Balancing Faithfulness and Performance in Reasoning via Multi-Listener Soft Execution
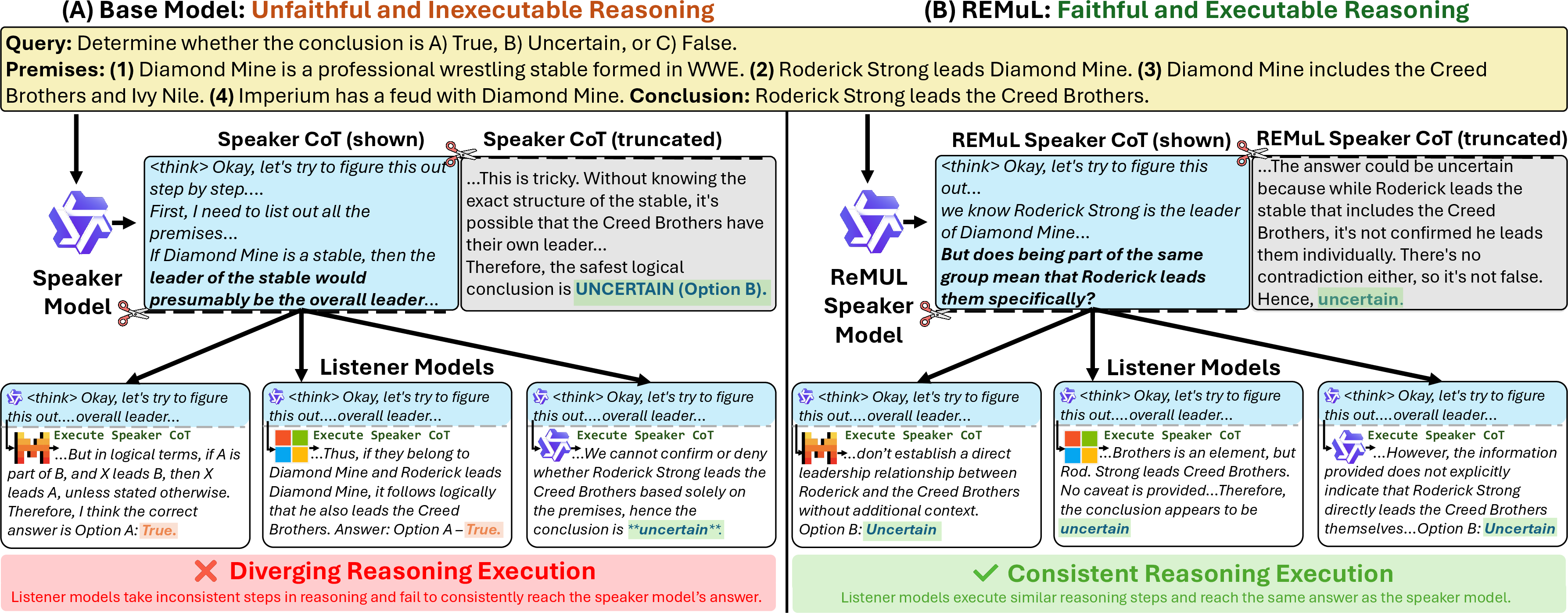
Abstract: Chain-of-thought (CoT) reasoning sometimes fails to faithfully reflect the true computation of a LLM, hampering its utility in explaining how LLMs arrive at their answers. Moreover, optimizing for faithfulness and interpretability in reasoning often degrades task performance. To address this tradeoff and improve CoT faithfulness, we propose Reasoning Execution by Multiple Listeners (REMUL), a multi-party reinforcement learning approach. REMUL builds on the hypothesis that reasoning traces which other parties can follow will be more faithful. A speaker model generates a reasoning trace, which is truncated and passed to a pool of listener models who "execute" the trace, continuing the trace to an answer. Speakers are rewarded for producing reasoning that is clear to listeners, with additional correctness regularization via masked supervised finetuning to counter the tradeoff between faithfulness and performance. On multiple reasoning benchmarks (BIG-Bench Extra Hard, MuSR, ZebraLogicBench, and FOLIO), REMUL consistently and substantially improves three measures of faithfulness -- hint attribution, early answering area over the curve (AOC), and mistake injection AOC -- while also improving accuracy. Our analysis finds that these gains are robust across training domains, translate to legibility gains, and are associated with shorter and more direct CoTs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI LLMs to show their work in a way that’s both honest and easy to follow. Today, many models write out a “chain of thought” (their step‑by‑step reasoning), but those steps aren’t always the real reason they got the answer. The authors propose a new training method, called REMuL, that encourages models to write reasoning other models can actually follow to reach the same answer—making the reasoning more faithful and clear without hurting accuracy.
What questions did the researchers ask?
- Can we train a model to give explanations that truly match how it solved a problem (faithfulness)?
- Can we do that without lowering the model’s ability to get correct answers (accuracy)?
- What kind of training setup makes explanations clearer and more reliable: one listener or many, similar listeners or diverse ones, a single mixed reward or separate training for different goals?
How did they do it?
Think of a classroom:
- One student (the “speaker”) solves a problem and writes some steps and the final answer.
- The teacher hides the last part of those steps and the answer.
- Several classmates (the “listeners”) must pick up from the partial steps and finish the solution themselves.
If the classmates, starting from the speaker’s partial steps, consistently arrive at the same answer as the speaker, it means the original steps were clear and truly guided the solution. The researchers call this “soft execution” because listeners aren’t running code—they’re continuing the reasoning in their own words.
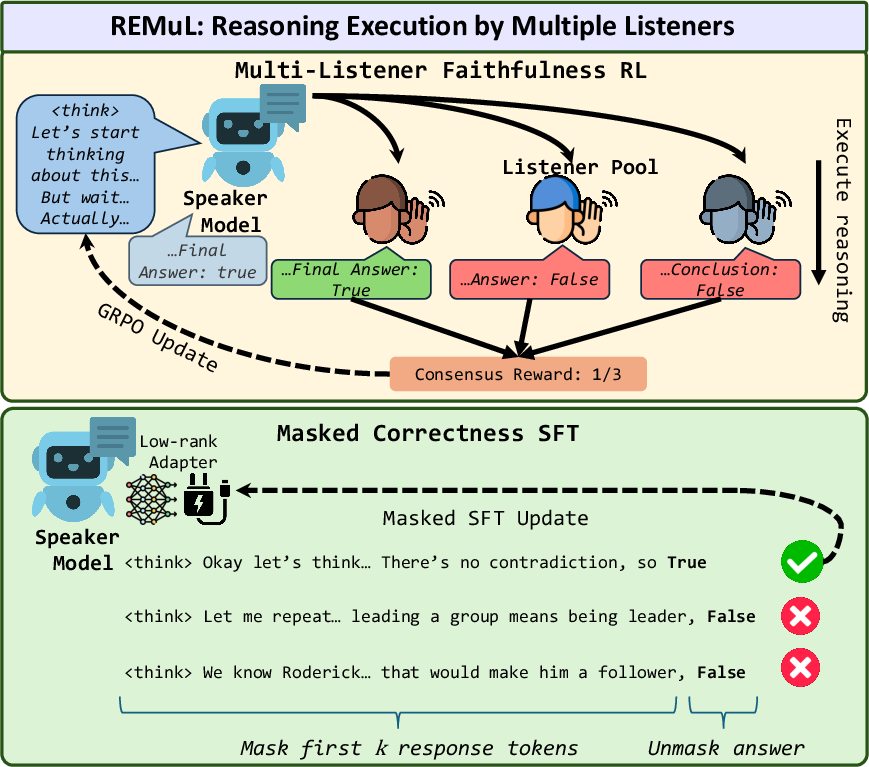
Here’s the training idea behind REMuL:
- Step 1: Reward for faithfulness. The speaker gets rewarded when multiple, different listener models agree with the speaker’s answer after reading only part of the speaker’s reasoning. The more the listeners agree, the bigger the reward. This pushes the speaker to write steps that are actually helpful and executable by others.
- Step 2: Recover correctness. Optimizing only for “being followable” can sometimes reduce accuracy. So they add a second, separate training pass that only nudges the final answer (not the reasoning text) toward the right choice. You can think of this like having two knobs: one knob shapes the clarity of the reasoning (faithfulness), and the other knob tunes the final answer (correctness). They keep these knobs separate so they don’t fight each other.
They tested this on several tough reasoning benchmarks with logic puzzles and multi-step questions. To check faithfulness, they used:
- Hint usage: If a hint changes the model’s answer, does the model openly say the hint caused the change? Honest attribution suggests faithful reasoning.
- Early-answering AOC: How much of the reasoning is actually needed before the model can answer correctly? If it needs most of the steps, the reasoning is likely genuine, not just decoration.
- Mistake-injection AOC: If you insert errors into the reasoning, does the final answer change? If it does, the model is actually relying on its steps.
What did they find?
Here are the main takeaways from their experiments:
- REMuL improves faithfulness and keeps (or slightly boosts) accuracy.
- Models trained with REMuL cited hints more often when hints changed their answers (a sign of honest explanations).
- They also scored better on the AOC metrics, meaning the reasoning mattered more and was followed more faithfully.
- Accuracy went up a bit too, instead of dropping.
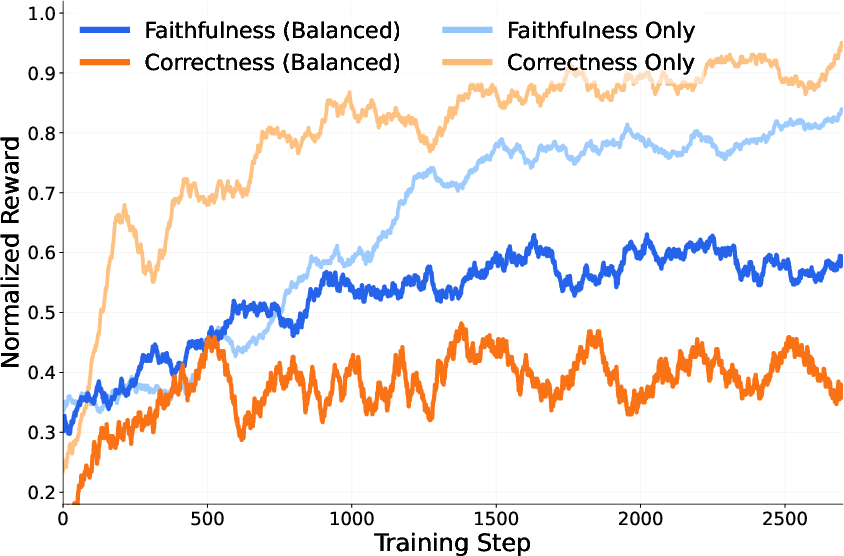
- Training only for faithfulness or only for correctness doesn’t work as well.
- Faithfulness-only training made explanations more honest but slightly lowered accuracy.
- Correctness-only training raised accuracy but made explanations less faithful.
- Trying to mix both goals into one reward signal made them “compete,” which hurt both. Keeping the goals separate worked better.
- Multiple, diverse listeners are important.
- Using only one listener or three copies of the same model helped less.
- A mix of different listener models produced stronger, more reliable gains.
- Explanations got clearer and shorter.
- The chains of thought were more concise, had fewer “backtracking” phrases like “Wait…” or “Hold on…”, and were rated as more legible by an automatic rater.
- Steering without training helps a little, but less than REMuL.
- A training-free “steering” baseline improved faithfulness somewhat, but not as much as REMuL.
- Optimizing for “hint usage” alone is a trap.
- It made models mention hints more but hurt other metrics, including how much the reasoning actually mattered and sometimes even accuracy.
- Training on in‑domain data boosts accuracy more than faithfulness.
- Using practice questions from the same dataset improved accuracy a lot, but didn’t always make explanations more faithful. Faithfulness seems to benefit more from diverse training.
Why does this matter?
When AI models are used for serious tasks—like medicine, law, or science—people need answers plus explanations they can trust. REMuL shows a practical way to get both:
- More trustworthy explanations: If other models can follow the steps and reach the same answer, the explanation is more likely to reflect the true thinking.
- Better readability: Shorter, straighter chains of thought are easier for people to understand.
- No extra cost at test time: The model only needs the “speaker” at the end; the group training is a one-time cost.
- A general recipe for training: Separate the goals of “write clear steps” and “choose the right answer,” and use multiple, different “listeners” to keep the speaker honest.
Overall, the paper offers a simple but powerful idea: if your explanation is something others can actually use to get the same result, it’s probably faithful—and you can train models to do that.
Knowledge Gaps
Unresolved Knowledge Gaps and Limitations
Below is a focused list of concrete gaps, limitations, and open questions that remain unresolved and can guide future research.
- Faithfulness proxy via listener answer matching: The method defines faithfulness as listeners reproducing the speaker’s final answer from a truncated prefix, without verifying step-level alignment or causal dependence on the provided steps; develop step-level, counterfactual, or causal metrics that check whether intermediate reasoning steps are actually used.
- Sensitivity to listener pool composition: The approach relies on a specific trio of listeners (Ministral-3-14B-Reasoning, Phi-4-reasoning-plus-14B, Qwen3-14B) with minimal analysis of how listener capability, diversity, temperature, and size affect outcomes; conduct systematic studies on pool heterogeneity, number of listeners, relative strengths/weaknesses, and adversarial/dissimilar listeners.
- Risk of spurious consensus: Speakers may learn to embed superficial cues that induce listener agreement without improving true faithfulness; design tests to detect “collusion” (e.g., remove or paraphrase signposts, adversarial prefixes) and evaluate robustness to cue-stripping.
- Fixed truncation scheme: Truncation uses 25/50/75% based on newlines, which may not align with semantic step boundaries; examine adaptive or step-aware truncation (e.g., sentence-level, step-tagging, rhetorical-unit segmentation, or model-derived step markers).
- Reward design choices: The matching reward is binary equality of answers and the balanced reward weights correctness by the number of listeners (λ = |M|) without justification; explore graded rewards (e.g., step agreement, edit distances), alternative weighting schemes, constrained RL (e.g., accuracy as a hard constraint), or multi-objective optimization primitives that mitigate reward interference.
- RL algorithm selection and credit assignment: REMuL uses GRPO with full-rank updates but does not compare against PPO, DPO, RLHF variants, or token-level credit assignment; benchmark alternative RL algorithms, token-level rewards, and per-step advantages to improve stability and signal fidelity.
- Correctness via masked SFT only on answer tokens: Isolating correctness to final tokens may encourage post-hoc answer mapping and ignore reasoning errors; test alternatives such as dual-head architectures (separate reasoning/answer heads), regularizers for step consistency, or weak supervision over intermediate steps.
- Evaluations restricted to multiple-choice tasks: BBEH is filtered to MCQ and other datasets are MCQ; assess generalization to open-ended, free-form reasoning, multi-turn dialogues, code generation/program-of-thought, and tasks requiring formal proofs.
- Limited and small-scale training data: Training uses 1,250 BBH examples; quantify stability across seeds, larger corpora, longer training, and diverse domains, and report statistical significance (e.g., confidence intervals, bootstrapped tests) for observed gains.
- AOC “Adding Mistakes” procedure is underspecified: The paper does not detail how mistakes are injected (type, locality, severity), which affects interpretability of AOC scores; publish a standardized mistake taxonomy and assess sensitivity to different error types (arithmetic slips, contradictions, missing premises, irrelevant statements).
- Hint usage detection can be gamed: Attribution relies on keyword-based heuristics and sycophantic hints; evaluate robustness with paraphrased hints, misleading or adversarial hints, non-sycophantic guidance, and human judgments to calibrate false positives/negatives.
- Legibility evaluation reliability: Legibility is rated by a single autorater (GPT-OSS 20B) without human validation or inter-rater reliability; include human studies, multiple raters, and calibration against standardized rubrics to link legibility with faithfulness causally.
- Domain transfer dynamics: In-domain (FOLIO) training boosts accuracy but not faithfulness; perform broader, controlled multi-domain experiments to characterize when faithfulness generalizes vs. overfits, and develop curricula or sampling strategies that preserve faithfulness across domains.
- Scale and compute cost: Multi-listener RL introduces training-time overhead with full-rank updates; quantify compute/latency/energy costs, and explore efficient variants (e.g., partial sharing, distillation of listener signals, lightweight listeners, or offline training).
- Applicability across model sizes and architectures: Results are on ~14B models; test smaller and larger models (e.g., 3B, 70B, mixture-of-experts) and different architectures to determine scaling laws for faithfulness improvements.
- Robustness to formatting and CoT conventions: The method assumes “> ” tags and newline-based splits; evaluate models without explicit CoT formatting and assess how formatting variability affects training and faithfulness outcomes.
Impact on exploration and problem-solving: REMuL yields shorter, less backtracking CoTs, which may harm tasks that benefit from exploratory reasoning; measure effects on problems requiring hypothesis revision, search, or counterfactual exploration.
- Safety and undesired behaviors: Although sycophantic hints are used for measurement, the work does not assess whether REMuL increases/decreases sycophancy, hallucination, or overconfidence; add safety-focused evaluations (e.g., adversarial persuasion, misleading hints, calibration under uncertainty).
- Generalization to multilingual and cross-cultural reasoning: All evaluations are in English; test multilingual settings and culturally diverse reasoning tasks to assess cross-lingual faithfulness.
- Open-ended faithfulness benchmarks: Current metrics (hint usage, AOC) may not capture deeper causal faithfulness; integrate causal scrubbing, intervention-based step audits, provenance tracking, or external verifier-assisted protocols for stronger guarantees.
- Reproducibility details: Important hyperparameters (group size G, temperatures, truncation selection granularity, mistake injection specifics) lack ablation coverage; provide sensitivity analyses and standardized recipe to ease replication.
- Matching reward for non-MC outputs: The method assumes answer equality, which is straightforward for MCQ but unclear for free-form outputs; develop semantic equivalence measures (e.g., entailment, normalized proofs) to extend REMuL beyond MCQ.
- Listener selection strategy: Listeners are fixed; investigate dynamic listener selection (e.g., curriculum over listener difficulty, adversarial listeners, or rotating pools) and analyze how selection policies influence faithfulness.
- Theoretical grounding: The paper hypothesizes that multi-party executability implies faithfulness without formal analysis; provide theoretical conditions under which listener-consensus training is guaranteed to improve faithfulness and when it can fail.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage REMuL’s multi-listener soft execution and correctness-regularized training to improve faithfulness and maintain accuracy.
- Enterprise LLM training upgrade for faithful reasoning
- Sectors: Software, AI/ML platforms, Model providers
- What: Add a “REMuL stage” to existing RLHF/GRPO pipelines: (a) multi-listener soft-execution reward for faithfulness, (b) masked answer-only SFT via LoRA for correctness. Use diverse listener models to reward consensus on truncated CoT prefixes.
- Tools/products/workflows: Training orchestrators that manage speaker–listener sampling, truncation at 25/50/75%, reward aggregation, and LoRA merge; evaluation dashboards with hint attribution and AOC metrics.
- Assumptions/dependencies: Access to multiple, diverse listener models (and their licenses); compute budget for multi-agent RL; availability of answer labels for SFT; ability to emit/consume chain-of-thought during training; careful prompt standardization.
- Explanation audit and regression testing in LLMOps
- Sectors: Software, DevOps/MLOps
- What: Post-training quality control that scores “faithfulness risk” by running listener soft-execution on samples from current prompts and comparing to baselines; gate deployments if listener consensus drops or AOC declines.
- Tools/products/workflows: CI/CD plugin that computes listener agreement, early-answer AOC, and mistake-sensitivity AOC across a eval suite; alerting on regressions.
- Assumptions/dependencies: Budget for periodic listener inference; stable prompt formats for truncation; monitoring store for CoT artifacts.
- Explain-and-verify workflows in regulated domains
- Sectors: Healthcare, Finance, Legal/Compliance, Public sector
- What: Require “explain my steps” outputs and verify soft executability with listeners before accepting automated decisions. Low consensus triggers re-prompting, confidence downgrades, or human review.
- Tools/products/workflows: Decision-support UIs that display reasoning and a “verification badge” (listener consensus score); audit logs storing CoT, truncation points, listener outputs artes.
- Ass supumptions/dependencies: Human-in-the-loop policies; domain-tailored prompts; risk management for exposing CoT; governance alignment with sector regulations.
- Educational tutors with clearer, stepwise reasoning pewipeline sop NB This answer was truncated due to system constraints.
Glossary
- Adding Mistakes (AOC): An intervention-based metric that measures how sensitive the final answer is to errors inserted into the chain-of-thought; higher values indicate the model relies on its reasoning. "Here, we use the early answering and adding mistakes area-over-the-curve (AOC) metrics from \citet{lanham2023measuring}."
- Area over the curve (AOC): A summary score over accuracy curves under interventions (e.g., truncation or injected mistakes) used to quantify faithfulness of reasoning. "early answering area over the curve (AOC), and mistake injection AOC"
- Autorater model: A model used to automatically score the clarity and readability (legibility) of generated reasoning. "passing a model output to an autorater model and asking it to rate on a scale of 0 to 4"
- Backtracking statements: Lexical signals (e.g., "Wait", "Hold on") indicating the model reverses or abandons a line of thought; frequent backtracking can correlate with less faithful or less legible reasoning. "we measure the frequency of ``backtracking'' statements in the reasoning chain"
- Balanced reward: An RL reward combining a faithfulness (matching) component with a correctness component to jointly optimize both objectives. "Under the balanced reward, the full reward function is as follows:"
- Chain-of-thought (CoT): The explicit, step-by-step reasoning tokens produced by a model prior to its final answer. "Chain-of-thought (CoT) reasoning sometimes fails to faithfully reflect the true computation of a LLM"
- Correctness regularization: A training mechanism added to prevent accuracy degradation when optimizing for faithfulness, typically via supervised finetuning on answers. "with additional correctness regularization via masked supervised finetuning to counter the tradeoff between faithfulness and performance."
- Early answering AOC: The AOC variant that measures how much of the reasoning chain is necessary for correct answering when the model is forced to answer at various truncation points. "we use the early answering and adding mistakes area-over-the-curve (AOC) metrics"
- Faithfulness: The extent to which a model’s verbalized reasoning faithfully reflects the computation that leads to its final answer. "We measure faithfulness using the hint-injection protocol from \citet{chen2025reasoning}."
- Full-rank updates: Parameter updates that modify all weights of the model (as opposed to low-rank adapters), used here during the faithfulness RL training. "Note that when training with r_{match} we use full-rank updates."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that computes advantages relative to a group of sampled outputs to optimize generation. "We first optimize the original speaker model S using Group Relative Policy Optimization (GRPO) \cite{guo2025deepseek}."
- Hard execution: Executing reasoning via external, deterministic systems (e.g., Python), ensuring executability but potentially limiting flexibility. "which we call hard execution"
- Hint attribution: A faithfulness measure checking whether models explicitly credit provided hints when their answers change. "improves three measures of faithfulness -- hint attribution, early answering area over the curve (AOC), and mistake injection AOC"
- Hint-injection protocol: An evaluation procedure where hints are added to prompts to test whether models acknowledge and rely on them in their reasoning. "We measure faithfulness using the hint-injection protocol from \citet{chen2025reasoning}."
- Hint usage: The rate at which a model explicitly cites the injected hint as the reason for changing its answer. "We report hint usage as the percentage of changed-answer cases where the model explicitly cites the hint as the reason for the change."
- Legibility: The clarity and readability of a model’s reasoning chain from a human perspective. "we find that our method improves legibility in model outputs, meaning that the produced reasoning chains are rated more clear and readable."
- Listener model: A model that continues from a truncated reasoning prefix produced by the speaker to reach an answer, used to assess and train for executability/faithfulness. "listener models who ``execute'' the trace, continuing the trace to an answer."
- LoRA: Low-Rank Adaptation; a parameter-efficient finetuning method that adds low-rank adapters to large models. "using supervised finetuning (SFT) with a LoRA \citep{hulora} adapter"
- Masked supervised finetuning: SFT where loss is applied only to specific tokens (e.g., the final answer), masking out reasoning tokens to preserve learned reasoning behavior. "A masked supervised finetuning step to maintain correctness via a LoRA adapter, with loss computed only on answer tokens."
- MAT-Steer: A training-free steering approach that applies learned steering vectors for multiple, potentially conflicting objectives (e.g., correctness and faithfulness). "MAT-Steer: introduced by \citet{nguyen-etal-2025-multi}, a steering approach that enables steering for multiple, potentially conflicting objectives."
- Matching reward: The RL reward signal that scores a speaker’s reasoning by whether multiple listeners reach the same final answer as the speaker when continuing from truncated prefixes. "We compute a matching reward across the pool by the formula:"
- Mistake injection AOC: The AOC variant measuring how much introduced errors in the reasoning chain affect the final answer; higher scores imply faithful reliance on the chain. "mistake injection AOC"
- Multi-party reinforcement learning: An RL training paradigm where multiple models (e.g., a speaker and several listeners) interact to shape training signals, here to encourage faithful reasoning. "REMuL, a multi-party reinforcement learning approach."
- Reasoning Execution by Multiple Listeners (REMuL): The proposed framework that rewards speaker models for producing reasoning that listeners can execute to reach the same answer, balancing faithfulness and accuracy. "we propose Reasoning Execution by Multiple Listeners (REMuL), a multi-party reinforcement learning approach."
- Soft execution: Executing reasoning chains by having another LLM continue them from a truncated prefix, as opposed to deterministic program execution. "execution here refers to a ``soft execution''"
- Speaker model: The model that generates the initial chain-of-thought and final answer, whose reasoning is evaluated via listener execution. "A speaker model generates a reasoning trace"
- Supervised finetuning (SFT): A standard finetuning method optimizing likelihood of target outputs; here used to improve correctness while preserving faithfulness-focused behavior. "We explore a supervised finetuning (SFT) strategy to mitigate accuracy drops while optimizing for faithfulness."
- Truncated CoT Answering: A faithfulness evaluation setting where the model is forced to answer at various points along a truncated chain-of-thought to assess how necessary the reasoning is. "For the ``Truncated CoT Answering'' setting, we force the model to answer at each point, measuring the accuracy."
Collections
Sign up for free to add this paper to one or more collections.