Information-Guided Noise Allocation for Efficient Diffusion Training
Abstract: Training diffusion models typically relies on manually tuned noise schedules, which can waste computation on weakly informative noise regions and limit transfer across datasets, resolutions, and representations. We revisit noise schedule allocation through an information-theoretic lens and propose the conditional entropy rate of the forward process as a theoretically grounded, data-dependent diagnostic for identifying suboptimal noise-level allocation in existing schedules. Based on these insight, we introduce InfoNoise, a principled data-adaptive training noise schedule that replaces heuristic schedule design with an information-guided noise sampling distribution derived from entropy-reduction rates estimated from denoising losses already computed during training. Across natural-image benchmarks, InfoNoise matches or surpasses tuned EDM-style schedules, in some cases with a substantial training speedup (about $1.4\times$ on CIFAR-10). On discrete datasets, where standard image-tuned schedules exhibit significant mismatch, it reaches superior quality in up to $3\times$ fewer training steps. Overall, InfoNoise makes noise scheduling data-adaptive, reducing the need for per-dataset schedule design as diffusion models expand across domains.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about training diffusion models—AI systems that generate things like images—more efficiently. Normally, these models are trained by adding and then removing different amounts of noise to data. Deciding “how much time to spend” training at each noise level is called the noise schedule. Today, people pick these schedules by hand, which often wastes computer time and does not transfer well from one dataset to another.
The authors propose a smarter, automatic way to choose the noise levels during training. They use an information signal—how quickly uncertainty about the clean data drops as noise decreases—to guide where training should focus. They call this method InfoNoise.
What questions are the authors asking?
- Can we stop hand-tuning noise schedules and instead learn a schedule that adapts to the data automatically?
- Is there a particular “sweet spot” of noise levels where the model learns the most?
- Can we estimate where that sweet spot is using the losses we already compute during training?
- Will this make training faster or better across very different kinds of data (like natural images and DNA sequences)?
- Can the same idea also help us pick better steps when generating samples (inference) after training?
How did they approach the problem?
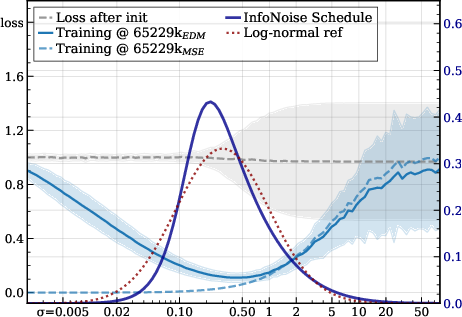
Think of denoising like cleaning a fogged-up window to see a scene behind it. At first, with super heavy fog (very high noise), you can’t tell much. At the very end, when there’s almost no fog (very low noise), you already see the scene clearly, so extra cleaning doesn’t help much. The most useful cleaning happens in the middle—an “informative window”—where each wipe reveals a lot.
To find this window automatically, the authors use:
- Conditional uncertainty: measures how unsure we still are about the clean data after seeing a noisy version (noise level ).
- Entropy rate: how fast that uncertainty changes as we reduce noise. If uncertainty drops quickly in a certain noise range, that’s where learning gives the most payoff.
- A classic math fact (linked to I–MMSE): it connects how fast uncertainty changes to the best possible denoising error at each noise level. In simple terms: if the best possible error is high at a noise level, reducing noise there changes information the most. This lets us estimate the “information profile” using the same per-noise losses the model already computes during training.
Their method, InfoNoise:
- Tracks the model’s denoising loss at different noise levels as training goes on.
- Converts those losses into an estimate of where uncertainty is dropping the fastest (the informative window).
- Samples those noise levels more often during training, without changing the loss function or model—only how often each noise level is picked.
- Uses a gentle “gate” to avoid focusing too hard on the extreme very-low-noise end, which can distort the signal.
They also show how the learned information profile can guide the steps used when generating new samples after training, so the model spends more effort where the denoising actually matters.
What did they find, and why is it important?
Across several experiments, two big patterns show up:
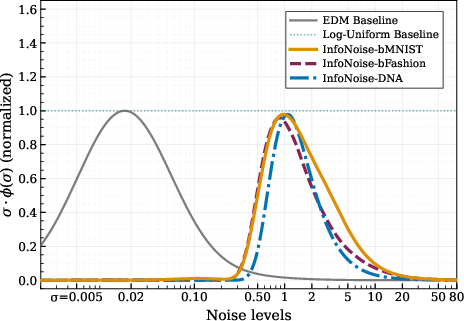
- There is a real “informative window” of noise levels. Most useful learning happens in the middle, not at the extremes. This holds in toy examples and in real image datasets.
- Where that window sits depends on the data and the representation (like images vs. DNA sequences vs. different image resolutions). This is why fixed, hand-tuned schedules often transfer poorly.
Key results:
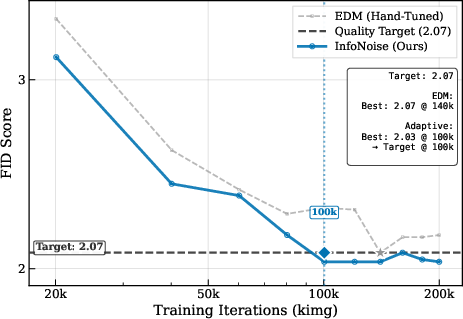
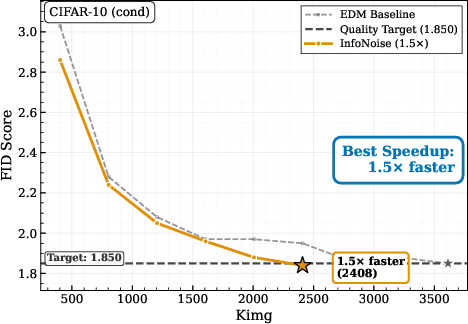
- On natural images (like CIFAR-10), InfoNoise matches or slightly beats carefully hand-tuned schedules, sometimes reaching the same quality with about 1.4–1.5× less training compute. That means faster training without manual schedule tuning.
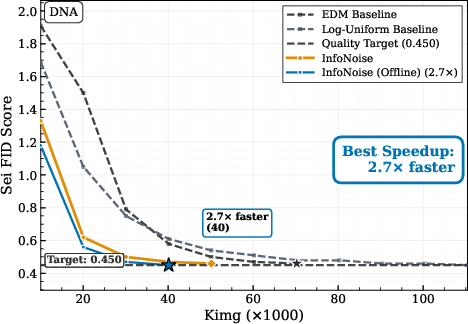
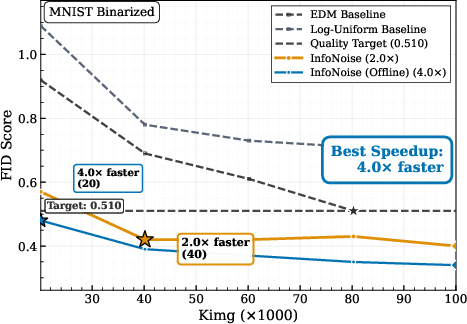
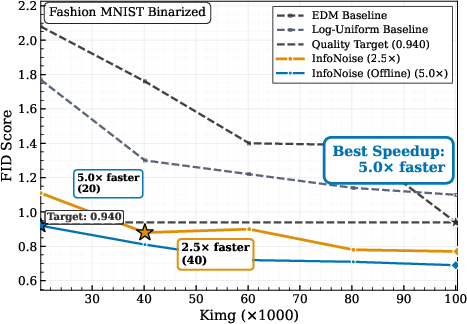
- On discrete data (like DNA or binarized images), fixed image-style schedules are a poor match. InfoNoise adapts to the data and reaches the same quality in up to 3× fewer training steps.
- The “informative window” shows up early in training. The schedule stabilizes quickly, meaning the method doesn’t need a fully trained model to work.
- The same information signal can also improve how we space the denoising steps at sampling time (inference). Using an “information-uniform” grid (InfoGrid) produced cleaner samples at the same compute compared to a standard grid.
Why this matters:
- Less wasted compute: The method points the training effort to where it counts the most.
- Fewer manual knobs: It reduces the need to hand-design and retune schedules for every new dataset or setting.
- Broad usefulness: It works for both continuous data (images) and discrete data (like DNA sequences), where mismatched schedules can really slow you down.
What could this change in practice?
- Training becomes more plug-and-play: Instead of trial-and-error schedule tuning, training adapts itself using an information signal it estimates on the fly.
- Faster iteration loops: Teams can get to good models sooner, especially when switching datasets, resolutions, or data types.
- Better sampling too: The same idea helps choose smarter denoising steps when generating samples, improving quality at the same cost.
Key ideas in plain terms
- Diffusion model: A model that learns to remove noise step by step so it can generate realistic data (like images).
- Noise schedule: A plan for how much time to spend training at each noise level, from super noisy to almost clean.
- Conditional entropy: A measure of “how unsure we still are” about the original clean data after seeing a noisy version.
- Entropy rate: How quickly that uncertainty drops as we reduce noise; it highlights the “informative window.”
- InfoNoise: A training method that uses the model’s own per-noise losses to estimate where learning is most effective and samples those noise levels more often.
- InfoGrid: A sampling-time method that takes evenly spaced steps in information space (not just in noise space), improving generation quality at the same compute.
In short, this paper shows that following the information—where uncertainty actually collapses—makes diffusion training and sampling both smarter and more efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open directions that future work could address to strengthen, generalize, or validate the paper’s claims.
- Lack of formal convergence guarantees: No theoretical analysis shows that sampling in proportion to the conditional-entropy rate accelerates optimization (e.g., bounds on sample complexity, convergence rates, or stability of SGD under InfoNoise).
- Early-training estimator reliability: The MMSE proxy derived from per-noise denoising losses can be highly biased when the model is poorly trained; there is no principled mechanism to detect and mitigate unreliable rate estimates during warm-up or rapid parameter drift.
- Hyperparameter sensitivity and calibration: The schedule depends on several heuristics (gate exponent n; pivot threshold p; refresh period M; FIFO capacity B; minimum per-bin count N_min; optional smoothing). The paper lacks systematic ablations, sensitivity analysis, and automated calibration procedures beyond the simple onset/power-law rules.
- Coverage guarantees across the noise path: While the method “still covers the rest of the path,” there is no formal floor or constraint ensuring non-negligible sampling at high- and low-noise extremes, which may be necessary for solver stability or model calibration at the endpoints.
- Objective and weighting interaction: InfoNoise “keeps the objective unchanged” and adjusts only π(σ), but the impact of different per-noise weightings w(σ) (e.g., EDM vs. DDPM vs. VP-style weightings) on the estimator bias and allocation is not analyzed; guidance on how to co-design w(σ) and π(σ) is missing.
- Generalization beyond VE Gaussian channel: The approach relies on I–MMSE in the VE coordinate; extensions to VP/sub-VP SDEs, discrete-time DDPM parameterizations (β-schedules), non-Gaussian noise channels, or hybrid corruption processes are not developed.
- Discrete endpoints theory: For discrete data, the gating and pivot selection are justified by empirical power-law behavior, but there is no theoretical account of when I–MMSE-based profiles and the σ3 scaling are appropriate, nor how channel discretization or alternative corruption models affect the rate estimate.
- Robustness across architectures and scales: Experiments use relatively small and standard setups (MNIST/FashionMNIST/CIFAR-10/FFHQ 64×64). It remains unknown whether InfoNoise remains effective and stable for high-resolution images (≥256×256), latent diffusion, transformers, multimodal models, or very large-scale training.
- Modalities and domains: The method is only evaluated on images and DNA sequences. Applicability to audio, text/token diffusion, video, 3D generative tasks, and other discrete sequences (e.g., protein structures) is unexplored.
- Statistical robustness and reproducibility: The paper does not report variability across seeds, confidence intervals, or statistical significance of speedups and FID differences; reproducibility and robustness under perturbations (e.g., data shifts) are unclear.
- Computation overhead accounting: The runtime/memory cost of maintaining per-σ buffers, periodic sampler refresh, interpolation for inverse-CDF sampling, and optional smoothing is not quantified; net speedups excluding this overhead are not reported.
- Failure modes and misestimation: Potential adverse effects when the entropy-rate profile is multi-peaked, noisy, or mislocalized (e.g., oversampling a spurious region, catastrophic forgetting at extremes, instability of the reverse dynamics) are not analyzed; safeguards or diagnostics are missing.
- Interaction with conditioning and guidance: While conditional CIFAR-10 is tested, the interaction between InfoNoise and classifier-free guidance (CFG) or other conditioning strategies (text prompts, class embeddings) is not studied, particularly for inference-time discretization where guidance reshapes the effective score field.
- Inference grid generality: InfoGrid is only shown with Heun and compared to EDM’s σ-grid qualitatively; rigorous FID-vs-NFE comparisons across solvers (e.g., Euler, DPM-Solver, UniPC, ancestral samplers) and under varying guidance strengths are absent.
- Unified treatment of the log-noise measure: The extra σ factor in the InfoGrid construction is motivated by log-noise integration, but a principled derivation and comparison to alternative measures (e.g., uniform in σ, log σ, or information time u) are missing; conditions under which uniform-u grids are optimal remain open.
- Effects on end-task metrics beyond FID: The approach is framed around FID and Sei-FID; its impact on likelihood/bpd, calibration of posterior estimates (e.g., MMSE consistency), perceptual metrics, diversity, and mode coverage is not examined.
- Data augmentation and curriculum: How InfoNoise interacts with data augmentation, curriculum strategies (e.g., coarse-to-fine), class imbalance, or importance sampling over data examples remains unexplored.
- Schedule floors and annealing strategies: There is no exploration of explicit schedule floors, annealing of the gate pivot c over training, or multi-phase allocation strategies that balance early stabilization and late refinement.
- Theoretical link to symmetry breaking: The paper qualitatively connects the entropy-rate peak to symmetry breaking and decision windows; a quantitative, high-dimensional theory (e.g., critical σ estimates, bifurcation analysis for realistic data manifolds) is not provided.
- Compatibility with alternative objectives: Extensions to likelihood-based training (ELBO), score matching variants, or energy-based formulations—and how InfoNoise’s allocation should change under these objectives—are not addressed.
- Domain shift and OOD behavior: Whether adaptive schedules overfit to training distributions and degrade robustness or generalization under domain shift is unknown; mechanisms to detect and adapt under shift are not proposed.
- Safety and stability constraints: No discussion of constraints to prevent degenerate allocations (e.g., concentrating too narrowly), nor of how to enforce solver stability requirements (e.g., step-size coupling or Lipschitz control in regions with steep information gradients).
- Practical deployment guidance: Clear recipes for choosing grid resolution K, refresh cadence M, warm-up length N_warm, and gating thresholds across different datasets are not provided; practitioners may need concrete defaults or automated tuning strategies.
Practical Applications
Immediate Applications
The following items describe concrete, deployable use cases that can be implemented now using the paper’s InfoNoise method (entropy-rate–guided training noise schedules) and InfoGrid (information-guided inference discretization), with sector links, workflows, and key dependencies.
- Training-efficient diffusion in production ML pipelines
- Sector: software/AI, cloud computing
- Use case: Replace hand-tuned training noise schedules with InfoNoise to cut compute and time-to-quality for diffusion models (e.g., 1.4× speedup on CIFAR-10; up to 3× fewer steps on discrete data such as DNA or binarized images).
- Tools/products/workflows:
- Integrate an InfoNoise scheduler into PyTorch/TensorFlow training loops that already compute per-noise denoising losses.
- Periodic sampler refresh based on FIFO buffers and EMA-smoothed per-σ loss bins; maintain current objective and model architecture.
- Logging dashboards for entropy-rate profiles and schedule evolution.
- Assumptions/dependencies:
- Gaussian corruption (VE) with access to per-noise losses; I–MMSE identity applies.
- Stable loss-to-entropy-rate estimation requires sufficient samples per noise bin and a warm-up under a baseline sampler.
- Low-noise gating pivot calibration (continuous vs. discrete endpoints) is part of the workflow.
- Transfer-friendly schedule adaptation across domains and representations
- Sector: multi-modal AI (images, audio codes, tokenized text, genomics)
- Use case: Avoid per-dataset schedule retuning by using InfoNoise to discover the “informative window” of noise levels in new domains, especially discrete representations where image-tuned schedules misallocate compute.
- Tools/products/workflows:
- Drop-in replacement for fixed EDM-style schedules; keep objective and loss weights unchanged.
- Automated gating calibration (onset-of-information for continuous, power-law departure for discrete endpoints).
- Assumptions/dependencies:
- Discrete modalities often show low-noise power-law behavior; gating prevents tail dominance.
- Requires loss weighting awareness (π(σ) ∝ ρ(σ)/w(σ)) to match target emphasis.
- Latency-conscious sampling with InfoGrid
- Sector: consumer apps, creative tools, platforms serving generative APIs
- Use case: Improve sample quality at fixed NFE by discretizing the reverse path via uniform spacing in the learned information coordinate u(σ) rather than in σ (replacing the EDM grid without changing solver or NFE).
- Tools/products/workflows:
- Build an inference grid from the trained u(σ); perform inverse-CDF interpolation over σ.
- Compatible with common ODE/SDE samplers (e.g., Heun); swap grids with minimal code changes.
- Assumptions/dependencies:
- Requires a stable entropy-rate profile learned during training.
- If the profile is noisy or mismatched, fall back to EDM grid or blend grids.
- AutoML/DevOps for diffusion training
- Sector: MLOps, enterprise ML
- Use case: Standardize and automate schedule selection and monitoring, reducing hyperparameter search and manual tuning.
- Tools/products/workflows:
- “InfoNoise-as-a-service” module for training platforms; automatic warm-up, refresh cadence M, buffer size B, and N_min enforcement.
- KPI tracking: compute-to-target (kEx), FID/Sei-FID, entropy-rate peaks and bandwidth.
- Assumptions/dependencies:
- Training objective must expose a consistent x₀-prediction or convert v-prediction to x₀-equivalent loss.
- Proper safeguards (min-bin counts, EMA smoothing) to avoid oscillatory schedule updates.
- Sustainable AI training practices
- Sector: policy, sustainability offices in tech companies
- Use case: Reduce energy per training run via information-guided allocation; report energy savings with compute-to-target metrics.
- Tools/products/workflows:
- Add energy tracking (J/kEx) to training; document reductions from InfoNoise vs. fixed schedules.
- Assumptions/dependencies:
- Savings depend on hardware and dataset modality; standardized measurement protocols are needed for credible reporting.
- Faster customization for brand/content generation
- Sector: advertising, media, design studios
- Use case: Train customized diffusion models for brand assets at new resolutions or in different representations without schedule retuning.
- Tools/products/workflows:
- Integrate InfoNoise into existing fine-tuning pipelines; sample σ from the learned schedule while keeping architecture/optimizer fixed.
- Assumptions/dependencies:
- For extreme resolutions or heavily quantized latents, verify gating calibration and bin coverage.
Long-Term Applications
These items require further validation, scaling, or development before broad deployment.
- Foundation-scale diffusion with universal, data-adaptive scheduling
- Sector: AI platforms, cloud providers
- Use case: Train large multi-domain diffusion models (images/video/audio/text/biology) with a unified InfoNoise scheduler that adapts per-domain and per-resolution, reducing recurring schedule engineering.
- Tools/products/workflows:
- Managed training services offering “adaptive scheduling” as a feature; cross-domain entropy dashboards; domain-specific gating presets.
- Assumptions/dependencies:
- Robustness across diverse corruption processes and parameterizations (e.g., VE vs. VP, non-Gaussian perturbations) needs research.
- Scalability tests on very large models and datasets.
- Adaptive inference controllers
- Sector: real-time generative systems, interactive tools
- Use case: Dynamically adjust step sizes at inference using online entropy feedback, aiming for near-uniform uncertainty reduction in user-facing generation (e.g., interactive editing).
- Tools/products/workflows:
- Runtime estimators of local information density; controllers that modulate σ-steps or NFE budgets on the fly.
- Assumptions/dependencies:
- Fast, reliable online estimation during inference; safeguards to prevent instability.
- Diffusion in robotics and control (diffusion policies)
- Sector: robotics, autonomous systems
- Use case: Apply information-guided schedules to train diffusion-based policies where the “informative window” depends on state distributions and sensor noise.
- Tools/products/workflows:
- Integrate InfoNoise into policy training loops; adapt σ-sampling to the robot/task data distribution.
- Assumptions/dependencies:
- Mapping from denoising losses to valid entropy-rate estimates in control settings; compatibility with policy objectives.
- Continual and streaming learning with schedule drift tracking
- Sector: enterprise AI, on-device personalization
- Use case: Monitor how the informative window shifts as data distributions change; update schedules without retraining from scratch.
- Tools/products/workflows:
- Schedule-refresh services with drift detection; safe rollback and blended schedules.
- Assumptions/dependencies:
- Accurate detection of distribution shift via entropy-rate signals; avoiding catastrophic forgetting.
- Standards and reporting for energy-efficient generative AI
- Sector: policy/regulation, sustainability
- Use case: Establish best-practice guidance for information-guided training; include entropy-rate diagnostics and compute-to-target benchmarks in model cards and audits.
- Tools/products/workflows:
- Templates and tooling for reporting entropy profiles, schedule choices, and energy usage.
- Assumptions/dependencies:
- Community consensus on metrics; reproducible measurement protocols.
- Ecosystem integration: libraries and frameworks
- Sector: open-source software
- Use case: Integrate InfoNoise and InfoGrid into major diffusion toolkits (e.g., Hugging Face Diffusers, KerasCV), offering adaptive scheduling and information-based grids as first-class options.
- Tools/products/workflows:
- SDKs providing: schedule construction (ρ(σ)), gate calibration, sampler builders, inference grid generators, and monitoring hooks.
- Assumptions/dependencies:
- Compatibility across objectives (x₀, ε, v-prediction) and solvers; thorough benchmarking on diverse tasks.
- Extending beyond Gaussian channels and to alternative objectives
- Sector: research/academia
- Use case: Generalize entropy-guided allocation to non-Gaussian corruption paths, alternative parameterizations, or hybrid objectives, leveraging broader information identities.
- Tools/products/workflows:
- Theoretical extensions of I–MMSE; empirical studies; ablation suites isolating channel effects.
- Assumptions/dependencies:
- New identities or approximations to estimate conditional entropy rates reliably; validation on real datasets.
- Risk and safety assessments tied to efficiency gains
- Sector: AI governance
- Use case: Evaluate how training efficiency improvements may accelerate capability growth; embed oversight mechanisms when deploying adaptive schedules for powerful generative systems.
- Tools/products/workflows:
- Governance checkpoints when enabling InfoNoise in large-scale training; compute allocation transparency.
- Assumptions/dependencies:
- Clear risk models and organizational processes for capability management.
Glossary
- Adaptive Sampling: Adjusting the probability of sampling different noise levels or data points during training to focus computation where it is most informative. "Adaptive Sampling"
- Bayes MMSE: The minimum mean-squared error achievable by any estimator given the posterior; here, a function of noise level σ capturing intrinsic denoising difficulty. "The intrinsic denoising difficulty at noise level is captured by the Bayes MMSE"
- Bayes-optimal denoiser: The posterior-mean estimator E[x0|xσ] that uniquely minimizes MSE under the data and corruption model. "Bayes-optimal denoiser"
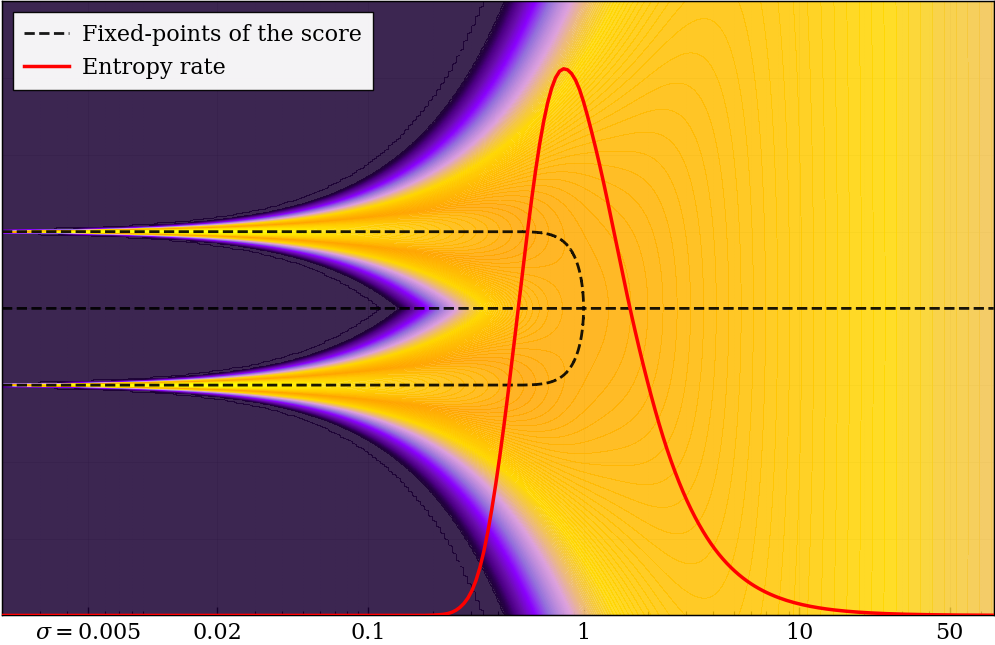
- Bifurcation: A qualitative change where system behavior splits into distinct branches as a parameter varies; here, the optimal denoising field splits into two stable branches at intermediate noise. "the optimal denoising field bifurcates"
- Conditional entropy: The expected uncertainty remaining about the clean sample after observing its noisy version, H[x0|xσ]. "A natural way to formalize this phenomenon is via the conditional entropy "
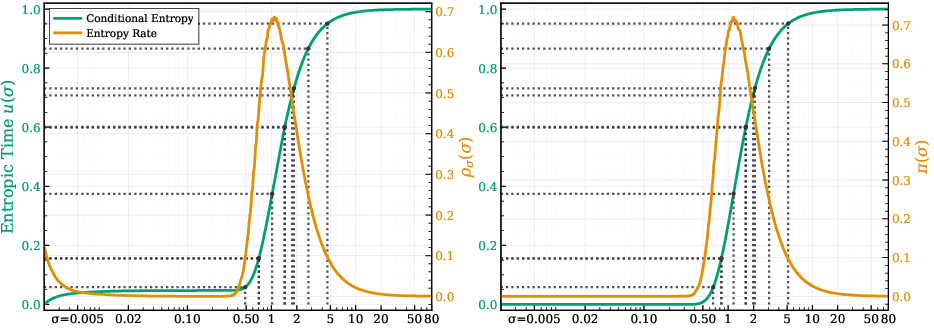
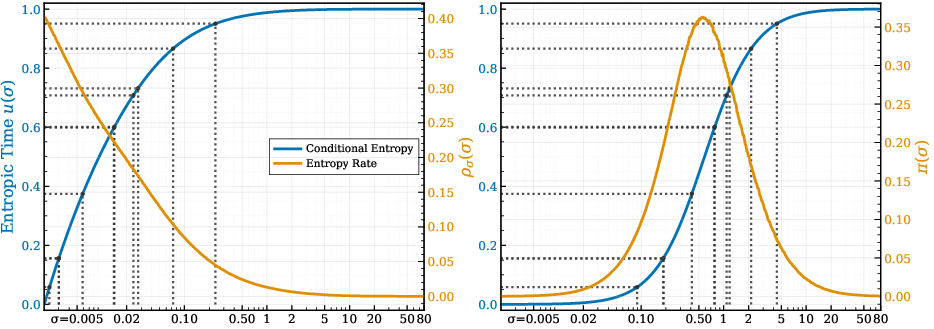
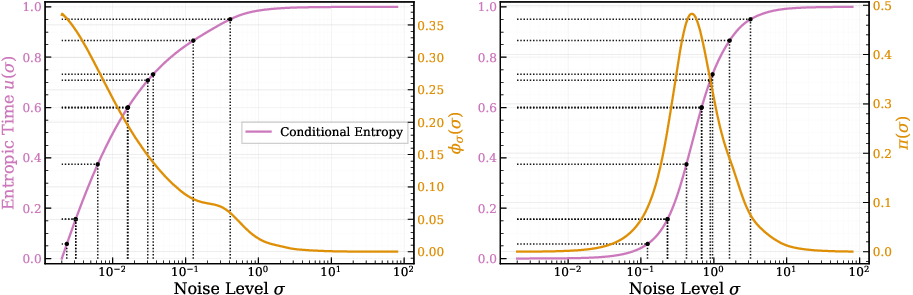
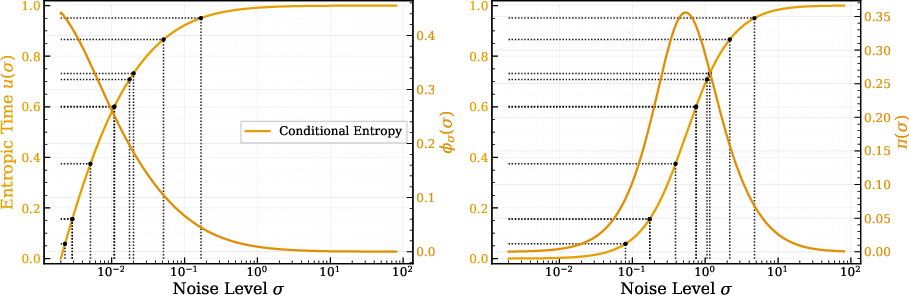
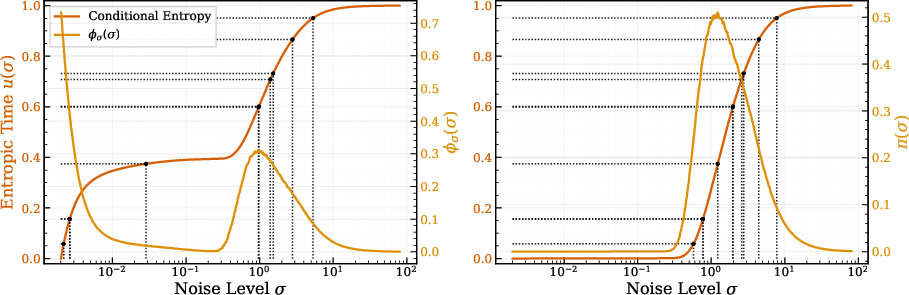
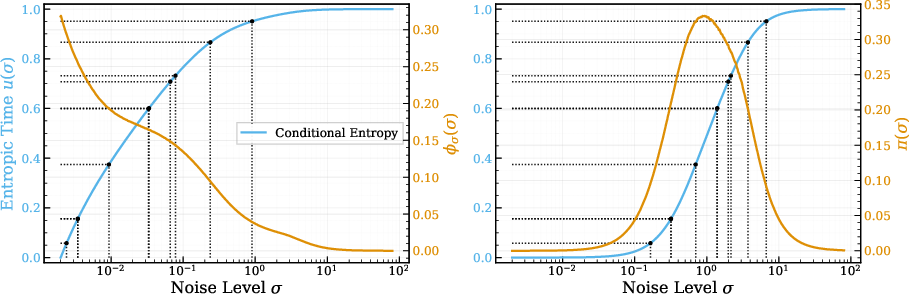
- Conditional-entropy rate: The derivative of conditional entropy with respect to σ, indicating how rapidly uncertainty changes along the noise path. "We refer to its slope along the corruption path as the conditional entropy rate (entropy rate)."
- EDM (Elucidated Diffusion Models): A diffusion modeling framework with a VE Gaussian corruption process, tailored objectives, and schedules. "EDM-style schedules"
- Entropic time: A cumulative coordinate u(σ) obtained by normalizing and integrating the entropy-rate profile, used to sample noise levels proportionally to information density. "We call entropic time"
- Entropic-time methods: Approaches that reparameterize inference-time discretization using an information-based time coordinate rather than fixed σ spacing. "Unlike entropic-time methods (e.g.\ \citep{stancevic2025entropic})"
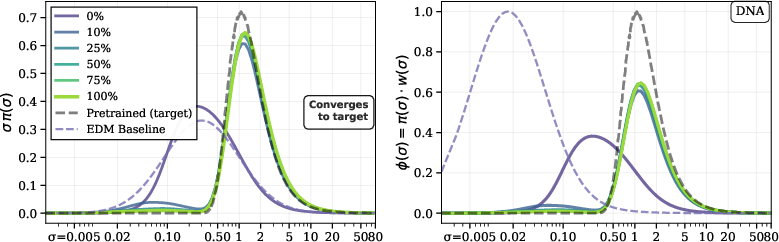
- Entropy rate: The rate of change of conditional entropy with noise, highlighting where uncertainty resolves most quickly. "(Left) estimated conditional entropy and (right) its entropy rate (from per- denoising losses; \cref{sec:info_noise}) show how the most-informative window shifts across settings."
- Entropy-rate identity (I--MMSE): The identity linking the derivative of conditional entropy along the Gaussian channel to the Bayes MMSE (e.g., d/dσ H[x0|xσ] = mmse(σ)/σ3 in VE coordinates). "Entropy-rate identity (I--MMSE)."
- Gaussian channel: A corruption model where noise is added linearly with Gaussian statistics, xσ = x0 + σε, ε∼N(0,I). "under the Gaussian channel ."
- Heun: A second-order Runge–Kutta numerical solver used for discretizing SDE/ODE-based sampling in diffusion models. "solver (Heun)"
- Information-guided discretization: Selecting inference-time noise steps by spacing them uniformly in an information coordinate rather than σ, to align solver effort with uncertainty reduction. "Information-guided discretization for sampling."
- Itô SDE: A stochastic differential equation interpreted in the Itô sense; used to describe the forward (and reverse) diffusion processes. "the It^o SDE"
- Mutual information: The shared information between the clean and noisy variables, equal to H[x0] − H[x0|xσ] under the Gaussian channel. "the mutual information satisfies"
- Noise schedule: The sampling distribution over noise levels during training that determines how often each σ is visited. "training noise schedule (hereafter, noise schedule)"
- Number of Function Evaluations (NFE): The count of solver evaluations (steps) used during sampling; a measure of inference-time compute. "NFE (35, top; 79, bottom)"
- Posterior mean: The conditional expectation E[x0|xσ], which is the unique MSE-optimal denoiser under Gaussian corruption. "The posterior mean is the unique MSE-optimal denoiser."
- Pushforward density: The transformed sampling density over σ induced by sampling in another coordinate t and mapping via σ(t). "the pushforward density (for invertible )"
- Reverse-time dynamics: The stochastic and deterministic dynamics that invert the forward diffusion process to generate data. "This forward SDE admits stochastic and deterministic reverse-time dynamics"
- Score (score function): The gradient of the log-density with respect to the noisy variable, ∇xσ log p(xσ;σ), which parameterizes reverse dynamics. "depend on the data only through the score "
- SDE (stochastic differential equation): A differential equation with stochastic (noise) terms modeling the forward and reverse diffusion processes. "This forward SDE admits stochastic and deterministic reverse-time dynamics"
- Sei-FID: A Fréchet Inception Distance-style metric adapted for evaluating generative models of DNA sequences. "Sei FID"
- Symmetry breaking: The transition where a symmetric state gives way to structured, asymmetric patterns as noise decreases. "coinciding with the noise range where uncertainty collapses fastest."
- Variance-exploding (VE) channel: A diffusion corruption parameterization where the variance increases with σ in the forward process. "variance-exploding (VE) channel"
- VE noise coordinate: The σ parameterization specific to the VE channel, under which certain identities (e.g., I--MMSE) take a simple form. "In the VE noise coordinate, this yields the pathwise entropy-rate identity"
- Wiener process: Standard Brownian motion used to drive SDEs in the forward diffusion model. "where is a standard -dimensional Wiener process indexed by ."
Collections
Sign up for free to add this paper to one or more collections.