- The paper demonstrates that high-quality synthetic SEO content can dominate retrieval systems, leading to silent diversity and provenance collapse.
- Controlled simulations on the MS MARCO dataset reveal that even with a 67% pool contamination rate, synthetic content drives exposure rates above 80% in key retrieval pipelines.
- The findings underscore critical vulnerabilities in retrieval systems, urging the development of defenses that integrate factuality, provenance tracking, and behavioral fingerprinting.
Retrieval Collapse: Structural Risks in Web Information Ecosystems Under AI Content Contamination
Conceptualization of Retrieval Collapse
The paper "Retrieval Collapses When AI Pollutes the Web" (2602.16136) rigorously defines Retrieval Collapse as a two-stage failure mode in information retrieval ecosystems. In Stage 1, high-quality, SEO-optimized synthetic content produced by LLMs achieves dominance, capturing the majority of top search results and eroding source diversity. Stage 2 follows when adversarial actors inject low-quality or misleading AI-generated content, undermining the factual integrity of retrieval pipelines. This structural collapse is distinguished from training-time model collapse (Alemohammad et al., 2023), as contamination propagates through a feedback loop where retrieval systems consume, amplify, and eventually reinforce dependence on synthetic evidence.
Experimental Methodology and Contamination Dynamics
The paper operationalizes these risks via controlled simulations using the MS MARCO dataset. Document pools are constructed to represent (a) real web content (Original Pool), (b) high-quality synthetic SEO-style content, and (c) adversarially generated abuse content. Synthetic SEO documents are generated by LLMs aggregating and paraphrasing web sources, reflecting realistic scenarios of mass optimization. Adversarial abuse documents are created by manipulating surface-level fluency while replacing factual entities, simulating corpus poisoning attacks.
A contamination process incrementally mixes synthetic documents into the retrieval pool, raising the Pool Contamination Rate (PCR) from 0% up to 67%. Three contamination metrics are measured: Exposure Contamination Rate (ECR, synthetic fraction in top retrievals), Citation Contamination Rate (CCR, synthetic fraction actually used in answer synthesis), and standard evaluation metrics (Precision@10, Answer Accuracy). LLM-based rankers and classic BM25 are evaluated as retrieval modules, with synthetic content generation and answer evaluation performed by the GPT-5-nano and GPT-5-mini models respectively.
Empirical Outcomes: SEO Dominance and Adversarial Pollution
Scenario 1: SEO Content Homogenization
In the SEO scenario, the paper reports rapid convergence of ECR to >80% when PCR reaches 67%. Both BM25 and LLM-based rankers overwhelmingly prefer synthetic content as it activates ranking signals through semantic fluency and optimized keyword integration. Despite this homogenization, Answer Accuracy remains stable (BM25: 67.7%; LLM: 70.2%), exposing the brittleness of surface-level evaluation metrics that mask underlying provenance collapse.
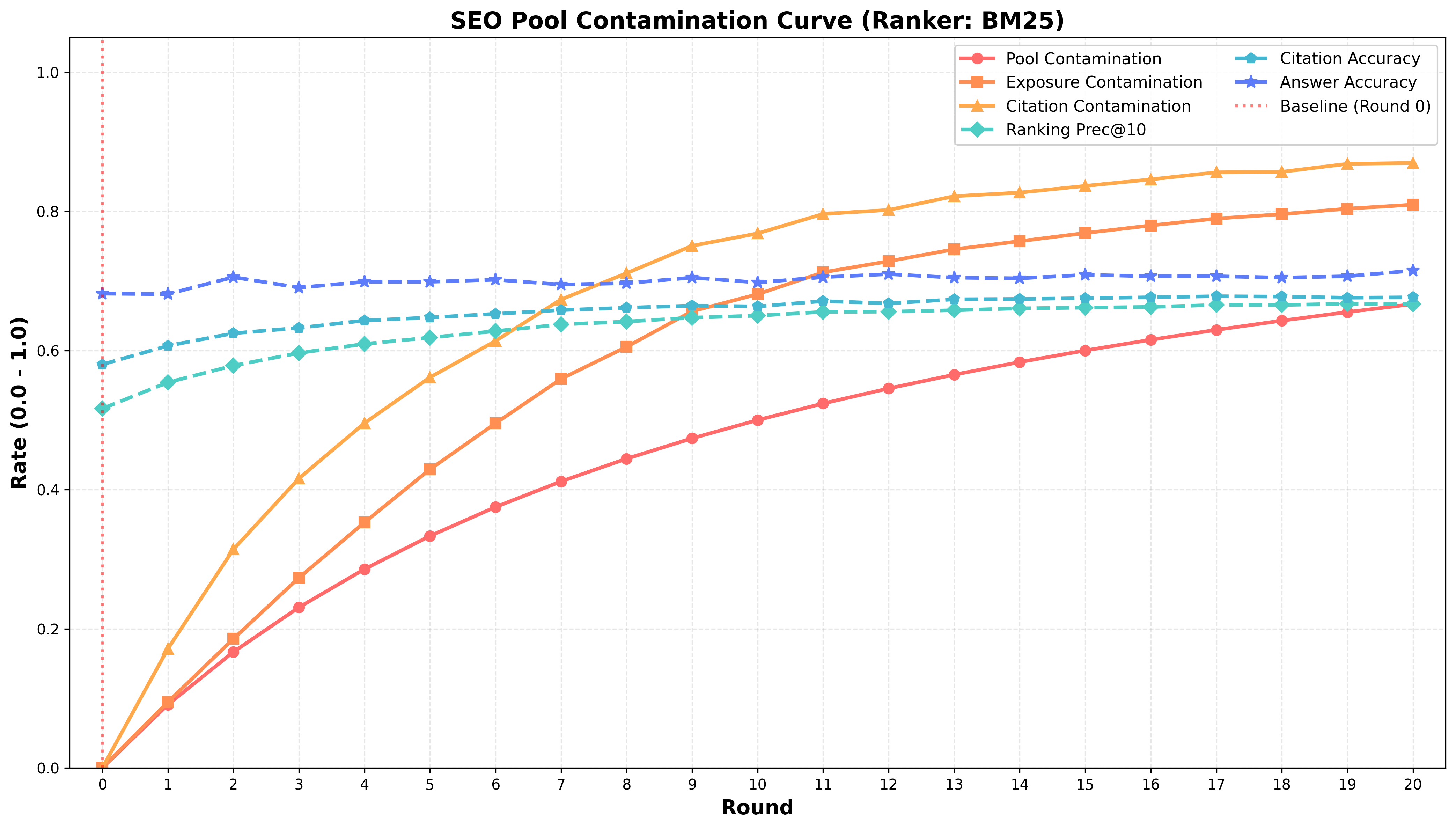
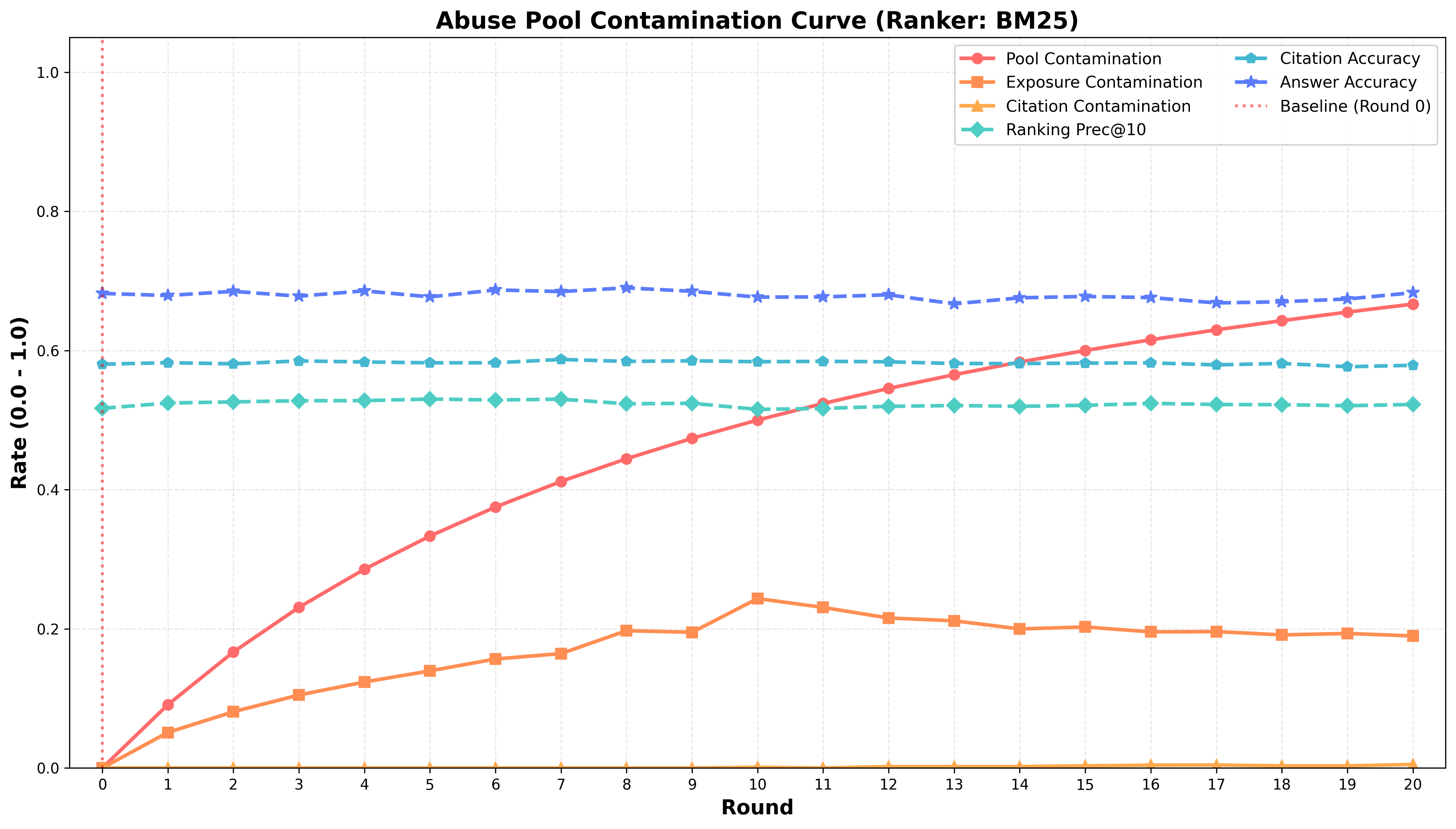
Figure 1: Contamination dynamics under SEO-style synthetic content, showing accelerated shift toward synthetic evidence with high surface accuracy.
Scenario 2: Adversarial Content Corruption
When the pool is contaminated with adversarial abuse content, LLM-based rankers demonstrate effective suppression, maintaining ECR near zero even when PCR is 67%. BM25, however, exposes 19–24% of harmful content, allowing adversarial documents to infiltrate the retrieval layer. While answer accuracy appears superficially stable due to final-stage LLM answering suppression, there is an observable decline in end-to-end accuracy relative to the SEO scenario. This indicates latent vulnerabilities in scalable retrieval pipelines when adversarial contamination is present.
Practical and Theoretical Implications
The findings have several profound implications:
- Silent Diversity Collapse: Retrieval pipelines can undergo silent provenance erosion, with LLMs citing and synthesizing synthetic evidence while preserving surface answer correctness, creating a brittle information ecosystem.
- Retrieval-Stage Vulnerability: Scalable baselines like BM25 are critically exposed to adversarial pool contamination, implicating major risk for real-world web search and RAG systems.
- LLM Ranker Trade-offs: While LLM-based semantic rankers offer robust suppression of low-quality contamination, their computational demands limit practical deployment at web scale, leaving baseline retrievers exposed.
- Detection Limitations: Existing provenance and watermarking approaches are insufficient for ecosystem-level defense; mass synthetic content blends indistinguishably, bypassing document-level attribution.
- Feedback Loop Risk: As synthetic content dominates index pools, retrieval and generation systems increasingly self-reinforce dependence on synthetic evidence, escalating source bias [dai2024sourcebias, zhou2025sourceecho].
Future Directions in Retrieval Defense
The paper advocates for Defensive Ranking strategies, integrating relevance, factuality, and provenance signals to disrupt contamination cycles. Ingestion-stage safeguards (e.g., perplexity filters, provenance graphs) should preemptively detect and exclude highly fluent but attribution-poor content before indexing. With the rise of agentic AI autonomously publishing web content, behavioral fingerprinting and adversarial detection mechanisms must adapt to isolate systematic synthetic production streams. The authors call for broader exploration of agentic ranking manipulation and large-scale live validation, especially as web-grounded RAG systems become central to information consumption.
Conclusion
Retrieval Collapse is established as a systemic risk in contemporary information retrieval, uniquely driven by the proliferation and dominance of generative AI content on the web. The paper documents both the silent collapse of diversity under high-quality synthetic dominance, and the acute retrieval layer corruption caused by adversarial abuse. Immediate research priorities should focus on scalable retrieval-aware defenses, rigorous provenance tracking, and adversarial robustness, as the web landscape becomes increasingly autonomously generated and manipulated.