation success are not characterized; run controlled tests across a matrix of physical properties.
- Safety and failure recovery: No explicit safety monitors or recovery strategies (e.g., automatic regrasp, retreat-and-replan) are implemented; develop watchdogs for tracking loss, contact anomalies, and out-of-distribution states.
- Long-horizon and hierarchical planning: The approach follows frame-by-frame pose targets; investigate hierarchical abstractions (subgoals, skills) and temporal plan compression to improve efficiency and reliability over long tasks.
- Data efficiency and scaling laws: Training uses thousands of simulated objects, but there is no analysis of how object/task diversity, point count, or training steps affect performance; derive scaling curves to guide dataset and compute budgets.
- Open-world deployment constraints: Robustness to challenging sensing conditions (low light, specular/transparent objects, clutter, moving distractors) and dynamic environments is not empirically evaluated; establish stress tests for these regimes.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities described in the paper, assuming access to off‑the‑shelf RGBD sensing, modern video generation and tracking models, and a dexterous arm‑hand platform.
- Closed-loop dexterous pick‑and‑place and reorientation for irregular items (manufacturing, warehousing, e‑commerce)
- Potential tools/workflows: “Anypose API” to specify object pose targets via paired point sets; a ROS node that ingests object-centric point tracks (from generated or recorded videos), runs online tracking, and executes the Dex4D student policy; “PointTrack Supervisor” monitoring distance thresholds to advance waypoints.
- Assumptions/dependencies: Single-object scenes; reliable RGBD depth and 2D point tracking under partial occlusions; a calibrated camera-to-robot frame; tasks constrained to reachable kinematics and moderate dynamics.
- Food prep and light kitchen assembly tasks like transferring produce/ingredients to bowls/plates and controlled pouring (food service, home robotics)
- Potential tools/workflows: “Video-to-PointTracks Planner” microservice using SAM2 + CoTracker + relative depth calibration to turn a target video into 3D waypoints; pre-bundled pouring trajectories as point-track libraries for common containers.
- Assumptions/dependencies: Stable grip without tactile feedback; liquid-safe workspace; limited flow rates and container sizes; tracking must remain robust despite finger occlusions.
- Lab and small-part handling: stacking cup-like components, rotating small boxes, placing labware with precise pose targets (lab automation, education)
- Potential tools/workflows: Lab-friendly Dex4D “Goal Pose Player” that sequences object-centric point tracks from a clip library; Isaac Gym-based sim curriculum to tune for specific labware geometries before deployment.
- Assumptions/dependencies: Single-object manipulation; consistent illumination and background for robust tracking; shallow articulation (i.e., non-hinged items).
- Post-packaging rework: regrasping and repositioning misaligned items without reprogramming (manufacturing QA)
- Potential tools/workflows: On-the-fly “Visual Plan Prompting” with a short smartphone video of the desired correction; paired point encoding to map current-to-target pose for rapid correction.
- Assumptions/dependencies: Adequate visual line-of-sight; limited clutter; reliable camera calibration.
- Rapid prototyping and coursework for goal-conditioned 3D policy learning (academia, education)
- Potential tools/workflows: Open-source Dex4D training scripts (Isaac Gym) demonstrating teacher–student distillation; ablation-ready modules for Paired Point Encoding and transformer action world models; evaluation tasks mirroring Apple2Plate, Pour, StackCup, RotateBox, etc.
- Assumptions/dependencies: GPU access for training; availability of object meshes or point sampling procedures; stable sim-to-real calibration pipeline.
- Safety vetting of generative video plans before execution (industry policy, internal governance)
- Potential tools/workflows: “Plan Verification via Point Tracks” that validates feasibility (reachability, collision margins, distance thresholds) and flags unrealistic motions before deploying to the robot.
- Assumptions/dependencies: Access to a digital twin or a coarse environment model; basic collision checks; conservative motion limits for the arm-hand system.
- DIY/maker demonstrations: tidying toys, simple household pick‑and‑place using consumer-grade arms and an RGBD camera (daily life, education)
- Potential tools/workflows: A lightweight GUI to record or generate target videos and stream resulting point tracks to the Dex4D controller; “Anypose Goals Editor” to manually tweak waypoints when tracking is unreliable.
- Assumptions/dependencies: Modest payloads; uncluttered scenes; line-of-sight camera view; acceptance of occasional tracking dropouts.
Long-Term Applications
These require further research and development, scaling, additional sensing, or broader validation to be productized.
- Multi-object, contact-rich assembly (manufacturing, electronics)
- Potential tools/products: “Dex4D Assembly Studio” integrating CAD/digital twins to author multi-object pose graphs; multi-camera fusion and tactile sensing to maintain point correspondences when objects occlude each other.
- Assumptions/dependencies: Robust multi-object tracking; reliable correspondence maintenance; advanced safety and throughput guarantees.
- Articulated object manipulation (appliances, furniture, tools)
- Potential tools/products: An articulated “Anypose++” policy that encodes joint states/constraints alongside paired points; planners that turn video plans into kinematic chains and contact schedules.
- Assumptions/dependencies: New goal representations for joints/constraints; improved perception for hinges/sliders; richer reward shaping and curricula.
- General home assistants for cooking, tidying, and organization across diverse objects and layouts (consumer robotics)
- Potential tools/products: “Household Skill Library” of video-derived point tracks; adaptive world models that blend visual plans with tactile and audio feedback; cloud planning with local safety filters.
- Assumptions/dependencies: Reliable tracking in clutter; multi-modal sensing (tactile, audio, force); robust failure recovery; long-horizon plan adaptation.
- Clinical and rehabilitation manipulators for assistive dexterous tasks (healthcare)
- Potential tools/products: Safety-certified, human-in-the-loop “Point-Track Teleassist” where therapists specify pose targets via video; policy adapters for medical-grade manipulators and sterile environments.
- Assumptions/dependencies: Medical compliance and rigorous safety validation; integration with clinician workflows; fail-safe control under sensing dropouts.
- Standardization and certification for generative-model-driven robot control (policy, standards)
- Potential tools/workflows: Auditable pipelines that log video prompts, derived point tracks, and execution traces; conformance tests for tracking robustness and closed-loop stability; guidelines for data governance and model updates.
- Assumptions/dependencies: Cross-industry consensus; test suites and metrics for reliability; regulatory engagement.
- Tactile and force-aware dexterous manipulation with fewer visible points (robotics, software)
- Potential tools/workflows: “PointTrack–Tactile Fusion” that stabilizes correspondence with contact cues; control policies that learn to manage occlusions and grip transitions reliably.
- Assumptions/dependencies: High-quality tactile arrays; synchronized multi-modal streaming; revised architectures and training objectives.
- Scalable sim-to-real services for enterprise deployment (software, robotics platforms)
- Potential tools/products: Managed “Sim Farm” that trains AP2AP policies across thousands of CAD objects with domain randomization; APIs to push updated policies to fleets; dashboards for success rate/task progress monitoring.
- Assumptions/dependencies: Robust domain randomization recipes; standardized hardware abstractions; automated calibration; MLOps for continuous updates.
- High-precision micro-assembly and surgical-like dexterity (manufacturing, healthcare)
- Potential tools/products: Policies with sub-millimeter accuracy, hybrid visual-tactile servoing, and force limits; “Dex4D Precision Suite” with validated micro-tracking and latency guarantees.
- Assumptions/dependencies: Ultra-low-latency sensing/control; precise calibration; fail-operational safety; extensive certification.
- Educational benchmarks and competitions for 3D goal-conditioned dexterity (academia, community)
- Potential tools/products: Public datasets of object-centric point tracks, tasks, and curricula; standardized metrics (success rate, task progress, stability under occlusion/noise).
- Assumptions/dependencies: Community-maintained assets; reproducible hardware setups or simulators; shared evaluation servers.
Notes on cross-cutting dependencies:
- Current system assumes single-object manipulation; multi-object and articulated tasks will need new representations and trackers.
- Robustness hinges on reliable 2D point tracking and depth (SAM2, CoTracker, Video Depth Anything); partial occlusions and significant motion can break tracking.
- Safety-critical deployments will require formal verification, redundancy (multi-camera, tactile), and certified motion constraints.
- Generalization beyond the trained object distribution may require continued sim curriculum design, stronger domain randomization, and on-device adaptation.
Glossary
- 4D reconstruction: Reconstructing 3D geometry over time from video to capture object motion in 3D. "We leverage video generation and 4D reconstruction to generate object-centric point tracks."
- 6D pose: An object’s pose combining 3D position and 3D rotation. "For reward shaping, instead of directly using the 6D pose (object position + rotation), our reward function leverages object points for a smoother reward landscape~\cite{zhao2025resmimic}."
- Action world model: A model that jointly predicts robot actions and future robot states/dynamics. "we distill from the teacher and learn a transformer-based student action world model that jointly predicts actions and future robot states."
- Anypose-to-Anypose (AP2AP): A task-agnostic formulation/policy that transforms an object from any current pose to any target pose. "We propose Dex4D, which learns a point track conditioned policy for Anypose-to-Anypose -- manipulating any object from any current pose to any target pose."
- Apriltags: Visual fiducial markers used for camera/robot calibration. "We use a single-view RealSense D435 camera for RGBD sensing and Apriltags~\cite{olson2011apriltag} for calibration."
- Behavior cloning: Supervised imitation learning where a policy learns to mimic provided actions. "The action world model is trained with a combination of a DAgger behavior cloning loss and a world modeling loss:"
- Closed-loop: Control that uses continuous feedback during execution. "During execution, Dex4D uses online point tracking for closed-loop perception and control."
- CoTracker3: A neural point-tracking model for robust 2D point tracking in videos. "CoTracker3~\cite{karaev2025cotracker3} for 2D point tracking."
- Curriculum: A staged training schedule that gradually increases task difficulty. "To facilitate effective exploration and stable RL training, we adopt a three-stage curriculum."
- DAgger: Dataset Aggregation; an imitation learning algorithm that iteratively collects expert labels under the learner’s state distribution. "After training the teacher policy, we distill it into a student policy under partial observability using DAgger~\cite{ross2011reductiondagger}."
- Dexterous manipulation: Control of high-DoF robotic hands to perform complex, contact-rich tasks. "Learning generalist policies capable of accomplishing a plethora of everyday tasks remains an open challenge in dexterous manipulation."
- Domain randomization: Randomizing simulation parameters (e.g., noise, friction) to improve sim-to-real transfer robustness. "Throughout training, we apply extensive domain randomization, including observation and action noise, PD gains, hand–object friction, and external force disturbances, to enable smooth and robust sim-to-real transfer."
- Embodiment gaps: Mismatches between the physical morphology/dynamics of different agents (e.g., humans vs. robots). "However, these works suffer from large embodiment gaps and a lack of closed-loop feedback, which are crucial for highly dynamic tasks such as dexterous manipulation."
- Gaussian Splatting: A 3D scene representation using collections of Gaussians, used for perception/policy learning. "and Gaussian Splatting~\cite{lu2024manigaussian}) for policy learning."
- Goal-conditioned Markov Decision Process (MDP): An MDP where the policy and rewards are conditioned on a goal variable. "We formulate AP2AP as a goal-conditioned Markov Decision Process (MDP) ..."
- Inverse Kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. "Specifically, we first apply our method for dexterous grasping, and then at each timestep, we estimate the transformation between current and target object points, and do real-time IK to move the robot arm accordingly."
- Isaac Gym: A GPU-parallel physics simulation platform for large-scale robot training. "We train teacher and student policies using the Isaac Gym simulator~\cite{makoviychuk2021isaac}."
- Kabsch algorithm: An algorithm to compute the optimal rigid transformation between two sets of corresponding points. "performing open-loop motion planning based on transformation estimation between current and target object points using the Kabsch algorithm~\cite{kabsch1976solution}."
- LEAP hand: A 16-DoF robotic dexterous hand used in the experiments. "a 16-DoF LEAP hand~\cite{shaw2023leap}."
- Mean–max mixed pooling: A feature aggregation method combining mean and max pooling for permutation-invariant point encodings. "which consists of shared MLP layers and mean-max mixed pooling to encode them into paired point features."
- Motion planning: Computing collision-free, feasible trajectories to achieve a target pose or path. "which are executed by motion planning."
- Object-centric point tracks: Sequences of tracked points tied to an object, specifying its desired trajectory/poses over time. "We leverage video generation and 4D reconstruction to generate object-centric point tracks."
- Paired Point Encoding: A goal representation that concatenates corresponding current and target 3D points to preserve correspondences. "we propose Paired Point Encoding, a representation that explicitly preserves correspondence between the current and target object points."
- PointNet: A neural network architecture for point cloud processing using shared MLPs and symmetric pooling. "encode them using a lightweight PointNet~\cite{qi2017pointnet} to preserve both correspondence and permutation invariance."
- Proprioception: Internal robot sensing of joint states (angles, velocities) used for control. "the state consists of robot proprioception (joint angles and velocities), the last action, and privileged information (e.g., joint torques, fingertip-to-object distances, etc.)."
- Proximal Policy Optimization (PPO): An on-policy reinforcement learning algorithm with clipped objectives. "we train a teacher policy using PPO~\cite{schulman2017proximalppo} with privileged states and fully observed object geometry in simulation."
- Relative depth estimation: Estimating per-frame depth up to scale, later calibrated to metric depth. "Next, we perform relative depth estimation for each frame and calibrate it using the initial depth observation ."
- Reward shaping: Designing structured reward components to guide RL training. "We propose Anypose-to-Anypose, a task-agnostic sim-to-real learning formulation without tedious simulation tuning and task-specific reward shaping."
- Self-attention: An attention mechanism enabling tokens to attend to each other within a transformer. "and then processed by self-attention layers~\cite{vaswani2017attention}."
- Sim-to-real: Training policies in simulation and transferring them to the real world. "Learning dexterous manipulation behaviors via sim-to-real reinforcement learning (RL) provides a promising alternative~\cite{xu2023unidexgrasp, chen2023bi}."
- Transformer-based: Using transformer architectures with attention for policy/world modeling. "we distill from the teacher and learn a transformer-based student action world model that jointly predicts actions and future robot states."
- UniDexGrasp: A large-scale dexterous grasping dataset used for training and evaluation. "Our AP2AP policy is trained entirely in simulation using 3,200 objects from UniDexGrasp~\cite{xu2023unidexgrasp} under diverse pose configurations and extensive domain randomization."
- Video generation models: Generative models that synthesize videos and serve as high-level planners. "such as video generation models~\cite{wiedemer2025veo3, wan2025wan} that have shown remarkable open-world generalization"
- World modeling: Learning predictive models of robot/world dynamics to aid action learning and control. "We also leverage world modeling as auxiliary supervision signals to jointly learn action prediction and robot dynamics from proprioception and 3D perception."
- Zero-shot transfer: Deploying a policy to new tasks or environments without additional finetuning. "this policy can be zero-shot transferred to real-world tasks without finetuning, simply by prompting it with desired object-centric point tracks extracted from generated videos."
Collections
Sign up for free to add this paper to one or more collections.