- The paper demonstrates that error accumulation in recursive training can lead to model collapse if fresh data is insufficiently incorporated.
- It introduces theoretical upper and lower divergence bounds using Girsanov’s theorem and observability coefficients to quantify score estimation errors.
- Empirical validation on Gaussian mixtures and CIFAR-10 highlights the critical role of the fresh data fraction (α) in maintaining model stability.
Error Propagation and Model Collapse in Diffusion Models: A Theoretical Study
Introduction and Problem Setting
Machine learning systems increasingly leverage synthetic data, especially in generative model pipelines. A prominent failure mode—termed model collapse—is observed when a generative model is recursively trained on its own outputs: distributional mass drifts toward high-density cores while diversity and fidelity erode. While prior theoretical work on recursive training focused on regression or maximum-likelihood estimators, a comprehensive quantitative analysis for score-based diffusion models remained unavailable.
This work presents a rigorous analysis of error propagation and model collapse in recursively trained score-based diffusion models, where each round of training incorporates both synthetic and a fraction α of fresh data sampled from the true data distribution. The central quantities tracked are:
- Accumulated divergence: Di=χ2(p^i∥data), measuring model drift from the target distribution at generation i,
- Intra-generation divergence: Ii=χ2(p^i+1∥qi), quantifying divergence induced by one training round, where qi=αdata+(1−α)p^i.
The propagation of score estimation errors and their impact on model collapse is characterized using pathwise statistics induced by the diffusion processes. This analysis clarifies how model collapse is mitigated by fresh data and exacerbated by error accumulation.
Theoretical Framework
Recursive Training Dynamics
Each generation begins with a mixture of fresh and synthetic samples. Training a score-based diffusion model on qi gives a new model p^i+1, which again partakes as synthetic data in subsequent rounds. This recursion is expressed as: p^i→qi=αdata+(1−α)p^i→p^i+1
The underlying training target becomes the score of qi, not the true data distribution, introducing a structural misalignment that is exacerbated by imperfect score estimation.
Divergence Bounds: Upper and Lower
The intra-generational divergence Ii is tightly bounded by the pathwise energy of the score error. Two critical results arise:
- Upper Bound (via Girsanov's theorem):
KL(p^i+1∥qi)≤21ε^i2
where ε^i2 is the pathwise L2 energy of the score error along the learned process.
- Lower Bound (with observability):
χ2(p^i+1∥qi)≥81ηiε⋆,i2
Critically, the observability coefficient ηi∈[0,1] measures the fraction of pathwise error that leaves a statistical imprint at the endpoint. ηi is typically nonzero in practical parametric models with state-dependent error.
The two-sided control is formalized as: c1ηiε⋆,i2≤χ2(p^i+1∥qi)≤c2ε⋆,i2
in the perturbative regime where score error is small.
Intergenerational Error Accumulation
The effect of the fresh data fraction α is to contract model divergence at each generation by (1−α)2, while the newly introduced score error increases divergence: Di+1=(1−α)2Di+(innovation due to score error)
Closed-form analysis reveals:
- If ∑iε⋆,i2=∞, then accumulated divergence never vanishes—model collapse is inevitable.
- If ∑iε⋆,i2<∞, the accumulated divergence remains uniformly bounded.
The long-term divergence, after N generations, admits a discounted sum structure: DN+1≍k=0∑N(1−α)2(N−k)ε⋆,k2
Errors from past generations are exponentially forgotten, with rate determined by α.
Numerical Experiments and Empirical Validation
Synthetic Data: Gaussian Mixture
Experiments with 10-dimensional Gaussian mixtures validate the theory. Low α (little fresh data) leads to rapid divergence:
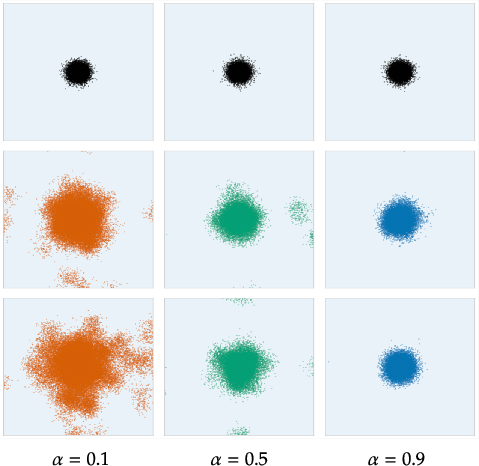
Figure 1: Samples from recursively trained models shown via PCA on a 10D Gaussian mixture; columns increase in α from left to right, rows progress through generations. Low α exhibits fast dispersal/collapse, while high α maintains stability.
Correspondingly, the intra-generational error bounds and the intergenerational accumulation law are empirically tight:
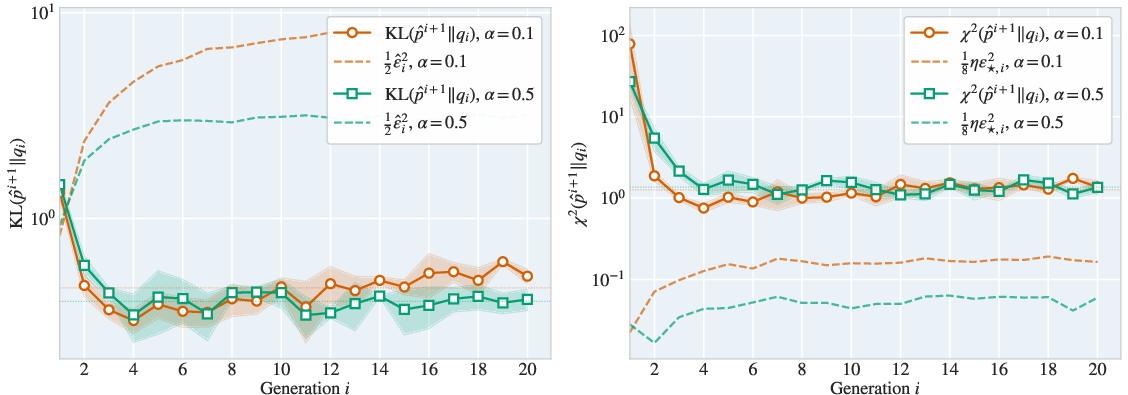
Figure 2: Empirical validation of intra-generational error upper/lower bounds, supporting the tightness of the theoretical predictions.
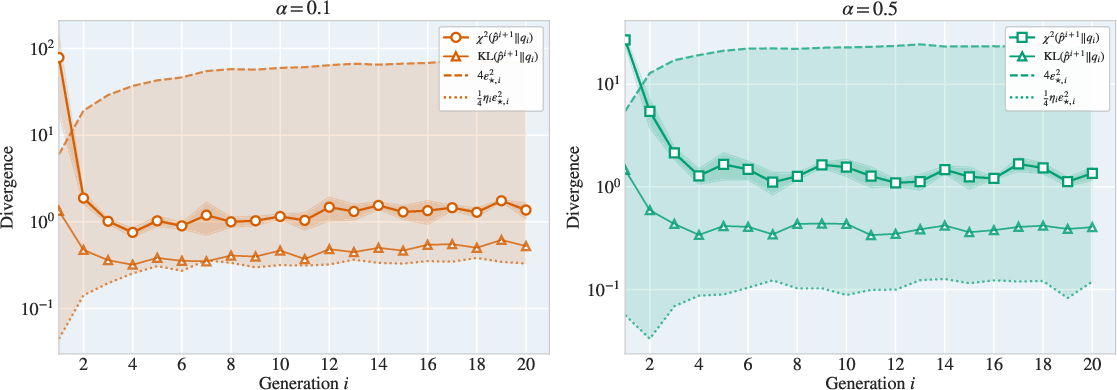
Figure 3: Two-sided control of intra-generation divergence, showing close agreement between theoretical and observed χ2 and KL divergences as functions of score error energy.
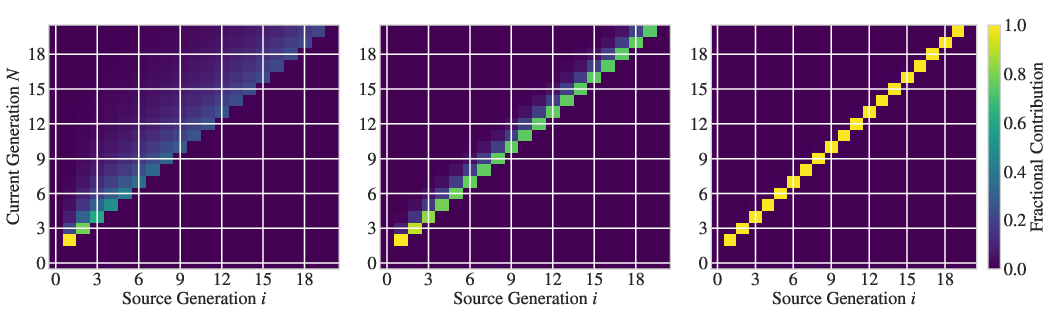
Figure 4: Memory heatmap visualizes the geometrically-discounted influence of errors from previous generations; sharp diagonal for high α (short memory), wide band for low α (long memory and more persistent collapse).
Key finding: For high α (e.g., α=0.9), distributional drift is nearly eliminated, and divergence is stable across many recursive generations.
Observability of Score Error
Controlled experiments on CIFAR-10 show observability coefficient ηi is consistently nonzero for state-dependent perturbations:
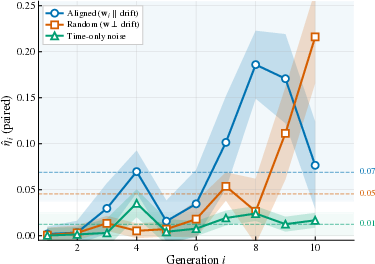
Figure 5: Observability coefficients for several classes of perturbations in CIFAR-10, confirming that state-dependent errors are more ‘visible’ and thus lead to statistically significant divergence.
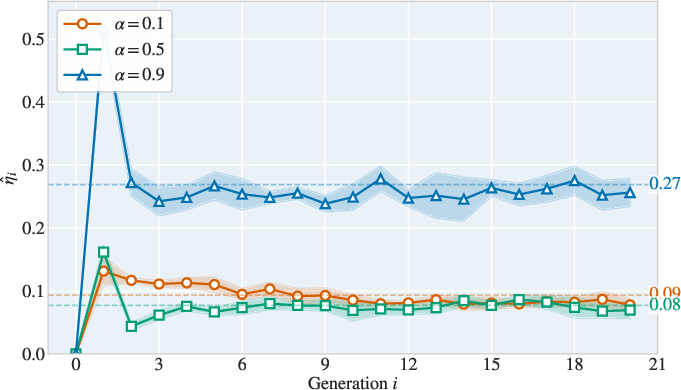
Figure 6: Observability coefficient η^i remains nonzero across generations (10D Gaussian Mixture), confirming persistent error visibility and hence the relevance of lower divergence bounds.
Visual Effects of Model Collapse
The visual impact of collapse under recursive training is apparent in sample quality and diversity:

Figure 7: Random samples over generations under three α rates in a recursive pipeline; low α leads to rapid mode collapse, high α maintains diversity.
Implications and Outlook
The theoretical construction and empirical results make several strong contributions:
- Provable divergence lower bounds for diffusion models via score error observability, demonstrating that error is not hidden but statistically manifest.
- Identification of a discounted memory principle: geometric forgetting of past errors with rate set by the fresh data fraction α.
- Contradicts the naive hypothesis that bounded per-round error always suffices for stability; accumulation can overwhelm contraction if errors are not summable.
Practical implications include principled selection of α to prevent collapse and direct estimation of safe training horizons given per-generation error statistics. The observability framework generalizes to more realistic models and high-dimensional settings, as confirmed with image datasets.
Theoretical implications include insight into structural sources of collapse, the role of conditional independence and state dependence in error propagation, and the importance of pathwise statistics.
Conclusion
This study establishes rigorous, quantitative links between pathwise score estimation error, error visibility (observability), and model collapse in recursive diffusion model training. The results precisely characterize the interplay between fresh data injection and unavoidable error accumulation, with empirical validation across both synthetic and real data domains. Open questions include analyzing large-error regimes, discrete-time implementations, and characterizing ultimate model fixed points under the recursive process. This framework provides a robust foundation for future developments in the reliable self-improvement of generative models and recursive pipelines.
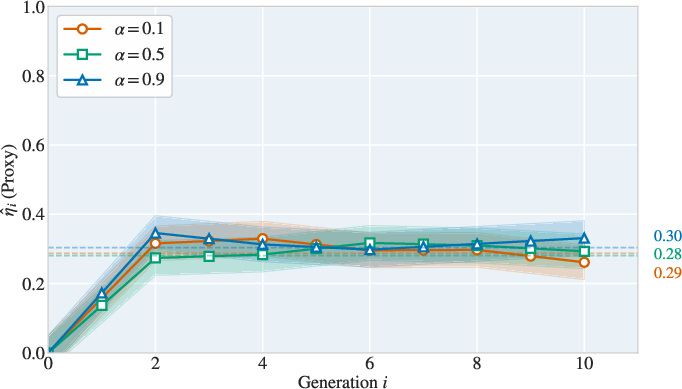
Figure 8: Observability coefficients on CIFAR-10 show stability across generations and further corroborate nonzero projection of error energy onto the output distribution.
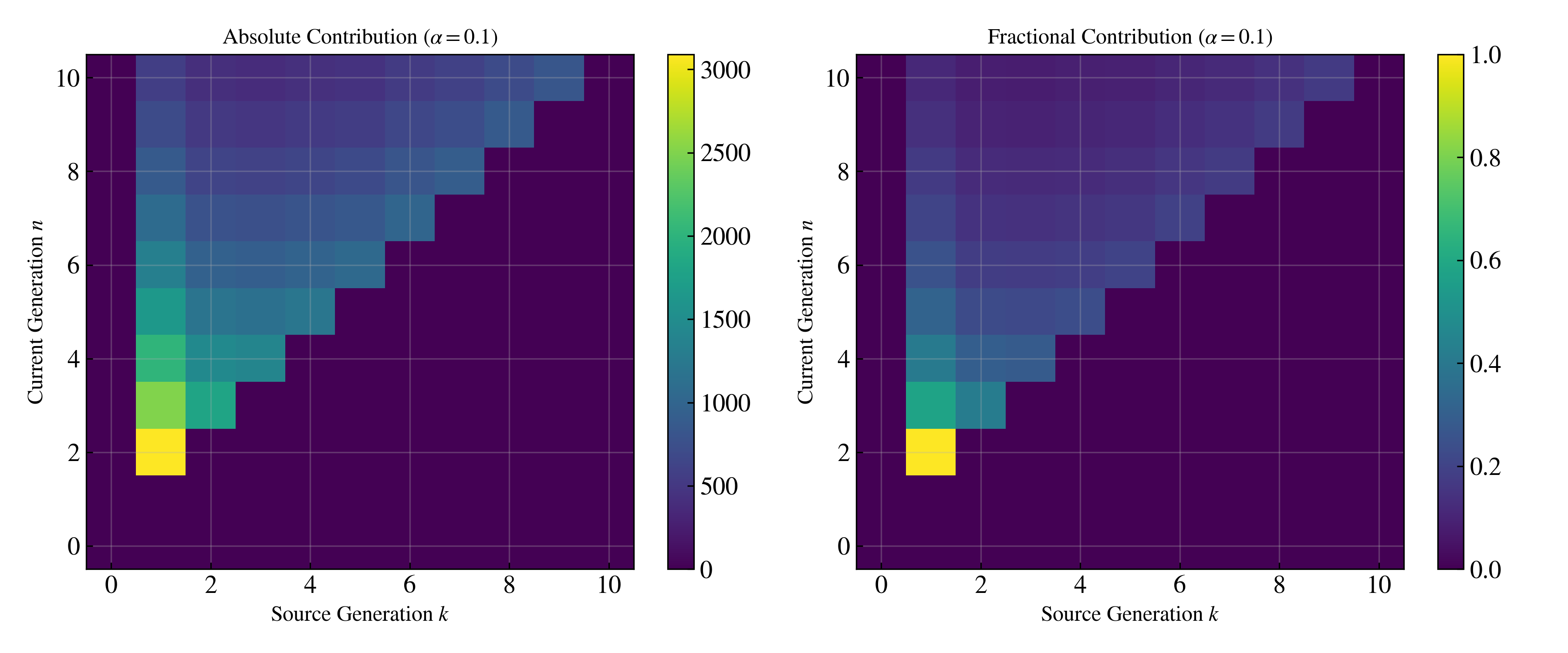
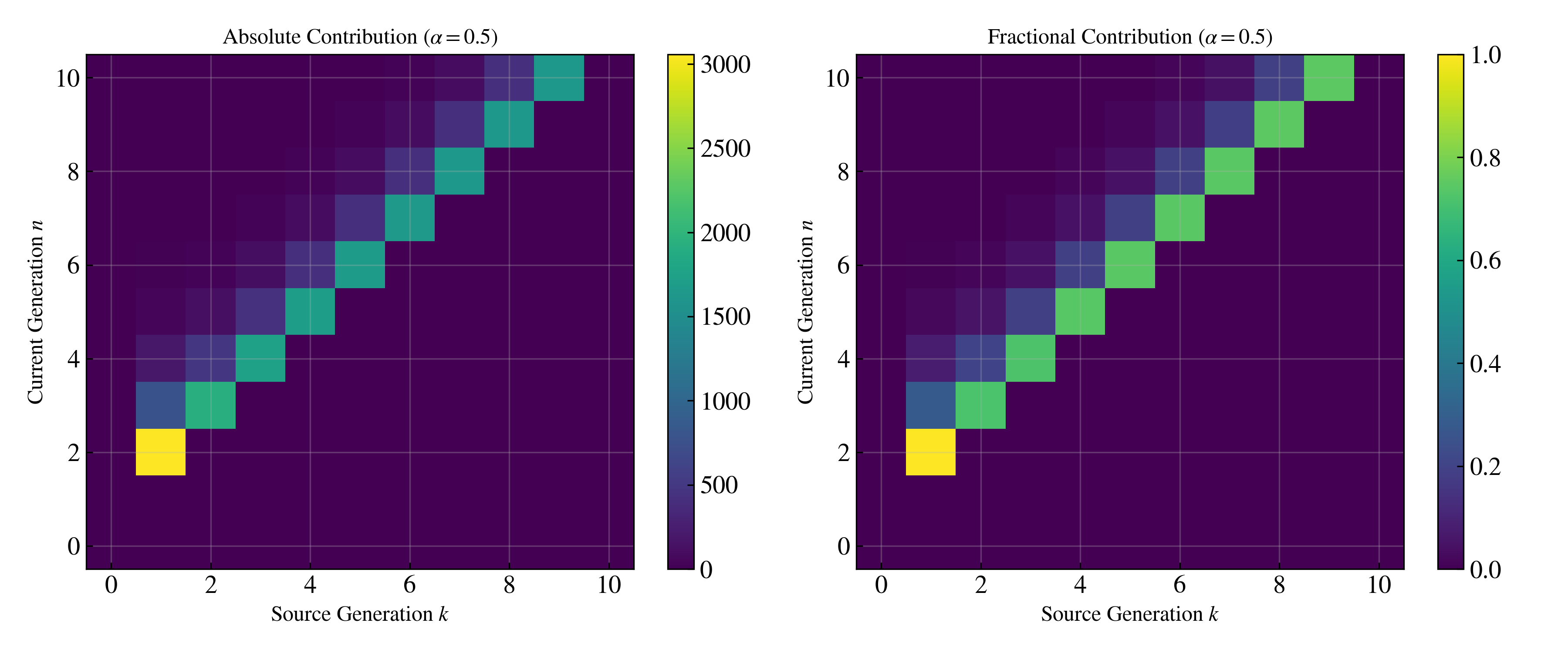
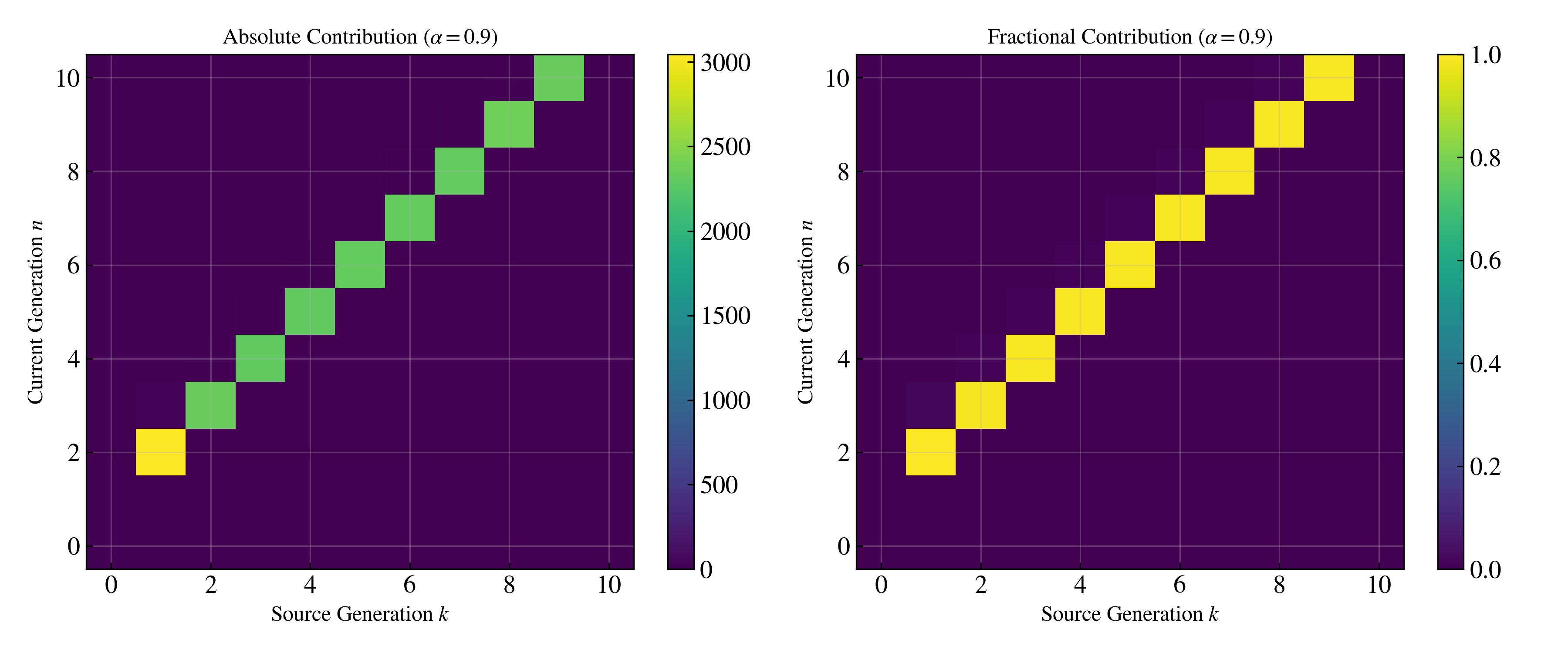
Figure 9: Additional visualizations of recursive training at α=0.1 emphasize rapid collapse without sufficient data refresh.