- The paper introduces rigorous risk bounds that decompose prediction errors into approximation, stochastic, and optimization components.
- GNN architectures using graph convolutions paired with deep ReLU networks can effectively approximate compositional target functions with controlled propagation depths.
- Empirical results validate the theoretical MSE scaling, emphasizing the significance of label efficiency and managing the receptive field in graph structures.
Semi-Supervised Learning on Graphs with Graph Neural Networks: Statistical Theory, Approximation, and Rates
Overview and Motivation
This paper establishes a comprehensive statistical foundation for semi-supervised node regression on graphs using Graph Neural Networks (GNNs) (2602.17115). The work addresses a significant theoretical gap: empirical success of GNNs in settings where only a small fraction of node responses are labeled, despite lacking rigorous understanding of stochastic and approximation error contributions and their interaction with the underlying graph structure. The framework analyzed encompasses common GNN message-passing architectures, where node features are first propagated through graph-structured filters before transformation by nonlinear readouts (e.g., deep neural networks).
Problem Setup and Modelling Framework
The authors formalize the node regression problem under partial supervision as follows: Given a graph G=(V,E) of n nodes, each with feature Xi, and observed responses Yi on a random subset Ω (with fraction π labeled), the goal is to predict responses at unobserved nodes. The statistical model posits a two-stage structure:
- Propagation: ψA∗ encodes graph-based feature aggregation, expressed either as exact/approximate polynomial functions of a graph operator (adjacency or Laplacian).
- Nonlinear Readout: A Hölder-smooth multivariate function φ∗ synthesizes the propagated features into node-level predictions.
This compositional model captures both local (feature- and neighborhood-based) and global graph effects.
Main Theoretical Contributions
The central results rigorously decompose the prediction error for GNN-based estimators into approximation, stochastic, and optimization components, with explicit dependence on the labeled node fraction π, graph receptive field size m, and function class complexity.
1. Oracle Inequality for Prediction Error
Theorem 1 (Oracle Inequality) provides upper and lower non-asymptotic risk bounds for general estimators based on:
- The best-in-class approximation of the ground truth regression function by the GNN model class;
- Stochastic error, controlled by metric entropy and the effective sample size πn;
- Optimization error, quantifying suboptimality with respect to empirical risk minimization.
The influence of graph structure enters via the receptive field parameter m: the risk scales as m2/π, quantifying how graph-induced dependency compounds the impact of limited supervision.
2. Approximation Theory for GNNs with Linear Graph Convolutions
The analysis shows that GNNs with k-layer linear graph convolutions paired with deep ReLU networks can approximate the target composed function arbitrarily well, provided the propagation matches the generative process and the DNN has sufficient width, depth, and sparsity. Approximation rates are governed by the intrinsic "compositional" smoothness and dimensionality of φ∗.
3. Non-Asymptotic Estimation and Convergence Rates
Theorem 2 (Convergence Rate) proves that, under suitable architectural scaling (with controlled GNN depth and appropriate DNN complexity relative to n), the least-squares risk decays as
R(f^,f∗)≤Cπm2log3nimaxn−2αi∗/(2αi∗+ti)
where αi∗,ti are effectivesmoothness and dimensions from the compositional structure. For classical Hölder regression (q=0, t0=d), this matches minimax-optimal rates. The dependence on m2/π quantifies how dense graphs or large aggregation depths affect generalization in sparse-label regimes.
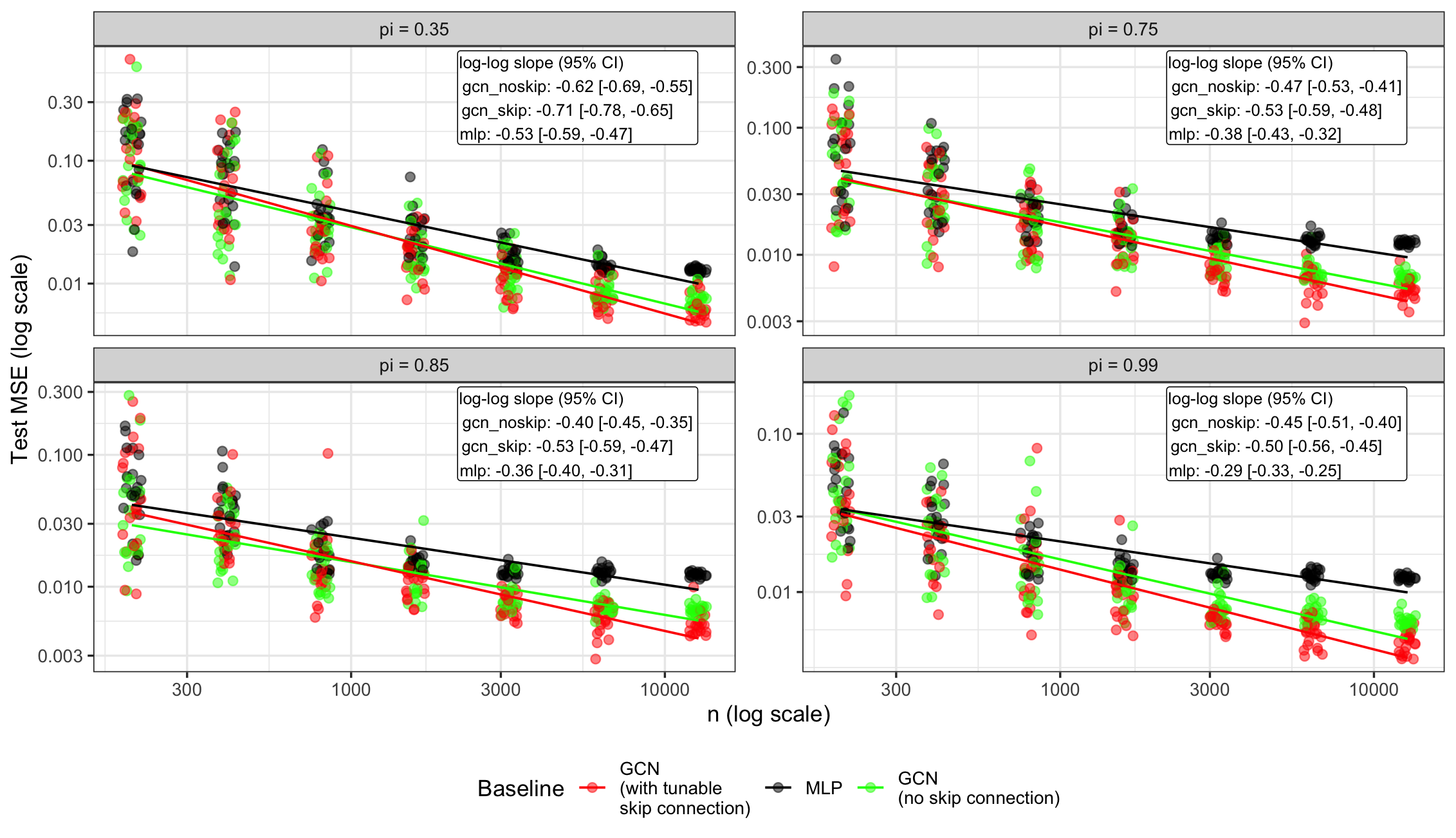
Figure 1: MSE (over 20 trials) as a function of training samples n and varying label fraction π, across GCNs (with/without skip connections) and the MLP baseline.
Empirical Validation: Scaling and Graph Topology Effects
Theoretical predictions are extensively validated using both synthetic and real-world datasets.
Sample Size and Label Proportion
As shown in Figure 1, the empirical test MSE exhibits the predicted n−1/2 decay for large label fractions, consistent with the established risk rates for α≈1/2,t=1. At very low π the rates deviate due to dominant optimization error or the failure of effective stochastic averaging.
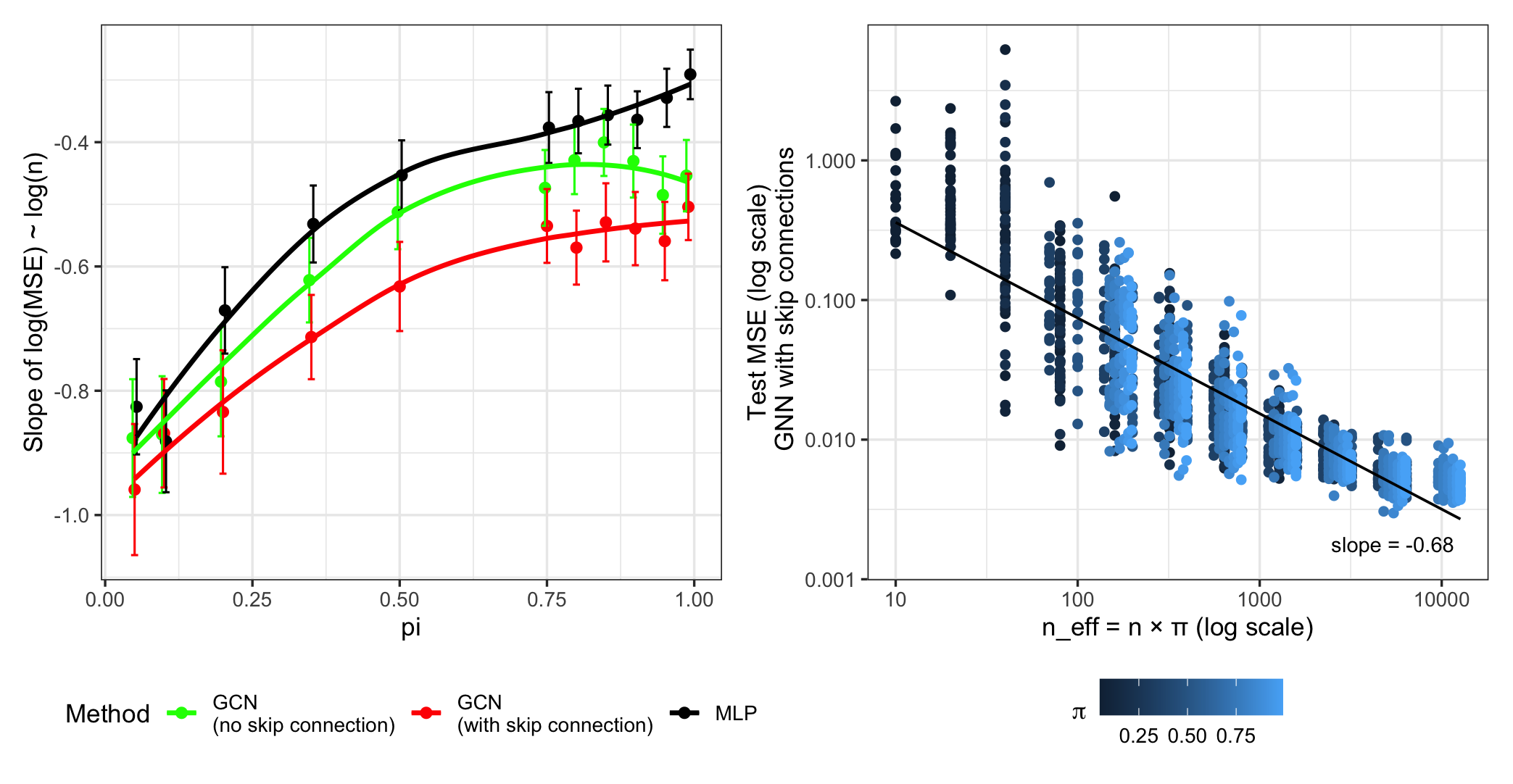
Figure 2: Fitted slopes of log(MSE) vs. log(n) as a function of π (left), and MSE as a function of effective sample size neff=nπ (right).
Graph Topology and Receptive Field
Experiments on a variety of random graph models (Erdős–Rényi, stochastic block models, random geometric graphs, Barabási–Albert) demonstrate that:
- The dominant effect is the size of the receptive field (m), particularly the maximal degree and propagation depth.
- Degree-normalized convolution operators (as in standard GCNs) substantially mitigate the deleterious effect of high-degree nodes compared to sum aggregators, confirming the theoretical prediction that m2 can be drastically smaller for sparse/regular graphs.
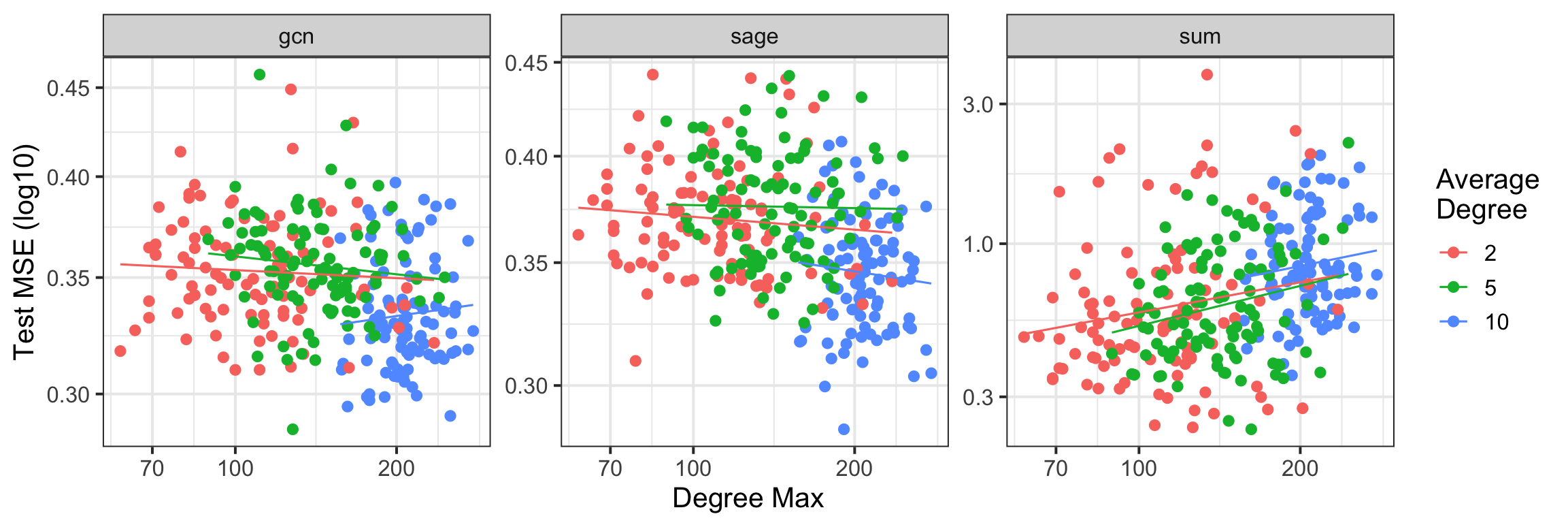
Figure 3: Performance (MSE) of the GCN with skip connection as a function of the graph's maximum degree and convolution type (sum, mean, GCN), across Barabási–Albert graphs.
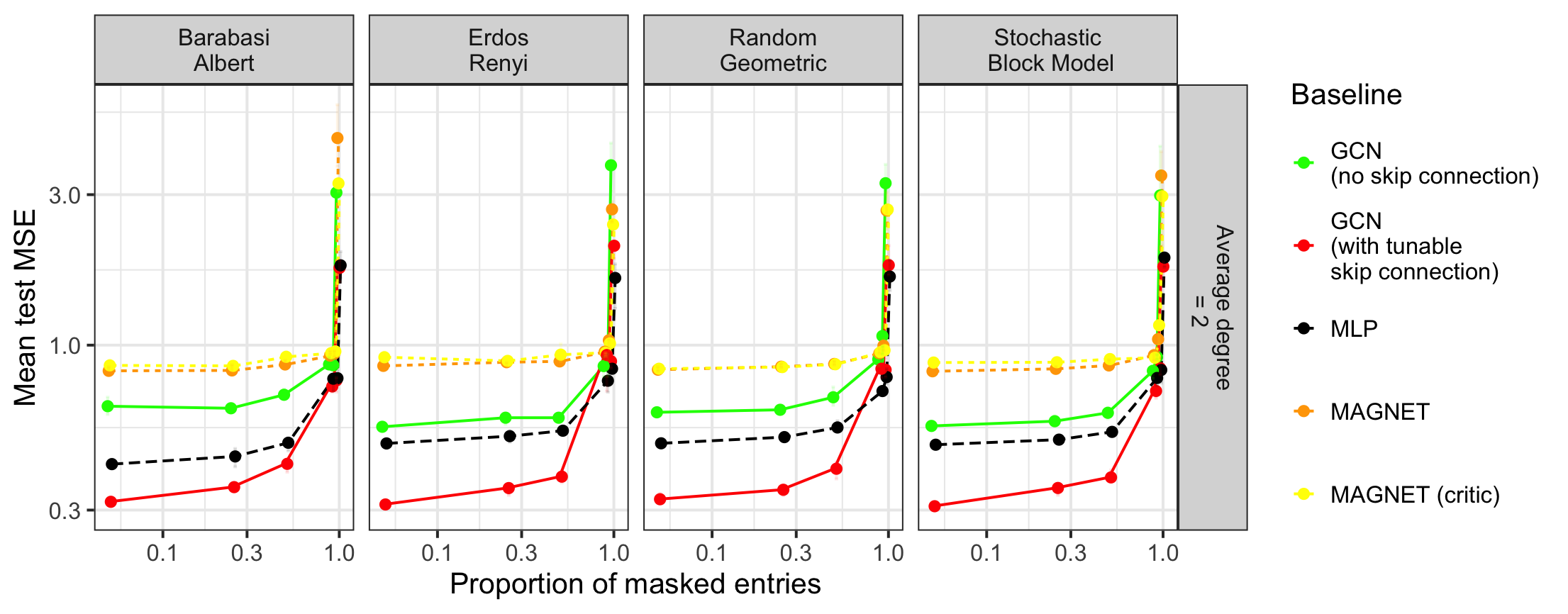
Figure 4: Performance of baselines as a function of π and graph type, for various architectures. Averaged over 5 runs, fixed GCN layers and average degree.
Real-World Graphs
On datasets such as California Housing and Wikipedia Chameleon, GNNs with degree-averaged diffusion outperformed MLPs and classical Laplacian regularization, unless feature graphs were extremely homophilic (where both Laplacian and GNN performed similarly with high π).
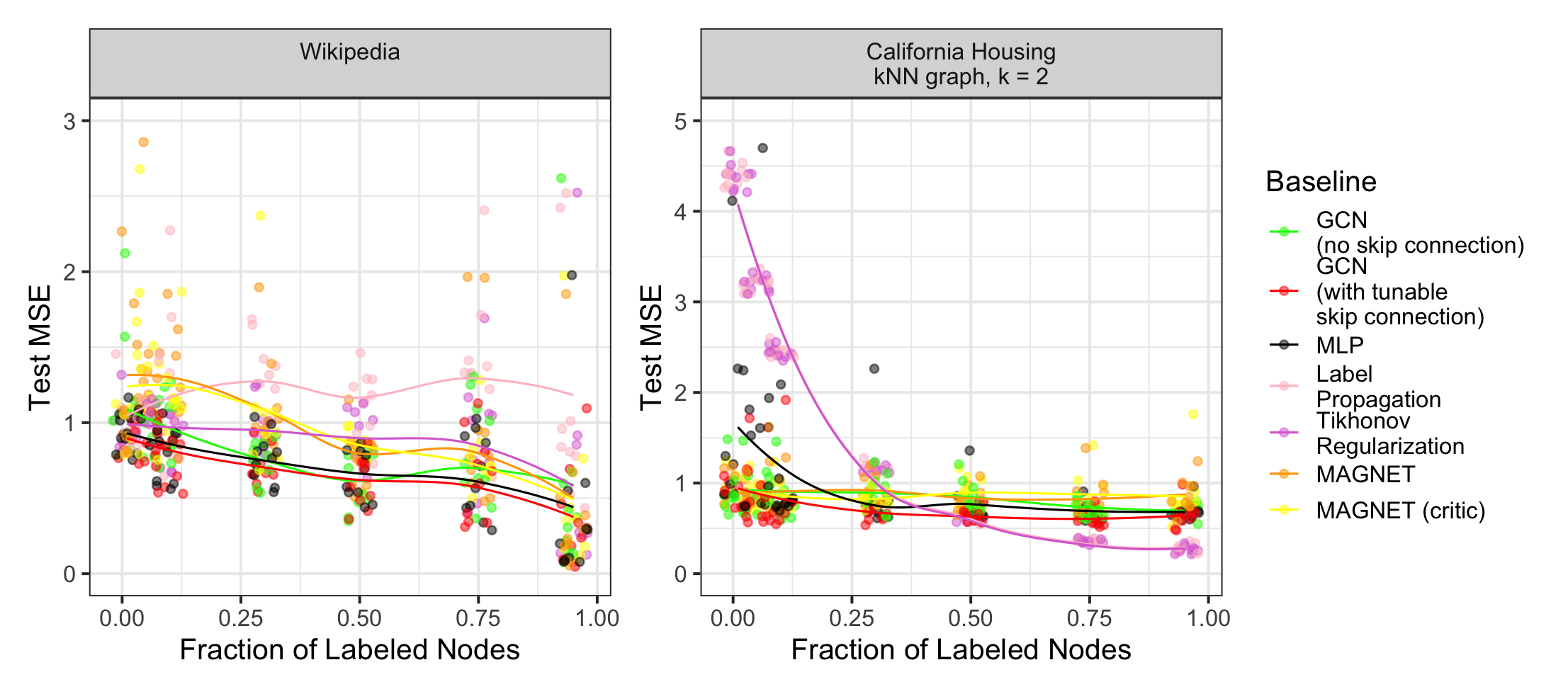
Figure 5: Test performance on California Housing and Wikipedia datasets as a function of label fraction, comparing GNNs, MLPs, and classical graph smoothing.
Implications and Theoretical Insights
- Label-Efficient Regimes: The explicit 1/π scaling allows design of GNNs that remain robust even at drastic label sparsity, provided m is controlled.
- Graph Perturbations: The m2 factor explains empirical GNN instability to changes in high-degree nodes or graph densification, advocating for local propagators and receptive field normalization.
- Compositional Nonparametrics: The approximation theory demonstrates that GNNs can overcome curse-of-dimensionality when the nonlinear readout admits compositional (multi-stage) structure.
Limitations and Future Directions
- Optimization Error: Current results decouple statistical and optimization errors. Understanding the implicit bias of SGD and how graph structure shapes the optimization landscape is an open problem, especially under nonconvexity.
- Spectral Dependencies: While m is a coarse descriptor, incorporating spectral gap/conductance may yield sharper risk bounds for well-connected but sparsely labeled graphs.
- Learning Graph Structure: Extensions to settings where the graph is partially observed or learned in tandem with node regression represent a promising avenue.
Conclusion
This paper precisely characterizes the statistical risk and approximation behavior for semi-supervised learning with GNNs. The explicit risk decomposition, sharp rates, and corresponding empirical verification establish a foundation for principled architecture design—emphasizing local aggregation, careful propagation depth, and architectural control of model complexity. The work sets a clear stage for identifying optimization-theoretic and graph-topological factors influencing generalization in networked data, motivating future research at the intersection of nonparametric statistics, deep learning, and random graph theory.