Learning Smooth Time-Varying Linear Policies with an Action Jacobian Penalty
Abstract: Reinforcement learning provides a framework for learning control policies that can reproduce diverse motions for simulated characters. However, such policies often exploit unnatural high-frequency signals that are unachievable by humans or physical robots, making them poor representations of real-world behaviors. Existing work addresses this issue by adding a reward term that penalizes a large change in actions over time. This term often requires substantial tuning efforts. We propose to use the action Jacobian penalty, which penalizes changes in action with respect to the changes in simulated state directly through auto differentiation. This effectively eliminates unrealistic high-frequency control signals without task specific tuning. While effective, the action Jacobian penalty introduces significant computational overhead when used with traditional fully connected neural network architectures. To mitigate this, we introduce a new architecture called a Linear Policy Net (LPN) that significantly reduces the computational burden for calculating the action Jacobian penalty during training. In addition, a LPN requires no parameter tuning, exhibits faster learning convergence compared to baseline methods, and can be more efficiently queried during inference time compared to a fully connected neural network. We demonstrate that a Linear Policy Net, combined with the action Jacobian penalty, is able to learn policies that generate smooth signals while solving a number of motion imitation tasks with different characteristics, including dynamic motions such as a backflip and various challenging parkour skills. Finally, we apply this approach to create policies for dynamic motions on a physical quadrupedal robot equipped with an arm.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching virtual characters and real robots to move in smooth, natural ways using reinforcement learning. The authors noticed that many learned controllers tell the character to make very fast, jittery movements that people and real robots can’t do. They propose a simple way to make these controllers calmer and more realistic, and they show it works for tough skills like backflips and parkour, and even on a real four-legged robot with an arm.
What questions were the researchers asking?
- How can we stop learned controllers from being “twitchy” and using super high‑frequency signals that look unnatural and don’t work well on real robots?
- Can we do this without lots of trial‑and‑error tuning for each task?
- Can we make the training fast and practical, even for complex skills?
How did they try to solve it?
The basic idea: teach smooth reactions, not just good results
Reinforcement learning is like training by trial and reward: the system tries things and gets points when it matches the target motion (like a walk, flip, or vault). The problem is that it can “cheat” by wiggling joints super fast to get more points. That looks bad and breaks on real hardware.
The authors’ solution is to teach the controller to be less sensitive—to not change its actions too much when the character’s state changes a little. Think of it like a car steering wheel: a good steering system doesn’t jerk wildly if you nudge it a tiny bit.
A “sensitivity penalty” (Action Jacobian penalty)
- The “Jacobian” is a math word for “how much does the output change when the input changes a tiny bit.”
- Here, the output is the action (the joint targets), and the input is the character’s current state (like joint angles and speeds).
- If this sensitivity is large, tiny state changes cause big action jumps—jerkiness.
- So they add a penalty during training that says: “Keep this sensitivity small.” This pushes the controller to be smoother.
Making the penalty fast and easy to use: Linear Policy Net (LPN)
Computing that sensitivity penalty is slow with a normal neural network. To fix that, the authors designed a special controller called a Linear Policy Net (LPN):
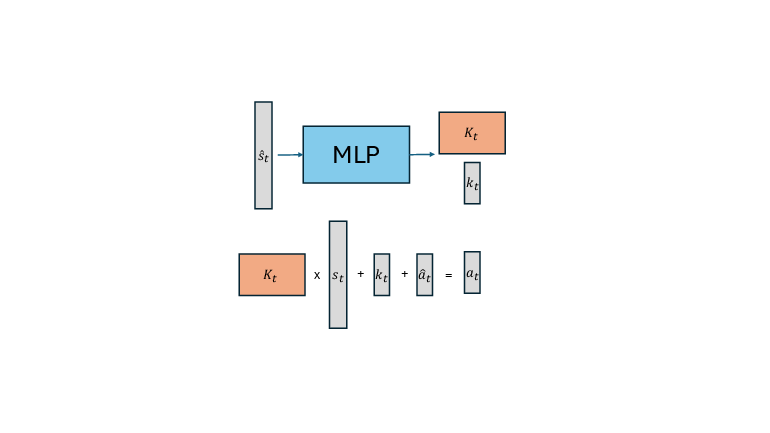
- Instead of directly outputting joint targets, the network outputs a simple “feedback rule” for each moment: a matrix and a vector that say “Action = Matrix × Current State + Vector + Reference Action.”
- Because this rule is linear in the current state, the sensitivity (the Jacobian) is just the matrix itself—no heavy math needed.
- That makes the penalty cheap to compute, training faster, and the final controller quick to run.
You can think of LPN like a smart “mixing board” that changes over time. At each moment, it sets simple sliders (the matrix) that turn the current state into a gentle, steady action. The network only needs to set those sliders from the task’s reference motion, keeping everything predictable and smooth.
What did they find?
The authors tested the method on a wide range of skills:
- Simulated human motions: walking, running, backflips, cartwheels, a table‑tennis footwork drill, and parkour skills like vaulting and wall climbing.
- A real quadruped robot with an arm (similar to Boston Dynamics Spot) doing dynamic leg and arm movements.
Key results:
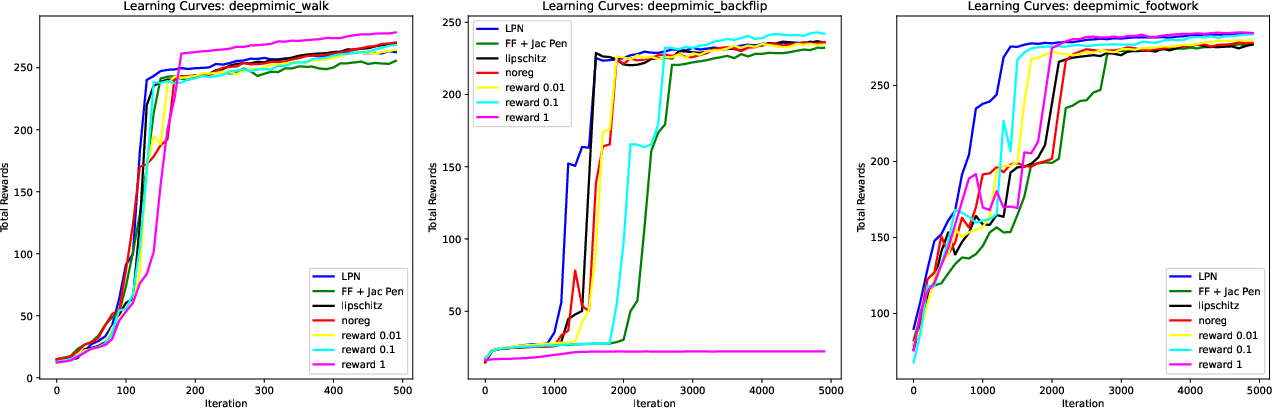
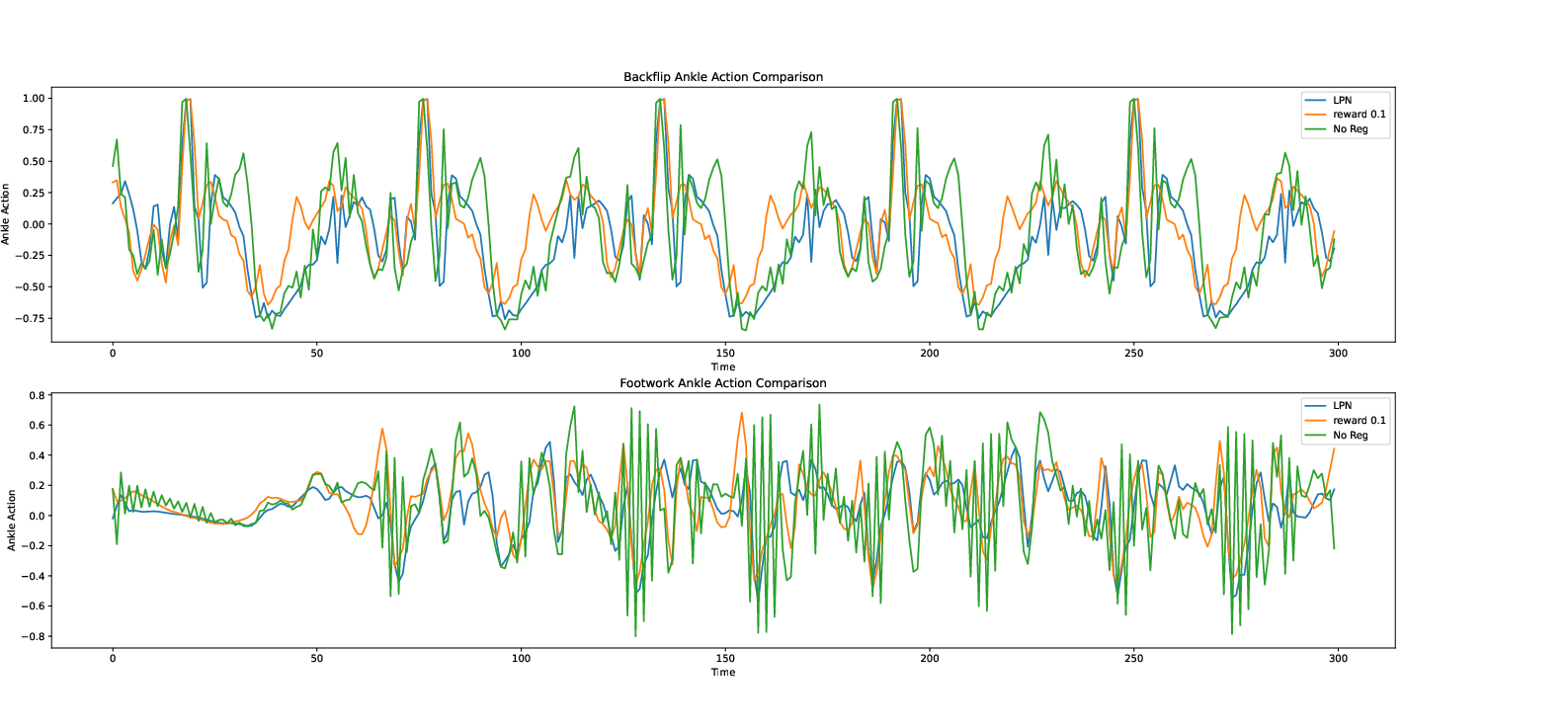
- Smoother actions without lots of hand-tuning: The action Jacobian penalty greatly reduced jittery, high‑frequency signals, and it worked across many tasks with the same simple setting.
- Faster training and cheaper to run: With LPN, the sensitivity penalty is quick to compute. Training converged faster than standard networks that tried to enforce smoothness, and the trained controller runs efficiently.
- Strong performance on hard skills: Even with the simpler “time‑varying linear” rule, the controller matched or beat standard neural networks in many tasks. It handled dynamic moves (like backflips) and complex environmental contacts (parkour).
- Real‑world success: The same idea worked on a physical quadruped with an arm, handling dynamic hops and fast arm swings while staying stable.
Notes:
- In some very dynamic moves (like a backflip), smoothness is naturally harder. The method still worked, but the actions were sometimes less smooth than in simpler tasks—because the motion itself needs quick changes.
Why is this important?
- More natural animation: Virtual characters move in smoother, more human‑like ways, which makes games, movies, and simulations look better.
- Safer, more reliable robots: Real robots can’t handle jittery commands. Smooth controllers avoid stress on motors and are easier to deploy in the real world.
- Less tuning, more scaling: Because the same penalty works across tasks and the LPN makes it fast, this approach can be used on many skills without endless parameter tweaking.
- Simpler, more understandable controllers: A time‑varying linear rule is easier to analyze and debug than a big black‑box network. That can lead to better insight and easier maintenance.
Big picture
This work shows that you don’t always need a complicated neural network to control complex motions. With the right “smoothness” guidance and a smartly designed controller (LPN), you can get high‑quality, realistic movements that work both in simulation and on real robots—and you can train them quickly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it:
- Lack of theoretical guarantees: no analysis of when time-varying linear feedback policies are sufficient (expressivity), stable (closed-loop), and near-optimal for the classes of tasks studied; no bounds on performance or robustness.
- Temporal smoothness not directly controlled: the action Jacobian penalty regularizes sensitivity to state () but not changes over time (); methods to explicitly control action derivatives in time or bound control bandwidth are absent, which likely hurts highly dynamic skills (e.g., backflip).
- Fixed Jacobian weight across tasks: the choice of is not justified or analyzed; no sensitivity study, task-agnostic tuning mechanism, or adaptive weighting strategy is provided.
- Norm and feature scaling choices: the Frobenius norm penalizes all Jacobian entries equally; with heterogeneous state feature scales (angles, velocities, positions), the penalty may be ill-conditioned; no normalization, per-feature/per-joint weighting, or physically grounded metric (e.g., energy-weighted or torque-weighted) is evaluated.
- Limited baseline tuning and fairness: Lipschitz-constrained policies are evaluated with a single weighting and sample strategy; no ablation over penalty strengths, estimator sample counts, or alternative gradient penalties to fully assess their potential.
- Restricted policy class: LPN deliberately limits policies to time-varying linear feedback; there is no exploration of when state-dependent linearization (i.e., making ) is necessary or beneficial, nor of hybrid (piecewise-linear) representations that could retain efficiency while improving expressivity.
- No principled low-rank training: reduced-order (low-rank) controllers are obtained by post-hoc SVD, not trained with rank constraints or sparsity regularizers; methods to learn low-rank (or structured) directly and criteria to select ranks per task are open.
- Update-rate limitation: LPNs fail to operate below 30 Hz for dynamic motions; techniques to train controllers explicitly robust to slow update rates (e.g., hold strategies, predictive action scheduling, multi-rate training) are not explored.
- Environment interaction metrics absent: parkour and juggling tasks are reported, but quantitative measures (success rates, contact stability, impact forces, task completion metrics) and comparisons to baselines are missing.
- Phase drift and timing robustness: since and depend on the reference (i.e., time) rather than the observed state, robustness to timing errors, phase drift, and off-reference recovery is not measured; methods for phase-adaptive or phase-free linear controllers are open.
- Exteroception and contact perception: LPN inputs use minimal coordinates without explicit environment perception (terrain height, obstacles, contact states); how to incorporate exteroceptive sensing or contact features while retaining computational advantages is not addressed.
- RL algorithm generality: results are only with PPO; applicability to other on-policy/off-policy methods (e.g., SAC, TD3, IMPALA) and the interaction between Jacobian penalties and different policy optimization schemes are unknown.
- PD/controller co-design: joint-level PD gains are fixed; joint tuning or co-optimization of PD gains with (or learning gains as part of the policy) is not studied, though it can materially affect stability and smoothness.
- Safety and constraint handling: torque limits, joint limits, impact constraints, and safe-contact policies are not integrated into training or evaluation; how Jacobian penalization interacts with physical constraints remains unclear.
- Per-joint sensitivity shaping: the penalty is uniform across joints, but tasks may require high sensitivity in certain joints (e.g., wrists for striking) while keeping others smooth; strategies for joint-specific Jacobian regularization are not explored.
- Human-bandwidth threshold and jerk metric validation: the 10 Hz cutoff and the jerk metric are used as proxies for naturalness without validation against human data or user studies; actuator-specific bandwidths on robots may differ and warrant task-specific thresholds.
- Runtime and compute benchmarking: claims of faster convergence and lower overhead for LPN are not backed by systematic runtime/inference benchmarks (per-iteration time, GPU usage, memory footprint) across tasks and model sizes.
- Sample-efficiency analysis: training sample counts and convergence comparisons are limited to a few tasks; no systematic sample-efficiency evaluation across broader task suites or under varying exploration noise ().
- Backflip performance gap: LPN underperforms FF+Jacobian on backflip smoothness; the underlying cause (temporal regularization deficiency, expressivity gap, update rate, PD interaction) is hypothesized but not empirically disentangled.
- Distillation and multi-skill scaling: skill composition is demonstrated for three motions, but scalability to larger skill libraries, transition reliability, and mechanisms for arbitration/gating between linear controllers are not evaluated.
- Sim-to-real limitations: Spot deployment uses precomputed , minimal domain randomization, and no online adaptation; robustness to sensor noise, delays, actuator saturation, modeling errors, and varying terrains is not quantified; no learning on hardware or closed-loop adaptation strategies are provided.
- Generalization beyond imitation: the approach is formulated for DeepMimic-style imitation; its extension to tasks without motion capture (e.g., goal-conditioned control, adversarial imitation, or reward-driven skills) remains untested.
- Explainability claims unsubstantiated: while matrices are arguably interpretable, no analyses (e.g., mapping structure to biomechanical control strategies, sensitivity maps, or mode decomposition) are presented to support explainability.
- Alternative smoothness regularizers: the paper does not compare Jacobian penalties to spectral norm constraints, weight decay, action filters with learned bandwidth, or structured controllers (e.g., LQR-inspired architectures) that may offer different smoothness/performance trade-offs.
- Feature normalization and scaling: input feature normalization is not described; unnormalized inputs can bias Jacobian penalties and learning dynamics; empirical and theoretical guidance on normalization choices is lacking.
- Robustness to disturbances: terrain adaptation is shown qualitatively, but robustness to quantified disturbances (impulses, pushes, parameter perturbations) and recovery behaviors are not measured.
- Humanoid hardware validation: sim-to-real is shown on a quadruped with an arm; transfer to humanoid hardware or more complex manipulators is not explored.
- Parameterization structure: is fully dense; the benefits of structured parameterizations (e.g., block-diagonal, joint grouping, sparsity) for efficiency, interpretability, and generalization are uninvestigated.
- Efficient Jacobian computation for FF nets: beyond noting overhead, the paper does not explore scalable Jacobian estimation (e.g., Hutchinson trace estimators, Jacobian-vector products with randomized directions) that could narrow the gap between FF and LPN.
- Combining model-based and DRL: while suggested, concrete methods to warm-start or constrain LPNs with DDP/iLQR (including how to choose costs, linearizations, and regularizations) and empirical evaluations are missing.
Practical Applications
Immediate Applications
The paper’s methods enable deployable workflows that yield smoother, more robust controllers with lower compute and tuning overhead. Below are concrete use cases, linked to sectors, with likely tools/workflows and key dependencies.
- Smooth, low-compute locomotion controllers for legged robots — Robotics
- Application: Train and deploy time-varying linear feedback policies for quadrupeds (e.g., Spot) that reduce actuator chatter, run at 15–30 Hz with precomputed feedback matrices, and handle concurrent motions (e.g., arm swings).
- Tools/workflows: PPO with action Jacobian penalty + Linear Policy Net (LPN); offline precomputation of K_t and k_t; onboard PD control; smoothness acceptance tests (High-Frequency Ratio, jerk).
- Dependencies/assumptions: Accurate state estimation; PD-controlled joints; representative physics in sim (actuator models); availability of reference motions; limited task variability at deployment.
- Robust sim-to-real pipelines with minimal reward tuning — Robotics, Software
- Application: Replace task-specific action-change rewards with a single action Jacobian penalty to regularize policies across skills (walk, run, flips, parkour-like contacts), improving transfer consistency.
- Tools/workflows: PyTorch autograd for Jacobian penalty; LPN architecture; standardized training recipe (w_Jac ≈ 10).
- Dependencies/assumptions: DRL stack with PPO; valid reference motions; similar sensing/actuation bandwidths between sim and hardware.
- Animation and game engines: smoother physics-based character control — Media/VFX, Gaming, Software
- Application: Plug-in controllers that mimic mocap sequences with reduced jitter and faster training convergence than FF networks; update rates compatible with game loops.
- Tools/products: LPN policy exporter; engine integration (Unreal/Unity) to run scheduled linear feedback; mocap-to-policy toolchain; smoothness QA metrics.
- Dependencies/assumptions: High-quality reference data; PD-style character rigs; consistent simulation time steps; content teams comfortable with time-varying linear policies.
- Real-time AR/VR avatar tracking with lower latency — AR/VR, Consumer Software
- Application: Leverage LPNs for smooth, low-latency retargeting of human motions to avatars using minimal state features; reduce jitter without heavy filtering that harms responsiveness.
- Tools/workflows: On-device LPN update at 15–30 Hz; offline scheduling of feedback matrices for known sequences; jerk- and frequency-based telemetry.
- Dependencies/assumptions: Stable body pose estimation; reference sequences (for scripted motions); device CPU/GPU budgets.
- Industrial arms and mobile manipulators: chatter reduction and wear minimization — Manufacturing, Logistics
- Application: Train controllers with Jacobian penalty to reduce high-frequency actuation in repetitive or dynamic tasks, lowering energy use and mechanical wear.
- Tools/workflows: LPN-based policy retraining for existing tasks; acceptance tests based on jerk and high-frequency energy ratios.
- Dependencies/assumptions: PD-like inner-loop control; consistent task references or trajectories; adequate sensing fidelity.
- Field robots operating on uneven terrain — Robotics (Inspection, Search & Rescue)
- Application: Fine-tune time-varying linear policies to sinusoidal/rough terrain without terrain perception; gain robustness from linear feedback structure.
- Tools/workflows: Terrain-randomized fine-tuning; robustness evaluations; deploy precomputed K_t schedules.
- Dependencies/assumptions: Perturbations within training distribution; adequate body state estimation; no large topology changes in terrain.
- Controller compression and interpretability in research and QA — Academia, Software
- Application: Use SVD-based low-rank approximations of learned feedback matrices to compress controllers and analyze salient control directions.
- Tools/workflows: Post-training SVD and rank selection; performance-vs-rank sweeps; interpretability reports for safety/QA reviews.
- Dependencies/assumptions: Acceptable performance loss at lower rank; availability of continuous evaluation benchmarks.
- Skill composition via policy distillation — Robotics, Media/VFX, Software
- Application: Distill multiple skill-specific LPNs into a single policy that transitions between dynamic motions (e.g., jump → sideflip → backflip) more reliably than FF baselines.
- Tools/workflows: Distillation training pipeline; motion graph scheduling of feedback matrices; transition QA.
- Dependencies/assumptions: Labeled reference segments; consistent character/robot morphology; limited combinatorial explosion of transitions.
- Standardized smoothness metrics and acceptance tests — Industry QA, Safety
- Application: Adopt action-change, high-frequency ratio (>10 Hz), and motion jerk as gate criteria for controller deployment and regression testing.
- Tools/workflows: CI pipelines generating smoothness reports; thresholds linked to human/actuator bandwidths.
- Dependencies/assumptions: Agreement on thresholds; task-specific exceptions for highly dynamic maneuvers.
- Education and lab prototyping — Academia, Education
- Application: Intro courses and labs demonstrating DRL → linear feedback policy learning, Jacobian-regularized training, and sim-to-real deployment on affordable platforms.
- Tools/workflows: Teaching code releases (PyTorch, MuJoCo/Gymnasium); lab rubrics using smoothness metrics.
- Dependencies/assumptions: Access to simulation; modest compute (single GPU); PD-controlled educational robots or simulators.
- Edge deployment on constrained hardware — Embedded/IoT, Robotics
- Application: Run precomputed linear schedules at low update rates to meet tight CPU budgets on embedded controllers, preserving smoothness.
- Tools/workflows: Offline K_t export; microcontroller PD loops; watchdogs for state drift beyond linear-region validity.
- Dependencies/assumptions: Tasks with predictable timing; bounded sensor noise; reliable time synchronization.
- Early-stage safety workflows for learned controllers — Policy, Compliance
- Application: Use Jacobian norm as a measurable proxy for control sensitivity in safety files; add caps or penalties to meet regulatory guidance in pilot deployments.
- Tools/workflows: Sensitivity audits; Jacobian-based “control Lipschitzness” dashboards; pre-deployment checklists.
- Dependencies/assumptions: Regulators/insurers accept smoothness proxies; risk assessments aligned to task dynamics.
Long-Term Applications
With further research and scaling, the following applications could emerge as standard practice across sectors.
- Assistive exoskeletons and prosthetics with smooth, explainable control — Healthcare
- Vision: Time-varying linear policies with bounded Jacobians for predictable, comfortable assistance; monitorable by clinicians.
- Dependencies/assumptions: Clinical trials; strict safety validation; high-fidelity user state estimation; personalized references.
- General-purpose home/service humanoids with skill libraries — Robotics, Consumer
- Vision: Large-scale libraries of time-varying linear policies distilled into controllers that transition between diverse daily-life skills.
- Dependencies/assumptions: Scaled motion datasets; robust transition graphs; reliable perception feeding state estimates.
- Piecewise-linear, region-based controllers for broad tasks — Robotics, Control
- Vision: Partition state space into few large regions with linear policies per region for robustness and interpretability.
- Dependencies/assumptions: Methods to learn coarse regions; guarantees on region-of-attraction; supervisor for region switching.
- DRL + model-based hybrid controllers (DDP/MPC warm-starts) — Robotics, Software
- Vision: Initialize LPN feedback with DDP or iLQR, then refine via DRL to combine sample efficiency with robustness.
- Dependencies/assumptions: Accurate dynamics models for warm starts; stable interfaces between model-based and learned components.
- Generative policy models that output feedback matrices from mocap — Media/VFX, Robotics
- Vision: Diffusion or other generative models produce sequences of K_t, k_t from motion prompts to automate content creation and robot skills.
- Dependencies/assumptions: Large paired datasets (motion ↔ feedback policies); safe post-hoc verification (Jacobian/jerk bounds).
- Certified “smoothness-by-design” standards for learned controllers — Policy, Certification
- Vision: Regulatory frameworks mandating Jacobian/sensitivity bounds for robots operating near people; standardized test batteries.
- Dependencies/assumptions: Consensus on metrics and thresholds; tooling for auditing and runtime monitoring.
- Teleoperation smoothing and shared autonomy — Drones, Industrial Arms, Public Safety
- Vision: Jacobian-penalized policies act as smart filters for operator inputs, removing high-frequency noise while preserving responsiveness.
- Dependencies/assumptions: Acceptable latency/lag trade-offs; operator acceptance; integration with existing teleop stacks.
- Energy-efficient motion and predictive maintenance — Manufacturing, Energy
- Vision: Systematic reduction of high-frequency actuation reduces power consumption and component fatigue; health diagnostics linked to smoothness trends.
- Dependencies/assumptions: Correlating smoothness metrics with wear; integration with CMMS and energy dashboards.
- Cross-platform controller marketplaces — Software, Robotics
- Vision: Exchange of certified linear feedback schedules for common robot models and tasks, ready for drop-in deployment with low compute needs.
- Dependencies/assumptions: Standardized robot abstractions; IP/licensing models; verification pipelines.
- Education-to-industry pipelines for explainable RL control — Academia, Workforce Development
- Vision: Curricula that bridge classical control and DRL through LPNs, yielding graduates skilled in safe, interpretable robot policy design.
- Dependencies/assumptions: Widely available open-source implementations; industry adoption of associated tooling.
- Public deployment guidelines for learned robots in shared spaces — Policy, Urban Planning
- Vision: Cities and facilities specify smoothness and sensitivity limits for mobile robots operating near pedestrians and infrastructure.
- Dependencies/assumptions: Pilot studies; sensor and policy monitoring infrastructure; enforcement mechanisms.
- Multimodal human–robot interaction with comfort guarantees — Healthcare, Service Robotics
- Vision: Controllers tuned to human comfort via jerk and frequency constraints in tasks like handovers, guidance, or rehabilitation exercises.
- Dependencies/assumptions: Human factors research; co-design of comfort metrics; closed-loop physiological sensing.
Notes on Cross-Cutting Assumptions and Dependencies
- Reference-driven training: The method assumes access to suitable reference motions (DeepMimic-style). For tasks without mocap, alternative objectives or adversarial imitation are needed.
- Control stack: Inner-loop PD control and reliable state estimation are presumed; actuator bandwidth and sensor noise strongly affect outcomes.
- Compute and tooling: Auto-diff frameworks (e.g., PyTorch) and PPO training are assumed; typical training uses a single GPU and parallel CPUs.
- Task dynamics: For highly dynamic skills (e.g., backflips), penalizing state-Jacobians alone may not reduce time-derivative action changes; hybrid penalties or time derivatives may be required.
- Expressivity vs. robustness: LPNs restrict policy expressiveness but improve smoothness, interpretability, and compute efficiency; some tasks may still need richer models or piecewise-linear variants.
Glossary
- Action Jacobian penalty: A regularization term that penalizes the sensitivity of policy actions to changes in state by minimizing the norm of the action-state Jacobian. "We propose to use the action Jacobian penalty, which penalizes changes in action with respect to the changes in simulated state directly through auto differentiation."
- Action Smoothness: A metric that measures average change in actions over time to quantify smoothness of control signals. "Action Smoothness: This metric evaluates the average action change of a policy: ."
- Auto-differentiation: Automatic computation of derivatives in computational graphs, used to efficiently optimize functions like the Jacobian penalty. "We propose directly optimizing for the norm of the full Jacobian, which can be achieved via auto-differentiation and backpropagation."
- Autograd: A deep learning framework feature that enables automatic differentiation through recorded computation graphs. "While penalizing the norm of the action Jacobian is straightforward thanks to the autograd features in a modern deep learning framework such as PyTorch."
- Backpropagation: The reverse-mode gradient computation used to update neural network parameters via gradient descent. "We propose directly optimizing for the norm of the full Jacobian, which can be achieved via auto-differentiation and backpropagation."
- Control bandwidth: The maximum rate at which actuators or controllers can respond, limiting feasible control signal frequencies. "the control bandwidth is limited by what the physical actuators can achieve."
- Deep reinforcement learning (DRL): A learning paradigm combining deep neural networks with reinforcement learning to learn complex control policies. "Deep reinforcement learning (DRL) has proven effective in physics-based character animation and robotics."
- DeepMimic: A reinforcement learning framework for physics-based motion imitation using motion capture references. "Our problem formulation is similar to DeepMimic."
- Diffusion model: A generative model that can be used to sample complex policy representations, e.g., feedback matrices. "a generative model such as a diffusion model can be used to generate the linear feedback policies."
- Differential dynamic programming (DDP): A second-order trajectory optimization method that yields time-varying linear feedback controllers. "Another way to synthesize a time-varying linear feedback policy is via model-based control such as differential dynamic programming (DDP)."
- Diagonal covariance matrix: A covariance structure with independent components, often used for Gaussian policy exploration. "the covariance matrix is a diagonal matrix with diagonal element ."
- Early termination: A training technique that ends episodes early when failure conditions are met, improving sample efficiency. "Similar to DeepMimic, we also apply reference state initialization and early termination to improve the learning efficiency."
- Feedback matrix: A matrix K that linearly maps state to action in a linear feedback policy. "the output of the MLP is a feedback matrix "
- Feedforward action: A baseline action term added to the feedback output to improve tracking of a reference. "and feedforward action "
- Fully connected feed forward (FF) neural network: A standard dense multilayer neural network architecture used to parameterize policies. "computing the Jacobian of a policy parameterized by a fully connected feed forward (FF) neural network incurs significant computational overhead."
- Finite differencing: A numerical method to approximate derivatives by discrete differences, used for jerk computation. "we use finite differencing to compute the joint jerk."
- Fourier transform: A frequency-domain transformation used to analyze the spectral content of action signals. "We compute the Fourier transform of the action output over time."
- Friction cone constraints: Inequality constraints ensuring contact forces remain within feasible friction limits. "However, the resulting controllers are still nonlinear due to the presence of inequality constraints such as the friction cone constraints."
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, used to measure Jacobian magnitude. "and is the square of the Frobenius norm of "
- Gaussian noise: Random perturbations sampled from a Gaussian distribution used for exploration in RL. "Reinforcement learning relies on injecting Guassian noise to the policy output for exploration and data collection."
- Gradient penalty: A regularization that penalizes gradients (e.g., of action likelihood) to constrain policy sensitivity. "a gradient penalty is imposed on the likelihood of a control action under the current policy"
- High Frequency Ratio: The fraction of action signal energy above a threshold (e.g., 10 Hz) indicating unnatural high-frequency content. "High Frequency Ratio: We compute the Fourier transform of the action output over time."
- Inverse optimal control: Techniques that infer cost functions or models so that observed policies are optimal under them. "Inverse optimal control techniques can potentially be used to search for this formulation"
- Jacobian: The matrix of partial derivatives of actions with respect to states, capturing action sensitivity. "with the Jacobian of the policy:"
- Jerk metric: A measure of motion smoothness based on the rate of change of acceleration (jerk), normalized by speed. "We then evaluate the jerk metric by dividing the mean jerk magnitude by the peak speed"
- Kinematic MPC planner: A model predictive control planner operating on kinematic models rather than dynamics. "and an agile table tennis stroke motion for the arm using a kinematic MPC planner"
- Linear Policy Net (LPN): A neural architecture that outputs linear feedback matrices and feedforward actions to produce control actions. "We introduce a Linear Policy Net (LPN) to parameterize our policies."
- Linearization (of the equation of motion): Approximating nonlinear dynamics with linear models to enable efficient control computations. "There is also work that applies linearization to the equation of motion."
- Lipschitz-constrained policies: Policies trained with constraints/penalties to bound action changes with respect to inputs, improving smoothness. "More recent work proposes using the Lipschitz-constrained policies to improve the smoothness of a learned control policy."
- Low-rank approximation: Approximating a matrix with a lower-rank version to reduce complexity while preserving key behavior. "we experiment with how to obtain a reduced-order linear policy by using low rank linear feedback matrices."
- Model predictive control (MPC): A control method that solves an optimization problem over a receding horizon to plan and execute actions. "require online replanning using computationally expensive model predictive control approaches"
- Mujoco: A physics engine used for accurate rigid-body simulation in robotics and animation. "We use Mujoco to simlulate the characters."
- Policy distillation: The process of merging multiple trained policies into a single model that can perform all tasks. "Policy Distillation and Transitions between Skills"
- Proportional-Derivative (PD) controller: A joint-level controller that sets torques based on proportional and derivative terms relative to target angles. "A joint level Proportional-Derivative (PD) controller is then used to actuate the character in a physics simulation."
- Proximal Policy Optimization (PPO): A popular RL algorithm that performs stable policy updates via clipped objectives and trust-region-like constraints. "We use Proximal Policy Optimization (PPO) to optimize the policies."
- Quadratic Programming (QP): An optimization problem with quadratic objective and linear constraints, often used in control. "because it only requires solving a small scale Quadratic Programming (QP) problem online."
- Reference state initialization: Initializing episodes near the reference trajectory states to stabilize and speed up imitation learning. "Similar to DeepMimic, we also apply reference state initialization and early termination to improve the learning efficiency."
- Region of attraction: The subset of the state space from which a controller drives the system to the desired behavior. "Learning linear feedback control policies that have a large region of attractions"
- ReLU activation function: A common neural network nonlinearity whose piecewise-linear nature partitions state space into linear regions. "Neural network policies that use ReLU as an activation function can already be used to generate such regions based on the activation patterns"
- Sim-to-real: Transferring policies learned in simulation to operate reliably on physical robots. "results in sim-to-real failure for robotics applications."
- Singular value decomposition: A matrix factorization revealing orthogonal bases and singular values, used for low-rank policy analysis. "We perform singular value decomposition on the learned feedback matrices"
- State estimator: A system that reconstructs the robot’s state (positions, velocities, etc.) from sensor measurements. "These features can also be easily obtained from a state estimator on a physical quadrupedal robot"
- Time-varying linear feedback policy: A linear controller whose feedback gains change over time (or reference phase) to track dynamic motions. "learning a time-varying linear feedback policy."
- Trajectory optimization: Computing motion plans by optimizing objective functions subject to dynamic constraints. "We generate a hopping motion via trajectory optimization of a single rigid body model"
Collections
Sign up for free to add this paper to one or more collections.