DDiT: Dynamic Patch Scheduling for Efficient Diffusion Transformers
Abstract: Diffusion Transformers (DiTs) have achieved state-of-the-art performance in image and video generation, but their success comes at the cost of heavy computation. This inefficiency is largely due to the fixed tokenization process, which uses constant-sized patches throughout the entire denoising phase, regardless of the content's complexity. We propose dynamic tokenization, an efficient test-time strategy that varies patch sizes based on content complexity and the denoising timestep. Our key insight is that early timesteps only require coarser patches to model global structure, while later iterations demand finer (smaller-sized) patches to refine local details. During inference, our method dynamically reallocates patch sizes across denoising steps for image and video generation and substantially reduces cost while preserving perceptual generation quality. Extensive experiments demonstrate the effectiveness of our approach: it achieves up to $3.52\times$ and $3.2\times$ speedup on FLUX-1.Dev and Wan $2.1$, respectively, without compromising the generation quality and prompt adherence.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
DDiT: Making image and video generators faster without hurting quality
1) What is this paper about?
This paper is about speeding up powerful AI systems that create images and videos, called diffusion transformers. The authors show a smart way to make them much faster while keeping the pictures and videos looking just as good. Their trick is to let the model look at the picture in different‑sized “chunks” at different times during generation.
2) What questions are the researchers asking?
- Do all moments in the image‑making process need the same level of detail?
- Can we save time by using big chunks when only rough shapes are forming, and small chunks later when tiny details matter?
- Can a model automatically choose the best chunk size for each step and each prompt (for example, “a blue sky” vs. “lots of zebras”)?
- Can we do this with little change to the original model and without lowering visual quality?
3) How does their method work? (Plain language)
Think of the model as an artist who starts with a noisy canvas and, step by step, removes noise until a clear picture appears. At each step, the model looks at the “hidden picture” (a compressed, internal version called a latent) by cutting it into square pieces called patches.
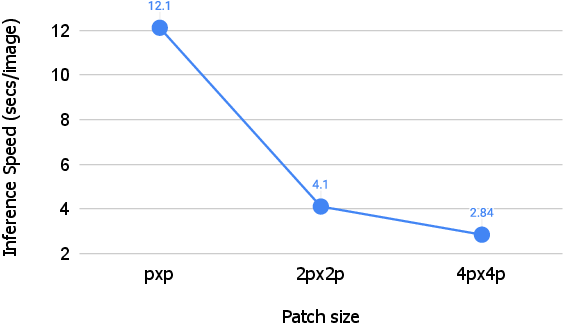
- Small patches = more detail but more computation.
- Big patches = less detail but much faster.
Key ideas:
- Early steps only need the big picture (shapes, layout), so big patches are fine.
- Later steps polish fine details (fur, text, edges), so small patches are better.
How does the model decide which patch size to use at each step?
- It measures how quickly the hidden picture is changing over the last few steps. You can think of this like checking whether the drawing is only shifting shapes slowly or adding lots of tiny, fast‑changing details.
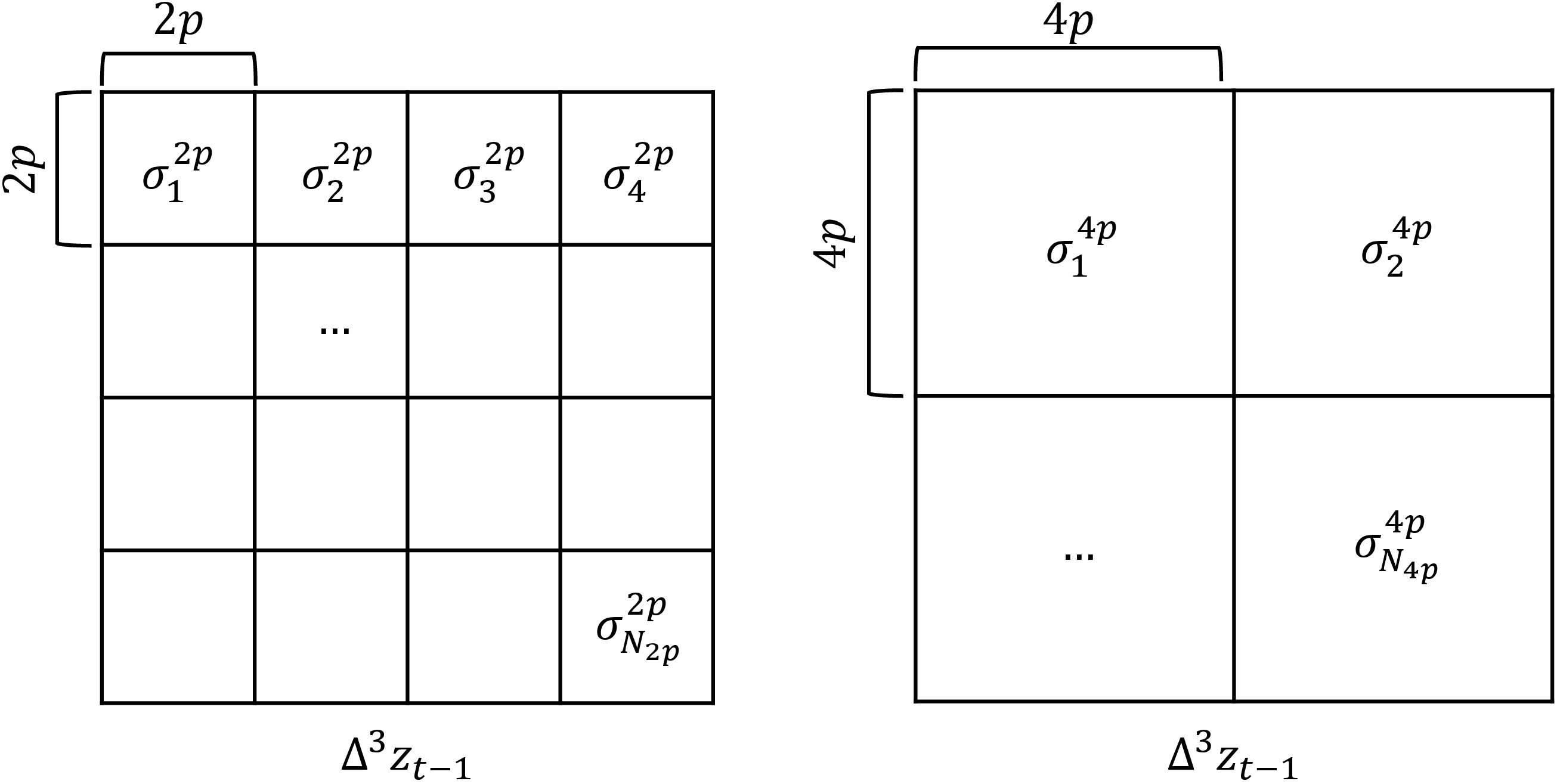
- Technically, they compute a “third‑order difference,” which is like measuring the “acceleration” of change in the latent. If change is calm and smooth, use big patches; if change is fast and detailed, use small patches.
- They also check how this change varies across different areas. Instead of averaging (which can hide small, detailed regions), they look at a percentile (a “busy parts” score) so that detailed regions still get the attention they need.
- A simple threshold controls how aggressive the speed‑up is. Higher threshold = faster but riskier; lower threshold = safer but slower.
How do they make the model accept different patch sizes?
- They add a lightweight adapter (called LoRA) and extra patch‑handling layers so the existing model can work with multiple patch sizes without retraining everything from scratch.
- They resize the model’s position hints (positional embeddings) so it still knows where each patch is, even when patches get bigger or smaller.
In short, the method:
- Enables the model to handle multiple patch sizes.
- At each denoising step, measures “how much and where things are changing.”
- Picks the largest patch size that still keeps details safe.
- Switches to smaller patches when fine detail is being formed.
4) What did they find, and why is it important?
Results on text‑to‑image (FLUX‑1.Dev) and text‑to‑video (Wan‑2.1):
- Big speedups with little to no quality loss:
- Images: up to about 2.2× faster on its own, and up to 3.5× faster when combined with a caching method, while keeping quality scores close to the original.
- Videos: about 1.6×–2.1× faster on its own, and up to 3.2× faster with caching, with similar video quality scores.
- Human judgments found no clear drop in quality; people often rated the outputs as equally good.
- The “third‑order” change measure worked best for deciding patch sizes versus simpler (first or second‑order) measures.
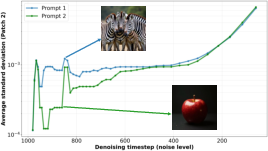
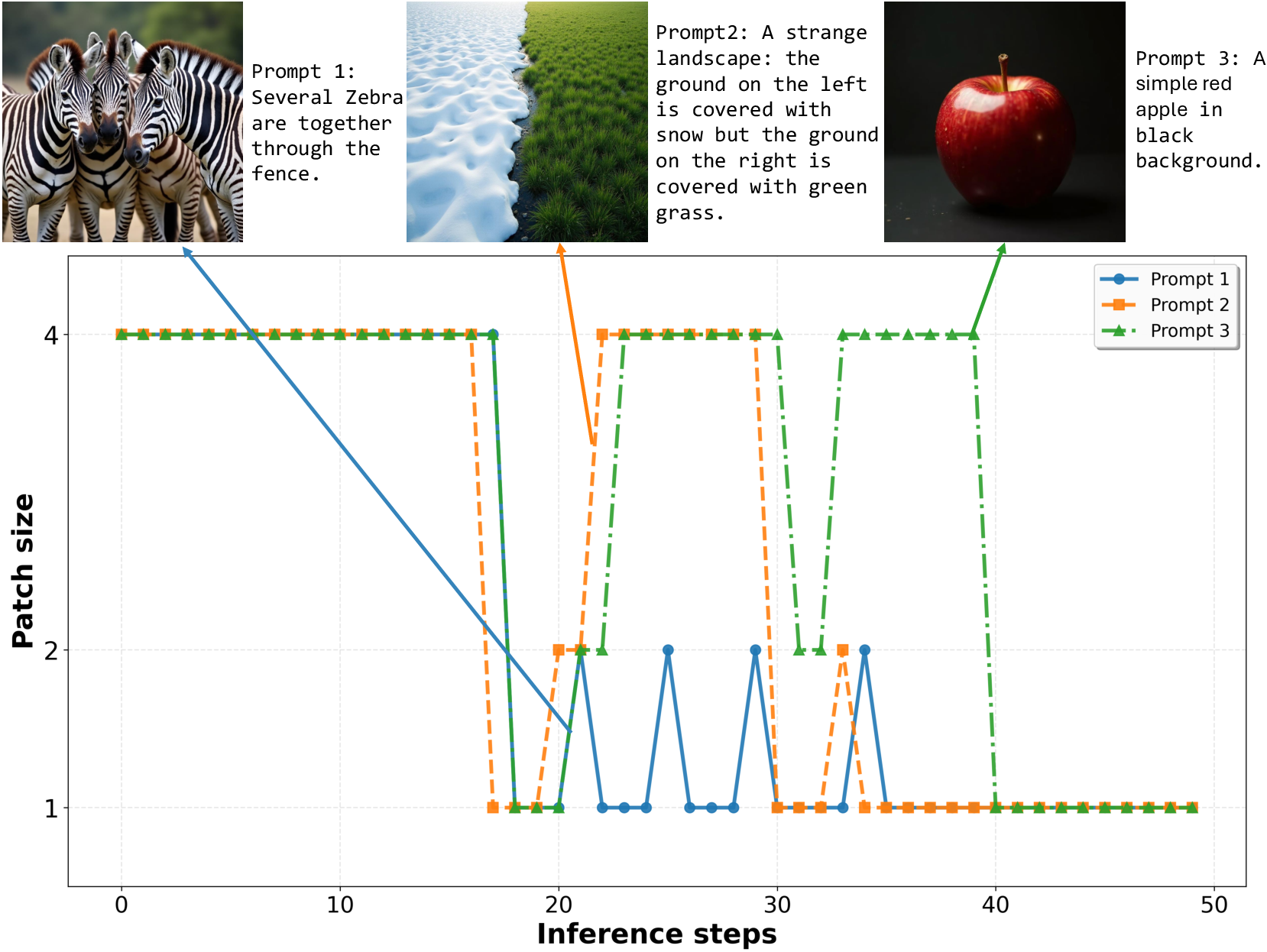
- The system adapts to the prompt: simple scenes (like “a red apple on a black background”) use big patches more often; complex scenes (like “many zebras”) automatically spend more time on small patches to keep stripes and textures sharp.
Why this matters:
- Faster generation means lower cost, less energy, and quicker results.
- It helps long video generation by fitting more content into the same compute budget.
- It doesn’t permanently throw away parts of the model (unlike some pruning methods). Instead, it smartly adjusts effort step by step and per prompt.
- It stacks with other speed‑up tricks like caching for even bigger gains.
5) What’s the impact and what could come next?
This work shows that “one size fits all” is not the best way to run diffusion models. By adapting patch size during generation, we can save a lot of time without sacrificing looks or faithfulness to the prompt. That makes high‑quality image and video creation more practical on regular hardware and for longer content.
Possible next steps:
- Use different patch sizes in different parts of the image at the same time (not just per step). That could squeeze out even more speed while keeping tiny details sharp exactly where they matter most.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research:
- Spatial adaptivity is only across timesteps, not within a timestep; the method uses a single global patch size per denoising step. Investigate spatially varying patch sizes within the same timestep (region-wise or token-wise adaptation) and mechanisms to avoid artifacts at patch boundaries.
- Supported patch sizes are limited to integer multiples of the base size (e.g., 2p, 4p). Explore a broader patch-size set, including smaller-than-p options, non-integer strides, and overlapping patches to reduce aliasing and boundary effects.
- The scheduler’s hyperparameters (threshold τ and percentile ρ) are empirically chosen and fixed. Develop an automatic, per-prompt or per-model calibration strategy and a predictable mapping between τ and speed/quality trade-offs (including target-speed controllers).
- The latent “acceleration” heuristic (third-order finite difference) lacks theoretical grounding and comprehensive sensitivity analysis. Test robustness across samplers (e.g., DDIM, DPM-Solver, ODE solvers), noise schedules, guidance scales, and different step counts.
- Computing third-order differences requires consecutive latents; the paper does not quantify the overhead, numerical stability, or compatibility with caching schemes. Measure the added compute/latency and design low-overhead proxies if needed.
- Positional embeddings are reused via bilinear interpolation without ablation. Compare alternative strategies (e.g., learned multi-resolution position encodings, rotary embeddings, patch-size-conditioned PE) and quantify their impact on quality and stability.
- Architectural changes require fine-tuning (LoRA adapters and new patch embedding/de-embedding layers); the “test-time strategy” claim is qualified. Report training cost (time/compute), data scale, and investigate zero-shot alternatives (e.g., prompt-only calibration or weight-free adapters).
- Distillation objective uses L2 between noise predictions; its adequacy for distribution matching is unclear. Compare against stronger objectives (e.g., path consistency, score-matching distillation, perceptual losses) and measure effects on prompt adherence and diversity.
- Fine-tuning is performed on synthetic data from the base models, risking feedback bias. Evaluate on real datasets, diverse and rare prompts, and out-of-distribution content to assess generalization and bias amplification.
- Generality is demonstrated on FLUX-1.Dev and Wan-2.1 only. Validate on a broader set of DiTs (e.g., SDXL, HunyuanVideo, Stable Video Diffusion, SVD), and across modalities (audio, 3D/NeRF) to confirm applicability and limitations.
- Scalability to high resolutions (e.g., 2K/4K images) and much longer videos is not characterized. Provide detailed memory and throughput profiles, analyze speed/quality scaling, and hardware dependence (A100 vs. 4090 vs. consumer GPUs).
- Human evaluation details (sample size, statistical significance, prompt diversity) are not reported, and no user study is provided for video. Conduct larger-scale, controlled studies (including video) to validate perceptual equivalence claims.
- Failure cases are not analyzed. Identify prompts/scenes where dynamic patching degrades detail (e.g., dense textures throughout) and develop safeguards (e.g., hysteresis or floor schedules to avoid premature coarsening).
- Interaction with other accelerations is assessed only with TeaCache. Systematically study compatibility and cumulative benefits/conflicts with pruning, quantization, KV cache reuse, distillation, and step-reduction methods.
- Impact on controllability and conditioning is unexplored. Evaluate effects on ControlNet, IP-Adapter, mask-based editing, regional guidance, negative prompts, and fine-grained attribute control, where coarse patches may harm precision.
- Video-specific scheduling details are under-specified (per-frame vs. global scheduling; spatial vs. temporal patching). Quantify temporal consistency, flicker, motion stability under patch-size transitions, and explore spatiotemporal patch scheduling.
- Patch-size switching may induce distribution shifts between steps. Analyze transition-induced artifacts and test smoothing/annealing strategies (e.g., hysteresis thresholds, gradual patch-size ramps).
- The variance proxy (per-patch std of latent acceleration) is one of many possible signals. Compare against alternative complexity indicators (e.g., cross-attention entropy, token importance scores, SNR, gradient norms) and assess correlation with human-perceived detail.
- Internal mechanism is not probed. Inspect attention maps, token interactions, and feature evolution under coarse-vs-fine phases to understand what computation is saved and when quality risks arise.
- Memory and throughput trade-offs are not fully reported. Quantify GPU memory changes, kernel efficiency, and variance across hardware; include the cost of difference computations and percentile aggregation.
- Reproducibility and stability across random seeds and stochasticity are not analyzed. Report variance in metrics under multiple seeds and prompts and provide guidelines for robust scheduler configuration.
- The mapping between τ, ρ, and quality/speed is model-dependent but not characterized. Provide calibration curves per model/resolution to enable practitioners to pick informed settings.
- Code, pretrained adapters, and detailed implementation for patch-embedding initialization are not indicated. Release artifacts and document reproducible pipelines to enable adoption.
- Learned scheduling is not explored. Investigate reinforcement learning/meta-learning to train a policy that optimizes speed-quality trade-offs conditioned on prompt/model/state, potentially outperforming fixed heuristics.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can adopt the paper’s method (DDiT: Dynamic Patch Scheduling) with modest engineering effort, leveraging its plug-in LoRA adapters, test-time scheduler, and compatibility with existing DiT-based image/video models.
- Sector: Cloud AI and Model Hosting
- Use case: Increase throughput and cut inference cost for text-to-image/video APIs without quality loss.
- Product/workflow: “Budget-aware generation API” that exposes a speed–quality slider mapped to DDiT’s threshold τ and percentile ρ; server-side integration with caching (e.g., TeaCache) for compounding 3.2–3.5× speedups.
- Why enabled by DDiT: Test-time dynamic patch sizes with minimal architectural changes and LoRA fine-tune; prompt/timestep adaptivity keeps quality stable.
- Assumptions/dependencies: Access to patch-embed/de-embed layers, LoRA fine-tuning set-up, license to modify host models (e.g., FLUX-1.Dev, Wan-2.1), online A/B safety checks for visual regressions.
- Sector: Creative Studios, VFX, Animation, Media
- Use case: Faster previsualization (previz), storyboard/animatics, shot exploration; quicker turnarounds on style/look development.
- Product/workflow: “Preview mode” (coarser patches early timesteps) and “Finalize mode” (finer patches late timesteps) in DCC tools (Blender/Unreal/Nuke) plug-ins.
- Why enabled by DDiT: Up to 3.5× speed with perceptual parity; coarse-to-fine align with creative iteration cycles.
- Assumptions/dependencies: Integration into studio pipelines, GPU support (consumer RTX-class is sufficient), content quality QA gates.
- Sector: Advertising/Marketing
- Use case: High-volume creative versioning, A/B test generation, dynamic personalization at scale.
- Product/workflow: Batch-generation orchestration that routes “simple” prompts to coarser schedules (lower cost), “complex” prompts to finer ones (quality-first).
- Why enabled by DDiT: Prompt-dependent adaptivity using latent evolution signal; keeps alignment (CLIP/ImageReward) competitive.
- Assumptions/dependencies: Prompt taxonomies/complexity heuristics, brand safety checks, governance over synthetic asset usage.
- Sector: E-commerce/Retail
- Use case: Product imagery/lifestyle variants, background swaps, seasonal refreshes at lower cost.
- Product/workflow: CMS-integrated generation with SLA-aware scheduling (τ controls per-job budget).
- Why enabled by DDiT: Large cost savings for routine/simple prompts (e.g., “isolated product on plain background”) with preserved detail when needed.
- Assumptions/dependencies: SKU compliance rules, image moderation, compatibility with existing DAM systems.
- Sector: Social/Consumer Apps
- Use case: Low-latency story/meme creation, filters, style transfers, and avatars on mobile or edge servers.
- Product/workflow: On-device “quick preview then refine” UX; server fallback for final high-res render.
- Why enabled by DDiT: Patch-size scheduling reduces compute enough to support interactive latency budgets.
- Assumptions/dependencies: Efficient on-device DiT variants; memory footprint of patch-embed variants; battery/thermal constraints.
- Sector: Video Tools and Newsrooms
- Use case: Rapid T2V storyboarding and explainer video drafts.
- Product/workflow: News/education content tools with “fast draft” generation (coarser patches early) and selective re-render for keyframes.
- Why enabled by DDiT: Demonstrated T2V speedups with stable VBench scores; content-aware scheduling controls cost-quality.
- Assumptions/dependencies: Rights management for generated media; editorial review workflows.
- Sector: Synthetic Data for ML (Robotics, Autonomy, Vision)
- Use case: Cost-effective generation of labeled synthetic images/videos for training/perception benchmarks.
- Product/workflow: Data factories that apply adaptive schedules to meet dataset targets under fixed compute budgets.
- Why enabled by DDiT: Better sample-per-dollar for large corpora; preserves fidelity/alignment that affect downstream model utility.
- Assumptions/dependencies: Validation that DDiT outputs meet domain fidelity requirements; bias monitoring; license terms for synthetic-to-train.
- Sector: Game Development
- Use case: Procedural asset and texture ideation, environment blockouts, cutscene draft generation.
- Product/workflow: Engine-integrated tool (Unity/Unreal) with “frame/scene budget controller” tied to τ; real-time previews for level designers.
- Why enabled by DDiT: Timesteps with coarse patches slash attention cost (O(N2) in token count) without disrupting final look refinement.
- Assumptions/dependencies: Toolchain integration; asset pipeline acceptance tests; IP policies.
- Sector: Education and Training
- Use case: Faster creation of lecture visuals, worksheets, and explainer videos.
- Product/workflow: LMS plug-ins offering low-cost bulk generation; quick preview → refine loop.
- Why enabled by DDiT: Maintains clarity while reducing render time for common “simple” visuals.
- Assumptions/dependencies: Content moderation, accessibility (alt-text), licensing for classroom use.
- Sector: Research/Academia
- Use case: Studying denoising dynamics; benchmarking variable compute schedules across prompts.
- Product/workflow: Open-source Diffusers extension implementing DDiT scheduler; diagnostic dashboards plotting latent acceleration statistics and chosen patch sizes over time.
- Why enabled by DDiT: Third-order finite-difference signal correlates with detail emergence; new analytic handle on denoising phases.
- Assumptions/dependencies: Access to intermediate latents; reproducible seeds; compatible samplers.
- Sector: Cloud/SRE/FinOps
- Use case: SLA- and cost-aware autoscaling for generative services; carbon reduction targets.
- Product/workflow: Policy that defaults to coarser schedules under load spikes; τ tuned by SLO; per-request budget capping.
- Why enabled by DDiT: Direct knob (τ, ρ) to trade quality vs. speed in real time.
- Assumptions/dependencies: Real-time quality monitors (CLIP/ImageReward proxies), rollback on distribution shifts.
- Sector: Policy and Sustainability Offices (within orgs)
- Use case: Reporting and governance for energy-efficient generative AI operations.
- Product/workflow: “Green GenAI” controls that mandate adaptive compute schedules; internal standards for energy-per-asset reporting.
- Why enabled by DDiT: Documented 2–3.5× speedups imply proportional energy savings under similar hardware.
- Assumptions/dependencies: Metering of GPU-hours/kWh; alignment with corporate sustainability frameworks.
- Sector: Regulated Industries (On-prem)
- Use case: Deploy generative tools within constrained hardware for privacy/security.
- Product/workflow: On-prem inference servers using DDiT to meet latency within limited compute envelopes.
- Why enabled by DDiT: Achieves target quality with smaller clusters.
- Assumptions/dependencies: Security review for LoRA/adapter training; data governance for any fine-tuning assets.
Long-Term Applications
The following use cases are enabled by the paper’s ideas but require further research, engineering, or ecosystem maturation (e.g., broader model support, spatially adaptive patching, or tighter systems integration).
- Sector: AR/VR and Real-Time Co-Creation
- Use case: On-device real-time T2I/T2V generation for AR glasses or VR co-creative assistants.
- Product/workflow: Latency-critical “coarse-first, refine-on-demand” pipelines that adapt schedule to gaze/scene dynamics.
- Dependencies: More aggressive stacking with quantization/sparsity; spatial adaptivity within a timestep; specialized NPUs.
- Sector: Spatially Adaptive Generation (within a timestep)
- Use case: Per-region token granularity (small patches for faces/text, large for skies/backgrounds) in the same denoising step.
- Product/workflow: Content-aware tokenization map predicted per step; hybrid attention kernels handling variable token grids.
- Dependencies: New routing modules, training/fine-tuning for stability, scheduling safety against artifacts at region boundaries.
- Sector: Long-Form Video and Storytelling
- Use case: Minutes-long video generation within fixed compute budgets.
- Product/workflow: Narrative-aware schedulers that dynamically allocate fine detail patches to important shots/scenes only.
- Dependencies: Temporal consistency modules, memory-efficient attention, dataset curation for long-range coherence.
- Sector: Multimodal Expansion (Audio, 3D, Scientific Simulation)
- Use case: Adaptive tokenization for audio diffusion (variable time windows), 3D/mesh/NeRF diffusion (variable spatial granularity), or physical simulators.
- Product/workflow: Modality-specific schedulers using analogous “latent acceleration” signals; multi-resolution tokenizers.
- Dependencies: New embeddings and losses per modality; perceptual metrics per domain.
- Sector: Self-Tuning and RL-Driven Schedulers
- Use case: Autonomous τ/ρ controllers optimizing for user-specified objectives (cost, quality, latency) and content type.
- Product/workflow: RL or Bayesian controllers that learn to predict patch schedules from prompt embeddings and early-step latents.
- Dependencies: Online feedback loops; robust reward proxies; safeguards against mode collapse or “gaming” metrics.
- Sector: Foundation-Model Integration and Standards
- Use case: “Adaptive compute compliance” settings shipping with DiT family models; standard APIs to expose patch-scheduling hints.
- Product/workflow: Model cards including energy/latency profiles under schedules; industry benchmarks for adaptive generation.
- Dependencies: Vendor buy-in; open standards for logging and reporting schedule choices and quality outcomes.
- Sector: Edge/Federated Collaborative Generation
- Use case: Split the denoising across edge and cloud, with coarse early steps local and fine refinement in the cloud.
- Product/workflow: Federated scheduler that moves computation based on bandwidth/latency; secure latent hand-off.
- Dependencies: Privacy-preserving latent protocols; robust resume semantics across heterogeneous devices.
- Sector: Hardware/Systems Co-Design
- Use case: Token-dynamic accelerators that efficiently handle variable sequence lengths within and across steps.
- Product/workflow: Attention engines with elastic batching; scheduler-aware memory controllers.
- Dependencies: Compiler/runtime support for dynamic token counts; kernel libraries tuned for changing patch sizes.
- Sector: Safety and Auditability
- Use case: Risk controls ensuring adaptive schedules do not bypass watermarking, safety filters, or text legibility.
- Product/workflow: Audit trails logging schedule choices; differential re-checks on “sensitive” prompts forcing finer patches.
- Dependencies: Safety-evaluation suites accounting for schedule changes; policy mapping of prompt categories to minimum granularity.
- Sector: Healthcare and Scientific Imaging
- Use case: Energy-efficient synthetic medical image generation for research, augmentation, or training.
- Product/workflow: Labs with limited compute generate controlled datasets; schedule presets for high-fidelity anatomical regions.
- Dependencies: Strict clinical validation; bias and artifact audits; regulatory approvals; domain-specific VAEs/DiTs.
- Sector: Finance and Enterprise Comms
- Use case: Low-cost generation of explainers, dashboards, and internal learning content (video briefs).
- Product/workflow: Enterprise content platforms using adaptive schedules tuned to compliance and brand standards.
- Dependencies: Content approval workflows; model governance; documented quality controls.
Cross-cutting Assumptions and Dependencies
- Model access and compatibility: DDiT was demonstrated on FLUX-1.Dev (T2I) and Wan-2.1 (T2V); other DiTs should work but require adding patch-embed/de-embed variants and LoRA adapters.
- Fine-tuning needs: Lightweight LoRA fine-tuning with distillation is required to support new patch sizes; training data availability (synthetic is acceptable in the paper).
- Scheduler tuning: τ and ρ must be tuned to the deployment’s target speed/quality; monitoring (CLIP/ImageReward/SSIM/LPIPS or human-in-the-loop) is recommended.
- Runtime implications: Third-order finite differences imply a small temporal window/buffering of latents within the sampler; ensure sampler/runtime supports it.
- Legal/ethical: Respect model licenses, data usage policies, and safety constraints; ensure watermarking, moderation, and IP policies are not weakened by adaptive schedules.
- Systems integration: Kernel performance for variable token counts, memory reuse, and caching interop (e.g., TeaCache) affect realized speedups; continuous profiling is needed.
- Generalization limits: While the paper shows negligible quality loss on benchmarks, domains with highly intricate micro-structure (e.g., dense text, medical scans) may need stricter thresholds or fallback to static fine patches.
Glossary
- Attention mechanism: The component in transformers that computes dependencies between tokens to focus on relevant information. "The attention mechanism learns to attend to relevant patches by computing pairwise dependencies among all patches."
- Bilinear interpolation: A resampling method that interpolates values across a 2D grid by linear interpolation in each dimension. "We reuse the learnt positional embeddings of the original patch size for $p_{\text{new}$ by bilinearly interpolating them for the new patch size."
- CLIP score: A metric that measures text–image alignment using a joint language–vision embedding model. "using CLIP score and ImageReward~\cite{xu2023imagereward} to measure textâimage alignment"
- De-embedding: The inverse operation of patch embedding that maps token embeddings back to spatial feature maps. "we add a residual connection from before the patch embedding layer to after the patch de-embedding block."
- Diffusion Transformer (DiT): A generative model that performs diffusion-based denoising using transformer architectures. "Diffusion Transformers (DiTs) have achieved state-of-the-art performance in image and video generation"
- Distillation loss: A training objective that transfers knowledge from a teacher model to a student model. "The distillation loss is:"
- FID (Fréchet Inception Distance): A metric that quantifies the visual quality of generated images by comparing feature distributions to real images. "we use the COCO dataset~\cite{lin2014microsoft} to compute CLIP~\cite{hessel2021clipscore, radford2021learning} and FID~\cite{heusel2017gans} scores against real images"
- Finite difference: A numerical method that approximates derivatives by using discrete differences across timesteps. "We employ finite-difference approximations of increasing order to quantify how latent representations evolve during the denoising process."
- Guidance scale: A hyperparameter controlling the strength of conditioning (e.g., text prompt) during generation. "using 50 inference steps and a guidance scale of 3.5 for the text-to-image task"
- ImageReward: A learned metric that scores images for perceived quality and prompt adherence. "ImageReward, {CLIP}, and {VBench} scores are reported (higher is better)."
- Knowledge distillation: A technique to compress models by training a smaller model to mimic a larger one. "Knowledge distillation methods~\cite{salimans2022progressive, li2023snapfusion, kim2024bk, zhang2024accelerating, feng2024relational, zhu2024accelerating, chen2025snapgen, park2025inference} achieve efficiency by compressing complex models into smaller version using distillation objectives~\cite{hinton2015distilling}."
- Latent manifold: The geometric structure of the latent space that evolves during denoising and encodes generative complexity. "We provide a detailed analysis of the rate of latent manifold evolution to generative complexity"
- Latent representation: The compressed feature map produced by an encoder (e.g., VAE) that serves as the input to the diffusion model. "a latent representation "
- LPIPS (Learned Perceptual Image Patch Similarity): A metric that measures perceptual similarity between images using deep network features. "SSIM~\cite{wang2004image} and LPIPS~\cite{zhang2018unreasonable} to assess structural similarity with the base model."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that adds low-rank adapters to layers. "we retain the base model originally trained on the latent patch size and introduce a Low-Rank Adaptation (LoRA) branch~\cite{hu2022lora} into \underline{each} transformer block in DiT."
- Patch embedding layer: The layer that tokenizes image or latent patches by projecting them into a fixed-dimensional embedding. "we adapt the patch embedding layer, originally operating on patch size , to also handle new patch sizes $p_{\text{new}$"
- Patchify operation: The process of dividing a spatial feature map into non-overlapping patches prior to tokenization. "patch embedding and de-embedding layers for the patchify operation"
- Percentile-based aggregation: A robust summary method using a chosen percentile of per-patch statistics to avoid averaging out important signals. "This percentile-based aggregation allows us to capture meaningful information across patches without averaging out important signals"
- Positional embeddings: Learned vectors added to tokens to encode their spatial positions. "We reuse the learnt positional embeddings of the original patch size for $p_{\text{new}$"
- Prodigy optimizer: An optimization algorithm that automatically tunes learning rates during training. "We use Prodigy~\cite{mishchenko2023prodigy}, an optimizer that automatically finds the optimal learning rate without requiring manual tuning"
- Pseudo-inverse: A generalized matrix inverse used for initializing weights to preserve functional behavior under projection. "using the pseudo-inverse of the bilinear-interpolation projection"
- Quantization-based methods: Techniques that reduce precision of weights/activations (e.g., to 8-bit) to accelerate inference and lower memory. "Quantization-based methods~\cite{shang2023post, so2023temporal, tian2024qvd, deng2025vq4dit,dong2025ditas, chen2025q, li2024svdquant, fan2025sq} improve efficiency by converting model weights and activations from high-precision to low-precision representations, such as 8-bit integers~\cite{dettmers2023qlora}."
- SSIM (Structural Similarity Index): A metric that assesses structural similarity between images, often used to compare outputs to a baseline. "SSIM~\cite{wang2004image} and LPIPS~\cite{zhang2018unreasonable} to assess structural similarity with the base model."
- Tokenization (dynamic tokenization): Converting patches into tokens for transformer processing; in this work, adapted dynamically across timesteps. "Main idea: dynamic tokenization during denoising."
- Variational Autoencoder (VAE): A generative model whose encoder maps images to a latent space and decoder reconstructs images from latents. "DiTs operate in the latent space of a pre-trained variational autoencoder (VAE)~\cite{rombach2022high}."
- VBench: An evaluation benchmark for text-to-video quality and consistency. "we adopt VBench~\cite{huang2024vbench} and follow the evaluation protocol proposed in their work."
- Vision Transformer (ViT): A transformer architecture applied to image patches for vision tasks. "Built upon the Vision Transformer (ViT) architecture~\cite{dosovitskiy2020image}, DiTs operate in the latent space of a pre-trained variational autoencoder (VAE)~\cite{rombach2022high}."
Collections
Sign up for free to add this paper to one or more collections.