- The paper introduces a training-free expert budgeting method, MoE-Spec, that reduces memory and computation during speculative decoding in MoE LLMs.
- It employs router-based ranking of experts using aggregate routing probabilities to select a fixed expert budget, achieving 10–30% higher throughput.
- Experimental results across multiple benchmarks show that MoE-Spec maintains quality while providing a continuous quality-latency Pareto frontier.
MoE-Spec: Resource-Constrained Speculative Decoding in Mixture-of-Experts LLMs
Introduction and Motivation
Speculative decoding methods achieve significant throughput gains for dense LLMs by verifying multiple drafted tokens in parallel. This parallelism, however, introduces a severe scalability bottleneck when applied to Mixture-of-Experts (MoE) Transformer architectures, which underpin leading models such as GPT-4, DeepSeek-R1, and Llama-4. In MoE models, sparse activation ensures that only a subset (k≪N) of the total experts, per layer, contribute to any given token's computation. However, during speculative decoding's verification phase—especially when using tree-structured drafts with high token depth—the union of all expert activations across the draft often approaches the full set of N experts. Consequently, memory bandwidth requirements negate the efficiency benefits of sparse activation and fundamentally limit speculative decoding's speedup.
Empirical analyses show that expert routing probabilities are heavy-tailed: a small fraction of experts accounts for the majority of routing decisions within the draft tree. Prior methods for speculative decoding on MoE LLMs either restrict speculation depth dynamically (mitigating, but not solving, the underlying issue) or make architectural alterations that impact model compatibility and training cost.
MoE-Spec Algorithm
MoE-Spec is a training-free, verification-time expert budgeting strategy that decouples speculative decoding depth from verification bandwidth cost. It enforces a fixed expert budget B per layer, selecting the most "important" experts by aggregating routing probabilities across the verification batch. The method requires no changes to model weights, draft models, or existing maximally efficient speculative decoding pipelines.
Given the draft tree, MoE-Spec:
- Aggregates each expert's routing probability over all tokens in the draft.
- Ranks experts and retains only the top B ("shortlist").
- For tokens whose routed experts fall outside the shortlist, either truncation (zeroing contribution) or substitution (replacing by available shortlist experts) is applied.
Notably, router-based ranking—where scores are aggregated at runtime—substantially outperforms static (precomputed) expert rankings at low budgets, and approaches an oracle upper bound (greedy minimization of MoE output reconstruction error) for practical budgets.
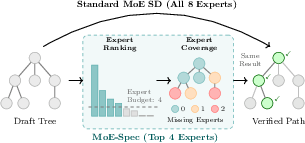
Figure 1: MoE-Spec loads only the experts with highest aggregate routing probability, contrasting with standard MoE verification that loads all experts activated across the draft tree.
Analysis of Verification Overheads and Routing Distributions
Standard speculative decoding for MoE models suffers from a rapid “expert explosion”: as tree size increases, the number of unique experts activated during verification approaches the total number of available experts per layer, nullifying compute and memory advantages.
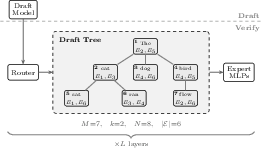
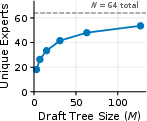
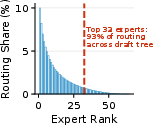
Figure 2: MoE verification workflows reveal that the target model must load the union of all experts activated across tokens in the draft tree.
Empirical routing distributions exhibit clear heavy-tailed behavior. For example, in OLMoE-1B-7B, the top 32 of 64 experts cover 93% of routing mass in a 63-token tree. This structure underpins MoE-Spec’s effectiveness: the costly tail of rarely used experts can be omitted with minimal impact on output quality.
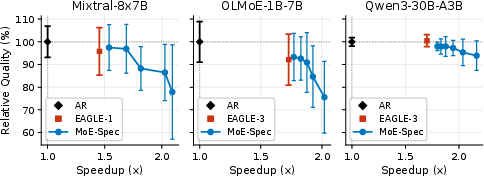
Figure 3: Quality-speedup tradeoff at T=1, normalized across five benchmarks, illustrates MoE-Spec's continuous Pareto curve compared to the singular operating point of EAGLE.
Experimental Results
MoE-Spec is evaluated on three representative MoE LLMs—OLMoE-1B-7B (N=64,k=8), Qwen3-30B-A3B (N=128,k=8), and Mixtral-8x7B (N=8,k=2)—across five benchmarks, measuring mathematical reasoning, code generation, and abstractive summarization, under both greedy (T=0) and sampling (T=1) regimes.
At similar quality levels (within one standard deviation of EAGLE-3), MoE-Spec achieves 10–30% higher throughput, with larger relative gains for higher-bandwidth models (Mixtral and Qwen3 exceeding 16–27%).
MoE-Spec alone offers a continuous Pareto frontier: by tightening the expert budget, latency can be further reduced at tradeoffs in quality, allowing deployment at customized operating points.
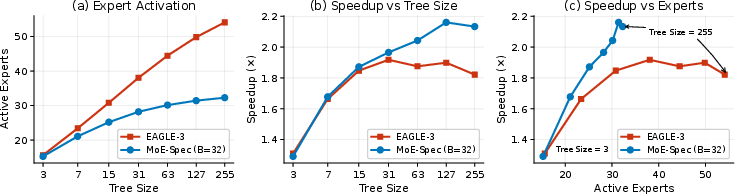
Figure 4: Expert activation and speedup on OLMoE-1B-7B: MoE-Spec saturates at its expert budget, while EAGLE-3's speedup declines as the number of unique loaded experts grows with draft tree size.
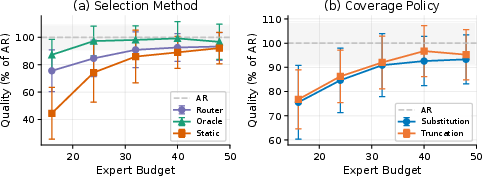
Figure 5: Design ablations demonstrate that router-based expert selection tracks the oracle upper bound, while static selection fails under tight budgets.
Robustness and Failure Modes
The degradation profile under aggressive expert budgets is primarily model-dependent: larger MoEs with more experts and higher per-token sparsity are more resilient. Analysis of routing probability coverage across benchmarks shows that code generation datasets (e.g., MBPP, HumanEval) require few experts (top 8 suffice for 90+% routing mass), while summarization (CNN/DM) requires broader coverage.
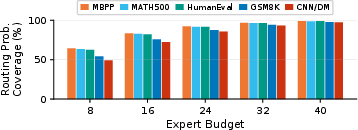
Figure 6: Routing probability coverage by expert budget and dataset in OLMoE-1B-7B; code datasets exhibit much greater concentration.
Oracle Analysis and Selection Methods
Oracle-based expert selection achieves similar reconstruction error to router-based selection while utilizing 25% fewer experts. The gap arises from correlated expert activations: pairs of experts are co-activated for the same tokens far more frequently than expected by chance (10–33× concentration amplification). This suggests that future selection methods can further exploit expert co-activation structure, closing the remaining efficiency gap towards the oracle.

Figure 7: Reconstruction error with oracle selection matches router-based error using 25% fewer experts.
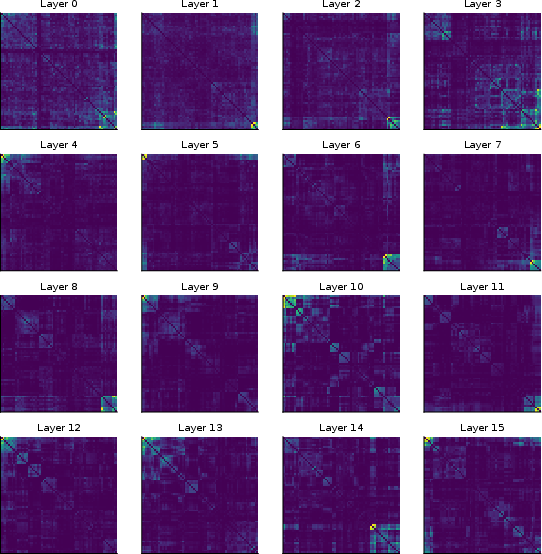
Figure 8: Co-activation heatmaps reveal expert clusters with frequent correlated routing, indicating redundancy exploitable for further budget compression.
Batch and System-Level Considerations
MoE-Spec’s effectiveness is greatest for single-request inference and scenarios where verification-phase expert loading dominates throughput. In high-batch serving workloads, the marginal cost of additional experts is amortized, potentially reducing MoE-Spec’s advantage. Batched implementations (vectorized expert execution) are adopted to maximize measured throughput.
Implications and Future Directions
MoE-Spec provides a practically deployable, training-free, and architecture-agnostic approach for controlling compute and memory tradeoffs in speculative decoding for MoE LLMs. Its expert budgeting mechanism enables deployment agility, as quality-vs-latency can be tuned by a single hyperparameter and adapted dynamically.
The theoretical insight into heavy-tailed routing and co-activation suggests promising directions:
- Co-activation-aware expert selection could close the 25% oracle gap.
- Per-layer adaptive budgeting can further customize compute allocation to model and workload heterogeneity.
- Compatibility with new routing mechanisms (e.g., sigmoid routing in DeepSeek-V3) and batch-optimized deployments is an open systems challenge.
Given the prevalence of MoE models and the increasing importance of efficient speculative decoding for interactive LLM applications, these advances have substantial impact on practical LLM systems.
Conclusion
MoE-Spec demonstrates that heavy-tailed expert routing enables significant reductions in memory and compute cost for MoE-LLMs during speculative decoding, via a training-free, verification-time expert budgeting approach that leverages router outputs. The method yields 10–30% throughput improvements over state-of-the-art baselines, defines a quality-latency Pareto frontier, and motivates future research into co-activation-aware selection for further compression.
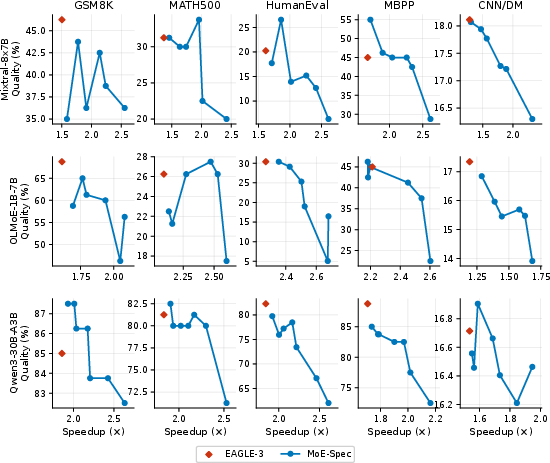
Figure 9: Quality vs. speedup at T=0 across three models and five benchmarks; MoE-Spec traces new Pareto frontiers.
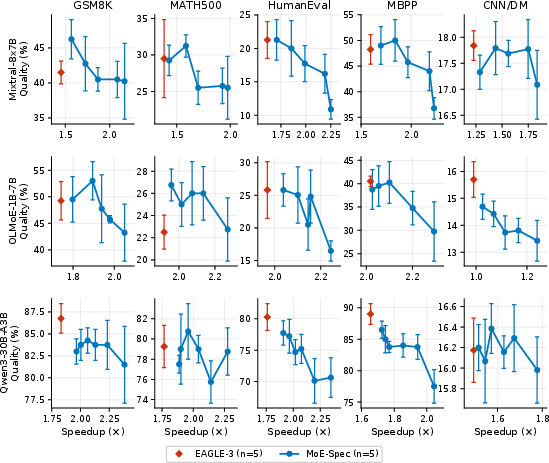
Figure 10: Quality vs. speedup at T=1, detailing robust tradeoffs across benchmarks under sampling-based decoding.