FAMOSE: A ReAct Approach to Automated Feature Discovery
Abstract: Feature engineering remains a critical yet challenging bottleneck in machine learning, particularly for tabular data, as identifying optimal features from an exponentially large feature space traditionally demands substantial domain expertise. To address this challenge, we introduce FAMOSE (Feature AugMentation and Optimal Selection agEnt), a novel framework that leverages the ReAct paradigm to autonomously explore, generate, and refine features while integrating feature selection and evaluation tools within an agent architecture. To our knowledge, FAMOSE represents the first application of an agentic ReAct framework to automated feature engineering, especially for both regression and classification tasks. Extensive experiments demonstrate that FAMOSE is at or near the state-of-the-art on classification tasks (especially tasks with more than 10K instances, where ROC-AUC increases 0.23% on average), and achieves the state-of-the-art for regression tasks by reducing RMSE by 2.0% on average, while remaining more robust to errors than other algorithms. We hypothesize that FAMOSE's strong performance is because ReAct allows the LLM context window to record (via iterative feature discovery and evaluation steps) what features did or did not work. This is similar to a few-shot prompt and guides the LLM to invent better, more innovative features. Our work offers evidence that AI agents are remarkably effective in solving problems that require highly inventive solutions, such as feature engineering.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces FAMOSE, an AI “agent” that automatically invents and tests new data features (extra columns made from existing ones) to help machine learning models make better predictions on tables of data. Instead of relying on a human expert to handcraft clever features, FAMOSE thinks, runs code, checks results, learns from mistakes, and repeats—like a junior data scientist working in a loop.
What questions were the researchers asking?
The authors wanted to know:
- Can an AI agent automatically discover useful features for both classification (predicting categories) and regression (predicting numbers)?
- Will an agent that learns from trial and error (not just a one-time guess) find better features?
- Can this be done reliably across many different datasets and models?
How does FAMOSE work? (Simple explanation)
Think of building a prediction model like cooking a dish. The raw columns in your table are ingredients. “Feature engineering” is finding better ingredients by combining or transforming the ones you already have (like making a sauce from tomatoes and herbs). Good new features can make the final dish (the model) much better.
FAMOSE is an AI assistant that:
- “Thinks” about what kinds of new features might help.
- “Acts” by writing small pieces of code to create those features.
- “Checks” how much each feature improves the model on validation data.
- “Learns” what didn’t work and tries different ideas next time.
This thinking-and-acting loop is called ReAct. It lets the AI remember which ideas helped and which didn’t, so it improves over time.
Here’s the basic flow:
- It splits the data into training and validation parts.
- It proposes a bunch of new features (like differences, ratios, dates turned into ages, or combinations of columns).
- It runs the code to build these features and tests whether each one actually improves the model.
- It keeps the best feature from a round and repeats the process for many rounds, each time trying to do better.
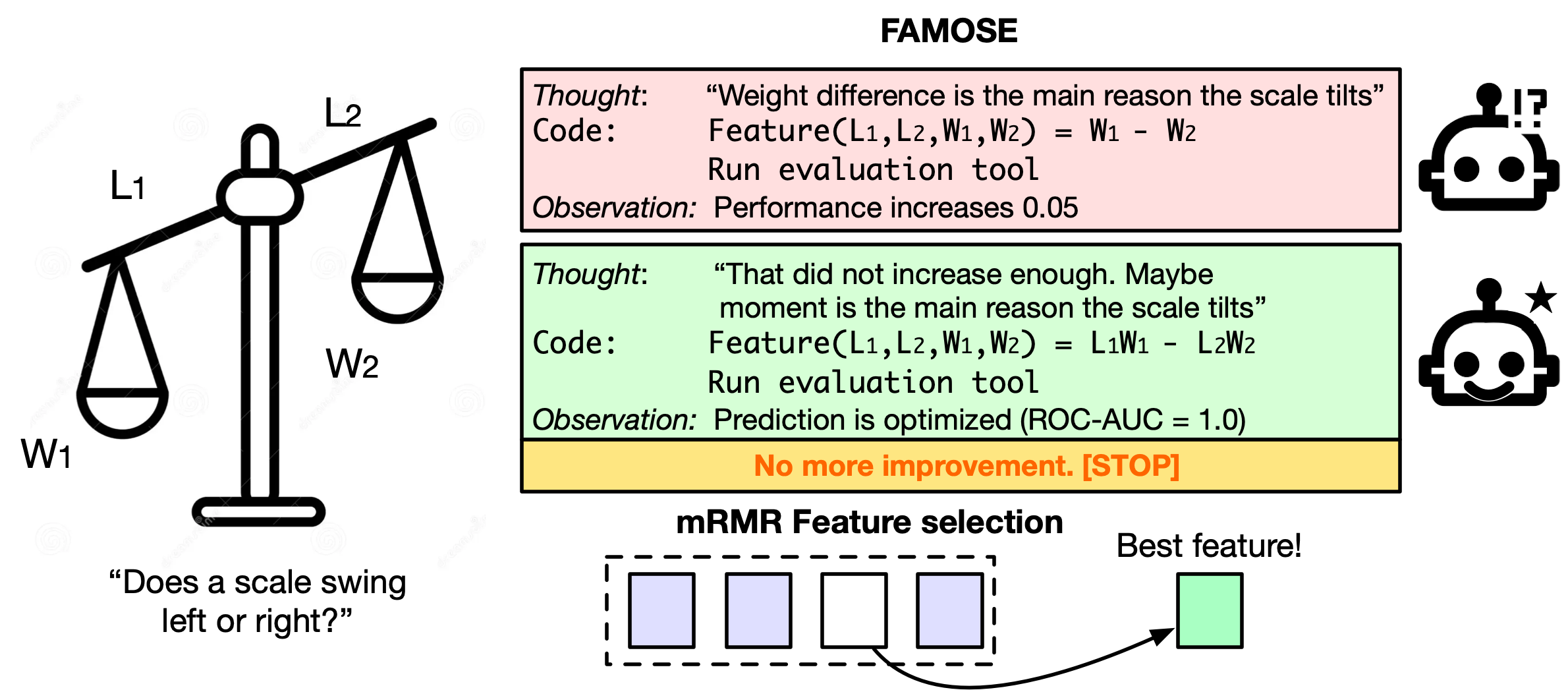
- At the end, it uses a selection method called mRMR (minimum redundancy, maximum relevance) to pick a small set of features that:
- add useful information for predicting the target, and
- don’t repeat the same information as each other.
A concrete example: In a balance-scale dataset, FAMOSE discovered a feature similar to “moment” (weight × distance), which perfectly tells whether the scale tilts left, right, or is balanced. It then removed unnecessary original columns, leaving one powerful, easy-to-understand feature.
What did the researchers find?
Across many public datasets:
- For classification tasks (predicting categories), FAMOSE was at or near state-of-the-art overall. On larger datasets (more than 10,000 rows), it did slightly better on average than other methods.
- For regression tasks (predicting numbers), FAMOSE reached state-of-the-art on average, reducing error by about 2%.
- It was more robust than some other tools (it handled errors better and worked reliably on big datasets where some methods crashed or timed out).
- The features it created also helped different kinds of models (like XGBoost, Random Forest, and AutoGluon), not just the one used during feature search.
- The agent explains why each feature might help, making the results more interpretable for humans.
In simple terms: FAMOSE didn’t just throw out random ideas; it tested them, kept the best, and learned as it went—leading to strong, reliable improvements.
Why is this important?
- Saves time and expert effort: Feature engineering usually takes a lot of human trial and error. FAMOSE automates that process.
- Works on many problems: It helped on both category-predicting and number-predicting tasks, and across different model types.
- More trustworthy: By actually running code and checking results every round (and correcting mistakes), it reduces “AI hallucinations.”
- More understandable: It explains its reasoning, so people can see why a feature is useful.
What are the limits and what’s next?
- Cost and size: The “think and test” approach uses more AI tokens and works best with stronger LLMs, which can be pricier.
- Background knowledge: The AI may do better on familiar topics than on very niche ones (adding task-specific info could help).
- Extensions: The method is designed for regular tables; future versions could adapt it for special cases (like multi-label tasks) or other data types.
Bottom line
FAMOSE shows that an AI agent that thinks, acts, and learns from feedback can automatically invent smart features—often matching or beating leading methods—especially on larger datasets. It brings us closer to AI systems that can handle some of the most creative (and time-consuming) parts of building machine learning models.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper and can guide future research:
- Quantify statistical significance for classification gains. The paper reports average ROC-AUC improvements (e.g., 0.23% for large datasets) without formal tests or confidence intervals per task; provide rigorous per-dataset significance analyses and multiple-comparison corrections.
- Measure run-to-run stability. LLM temperature is fixed at 0.8, but variance across independent agent runs is not reported; quantify stochasticity-induced performance variability and its impact on reproducibility.
- Report computational cost and scalability. No token counts, runtime, memory footprint, or dollar costs are provided; characterize scaling laws (dataset rows, columns, agent rounds/steps) and cost–performance trade-offs.
- Ablate agentic reasoning vs simpler workflows. Isolate the contribution of ReAct-style iteration by comparing against one-shot LLM proposals with external evaluation loops, human-in-the-loop variants, and scripted transformation enumerations.
- Hyperparameter sensitivity analysis. Systematically vary key settings (1% improvement goal, 10 agent steps, up to 20 rounds, 5-fold CV, mRMR parameters) to quantify sensitivity and derive robust default recommendations.
- Principled stopping criteria. The agent stops after “no improvement after 6 rounds”; evaluate adaptive or statistically grounded stopping rules to avoid premature termination or validation overfitting.
- Validation-overfitting risk. The agent repeatedly evaluates on the same validation split; assess bias due to iterative validation usage (e.g., with nested CV, repeated holdouts, or cross-fitting).
- Feature selection method choice. mRMR is assumed superior to LLM selection but not compared; benchmark mRMR against alternatives (e.g., mutual information variants, SHAP-based selection, LASSO, Boruta) and analyze interactions with tree vs linear models.
- Nonlinear relevance and synergy. mRMR’s redundancy/relevance criteria may discard individually redundant but jointly synergistic features; test multi-feature interaction-aware selectors.
- Generalization across model families. Features were evaluated on XGBoost, Random Forest, and AutoGluon; extend tests to linear/logistic models, gradient-boosting variants, neural nets, and calibrated probabilistic models to map where feature gains translate.
- Metric choice for imbalanced tasks. Reliance on ROC-AUC may mask performance on highly imbalanced datasets (e.g., fraud); include PR-AUC, calibration error, and decision-cost metrics.
- Multi-class metric choices. Use of unweighted one-vs-one ROC-AUC is nonstandard for multi-class; compare against macro/micro ROC-AUC, log-loss, and PR metrics.
- Regression baseline coverage. LLM-based baselines are missing for regression; include or develop LLM feature-engineering baselines for regression to support SOTA claims.
- LLM dependency and minimum model size. Performance with smaller/open models (e.g., Llama 3.1-8B) is noted as poorer but not quantified; map performance vs model size/capability and identify “minimum viable LLM” configurations.
- Domain knowledge injection. The paper proposes RAG as a potential remedy but does not test it; evaluate RAG-enhanced agents for domain-specific or rare tasks and quantify gains vs token cost.
- Metadata tool accuracy. The automatic type detection (numerical/datetime/categorical) is not validated; assess misclassification rates (e.g., ordinal vs nominal) and impact on feature proposals/outcomes.
- Data leakage safeguards. Beyond removing the target column, evaluate robustness to subtle leakage (e.g., temporal leakage in time series, future-derived features, identifiers) and propose detection/prevention mechanisms.
- Handling of time series and temporally structured data. Extend FAMOSE to time-aware CV, lag/rolling features, and leakage prevention; benchmark on standardized time-series datasets.
- Multi-label classification support. The paper notes planned modifications; implement and evaluate multi-label settings (metrics, agent objectives, feature evaluation tooling).
- High-dimensional feature spaces. Test FAMOSE on datasets with hundreds/thousands of columns to assess scalability and the agent’s ability to navigate dense interaction spaces.
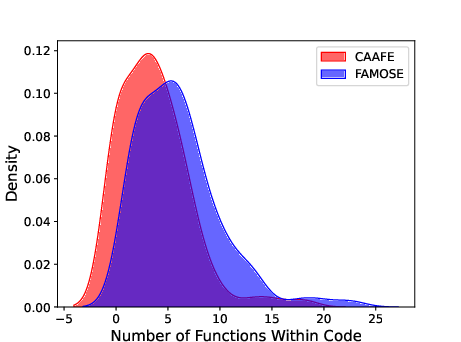
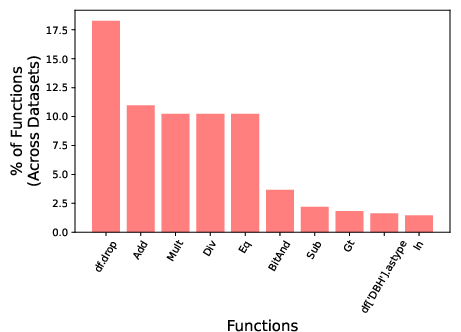
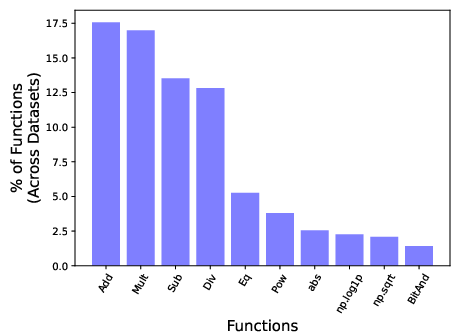
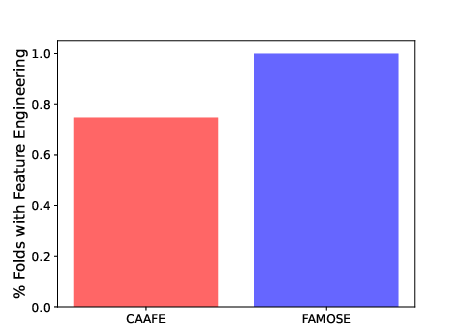
- Diversity of generated transformations. Provide a taxonomy and quantitative diversity measures of proposed features (e.g., distribution over operators, composition depth, function classes) and compare to baselines like CAAFE/OpenFE.
- Hallucination mitigation effectiveness. Quantify the frequency/types of LLM errors (e.g., hallucinated columns, invalid code) and the success rate/overhead of correction tools; characterize residual failure modes.
- Safety of code execution. Detail sandboxing constraints for executing LLM-generated Python, audit for unsafe operations, and evaluate security guarantees.
- Fairness and bias. Investigate whether engineered features encode or amplify protected attributes; include fairness metrics, subgroup robustness, and mitigation strategies.
- Interpretability validation. Agent rationales are provided but not evaluated; conduct human studies or use objective measures (e.g., faithfulness tests, rationale–code alignment) to assess explanation quality.
- Transfer across datasets/tasks. Explore meta-learning or memory of successful feature motifs across datasets to improve sample efficiency and reduce token cost.
- Effect on downstream AutoML. Study how FAMOSE interacts with end-to-end AutoML (e.g., hyperparameter tuning, stacking); measure net benefit vs redundant transformations already discovered by AutoML frameworks.
- Token cost vs performance frontier. Characterize the Pareto frontier by varying agent depth/steps and reasoning verbosity; identify cost-efficient operating points.
- Robust handling of categorical data. Clarify and evaluate encoding strategies (e.g., target encoding, ordinal vs nominal handling) within FAMOSE to avoid inappropriate numeric conversions.
- Stop criteria for “goal” prompt. The 1% improvement target influences behavior; optimize or adaptively set goals (task-, metric-, or noise-aware) to balance exploration vs exploitation.
- Impact under distribution shift. Test robustness of learned features across temporal or domain shifts (e.g., train–test drift, covariate shift) and incorporate shift-aware evaluation protocols.
- Reproducibility and code availability. Provide complete reproducible pipelines (including environment, seeds, data preprocessing) and evaluate portability beyond AWS Bedrock/SageMaker.
- Dataset selection coverage. Expand to larger, messier, real-world datasets (high-cardinality categoricals, missingness, skew, noisy labels) and report failure cases and mitigation strategies.
Glossary
- ablated: Removing or disabling components of a system to assess their contribution to performance. "We can also test whether {FAMOSE} can be ablated to a simpler model (Appendix Tables~\ref{tab:ablation_class} {paper_content}~\ref{tab:ablation_reg})."
- agentic ReAct framework: Applying the ReAct approach within an autonomous agent that iteratively reasons and acts. "To our knowledge, FAMOSE represents the first application of an agentic ReAct framework to automated feature engineering, especially for both regression and classification tasks."
- AutoFeat: A classical automated feature engineering method that generates and prunes transformed features. "This includes AutoFeat \cite{horn2019autofeat}, DIFER \cite{zhu2022difer}, and OpenFE \cite{zhang2023openfe}, which each create a set of new features based on transformations and operations on older features and then prune the resulting feature set."
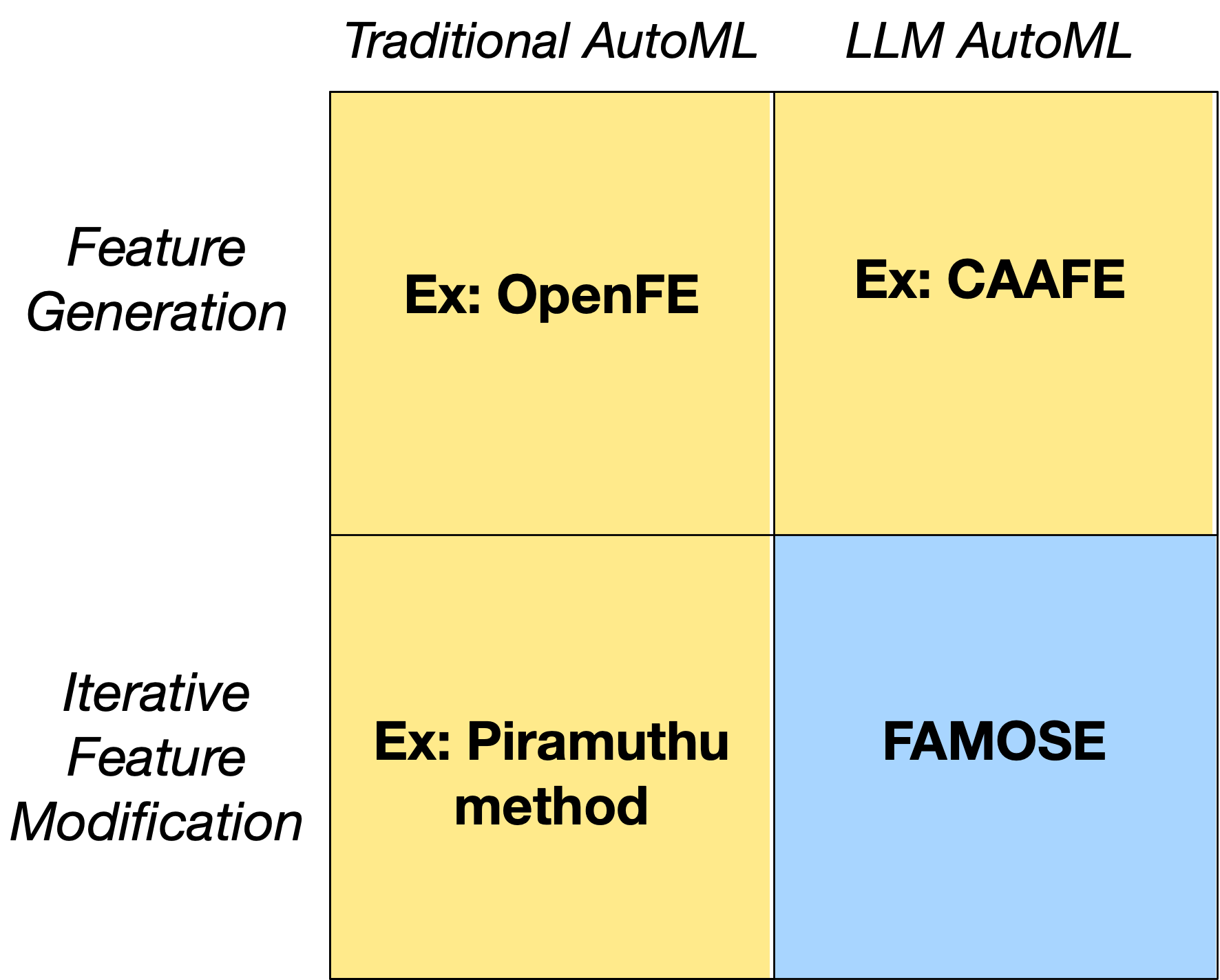
- AutoML: Automated machine learning systems that handle tasks like model selection and feature engineering with minimal human intervention. "Types of AutoML. In traditional AutoML, feature engineering would include feature discovery, such as within OpenFE \cite{zhang2023openfe}, or iterative feature modification, such as the method of Piramuthu et al. \cite{piramuthu2009iterative}."
- Autogluon: An AutoML framework that builds weighted ensembles of diverse models. "We also apply the XGBoost-derived features to Random Forest \cite{breiman2001random} and Autogluon in order to determine the robustness of these features across models."
- boosted trees: Ensembles of decision trees trained via boosting to improve predictive performance. "We believe the models we choose, however, represent exemplars of state-of-the-art tabular models: boosted trees (XGBoost), ensembles of trees (Random Forest), and weighted ensembles of deep-learning, boosted, and foundation models (Autogluon)."
- chain-of-though reasoning: An LLM technique that explicitly traces multi-step reasoning, often increasing token usage. "First, the ReAct framework can be expensive due to the number of tokens needed for agentic chain-of-though reasoning."
- classification tasks: Prediction problems where the target is categorical. "To our knowledge, FAMOSE represents the first application of an agentic ReAct framework to automated feature engineering, especially for both regression and classification tasks."
- context window: The span of tokens an LLM can attend to, which maintains history and influences generation. "We hypothesize that FAMOSE's strong performance is because ReAct allows the LLM context window to record (via iterative feature discovery and evaluation steps) what features did or did not work."
- cross-validation: A resampling strategy that partitions data into folds to estimate model performance reliably. "We specifically use 5-fold cross-validation within the training dataset to find the optimal number of features to select (based on ROC-AUC or RMSE), then apply mRMR to the training dataset to select the specific features."
- Deep Feature Synthesis: A method that automatically constructs features via aggregations and transformations over relational data. "Other examples include ExploreKit \cite{Katz2016ExploreKitAF} and Deep Feature Synthesis \cite{Kanter2015DeepFS} (also cf. \cite{Heaton2016,nargesian2017learning,davis2016automated,nargesian2017learning}), which generate candidate features by enumerating transformations over existing features, then follow a heuristic or model-based evaluation for feature selection."
- Deepseek-R1: A LLM used as an alternative for generating and refining features. "We apply an alternative LLM, Deepseek-R1 \cite{guo2025deepseek}, to {FAMOSE} and discover performance is similar (see Tables~\ref{tab:LLM_class} {paper_content}~\ref{tab:LLM_reg} in the Appendix)."
- data leakage: Inadvertent use of target information in features or training that inflates performance estimates. "Data provided to the feature generation code also has the target variable removed to avoid data leakage."
- DIFER: An automated feature engineering approach focusing on transformations and selection. "This includes AutoFeat \cite{horn2019autofeat}, DIFER \cite{zhu2022difer}, and OpenFE \cite{zhang2023openfe}, which each create a set of new features based on transformations and operations on older features and then prune the resulting feature set."
- ExploreKit: A framework that enumerates feature transformations and evaluates them with heuristics or models. "Other examples include ExploreKit \cite{Katz2016ExploreKitAF} and Deep Feature Synthesis \cite{Kanter2015DeepFS}..."
- feature engineering: The process of creating, transforming, and selecting input variables to improve model performance. "Feature engineering remains a critical yet challenging bottleneck in machine learning, particularly for tabular data, as identifying optimal features from an exponentially large feature space traditionally demands substantial domain expertise."
- feature selection: Choosing a subset of features that optimizes performance or simplicity, often reducing redundancy. "Once performance stops increasing at the feature discovery step, FAMOSE then applies a minimal-redundancy maximal-relevance (mRMR) feature selection step \cite{ding2005minimum} to produce a compact final feature set."
- feature space: The set of all possible features or transformations that could be considered in modeling. "identifying optimal features from an exponentially large feature space traditionally demands substantial domain expertise."
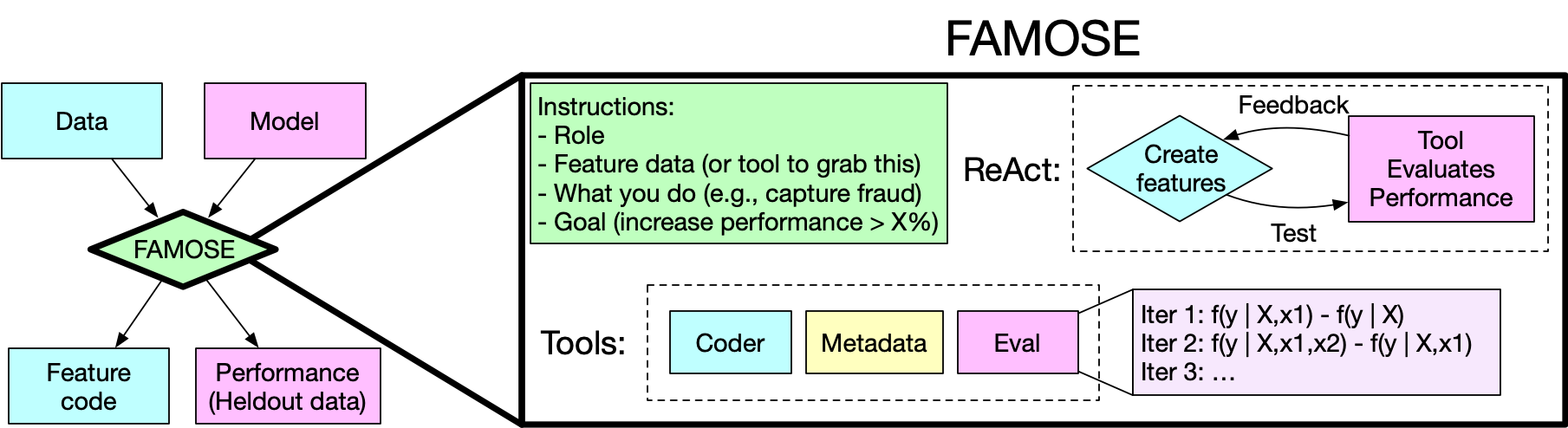
- feedback-driven search process: An iterative procedure that uses validation feedback to guide feature generation and refinement. "Inspired by the Reasoning and Acting paradigm, the agent can reason about the task, execute code, and adapt its strategy based on validation performance, enabling a feedback-driven search process similar to how human practitioners experiment with features."
- few-shot learning: Leveraging a small number of examples or prior cases to generalize and improve performance. "We hypothesize FAMOSE's ability to create useful features is due to the LLM context window recording the features that did and did not improve model performance, which is akin to few-shot learning, allowing new features invented by an agent to improve on the mistakes of features the agent invented in previous steps."
- few-shot prompt: A prompt that includes a handful of examples to steer an LLM’s outputs. "This is similar to a few-shot prompt and guides the LLM to invent better, more innovative features."
- hallucinations: Fabricated or incorrect outputs produced by LLMs without grounding in data or tools. "The iterative loop also allows the agent to detect and correct invalid or unhelpful features, reducing hallucinations and improving robustness."
- held-out data: A portion of the dataset reserved for validation/testing to objectively assess model performance. "The model performance (ROC-AUC or RMSE) in held-out data containing the candidate feature, the original features, and all of the best features chosen so far is compared against a model without the candidate feature."
- K-Folds: A cross-validation scheme where data is split into K partitions for training and testing in turns. "For training/validation and testing, we use scikit-learn's K-Folds (if regression) or StratifiedKFold (if classification) with K5, and use a random seed of 42 \cite{scikit-learn}."
- LLM: LLM; a neural network trained on vast corpora to generate and understand text. "While LLM-based methods may offer a route to search this space more efficiently, these methods do not iteratively improve on their prior features by learning from their mistakes."
- metadata: Descriptive information about data columns (types, names) used to guide feature generation. "created a metadata generator tool that allows the agent to determine data file column names (features) and whether the column values represent numerical, datetime, or categorical data."
- minimal-redundancy maximal-relevance (mRMR): A feature selection criterion that maximizes relevance to the target while minimizing redundancy among features. "Once performance stops increasing at the feature discovery step, FAMOSE then applies a minimal-redundancy maximal-relevance (mRMR) feature selection step \cite{ding2005minimum} to produce a compact final feature set."
- model-based evaluation: Assessing candidate features by training models and measuring performance to decide retention. "then follow a heuristic or model-based evaluation for feature selection."
- one-shot: Generating features in a single pass without iterative refinement based on feedback. "Unlike one-shot or template-based approaches, the agent can directly interact with the dataset to compute statistics, inspect distributions, and test hypotheses about feature utility."
- one-versus-one ROC-AUC: Averaging ROC-AUC scores computed for each pair of classes in multi-class problems. "For any multi-class tasks, such as balance-scale, we calculate an unweighted average of one-versus-one ROC-AUC."
- OpenFE: A modern automated feature engineering tool that enumerates and selects transformed features. "This includes AutoFeat \cite{horn2019autofeat}, DIFER \cite{zhu2022difer}, and OpenFE \cite{zhang2023openfe}..."
- orthogonal features: Features that are uncorrelated and linearly independent in PCA-derived representations. "In PCA, a new set of orthogonal features are created that represent the largest amount of variance in the data."
- PCA (Principal component analysis): A dimensionality reduction technique creating components that explain maximal variance. "Early work focused on pre-processing data, namely creating compact or latent representations of data, including principal component analysis (PCA) \cite{abdi2010principal}."
- RAG framework: Retrieval-Augmented Generation; combining external knowledge retrieval with LLM generation. "A RAG framework might help in these scenarios by inserting more bespoke background knowledge of the task to the LLM prior to the feature generation step."
- Random Forest: An ensemble of decision trees built via bagging to reduce variance and improve generalization. "We also apply the XGBoost-derived features to Random Forest \cite{breiman2001random} and Autogluon in order to determine the robustness of these features across models."
- Reasoning and Acting paradigm: A framework where agents interleave internal reasoning with external actions (tool use). "Inspired by the Reasoning and Acting paradigm, the agent can reason about the task, execute code, and adapt its strategy based on validation performance..."
- ReAct: A technique for LLM agents that integrates chain-of-thought reasoning with tool execution. "In contrast to prior approaches, our work's most substantial contribution is that {FAMOSE} uses a ReAct framework \cite{yao2022react}, in which the LLM iteratively proposes, evaluates, and refines features based on model feedback and data-driven analysis."
- regex: Regular expressions used for pattern matching and extraction in strings or code. "The tool is highly robust with the help of error correction and regex to extract all the feature names in the feature code..."
- regression tasks: Prediction problems where the target is continuous. "and achieves the state-of-the-art for regression tasks by reducing RMSE by 2.0\% on average..."
- RMSE: Root Mean Square Error; a regression metric measuring average prediction error magnitude. "and achieves the state-of-the-art for regression tasks by reducing RMSE by 2.0\% on average"
- ROC-AUC: Area under the ROC curve; a classification metric measuring rank-based separability. "Extensive experiments demonstrate that FAMOSE is at or near the state-of-the-art on classification tasks (especially tasks with more than 10K instances, where ROC-AUC increases 0.23\% on average)"
- Smolagents: An open-source agent framework enabling LLMs to think, act, and observe with tool integration. "Smolagents is an opensource AI agent that can think, act, and observe, but can hallucinate without appropriate tools."
- StratifiedKFold: Cross-validation that preserves class proportions across folds. "For training/validation and testing, we use scikit-learn's K-Folds (if regression) or StratifiedKFold (if classification) with K5..."
- stratified: A sampling procedure that maintains class distribution in splits. "Split into folds (stratified if classification)"
- tabular data: Structured datasets organized into rows and columns. "Feature engineering remains a critical yet challenging bottleneck in machine learning, particularly for tabular data..."
- tabular models: Machine learning models tailored for structured, table-like data. "Despite the simplicity of tabular models, their performance is often difficult to optimize."
- template-driven workflow: A process constrained by predefined templates, limiting iterative refinement. "However, most existing LLM-based approaches follow a one-shot or template-driven workflow: features are generated once, evaluated externally, and not iteratively refined by the LLM itself."
- tool feedback: Information returned by tools (e.g., evaluators, compilers) that guides an agent’s next actions. "Agent proposes a feature, , using metadata and tool feedback"
- validation performance: Model performance measured on a held-out validation split used to guide decisions. "Inspired by the Reasoning and Acting paradigm, the agent can reason about the task, execute code, and adapt its strategy based on validation performance..."
- weighted ensembles: Ensembles that combine multiple models with learned weights to optimize performance. "weighted ensembles of deep-learning, boosted, and foundation models (Autogluon)."
- Wilcoxon signed rank test: A nonparametric test for comparing paired samples across conditions. "Wilcoxon signed rank test p-value between {FAMOSE} and the baseline."
- XGBoost: A gradient boosting library for decision trees, widely used for tabular ML. "We compare different feature engineering approaches using XGBoost, as this is a common high-quality tabular model baseline."
Practical Applications
Immediate Applications
The following items outline specific, deployable use cases that leverage FAMOSE’s agentic, ReAct-based feature engineering for tabular data, along with sector links, potential tools/products/workflows, and feasibility notes.
- Automated feature engineering in existing tabular ML pipelines
- Sectors: software, finance, healthcare, e-commerce, cybersecurity, public sector
- What to do: Integrate FAMOSE as a pre-model step in XGBoost/Random Forest/AutoGluon pipelines to iteratively propose, validate, and select high-utility features (with mRMR).
- Tools/products/workflows: Python package or microservice wrapping Smolagents + AWS Bedrock (Sonnet 3.5 V2 or DeepSeek-R1), CI/CD jobs that run 5-fold CV, feature evaluation tool (ROC-AUC/RMSE), post-processing mRMR.
- Assumptions/dependencies: Access to an LLM API and Python execution sandbox; reliable schema/metadata; cross-validation splits representative of production; token and compute budgets manageable.
- Cost-aware model improvement using cross-model feature transfer
- Sectors: enterprise ML (any domain)
- What to do: Generate features with a fast baseline (e.g., XGBoost) and reuse them across heavier models (e.g., AutoGluon or ensembles) to save inference and experimentation cost/time.
- Tools/products/workflows: Feature store entries tagged with provenance (“FAMOSE-generated”), automated downstream re-training with feature reuse.
- Assumptions/dependencies: Downstream models accept the same tabular schema; features generalize across models; DVC/feature store supports versioning.
- Regulated-domain interpretability boost via agent explanations
- Sectors: finance (credit risk/fraud), healthcare (risk scoring), insurance (pricing), public health/policy analytics
- What to do: Use FAMOSE’s reasoning traces to produce human-readable justifications for engineered features in model documentation, audits, and model risk governance.
- Tools/products/workflows: “Explainability sheet” export (LLM rationales + performance deltas + mRMR selections), governance checklists, model card integration.
- Assumptions/dependencies: Explanations are consistent and comprehensible; stakeholders accept LLM-generated narratives as supporting documentation; legal teams define acceptable use.
- Fraud detection and credit risk uplift
- Sectors: finance
- What to do: Apply FAMOSE to tasks like bank_fraud_base and credit-g to discover interaction features (e.g., transaction pattern ratios, recency-weighted aggregates) that improve ROC-AUC.
- Tools/products/workflows: Batch feature generation jobs, adverse action reporting enriched with interpretable features.
- Assumptions/dependencies: Label quality; stable data distributions; rigorous backtesting; fairness monitoring to avoid proxy variables.
- Marketing response prediction and churn modeling
- Sectors: marketing, telecom, SaaS
- What to do: Use FAMOSE to derive features for bank_marketing, customer churn, and campaign uplift (e.g., lagged behaviors, normalized engagement ratios).
- Tools/products/workflows: A/B pipelines where engineered features are pushed to production via feature store; ongoing monitoring of uplift and drift.
- Assumptions/dependencies: Accurate event timestamps; minimal label leakage; adequate sample sizes for >10K rows benefit.
- Cybersecurity alert triage
- Sectors: cybersecurity
- What to do: Improve alert severity classification using FAMOSE-generated features (e.g., aggregated frequency patterns, entropy-based measures).
- Tools/products/workflows: SOC pipeline integration; daily batch jobs generating engineered features for SIEM/UEBA models.
- Assumptions/dependencies: Reliable categorical encoding; careful handling of high-cardinality features; adherence to security policy for code execution.
- Operational forecasting (claims, demand, pricing)
- Sectors: insurance, retail, energy
- What to do: Use FAMOSE for regression tasks (e.g., insurance pricing, bike rentals, energy load) to reduce RMSE via transformation and interaction features (e.g., seasonality indices, log transforms, residual-based combinations).
- Tools/products/workflows: Scheduled feature generation; retraining with mRMR-selected compact sets to limit overfitting.
- Assumptions/dependencies: Time-aware CV; holiday/seasonality metadata; domain guardrails to avoid leakage.
- Data validation and schema hygiene via tool feedback
- Sectors: software, data engineering (any)
- What to do: Exploit FAMOSE’s code validation and column-name regex extraction to catch mismatched schema, missing columns, and improper types before training.
- Tools/products/workflows: Pre-training “feature health check” step; automated schema correction utilities.
- Assumptions/dependencies: Access to dataset metadata; sufficient developer permissions for code execution; robust sandboxing.
- Education and training in feature engineering
- Sectors: education, professional upskilling
- What to do: Use FAMOSE in Jupyter/Colab to teach iterative feature design, evaluation, and selection with transparent reasoning.
- Tools/products/workflows: Classroom notebooks; assignments where students compare one-shot vs ReAct approaches; guided labs.
- Assumptions/dependencies: LLM access for classrooms; guardrails for code execution; simplified datasets for didactics.
- Spreadsheet and BI augmentation for small businesses
- Sectors: daily life, SMBs
- What to do: Build a lightweight plugin that invokes FAMOSE to propose features directly in Excel/Google Sheets for sales, inventory, or financial tracking.
- Tools/products/workflows: Local Python backend or cloud function; “Generate features & explain” button; export to CSV.
- Assumptions/dependencies: Simplified setup; privacy-safe deployment; limited compute budgets.
- Model simplification via compact feature sets
- Sectors: all
- What to do: Use mRMR to prune feature sets to high-relevance, low-redundancy subsets that improve stability and reduce inference cost.
- Tools/products/workflows: Feature pruning stage with 5-fold CV to select an optimal number of features; inference latency dashboards.
- Assumptions/dependencies: Feature store supports versioning; consistent preprocessing across train/test; careful monitoring of performance-latency trade-offs.
Long-Term Applications
These items are feasible with further research, scaling, or product development, including robustness, governance, and multi-modal extensions.
- Enterprise-grade “FeatureCopilot” platform
- Sectors: software (MLOps), all data-driven enterprises
- What to do: Productize FAMOSE as a managed service with guardrails, observability, cost controls, and policy packs; integrate with AutoML for end-to-end model lifecycle.
- Tools/products/workflows: Role-based access, lineage tracking, feature store integration, budget-aware LLM routing.
- Assumptions/dependencies: Mature platform engineering; multi-tenant security; SLA support.
- Fairness-aware and compliance-constrained feature engineering
- Sectors: finance, healthcare, public sector
- What to do: Add fairness constraints and prohibited proxy detection (e.g., disallow features correlating with protected attributes), explainability checks, and audit trails.
- Tools/products/workflows: Constraint solvers layered on top of mRMR; fairness dashboards; legal review workflows.
- Assumptions/dependencies: Availability of protected attribute metadata or proxies; governance adoption; regulator acceptance.
- Privacy-preserving and on-prem LLM deployment
- Sectors: healthcare, finance, defense
- What to do: Run FAMOSE with smaller/fine-tuned on-prem LLMs; integrate differential privacy or secure enclaves for sensitive data.
- Tools/products/workflows: Kubernetes on-prem clusters; confidential computing; private RAG for domain-specific context.
- Assumptions/dependencies: Adequate local compute; acceptable performance from smaller LLMs; internal security approvals.
- Streaming and online feature evolution with data drift handling
- Sectors: e-commerce, ad-tech, IoT, energy
- What to do: Extend FAMOSE to operate on streaming data (rolling CV, online mRMR) and automatically refresh features when drift or performance degradation is detected.
- Tools/products/workflows: Drift detectors, event-time windows, scheduled re-generation, canary deployments for feature updates.
- Assumptions/dependencies: Robust streaming infra; latency constraints; stable monitoring signals.
- Domain-grounded agents via RAG-enhanced feature ideation
- Sectors: healthcare (clinical guidelines), energy (grid ops), manufacturing (process know-how)
- What to do: Inject curated domain knowledge (RAG) before feature generation to improve relevance on specialized tasks (e.g., clinical risk indices, physical constraints).
- Tools/products/workflows: Domain KBs, RAG pipelines, guardrails to prevent leakage from text sources.
- Assumptions/dependencies: High-quality, updated knowledge bases; relevance filtering; copyright/licensing compliance.
- Time series and multi-label extensions
- Sectors: energy load forecasting, supply chain, recommender systems
- What to do: Extend methodology for lagged/seasonal features, multi-horizon targets, and multi-label classification; add time-aware CV and leakage prevention.
- Tools/products/workflows: Specialized time-series agents, feature templates (Fourier terms, holiday effects), hierarchical forecasting support.
- Assumptions/dependencies: Accurate timestamps; control for lookahead bias; additional evaluation metrics (MAPE, F1-micro/macro).
- Human-in-the-loop review and A/B feature experimentation
- Sectors: product analytics, marketing, ops
- What to do: Build UI for reviewing agent proposals, approving deployments, and running A/B tests on feature sets to quantify incremental contribution in production.
- Tools/products/workflows: Feature diff views, risk flags, A/B orchestration, gating via approval workflows.
- Assumptions/dependencies: Product experimentation platform; statistical power; organizational processes for sign-off.
- Robustness benchmarking across LLMs and cost optimization
- Sectors: software (MLOps)
- What to do: Systematically evaluate FAMOSE across LLMs (Sonnet 3.5 V2, DeepSeek-R1, others), token budgets, and prompt variants; auto-route tasks to best-value models.
- Tools/products/workflows: LLM router, performance-cost trade-off dashboards, automated ablation tests.
- Assumptions/dependencies: Access to multiple LLMs; standardized benchmarks; reproducible evaluation harness.
- Edge/IoT-optimized feature sets
- Sectors: robotics, manufacturing, smart energy
- What to do: Generate compact, computation-light features tailored for edge devices to reduce on-device latency while maintaining accuracy.
- Tools/products/workflows: Hardware-aware pruning; feature-inference profiling; deployment toolchains for embedded systems.
- Assumptions/dependencies: Hardware constraints known; efficient preprocessing; local inference libraries.
- Organizational “canonical features” and governance
- Sectors: large enterprises
- What to do: Establish central catalogs of vetted FAMOSE-generated features with provenance and lifecycle management, reducing duplication and ensuring consistency.
- Tools/products/workflows: Feature store governance, semantic tagging, retirement schedules, peer review committees.
- Assumptions/dependencies: Strong data stewardship; buy-in from analytics teams; metadata completeness.
- Automated raw-signal discovery recommendations
- Sectors: product analytics, IoT, manufacturing
- What to do: Use agent feedback loops to identify missing raw inputs (e.g., propose collecting new sensors or logs) that could yield high-impact engineered features.
- Tools/products/workflows: “Instrumentation suggestions” reports; ROI analysis; data engineering backlog integration.
- Assumptions/dependencies: Ability to add new instrumentation; cross-team coordination; privacy and cost constraints.
- SaaS/API commercialization
- Sectors: software vendors, consultancies
- What to do: Offer FAMOSE as a hosted API or SaaS with tiered plans (batch jobs, streaming, governance add-ons) for clients needing automated feature engineering.
- Tools/products/workflows: Billing, usage metering, tenant isolation, compliance packs by sector.
- Assumptions/dependencies: Market demand; support model; security certifications (SOC2, HIPAA where relevant).
Collections
Sign up for free to add this paper to one or more collections.