TeFlow: Enabling Multi-frame Supervision for Self-Supervised Feed-forward Scene Flow Estimation
Abstract: Self-supervised feed-forward methods for scene flow estimation offer real-time efficiency, but their supervision from two-frame point correspondences is unreliable and often breaks down under occlusions. Multi-frame supervision has the potential to provide more stable guidance by incorporating motion cues from past frames, yet naive extensions of two-frame objectives are ineffective because point correspondences vary abruptly across frames, producing inconsistent signals. In the paper, we present TeFlow, enabling multi-frame supervision for feed-forward models by mining temporally consistent supervision. TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames. Extensive evaluations demonstrate that TeFlow establishes a new state-of-the-art for self-supervised feed-forward methods, achieving performance gains of up to 33\% on the challenging Argoverse 2 and nuScenes datasets. Our method performs on par with leading optimization-based methods, yet speeds up 150 times. The code is open-sourced at https://github.com/KTH-RPL/OpenSceneFlow along with trained model weights.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
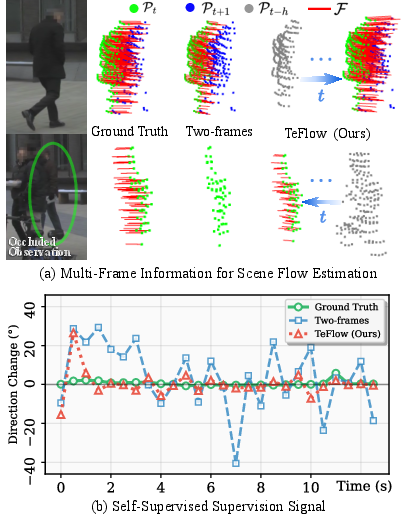
This paper introduces TeFlow, a way for computers to understand how things move in 3D using only a car’s laser scanner (LiDAR). It focuses on “scene flow,” which means figuring out how every 3D point in a scene moves from one moment to the next. TeFlow learns without human-made labels and runs fast enough for real-time use (like in self-driving cars). Its big idea is to learn from several frames at once, not just two, so it gets a more stable and reliable sense of motion—even when objects are briefly hidden or points are missing.
What questions did the researchers ask?
- Can a fast, feed-forward model (one-pass, no per-scene fine-tuning) learn accurate 3D motion without ground-truth labels?
- How can we use more than two frames to give the model better “teaching signals” during training, especially when objects are occluded (partly hidden) or LiDAR points are missing?
- Can this multi-frame training be stable and consistent enough to beat existing fast methods—and come close to the accuracy of slow, optimization-heavy methods?
How did they do it? (Methods in everyday terms)
Think of tracking people in a crowded room with a strobe light that flashes several times a second. If you only compare two flashes, you might lose track when someone is briefly blocked from view. But if you look across several flashes, you can piece together a steadier path.
TeFlow turns that idea into a training strategy:
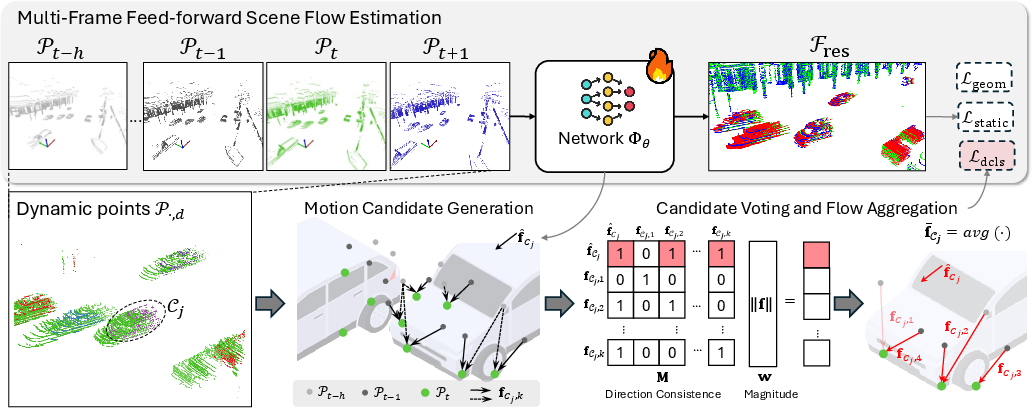
- It groups moving points into “dynamic clusters.” For example, all the points that belong to the same car are considered one cluster. The model predicts how each cluster moves.
- It builds a “candidate pool” of motion guesses for each cluster:
- Internal candidate: the model’s own current guess for that cluster’s motion (works like an anchor).
- External candidates: motion hints gathered by comparing the current frame with several nearby frames (past and next), using nearest-neighbor matching and adjusting for time gaps.
- It then picks the most reliable motion using a simple voting idea:
- Check which candidates point in similar directions (direction agreement).
- Give more weight to candidates that look clearer (e.g., bigger, more reliable motions, and more recent/consistent ones).
- Choose the candidate with the most support, and average it with other agreeing candidates to get a clean, stable “teaching signal.”
- It trains the network with self-supervised losses:
- Static loss: background points (like the ground and buildings) should have near-zero “residual” motion once the car’s own movement is accounted for.
- Dynamic cluster loss: compares the model’s predicted flow to the stable, voted motion for each moving cluster. It combines:
- Point-level accuracy (fit each point),
- Cluster-level balancing (so big objects with many points don’t drown out small objects like pedestrians).
- Geometric consistency: make sure that if you “move” the earlier frame by the predicted flow, it lines up with the neighboring frames.
In short: TeFlow gathers motion clues from multiple frames, lets them “vote” on a consistent direction, and uses that as a strong, low-noise teacher for training a fast model.
What did they find, and why is it important?
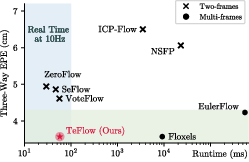
- Much better accuracy with real-time speed:
- On two big self-driving datasets (Argoverse 2 and nuScenes), TeFlow sets a new state-of-the-art among fast, self-supervised methods.
- It improves results by up to about 33% compared to previous fast methods, especially on challenging cases like pedestrians.
- It reaches accuracy close to some slow, optimization-heavy methods but is about 150× faster.
- Stability from multi-frame supervision:
- The “voting” over several frames makes the training signals much steadier than the usual two-frame training, which often flips when points are missing or occluded.
- TeFlow found a sweet spot around five frames: enough context to be stable, but not so many that far-away frames add noise.
- Fair treatment of small objects:
- The cluster-level loss ensures small, important objects (like pedestrians and scooters) get a fair say during training, improving their motion estimates.
Why this matters: Reliable, real-time motion understanding helps self-driving systems predict where cars, bikes, and people are going—critical for safety and smooth navigation.
What’s the impact?
- Practical for real-world use: TeFlow runs fast and doesn’t need hand-labeled motion data, making it scalable for large fleets or long drives.
- Better handling of occlusions and sparse data: By learning from multiple frames, it keeps motion estimates steady even when objects disappear for a moment.
- Useful beyond scene flow: More accurate 3D motion can improve related tasks like predicting future motion, building 3D models of moving objects, and understanding road occupancy over time.
In simple terms, TeFlow teaches a fast model to “follow” objects more reliably by listening to several moments in time and letting them agree on the best direction—much like asking multiple witnesses rather than relying on a single snapshot.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps, uncertainties, and unresolved questions that future work could address to strengthen, generalize, and better understand TeFlow.
- Undefined term in weighting: The reliability weight uses , but is not defined in the paper (e.g., is it temporal distance, recency, or something else?). This omission hinders reproducibility and sensitivity analysis.
- Reliance on external preprocessing: Training depends on
DUFOMapfor static/dynamic segmentation andHDBSCANfor clustering. The paper does not quantify sensitivity to errors in these components, nor provide robustness analysis when segmentation or clustering is noisy, domain-shifted, or misconfigured. - Cluster-level rigidity assumption: Supervision uses a single translational vector per cluster (no rotation or non-rigid modeling). How does this affect articulated objects, rotating rigid bodies, and intra-cluster motion variation? Would SE(3) per-cluster or locally rigid/non-rigid models yield better supervision?
- Fixed directional threshold: Consensus relies on binary directional consistency with a fixed (45°). The paper does not evaluate sensitivity to this choice, nor explore soft/learned thresholds or distance-aware direction metrics that could better handle curved or accelerating motion.
- Magnitude-biased voting: Emphasizing large displacements in may bias supervision toward fast movers and away from slow, small, or partially occluded objects. Quantify this trade-off and explore alternative weighting (e.g., uncertainty-aware, density-aware, or class-aware weights).
- Nearest-neighbor candidate generation risks: External candidates are built from nearest neighbors across frames and the Top-K largest displacements. This can amplify mismatches under occlusions, sparsity, and sensor noise. The paper does not compare to more robust correspondence strategies (e.g., local ICP, graph matching, multi-frame tracklet association, or outlier-rejecting estimators).
- Odometry dependence and error robustness: The approach assumes accurate ego-motion . There is no analysis of robustness to odometry drift, calibration errors, or IMU noise, nor any mitigation (e.g., uncertainty modeling or joint ego-motion refinement).
- Temporal window selection: Performance peaks at five frames, yet the method uses a fixed window and fixed . There is no exploration of adaptive frame selection (based on scene dynamics/occlusion), learned temporal decay, or policies conditioned on LiDAR frame rate and motion statistics.
- Use of future frame in training/inference: The mapping uses as input. The paper does not discuss constraints or alternatives for settings where only past frames are available at decision time (e.g., strictly online prediction or forecasting).
- Generality across backbones: Results are shown primarily with the
DeltaFlowbackbone. It remains unclear how TeFlow’s supervision transfers to other multi-frame architectures (e.g.,Flow4D, 4D convnets, transformers), and whether gains persist across varied feature extractors. - Scalability of candidate pooling: The consensus step scales with the pool size ($1+K(h+1)$) and requires computing the full agreement matrix . There is no runtime/memory analysis for larger windows or higher K, nor exploration of pruning, sub-sampling, or approximate consensus (e.g., M-estimators, RANSAC, robust mean).
- Direction-only consensus: The consensus criterion uses direction agreement but ignores magnitude closeness. This can average flows with similar directions but inconsistent speeds. Investigate combined direction–magnitude consistency or learned similarity metrics.
- Failure modes under severe occlusions: While multi-frame supervision is motivated by occlusion stability, the paper does not characterize failure cases (e.g., long-term occlusion, complete object disappearance, heavy rain/fog) or introduce occlusion-aware gating for candidate generation.
- Domain generalization: Experiments are limited to Argoverse 2, nuScenes (and Waymo in the appendix). There is no study of generalization to different LiDAR configurations (e.g., channel counts, scanning patterns), frame rates, indoor scenes, night/weather conditions, or cross-city distribution shifts.
- Downstream impact: The paper motivates scene flow for motion prediction, reconstruction, and occupancy flow, but does not quantify downstream gains from TeFlow. Evaluating task-level improvements would validate practical benefits.
- Uncertainty estimation: TeFlow outputs deterministic flows without confidence/uncertainty. Incorporating uncertainty (e.g., aleatoric/epistemic) could improve consensus weighting, outlier rejection, and downstream safety-critical use.
- Static/dynamic misclassification handling: The static loss assumes accurate background classification; mislabelled dynamic points can be over-regularized. Examine strategies to detect and correct misclassification (e.g., iterative re-labeling, joint segmentation–flow learning).
- Robustness to evaluation protocol and ground-truth noise: The paper references ground-truth estimation in the appendix, but does not analyze label noise or metric sensitivity (e.g., bucket definitions, region-of-interest changes), which could affect conclusions.
- Hardware and deployment constraints: Per-sequence runtimes are reported, but per-frame latency, memory footprint, and embedded deployment feasibility (e.g., automotive-grade GPUs/NPUs) are not detailed. Provide thorough profiling under realistic deployment constraints.
- Learned consensus vs. heuristic voting: The current consensus is heuristic (binary directional consistency plus magnitude weighting and temporal decay). Investigate end-to-end learnable aggregators (e.g., attention across candidate sets, meta-learned consistency functions) that adapt to scene-specific dynamics.
- Beyond one-step flows: TeFlow trains on flow from to . Extending supervision to multi-step horizons (e.g., ), cycle-consistency across longer sequences, or physically plausible motion priors could further stabilize learning.
- Clustering hyperparameters and purity: The paper does not study sensitivity to
HDBSCANhyperparameters, over-/under-segmentation impacts, or cluster purity (especially for crowded scenes). Consider adaptive or learned clustering that better aligns with motion coherence. - Candidate pool composition and K selection: Aside from a brief ablation, there is limited exploration of how and frame sampling strategies affect accuracy, especially across object scales and speeds. Systematically tune and possibly learn K or sampling policies.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage TeFlow’s findings (multi-frame temporal ensembling, consensus voting, and self-supervised, real-time scene flow):
- Real-time motion estimation in autonomous driving perception stacks
- Sectors: automotive, robotics
- Tools/workflows: integrate as a ROS2 node or perception module feeding downstream tracking, planning, and collision avoidance; use open-source repo and pretrained weights to bootstrap; export per-frame scene flow for fusion with tracking and occupancy flow predictors
- Assumptions/dependencies: requires 3D LiDAR (or equivalent point clouds), reliable odometry for ego-motion compensation, sensor calibration, and sufficient compute on-vehicle; retraining recommended for new sensor configs and environments (e.g., weather, night)
- Feature generation for trajectory forecasting and behavior prediction
- Sectors: automotive, mobility analytics
- Tools/workflows: use stabilized cluster-wise flow as inputs to motion forecasting networks; deploy in pipeline before trajectory prediction models; evaluate gains on AV2/nuScenes-like datasets
- Assumptions/dependencies: alignment with predictor input conventions; careful synchronization with object detection/tracking modules
- Dynamic object reconstruction and mapping (dynamic SLAM support)
- Sectors: mapping, robotics, AR
- Tools/workflows: filter dynamic points from HD map pipelines; reconstruct moving actors (vehicles, pedestrians) using consistent cluster flow; maintain dynamic layers in maps for digital twins
- Assumptions/dependencies: quality of static/dynamic segmentation (e.g., DUFOMap) and clustering (e.g., HDBSCAN); domain tuning for indoor/outdoor differences
- Unlabeled fleet learning (reduce annotation cost)
- Sectors: software/AI ops, automotive
- Tools/workflows: continuous self-supervised training on unlabeled fleet logs; MLOps pipeline using TeFlow to refresh models without manual labels; use consensus scores as QA signals
- Assumptions/dependencies: data governance and storage; compute for periodic training (15–20 hours reported on 10 GPUs); monitoring drift and failure modes
- Warehouse/industrial AGV perception (forklifts, AMRs)
- Sectors: logistics, industrial robotics
- Tools/workflows: deploy on fixed or vehicle-mounted LiDAR in warehouses for pallet and forklift motion estimation; integrate with PLC/SCADA alerts for near-miss prevention
- Assumptions/dependencies: retraining for indoor geometry, sensor placement, reflective surfaces, and occlusions; compute constraints on embedded platforms
- Smart-city traffic monitoring with stationary LiDAR
- Sectors: public sector, transportation
- Tools/workflows: install LiDAR at intersections; compute scene flow to derive speeds and turning behavior for cars, bikes, pedestrians; feed into analytics dashboards
- Assumptions/dependencies: fixed-sensor calibration and odometry proxy (ego-motion = 0); privacy impact assessment (LiDAR reduces PII but policies still apply)
- HD map maintenance (dynamic point suppression)
- Sectors: mapping, GIS
- Tools/workflows: use consensus flow to remove moving points before map stitching; reduce ghosting and map pollution from transients
- Assumptions/dependencies: reliable separation of moving vs. static; appropriate thresholds for cluster consensus
- Anomaly and occlusion detection via consensus confidence
- Sectors: safety monitoring, QA tooling
- Tools/workflows: use low consensus (pre-aggregation voting scores) as a real-time health signal for sensor occlusion, rain/snow, or calibration issues; trigger fallback policies
- Assumptions/dependencies: calibrated thresholds; aggregation window tuned to platform dynamics; handling of persistent low-visibility conditions
- Edge robotics (drones, delivery bots) collision avoidance
- Sectors: robotics
- Tools/workflows: run feed-forward flow on Jetson-class hardware; quantize/prune model; fuse with planning for dynamic obstacle avoidance
- Assumptions/dependencies: availability of lightweight 3D sensing (solid-state LiDAR or depth sensor); power/latency constraints
- Security/perimeter monitoring with LiDAR
- Sectors: security, facilities
- Tools/workflows: install LiDAR around perimeters; compute scene flow to track intruders, vehicles; integrate with VMS/PSIM systems
- Assumptions/dependencies: coverage planning; nighttime and weather robustness; compliance with site policies
- AR/VR occlusion and dynamic scene handling (depth-equipped devices)
- Sectors: AR/VR, consumer electronics
- Tools/workflows: use stabilized scene flow to improve occlusion, re-localization, and dynamic interaction in depth-sensor-equipped devices (e.g., tablets/phones, depth cameras)
- Assumptions/dependencies: retraining for low-power, low-resolution depth sensors; energy constraints on-device
- Research and education baseline for multi-frame self-supervision
- Sectors: academia, education
- Tools/workflows: adopt OpenSceneFlow code/weights for labs, benchmarking, and coursework in CV/robotics; use TeFlow as a teacher to distill smaller models without costly teachers
- Assumptions/dependencies: GPU availability; dataset compatibility and preprocessing; adherence to repo’s license
Long-Term Applications
These opportunities require further research, scaling, domain adaptation, or regulatory work before widespread deployment:
- Cross-modal and multi-modal extensions (LiDAR+camera+radar; RGB-D; event cameras)
- Sectors: robotics, software
- Potential products: “Temporal Consensus Module” adapted for optical flow, radar-flow, or fused scene flow; plug-in for AV perception stacks
- Assumptions/dependencies: new correspondence strategies across modalities, calibration, and training data; redesign of consensus thresholds for different noise models
- Certification-grade AV perception for L3+/robotaxis
- Sectors: automotive, policy/regulatory
- Potential products: validated scene-flow module with safety cases; standardized conformance tests using three-way EPE and bucket-normalized metrics
- Assumptions/dependencies: formal verification, safety engineering, extreme weather robustness, redundancy with cameras/radar; regulatory approvals
- Medical 4D motion estimation (e.g., cardiac/respiratory motion)
- Sectors: healthcare
- Potential products: motion-tracking in ultrasound or 4D CT/MRI via point-cloud or surface representations with temporal ensembling
- Assumptions/dependencies: adapting to medical data formats and physics, clinical validation, and regulatory clearance; rethinking static/dynamic partitioning and clustering
- City-scale dynamic digital twins
- Sectors: smart cities, infrastructure, real estate
- Potential products: dynamic layers for digital twins driven by fleet and roadside sensors; real-time traffic and pedestrian flow maps
- Assumptions/dependencies: large-scale data sharing agreements, privacy frameworks, compute/storage scaling, and standardized APIs
- Consumer AR glasses and mobile devices (on-device scene flow)
- Sectors: consumer electronics
- Potential products: ultra-light models for battery-operated devices enabling persistent dynamic occlusion and interaction
- Assumptions/dependencies: hardware acceleration, quantization/compression, robust performance with sparse/low-quality depth; thermal constraints
- Maritime/aerial autonomy (ships, UAVs)
- Sectors: transportation, defense
- Potential products: scene-flow-based collision avoidance in cluttered harbors or urban airspaces using 3D LiDAR or radar point clouds
- Assumptions/dependencies: domain adaptation to different motion statistics and reflectivity; sensor survivability in harsh environments
- Energy/industrial asset monitoring (structural deflection, moving machinery)
- Sectors: energy, manufacturing
- Potential products: flow-based monitoring of blades, cranes, pipelines with fixed LiDAR; predictive maintenance dashboards
- Assumptions/dependencies: sub-centimeter accuracy on long-range sensors; robust segmentation of rigid vs. non-rigid motion; calibration stability
- General-purpose “temporal consensus” self-supervision library
- Sectors: AI R&D, software tooling
- Potential products: reusable toolkit for multi-frame self-supervision (flow, occupancy flow, non-rigid reconstruction), with plug-ins for PCL/Open3D/ROS
- Assumptions/dependencies: API standardization, broad dataset coverage, and community adoption
- Sustainability and green-AI initiatives
- Sectors: energy, policy
- Potential products: guidelines and tooling that quantify compute and energy savings from feed-forward vs. optimization-based pipelines; procurement criteria favoring efficient models
- Assumptions/dependencies: accepted measurement protocols, lifecycle assessment frameworks, and vendor participation
Cross-cutting Assumptions and Dependencies
- Sensor and odometry requirements: TeFlow assumes access to reliable odometry to separate ego-motion and multi-frame 3D point clouds (typically LiDAR). Domain shifts (sensor models, mounting, weather) necessitate retraining/fine-tuning.
- Preprocessing: Static/dynamic segmentation (e.g., DUFOMap) and clustering (e.g., HDBSCAN) quality affect supervision; parameters like cosine thresholds, Top-K, and decay factor must be tuned to environment and frame rate.
- Compute budgets: While inference is real-time, training still needs multi-GPU resources; embedded deployment may require model compression.
- Window size: Best performance reported with ~5 frames; larger windows can degrade quality if they introduce inconsistent motion/noise.
- Safety/compliance: Safety-critical deployments require extensive validation and fallback strategies; privacy and data governance remain essential even with “label-free” learning.
Glossary
- 4D convolutions: Convolution operations over three spatial dimensions plus time, enabling processing of spatio-temporal voxel data. "use 4D convolutions~\cite{choy20194d} to process voxelized point-cloud sequences."
- Chamfer distance: A point-set distance metric commonly used to measure alignment between two point clouds. "The geometric consistency loss $\mathcal{L}_{\text{geom}$ applies multi-frame Chamfer and dynamic Chamfer distances to ensure that the source point cloud, warped by the predicted flows, aligns with neighboring frames."
- consensus matrix: A matrix encoding pairwise agreement (e.g., directional consistency) among candidate motion vectors. "It is measured through a consensus matrix ."
- coordinate-based MLP: A neural network that maps input coordinates directly to outputs (e.g., flow), optimized per scene or frame pair. "The pioneering NSFP~\cite{li2021neural} optimizes a small coordinate-based MLP for each two-frame pair."
- Delta scheme: A computational strategy that operates on differences between voxelized frames to reduce input expansion and cost. "DeltaFlow~\cite{zhang2025deltaflow} introduces a computationally lightweight ` scheme' that computes the difference between voxelized frames."
- DeltaFlow: A multi-frame backbone architecture that efficiently processes voxelized point-cloud sequences via the Delta scheme. "We build TeFlow on top of the multi-frame DeltaFlow backbone~\cite{zhang2025deltaflow}."
- dynamic Chamfer distance: A variant of Chamfer distance tailored to dynamic points across frames to enforce motion-aware geometric consistency. "applies multi-frame Chamfer and dynamic Chamfer distances"
- dynamic cluster loss: A training objective that supervises coherent motion within dynamic clusters via both point-level and cluster-level terms. "The proposed dynamic cluster loss $\mathcal{L}_{\text{dcls}$ is the sum of the point-level and cluster-level terms:"
- Dynamic Bucket-Normalized EPE: An error metric that normalizes endpoint error by mean speed within predefined motion buckets to compare across classes. "Dynamic Bucket-Normalized EPE normalizes the EPE by the mean speed within predefined motion buckets, providing a fairer comparison across different object classes."
- ego-motion: Motion induced by the movement of the sensor platform (e.g., vehicle), typically estimated and separated from object motion. "ego-motion flow $\mathcal{F}_{\text{ego}$ induced by the movement of the vehicle"
- End Point Error (EPE): The L2 distance between predicted and ground-truth flow vectors, measuring flow accuracy. "EPE measures the L2 distance between predicted and ground-truth flow vectors in meters."
- feed-forward: A modeling paradigm where predictions are produced in a single forward pass, without costly test-time optimization. "feed-forward methods~\cite{zhang2024seflow,lin2025voteflow} achieve high efficiency by generating results in a single forward pass"
- HDBSCAN: A hierarchical density-based clustering algorithm used to discover dynamic clusters in point clouds. "dynamic clusters are pre-computed using HDBSCAN~\cite{campello2013density}."
- knowledge distillation: A training technique where a “teacher” model provides pseudo-labels or guidance to a faster “student” model. "A prominent approach is knowledge distillation, exemplified by ZeroFlow~\cite{zeroflow}."
- LiDAR point clouds: 3D point sets captured by LiDAR sensors, used as input for scene flow estimation. "Given a continuous stream of LiDAR point clouds, our goal is to train a feed-forward network"
- nearest-neighbor search: An operation that finds the closest point in a target set, often used for correspondence and alignment. "where denotes nearest-neighbor search."
- odometry: Estimation of platform motion over time; used to align frames and separate ego-motion from residual object motion. "Since ego-motion can be obtained directly from odometry, the network is trained only to estimate the residual flow."
- ordinary differential equation: A continuous-time dynamical system formulation used to model scene flow across sequences. "reframes scene flow as the task of estimating a continuous ordinary differential equation over an entire sequence."
- rigidity loss: A loss enforcing that points within a cluster move coherently under a shared rigid motion. "Each cluster is assumed to undergo a shared rigid motion and is trained with a rigidity loss, i.e., dynamic cluster loss, enforcing coherent motion within the group."
- scene flow: The 3D motion field of points between consecutive point clouds. "Scene flow determines the 3D motion of each point between consecutive point clouds"
- self-supervised learning: Training without ground-truth labels by exploiting geometric or temporal consistency in the data. "Self-supervised methods eliminate the dependency on ground-truth annotations and can be broadly categorized into optimization-based and feed-forward approaches."
- temporal ensembling: Aggregating motion cues across multiple frames to form stable and consistent supervisory signals. "TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames."
- voxel grid: A volumetric discretization of 3D space used to represent point clouds for convolutional processing. "represented as a voxel grid with $0.15$\,m resolution."
- voxel-based backbone: A neural network architecture that operates on voxelized inputs to efficiently process large-scale point clouds. "use voxel-based backbones to efficiently process large-scale point clouds"
- voting scheme: A consensus mechanism that aggregates candidate motions based on agreement and reliability to select a representative flow. "applies a voting scheme to aggregate the most consistent ones."
Collections
Sign up for free to add this paper to one or more collections.