- The paper presents a two-stage framework that combines supervised contrastive loss with a multi-class circle loss to optimize graded relevance in e-commerce search.
- It leverages LLM-based re-annotation, hard negative mining, and spelling augmentation to enhance semantic embedding separability and robustness.
- The approach achieves significant offline improvements in metrics like NDCG and online gains in add-to-cart and conversion rates.
Authoritative Summary of "Mine and Refine: Optimizing Graded Relevance in E-commerce Search Retrieval" (2602.17654)
Motivation and Problem Setting
The paper addresses graded, policy-driven relevance in embedding-based retrieval (EBR) systems for e-commerce search. E-commerce platforms operate with multicategory catalogs, noisy and long-tail queries, and require robust, scalable semantic search. Exact matches, substitutes, and complements must be properly represented, and retrieval systems must enforce clear boundaries in similarity scores for stable hybrid blending and thresholding. Traditional binary relevance training pipelines are inadequate for capturing these nuanced requirements, and naive hard negative mining can exacerbate label noise, compromising generalization—especially in long tail scenarios.
Mine and Refine Framework
The proposed solution is a two-stage contrastive training pipeline termed "Mine and Refine." The labeling workflow begins with human annotation following a three-level relevance guideline (relevant, moderately relevant, irrelevant), which is scaled via finetuning a lightweight LLM (gpt-4o-mini) achieving 87.6% 3-class accuracy and 98.8% within-1 accuracy. An engagement-guided audit, leveraging more capable LLMs and expert re-annotation, reduces label errors by 5.74%, ensuring policy alignment.
Stage 1 utilizes a Siamese multilingual two-tower encoder, initialized from a pretrained 0.1B parameter backbone and trained with supervised contrastive loss (SupCon). This stage forms a globally robust semantic space.
Stage 2 conducts offline mining of hard cases using ANN retrieval, re-annotates confusable pairs with the policy-aligned LLM, and trains with a novel multi-class extension of circle loss. This loss explicitly sharpens boundaries between relevance strata, addressing similarity score separability for downstream serving and thresholding.
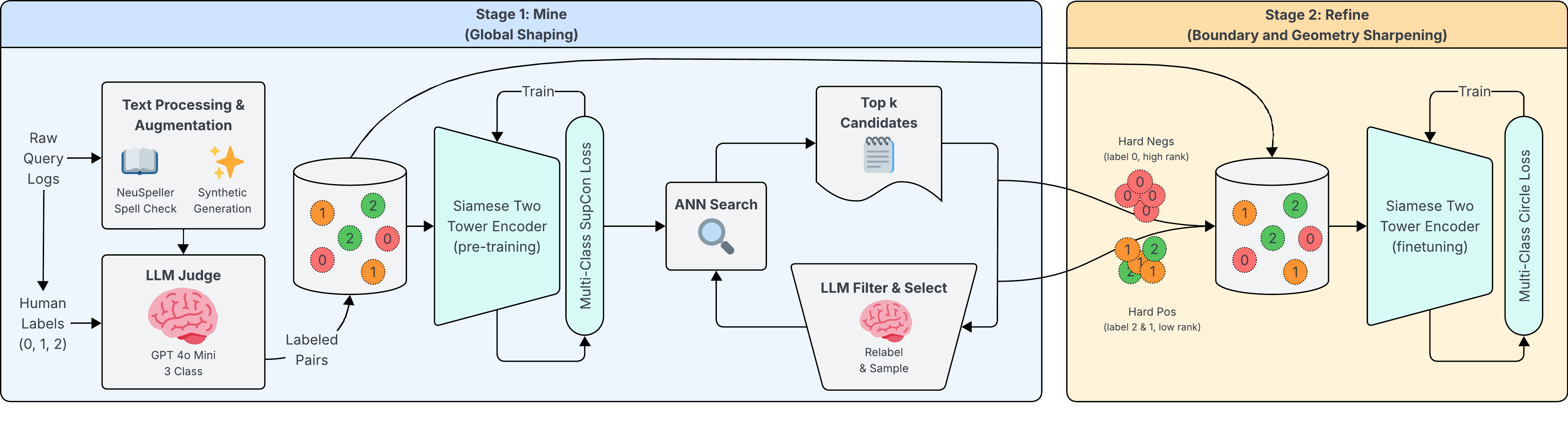
Figure 1: Mine and Refine: Stage 1 uses SupCon, Stage 2 uses circle loss with self-pacing and definite convergence, enforcing strong separation among relevance levels.
Model Design and Data Augmentation
The architecture is based on a Siamese encoder with dual projection heads, facilitating efficient real-time query encoding. Item representations are constructed by concatenating item names with taxonomy paths, enhancing semantic discrimination. Synthetic queries are generated from item features for items lacking positive query-item pairs, and labeled with the finetuned LLM. Robustness to misspellings is achieved by additive spelling augmentation, using NeuSpell's probabilistic noise injection and retaining both clean and noisy variants. This enrichment is shown to improve both recall and precision on misspelled queries, outperforming regularization-based and in-place substitution methods.
Contrastive Objective and Circle Loss Extension
The supervised contrastive loss is extended for three-level relevance, leveraging label-aware batch composition. Circle loss, originally introduced for binary metric learning, is generalized to multi-class relevance. Adaptive weighting and precise margin boundaries between classes (Δ2,p,Δ1,p,Δ1,n,Δ0,n) enforce intra-class compactness and inter-class separability.
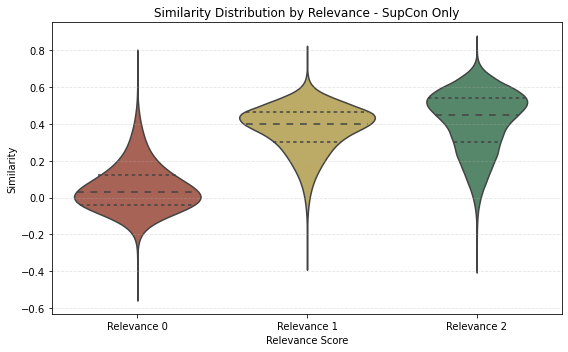
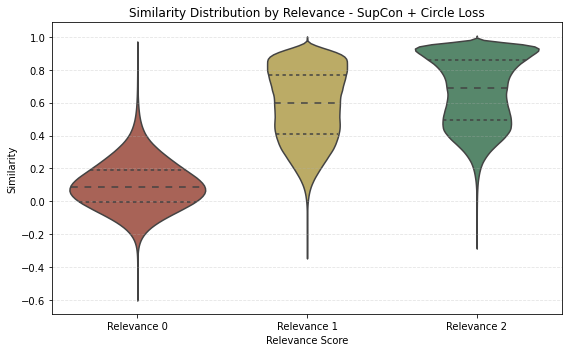
Figure 2: Violin plots demonstrate sharper similarity score distribution separability after circle loss refinement.
Offline mining is tuned to extract both hard negatives (label 0 ranking high among ANN results) and hard positives (labels 1/2 ranking low), with careful retention of original negatives to prevent catastrophic forgetting. This pipeline achieves robust geometric calibration of the semantic space, critical for downstream blending and stable ranking.
Empirical Evaluation and Results
Offline experiments are conducted on a "Golden Eval Set" comprising 155M query-item pairs, and side-by-side evaluations with 12K queries deployed in production settings. NDCG@10, Recall@K, and Precision@K metrics are reported. Compared to a strong pretrained encoder baseline (>0.6B parameters), the Siamese SupCon + Circle Loss model achieves up to 10.39% NDCG@10 improvement and consistent recall/precision gains. Side-by-side evaluations yield 2.32% absolute improvement in NDCG@10 over hybrid baselines.
Online A/B testing over one month, with a 50% traffic split, demonstrates statistically significant lifts: add-to-cart rate +2.5%, conversion rate +1.1%, and gross order value +0.9% (p<0.05), with stability in downstream business logic despite only swapping the retriever component.
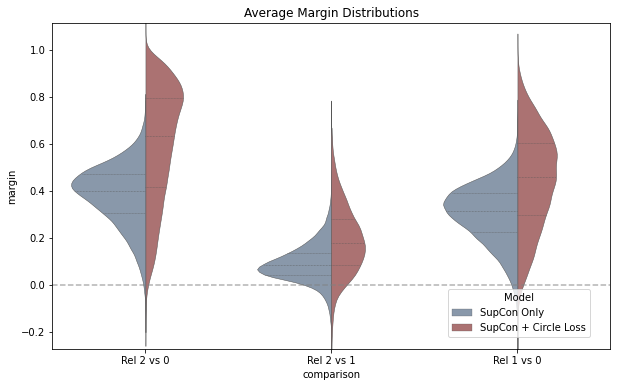
Figure 3: Violin plots for query-level average margins quantify increased separability of relevant vs. irrelevant item pairs after refinement.
Ablation Studies
The paper conducts extensive ablations on encoder architecture, taxonomy enrichment, synthetic query augmentation, spelling variation strategies, and mining thresholds. Key findings:
- Siamese encoders consistently outperform asymmetric dual encoders.
- Two-level taxonomy enrichment optimally balances improved category discrimination and semantic noise.
- Selective low-ratio synthetic query injection for items without positives, combined with catalog enrichment, boosts both retrieval metrics and similarity margin metrics.
- Additive spelling augmentation yields robust improvements; regularization and full substitution degrade performance.
- Circle loss is more robust to hard negatives than triplet loss, supporting aggressive mining without training instability.
Implications and Future Directions
The "Mine and Refine" pipeline advances graded relevance calibration in EBR systems under real-world policy constraints. Explicit multi-class margin enforcement and robust offline mining yield models that can reliably support hybrid blending, threshold-based serving, and rankers in large-scale, production e-commerce environments. The empirical gains in online metrics underscore practical business impact.
The methodology is extensible to other domains requiring nuanced retrieval and semantic score calibration (e.g., marketplace, recommendation). Future directions include automating further stages of hard positive augmentation, integrating multimodal signals, and leveraging dynamic LLM-powered relevance annotation with continual feedback.
Conclusion
This paper introduces a structured, two-stage optimization framework for graded relevance in semantic search. The integration of LLM-driven scalable labeling, robust supervised contrastive training, and multi-class circle loss refinement enables stable, high-performing retrieval embeddings. The approach exhibits measurable improvements in both relevance metrics and business objectives, setting a new practical standard for policy-aligned semantic retrieval in e-commerce.