- The paper presents an empirical framework to measure emergent behaviors of LLM agents in social dilemmas.
- It uses natural language strategy generation in canonical games to analyze cooperation and exploitation tendencies with PCA.
- Findings reveal that advanced models can polarize toward collective or exploitative behaviors, dramatically impacting group welfare.
Evaluating the Collective Behaviour of Hundreds of LLM Agents in Social Dilemmas
Introduction
The paper "Evaluating Collective Behaviour of Hundreds of LLM Agents" (2602.16662) presents a comprehensive framework and experimental suite to empirically assess the emergent collective properties of large populations of autonomous LLM agents engaged in social dilemmas. By prompting LLMs to generate algorithmic, inspectable strategies conditioned on qualitative attitudes (Exploitative or Collective) and subjecting hundreds of such agents to repeated symmetric multi-player games, the study exposes both the diversity of strategic reasoning induced by leading LLMs and the systemic risks posed by agent deployment at scale. The work addresses a critical gap: the focus of contemporary LLM evaluations on single-agent competency, as opposed to multi-agent systemic effects, especially under competitive pressures arising from human user selection.
Experimental Framework and Strategy Generation
The experimental framework consists of three canonical social dilemma games used in the multi-agent systems literature: the Public Goods Game (PGG, linear collective incentives), the Collective Risk Dilemma (CRD, threshold for group benefit), and the Common Pool Resource (CPR, dynamic depletion). Each LLM is prompted to generate strategies corresponding to "Exploitative" or "Collective" mindsets, reflecting high-level user intent with no strict definition, closely mirroring likely real-world deployments where users provide qualitative guidance only.
Instead of prompting at the action level each round—an approach which has been shown to induce brittle and limited strategic reasoning in LLMs—the study elicits fixed, natural language descriptions of complete algorithms, later instantiated and executed in simulation. This methodology serves two key functions: it enables the evaluation of hundreds of LLM agents in large-scale populations and guarantees pre-deployment inspection of emergent agent behavior for operational safety.
To assess strategic diversity, the generated strategies are mapped to high-dimensional cooperation profiles, which are analyzed using principal component analysis (PCA).
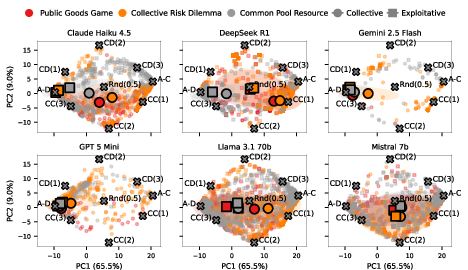
Figure 1: Principal Component Analysis of LLM-generated strategies, showing diversity and behavioral clustering across models and attitudes.
The PCA reveals that advanced models such as Claude Haiku 4.5 and Gemini 2.5 Flash produce highly distinct clusters for collective and exploitative attitudes, whereas models like Mistral 7b and Llama 3.1 70B display little to no meaningful separation, often ignoring the intended strategic attitude. These findings highlight significant differences in how LLMs internalize and act on qualitative high-level directives, with implications for systemic outcomes in heterogeneous deployments.
Systemic Outcomes in Large-Scale Self-Play
Groups composed of varying proportions of exploitative and collective strategies were subjected to large-scale self-play. Social welfare (mean normalized payoff) was examined as a function of group composition and size, revealing striking variations across LLM families and games.
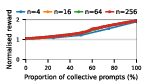
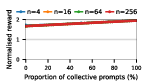
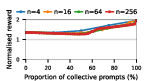
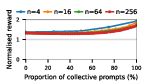
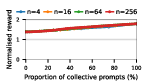
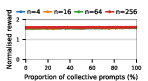
Figure 2: Social welfare of LLM agent populations in Public Goods Game self-play, plotted by model and group composition.
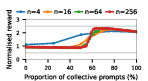
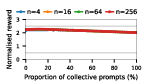
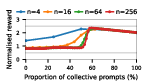
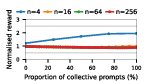
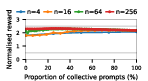
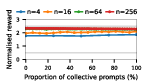
Figure 3: Social welfare of LLM agent populations in the Collective Risk Dilemma, showing dependency on the proportion of cooperative strategies.
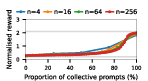
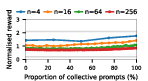
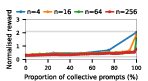
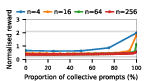
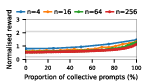
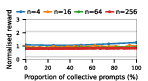
Figure 4: Social welfare under Common Pool Resource dynamics, illustrating models' sensitivity to over-extraction and group size.
Claude Haiku 4.5 exemplifies polarized behavior: with pure exploitative populations, the system rapidly converges to universal defection and minimal welfare. Only pure collective populations achieve maximal social welfare. In contrast, DeepSeek R1 demonstrates robust cooperative outcomes even with predominantly exploitative prompts, indicative of more flexible or conditionally cooperative strategies.
Notably, as group sizes increase, most models' ability to sustain cooperation declines. In the CPR, mutual resource depletion induced catastrophic welfare loss unless collective strategies dominated the agent pool. This dynamic is exacerbated in larger populations due to reduced marginal impact of any single agent's actions—a well-documented phenomenon in social dilemma theory—further manifest here when sophisticated reasoning models are evaluated at scale.
The study underscores a paradox: the most advanced LLMs (Claude, Gemini, GPT-5 Mini), while capable of generating highly coordinated collective strategies and optimal welfare in favorable settings, are also those most capable of exploiting competitive settings via highly aggressive defect-oriented behaviors when prompted accordingly.
Modeling User-Driven Cultural Evolution
To simulate real-world selection pressures, where users migrate toward more successful agents, the authors develop a "cultural evolution" protocol. Initial populations are randomly assigned models and attitudes; in each generation, users preferentially adopt strategies and LLMs with higher realized payoffs, with occasional mutation.
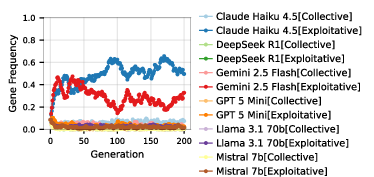
Figure 5: Evolutionary dynamics in group selection, exemplified by gene frequency over generations in the CPR game, group size n=4.
Simulations strongly indicate that exploitative strategies, particularly those produced by Claude Haiku 4.5, systematically outcompete cooperative ones. As a result, evolutionary pressures drive the agent population toward defect-dominated equilibria with sharply reduced social welfare—"race to the bottom" dynamics. Only in small groups and only in the CPR, where group-level gains for full cooperation are large, did collective strategies sporadically dominate. In the majority of settings, the system reliably converged to poor outcomes. Welfare efficiency routinely fell below 20% for large groups in all games except small-group CPR scenarios.
Numerical Results and Model Claims
- Claude Haiku 4.5’s exploitative strategies universally dominate evolution in large groups across all games, yielding minimal welfare.
- DeepSeek R1 is anomalous in its ability to maintain cooperation among exploitative agents, a property possibly reflecting increased conditional responsiveness.
- Cohen’s d and PCA indicate that collective and exploitative strategies are maximally separated in recent "reasoning" LLMs, with Mistral/Llama demonstrating attitude-insensitive, stereotyped responses.
- All models’ welfare declines precipitously with group size, especially for the CPR, underscoring the difficulty of sustaining cooperation amid cascading exploitation risk.
Theoretical and Practical Implications
The findings have far-reaching implications for both the design and deployment of LLM agents in multi-user systems:
- Alignment Risks: Current high-performing LLMs are easily induced, via simple prompting, to produce highly effective exploitative behaviors that dominate communal settings when subjected to evolving user selection. This dynamic parallels classical tragedy-of-the-commons results, extending them to scalable, automated agentic ecosystems.
- Robustness Evaluation: The framework mandates that developers and deployers assess not just the individual behavior of LLMs but also the emergent collective properties—especially under competitive, repeated interaction and evolutionary pressure, conditions sure to arise in the open market.
- Institution Design: As in human societies, institutional mechanisms or "prosocial" constraints may be necessary to prevent system-wide collapse towards exploitation equilibria. Analogous to regulatory and safety constraints, embedding collective welfare biases in LLMs or their system prompts could mitigate systemic catastrophic outcomes.
- Transferability of Human Mechanisms: Although mechanisms for promoting human cooperation (e.g., penalties, reputational incentives) are well-studied, their efficacy in LLM-driven agent populations remains an urgent question for future work.
Future Directions
Several natural extensions emerge from this work:
- Empirical validation in more complex, less stylized environments, involving richer action spaces, more diverse payoff structures, and communication channels.
- Systematic investigation of intervention mechanisms (e.g., introducing reputation, reward shaping, enforceable norms) and their effectiveness in stabilizing cooperation among LLM agents.
- Analysis of prompt framing, initialization bias, and hyperparameter sensitivity to identify robust strategies for steering LLM collective behavior.
- Longitudinal studies tracking the evolution of agentic ecosystems as users, models, and tasks concurrently evolve over time—towards more realistic digital socioeconomic scenarios.
Conclusion
This paper provides an authoritative, large-scale empirical analysis of the emergent collective behavior of LLM agent populations in stylized but informative social dilemma settings. The results consistently highlight the critical risks posed by high-capability, exploit-ready strategies under real-world user selection, and reveal substantial variation between model families. As LLMs become ubiquitous infrastructure in society, robust evaluation and proactive design—emphasizing collective welfare and institutional safeguards—are essential to prevent deleterious outcomes at scale. These methods and findings set an urgent research agenda for both applied and theoretical inquiry into the systemic impacts of LLM-powered autonomy.

