Multi-agent cooperation through in-context co-player inference
Abstract: Achieving cooperation among self-interested agents remains a fundamental challenge in multi-agent reinforcement learning. Recent work showed that mutual cooperation can be induced between "learning-aware" agents that account for and shape the learning dynamics of their co-players. However, existing approaches typically rely on hardcoded, often inconsistent, assumptions about co-player learning rules or enforce a strict separation between "naive learners" updating on fast timescales and "meta-learners" observing these updates. Here, we demonstrate that the in-context learning capabilities of sequence models allow for co-player learning awareness without requiring hardcoded assumptions or explicit timescale separation. We show that training sequence model agents against a diverse distribution of co-players naturally induces in-context best-response strategies, effectively functioning as learning algorithms on the fast intra-episode timescale. We find that the cooperative mechanism identified in prior work-where vulnerability to extortion drives mutual shaping-emerges naturally in this setting: in-context adaptation renders agents vulnerable to extortion, and the resulting mutual pressure to shape the opponent's in-context learning dynamics resolves into the learning of cooperative behavior. Our results suggest that standard decentralized reinforcement learning on sequence models combined with co-player diversity provides a scalable path to learning cooperative behaviors.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI “players” to cooperate with each other in games where they could choose to be selfish. The authors show a simple way to get cooperation: train the AIs to play against many different kinds of opponents and let them figure out how others behave during the game. This “learn-in-the-moment” ability (called in-context learning) ends up encouraging fair, cooperative behavior—without needing complicated tricks or special rules.
Key Questions and Goals
Here’s what the researchers wanted to find out:
- Can AI agents learn to cooperate just by playing against a wide variety of opponents, without hardcoded assumptions about how others learn?
- Will “in-context learning” (learning from the unfolding game history inside a single match) naturally appear, and does it help?
- Does a known pathway to cooperation—where agents that can pressure each other (extort) end up settling on cooperation—show up on its own in this setup?
How They Did It (Methods Explained Simply)
Think of a repeated game like the Iterated Prisoner’s Dilemma (IPD). In each round, two players choose:
- Cooperate (help each other) → both get a decent reward
- Defect (be selfish) → if one defects while the other cooperates, the defector gets more and the cooperator gets less; if both defect, both do poorly
Because the game repeats many times, players can react to what the other did before—like remembering if someone was nice or mean.
What the authors trained:
- Learning agents: These are AI models with memory (sequence models) that read the whole game history and choose what to do next. They don’t change their code mid-game; instead, they “figure you out” on the fly by paying attention to what you’ve done so far (that’s in-context learning, like adjusting your strategy while you talk to someone).
- Tabular agents: Simple, fixed strategies that decide based on just what happened in the last round. They don’t learn.
Training setup (the “mixed pool”):
- Each learning agent plays half of its games against other learning agents and half against random tabular agents.
- No labels are given about who they’re playing; they must infer the opponent’s type by watching behavior.
Two training approaches:
- A2C (Advantage Actor-Critic): A standard reinforcement learning method—learn by trial and error to get more points.
- PPI (Predictive Policy Improvement): The agent first learns a “world model” that predicts what happens next (like a mental simulator). It then uses that model to plan better moves and retrains itself on those better moves. You can think of it as: 1) Practice predicting the game, 2) Use the predictions to choose smarter actions, 3) Fold those smarter actions back into the model.
Why this matters method-wise:
- No special “fast learner vs. slow meta-learner” setup is needed.
- No hard assumptions about how the opponent learns.
- Just train on diverse opponents and let in-context learning do the rest.
Main Findings and Why They Matter
Here are the main results, presented in simple terms:
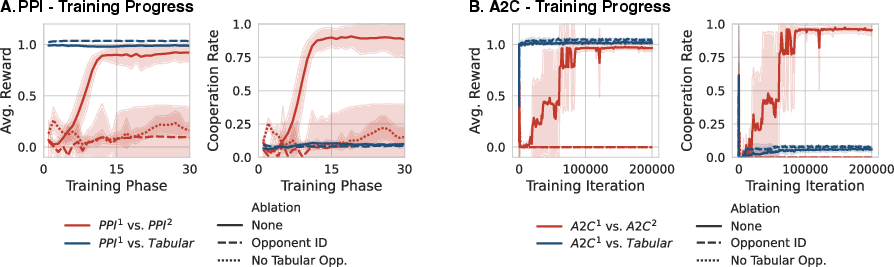
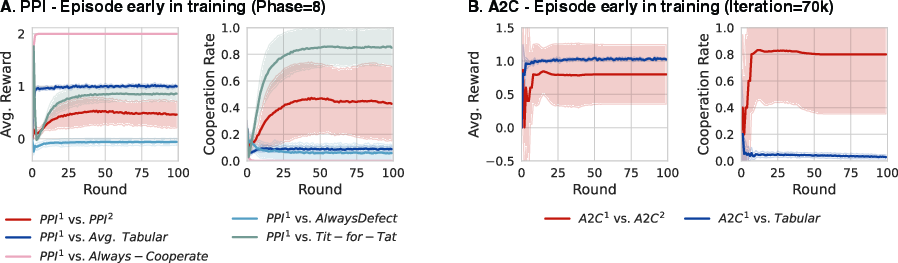
- Mixed training leads to cooperation: When learning agents practice against a mix of many opponent types, they end up cooperating in the repeated game. This happened with both A2C and PPI.
- In-context learning is the key: Agents learn to quickly “read” their opponent during the same game and adjust to a best response. This fast adaptation is what opens the door to cooperation later.
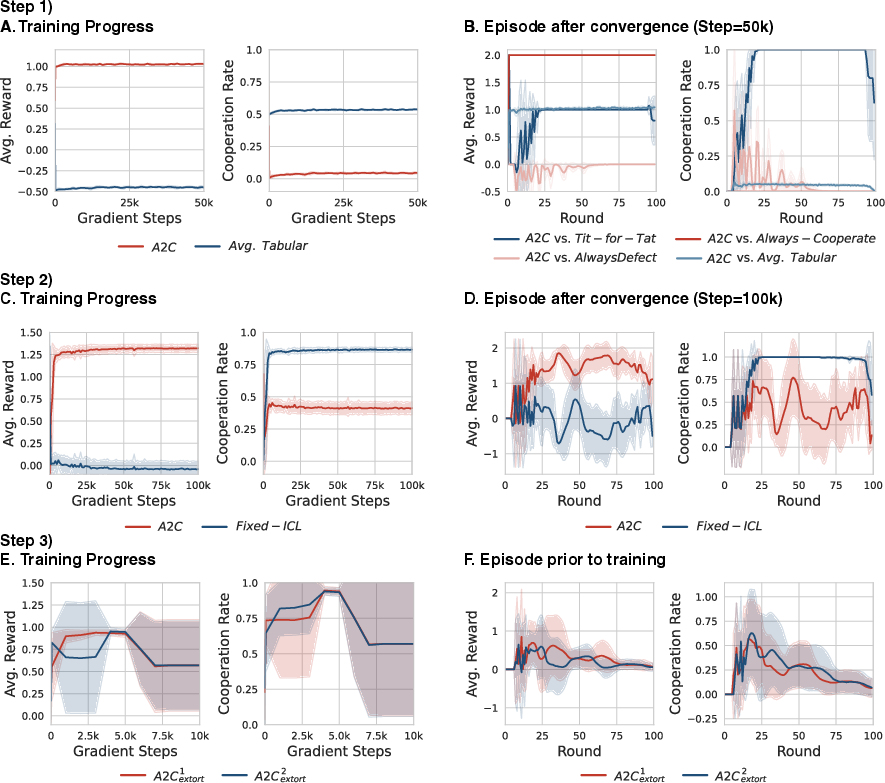
- Extortion appears naturally: If an agent adapts to you during the game, you can pressure it—by threatening to defect unless it cooperates (this is “extortion”). The authors show that learning agents can discover such pressure tactics against in-context learners.
- Mutual pressure → cooperation: When two agents can both pressure each other, they end up shaping each other’s behavior toward cooperation. They try to extort, realize it doesn’t pay off long-term against someone equally capable, and settle into cooperating.
- Ablation checks (what happens if you remove key pieces):
- If agents only play other learning agents (no diverse opponents), or
- If agents are told exactly who they’re playing (so there’s no need to infer anything),
- they slide into mutual defection. This shows that learning to infer and adapt in context is essential for cooperation.
Why this is important:
- Past methods needed complicated setups (e.g., assuming how the other learns, or separating agents into fast “naive learners” and slow “meta-learners”).
- This paper shows a simpler, scalable recipe: train sequence-model agents on a diverse pool, and cooperation can emerge by itself.
What This Means Going Forward (Implications)
- A practical path to cooperative AI: As we build more AI agents that interact with each other (like digital assistants, game bots, or automated negotiators), this approach gives a simple way to encourage fair and cooperative outcomes—no heavy “meta-learning” machinery needed.
- Fits naturally with modern AI: Big “foundation” models already learn from diverse data and show in-context learning. This work hints that, with the right training environment, such agents can learn cooperative social behaviors at scale.
- More robust multi-agent systems: By relying on diversity and in-context inference, agents can handle many types of co-players and still find cooperative solutions, even in mixed-motive situations.
In short: Train memory-based agents against a wide variety of opponents, let them learn to read and adapt within each game, and cooperation can emerge on its own—even among self-interested players.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to enable concrete follow-up work.
- Generalization beyond IPD: Validate whether mixed-pool training induces cooperation in other general-sum games (e.g., Stag Hunt, Chicken, bargaining, public goods, common-pool resource games), including asymmetric-payoff and non-Markovian settings.
- N-player interactions: Extend experiments from 2-player IPD to multi-player (N>2) environments to test whether in-context co-player inference scales to group dynamics and networked interactions.
- Continuous and high-dimensional spaces: Assess scalability to continuous action spaces and high-dimensional, noisy, or partially observable observation streams (e.g., visual or language inputs).
- Opponent diversity: Replace the simple memory-1 tabular opponents with richer and adaptive co-players (e.g., long-memory strategies, stochastic tit-for-tat, grim trigger, zero-determinant strategies, other RL algorithms, LLM-based agents) and quantify how diversity type/distribution affects outcomes.
- Training distribution design: Systematically study how the mixture proportions and parameterizations in the training pool (e.g., 50/50 split, uniform sampling in tabular parameter space) impact learned behavior; identify minimal diversity needed for cooperation.
- Out-of-distribution robustness: Evaluate learned policies against unseen strategies (including human-designed and LLM-based agents) to measure generalization and brittleness to distribution shift.
- Formal extortion characterization: Quantify extortion via established metrics (e.g., zero-determinant extortion parameter χ) to confirm that learned policies implement extortion and to track how extortion evolves during training.
- Mechanism guarantees: Provide theoretical conditions under which mutual extortion reliably leads to cooperation, including proofs or counterexamples in finite-horizon, stochastic, and noisy settings.
- Horizon sensitivity: Analyze sensitivity to episode length T and discount γ, including random termination; extortion/cooperation mechanisms may depend critically on effective horizon.
- In-context adaptation rate: Measure and control the speed of intra-episode adaptation; study outcomes when both agents adapt at similar/different rates and how this affects extortion vulnerability and cooperation.
- Identity and observability: The ablation shows that explicit agent identification collapses to defection; investigate mechanisms that maintain cooperation when identities or partial type signals are available (more realistic deployments).
- Communication channels: Examine whether cheap talk or structured communication aids or undermines the inferred mechanism; identify conditions under which communication stabilizes cooperation without enabling exploitation.
- Noise and mistakes: Test robustness to observation noise, action slips, delayed feedback, and miscoordination (trembling-hand errors) to determine if cooperation persists under realistic imperfections.
- Population-level dynamics: Move beyond pairwise training to large mixed populations; study replicator dynamics, policy diversity maintenance, and equilibrium selection in evolving ecosystems of agents.
- Algorithmic breadth: Compare results across a wider set of RL methods (e.g., PPO, Q-learning variants, model-based RL beyond PPI) to establish whether the effect is algorithm-agnostic or sensitive to specific training choices.
- Hyperparameter robustness: Provide deeper sensitivity analyses for key hyperparameters (e.g., β in PPI, entropy regularization, reward scaling), including broader ranges and interactions, to rule out fragile tuning effects.
- PPI design choices: Justify and ablate the reinitialization of the sequence model at each phase; compare against continuous fine-tuning to assess stability, sample efficiency, and catastrophic forgetting.
- Planning horizon adequacy: The PPI rollout depth (15 steps) may be too short for long-horizon games; quantify how planning depth affects policy quality, extortion/cooperation emergence, and computational cost.
- World-model fidelity: Measure how model mis-specification and compounding prediction errors affect policy improvement; explore uncertainty-aware planning or model ensembles to mitigate degradation.
- Fairness vs. efficiency: Extortion achieves unequal payoffs en route to cooperation; study objective designs or constraints that promote both efficiency and fairness (e.g., fairness-regularized policies, social welfare trade-offs).
- Safety and misuse: In-context vulnerability to extortion could be exploited; develop robustification strategies (e.g., extortion detectors, safety policies, adversarial training) that preserve cooperation without enabling exploitation.
- Pretraining dependence: Determine whether pretraining on tabular interactions is necessary; compare with self-play, curricula, or broader synthetic datasets to reduce reliance on narrow pretraining distributions.
- Evaluation depth: Expand reporting beyond mean and standard deviation over 10 seeds (e.g., confidence intervals, effect sizes, failure modes) and include reproducibility artifacts to strengthen evidence.
- Real-world constraints: Investigate how the mechanism behaves when agents have costly exploration, limited memory, computational constraints, or when identity and reputation systems are available (typical in practical deployments).
- Equilibrium analysis: The appendix references predictive equilibria; provide main-text clarity on existence, uniqueness, and relationship to Nash and subjective embedded equilibria, including conditions for convergence and stability.
Practical Applications
Overview
This paper shows that training sequence-model agents (foundation-model-style policies) against a diverse pool of co-players induces in-context co-player inference and fast intra-episode best-response adaptation. That adaptation makes agents vulnerable to extortion, and mutual extortion pressures between similarly capable agents drive them toward cooperative behaviors—without hardcoded opponent-learning rules, explicit meta-gradients, or engineered timescale separation. The paper also introduces Predictive Policy Improvement (PPI), a practical model-based RL method that blends self-supervised sequence modeling with planning to learn such in-context best responses.
The following lists synthesize actionable real-world applications derived from these findings and methods. Each item notes sector links, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
The items below can be piloted with current tools and infrastructure (e.g., sequence models, simulation environments, standard RL libraries).
- Multi-agent cooperation curriculum for AI agents in simulated platforms
- Sector: software, research
- What: Adopt “mixed-pool training” (diverse co-players, no explicit IDs) to induce in-context co-player inference and cooperative equilibria in repeated, mixed-motive tasks (e.g., bargaining, resource sharing).
- Tool/workflow: Add a Mixed-Pool Training Curriculum to existing MARL frameworks (PettingZoo-like), with tabular/opponent policy generators; integrate A2C or PPI trainers; evaluation via iterated social dilemmas.
- Assumptions/dependencies: Repeated interactions; diverse opponent distribution; no opponent ID leakage; game/task resembles mixed-motive dynamics (not one-shot zero-sum).
- Predictive Policy Improvement (PPI) library for sequence-model agents
- Sector: software, robotics, education, research
- What: Package PPI (sequence-model pretraining + next-token prediction + Monte Carlo value rollouts + action reweighting) as a training/inference module for sequence models in multi-agent settings.
- Tool/product: “PPI Planner” library compatible with JAX/PyTorch; APIs for model-based rollouts and policy improvement over sequence-model priors; examples for IPD and other repeated games.
- Assumptions/dependencies: Reasonably accurate learned world model; sufficient compute for planning rollouts; stability in performative prediction loops.
- Cooperative agent teams for enterprise automation workflows
- Sector: software (RPA/agent ops), operations
- What: Train agent teams to cooperatively route tasks, resolve contention (e.g., ticket triage, procurement approvals), and avoid defection-like behaviors such as blame-shifting or resource hogging.
- Workflow: Mixed-pool simulation of typical co-worker behaviors; deploy agents with in-context inference to adapt to collaborator styles; monitor cooperation metrics.
- Assumptions/dependencies: Repeated tasks and feedback; simulated opponents approximating human variability; guardrails to prevent extortion-like strategies against humans.
- Negotiation bots for marketplaces and B2B procurement
- Sector: finance, supply chain, e-commerce
- What: Use in-context co-player inference to negotiate discounts, delivery schedules, and SLAs, learning cooperative outcomes (e.g., splitting surplus) across repeated interactions.
- Tool/product: “CoPlay Negotiator” bots trained via mixed pools (including hard bargainers and generous partners), tracking fairness and long-term value.
- Assumptions/dependencies: Repeated relationships; reliable signals about counterpart behavior via interaction history; compliance controls to avoid collusion/anti-competitive behaviors.
- Multi-robot coordination in constrained environments
- Sector: robotics, logistics
- What: Coordinate warehouse or fleet robots to avoid congestion and mutually beneficially share lanes, chargers, or tools using in-context inference of co-robot behavior.
- Workflow: Simulated mixed co-player populations (aggressive vs. courteous policies); deploy PPI-trained sequence agents; measure throughput and conflict rate.
- Assumptions/dependencies: Reliable perception of others’ actions; repeated local interactions; safe policy bounds; sim2real transfer for sequence models.
- Multi-stakeholder recommender/control agents that avoid “race-to-the-bottom”
- Sector: software, ads/recommendations
- What: Train serving agents to balance user value, creator fairness, and platform metrics without devolving into mutual defection (e.g., clickbait amplification).
- Tool/workflow: Mixed pools reflecting different stakeholder strategies; sequence-model agents with PPI for in-context adaptation; metrics for cooperative outcomes (retention, satisfaction).
- Assumptions/dependencies: Credible reward signals for long-term value; repeated dynamics; alignment with platform policy; careful monitoring for extortion-like exploitation of creators/users.
- AI social simulation benchmarks for cooperative behavior
- Sector: academia, AI safety
- What: Build evaluation suites where LLM-based agents learn cooperation through mixed-pool training; measure extortion vulnerability, mutual shaping, and convergence to cooperative norms.
- Tool/product: “Cooperation Scorecard” (cooperate/defect rates, fairness indices, extortion detection); open datasets of tabular/random strategies; ablations for ID leakage vs. in-context inference.
- Assumptions/dependencies: Sequence-model agents with in-context skills; standardized metrics; careful ethics review for extortion dynamics.
- Training personal productivity assistants to collaborate across teams
- Sector: daily life, enterprise
- What: Personal assistants that learn colleagues’ preferences through interaction history and adapt toward cooperative scheduling, document sharing, and task handoffs.
- Workflow: Mixed pool of collaborator profiles; sequence-model policy with PPI; integration with calendar/email APIs; opt-in consent and transparency.
- Assumptions/dependencies: Repeated interactions; privacy-preserving design; guardrails against exploitative shaping of user behavior.
- Policy sandboxing for platform cooperative AI behavior
- Sector: policy, governance
- What: Regulators and platforms test agent training schemes that include co-player diversity to induce cooperation; deploy detection dashboards for extortion strategies.
- Tool/product: Regulatory sandbox with simulated agents; extortion-vulnerability tests; reporting standards for multi-agent training curricula.
- Assumptions/dependencies: Access to simulation tools; agreement on metrics for “cooperation” vs. “collusion”; interoperability across agent vendors.
Long-Term Applications
These require further validation beyond IPD, broader scaling, domain adaptation, and/or regulatory and social alignment work.
- Traffic and infrastructure cooperation among autonomous systems
- Sector: mobility, smart cities
- What: Vehicles and traffic controllers learn to cooperate at intersections, lane merges, and charging queues via in-context inference of others’ policies; reduce gridlock and aggressive driving equilibria.
- Potential tools: Urban-scale multi-agent simulators with mixed driver policy pools; PPI-like training at scale; V2X standards for interaction histories.
- Assumptions/dependencies: High-fidelity simulation; robust perception; safety certification; diverse opponent behaviors representative of human drivers.
- Coordinated energy demand response and prosumer markets
- Sector: energy
- What: Household/business energy agents learn to cooperate in load shifting, storage, and microgrid trading; avoid mutual defection (e.g., peak hoarding) and extortionate pricing.
- Tools/workflows: Mixed-pool market simulators; cooperative bidding agents; policy guardrails to prevent collusion and protect consumers.
- Assumptions/dependencies: Reliable repeated interactions; fair market rules; transparency; regulatory compliance.
- Cross-hospital and care-team resource allocation
- Sector: healthcare
- What: Agents representing departments (OR scheduling, ICU beds) coordinate to achieve better global outcomes; learn cooperative sharing protocols through in-context inference.
- Tools: Healthcare MARL testbeds; PPI-trained agents with bounded incentives; auditing and fairness checks.
- Assumptions/dependencies: Privacy-preserving data exchange; clinical safety; governance of agent decisions; robust against adversarial strategies.
- Supply chain coalition formation and fair surplus splitting
- Sector: supply chain, logistics
- What: Agents coordinating suppliers, manufacturers, and carriers learn cooperative contracts for lead times and inventory buffers; avoid repeated defection in dispute scenarios.
- Tools: Mixed-pool contract negotiation simulators; cooperative outcome metrics; integration with ERP systems.
- Assumptions/dependencies: Long-horizon interactions; enforceable agreements; careful limits to avoid anti-competitive outcomes.
- Multi-agent financial systems with pro-social objectives
- Sector: finance
- What: Agents in auctions/market making learn cooperative dynamics that internalize long-term value and market stability (e.g., reduced toxic flow), while avoiding collusion.
- Tools: Market simulators with diverse counterpart strategies; PPI-based training; compliance layers to detect extortion/collusion patterns.
- Assumptions/dependencies: Strong regulation; explainability; robust anomaly detection; validated social welfare objectives.
- Collaborative educational agents in group learning
- Sector: education
- What: AI tutors/peers adapt to student group dynamics via in-context inference to promote cooperation, fair participation, and shared problem-solving.
- Tools: Classroom simulation with diverse student profiles; cooperative pedagogy metrics; deployment with teacher oversight.
- Assumptions/dependencies: Ethical constraints; measurable learning gains; prevention of manipulative/extortionate interactions.
- Agent governance frameworks leveraging “cooperation via diversity”
- Sector: policy, AI governance
- What: Standards recommending mixed-pool training and withholding opponent IDs to encourage in-context inference and cooperative equilibria; audits for extortion vulnerability and shaping.
- Tools: Certification criteria; test suites for social dilemmas beyond IPD (e.g., public goods, bargaining); reporting templates.
- Assumptions/dependencies: Broad industry buy-in; empirical generalization to many domains; clear distinction between cooperation and illicit collusion.
- Safety research on extortion vulnerability and mutual shaping
- Sector: AI safety, research
- What: Systematize detection/mitigation of extortion and exploitative shaping in foundation-model agents; design norms and interventions that steer mutual shaping toward prosocial outcomes.
- Tools: Extortion-vulnerability diagnostics; mechanism design overlays; counter-shaping policies embedded in agent objectives.
- Assumptions/dependencies: Agreement on ethical definitions; validated interventions; cross-model generality.
- Human-AI collaboration protocols
- Sector: daily life, enterprise
- What: Design interaction protocols where human partners and AI agents achieve cooperative outcomes through transparent histories and repeated engagements, minimizing exploitative dynamics.
- Tools: Interaction logs with consent; explainable in-context inference; safeguards and opt-out mechanisms; longitudinal evaluation of cooperation/fairness.
- Assumptions/dependencies: User trust; strong privacy; participatory design; ongoing monitoring for manipulation.
Cross-cutting assumptions and dependencies
- Generalization: Results demonstrated primarily in Iterated Prisoner’s Dilemma; extending to richer, partially observed, high-dimensional environments requires further empirical validation.
- Diversity and anonymity: Cooperative dynamics rely on training against diverse co-players and withholding explicit opponent identifiers; real systems may leak identities or metadata.
- Repeated interactions: Mechanism depends on intra-episode adaptation over many rounds; one-shot interactions may not exhibit cooperative pressures.
- Model quality: PPI depends on accurate sequence-model world predictions for planning; poor models can distort value estimates.
- Ethics and compliance: Extortion vulnerability is a double-edged sword; safeguards are needed to prevent exploitative shaping of humans or unfair market behaviors.
- Compute and engineering: Monte Carlo rollouts, sequence model training, and mixed-pool simulation require non-trivial infrastructure; optimization for latency and scale may be necessary.
These applications translate the paper’s core insight—cooperation emerging from in-context co-player inference under diverse training—into practical deployments and research agendas, while highlighting the conditions under which the mechanism is likely to succeed and remain safe.
Glossary
- Ablation: An experimental removal or modification of components to test their impact on outcomes. "we perform two ablations:"
- Advantage Actor-Critic (A2C): A policy-gradient reinforcement learning algorithm that uses an actor to select actions and a critic to estimate value, leveraging advantage estimates for updates. "We employ Advantage Actor-Critic (A2C)~\citep{mnih_asynchronous_2016} as a standard decentralized model-free RL method."
- Advantage normalization: A training technique that normalizes advantage estimates to stabilize policy gradient updates. "including the value function estimation, Generalized Advantage Estimation~\citep{schulman2015high}, advantage normalization and reward scaling."
- Bootstrapped temporal-difference errors: Value estimation method using the current value function to bootstrap targets for TD learning. "During training, we estimate the advantage A(x_{\leq t}, a_t) using bootstrapped temporal-difference errors:"
- Decentralized Multi-Agent Reinforcement Learning (MARL): Learning setting where multiple agents optimize policies with only local observations and no centralized controller. "Decentralized Multi-Agent Reinforcement Learning (MARL) addresses the problem of learning to interact with other agents while only having access to local observations."
- Extortion: In game theory, a strategy that enforces a linear payoff relation to exploit adaptive opponents, often in iterated dilemmas. "The optimal strategy against a naive learner (an agent updating its policy to maximize rewards on a fast timescale) is extortion \citep{press_iterated_2012}."
- General-sum games: Games where the sum of players’ payoffs is not constant; players’ interests are partly aligned and partly opposed. "In general-sum games, many Nash equilibria may exist, and agents independently optimizing their own rewards frequently converge to suboptimal outcomes"
- Generalized Advantage Estimation (GAE): A technique to compute low-variance, biased advantage estimates using exponentially weighted TD residuals. "including the value function estimation, Generalized Advantage Estimation~\citep{schulman2015high}"
- In-context best-response: A policy that infers the opponent during the episode and adapts its actions to the best response within the same trajectory. "We hypothesize that training sequence model agents via decentralized MARL against a diverse distribution of co-players naturally yields in-context best-response policies."
- In-context learning: The ability of a model to adapt behavior based on observed context within a single episode, without changing weights. "the in-context learning capabilities of sequence models allow for co-player learning awareness without requiring hardcoded assumptions or explicit timescale separation."
- In-weight updates: Parameter updates across episodes that occur on a slower timescale than in-context adaptation. "agents become susceptible to extortion by other learning agents using in-weight updates."
- Iterated Prisoner's Dilemma (IPD): A repeated two-player game where cooperate/defect choices yield payoffs that create a social dilemma across rounds. "We focus on the Iterated Prisoner's Dilemma (IPD), a canonical model for studying cooperation among self-interested agents"
- Maximum A-Posteriori Policy Optimization (MPO): A policy optimization method that reweights actions by exponentiated value while regularizing towards a prior. "This method is a variation of Maximum A-Posteriori Policy Optimization~\citep[MPO]{abdolmaleki2018maximum}"
- Meta-learning: Learning strategies that enable agents to learn how to learn, often via optimization across tasks or updates. "effectively treating the interaction as a meta-learning problem \citep{bengio_learning_1990, schmidhuber_evolutionary_1987, hochreiter_learning_2001}."
- Meta-gradient machinery: Techniques that compute gradients through learning processes (e.g., opponent updates or inner loops) to shape learning-aware behavior. "without explicit time-scale separations or meta-gradient machinery."
- Mixed-motive settings: Interaction scenarios where agents have partially aligned and partially conflicting objectives. "ensuring that self-interested agents robustly cooperate in mixed-motive settings remains an important open challenge"
- Monte Carlo rollouts: Simulated trajectories used to estimate expected returns or Q-values by sampling future outcomes. "The action value \hat{Q}_p(h,a) is estimated via Monte Carlo rollouts performed within the sequence model ."
- Mutual extortion: A dynamic where both agents attempt extortion, often leading to pressure that transforms behavior towards cooperation. "Mutual extortion leads to cooperation:"
- Nash equilibria: Strategy profiles where no player can improve their payoff by unilaterally deviating. "In general-sum games, many Nash equilibria may exist"
- Non-stationarity: An environment property where dynamics change over time, e.g., because other agents are learning simultaneously. "the environment is non-stationary because other agents are simultaneously learning and adapting their policies"
- Partially observable stochastic game (POSG): A multi-agent extension of POMDPs where agents receive private observations and act simultaneously with stochastic transitions. "We formalize the multi-agent interaction as a partially observable stochastic game \citep[POSG;] []{kuhn_extensive_1953} of agents."
- Performative prediction: Training predictive models where the data distribution is influenced by the model’s deployed predictions. "This is a common strategy in performative prediction \citep{perdomo2020performative} to ensure more stable training of the prediction model."
- Policy iteration: A procedure alternating policy evaluation and policy improvement to converge toward optimal policies. "similar to classical policy iteration."
- Policy prior: A prior distribution over actions produced by a model, which is combined with value-based reweighting during improvement. "serving simultaneously as a world model and a policy prior."
- Predictive Policy Improvement (PPI): A model-based algorithm that improves policies by reweighting a learned sequence-model prior with estimated action values, then distilling back into the model. "Predictive Policy Improvement (PPI). We introduce a model-based algorithm that leverages a sequence model predicting the joint sequence of actions, observations, and rewards, serving simultaneously as a world model and a policy prior."
- Sequence model: A model (e.g., RNN/Transformer) that processes and predicts sequences of tokens such as actions, observations, and rewards. "We introduce a model-based algorithm that leverages a sequence model predicting the joint sequence of actions, observations, and rewards"
- Social dilemma: A situation where individual rationality leads to collectively suboptimal outcomes, e.g., mutual defection. "agents independently optimizing their own rewards frequently converge to suboptimal outcomes, such as mutual defection in social dilemmas"
- Subjective embedded equilibria: Equilibrium notions for agents with internal models embedded in environments, accounting for subjective predictions. "and relate it to Nash equilibria and subjective embedded equilibria \citep{meulemans2025embedded}."
- Timescale separation: A design where different learning processes operate at distinct speeds (e.g., fast inner updates vs. slow meta-updates). "without requiring hardcoded assumptions or explicit timescale separation."
- World model: A learned predictive model of environment dynamics and observations used for planning or policy improvement. "serving simultaneously as a world model and a policy prior."
Collections
Sign up for free to add this paper to one or more collections.