Reverso: Efficient Time Series Foundation Models for Zero-shot Forecasting
Abstract: Learning time series foundation models has been shown to be a promising approach for zero-shot time series forecasting across diverse time series domains. Insofar as scaling has been a critical driver of performance of foundation models in other modalities such as language and vision, much recent work on time series foundation modeling has focused on scaling. This has resulted in time series foundation models with hundreds of millions of parameters that are, while performant, inefficient and expensive to use in practice. This paper describes a simple recipe for learning efficient foundation models for zero-shot time series forecasting that are orders of magnitude smaller. We show that large-scale transformers are not necessary: small hybrid models that interleave long convolution and linear RNN layers (in particular DeltaNet layers) can match the performance of larger transformer-based models while being more than a hundred times smaller. We also describe several data augmentation and inference strategies that further improve performance. This recipe results in Reverso, a family of efficient time series foundation models for zero-shot forecasting that significantly push the performance-efficiency Pareto frontier.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Reverso, a family of small, fast computer models that predict the future of time-based data, like weather or electricity use. The key idea is that you don’t need huge, expensive models to get strong forecasts. Reverso shows that carefully combining a few simple parts can match or beat much larger models while using far fewer computer resources.
What questions were the authors trying to answer?
- Can we build a general-purpose time series “foundation model” that makes good predictions on new data without extra training (this is called zero-shot forecasting)?
- Do we really need giant models with hundreds of millions of parameters, or can much smaller models perform just as well?
- Which simple design choices and training tricks actually matter for better forecasting?
How did they build their approach?
To understand the approach, think of a time series as a long list of numbers collected over time (like daily temperatures). The model looks at a window of past numbers and predicts the next chunk.
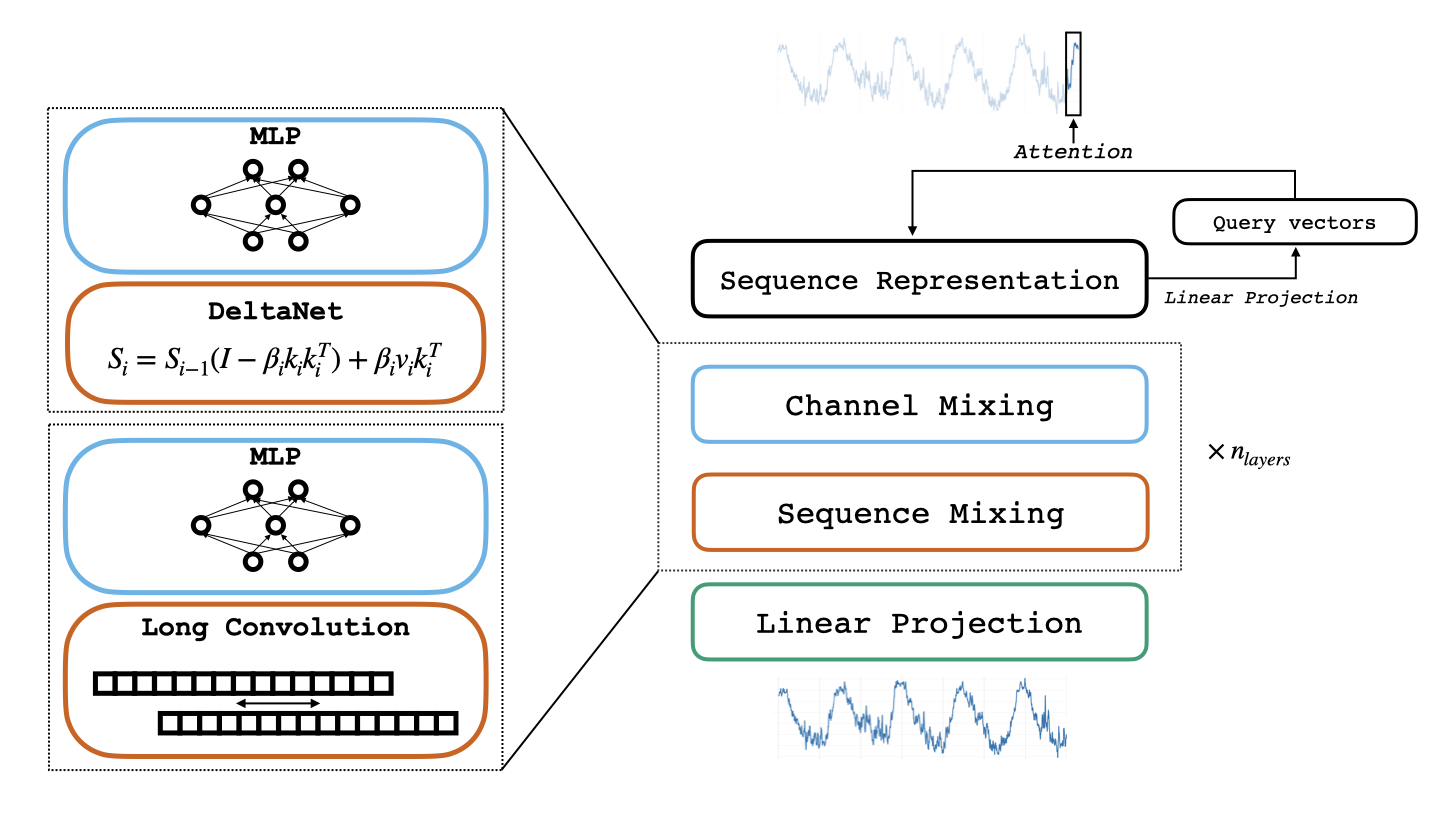
The model design (simple parts that work well together)
Reverso mixes two proven ideas for reading sequences:
- Long convolutions: Imagine sliding a very long ruler across the data to detect repeating patterns and rhythms. This helps the model “feel” seasonality and trends over long spans.
- Linear RNN layers (DeltaNet): Think of this like a neat notepad the model updates as it reads the sequence, keeping only the most useful bits of memory. It’s fast and efficient.
These two are stacked in alternating layers. After that, a small MLP (a simple neural network block) mixes information across features. Finally, a lightweight attention-based “head” decides how to turn the processed information into a batch of predictions.
A few practical choices:
- The model reads a context of about 2,048 past points and predicts 48 future points at a time, repeating this until it reaches the full forecast length.
- Inputs are scaled to the 0–1 range so the model sees similar value sizes across different series.
Why this matters: Transformers (a popular but heavy architecture) aren’t strictly necessary here. This hybrid design is much smaller and still strong.
Training data and making data more varied
The model is trained on a large, mixed collection of real time series (from the Gift-Eval dataset), such as weather and building sensors. But the data are imbalanced (some sources dominate), so the authors carefully sample to keep training fair across sources.
They also boost variety using:
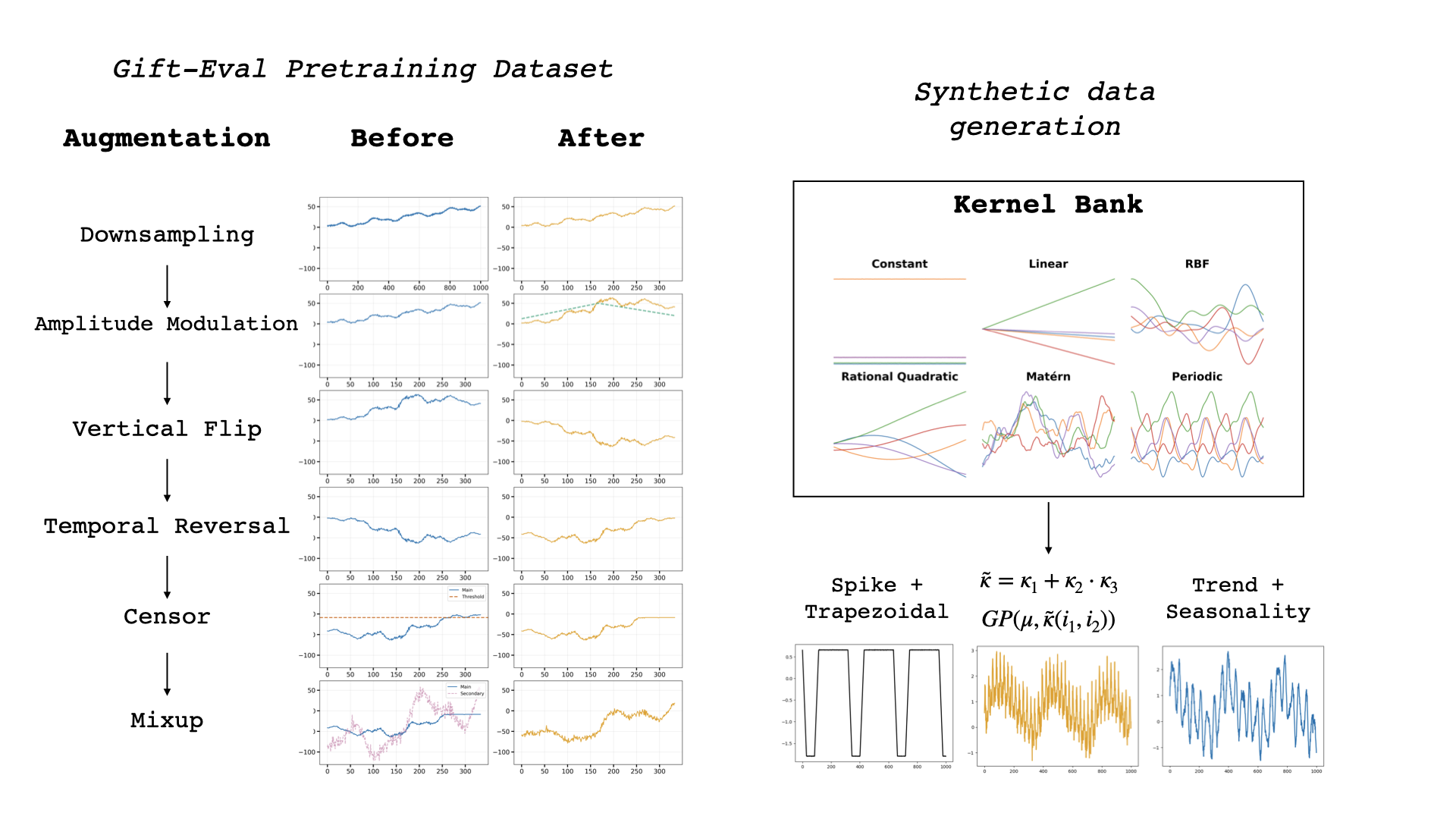
- Data augmentation: make slightly changed copies of the data (downsampling, flipping the time direction, changing amplitude, hiding parts, mixing series). This is like showing the model many realistic “views” of the same pattern so it generalizes better.
- Synthetic data: create believable fake series using tools like Gaussian processes (which are good at drawing realistic wavy patterns), plus simple patterns (spikes, trends, and seasonal cycles). This fills in gaps and teaches the model to recognize common shapes it might see later.
How the model makes predictions (helpful tricks at use-time)
Two simple tricks improve accuracy when the model predicts:
- Flip averaging (flip equivariance): Make predictions on the original series and on a “flipped” version (like reading forward and backward), then average the results. It’s like double-checking from two directions.
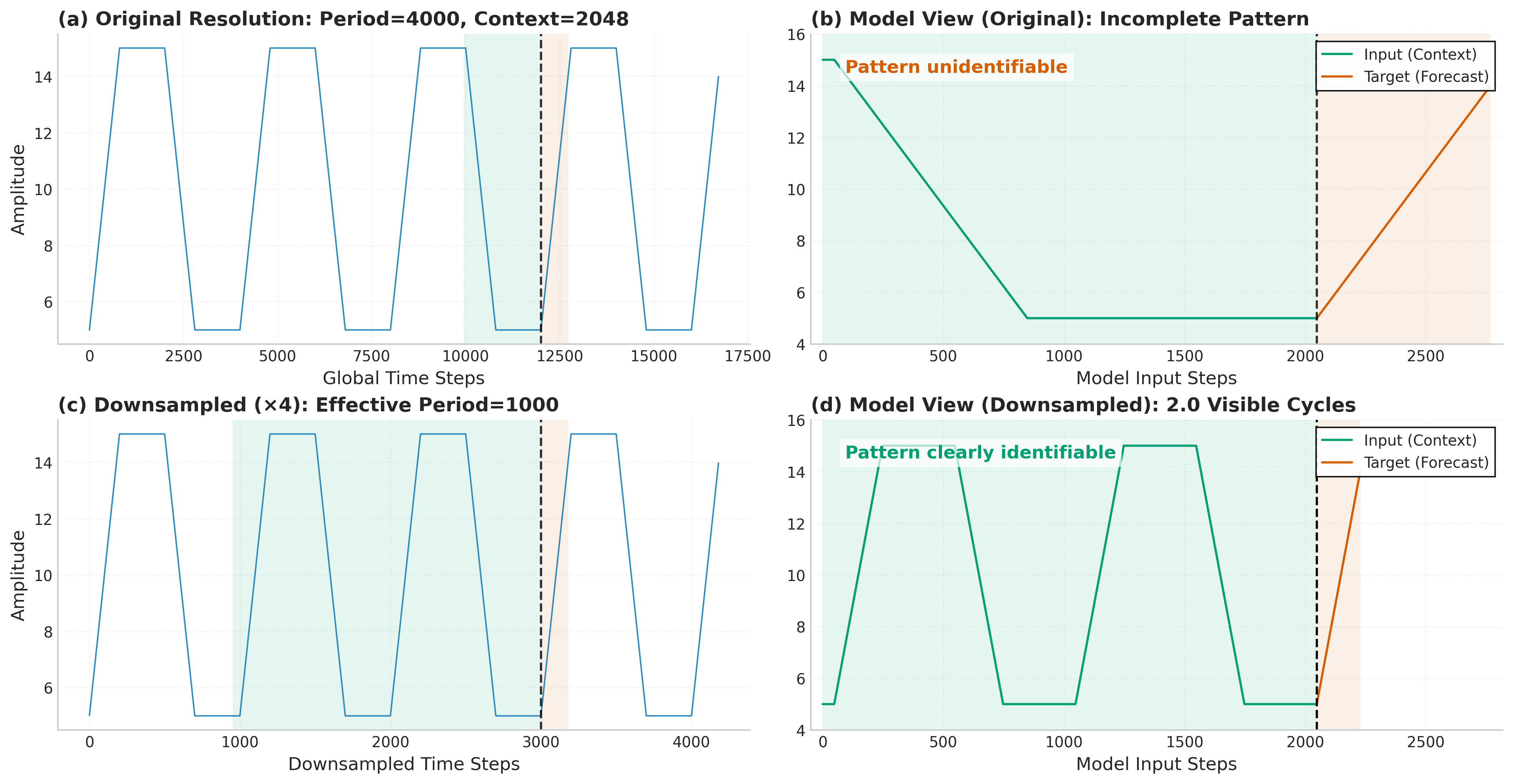
- Automatic downsampling: If the important repeating cycle in the data is longer than the model’s input window, the model first “speeds up” the view (downsamples), makes predictions, then “slows it back down” (upsamples). The model uses FFT (a method like turning a song into its list of beats and notes) to detect the main rhythm and choose a good downsampling rate.
What did they find?
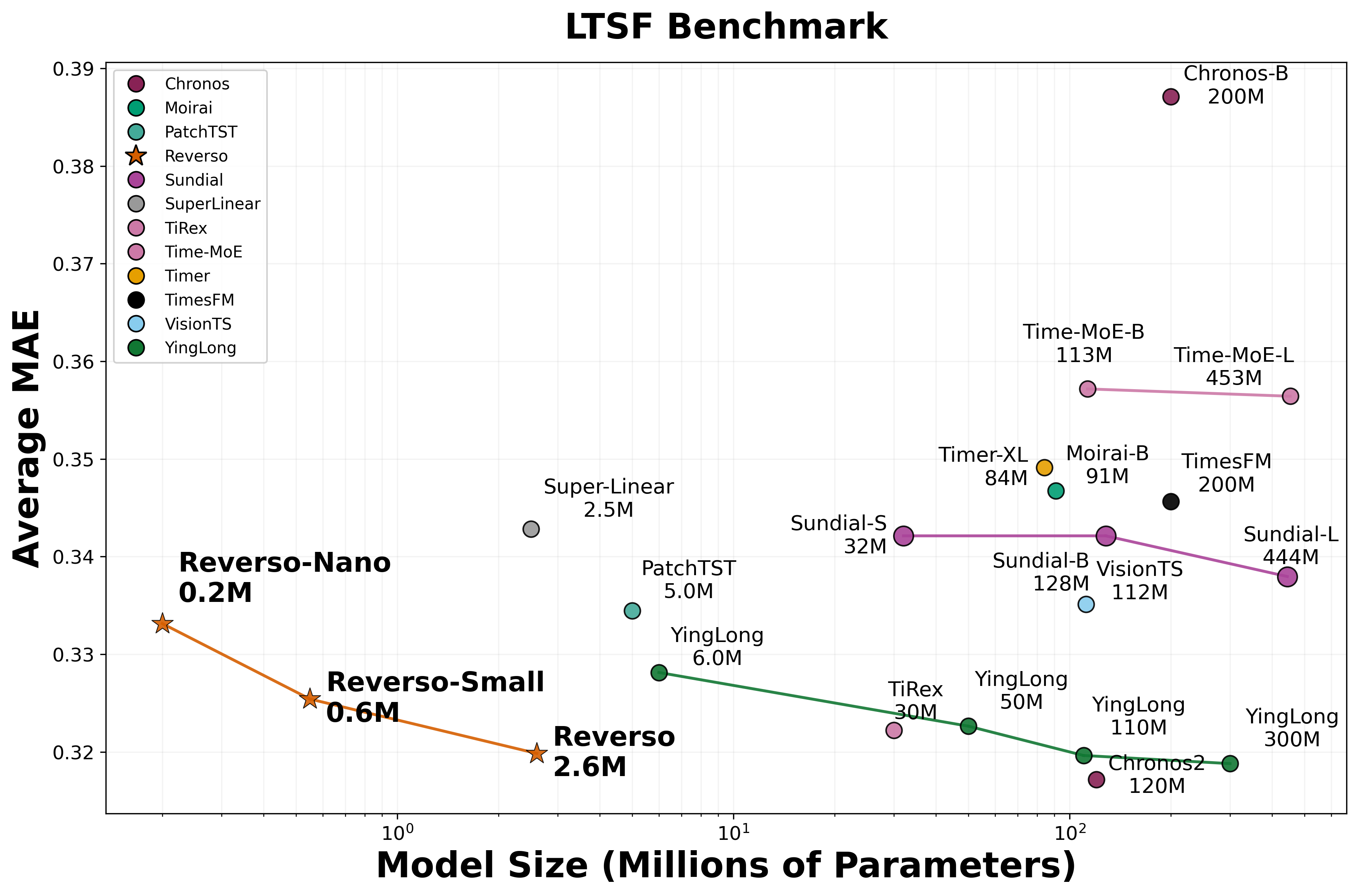
- Small can be powerful: Reverso models with about 0.2–2.6 million parameters match or beat models that are 100–1000 times larger on standard tests.
- Strong zero-shot forecasting: On Gift-Eval (a big benchmark), the largest Reverso (2.6M) achieved competitive error scores while staying tiny and fast. It is especially good at long-horizon forecasts (predicting far into the future).
- Good generalization: On another popular set of datasets (LTSF), Reverso competes with or outperforms many larger models.
- Simple choices matter: The hybrid of long convolutions + DeltaNet, the attention-based output head, plus data augmentation and synthetic data all contribute to better results. Inference tricks (flip averaging and downsampling) give consistent boosts too.
In short: You don’t need a giant transformer to get top-tier forecasts.
Why does this matter?
- Efficiency: Smaller models are cheaper to train and run, use less memory, and can be deployed on ordinary computers or edge devices.
- Accessibility: Organizations without massive computing budgets can still use high-quality forecasting.
- Practicality: Faster, lighter models are easier to maintain and less energy-intensive, which is better for sustainability.
Limitations and next steps
- Mostly univariate: Reverso focuses on one time series at a time. Handling many related series together (multivariate forecasting) is a next step.
- Short-horizon gap: Big models may still do slightly better on short-term predictions.
- Uncertainty estimates: The paper focuses on point predictions. Adding confidence ranges (uncertainty) would help real-world decision-making, though simple add-ons like conformal prediction could be applied.
Takeaway
Reverso shows that with the right recipe—long convolutions, efficient memory layers (DeltaNet), thoughtful data augmentation, a bit of synthetic data, and simple prediction tricks—you can build small, fast time series foundation models that forecast as well as much larger systems. This pushes the field toward practical, affordable forecasting tools that work well out of the box.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions in the Paper
The research paper on "Reverso: Efficient Time Series Foundation Models for Zero-shot Forecasting" presents significant advancements in efficient time series forecasting models. However, several areas remain unexplored or insufficiently addressed in the paper. Below is a list of specific knowledge gaps, limitations, and open questions:
Knowledge Gaps and Limitations
- Detailed Evaluation on Multivariate Forecasting: The paper primarily focuses on univariate time series forecasting. There is limited exploration of how the proposed models perform on multivariate datasets, which is essential given the growing importance of multivariate time series forecasting in real-world applications.
- Robustness to Noise and Missing Data: While the paper addresses missing data imputation during normalization, there is no comprehensive study on the robustness of the model to varying degrees of noise and missing data. Future research could benefit from a detailed analysis of the model's performance under such conditions.
- Scalability and Application to Very Large Datasets: The scalability of the Reverso models to very large datasets or real-time data streams is not thoroughly addressed. It would be valuable to understand the computational requirements and performance trade-offs when scaling to bigger datasets or deploying in real-time scenarios.
- Interpretability of Model Predictions: The paper lacks a discussion on the interpretability of the model outputs. Given the complexity of deep learning models, providing insights into how predictions are made is crucial, especially for critical applications in finance and healthcare.
- Comparison with State-space Models: Although the paper compares Reverso with several transformer-based models, there is limited comparison with state-space models which have shown strong performance in time series forecasting. A direct comparison could provide a more comprehensive evaluation of its relative strengths and weaknesses.
Open Questions
- Effectiveness of Data Augmentation Techniques: While the paper mentions various data augmentations, further investigation is needed into which specific augmentations most significantly contribute to improved performance. This could guide optimal augmentation strategies for similar tasks.
- Generalization to Other Domains: How well do the model and techniques generalize to domains not covered in Gift-Eval, such as healthcare or social sciences? Future work could explore the adaptability and transfer learning capabilities of the models in these domains.
- Potential for Hybrid Models: The paper explores hybrid models using long convolutions and RNN layers. An open question remains on whether further hybridization with other model architectures could yield even better performance, especially for diverse forecasting tasks.
- Integration of External Knowledge: Can the Reverso models incorporate external knowledge or domain-specific information to enhance forecasting accuracy? Exploring this integration could enhance the model's applicability to specific industries.
- Efficacy of the Inference Strategies Across Different Scenarios: The paper proposes several inference strategies such as flip equivariance and downsampling. Further study is needed to quantify the efficacy of these strategies across different types and scales of time series data.
These knowledge gaps and open questions present opportunities for further research to enhance the effectiveness and applicability of time series foundation models, contributing to substantial advancements in the field.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from gradient-based updates to improve training stability. "We train with AdamW~\cite{adamw} with maximum learning rate using a WSD scheduler~\cite{wsd}, and weight decay of $0.1$"
- ablation studies: Controlled experiments that remove or alter components to assess their impact on performance. "In our ablation studies we also compare against other DeltaNet variants such as Gated DeltaNet~\citep[GDN; ] []{yang2025gated} and Gated Delta Product \citep[GDP;] []{siems2025deltaproduct}"
- amplitude modulation: A data augmentation that rescales signal amplitude to increase training diversity. "Downsampling and amplitude modulation are applied at the level of the full sequence."
- autoregressive rollout: Sequentially generating future predictions in steps, using previous outputs as inputs. "despite the multiple autoregressive rollouts using our prediction length of 48"
- censor augmentation: A data augmentation that masks or removes parts of a sequence to improve robustness. "flip augmentations and censor augmentations are applied on each subsampled sequence of context length "
- channel mixing: Transformations across feature dimensions (channels) to integrate information per time step. "Each sequence mixing layer is followed by a channel mixing MLP layer."
- composite kernel: A kernel formed by combining multiple base kernels via addition or multiplication for Gaussian processes. "This forms a composite kernel ."
- conformal methods: Statistical techniques to derive uncertainty bounds or prediction intervals with coverage guarantees. "insofar as conformal methods~\cite{conformal2021, conformal2025} have also been adopted as a lightweight adaptation to obtain uncertainty bounds for any point time series forecasts"
- context length: The number of past time steps provided to the model as input. "For sequences shorter than the model context length , the remaining values are back-filled using the leftmost available data point."
- decoder head: The final module that transforms hidden states into output predictions, often with attention. "We found this type of attention-based decoder “head” to be more performant and parameter-efficient than a simple linear layer"
- DeltaNet: A linear recurrent layer that updates a state with low-rank corrections using query, key, and value vectors. "DeltaNet learns the following state transition"
- depthwise separable convolutions: Convolutions that apply per-channel filtering followed by pointwise mixing to reduce computation. "The long convolution layer uses depthwise separable convolutions~\cite{chollet2017xceptiondeeplearningdepthwise}"
- downsampling: Reducing the sampling rate of a time series to fit longer periodicities within the model’s context. "We instead use a simple algorithm to determine the downsampling factors using FFT as described below."
- FFT (Fast Fourier Transform): An algorithm to compute the discrete Fourier transform efficiently. "With FFT the overall complexity of the convolution layer is "
- FFT-based convolutions: Convolution implementations that leverage FFTs to accelerate long-kernel operations. "While the FFT-based convolutions was previously not optimized for GPUs, recent works have enabled significant wallclock speed-ups \cite{flashfft}"
- flip equivariance: An inference technique ensuring consistent predictions under sign inversion by averaging outputs. "we found it helpful to ensure flip equivariance by passing both the original and flipped context to the model, and then averaging the results:"
- flip-every: Averaging original and flipped predictions at each autoregressive step during rollout. "flip-every where the original and flipped predictions are averaged at the end of each intermediate autoregressive step"
- flip-once: Averaging original and flipped predictions only once after the full autoregressive rollout. "flip-once where the original and flipped predictions across the whole forecast horizon are obtained separately and averaged once at the end after the autoregressive rollout is completed"
- Gaussian process: A probabilistic model defining distributions over functions via mean and kernel, used for synthetic data. "We then use and in a Gaussian process to sample the synthetic time series ."
- Gift-Eval: A benchmark suite of diverse time-series datasets and tasks for evaluating forecasting models. "The Gift-Eval benchmark~\citep{aksu2024giftevalbenchmarkgeneraltime} contains 23 different datasets with 97 different forecasting tasks."
- Gated DeltaNet: A DeltaNet variant that introduces gating mechanisms to modulate state updates. "In our ablation studies we also compare against other DeltaNet variants such as Gated DeltaNet~\citep[GDN; ] []{yang2025gated}"
- Gated Linear Attention (GLA): A linear attention mechanism with gates, generalizing certain state-space models. "as well as linear attention variants such Gated Linear Attention \citep[GLA;] []{gla} (which generalizes state-space models such as Mamba-2 \citep{dao2024transformers})"
- group attention mechanism: An attention strategy that processes multivariate inputs by grouping channels. "Chronos-2 \cite{chronos2} introduced the group attention mechanism for multivariate forecasting."
- head dimension: The dimensionality assigned to each attention or recurrent head in multi-head architectures. "with head dimension "
- hierarchical block attention mechanism: An attention design that structures sequences into blocks with hierarchical interactions. "Xihe \citep{xihe} scales up TSFMs to over a billion parameters with a hierarchical block attention mechanism."
- in-context learning: Performing a task by conditioning on input examples without updating model parameters. "via in-context learning, i.e., predicting the future given any historical time series data given as context."
- kernel bank: A predefined set of kernels from which to sample and compose Gaussian process covariance functions. "we define a kernel bank (see Table~\ref{tab:kernel_bank} of the appendix)"
- LayerNorm: A normalization technique applied across features to stabilize and accelerate training. ""
- linear attention: Attention mechanisms whose computational complexity scales linearly with sequence length. "These works generally make use of linear attention layers \citep{linearattention,peng2021random,schlag2021linear,gla,yang2024parallelizing}"
- linear RNN: Recurrent neural network layers with linear state updates enabling efficient sequence processing. "modern linear RNN layers (in particular DeltaNet layers \citep{schlag2021linear,yang2024parallelizing})"
- long convolution: Convolution with kernel size equal to the sequence length to capture long-range dependencies. "We adopt a hybrid sequence mixing strategy wherein we switch between (gated) long convolution \citep{flashfft} and DeltaNet layers"
- MAE (Mean Absolute Error): A loss function measuring average absolute difference between predictions and targets. "train against the ground truth output , using the mean absolute error (MAE) loss"
- Mamba: A state-space modeling architecture effective for sequence tasks, used as a building block in TS models. "TSMamba \citep{ma2024mamba} and Mamba4Cast \cite{bhethanabhotla2024mamba4cast} show that Mamba layers can be effective for time series."
- Mamba-2: An advanced state-space model variant used as a reference for generalized linear attention. "Gated Linear Attention \citep[GLA;] []{gla} (which generalizes state-space models such as Mamba-2 \citep{dao2024transformers})."
- MASE (Mean Absolute Scaled Error): A scale-free forecasting error metric normalized by in-sample naive forecast error. "Reverso achieves a competitive MASE value of 0.711 at a modest model size of 2.6M parameters."
- mixup: A data augmentation that linearly combines pairs of samples to improve generalization. "censor augmentation and mixup~\cite{chronos}, applied in this order."
- positional embedding: Encodings that inject sequence position information into model inputs or hidden states. "We find that smaller models train well without any positional embedding, whereas sin-cos positional embedding improves performance for Reverso-2.6M."
- ReLU: A nonlinear activation function defined as max(0, x), used in MLP layers. "The MLP layer works as in the standard transformer architecture~\cite{vaswani2017attention}, with a dimension expansion factor of 4, with ReLU activations:"
- RoPE (Rotary Positional Embedding): A positional encoding method that rotates queries and keys in attention. "Attention (RoPE)"
- seasonality: Periodic patterns in time-series data characterized by repeated cycles. "we generally want to ensure that patterns we wish to capture in the time series have seasonality period ."
- sequence mixing: Operations that mix information across time steps to model temporal dependencies. "We adopt a hybrid sequence mixing strategy wherein we switch between (gated) long convolution \citep{flashfft} and DeltaNet layers"
- SiLU: A smooth activation function (also known as swish) defined as x·sigmoid(x). ""
- state-space models: Sequence models that represent dynamics via latent states evolving over time. "state-space models \citep{gu2022efficiently,smith2023simplified_s5,Gu2023MambaLS,dao2024transformers}"
- state-weaving: A technique that connects layer states across boundaries to enhance bidirectional context. "We found this type of vector-based “state-weaving” strategy to work well in practice."
- stride: The step size used when sampling segments from sequences to control dataset balance. "we precompute the strides on each dataset necessary to achieve a target (roughly uniform) fraction of time series sampled."
- synthetic data: Artificially generated data used to augment training and improve model robustness. "We use synthetic data similar to established baselines~\cite{tirex, chronos}"
- TSFM (Time Series Foundation Model): A large pretrained model designed to generalize across diverse time-series tasks. "TSFMs are large-scale neural networks trained on heterogeneous time series data taken from broad domains"
- TSI: A synthetic process class capturing Trend, Seasonality, and Irregularity used for training. "We also include spike processes \cite{tirex, tempopfn, kairos} and TSI \cite{tsi} as used in Chronos-2"
- zero-shot forecasting: Making predictions on new tasks without task-specific training, using only context. "Learning time series foundation models has been shown to be a promising approach for zero-shot time series forecasting across diverse time series domains."
Practical Applications
Immediate Applications
Below are concrete uses that can be deployed now, leveraging Reverso’s small, efficient zero-shot time-series forecasting models, its data/inference recipes, and its training pipeline.
- Forecasting at the Edge for Energy and Utilities (Energy)
- What: On-device demand and generation forecasting for smart meters, microgrids, PV/wind inverters, and HVAC controllers.
- Why Reverso: 0.2–2.6M parameters fit into tight compute/memory budgets, require no task-specific training, and handle long horizons well.
- Tools/Workflows:
- An embeddable forecaster library (e.g., C++/Rust/ONNX runtime) that runs FlashFFTConv and DeltaNet on CPUs.
- A simple CLI/SDK for CSV-in/forecast-out with optional FFT-based downsampling.
- Assumptions/Dependencies: Predominantly univariate targets; zero-shot performance depends on similarity to pretraining domains; add conformal wrappers for uncertainty if required by operators/regulators.
- Store/SKU-Level Demand Forecasting on Laptops and ERP Add-ons (Retail & Supply Chain)
- What: Rapid zero-shot forecasts for new products, long-tail SKUs, or new regions without collecting task-specific training data.
- Why Reverso: Minimal metadata needs, operates on raw numeric series, strong long-horizon performance, cheap inference.
- Tools/Workflows:
- ERP/BI plugin (e.g., SAP/Oracle/Power BI) that invokes Reverso for rolling demand forecasts.
- Batch inference in Airflow/Prefect pipelines; Pandas or Spark UDF wrappers.
- Assumptions/Dependencies: Univariate forecasting; exogenous covariates (promotions, marketing) not natively modeled—consider hybrid pipelines that blend exogenous signals or use scenario overlays.
- Hospital Census, ED Arrivals, and Bed Occupancy Forecasts (Healthcare)
- What: Daily/weekly patient counts to support staffing and bed management in clinics/hospitals with limited IT resources.
- Why Reverso: Runs on-prem for privacy, robust to missing values, no reliance on calendar/holiday metadata.
- Tools/Workflows:
- On-prem Docker service that receives time series via FHIR-compatible extracts and returns forecasts.
- Simple monitoring of forecast residuals for anomaly detection (residual-thresholding).
- Assumptions/Dependencies: Primarily univariate; absence of uncertainty intervals requires conformal or bootstrap wrappers for operational safety.
- Network/Server Resource Forecasting for Autoscaling (Software/IT Ops)
- What: Forecast CPU, memory, and I/O loads for capacity planning and autoscaling in cloud and on-prem clusters.
- Why Reverso: Low-latency, low-cost inference across thousands of metrics; FFT-based seasonality detection helps capture diurnal/weekly cycles.
- Tools/Workflows:
- K8s sidecar microservice that retrieves Prometheus metrics and publishes rolling forecasts for HPA policies.
- Assumptions/Dependencies: Forecasts are univariate per metric; for correlated scaling across services, aggregate or post-process forecasts.
- Traffic and Throughput Prediction in Telecom/Content Delivery (Telecom/Networking)
- What: Local forecasts at base stations or PoPs to schedule backhaul capacity and CDN prefetching.
- Why Reverso: Efficient on low-end hardware; insensitivity to missing data due to built-in imputation.
- Tools/Workflows:
- Lightweight agents at network edges; FFT-based downsampling to accommodate weekly/monthly periodicities beyond context length.
- Assumptions/Dependencies: Sudden regime shifts (outages) require anomaly gating; use residual-based alerting.
- Predictive Maintenance on Embedded Gateways (Manufacturing/Industrial IoT)
- What: Zero-shot forecasting of sensor health signals (vibration, temperature) to flag pre-failure trends.
- Why Reverso: Small footprint; downsampling detects long periodic cycles; handle sparse/intermittent sensors with interpolation.
- Tools/Workflows:
- Edge deployment on gateways; residual-based anomaly scores for early warnings; scheduled retraining not required.
- Assumptions/Dependencies: Univariate signals; for multi-sensor dependencies use ensemble or post-hoc fusion.
- Environmental Monitoring and Local Weather Nowcasting (Public Sector/Environment)
- What: Forecast air quality, river levels, or microclimate station readings where long cycles exceed context.
- Why Reverso: FFT-based automatic downsampling finds dominant seasonality without metadata; zero-shot forecasts reduce setup.
- Tools/Workflows:
- Municipal dashboards with on-prem inference services; scheduled batch forecasting pipelines.
- Assumptions/Dependencies: Zero-shot performance may degrade in rare/niche phenomena not in pretraining data.
- Personal Finance and Home Energy Forecasts on Devices (Daily Life/Consumer Apps)
- What: Budgeting forecasts (expenses) and household energy usage forecasts in mobile apps.
- Why Reverso: Runs on phones/offline; minimal inputs; robust to short data histories (with caveats for short-sequence performance).
- Tools/Workflows:
- Mobile SDKs (e.g., CoreML/NNAPI) wrapping the 200K–550K parameter variants.
- Assumptions/Dependencies: Short-sequence performance lags larger models; use longer histories or fallback heuristics when possible.
- Out-of-the-Box Anomaly Detection via Forecast Residuals (Cross-Sector)
- What: Use forecast vs. actual residuals for anomaly scoring without training specialized detectors.
- Why Reverso: Zero-shot forecasting yields strong baselines; test-time flip-equivariant averaging stabilizes residuals.
- Tools/Workflows:
- Residual z-scores or conformalized residual bands for alerting.
- Assumptions/Dependencies: Requires calibrated thresholds; add basic seasonality guards for non-stationary series.
- Plug-and-Play Test-Time Optimizations for Existing TS Pipelines (Software/MLOps)
- What: Integrate FFT-based automatic downsampling and flip-equivariant averaging to boost any forecaster’s accuracy.
- Why Reverso: The paper’s inference strategies are model-agnostic and easy to add to prediction workflows.
- Tools/Workflows:
- A small Python/Scala module exporting downsampling-factor detection and flip TTA wrappers.
- Assumptions/Dependencies: Seasonality detection assumes identifiable peaks in FFT; adds minor latency (extra forward pass for flip).
- Cost-Down Migration from Large TSFMs to Compact Models (All Sectors)
- What: Replace 200M–1.5B parameter forecasters with ≤2.6M parameter Reverso where accuracy is comparable.
- Why Reverso: Massive compute/memory savings; feasible on commodity CPUs; faster and cheaper batch runs.
- Tools/Workflows:
- Comparative A/B tests; model registry updates; ONNX export for broad deployment.
- Assumptions/Dependencies: Validate on in-domain datasets; monitor for long-tail degradation and add safeguards.
- Training Pipeline Recipes for Academic and Industrial Labs (Academia/ML Engineering)
- What: Adopt Reverso’s data pipeline: dataset rebalancing via stride precomputation, augmentation stack, and synthetic data generation (Gaussian-process kernel bank + spikes/TSI).
- Why Reverso: Demonstrated gains with low compute (10–40 H100-hours), easy to reproduce and extend.
- Tools/Workflows:
- Open-source augmentation/synthetic modules; template configs for WSD scheduler and AdamW; ablation-ready scripts.
- Assumptions/Dependencies: Careful curation of kernel bank; ensure synthetic/real ratios to avoid overfitting to artifacts.
Long-Term Applications
These opportunities likely require further research, scaling, new features, or ecosystem development before routine deployment.
- Multivariate Foundation Forecasting with Cross-Channel Dependencies (Healthcare, Energy, Finance, Manufacturing)
- What: Jointly model correlated signals (e
Collections
Sign up for free to add this paper to one or more collections.