One-step Language Modeling via Continuous Denoising
Abstract: LLMs based on discrete diffusion have attracted widespread interest for their potential to provide faster generation than autoregressive models. In practice, however, they exhibit a sharp degradation of sample quality in the few-step regime, failing to realize this promise. Here we show that LLMs leveraging flow-based continuous denoising can outperform discrete diffusion in both quality and speed. By revisiting the fundamentals of flows over discrete modalities, we build a flow-based LLM (FLM) that performs Euclidean denoising over one-hot token encodings. We show that the model can be trained by predicting the clean data via a cross entropy objective, where we introduce a simple time reparameterization that greatly improves training stability and generation quality. By distilling FLM into its associated flow map, we obtain a distilled flow map LLM (FMLM) capable of few-step generation. On the LM1B and OWT language datasets, FLM attains generation quality matching state-of-the-art discrete diffusion models. With FMLM, our approach outperforms recent few-step LLMs across the board, with one-step generation exceeding their 8-step quality. Our work calls into question the widely held hypothesis that discrete diffusion processes are necessary for generative modeling over discrete modalities, and paves the way toward accelerated flow-based language modeling at scale. Code is available at https://github.com/david3684/flm.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making computer programs that write text (like chatbots) much faster without making the quality worse. Instead of writing one word at a time, the authors show how to generate many words at once—sometimes the whole sentence in a single step—by using a smarter way to “clean up” noise into readable text.
The big questions the researchers asked
- Can we build a LLM that writes high‑quality text in just a few steps, even one step?
- Why do some fast “parallel” methods for text (called discrete diffusion) lose quality when you try to use only a few steps?
- Is there a better approach that keeps quality high and speeds things up?
How their approach works (in simple terms)
Think of making a sentence appear from static, like tuning an old TV from snow to a clear picture. There are two common ways to do this:
- One-at-a-time writing: write the sentence word by word. It’s accurate but slow because every word waits for the previous one.
- Discrete diffusion: start with a noisy sentence and clean it little by little, fixing many words in parallel each step. In theory it’s fast, but in practice it often needs many steps; if you cut steps, the quality drops sharply.
The authors propose a different route: continuous flows with a shortcut.
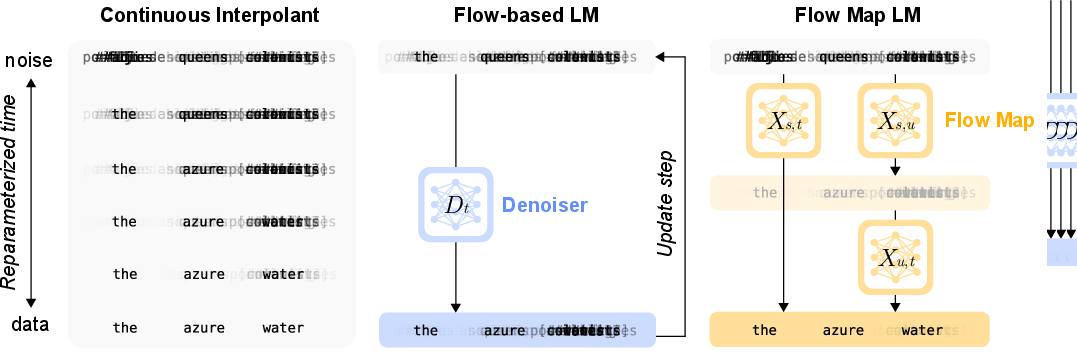
- Continuous flow (their FLM): Instead of treating words as totally separate choices each step, the model moves the whole sentence smoothly from “noise” toward the final clean text. Internally, each word is represented as a “one‑hot” lightboard (only one light on for the chosen word), and the model learns how to slide these lights from random to correct positions.
- A smarter target to learn: Rather than predicting the “difference” between noisy and clean text (which is messy and hard), the model directly predicts the clean words themselves at each moment. That’s like aiming for the final answer every time, which is easier to learn.
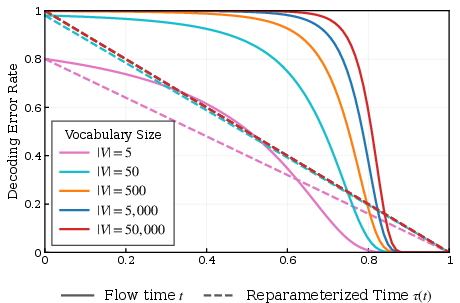
- Time re-timing: The team noticed that the important decisions about which word is correct mostly happen very late in the process—especially with big vocabularies. If you train by picking times uniformly (early, middle, late), you waste effort on times where not much changes. So they re‑draw the timeline so that every training step focuses equally on moments that actually decide words. This makes training more stable and generation better.
- Flow map (their FMLM): A “flow map” is a learned shortcut that jumps directly from noise to clean text between any two times (like taking an express elevator instead of stairs). The authors distill their slower flow into this shortcut in two stages: 1) Learn a small correction that turns a rough step into an accurate jump. 2) Compress everything into a single fast model that can do big jumps—down to one jump.
Why discrete diffusion struggles in few steps: It often treats each word as independent when denoising many positions at once. That can create combos that don’t belong together. Imagine a toy dataset where “new‑york” and “san‑diego” are valid pairs; a method that fixes each part separately might produce “new‑diego” or “san‑york,” which sounds wrong. Continuous flows avoid this by moving the whole sentence in a coordinated way, preserving word‑to‑word relationships.
What they found
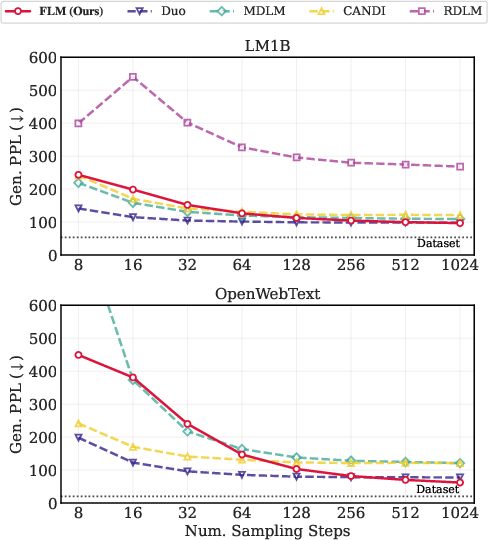
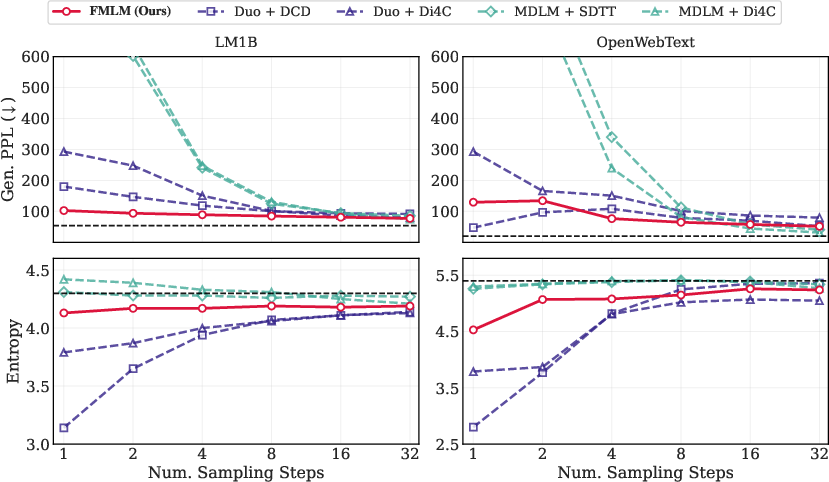
- Their flow-based model (FLM) matches or beats recent diffusion-style LLMs on two standard datasets (LM1B and OpenWebText) when using many steps.
- Their distilled flow map model (FMLM) is fast and strong in very few steps:
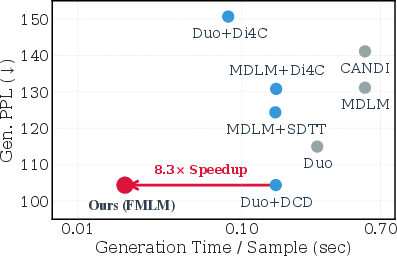
- On LM1B, one-step FMLM matches the quality that other methods need 8 steps to reach—about an 8.3× speedup in their setup.
- On OpenWebText, one-step FMLM reaches quality similar to other methods using 4–8 steps.
- Stability matters: Some competing few-step methods either break down (very bad scores) or look good but repeat themselves too much (low “entropy,” meaning low variety). FMLM keeps both quality and variety at healthy levels.
A quick guide to the scores they used:
- Generative perplexity (lower is better): How fluent or likely the text seems to a strong reference model.
- Entropy (higher is more varied): How diverse the output tokens are; too low can mean repetitive text.
Why this matters
- Faster text generation: Being able to write in one or a few steps can dramatically speed up LLMs, which helps with real-time applications and reduces compute costs.
- Better modeling of word relationships: By moving the whole sentence together, the method avoids “mix-and-match” errors that can happen when words are treated independently.
- Rethinking the field: Many people assumed that “discrete diffusion” was the right way to do fast parallel text generation. This paper shows that a continuous flow approach can be both faster and better, challenging that belief.
- A path to scaling: The flow map idea (learning the shortcut) suggests we can train accurate models and then compress them into very fast generators—useful for large systems and for other discrete data like code or symbolic sequences.
In short
The authors introduce a continuous denoising approach to language modeling (FLM) and a distilled shortcut version (FMLM). These models generate high‑quality text in very few steps—often just one—by smoothly transforming noise into sentences and learning a direct jump. This offers both speed and quality, pushing forward how fast we can make strong LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain, missing, or unexplored in the paper, structured to guide future research.
- Scaling to larger models and datasets:
- Evidence is limited to a 170M-parameter DiT on LM1B and OWT. It remains unknown how FLM/FMLM behaves at billion-parameter scales, on larger corpora (e.g., C4, The Pile), and under longer contexts (e.g., 4k–32k tokens).
- Efficiency and wall-clock comparisons:
- The paper shows a speed-quality Pareto curve and an ~8.3× speedup for LM1B, but lacks detailed, controlled wall-clock benchmarks against strong autoregressive (AR) baselines and discrete diffusion across hardware setups, batch sizes, and sequence lengths.
- Memory/computation scaling for one-hot encodings in R{L×|V|} (up to |V|≈50k, L up to 1024) is not quantified; practical limits and memory-optimizing strategies (e.g., factorized vocab projections, sparsity) are not explored.
- Conditional/prefix-to-suffix generation and in-context use:
- The experiments focus on unconditional generation. How to condition FLM/FMLM on prefixes (e.g., clamp a subset of tokens, conditional flows, or masked conditioning) and the resulting speed/quality trade-offs are not addressed.
- Generalization to multilingual and alternative tokenizations:
- Only English (LM1B, OWT) and two tokenizers (BERT WordPiece, GPT-2 BPE) are used. Robustness to different tokenization schemes (SentencePiece/BPE variants), morphologically rich languages, and multilingual corpora is unknown.
- Evaluation breadth and validity:
- Generative perplexity (Gen. PPL) is measured by GPT-2 Large plus unigram entropy; no human evaluation, long-range coherence tests, or task-based metrics are included.
- Over-reliance on a single external scorer (GPT-2 Large) may bias conclusions; sensitivity of Gen. PPL to scorer choice is not assessed.
- Additional diversity metrics beyond unigram entropy and Self-BLEU (e.g., distinct-n, repetition rates across spans) and quality dimensions (factuality, toxicity, coherence across paragraphs) are not reported.
- Comparison to strong autoregressive baselines:
- There is no speed-quality comparison with modern AR transformers tuned for fast decoding (e.g., chunked decoding, speculative or assisted generation), leaving unclear whether FMLM’s one-step advantage holds against best-practice AR methods.
- Robustness and failure modes:
- Stability under out-of-distribution prompts, rare tokens, and long-tail vocabulary is not studied.
- Sensitivity to sequence length mismatches between train and test (e.g., training at L=1024 but generating at longer/shorter lengths) is unreported.
- Time reparameterization τ(t) design and estimation:
- τ(t) is defined in terms of the decoding error rate P_e(t), but how P_e(t) is estimated in practice (dataset dependence, estimation noise) is not fully specified. The sensitivity of performance to mis-specified τ(t) or to changes in |V|, L, and data domain is unclear.
- Adaptive or learned schedules versus the proposed fixed τ(t) are not compared.
- Flow-map learning choices:
- The paper adopts semigroup-based distillation with a novel two-stage scheme; alternatives (e.g., MeanFlow, Lagrangian self-distillation, Jacobian-vector-product–based objectives) are noted but not empirically explored. Whether these alternatives improve one-step quality or stability is an open question.
- Lack of ablations on the two-stage design (residual correction then compression): it is unclear how much each stage contributes and whether a single-stage student suffices with appropriate objectives.
- Numerical aspects and ODE/flow properties:
- No analysis of stiffness near t≈1 (where token decisions concentrate) or of numerical stability beyond the proposed τ(t). The effect of higher-order integrators for many-step sampling (vs Euler) is not evaluated.
- Existence/uniqueness and regularity of the learned velocity/flow in the high-dimensional one-hot space are not analyzed; theoretical guarantees for invertibility/consistency or error bounds for discretization remain open.
- Representation and decoding design:
- The Euclidean, unconstrained one-hot representation is argued to be effective, but systematic comparisons with constrained/simplex-projected representations or learned embeddings are limited. When, and why, each representation works best remains unclear.
- Final decoding is by argmax; the impact of alternative decoding schemes (e.g., sampling from the denoiser distribution, temperature scaling, top-k/p) on quality/diversity and calibration is unexplored.
- Calibration and probabilistic correctness:
- While the denoiser outputs lie on the simplex and training uses cross-entropy, calibration of the posterior p_{1|t}l(·|x_t) is not assessed. Whether better-calibrated denoisers yield better flows/maps is unknown.
- Guidance and controllability:
- The paper briefly mentions autoguidance in the appendix; broader guidance strategies (classifier-free, attribute or topic controls) and their impact on one-step quality and diversity are not systematically studied.
- Distillation capacity and compression:
- The student flow-map model appears to match teacher capacity. How much the teacher can be compressed (e.g., smaller student, lower precision) without losing one-step quality and how this interacts with sequence length is untested.
- Token-level correlation assessment:
- A key claim is avoiding discrete diffusion’s factorization error. However, there is no direct measurement of inter-token correlation capture (e.g., mutual information across positions, syntactic/semantic dependency metrics) to substantiate this mechanism empirically.
- Generalization to other discrete modalities:
- Although the method is conceptually general, experiments are only on text. Application to other discrete domains (code, music tokens, molecular sequences) is untested.
- Training stability and loss weighting:
- EDM2 learned loss weighting is used, but the paper lacks ablations that isolate its effect versus τ(t), architecture, or optimizer settings.
- Data and safety considerations:
- Bias, toxicity, and safety aspects of generations are not evaluated; how one-step generation interacts with content safety filters or post-hoc controls remains to be determined.
- Reproducibility and hyperparameter sensitivity:
- Many key choices (τ(t) computation, learned loss weighting specifics, semigroup sampling distribution, step-size distributions) may materially affect outcomes; systematic hyperparameter sensitivity studies are missing.
- Theoretical relationship to Monge maps and optimal transport:
- The paper notes sample-level flow maps are tractable in continuous space, but does not analyze optimality properties (e.g., relation to Monge maps or transport costs) or whether learned maps approximate any optimal transport under a suitable cost.
- Limits of one-step generation:
- While one step performs well at the tested scales, the regime in which more steps become necessary (e.g., very long contexts, structured tasks, richer tokenizations) and how step count trades off with quality remains unexplored.
Practical Applications
Overview
The paper introduces a flow-based LLM (FLM) that performs continuous denoising on one-hot token encodings and a distilled flow-map LLM (FMLM) that enables few-step (even one-step) parallel text generation. Key innovations include: (1) Euclidean denoising over one-hot encodings with a cross-entropy objective; (2) a time reparameterization derived from decoding error that stabilizes training and optimizes step allocation; and (3) a two-stage flow-map distillation that turns a velocity-based flow into a robust, few-step flow map. Empirically, FMLM achieves one-step generation quality comparable to 8-step baselines, yielding substantial speedups.
Below are actionable applications derived from these findings.
Immediate Applications
The following use cases can leverage the methods largely as-is (subject to standard engineering integration), given the demonstrated performance on LM1B and OWT and the released code.
- Low-latency assistants and typing aids (software, mobile)
- Use case: Reduce response latency for chatbots, smart keyboards, email and document writing aids by generating entire segments in one or few steps.
- Tools/products/workflows: Integrate FMLM as an inference engine in mobile apps; expose a “few-step generation” API for text suggestions; run one-shot completion for sentences/paragraphs.
- Assumptions/dependencies: Requires domain-specific fine-tuning; on-device deployment needs quantization/pruning; quality beyond LM1B/OWT must be validated.
- Server throughput optimization for text services (cloud, SaaS)
- Use case: Increase per-GPU throughput by replacing long, serial autoregressive decoding with few-step parallel generation in batch settings (copy generation, summarization at scale).
- Tools/products/workflows: Deploy FMLM microservices; schedule requests on reparameterized time grids; integrate learned loss weighting for stability.
- Assumptions/dependencies: Throughput gains depend on sequence length and hardware; careful benchmarking vs KV-cached autoregressive systems is required.
- Speculative/draft decoding for large autoregressive LMs (software, AI infrastructure)
- Use case: Use FMLM to propose multi-token drafts that a primary AR LM verifies/corrects, reducing end-to-end latency and cost.
- Tools/products/workflows: Draft-then-verify pipeline; FMLM proposes one-step outputs; AR LM accepts/rejects spans; feedback loop tunes FMLM for high acceptance.
- Assumptions/dependencies: Requires efficient verifier integration; mismatch between FMLM and AR distributions must be managed.
- Real-time infilling and document editing (productivity, IDEs)
- Use case: Parallel fill-in-the-blank, sentence/paragraph rewriting, code refactoring with few-step or one-step infills.
- Tools/products/workflows: Condition FMLM on context spans; run constrained denoising for masked positions; provide “instant infill” UX.
- Assumptions/dependencies: Conditioning mechanisms (masked inputs, classifier guidance) must be implemented and tuned; training for infill tasks may be needed.
- Energy-aware inference for green AI (energy, cloud ops)
- Use case: Fewer forward passes per sequence reduce energy per output, supporting sustainability goals and cost reduction.
- Tools/products/workflows: Track energy/sequence KPIs; deploy FMLM in power-constrained environments (edge servers, datacenter PUE-sensitive clusters).
- Assumptions/dependencies: Net energy benefit depends on model size, batch size, and sequence length; measurement must compare against KV-cached AR baselines.
- Safer, steered generation via guidance (trust & safety)
- Use case: Combine autoguidance/classifier guidance with flow maps to steer outputs away from toxicity or toward style/format constraints.
- Tools/products/workflows: Plug toxicity or style classifiers into guidance; run guided few-step sampling for policy-compliant outputs.
- Assumptions/dependencies: Requires reliable auxiliary classifiers; guidance strength must be tuned to avoid quality degradation.
- High-throughput synthetic text generation for data augmentation (ML training)
- Use case: Quickly produce diverse corpora for pretraining, robustness tests, and domain adaptation.
- Tools/products/workflows: FMLM sampler with noise seeds for diversity; automatic filtering pipelines to enforce quality.
- Assumptions/dependencies: Domain shift requires careful curation; avoid distributional artifacts and repetition (monitor entropy/Self-BLEU).
- Research baselines and teaching materials (academia, education)
- Use case: Study continuous flows for discrete data; examine factorization error vs. continuous denoising; teach flow maps, semigroup training, and time reparameterization.
- Tools/products/workflows: Use the public code; replicate LM1B/OWT results; small-scale lab exercises on τ(t) scheduling and two-stage distillation.
- Assumptions/dependencies: Compute resources for training; familiarity with DiT architectures and flow-matching objectives.
- Plugin for inference frameworks (software tooling)
- Use case: Add a “flow map backend” to existing inference stacks (e.g., vLLM-like systems) for batch few-step generation.
- Tools/products/workflows: Implement kernels for (s, t) flow-map jumps; expose configuration for τ(t) grids and step counts.
- Assumptions/dependencies: Requires engineering to integrate with tensor parallelism, quantization, and serving infrastructure.
- Rapid whole-sequence rollout for evaluation and RL (ML ops, RLHF pipelines)
- Use case: Generate full sequences in one/few steps to accelerate evaluation, reward-model scoring, or preference data collection.
- Tools/products/workflows: Use FMLM for fast candidate generation; run reward models on batches; close the loop with human or automated feedback.
- Assumptions/dependencies: Compatibility with downstream reward models; align data formats and lengths with RL pipelines.
Long-Term Applications
These use cases require additional research, scaling, or integration work before deployment.
- Flow-based cores for large-scale general-purpose LMs (software, cloud, consumer)
- Use case: Replace or augment AR decoding with few-step flow-map generation in high-capacity models to cut latency at scale.
- Tools/products/workflows: Train large FLM→FMLM with instruction tuning; hybrid systems that choose AR vs FMLM per task.
- Assumptions/dependencies: Open scaling laws for flow-based LMs; alignment and safety tooling needed at larger scales.
- On-device private assistants for sensitive domains (healthcare, finance, government)
- Use case: Offline note drafting, summarization, and templated reporting on secure devices with minimal cloud dependency.
- Tools/products/workflows: Domain-fine-tuned FMLMs; audited classifiers for safety guidance; secure firmware updates.
- Assumptions/dependencies: Rigorous compliance, data governance, and evaluation for domain accuracy and safety; hardware acceleration on edge devices.
- Multi-modal discrete generation with flow maps (media, code, scientific tokens)
- Use case: Extend continuous denoising over one-hot to other tokenized modalities (music, code, protein/DNA), enabling few-step parallel generation.
- Tools/products/workflows: Tokenizers and decoders per modality; modality-specific τ(t) schedules; multi-task flow-map distillation.
- Assumptions/dependencies: Modality-dependent data and metrics; controlling long-range constraints (syntax, structure) may require specialized guidance.
- Structured and constraint-aware generation (compliance, enterprise)
- Use case: Enforce schemas, templates, or regulatory constraints during generation by integrating differentiable constraints/guidance into the flow map.
- Tools/products/workflows: Constrained decoding via classifier/energy guidance; validation layers that project onto feasible sets.
- Assumptions/dependencies: Robust constraint models; proofs or empirical guarantees of constraint satisfaction without excessive quality loss.
- Compiler-like “flow map kernels” for inference acceleration (systems, hardware)
- Use case: Create compilers that optimize (s, t) transport operators for GPUs/NPUs, exploiting the deterministic, few-step nature of flow maps.
- Tools/products/workflows: Kernel fusion for τ(t) grids; memory layout optimizations; operator autotuning.
- Assumptions/dependencies: Requires systems research and hardware co-design; robust benchmarks across sequence lengths and batch sizes.
- Retrieval-augmented generation with flow conditioning (RAG)
- Use case: Condition flow-map generation on retrieved documents to deliver low-latency RAG answers for search and enterprise knowledge bases.
- Tools/products/workflows: Input-conditioning layers for context; retrieval adapters; caching of context embeddings for flow steps.
- Assumptions/dependencies: Conditioning mechanisms for flows on long contexts must be developed and validated.
- Robust, controllable distillation pipelines for enterprise models (ML engineering)
- Use case: Adopt the two-stage correction + single-model distillation to compress heavy flows into fast flow maps with minimal quality loss.
- Tools/products/workflows: Automated distillation orchestration; learned loss weighting; time-schedule calibration via P_e(t).
- Assumptions/dependencies: Stability at larger scales and across domains; monitoring and guardrails for semigroup consistency.
- Policy frameworks for energy-efficient and private AI (public sector)
- Use case: Incentivize deployment of few-step LMs that reduce energy and enable on-device processing for privacy-preserving services.
- Tools/products/workflows: Benchmarks standardizing “energy per generated token/sequence”; procurement guidelines favoring low-latency, on-device capable models.
- Assumptions/dependencies: Consensus metrics and third-party audits; collaboration with industry to standardize reporting.
- Education and accessibility with real-time generation (education, assistive tech)
- Use case: Instant summarization, captioning, and tutoring on low-cost devices for classrooms and accessibility aids.
- Tools/products/workflows: Lightweight FMLMs tuned for pedagogical prompts; offline content support; UI for latency-sensitive scenarios.
- Assumptions/dependencies: Requires high-quality, safe behavior under constrained compute; content filtering and age-appropriate controls.
- Accelerated scientific workflows (research, bio/chem)
- Use case: Rapid hypothesis generation, protocol drafting, or token-based scientific design (e.g., sequences), with swift iteration enabled by few-step sampling.
- Tools/products/workflows: Domain-specific tokenizers and evaluation harnesses; guided flows to respect scientific constraints.
- Assumptions/dependencies: Domain validation; integration with lab-specific tools and safety checks.
Notes on Feasibility and Dependencies (cross-cutting)
- Scaling: Results are shown on LM1B/OWT with ~170M-parameter DiT; performance at billions of parameters and instruction-tuned settings remains an open research area.
- Conditioning: The paper focuses on unconditional generation; practical applications often need prompt conditioning, infilling, or RAG—additional engineering and training are required.
- Safety: Although guidance is compatible with flows, robust, domain-ready safety requires curated classifiers, tuning, and red-teaming.
- Measurement: Reported quality uses generative perplexity and entropy; human preference alignment and task-specific metrics should be added before production use.
- Systems integration: Benefits depend on hardware, batch size, and sequence length. Real-world wins require careful benchmarking against optimized AR baselines (e.g., KV cache, paged attention).
- Model compression: On-device scenarios need quantization/pruning/distillation; these must preserve the flow-map’s semigroup accuracy.
Glossary
- Ancestral sampling: A generative procedure that samples sequentially from learned transition distributions along a time grid. "generation can be performed via ancestral sampling over a temporal grid"
- Argmax decoder: A decoding function that maps continuous token scores to discrete tokens by taking the index with the maximum value. "with an argmax decoder g:R{L\times |V|}\to VL"
- Autoregressive: Refers to models that generate each token conditioned on previously generated tokens in sequence. "based on an autoregressive process that produces one subword (token) per step"
- Average velocity (mean flow): The two-time vector field v_{s,t} whose scaled evaluation defines the flow map between times s and t; also called “mean flow.” "where v is called the average velocity or 'mean flow'"
- Boundary condition: The requirement that a flow map equals the identity when start and end times are the same. "By construction, it satisfies the boundary condition and tangent condition"
- Categorical cross-entropy loss: A loss function for multi-class classification used here to train probability outputs on the vocabulary simplex. "through a categorical cross-entropy loss"
- Conditional expectation: The expected value of a random variable given observations, used to define the optimal velocity and denoiser targets. "The conditional expectation form ... means that the velocity can be learned efficiently"
- Continuous diffusion: Generative models that operate in continuous spaces by denoising continuous representations. "continuous diffusion LLMs, which represent and denoise subwords in a continuous space"
- Denoiser: A model that predicts the clean data from a noised intermediate state, parameterized as tokenwise probabilities. "The function D_t, called the ``denoiser'', can be learned"
- Diffusion Transformer (DiT): A transformer architecture adapted for diffusion-like generative processes. "a 170M-parameter diffusion transformer (DiT)"
- Discrete diffusion: Generative models that reverse a discrete noising process on token sequences. "Discrete diffusion LLMs aim to achieve faster generation by producing several tokens in parallel at each step"
- Euler method (forward Euler method): A first-order numerical integration scheme for differential equations used to simulate flows. "for example with the forward Euler method."
- Euclidean denoising: Denoising performed in unconstrained Euclidean space rather than on a manifold or simplex. "performs Euclidean denoising over one-hot token encodings."
- Factorization error: The degradation arising from assuming independence across tokens in transition probabilities. "Factorization error in discrete diffusion."
- Factorized approximation: An approximation that decomposes joint transition probabilities into products of per-token conditionals. "discrete methods employ a factorized approximation p_{t|s}\star\approx p_{t|s}"
- Flow map: The solution operator X_{s,t} that transports a state from time s to time t under a learned flow. "the flow map X_{s, t}: R{L \times |V|} \to R{L \times |V|}"
- Flow matching: A training framework that matches a model’s vector field to the probability flow induced by a chosen interpolant. "leveraging flow matching over a stochastic interpolant."
- Gaussian noise: A normal (Gaussian) random perturbation used as the starting distribution in the interpolant. "continuous interpolation between Gaussian noise and one-hot language encoding."
- Generative perplexity: A metric assessing the likelihood of generated text under a reference LLM. "measure the generative perplexity (Gen.~PPL~) using pretrained GPT-2 Large"
- Jacobian-vector products: Computations involving the product of a Jacobian and a vector, used in certain flow-map objectives. "require the computation of Jacobian-vector products"
- Learned loss weighting: A schedule that stabilizes training by adjusting loss contributions across time. "employ the learned loss weighting proposed in EDM2"
- One-hot representation: A token encoding where each token is represented as a vector with a single 1 and zeros elsewhere. "a simple and canonical tokenwise one-hot representation f:VL\toR{L\times |V|}"
- Posterior probability: The probability of the clean token given the noised state at time t. "equals the posterior probability over the vocabulary:"
- Probability flow: The deterministic evolution of distributions induced by a velocity field. "where b_t is the velocity field of the probability flow"
- Probability path: The family of intermediate distributions p_t defined by an interpolant between noise and data. "we specify a probability path p_t({\bf x}_t) as the density of an interpolant"
- Probability simplex: The set of valid token-probability vectors summing to one. "lies on the probability simplex "
- Rotary positional embeddings (RoPE): A method of encoding position by rotating feature dimensions, used in transformers. "equipped with rotary positional embeddings (RoPE)"
- Score function: The gradient of the log-density used in score-based generative modeling; here referenced alongside velocity fields. "deterministic evolution driven by a velocity or score function"
- Self-distillation: Training a model using targets generated by itself (or its components) to improve or compress behavior. "via self-distillation for the flow map"
- Semigroup condition: The compositional property X_{u,t}(X_{s,u}(x)) = X_{s,t}(x) that characterizes flow maps. "We use the semigroup condition due to its simplicity"
- Stochastic interpolant: A random path (e.g., linear combination of noise and data) defining intermediate states for training flows. "leveraging flow matching over a stochastic interpolant"
- Stop-gradient operator: An operator that prevents gradients from flowing through certain computation paths during training. "with sg{\cdot} denoting the stop-gradient operator."
- Tangent condition: The requirement that the flow map’s time derivative at s equals the instantaneous velocity field b_s. "By construction, it satisfies the boundary condition and tangent condition"
- Teacher forcing: A training strategy where ground-truth tokens are fed to the model during training to stabilize learning. "through teacher forcing"
- Time reparameterization: A monotone transformation of time used to redistribute training and sampling effort. "We address this using a time reparameterization "
- Transport map: A deterministic mapping that moves data from a source distribution to a target distribution. "learns a deterministic transport map"
- Two-time denoiser: A generalization of the denoiser that predicts clean data across a pair of times (s,t) consistent with the flow map. "we refer to as the two-time denoiser:"
- Variance-exploding diffusion: A diffusion process whose noise variance increases with time. "variance-exploding ... and variance-preserving ... diffusions"
- Variance-preserving diffusion: A diffusion process designed to preserve variance across time, often used in discrete-time diffusion. "variance-exploding ... and variance-preserving ... diffusions"
- Velocity field: The vector field b_t(x) whose flow transports samples along the probability path. "where b_t is the velocity field of the probability flow"
Collections
Sign up for free to add this paper to one or more collections.