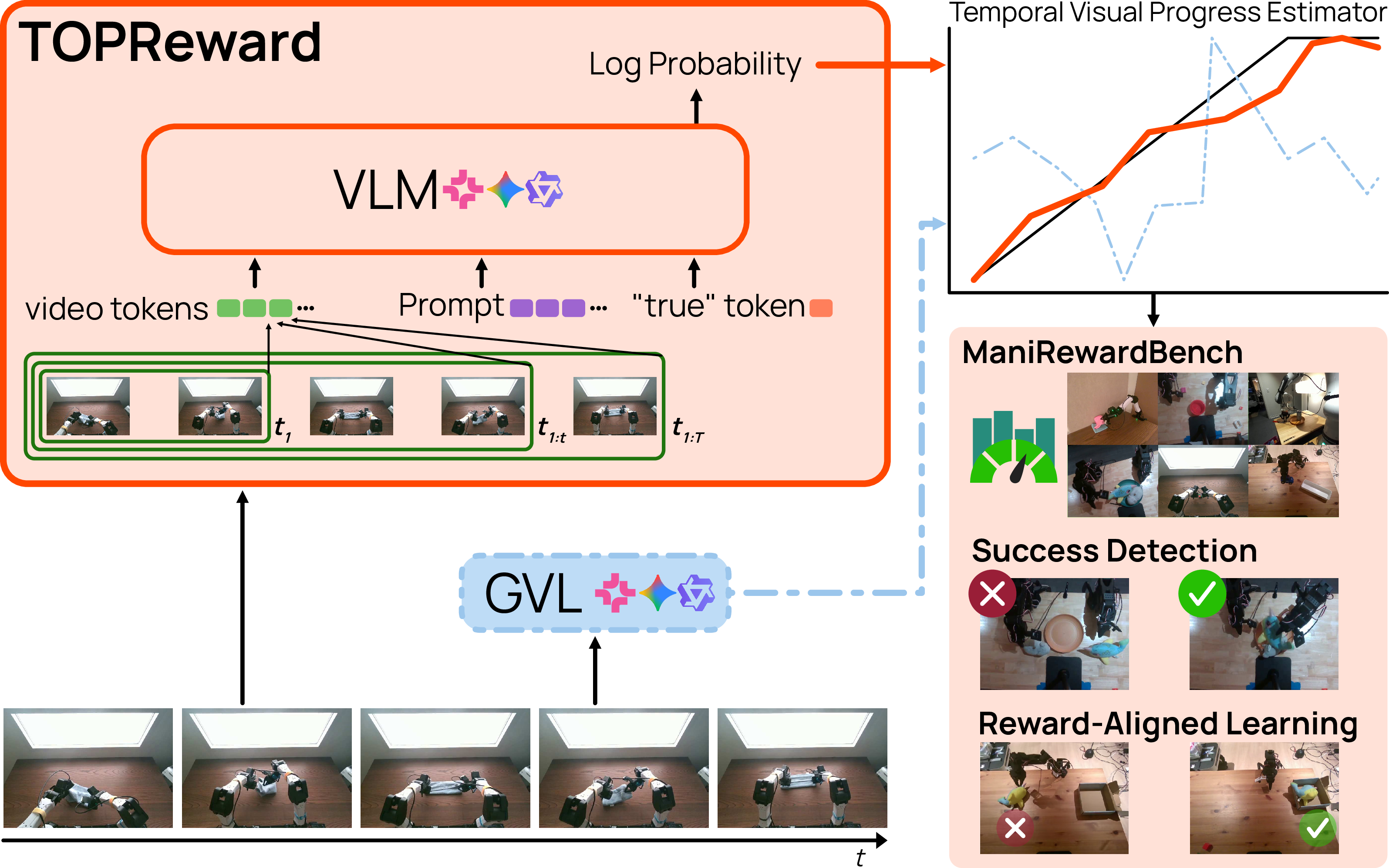
TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for Robotics
Abstract: While Vision-Language-Action (VLA) models have seen rapid progress in pretraining, their advancement in Reinforcement Learning (RL) remains hampered by low sample efficiency and sparse rewards in real-world settings. Developing generalizable process reward models is essential for providing the fine-grained feedback necessary to bridge this gap, yet existing temporal value functions often fail to generalize beyond their training domains. We introduce TOPReward, a novel, probabilistically grounded temporal value function that leverages the latent world knowledge of pretrained video Vision-LLMs (VLMs) to estimate robotic task progress. Unlike prior methods that prompt VLMs to directly output progress values, which are prone to numerical misrepresentation, TOPReward extracts task progress directly from the VLM's internal token logits. In zero-shot evaluations across 130+ distinct real-world tasks and multiple robot platforms (e.g., Franka, YAM, SO-100/101), TOPReward achieves 0.947 mean Value-Order Correlation (VOC) on Qwen3-VL, dramatically outperforming the state-of-the-art GVL baseline which achieves near-zero correlation on the same open-source model. We further demonstrate that TOPReward serves as a versatile tool for downstream applications, including success detection and reward-aligned behavior cloning.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces TOPReward, a new way to help robots learn from videos using vision-LLMs (VLMs). Instead of asking the model to write down numbers like “30% done” or “80% done,” TOPReward reads the model’s internal confidence about whether a task is being completed and turns that into a smooth “progress bar” over time. This gives robots a helpful, automatic reward signal—like points—without extra training or hand-made rules for each task.
Goals and Questions
The paper tries to answer simple but important questions:
- Can we use a pretrained video vision-LLM (VLM) to tell how far along a robot is in a task, without any extra training?
- Can this “progress bar” work across many different robots and tasks?
- Is reading the model’s internal signals (its token probabilities) better than asking it to output numbers in text?
- Can this signal help with practical things like detecting success, filtering data, and improving robot policies?
How It Works (Methods)
Think of a vision-LLM as a very smart viewer that watches a video and reads an instruction, like “Put the cube in the cup.” When it generates text, the model doesn’t just pick words—it has internal probabilities about which word comes next. TOPReward uses those hidden probabilities instead of relying on the model to write neat, accurate numbers.
Here’s the core idea in everyday terms:
- The model watches the video up to a certain point (a “prefix” of the trajectory) and reads the instruction.
- Instead of asking “What percent done is this?”, TOPReward asks a yes/no question: “Is this video completing the task?” and looks at the model’s internal probability for “True.”
- That probability acts like a confidence meter. As the video shows more steps toward finishing the task, the “True” confidence should go up.
- To get a smooth progress curve, the method repeats this at several points in the video (early, middle, late), then rescales the confidence to a clean 0–1 progress bar.
- For learning a better policy (teaching the robot), the team converts progress increases into small rewards, so good actions get slightly more weight than bad or irrelevant actions.
Key terms explained simply:
- Vision-LLM (VLM): A model that understands both images/videos and text.
- Token probability: How likely the model thinks a specific word (token) will show up next. “True” is a token; a high probability means the model is confident.
- Zero-shot: Using a model as-is, with no extra training.
- Trajectory prefix: The video up to a certain time point (like “first 10 seconds”).
- Normalization: Scaling values so they fit between 0 and 1, like turning a raw score into a percent.
Main Findings
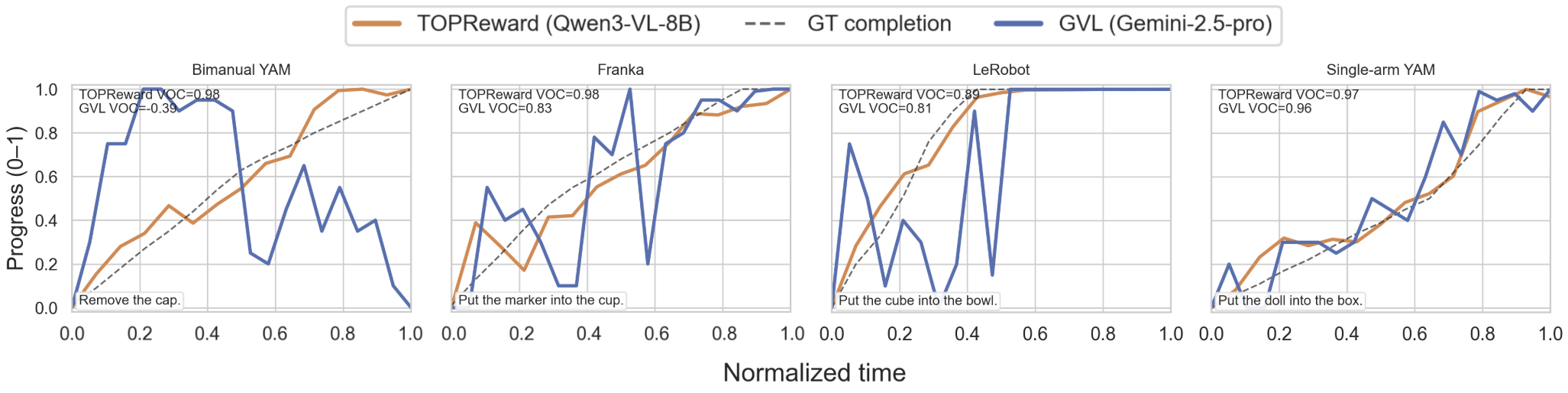
The authors tested TOPReward on many real robot tasks and compared it to a popular baseline called GVL (which asks VLMs to output numeric progress for shuffled frames). They looked at whether scores rise as the video goes forward—a metric they call Value-Order Correlation (VOC). In simple terms, VOC checks if the “progress bar” goes up in order.
Highlights:
- Across 130+ real-world tasks and several robot types (Franka, YAM, SO-100/101), TOPReward gave a very consistent and high-quality progress signal.
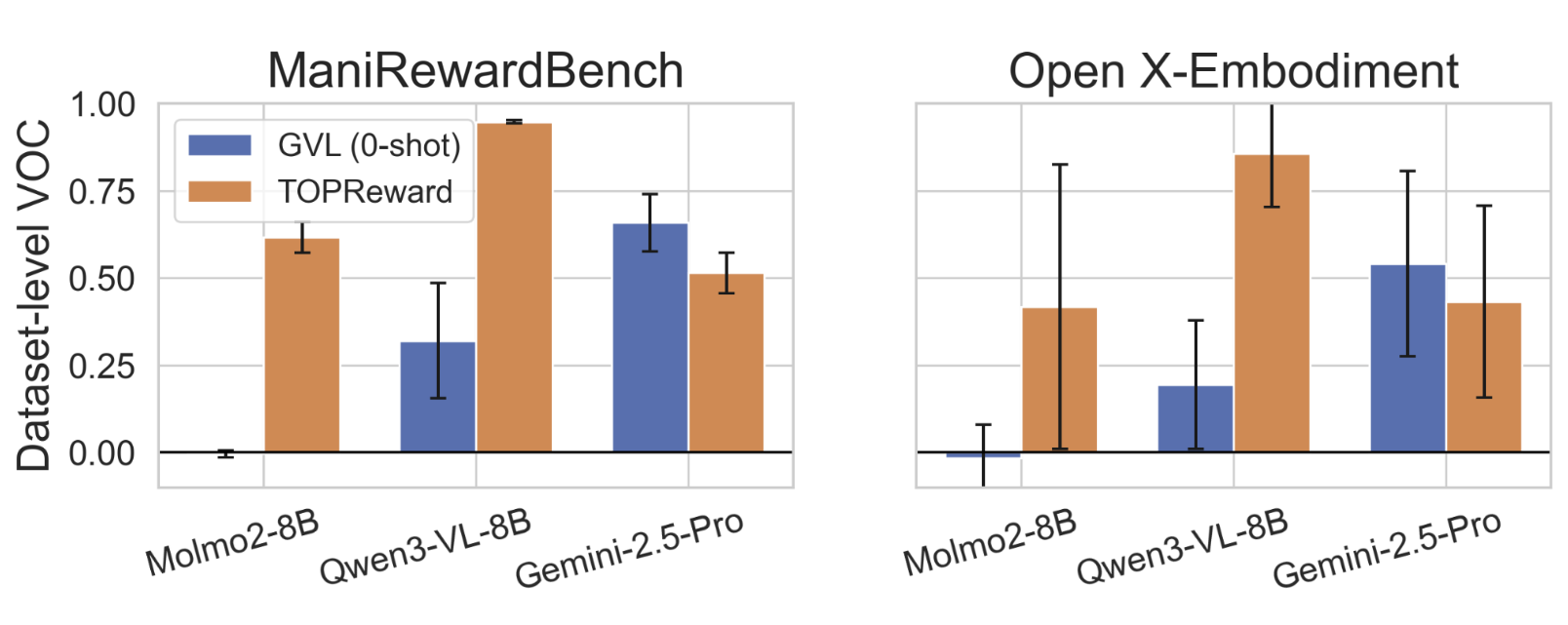
- On the open-source model Qwen3-VL, TOPReward reached about 0.947 VOC on their Mani benchmark—far better than GVL, which was near zero on open-source models.
- On the Open X-Embodiment data (a large mix of robot datasets), TOPReward also outperformed GVL on open-source models (e.g., Qwen3-VL average VOC ~0.857 vs. GVL ~0.194).
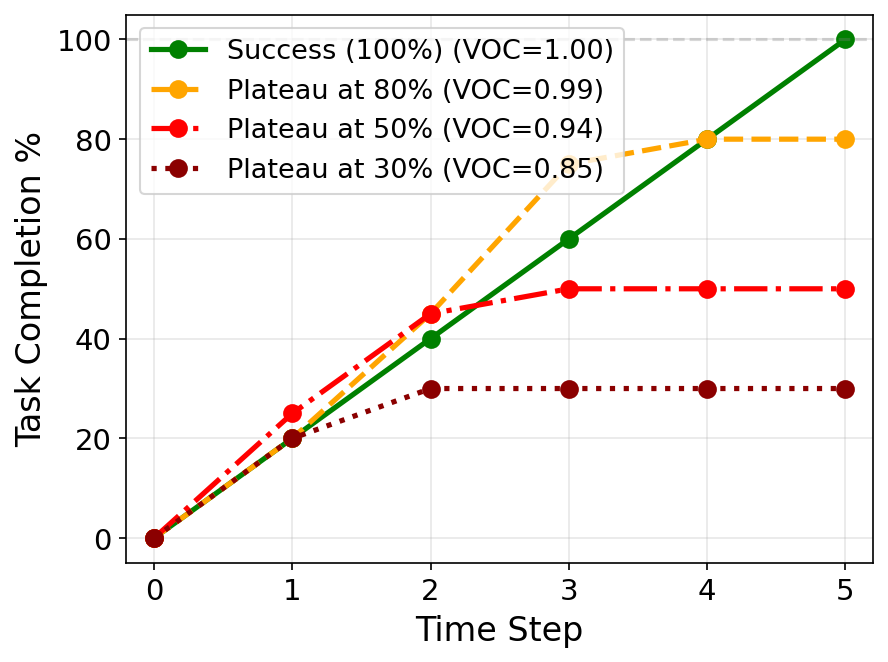
- Success detection: Because TOPReward uses absolute confidence (not just ordering), it was better at telling successful attempts from failed ones on open-source models. That’s important because VOC alone can look “good” even when a video plateaus early and never actually finishes the task.
- Real-world robot improvement: Using TOPReward’s progress signal to weight training examples (advantage-weighted behavior cloning), they improved success rates across six real tasks, sometimes turning inconsistent success into consistent completion (e.g., “Place doll in box” went from 7/10 to 10/10).
- Prompt formatting matters: Forcing a “chat template” hurt TOPReward’s performance, showing that direct access to the model’s token probabilities (without extra wrapping) is best.
Why It Matters
- Scaling robot learning: Robots need rewards to learn, but making hand-crafted rewards for every new task is slow and fragile. TOPReward offers a general, automatic reward signal that works across many tasks.
- Works with open-source models: Instead of depending on proprietary systems, TOPReward unlocks strong performance from open models by reading their internal confidence rather than asking them to write precise numbers.
- Better reliability: Numeric text outputs can be unstable or poorly calibrated. Using token probabilities is like reading the model’s “thought bubble” directly, which is often more trustworthy.
- Practical impact: The same progress signal helps detect success, filter datasets, and improve policies—so it’s useful in the full pipeline from data to deployment.
Simple Conclusion
TOPReward turns a vision-LLM’s hidden confidence into a progress bar for robot tasks, without extra training. This progress bar is stable, general, and useful: it helps robots learn better and makes it easier to judge whether tasks are being completed. By looking inside the model’s probabilities instead of demanding perfect numeric answers, TOPReward makes zero-shot reward modeling practical on open-source video models and helps pave the way for more reliable, scalable robot learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is concrete to guide follow-up research.
- Absolute progress calibration across episodes is unresolved: min–max normalization is per-trajectory, preventing direct comparison and aggregation of progress across tasks, instructions, and embodiments. Develop global calibration methods to map log probabilities to comparable completion scales.
- Monotonicity is not guaranteed: the method does not enforce strictly increasing progress curves and relies on empirical smoothness. Investigate monotonic post-processing or prompt designs that provably yield monotonic temporal signals.
- Prompt sensitivity is underexplored: performance degrades with chat templates and may depend on prompt phrasing. Conduct systematic robustness studies across paraphrases, negations, compound instructions, and multilingual variants.
- Token choice is ad hoc: using only the “True” token lacks analysis versus alternatives (e.g., logit difference between “True” and “False”, multi-token sequences, capitalization effects). Evaluate tokenization strategies across model families with ablations.
- Logit access is a practical constraint: many proprietary VLM APIs do not expose logits. Explore proxy methods (e.g., calibration heads, distilled classifiers) or API-compatible inference tricks to recover comparable signals.
- Instruction compositionality is untested: the approach assumes a single goal sentence and does not handle multi-goal, branching, conditional, or disjunctive tasks. Extend to compositional progress that tracks and aggregates subgoals.
- Temporal granularity and budget are not analyzed: K uniformly spaced prefixes are used without sensitivity studies for K, frame sampling rate, or trajectory length. Design adaptive prefix selection under compute budgets.
- Computational cost is unquantified: K forward passes per trajectory may be prohibitive for real-time deployment. Measure latency and propose caching/incremental attention strategies for on-robot use.
- Viewpoint and environment robustness is unmeasured: the method’s sensitivity to camera changes, occlusions, lighting, clutter, and multi-view settings is not quantified. Evaluate and improve robustness to heterogeneous sensing conditions.
- Fine-grained manipulation limitations are acknowledged but not addressed: small-object, precise alignment tasks likely produce noisy estimates. Investigate higher-resolution inputs, depth/tactile sensing, or perception-enhanced backbones.
- Cross-model generality is narrow: only Qwen3-VL-8B, Molmo2-8B, and Gemini-2.5-Pro are tested. Benchmark across a broader set (e.g., LLaVA-Video, InternVL, Idefics, VILA) to validate general applicability.
- Benchmark reproducibility is limited: Mani remains restricted-access, hindering external replication and stress-testing. Provide a public subset, synthetic analogs, or a standardized evaluation harness for community use.
- Baseline coverage is incomplete: comparisons focus on GVL; trained reward models (RoboReward, RoboDopamine) and embedding-based methods (VIP, LIV, R3M) are not evaluated head-to-head. Run unified evaluations to establish relative performance.
- Probability calibration is not assessed: no reliability diagrams, Brier scores, or calibration metrics are reported for token probabilities vs. success labels. Quantify calibration and apply temperature/Platt scaling if needed.
- Success detection thresholding is not operationalized: ROC-AUC is reported without practical threshold selection or cost-sensitive analysis. Develop task-agnostic and task-specific threshold calibration procedures.
- Domain generalization is unclear: the focus is manipulation; navigation, mobile robotics, deformables, and long-horizon tasks remain untested. Perform cross-domain transfer studies.
- Reward hacking and safety are not addressed: agents could learn to exploit visual cues (e.g., camera positioning) to increase “True” probability without completing tasks. Design adversarial/red-teaming evaluations and mitigation strategies.
- Language variability is untested: robustness to paraphrases, synonyms, verbosity, grammar errors, and non-English instructions is unknown. Build instruction canonicalization or semantic normalization pipelines.
- Stage-aware outputs are missing: Mani provides stage annotations, but TOPReward does not infer subtask boundaries or stage completion. Extend the method to predict stage transitions and stage-aligned rewards.
- Statistical significance is absent: VOC improvements lack confidence intervals or hypothesis testing. Report bootstrapped CIs and significance tests for all key metrics.
- Error analysis is lacking: failure cases where TOPReward misorders frames or misclassifies success are not dissected. Provide a taxonomy of errors and diagnostic tools to target weaknesses.
- Hyperparameter sensitivity is unstudied: ε in min–max normalization, τ and δ_max in advantage weighting are set without ablation. Perform sensitivity analyses and automatic tuning.
- Closed-source constraints persist: Gemini’s mandatory chat template degrades performance; mitigation strategies (prompt restructuring, system prompt control, logit retrieval via hidden endpoints) are unexplored.
- Online RL integration is missing: results are limited to offline AWR fine-tuning. Test on-policy RL with TOPReward as the reward, measure sample efficiency and stability under noisy signals.
- Real-time deployment metrics are absent: no latency, throughput, or memory profiling on robot hardware. Quantify performance and optimize for deployment constraints.
- Multimodal extensions are not explored: the method uses only video. Integrate proprioception, audio, depth, and tactile inputs; evaluate whether multimodal conditioning improves progress estimation.
- Failure-set coverage is limited: the failure split (23 tasks, 156 episodes) may not capture diverse failure modes (recoveries, regressions, partial reversions). Curate larger, varied failure datasets and analyze behavior.
- Cross-episode comparability remains partial: success detection uses last frames, but per-episode normalization hampers absolute comparisons. Develop global priors or calibration curves to enable cross-episode ranking.
- Tokenization variability across models is not handled: “True” may tokenize differently across VLMs. Standardize token mapping or use string-free logit probes (e.g., contrastive heads) for portability.
- Inference settings influence logits but are not controlled: temperature and decoding configurations can affect log probabilities. Evaluate and standardize inference settings across models.
- Dataset bias and ethical considerations are unexamined: potential biases in Mani and OXE subsets (objects, environments, demographics) may affect generalization. Audit datasets and report bias mitigation approaches.
- Long-horizon and idle-phase handling is unclear: uniform prefix sampling may underrepresent tasks with extended idle periods or delayed evidence. Develop hierarchical or adaptive sampling schemes.
Glossary
- Advantage-weighted behavior cloning: A variant of behavior cloning that weights training examples by estimated advantage to emphasize more promising actions. Example: "using it to weight expert examples in offline advantage-weighted behavior cloning."
- Advantage-weighted regression (AWR): A supervised RL method that reweights samples by their estimated advantage to improve policy learning. Example: "advantage-weighted regression (AWR) \citep{peng2019advantage, peters2007reinforcement}"
- Autoregressive text generation: Generating tokens sequentially where each token is conditioned on previous ones; often used in LLMs. Example: "bypasses autoregressive text generation entirely."
- Behavior cloning (BC): Learning a policy by directly imitating expert actions from demonstrations. Example: "We compare AWR performance against a behavior cloning (BC) baseline that directly minimizes the unweighted flow matching loss on the same dataset."
- Bimanual YAM: A specific robot platform with two manipulators (arms) used in manipulation tasks. Example: "Data are collected across four robot platforms (Franka, SO-100/101, single-arm YAM, and bimanual YAM)"
- Chat template: A system-specific wrapper format for prompts that can affect model behavior and outputs. Example: "adding a chat template substantially degrades performance."
- Diffusion-based visuomotor policies: Control policies trained with diffusion models to map visual inputs to motor actions. Example: "trains diffusion-based visuomotor policies directly on real robots using human-provided success signals,"
- Embodiment shifts: Changes in robot bodies or configurations that challenge generalization across different platforms. Example: "enabling evaluation under embodiment shifts."
- Flow matching loss: A training objective used with flow/diffusion models to align generated trajectories with data. Example: "a behavior cloning (BC) baseline that directly minimizes the unweighted flow matching loss on the same dataset."
- Generative Value Learning (GVL): A training-free method that prompts VLMs to assign progress scores by ordering frames. Example: "Generative Value Learning (GVL)~\cite{ma2024vision} poses progress prediction as a temporal ordering problem:"
- Imitation learning: Learning policies by mimicking expert demonstrations rather than optimizing explicit rewards. Example: "we integrate into imitation and reinforcement learning pipelines"
- Min-max normalization: Rescaling values to a [0,1] range using their minimum and maximum within a set. Example: "We therefore use min-max normalization to map rewards to a normalized progress score"
- Open X-Embodiment (OXE): A large multi-dataset collection of robot data spanning tasks and platforms. Example: "The Open X-Embodiment (OXE) dataset~\citep{o2024open} is a collection of 50 academic robot datasets spanning diverse tasks, camera configurations, and robot platforms."
- ROC-AUC: Area under the Receiver Operating Characteristic curve; evaluates binary classification performance across thresholds. Example: "We frame success detection as binary classification and report ROC-AUC."
- Reward shaping: Modifying or augmenting reward signals to provide dense guidance for learning. Example: "but produce signals too coarse for dense reward shaping"
- Spearman's rank correlation: A nonparametric measure of monotonic association between two ranked variables. Example: "we use Value-Order Correlation (VOC) to measure Spearman's rank correlation between the chronological order of input video frames and the predicted values,"
- Stage-aware annotation: Labeling trajectories with ordered subtask stages to enable fine-grained progress evaluation. Example: "Stage-aware annotation."
- Subtask boundaries: Temporal points that delimit stages in a task, used to assess progress. Example: "computed from annotated subtask boundaries"
- Temporal value function: A function that estimates task progress or value over time, typically increasing toward completion. Example: "progress estimation functions as a temporal value function that monotonically increases as a task nears completion,"
- Token logits: The pre-softmax scores a LLM assigns to tokens, reflecting its internal beliefs before normalization. Example: " extracts task progress directly from the VLM's internal token logits."
- Token probability: The probability assigned by a LLM to a specific next token or token sequence. Example: "Token probability as the reward"
- Universal Value Learning: A framework that generalizes value functions across goals or tasks. Example: "aligning it with the principles of Universal Value Learning"
- Value-Order Correlation (VOC): A metric measuring how well predicted values preserve the temporal order of frames (via rank correlation). Example: "we use Value-Order Correlation (VOC) to measure Spearman's rank correlation"
- Video Vision-LLMs (VLMs): Multimodal models that understand video inputs and text jointly. Example: "pretrained video Vision-LLMs (VLMs)"
- Vision-Language-Action (VLA): Models that connect visual perception, language understanding, and action generation for control. Example: "Vision-Language-Action (VLA) models have seen rapid progress in pretraining,"
- Visual question-answering: A task where models answer questions about visual inputs, often used to probe understanding. Example: "casts progress estimation as visual question-answering"
- Zero-shot: Performing a task without any additional task-specific training or fine-tuning. Example: "In zero-shot evaluations across 130+ distinct real-world tasks and multiple robot platforms (e.g., Franka, YAM, SO-100/101), achieves 0.947 mean Value-Order Correlation (VOC) on Qwen3-VL,"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with current capabilities of TOPReward (token-logit-based, zero-shot progress estimation), along with sector links, potential tools/workflows, and key assumptions/dependencies that could affect feasibility.
- Zero-shot success detection and stop conditions in robot deployments (Robotics, Manufacturing, Logistics, Home/Service)
- What: Use the model’s final “True” token probability over recent frames to detect task completion or failure and trigger stop/retry/fallback policies.
- Tools/workflows:
- ROS2 node “success_detector” exposing a gRPC/REST endpoint;
- On-robot module that gates gripper release, tool retraction, or next-step transitions.
- Assumptions/dependencies:
- Access to a video VLM with logit output and video input support (e.g., Qwen3-VL-8B);
- Camera views capture salient evidence of completion;
- Prompt should avoid chat templates that degrade performance.
- Reward-aligned behavior cloning via advantage-weighted regression (R&D Labs, Industrial Automation)
- What: Weight imitation learning updates by progress increments (as in the paper’s TOP-AWR) to improve policies from mixed-quality demonstrations without hand-crafted rewards.
- Tools/workflows:
- A plug-in for OpenVLA/Octo/LeRobot pipelines to compute per-step weights;
- MLOps scripts to log progress curves and weight distributions during fine-tuning.
- Assumptions/dependencies:
- Requires K forward passes over prefixes per trajectory;
- Uses per-episode min–max normalization (limits absolute cross-episode comparability);
- Backbone VLM quality bounds performance on fine-grained tasks.
- Automatic dataset curation and filtering by completion/progress (Academia, Industry ML Ops)
- What: Rank or filter robot trajectories by inferred completion to build higher-quality training sets and reduce annotation workload.
- Tools/workflows:
- Dataset scoring job that outputs per-episode completion probabilities, stage-change markers, and removal of near-zero-progress clips;
- Integration with Hugging Face/LeRobot datasets and data versioning.
- Assumptions/dependencies:
- Sufficient visual evidence across frames;
- Instruction strings must faithfully describe the intended task;
- Zero-shot model bias may require periodic spot-checks.
- Online monitoring and KPI dashboards for robot fleets (Manufacturing, Warehousing, Field Robotics)
- What: Track real-time progress curves and success rates per task and environment; trigger alerts when progress plateaus.
- Tools/workflows:
- “Progress Meter” microservice feeding Prometheus dashboards;
- Threshold-based alerts when progress stagnates or false-positive success is detected.
- Assumptions/dependencies:
- Stable video pipeline;
- On-robot compute/resources for VLM inference or low-latency edge-server;
- Calibrated thresholds tuned to task families.
- Stage-aware evaluation and CI for policy releases (Academia, Robotics QA)
- What: Use progress traces to automatically verify monotonic progress across subtask boundaries in regression tests before deploying updated policies.
- Tools/workflows:
- CI checks that compute VOC and plateau metrics over held-out evaluation suites (e.g., Mani-like staging);
- Auto-regression reports for PR gates.
- Assumptions/dependencies:
- Access to evaluation videos;
- Subtask boundary metadata optional but improves interpretability.
- Semi-automated annotation assistance (Academia, Data Labeling Vendors)
- What: Suggest success/failure labels and rough stage boundaries to reduce human labeling cost and time.
- Tools/workflows:
- Labeling UI plug-in that overlays progress curves and candidate boundary frames for quick human confirmation.
- Assumptions/dependencies:
- Human-in-the-loop verification recommended;
- Ambiguous/occluded scenes may still require manual correction.
- Retrofitting legacy robot cells with task-completion detection (Manufacturing)
- What: Add a camera and a small GPU to legacy cells to provide a non-invasive, zero-shot completion signal for PLCs/robot controllers.
- Tools/workflows:
- Edge appliance running Qwen3-VL with a simple “completion signal” digital output line to a PLC;
- Failsafe logic using low “True” probability thresholds to pause or request operator intervention.
- Assumptions/dependencies:
- Regulatory and safety approvals;
- Robustness across lighting/occlusion;
- Stable network between appliance and cell controller.
- Education and rapid prototyping in university labs (Education, Academia)
- What: Provide students with a plug-and-play progress/reward module for RL/IL projects, reducing the need for bespoke reward engineering.
- Tools/workflows:
- Python SDK
topreward.get_progress_curve(video, instruction, k); - Colab templates and ROS nodes.
- Assumptions/dependencies:
- Availability of open-source VLM weights and sufficient GPU memory.
- Benchmarking and fair comparisons using Mani-style evaluation (Academia, Open-Source Communities)
- What: Adopt stage-aware progress evaluation to compare reward models and policies across embodiments.
- Tools/workflows:
- Public evaluation harness mirroring Mani’s metrics and VOC;
- Leaderboards and badges for progress consistency and success detection ROC-AUC.
- Assumptions/dependencies:
- Access to comparable evaluation data (if Mani remains controlled, use alternative public sets with similar annotations).
Long-Term Applications
These use cases are plausible extensions that may require further research, scaling, integration, or regulatory buy-in.
- Autonomous reinforcement learning in the wild with zero manual rewards (Robotics, Service Robots, Warehousing)
- What: End-to-end online RL where progress signals guide exploration and policy improvement across many tasks and embodiments without human reward engineering.
- Potential products/workflows:
- “Reward-as-a-Service” platform exposing progress, success, and safety scores for any robot policy;
- Continual learning loops with automatic curriculum generation based on progress plateaus.
- Additional requirements:
- Robustness to reward hacking/adversarial behaviors;
- Better cross-episode calibration beyond per-episode min–max;
- Multi-view and multi-sensor fusion for occlusion resiliency.
- Home/assistive robots with generalized task-completion understanding (Consumer, Healthcare, Elder Care)
- What: Robots that can verify completion of chores or assistive tasks (e.g., “placed medication in organizer”) and adapt behavior when progress stalls.
- Potential products/workflows:
- Household robot companions with built-in progress/status reporting;
- Care robots logging verifiable task completion for caregivers.
- Additional requirements:
- Stronger fine-grained visual reasoning (small objects, safety-critical subtasks);
- Privacy-preserving on-device inference;
- Regulatory compliance for healthcare environments.
- Process mining and cycle-time analytics from factory/facility video (Manufacturing, Energy, Utilities)
- What: Apply progress estimation to segment long-horizon industrial workflows, measure cycle times, and identify bottlenecks without bespoke instrumentation.
- Potential products/workflows:
- Video-based process intelligence dashboards;
- Automated SOP conformance checks via progress/stage traces.
- Additional requirements:
- Domain adaptation for non-robot actors and mixed human–robot settings;
- Robustness to camera diversity and environmental variability.
- Subtask discovery and compositional policy learning (Academia, Advanced Robotics)
- What: Use inflection points in progress curves to automatically discover stages, enabling options/policies for long-horizon tasks.
- Potential products/workflows:
- Libraries that convert progress plateaus/ramps into reusable skills/options for hierarchical RL.
- Additional requirements:
- Reliable detection of subtle stage boundaries;
- Validation that discovered subtasks align with causal structure of tasks.
- Safety/failure prognostics from internal token probabilities (Robotics, Compliance, Insurance)
- What: Extend logit-based probes to estimate risk, detect anomalies, or predict imminent failure without extra training.
- Potential products/workflows:
- “Failsense” modules that predict when to intervene based on decreasing confidence trends;
- Audit logs for compliance and insurance claims.
- Additional requirements:
- Broader probing beyond “True/False” completion (e.g., hazard tokens);
- Calibration under distribution shift and adversarial conditions.
- Cross-domain video progress understanding (Education, Sports, Construction, Remote Operations)
- What: Generalize the method to non-robot task videos (e.g., assembly instructions, sports drills) to track progress and provide feedback.
- Potential products/workflows:
- Coaching apps that measure drill completion;
- Construction monitoring for task adherence and delay detection.
- Additional requirements:
- Task-agnostic instruction parsing;
- Better handling of human variability and occlusions;
- Adaptation to longer, more complex narratives.
- Standardized reward/validation protocols for robotic certification (Policy, Standards Bodies)
- What: Use zero-shot progress and success detection as part of transparent, reproducible evaluation standards for general-purpose robot policies.
- Potential products/workflows:
- Certification suites with public benchmarks and reference implementations;
- Procurement guidelines requiring progress-based validation.
- Additional requirements:
- Consensus across vendors;
- Open, audited datasets and evaluation harnesses;
- Governance around model updates and version drift.
- Integrated digital twins linking simulated and real progress signals (Software, Simulation, MLOps)
- What: Align progress from real-world video with simulation ground truth to close the sim2real loop and accelerate policy iteration.
- Potential products/workflows:
- Twin dashboards showing predicted (video) vs. actual (sim) progress and discrepancies for rapid debugging.
- Additional requirements:
- Time-synchronization, calibration between sim and real sensors;
- Domain randomization to avoid overfitting to visual shortcuts.
Cross-cutting assumptions and dependencies
- VLM access and inference: Best results currently rely on open-source video VLMs that expose logits (e.g., Qwen3-VL-8B). Some APIs enforce chat templates or hide logits, degrading performance.
- Visual evidence quality: Camera viewpoints, lighting, and occlusions strongly affect progress estimation; multi-view support can mitigate failure modes.
- Task instruction clarity: The instruction must be accurate and specific; ambiguous instructions reduce calibration.
- Compute and latency: Prefix sampling requires multiple forward passes per clip; edge deployment may need model distillation or streaming strategies.
- Calibration and comparability: Per-episode normalization supports within-trajectory progression but limits absolute comparisons across episodes; success detection using end-of-trajectory probabilities helps but may need further calibration for large-scale analytics.
- Ethical and safety considerations: For downstream RL, guard against reward hacking; for real deployments, include human override and logging for accountability.
Collections
Sign up for free to add this paper to one or more collections.