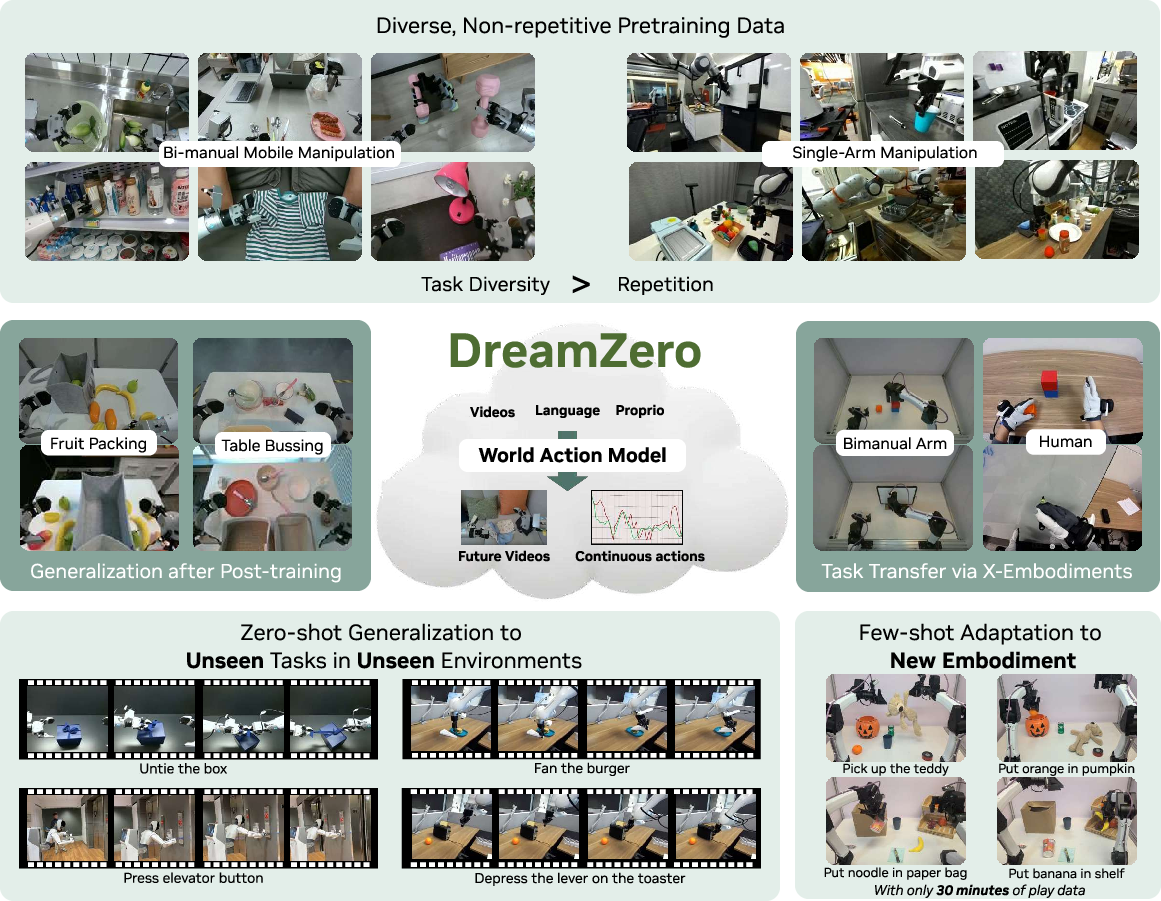
World Action Models are Zero-shot Policies
Abstract: State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from other robots or humans yield a relative improvement of over 42% on unseen task performance with just 10-20 minutes of data. More surprisingly, DreamZero enables few-shot embodiment adaptation, transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
What is this paper about?
This paper introduces a new kind of robot brain called a World Action Model (WAM). Instead of only reading text and looking at pictures to decide what to do, a WAM predicts a short “future video” of the world and the robot’s actions at the same time. By learning how the world is likely to change, the robot can figure out the right moves—even for tasks and places it has never seen before. The authors show that their 14-billion-parameter WAM can control real robots smoothly in real time and generalize far better than popular Vision-Language-Action (VLA) models.
Goals and Questions
The paper focuses on answering three simple questions:
- Can robots learn better when they predict what will happen next (as video) and what they should do (actions) together?
- Will this help robots do new tasks they weren’t trained on, and work in new environments they’ve never seen?
- Can robots learn from videos of other robots or humans and quickly adapt to a different robot body with very little extra practice?
How did they do it?
The team built a large model that:
- Watches the current scene and reads a text instruction (like “fold the shirt”).
- Predicts a short future: both a video of how the scene will change and a matching sequence of robot actions.
- Executes those actions, then replaces any predicted frames with the real camera frames it just saw, and continues. This keeps it from drifting off-course.
Here are the key ideas explained in everyday language:
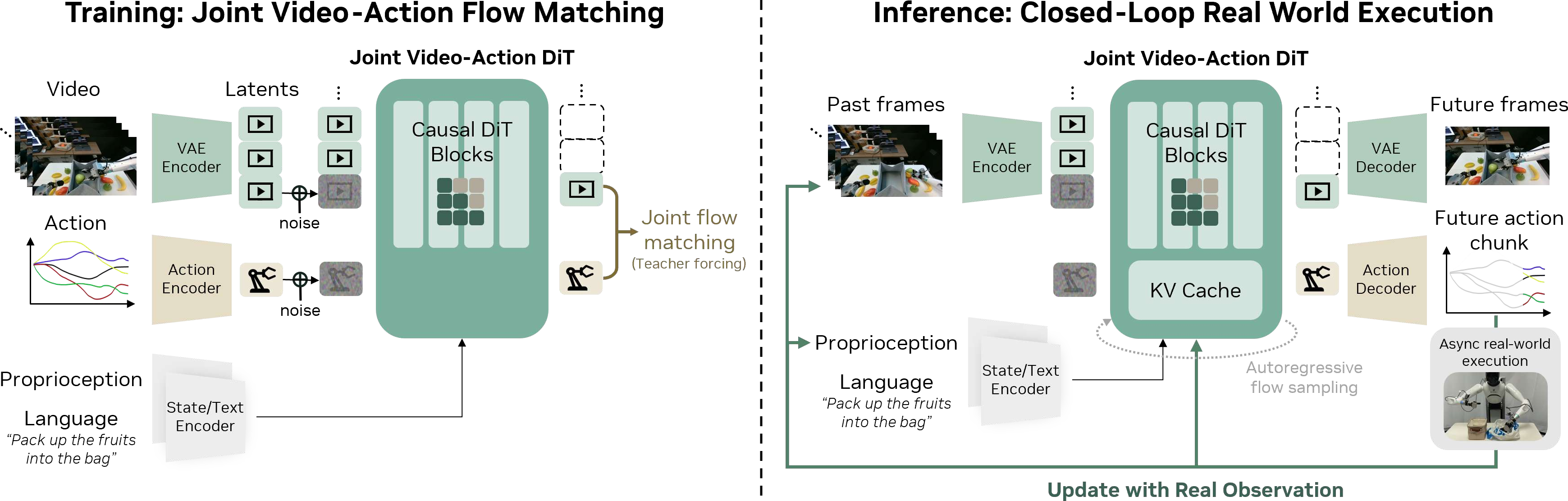
- Joint video-and-action prediction: Imagine planning by “daydreaming” a short movie of the next few seconds and, at the same time, deciding the exact moves to make that match that movie. If the predicted movie shows the shirt being folded, the actions will also fold the shirt. This tight link helps the robot stay aligned with real physics.
- Autoregressive generation: The model plans step by step, using what it just saw and did—like writing a story one sentence at a time and using the previous sentences to guide the next one. This keeps actions smooth and consistent.
- Diffusion model backbone: They start from a powerful video generator trained on tons of internet videos. A diffusion model is like starting with a noisy, blurry frame and gradually “cleaning” it into a realistic video. Because this model already knows a lot about how the world moves, the robot can use those motion “priors” (common patterns in real life) to act more intelligently.
- Teacher forcing: During training, the model is given the correct history (not only its own predictions), so it learns faster and doesn’t pick up bad habits.
- Real-time speed-ups: Diffusion models can be slow, which is bad for a moving robot. The authors combined smart system tricks (parallel processing, caching), software improvements (compiling and optimized GPU kernels), and a training tweak they call “Flash” (teaching the model to make clean action decisions even when the video is still a bit fuzzy). Together, these changes make the model fast enough to control a real robot at about 7 updates per second.
What did they find?
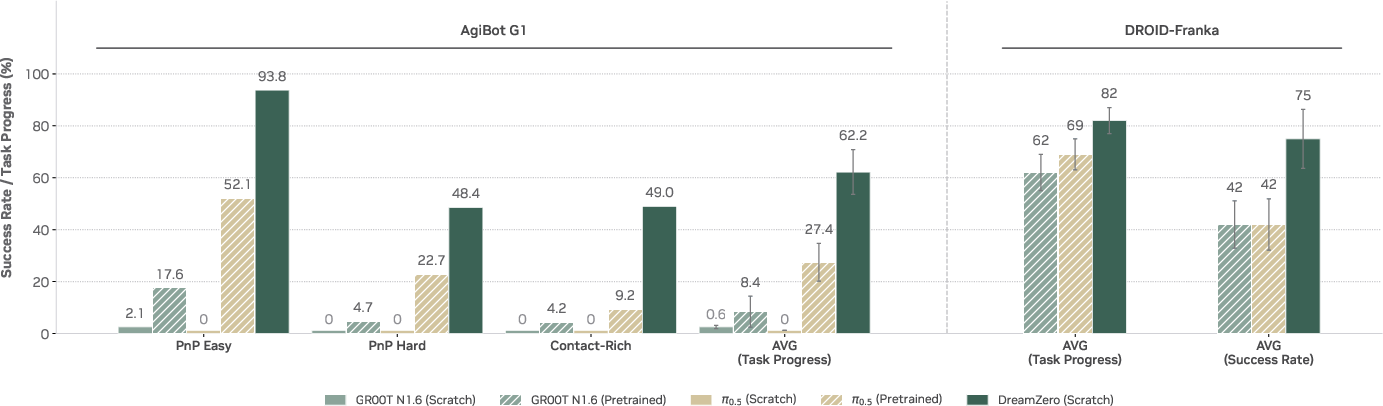
The main results show big wins over popular VLA models:
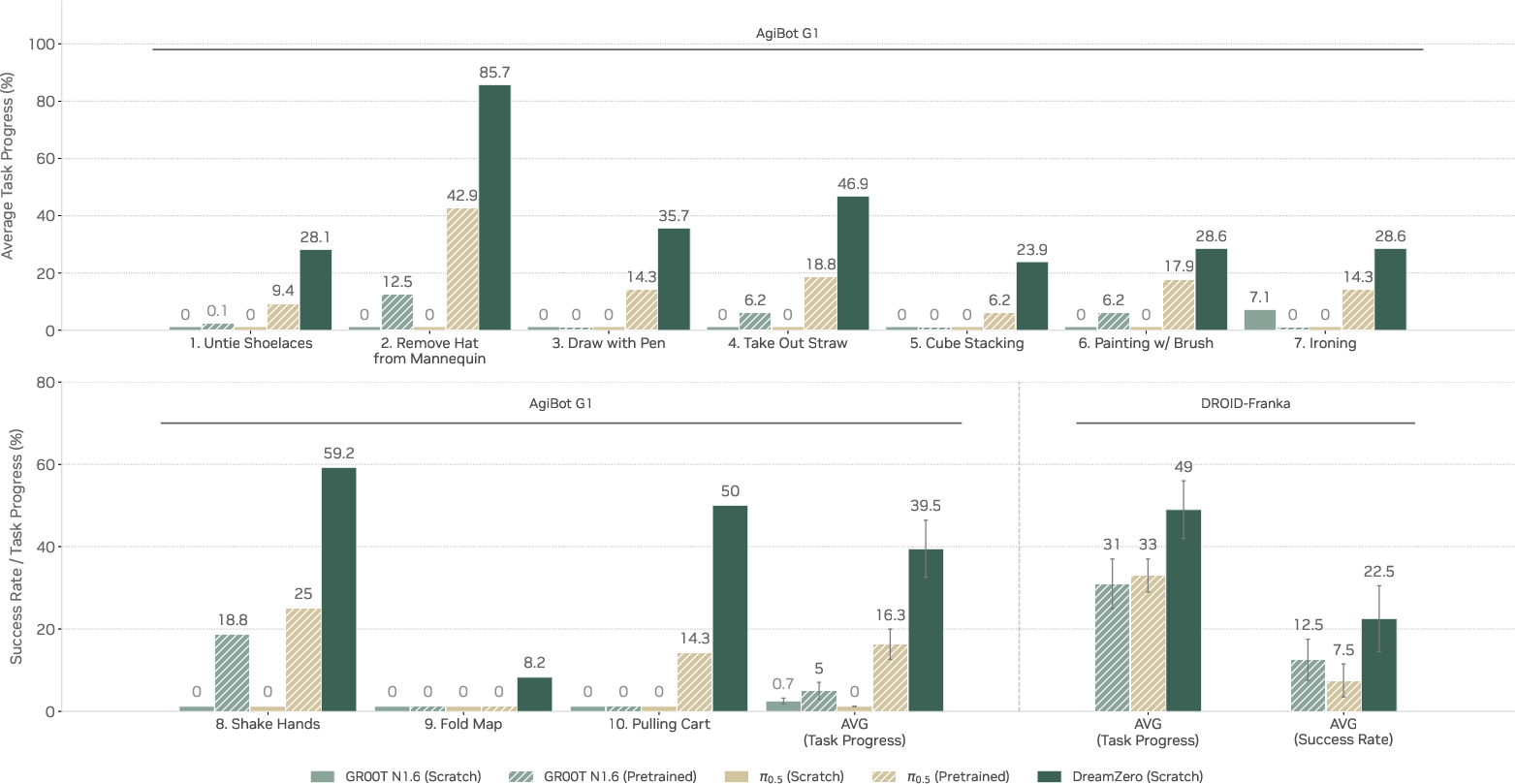
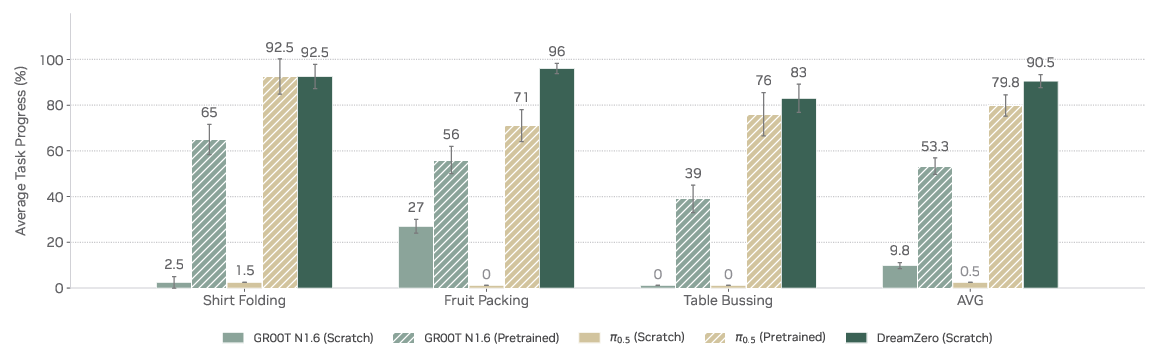
- Stronger generalization: On real robots, the WAM scored over 2× better than top VLA baselines when trying new tasks and working in new environments. For example, it could handle tasks like “remove a hat from a mannequin” or “shake hands,” even though those weren’t in the training set.
- Learns from diverse, non-repetitive data: Instead of needing many repeated demos of the same task, the WAM learned from a wide mix of real-world activities collected across homes, shops, and offices. This is more like how people learn—lots of variety, not just perfect repeats.
- Real-time control: With all the optimizations, the 14B model runs fast enough for smooth, closed-loop control at about 7 Hz, which is important so the robot can react quickly.
- Cross-embodiment transfer:
- Video-only demos: The robot improved by over 42% on new tasks just by watching 10–20 minutes of videos of humans or other robots doing them—no actions provided, only visuals.
- Few-shot adaptation: A model trained on one robot could adapt to a different robot body with only 30 minutes of playful practice while still keeping its “zero-shot” ability to handle new tasks.
- Quality of video matters: Better video prediction led to better actions. In other words, improving the “future movie” improves the robot’s performance.
Why it matters
This research points to a future where robots:
- Learn more like people—by watching and imagining what will happen next—rather than needing tons of perfectly repeated demonstrations.
- Handle new tasks and environments without special retraining, making them more useful in the real world (homes, hospitals, warehouses).
- Quickly adapt to different robot bodies and learn from videos of humans or other machines, reducing data collection costs.
- Benefit directly from advances in video generation: as video models get better, robot control can get better too.
In short, World Action Models make robots smarter, more flexible, and easier to teach—bringing us closer to helpful everyday robots that can learn and adapt on the fly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research:
- Missing head-to-head comparisons with recent WAMs built on pretrained video diffusion (e.g., COSMOS, Genie-based WAMs, MIMIC). Provide controlled ablations under identical data, compute, and evaluation protocols to isolate architectural and training contributions.
- Limited reproducibility due to non-released in-house AgiBot dataset (∼500 hours). Release the dataset or create a publicly reproducible surrogate (same environments, prompts, object pools) to enable third-party verification.
- Unclear generalizability across embodiments beyond the AgiBot G1 ↔ YAM pair. Systematically evaluate across a broader set of robot morphologies (mobile base vs fixed, 7-DoF vs 6-DoF, underactuated hands, different grippers).
- No multi-embodiment pretraining. Explore joint pretraining across multiple robots to test whether cross-embodiment priors learned from video-action alignment can reduce adaptation time further.
- Limited sensing modalities. Evaluate integrating tactile/force/FT sensors, depth/point clouds, and audio; assess whether joint modeling of non-visual world state (beyond video) further improves generalization and contact-rich skills.
- Action representation choices underexplored. Compare relative joints vs velocities vs operational-space Cartesian commands vs torque; quantify impacts on stability, contact handling, and generalization.
- Control frequency and latency constraints. Assess performance on high-speed or force-sensitive tasks that require >50–100 Hz control; quantify degradation from 7 Hz action updates and chunked execution.
- No formal stability or safety guarantees for asynchronous closed-loop execution. Analyze worst-case delays, missed deadlines, and staleness of action chunks; derive bounds or design watchdogs/fallback controllers.
- Failure mode taxonomy is missing. Provide systematic analysis of errors (video hallucinations, action-video misalignment, grasp failures, occlusion handling, contact misestimation) and their frequency.
- Robustness to real-world distribution shift not characterized. Test under lighting changes, heavy occlusions, camera jitter, sensor dropouts, moving humans/objects, clutter density, and weather for mobile settings.
- Uncertainty estimation and risk-aware control absent. Leverage diffusion’s inherent stochasticity or auxiliary heads to estimate uncertainty and modulate speed, contact force, or ask for help under uncertainty.
- Limited temporal memory analysis. Quantify how long the KV cache can be effectively used (minutes vs tens of minutes), truncation strategies, and the impact of memory length on long-horizon tasks (e.g., multi-room navigation + manipulation).
- Autoregressive-only video modeling choice not fully validated. Provide controlled comparisons with bidirectional or hybrid architectures on modality alignment, long-horizon error accumulation, and inference efficiency.
- Teacher forcing and train–test mismatch. Measure exposure bias within-chunk and across chunks; evaluate scheduled sampling or consistency training to reduce reliance on clean-history conditioning.
- Chunk length and horizon design. Ablate chunk size, overlap, and smoothing strategies; quantify trade-offs between reactivity, smoothness, and long-horizon planning.
- “Video quality → policy performance” claim is not quantified. Correlate standard video metrics (e.g., VBench/FVD) and task success across backbones, sampling steps, and denoisers to validate this causal link.
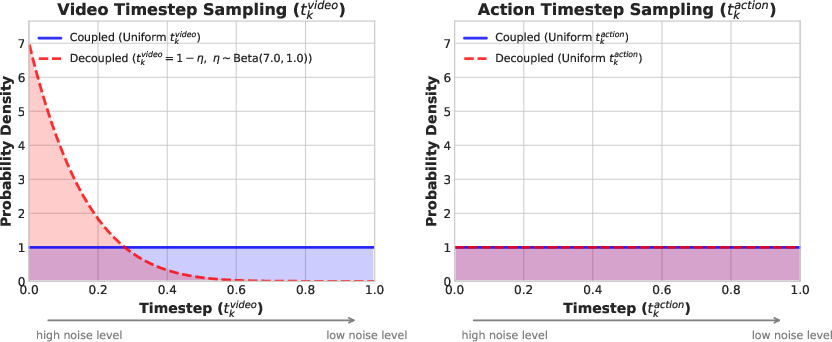
- Impact of -Flash decoupled noise schedules on video fidelity and alignment. Quantify whether biased video noise harms visual prediction quality, temporal consistency, or action-video coherence in few-step and full-step regimes.
- Inference hardware dependence. Report absolute latency and success on single-GPU H100/consumer GPUs; assess deployability on edge/onboard compute and power-constrained platforms.
- Data diversity vs repetition trade-offs only qualitatively discussed. Provide controlled studies matching hours but varying heterogeneity/repetition to quantify their effects on learning and generalization.
- Language grounding depth not evaluated. Test compositional generalization (unseen verb–object pairings, multi-step instructions, negation, spatial prepositions) and diagnose instruction-following failure modes.
- Safety in human-robot interaction tasks (e.g., shaking hands) not addressed. Specify force limits, proximity constraints, and compliance strategies; evaluate under IRB-like safety protocols.
- No baselines from classical control/planning. Compare to visual servoing, MPC over learned latent dynamics, or task-specific controllers on subsets where they are strong, to contextualize gains.
- Cross-embodiment video-only learning mechanism unclear. Detail how viewpoint differences, camera intrinsics/extrinsics, and embodiment mismatches are handled; study sensitivity to viewpoint and domain gaps.
- Continual learning and catastrophic forgetting. Measure retention of zero-shot generalization after embodiment adaptation and task-specific post-training; develop strategies to prevent forgetting.
- Sim–real generalization only anecdotally noted. Provide quantitative results on Genie Sim 3.0 (or other sims) and analyze failure transfer patterns between sim and real.
- Dataset ethics and privacy. Clarify consent/anonymization for data collected in public or semi-public spaces (homes, restaurants), and outline procedures for compliant data release.
- Navigation–manipulation integration. Evaluate tasks requiring multi-room navigation, mapping, and long-horizon temporal credit assignment; explore coupling with SLAM or world memory modules.
- Multi-view handling by naive concatenation may underuse geometry. Compare to architectures that explicitly model 3D geometry or perform multi-view fusion to handle occlusions and precise spatial reasoning.
- Planning over the world model not explored. Investigate using the WAM as a predictive model for planning (e.g., CEM/MPC in latent/video space) vs direct policy rollout.
- Evaluation statistics and significance. Increase rollout counts per task, report variance/confidence intervals, and conduct statistical tests to substantiate performance differences.
- Generalization taxonomy and benchmarks. Standardize what constitutes “unseen tasks” (new verbs vs new motion primitives vs new affordances) and release a public benchmark suite with clear scoring rules.
- Long-term autonomy and recovery. Study performance on hours-long deployments, including recovery from compounding minor errors, re-planning after failures, and re-localization after large disturbances.
- Safety filters beyond action smoothing. Incorporate constraint layers, contact-aware controllers, and learned safety critics to intercept unsafe commands predicted by the WAM.
- Environmental and compute cost reporting. Provide training/inference energy, carbon footprint, and cost; study compute–performance scaling and more efficient distillation/adapter strategies.
Glossary
- Affordances: Action possibilities implied by objects or environments that a robot can exploit. "visual traces, or affordances"
- Action horizon: The number of control steps in a single planned action segment or chunk. "an action horizon of 48 steps at 30Hz control frequency"
- Asynchronous execution: Running policy inference concurrently with ongoing robot motion to reduce perceived latency. "asynchronous execution that decouples inference from action execution."
- Attention masking: Restricting which tokens can attend to which others during transformer computation to enforce temporal or modality constraints. "apply attention masking"
- Autoregressive architecture: A model that predicts outputs sequentially, conditioning each prediction on previously generated context. "we adopt an autoregressive architecture"
- Autoregressive DiT backbone: A diffusion transformer set up to generate sequences by conditioning on past tokens. "autoregressive DiT backbone"
- Autoregressive generation: Producing sequences step-by-step, using prior generated content as context. "Autoregressive generation possesses the following advantages"
- Autoregressive video generation: Predicting future video frames one step at a time, which can accumulate errors over long horizons. "the compounding error problem inherent to autoregressive video generation"
- Beta distribution: A probability distribution on [0,1] used here to bias noise levels during training. "via a Beta distribution"
- Bidirectional diffusion: Diffusion modeling that processes fixed-length sequences without strict causality, often requiring subsampling. "bidirectional diffusion typically requires processing fixed-length sequences"
- Blackwell architecture: NVIDIA’s GPU architecture generation (e.g., GB200) referenced for specific quantization support. "On Blackwell architecture, we quantize weights and activations to NVFP4"
- Classifier-free guidance (CFG): A generative technique combining conditional and unconditional predictions to steer outputs without an explicit classifier. "Classifier-free guidance requires two forward passes"
- Closed-loop control: Control that continuously uses sensor feedback to update actions during execution. "real-time closed-loop control at 7Hz"
- Cross-embodiment transfer: Leveraging data from one robot or humans to improve performance on another robot. "we demonstrate two forms of cross-embodiment transfer"
- CUDA Graphs: A CUDA feature that captures and replays GPU workloads to reduce launch overhead and improve throughput. "CUDA Graphs"
- cuDNN backend: NVIDIA’s optimized deep learning library used for efficient attention and other kernels. "We use the cuDNN backend for attention"
- Denoising timestep: The scalar parameter in diffusion that controls the noise level of latents at each step. "the denoising timestep "
- Diffusion Transformer (DiT): A transformer architecture adapted to predict velocities or scores within diffusion models. "DiT backbone"
- DiT caching: Reusing previously computed diffusion velocities/steps to cut the number of expensive backbone passes. "DiT Caching"
- Few-shot embodiment adaptation: Adapting a policy to a new robot using only a small amount of data while retaining generalization. "few-shot embodiment adaptation"
- Flow matching: A training objective that learns a velocity field to match probability flows between noise and data distributions. "we employ flow-matching"
- Image-to-video diffusion model: A generative model that predicts future video frames conditioned on a single image using diffusion. "a 14B image-to-video diffusion model"
- Inverse dynamics model (IDM): A model that infers actions needed to transition between observed states. "inverse-dynamics model (IDM)"
- KV cache: Cached key and value tensors in transformers to accelerate long-context autoregressive inference. "ground-truth observations are fed back into the KV cache"
- Latent world models: Models that learn environment dynamics in compact latent spaces rather than directly on pixels. "latent world models"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning technique for large models. "We experimented with LoRA"
- NVFP4: NVIDIA’s 4-bit floating-point format used for aggressive post-training quantization. "NVFP4"
- Optical flow: Per-pixel motion field estimation between consecutive frames used for dense correspondence. "optical flow as dense correspondence"
- Proprioceptive state: Internal robot measurements (e.g., joint positions) used as inputs to the policy. "proprioceptive state"
- QKV attention: The query-key-value mechanism in transformers; here, with masking strategies across modalities. "QKV attention masking strategy"
- Savitzky-Golay filter: A smoothing filter that fits local polynomials to reduce high-frequency noise in signals. "apply a Savitzky-Golay filter"
- Spatiotemporal priors: Prior knowledge of space and time dynamics learned from large-scale videos. "rich spatiotemporal priors"
- Teacher forcing: Training that feeds ground-truth previous outputs into the model to stabilize sequence learning. "apply teacher forcing"
- torch.compile: PyTorch’s compilation API that fuses and optimizes operations for faster inference. "torch.compile"
- VAE (Variational Autoencoder): A generative encoder-decoder that learns latent representations via variational inference. "encoded via a VAE"
- Video diffusion models: Diffusion-based generative models that synthesize videos through iterative denoising. "video diffusion models require iterative denoising"
- World Action Model (WAM): A model that jointly predicts future visual states and actions to align control with world dynamics. "World Action Model (WAM)"
- World modeling objective: The objective of predicting future environment states to guide planning and action. "world modeling objective"
- Zero-shot generalization: Performing novel tasks without additional task-specific training data. "zero-shot generalization to new tasks"
Practical Applications
Immediate Applications
Below are applications that can be deployed now, leveraging the paper’s demonstrated capabilities: joint video–action prediction, real-time closed-loop control at 7 Hz, learning from heterogeneous play data, video-only cross-embodiment transfer, and few-shot embodiment adaptation.
- Generalist mobile manipulation for hospitality and facilities
- Sector: robotics, hospitality, janitorial services
- Description: Deploy the WAM policy on mobile bimanual manipulators for table bussing, dish sorting, wiping, pick-and-place, stacking, and laundry folding in cafes, restaurants, offices, and homes—tasks the paper shows strong performance on in unseen environments with unseen objects.
- Tools/products/workflows: WAM runtime with asynchronous closed-loop control; DreamZero open-source weights and inference code; -Flash for low-latency inference; task-specific post-training pipelines (e.g., 12–40 h for fruit packing, table bussing, shirt folding).
- Assumptions/dependencies: High-end GPU (GB200 or H100) or access to accelerated inference appliance; reliable RGB camera streams and proprioceptive state; safety monitors and fail-safes; site-specific calibration; acceptance of partial task progress for long-horizon sequences.
- Retail and light warehousing pick-and-place in dynamic shelves
- Sector: retail, logistics
- Description: Use zero-shot environment generalization for restocking, kitting, and bagging (e.g., fruit packing) with minimal reprogramming; adapt quickly to layout changes and novel objects.
- Tools/products/workflows: “Video-to-Action Skill Authoring” pipeline where staff record short video-only demonstrations (10–20 min) to improve unseen task performance by ~42%; DreamZero code for deployment; action chunk smoothing for smooth motions.
- Assumptions/dependencies: Camera viewpoint consistency between human/robot demonstration; basic grasping hardware; GPU compute; safety interlocks for aisle traffic.
- Household assistive chores customization via short videos
- Sector: consumer robotics, daily life
- Description: Owners record short videos showing desired ways to fold clothes, organize shelves, or wipe surfaces; the WAM adapts to preferences using video-only data, without extensive teleoperation.
- Tools/products/workflows: “Video Skills Studio” for onboarding new skills; few-shot video-only tuning workflow; smartphone capture to robot alignment utilities.
- Assumptions/dependencies: Robust privacy and consent handling for household videos; camera view alignment; consumer-grade robot with adequate manipulation capabilities; safety gating based on video prediction quality.
- Rapid porting of policies between robot platforms (few-shot embodiment adaptation)
- Sector: robotics OEMs/integrators
- Description: Transfer a pretrained policy to a new robot in ~30 minutes of play data, retaining zero-shot generalization (demonstrated from AgiBot G1 to YAM).
- Tools/products/workflows: Cross-Embodiment Adapter SDK; calibration routines for state/action spaces; minimal architecture changes (add state/action encoders/decoders).
- Assumptions/dependencies: Compatible action representation (e.g., relative joint positions); correct proprioception mapping; basic play data collection on target platform.
- Academic benchmarking and reproducible research on world–action alignment
- Sector: academia, education
- Description: Use open-source weights and code to run RoboArena (real) and PolaRiS/Genie Sim 3.0 (sim) evaluations, study autoregressive vs. bidirectional design, and quantify how video generation quality drives policy performance.
- Tools/products/workflows: Training scripts with teacher-forcing chunk-wise video denoising; ablations across model sizes (5B vs. 14B); environment and object generalization protocols.
- Assumptions/dependencies: Access to public datasets (DROID) and benchmarks; GPU resources; lab safety protocols for real-robot trials.
- Real-time WAM inference stack for enterprise deployments
- Sector: software, robotics infrastructure
- Description: Productionize the paper’s low-latency inference stack (38× speedup on GB200) combining CFG parallelism, DiT caching, torch.compile + CUDA Graphs, NVFP4 quantization, and -Flash training.
- Tools/products/workflows: “WAM Inference Appliance” or cloud service; deployment templates for 7 Hz closed-loop control with 30 Hz motor servo; KV cache integration with live observations.
- Assumptions/dependencies: Specific GPU support for quantization (e.g., NVFP4 on Blackwell); integration with robot motion controllers; monitoring for latency bounds (≤150–200 ms per chunk).
- Healthcare logistics (non-patient-facing)
- Sector: healthcare
- Description: Linen handling, surface wiping, supply restocking, and bin sorting in hospitals or elder-care facilities where environment changes are frequent and exact task repetition is impractical.
- Tools/products/workflows: On-site post-training with modest data (10–40 h per task); video-only demos by staff for local variations; safety and hygiene protocols.
- Assumptions/dependencies: Strict safety constraints; environmental sanitization; camera and robot sterilization protocols; oversight by clinical staff.
- Construction and maintenance micro-tasks
- Sector: construction, maintenance
- Description: Simple painting/wiping in controlled zones; removing protective caps; moving small fixtures—leveraging zero-shot generalization to novel scenes and objects.
- Tools/products/workflows: Site capture for environment context; short video demonstrations; runtime that leverages long visual history via KV caching.
- Assumptions/dependencies: Suitable end-effectors; safe separation from humans; robustness to dust/occlusions; reliable lighting and camera placement.
- Simulation-informed deployment gating
- Sector: robotics software, safety
- Description: Use Genie Sim 3.0 and PolaRiS as pre-deployment validation to estimate performance on new tasks or sites; proceed to controlled pilots before full roll-out.
- Tools/products/workflows: Sim-to-real workflows; result dashboards; task progress scoring; trial gating thresholds.
- Assumptions/dependencies: Sim-to-real gap management; domain randomization; conservative criteria for promotion to real-world trials.
- Governance, privacy, and safety checklists for video-driven learning
- Sector: policy, compliance
- Description: Establish data consent and retention policies for video-only training; create site-specific safety assessments for zero-shot deployments.
- Tools/products/workflows: Data governance templates; safety case documentation; human-in-the-loop override procedures; audit trails of training and evaluation runs.
- Assumptions/dependencies: Organizational buy-in; legal review for video data handling; incident response mechanisms.
Long-Term Applications
These applications require further research, scaling, or development, including improved video generation quality, additional modalities (tactile/force), broader embodiment coverage, safety certification, and edge deployment.
- Generalist home assistant learning personalized chores on-device
- Sector: consumer robotics, daily life
- Description: A robot that reliably learns new tasks from a user’s short videos and adapts to household changes—folding varied garments, organizing, cleaning—without cloud training.
- Tools/products/workflows: On-device distillation and quantization; persistent memory for long-horizon tasks; safety gating via multimodal monitors; “Video Skills Studio” embedded in the robot.
- Assumptions/dependencies: Edge-capable inference (smaller distilled WAMs); high reliability in contact-rich manipulation; robust video prediction in low light; strong privacy guarantees.
- Cross-modal World Action Models (tactile/force/3D)
- Sector: robotics, advanced manipulation
- Description: Extend WAMs beyond video to tactile and force sensing or 3D world prediction, enabling precise contact-rich tasks (e.g., shoelace untying, garment handling, assembly).
- Tools/products/workflows: Multimodal encoders/decoders; datasets with aligned force/vision/tactile; training objectives for joint multimodal denoising; new safety monitors.
- Assumptions/dependencies: Sensorized grippers; curated multimodal datasets; architectural changes to fuse modalities; higher compute budgets.
- Unified multi-embodiment foundation model for fleets
- Sector: robotics OEMs/integrators
- Description: A single WAM trained across many robot types (arms, mobile bases, bimanual, humanoids) that transfers skills seamlessly across embodiments and sites.
- Tools/products/workflows: Standardized action/state schemas; automated calibration pipelines; fleet learning and continuous deployment infrastructure.
- Assumptions/dependencies: Large-scale multi-embodiment datasets; alignment across kinematics; rigorous testing across diverse environments.
- High-reliability autonomous industrial assembly
- Sector: manufacturing
- Description: Open-world assembly and rework tasks with many variants and tolerances, guided by visual futures and language instructions, reducing reprogramming costs.
- Tools/products/workflows: Integration with language reasoners for high-level planning; precision grippers; multimodal WAMs for fine contact; stringent QA and certification.
- Assumptions/dependencies: Near-perfect reliability; compliance with industrial safety standards; improved video-action alignment at fine spatial resolutions.
- Human–robot collaboration with gestures and handovers
- Sector: robotics, HRI
- Description: Learning nuanced interactive skills (shake hands, handover tools) from human videos; robust bidirectional perception for intent recognition and timing.
- Tools/products/workflows: HRI datasets; intent-aware conditioning; temporal alignment modules; safety envelopes for proximity.
- Assumptions/dependencies: Advanced perception and prediction under occlusions; social and ergonomic constraints; formal user studies and regulatory review.
- Adaptive disaster response and field robotics
- Sector: public safety, defense
- Description: Operation in unstructured environments with occlusions, debris, and poor visibility; zero-shot adaptation and video-guided action where teleoperation is limited.
- Tools/products/workflows: Ruggedized robots; multimodal WAMs; uncertainty-aware policies; redundancy in sensing; offline and online adaptation loops.
- Assumptions/dependencies: Robustness to extreme conditions; real-time reliability under compute constraints; stringent safety oversight.
- Healthcare assistance near patients
- Sector: healthcare
- Description: Assistive tasks that involve close contact (dressing assistance, feeding support) with learned tactile-aware policies for safety and comfort.
- Tools/products/workflows: Clinical-grade sensors; multimodal safety monitors; trial protocols; human-in-the-loop supervision; compliance with medical device regulations.
- Assumptions/dependencies: High safety certification; extensive clinical trials; strong multimodal modeling and error recovery.
- Energy-efficient WAMs and sustainable deployment
- Sector: energy, policy
- Description: Distilled/smaller WAMs enabling edge deployment and lower energy consumption, with guidelines for sustainable AI operations in robotics.
- Tools/products/workflows: Model compression, distillation, sparse inference; standardized energy reporting and targets; policy frameworks for green compute procurement.
- Assumptions/dependencies: Acceptable accuracy–efficiency trade-offs; improved training pipelines; organizational commitment to sustainability.
- Marketplace for video-only skill sharing
- Sector: platforms, software
- Description: A curated ecosystem where experts upload short videos to teach robots new skills across contexts and embodiments; automatic vetting and adaptation.
- Tools/products/workflows: Content moderation; viewpoint normalization; automated skill transfer pipelines; usage analytics; safety certification workflows.
- Assumptions/dependencies: Legal frameworks for data licensing and liability; standardized metadata and capture protocols; robust privacy guarantees.
- Urban service robotics at scale
- Sector: smart cities, public services
- Description: City-wide fleets handling cleaning, light maintenance, public-space organization, adapting quickly to seasonal and layout changes through video-driven learning.
- Tools/products/workflows: Fleet orchestration; generalization auditing; continuous learning from public datasets; incident response procedures.
- Assumptions/dependencies: Municipal approvals and public trust; strong safety and privacy controls; resilience to varied weather and lighting.
Cross-cutting assumptions and dependencies
- Hardware: Current real-time performance is demonstrated on high-end GPUs (GB200/H100) with specific optimizations (NVFP4 quantization on Blackwell). Edge deployment will require distillation and further optimization.
- Data: Heterogeneous play data works well; video-only demonstrations require compatible viewpoints and basic calibration. Safety demands rigorous validation for tasks beyond simple pick-and-place.
- Safety: Fail-safes and gating (e.g., quality metrics on video predictions) are crucial. Most failures track video generation errors, implying action quality hinges on improving video backbones.
- Integration: Requires alignment of robot states/actions, high-FPS cameras, and motion controllers capable of asynchronous chunk execution with smoothing.
- Governance: Video data collection mandates consent, retention policies, auditability, and compliance with local regulations; especially critical in homes, healthcare, and public spaces.
Collections
Sign up for free to add this paper to one or more collections.