EgoPush: Learning End-to-End Egocentric Multi-Object Rearrangement for Mobile Robots
Abstract: Humans can rearrange objects in cluttered environments using egocentric perception, navigating occlusions without global coordinates. Inspired by this capability, we study long-horizon multi-object non-prehensile rearrangement for mobile robots using a single egocentric camera. We introduce EgoPush, a policy learning framework that enables egocentric, perception-driven rearrangement without relying on explicit global state estimation that often fails in dynamic scenes. EgoPush designs an object-centric latent space to encode relative spatial relations among objects, rather than absolute poses. This design enables a privileged reinforcement-learning (RL) teacher to jointly learn latent states and mobile actions from sparse keypoints, which is then distilled into a purely visual student policy. To reduce the supervision gap between the omniscient teacher and the partially observed student, we restrict the teacher's observations to visually accessible cues. This induces active perception behaviors that are recoverable from the student's viewpoint. To address long-horizon credit assignment, we decompose rearrangement into stage-level subproblems using temporally decayed, stage-local completion rewards. Extensive simulation experiments demonstrate that EgoPush significantly outperforms end-to-end RL baselines in success rate, with ablation studies validating each design choice. We further demonstrate zero-shot sim-to-real transfer on a mobile platform in the real world. Code and videos are available at https://ai4ce.github.io/EgoPush/.




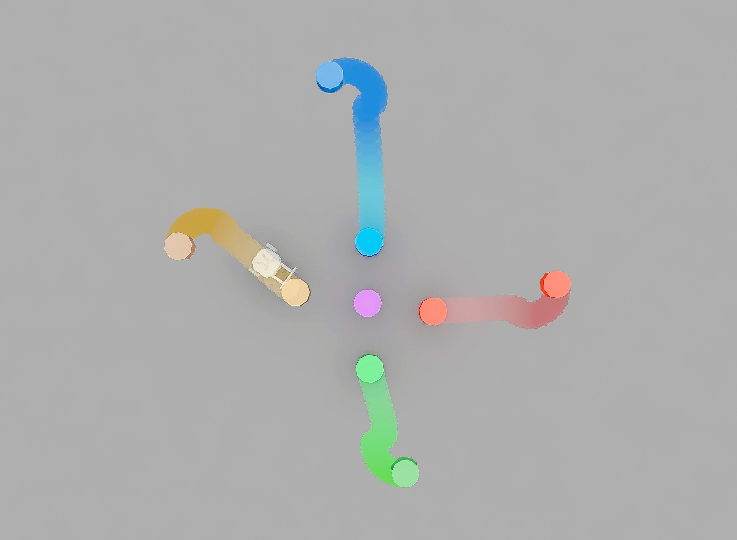
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper shows how to teach a small mobile robot to rearrange several objects by pushing them into neat patterns (like a cross or a line) using only what it “sees” from its own camera, just like you or I would with our eyes. The robot doesn’t rely on a global map or GPS-like coordinates; instead, it learns to keep track of where things are relative to itself and to each other, even when objects block its view for a moment.
What questions the researchers asked
- Can a robot push multiple objects into specific formations using only its own forward-facing camera (an egocentric view), without a global map?
- How can the robot learn to handle long, multi-step tasks where objects often go in and out of view?
- Can we train a robot in simulation and then use the same skills in the real world without extra training?
How they approached the problem (in simple terms)
Think of a coach and a player:
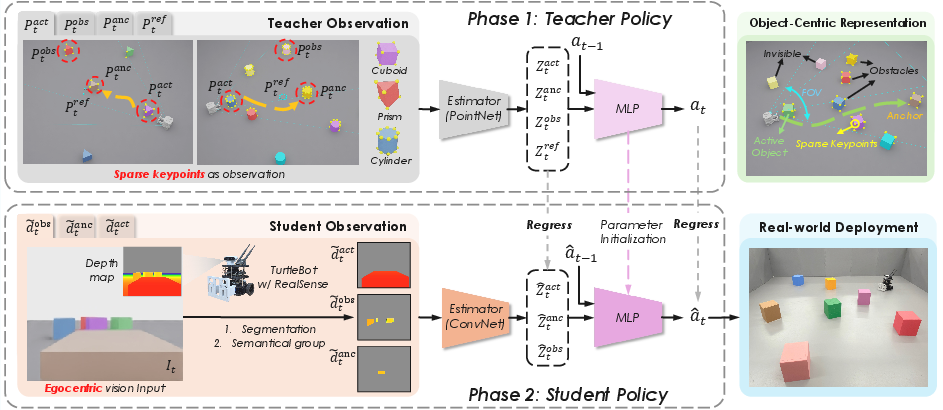
- The “coach” is a teacher policy trained in simulation. It gets a simplified, clean summary of the scene—just a few important points on each object (called “keypoints”)—instead of messy raw images. But to make sure the player can imitate it later, the coach is only allowed to “see” what would be visible from the robot’s camera, and only when key objects are centered—so the coach can’t cheat by using information the player won’t have.
- The “player” is a student policy that learns from raw camera depth images (how far things are), grouped by which object is being pushed, which is the anchor (the target reference), and which are obstacles.
Here are the main ideas they used:
1) Object roles and relative relationships
The robot doesn’t try to memorize exact world coordinates. Instead, it thinks in terms of roles:
- Active object: the one it’s currently pushing.
- Anchor: the object that defines the target arrangement (for example, the center of a cross).
- Obstacles: everything else to avoid.
This “object-centric” view lets the robot focus on how things relate to each other—like “push this block near that anchor”—instead of absolute positions.
2) A teacher that doesn’t cheat
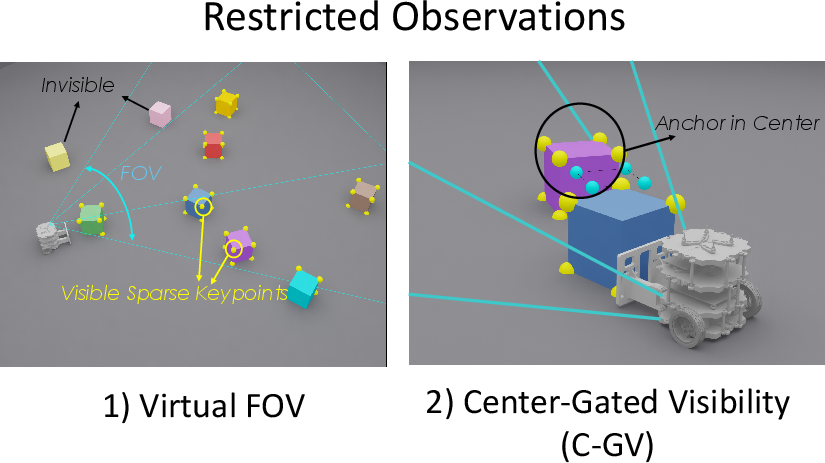
Even though the teacher uses clean geometric points (keypoints) to learn faster, the team restricted the teacher to:
- A limited field of view that matches the robot’s camera.
- Only seeing the “reference target” when the anchor is actually centered in view.
This forces the teacher to behave in ways the student can copy, like turning to keep important objects visible. It encourages “active perception”: moving not just to push, but to see better.
3) Breaking the task into stages with time bonuses
Long tasks are hard to learn if a robot only gets a “success/fail” at the end. The team split each rearrangement into smaller stages (for example, “reach the object” then “place it near the anchor with the right angle”), and gave a bigger reward if a stage is finished sooner. This is like giving more points for finishing a level quickly, which helps the robot learn efficient habits.
4) Teaching the student with distillation
The student learns by imitating the teacher while acting in the world (an interactive process similar to DAgger). But instead of just copying actions, the student also tries to match the teacher’s sense of how objects relate to each other. The student sees depth images, uses simple color-based masks to separate objects by role, and learns both:
- What action to take now.
- How the active, anchor, and obstacles relate in space (so it develops the same “spatial common sense” as the teacher).
5) From simulation to the real world
They practiced in simulation with many variations (such as noisy depth), then ran the same policy on a real TurtleBot with an Intel RealSense camera. They also cleaned up real camera noise to reduce the mismatch between sim and real.
What they found and why it matters
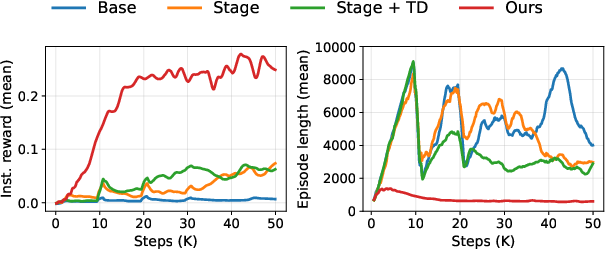
- The robot successfully formed patterns like crosses and lines by pushing cubes, cylinders, and triangular prisms—handling obstacles and occlusions.
- Their method beat standard end-to-end RL approaches that learn directly from images. Those methods struggled with partial views and the long sequence of decisions needed.
- A mapping-based baseline (which builds a top-down map and plans) also struggled because small pose mistakes add up over time, especially when objects move during pushing.
- Making the teacher follow the same visibility limits as the student was crucial. If the teacher had access to global info, it often produced actions the student couldn’t explain from camera images, and the student failed.
- Breaking the task into stages with time-weighted rewards sped up learning and led to more reliable success.
- In real-world tests, the trained student policy achieved an 80% success rate on a multi-object cross arrangement task without extra fine-tuning, showing good transfer from simulation.
Why this is important
- Works without a global map: This is closer to how people move objects in real rooms—using what they see, not perfect coordinates.
- Handles long, multi-step tasks: The staged rewards and visibility-aware teacher help robots learn complicated sequences that take many actions to finish.
- Robust to occlusions: By focusing on relative relationships and encouraging the robot to move to keep important things in view, the method copes with objects blocking each other.
- Practical and adaptable: Training in simulation and going straight to a real robot makes it practical for real environments like homes, warehouses, or offices.
- A step toward more autonomous robots: The approach blends perception and action in a natural way, moving robots closer to doing useful tidying, sorting, or setup tasks around people.
In short, this paper shows a smart way to teach robots to rearrange multiple objects by pushing, using only a forward-facing camera—by giving them the right goals, the right “teacher,” and a way to learn from what they can actually see.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed to be actionable for future research.
- Assumed role priors: The method presupposes known semantic roles (active object, anchor, obstacles) and a fixed target configuration per task category. How to infer roles online from task instructions, natural language, or scene context, and handle dynamic or changing anchors, remains open.
- Goal-conditioning: Relational distillation relies on the invariance of anchor-to-target pose across episodes; the student does not receive explicit goal inputs. It is unclear how to adapt the policy to variable, user-specified goals at runtime or to multiple goal types without retraining.
- Segmentation robustness: Experiments rely on color-coded objects and HSV thresholding. The robustness of instance grouping under realistic, cluttered textures, lighting changes, partial occlusions, overlapping instances, and segmentation errors (even with modern zero-shot models) is not evaluated.
- Instance aggregation losses: Summing per-instance depth into group-wise layers discards instance identity and fine-grained geometry. Whether per-instance representations, attention over instances, or set encoders yield better performance—especially with many obstacles or diverse shapes—remains unexplored.
- Memory and belief tracking: The student policy is primarily reactive and lacks explicit spatial memory. Systematic evaluation and integration of recurrent models (GRU/LSTM), object tracking, or learned belief maps to handle prolonged occlusions and narrow-pass “goal-seek vs. path-seek” deadlocks is needed.
- Teacher constraints sensitivity: The virtual FOV mask and center-gated reference visibility are heuristic. Their sensitivity to camera FOV, placement, robot size, scene scale, and dynamics is unreported. Learning or adapting gating parameters across platforms and environments is an open direction.
- Stage decomposition generality: Rewards decompose tasks into reach/place phases with a stage timer. How to generalize to tasks with more stages, unknown stage boundaries, or automatically discovered subgoals (e.g., via hierarchical RL or option discovery) is unaddressed.
- Long-horizon scalability: Performance and training stability with larger numbers of objects, larger arenas, longer horizons, and more complex arrangements (beyond 5 boxes and cross/line formations) are not characterized.
- Physical variability coverage: While domain randomization is mentioned, sensitivity to object size, mass, friction, contact compliance, surface properties, and robot dynamics is not quantified. Systematic robustness analysis across wide physical parameter ranges is missing.
- Deformable/articulated objects: The approach is evaluated on rigid primitives (cube, cylinder, prism). Handling deformable, articulated, tall, or irregular objects with complex contact dynamics remains open.
- Dynamic obstacles and moving anchors: Scenes with independently moving obstacles or anchors (e.g., human interference) are not tested. Policies for re-planning under dynamic partial observability are unexplored.
- Safety and contact risk: Collisions trigger early termination but are not penalized or modeled for safety. Strategies for risk-aware pushing, damage avoidance, and compliance on real hardware require investigation and metrics.
- Sim-to-real breadth: Real-world evaluation is limited (10 episodes, one arena, one robot, loose success metric). Broader studies across different robots, cameras, environments, lighting, surfaces, and on-board compute constraints (latency, bandwidth) are needed.
- Depth sensing limitations: Reliance on depth denoising via Navier–Stokes inpainting is noted, but robustness to common depth failures (transparent/reflective materials, glare, multipath) and calibration drift is not assessed.
- Active perception planning: While constrained teacher induces active perception, explicit planning for view selection or information-gain-driven exploration is absent. Measuring and optimizing the trade-off between keeping goals in view and inspecting feasible corridors remains an open problem.
- Role selection for multi-object sequences: The framework assumes a known active object per stage. Algorithms for selecting the next active object (when multiple candidates exist), scheduling, and global arrangement planning are not provided.
- Distillation objectives: The relational distillation aligns pairwise cosine similarities of latent groups but ignores the privileged reference latent. Exploring alternative alignment strategies (e.g., contrastive learning, teacher-student mutual information, graph-structured relations) could improve transfer.
- Teacher signal realism: The teacher uses privileged sparse keypoints unavailable in real deployments. Learning teachers from less privileged signals (e.g., noisy detections), discovering keypoints unsupervised, or co-training with student observations is an open direction.
- Sample efficiency and compute budget: Claims of improved efficiency are not benchmarked under matched compute/data budgets. Systematic comparisons of wall-clock time, environment interactions, and resource usage across baselines are missing.
- Reward shaping generalization: The time-decayed, stage-local completion rewards work for reach/place tasks, but principled guidance on designing, tuning, and verifying reward schemes for different rearrangement families is absent.
- Policy interpretability: The object-centric latent space is central but not probed. Tools to interpret learned relations, diagnose failure modes, and verify geometric reasoning (e.g., probing with controlled occlusion/perturbation tests) would strengthen understanding.
- Contact skill diversity: The policy focuses on pushing. Extending to other non-prehensile skills (sliding, pivoting, toppling, dynamic pushes) and learning when to switch among them is unaddressed.
- Camera configuration and viewpoint control: The impact of camera height, tilt, and placement on observability is not studied. Policies for actively adjusting viewpoint (e.g., pan/tilt units) to mitigate occlusions are unexplored.
- Multi-agent extension: Coordination among multiple robots for collaborative rearrangement under egocentric views and partial observability is not considered.
Practical Applications
Immediate Applications
Below are practical, near-term uses that can be prototyped or piloted now, drawing on the paper’s demonstrated zero-shot sim-to-real transfer on a TurtleBot and the released code.
- Robotics/Industry: On-demand obstacle clearance for AMRs in dynamic spaces
- Use case: An autonomous mobile robot (AMR) egocentrically identifies and gently pushes light, movable obstacles (e.g., small boxes, foam blocks, stray totes) out of aisles to restore traversability when global maps/SLAM are unreliable due to dynamics or texture sparsity.
- Sectors: Warehousing, manufacturing, micro-fulfillment, back-of-house retail.
- Tools/products/workflows:
- A ROS skill package (“egocentric push-and-clear”) using a single RGB-D camera, instance segmentation (HSV / SAM2), and EgoPush’s depth-layered object grouping.
- Constrained-teacher RL + DAgger distillation workflow to retarget the skill to site-specific obstacles.
- Safety overlays (bumpers, force/torque limits) and restricted zones.
- Assumptions/dependencies:
- Obstacles must be safe and designed to be pushed (weight/shape/friction within robot limits).
- Reliable instance masks (color tags or robust zero-shot segmentation).
- Clear operational SOPs and safety monitors for contact behavior.
- Facilities/Event management: Chair/table alignment into patterns without maps
- Use case: Arrange chairs in rows/lines or around an anchor table using only egocentric vision, handling occlusions and limited field of view.
- Sectors: Hospitality, conference centers, education (classrooms).
- Tools/products/workflows:
- “Chair aligner” mode for lightweight AMRs with a front pusher attachment.
- Pre-define anchor(s) and target formations; deploy the student policy with limited on-site fine-tuning.
- Optional colored sleeves/tags for easier segmentation initially.
- Assumptions/dependencies:
- Controlled environment with low foot traffic during operation.
- Objects with geometries comparable to demonstration (box-/chair-like on flat floors).
- Adequate camera FOV and lighting for segmentation.
- Retail/Service: Cart or queue-barrier realignment
- Use case: Align carts or lightweight stands into lines when they drift, reducing staff effort.
- Sectors: Retail, airports, event venues.
- Tools/products/workflows:
- “Line formation” policy (as in the paper’s line/cross targets) adapted to wheeled objects.
- Training with domain randomization to account for rolling friction and geometry variation.
- Assumptions/dependencies:
- Regulations on contact with customer-facing assets; visibility of the anchor object.
- Reliable detection of reflective surfaces (rolling carts) in depth.
- Academia/Research: Benchmarking and method development for egocentric non-prehensile manipulation
- Use case: Evaluate long-horizon, contact-rich rearrangement under partial observability with a reproducible pipeline and metrics.
- Sectors: Robotics research, ML/RL, computer vision.
- Tools/products/workflows:
- Released codebase and Isaac Lab simulation tasks; plug-and-play PPO teacher, DAgger student, stage-wise reward templates.
- Object-centric latent encoders and relational distillation modules for new tasks.
- Assumptions/dependencies:
- Access to GPU compute for large-batch simulation; willingness to adopt instance segmentation (color-coded or zero-shot).
- Software/ML: Deployable pipeline components
- Use case: Integrate components into existing robotics stacks to improve sample efficiency and robustness under partial observability.
- Sectors: Software tooling, robotics middleware, RL platforms.
- Tools/products/workflows:
- Constrained-teacher RL (virtual FOV masking, center-gated goal cues) as a library.
- Depth-layer generation from instance masks to create stable, constant-dimension inputs.
- Stage-wise, time-decayed reward templates for long-horizon credit assignment.
- Assumptions/dependencies:
- Availability of instance segmentation; synchronization between RGB and depth; real-time inference budget.
- Daily life/Hobbyist: Home/garage tidying of box-like items
- Use case: A small mobile robot pushes shoe boxes/storage bins into neat configurations around a reference point (e.g., a shelf).
- Sectors: Consumer robotics (prototype/hobbyist).
- Tools/products/workflows:
- ROS packages + Jetson-class compute; printed color tags for segmentation.
- Safety constraints on speed and force.
- Assumptions/dependencies:
- Flat floors; movable, robust items; controlled household environments.
- User-supervised operation due to safety and perception limits.
Long-Term Applications
These applications require further research and engineering (e.g., stronger segmentation beyond color cues, memory for occlusions, larger action spaces, safety certification, heavier objects, multi-agent coordination).
- General-purpose, map-free rearrangement in logistics and manufacturing
- Use case: AMRs perform precise multi-object staging via non-prehensile pushing, pre-positioning totes/pallet skids for pick stations or robots, without reliance on global localization.
- Sectors: Warehousing, manufacturing.
- Potential products/workflows:
- “Rearrangement AMR” line with interchangeable pushers/skirts; integration with WMS/MES.
- Hybrid workflows combining egocentric pushing with intermittent global references (fiducials/overhead cameras) for QA.
- Assumptions/dependencies impacting feasibility:
- Robust perception of diverse, unlabeled objects and reflective materials.
- Memory-enabled policies (recurrent latent state) to handle long occlusions and narrow passages.
- Comprehensive safety and compliance for contact in shared workspaces.
- Hospital/Healthcare support: Corridor clearance and asset positioning
- Use case: Adjust positions of IV stands, stools, small carts to keep corridors operative or prepare rooms.
- Sectors: Healthcare operations.
- Potential products/workflows:
- Hospital-certified AMR modules with tactile/force sensing and conservative speeds.
- Integration with hospital scheduling and facility maps for constraints.
- Assumptions/dependencies:
- Strict safety/privacy standards for egocentric cameras; HIPAA-adjacent governance.
- High reliability around patients/staff; precise force control; non-damaging contact policies.
- Construction and field robotics: Site tidying and debris management
- Use case: Clear pathways by pushing lightweight materials or bins in semi-structured outdoor sites where SLAM is degraded.
- Sectors: Construction, utilities.
- Potential products/workflows:
- Ruggedized bases with stronger pushers; learned policies adapted to uneven terrains and high sensor noise.
- Assumptions/dependencies:
- Robust depth sensing outdoors; handling dust, glare; larger action forces; expanded safety envelopes.
- Home service robots: Room reconfiguration and assistive rearrangement
- Use case: Arrange furniture (chairs, small tables), organize clutter around anchors (e.g., a central table) via voice-specified patterns.
- Sectors: Consumer robotics, eldercare assistive tech.
- Potential products/workflows:
- High-level intent interfaces (“make a circle around the table”) feeding into an egocentric rearrangement stack.
- Mixed non-prehensile + prehensile manipulation pipelines.
- Assumptions/dependencies:
- Strong generalization across object categories; robust segmentation without tags; learning-to-remember for occlusions.
- Household safety certification; reliable operation around people and pets.
- Multi-robot rearrangement and coordination
- Use case: Teams of robots form complex configurations (lines/grids) of many objects under partial, egocentric observability.
- Sectors: Warehousing, event setup, public venues.
- Potential products/workflows:
- Communication-efficient, role-based object-centric latents for coordination; shared anchors; collision-aware policies.
- Assumptions/dependencies:
- Multi-agent credit assignment and safety guarantees; standardized V2V protocols; robust failure recovery.
- Software/ML platforms: Foundation policies and memory-enabled egocentric manipulation
- Use case: Train generalizable, object-centric rearrangement policies with recurrent memory (GRU/LSTM) for belief maintenance through occlusion, then distill into lightweight onboard students.
- Sectors: ML tooling, simulation platforms, robot OS.
- Potential products/workflows:
- Pretrained “Egocentric Rearrangement Foundation Model” with relational distillation; adapters for specific robots.
- Tooling that automates FOV constraints, reward shaping, and online DAgger for new tasks.
- Assumptions/dependencies:
- Large-scale simulation and domain randomization; standardized datasets and benchmarks; compute availability.
- Policy and standards: Governance for contact-based mobile manipulation
- Use case: Establish safety envelopes, permissible contact forces, and privacy policies for camera-equipped contact robots operating in shared spaces.
- Sectors: Public policy, standards bodies, risk management.
- Potential products/workflows:
- Certification frameworks for non-prehensile AMR behaviors; facility design guidelines (e.g., push-friendly casters, visual tags).
- Assumptions/dependencies:
- Consensus across manufacturers/operators; testing protocols; liability frameworks for contact interactions.
- Education and workforce development
- Use case: Curricula and competitions focused on long-horizon egocentric rearrangement, active perception, and teacher-student distillation.
- Sectors: Higher education, vocational training.
- Potential products/workflows:
- Course kits with simulated and real robot exercises; standardized challenge tasks (cross/line formations).
- Assumptions/dependencies:
- Accessible hardware (TurtleBot-class) and compute; classroom-safe environments.
Notes on Cross-Cutting Dependencies
- Perception: Reliable instance segmentation from a single egocentric RGB-D camera; initial deployments may need color tags or carefully chosen object palettes. Progress toward robust zero-shot models (e.g., SAM2, DINOv3) reduces this dependency.
- Objects and environments: Objects must be pushable, with predictable friction/weight; flat floors are assumed in the current demos; rough terrain and highly reflective/transparent surfaces remain challenging.
- Compute and latency: Real-time inference on embedded or edge servers; ensure connectivity and fail-safe behavior if links drop.
- Safety and compliance: Policies for contact forces, human proximity, and privacy; conservative speed limits and bump sensors/tactile feedback are advised.
- Training workflow: Access to high-fidelity simulation (e.g., Isaac Lab), domain randomization, and on-site fine-tuning; adoption of constrained teacher RL and stage-wise rewards for long-horizon tasks.
Glossary
- Active perception: A strategy where an agent deliberately moves to improve what it can see and sense to make better decisions. "This induces active perception behaviors that are recoverable from the student’s viewpoint."
- Asymmetric actor-critic: A reinforcement learning setup where the actor and critic receive different observations (e.g., the critic gets privileged information). "asymmetric actor-critic"
- Behavior cloning (BC): Supervised learning that imitates expert actions directly from observations. "We avoid pure BC to minimize the mean squared error (MSE) between student and teacher actions"
- Center-gated visibility: A constraint that only reveals a reference target when the anchor object is centrally visible to encourage visually grounded actions. "This approach incorporates two key designs: virtual egocentric FOV masking and center-gated visibility for privileged reference keypoints."
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "We compute the pairwise cosine similarity matrix for the shared groups $\mathcal{K}_{\text{shared} = \{\mathrm{act, anc, obs}\}$:"
- Cross-modal distillation: Training a student policy (e.g., from vision) to imitate a teacher trained with privileged non-visual state. "A natural direction to improve sample efficiency is cross-modal distillation: training a privileged teacher with low-dimensional environment states via online RL, then distilling its behavior into an egocentric visual student"
- DAgger: An interactive imitation learning method that aggregates data by querying the expert during policy rollouts. "via imitation learning (behavior cloning) or interactive variants (DAgger~\cite{ross2011dagger})"
- Differential-drive kinematics: The motion model that maps linear and angular velocities to left/right wheel speeds for a two-wheeled robot. "which are then converted into left/right wheel velocities via differential-drive kinematics and executed by PD controller."
- Domain randomization: Randomly varying simulation parameters during training to improve transfer to real-world variability. "and apply domain randomization to key physical parameters."
- Egocentric vision: Perception from the robot’s own viewpoint rather than a global or third-person perspective. "from purely egocentric visual observations."
- Field of View (FOV): The angular extent of the observable world captured by the camera. "We utilize an RGB-D camera with a horizontal Field of View (FOV) and a resolution of pixels."
- Frustum: The 3D pyramidal region representing what the camera can see, used to mask out non-visible points. "we define a robot-pose-based viewing frustum and uniformly mask points outside the frustum or beyond a maximum range."
- Indicator function: A function that returns 1 if a condition is true and 0 otherwise, commonly used in reward formulations. "and is the indicator function that equals $1$ if the condition holds and $0$ otherwise."
- Instance-level segmentation: Identifying and separating individual object instances in an image. "Specifically, we run instance-level segmentation on the RGB image to obtain a binary mask for each visible object instance "
- Latent space: A learned low-dimensional representation capturing essential structure (e.g., relative object relations). "EgoPush designs an object-centric latent space to encode relative spatial relations among objects, rather than absolute poses."
- Monte Carlo Tree Search (MCTS): A planning algorithm that uses randomized simulations to evaluate action sequences. "\citet{song2020iros} formulates planar sorting with Monte Carlo Tree Search to reason over contact-induced transitions"
- Navier–Stokes inpainting: A PDE-based method to fill in missing image/depth data by modeling fluid-like propagation. "applying the Navier-Stokes inpainting algorithm~\cite{bertalmio2001ns,zhang2026highspeedvisionbasedflightclutter} to denoise in real world."
- Non-prehensile manipulation: Manipulating objects without grasping, e.g., pushing or sliding. "Non-prehensile manipulation is a practical cornerstone for mobile robots in clutter"
- Object-centric representation: Encoding scenes around object roles (active/anchor/obstacle) to reason about their relations. "we first introduce an object-centric latent representation that abstracts the scene into task-relevant roles"
- Odometry drift: Accumulating pose error over time when integrating motion estimates, degrading map consistency. "without GT pose, action-integrated odometry drift accumulates over long-horizon, contact-rich episodes and undermines mapping and planning consistency"
- Parallel differentiable simulation: Running many differentiable physics simulations in parallel to accelerate learning. "parallel differentiable simulation~\cite{you2025accelerating}"
- PD controller: A proportional-derivative controller that computes control inputs based on error and its rate of change. "and executed by PD controller."
- Proprioception: Internal sensing of a robot’s own state (e.g., joint angles, velocities) used alongside vision. "maps high-dimensional images (often fused with proprioception) directly to actions."
- Proximal Policy Optimization (PPO): A stable on-policy RL algorithm that constrains policy updates. "We train the teacher policy using Proximal Policy Optimization (PPO)~\cite{schulman2017ppo}"
- Relational distillation: Transferring the teacher’s structured relations among entities to the student via representation alignment. "we introduce a relational distillation loss to bridge the representation gap between the privileged PointNet-based teacher and the vision-based student."
- Sim-to-real transfer: Deploying policies trained in simulation to real robots without additional fine-tuning. "We further demonstrate zero-shot sim-to-real transfer on a mobile platform in the real world."
- SLAM: Simultaneous Localization and Mapping; estimating a map and robot pose from sensor data. "texture-sparse scenes challenge SLAM or visual odometry to maintain consistent localization during object motion"
- Stage-wise rewards: Rewarding sub-goal completion per stage to improve learning in long-horizon tasks. "we introduce stage-wise rewards computed per stage (SWR) to encourage sub-goal attainment"
- Teacher–student distillation: Training a privileged teacher policy and transferring its behavior to a visual student. "privileged RL teacher--visual student distillation"
- Temporal credit assignment: Determining which past actions led to current outcomes in long sequences. "the long-horizon nature of multi-object tasks presents another bottleneck: temporal credit assignment."
- Visual odometry: Estimating motion by analyzing visual input over time. "texture-sparse scenes challenge SLAM or visual odometry to maintain consistent localization during object motion"
- Waypoint-tracking controller: A controller that converts target waypoints into low-level velocity commands. "which we convert to the same local velocity action interface via a waypoint-tracking controller with identical action bounds."
- Yaw error: The difference in orientation around the vertical axis between the object and its target. " is the yaw error between the active object and its target orientation"
- Zero-shot segmentation: Obtaining segmentation masks without task-specific training, leveraging generalized models. "Recent progress in zero-shot segmentation models~\cite{ravi2024sam2segmentimages,simeoni2025dinov3} suggests that obtaining such masks from RGB can be reliable in real scenes;"
- Zero-shot sim-to-real transfer: Deploying a simulated-trained policy to the real world without any additional training. "We further demonstrate zero-shot sim-to-real transfer on a mobile platform in the real world."
Collections
Sign up for free to add this paper to one or more collections.