- The paper introduces IA-EiLM, an instance-adaptive modulation framework that enables precise temporal alignment of melody conditions in cover song generation.
- It integrates a Diffusion Transformer backbone with a custom melody encoder to achieve significant improvements in pitch accuracy and overall audio fidelity.
- The approach offers parameter-efficient modulation and robust melody control, setting a new benchmark for controllable cover song synthesis.
SongEcho: Instance-Adaptive Modulation for Controllable Cover Song Generation
Cover song generation, characterized by the simultaneous synthesis of new vocals and coherent accompaniment conditioned on the original vocal melody and textual prompts, remains an open challenge distinct from traditional Singing Voice Synthesis (SVS) and Singing Voice Conversion (SVC). Existing approaches are limited by single-track focus or fail to achieve precise temporal melody control, lyric synchronization, and natural instrumental coherence. The principal bottleneck lies in robust condition injection—the mechanism by which melody control is integrated into generative backbones.
IA-EiLM: Instance-Adaptive Element-wise Linear Modulation
SongEcho introduces IA-EiLM, comprising Element-wise Linear Modulation (EiLM) and Instance-Adaptive Condition Refinement (IACR). Traditional condition injection schemes, such as cross-attention or element-wise addition, are either computationally redundant or inflexible in modulation. FiLM, though proven in vision and speech, is extended by EiLM to permit element-wise, temporally aligned modulation:
him=EiLM(hi∣c)=γi⊙hi+βi,
where
(γi,βi)=fi(c)
and fi is a linear projector matching the hidden state dimensionality.
Unlike FiLM, which only modulates features globally, EiLM can precisely align the melody condition temporally with hidden states, obviating the need for sequence partitioning or indirect alignment mechanisms.
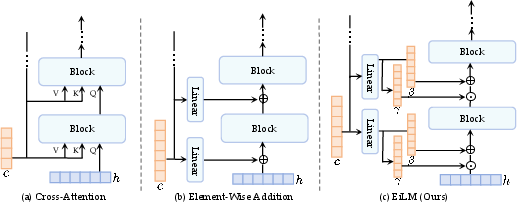
Figure 1: EiLM enables direct temporal alignment and flexible modulation, contrasting with the rigidity and complexity of prior addition and cross-attention-based mechanisms.
IACR further refines the conditional representation by facilitating active interaction between melody conditions and hidden states, using a gating mechanism inspired by WaveNet. This enables dynamic adaptation, resolving the underconstrained optimization problem inherent in static conditional injection. The refined conditional vector
ci=tanh(hi′)⊙tanh(mi′),
where both hi′ and mi′ are projected through linear layers, supports instance-tailored modulation parameters (γh,m,βh,m)=F(m,h).
SongEcho Architecture and Integration
SongEcho extends the ACE-Step full-song generation model, employing a Diffusion Transformer (DiT) backbone. IA-EiLM is injected before each FFN layer in transformer blocks—leveraging local feature transformation for melody retention, unlike global self-attention which dilutes melodic signals. The melody encoder, built from 1D convolutions, aligns extracted pitch sequences with hidden states. Except for the IA-EiLM and melody encoder, all model parameters are frozen, maximizing parameter efficiency.
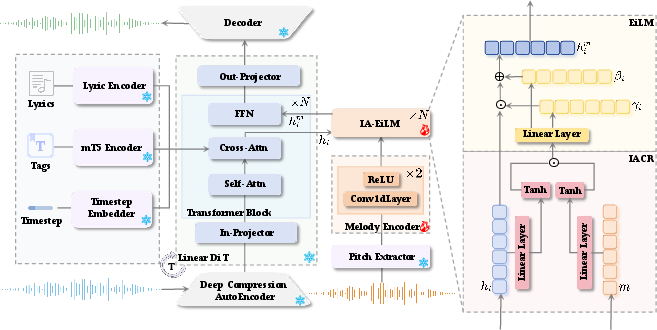
Figure 2: SongEcho pipeline showing DiT backbone, pitch extraction, melody encoding, and instance-adaptive conditioning through IA-EiLM modules integrated per transformer block.
Suno70k Dataset and Evaluation Protocol
Addressing data scarcity, Suno70k is constructed from a filtered subset of the Suno.ai Music Generation dataset. Rigorous curation involves metadata deduplication, quality assessment with SongEval, enhanced tagging via Qwen2-audio, and lyrics alignment consistent with ACE-Step requirements, yielding ~3,000 hours of high-quality AI-generated songs.
Melody control is objectively evaluated with Raw Pitch Accuracy (RPA), Raw Chroma Accuracy (RCA), Overall Accuracy (OA), and supported by audio similarity (FDopenl3, KLpasst), CLAP score for text-audio alignment, and Phoneme Error Rate (PER) for vocal content fidelity.
Empirical Results and Strong Numerical Claims
SongEcho demonstrates markedly superior performance against ACE-Step+SA ControlNet and ACE-Step+MuseControlLite baselines:
- RPA: 0.7080 (+14% absolute over nearest baseline).
- RCA: 0.7339 (+9% absolute).
- FDopenl3: 42.06 (reducing baseline values by over 40%).
- Trainable parameters: 49.1M (3.07% of ACE-Step+SA ControlNet).
Subjective evaluation via Mean Opinion Score confirms higher melody fidelity, text adherence, audio quality, and overall preference from both musician and non-musician listeners. Ablation studies validate the necessity of IACR and element-wise modulation, demonstrating sensitivity of melody metrics to module placement and training data scale.
Qualitative Analysis, Limitations, and Future Directions
SongEcho achieves high-quality cover generation with precise melody control, maintaining vocal-accompaniment coherence and minimizing lyric-melody misalignment. The model is robust to tag-melody conflicts and supports flexible inpainting/outpainting with simple masking. Global tempo and key can be manipulated via post-processing of the F0 sequence.
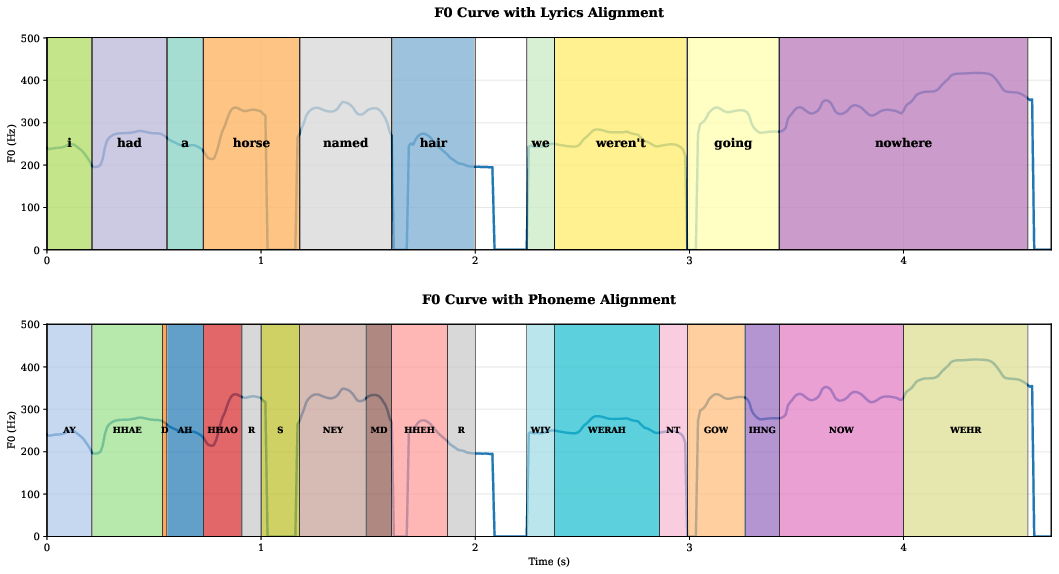
Figure 3: Visualization of F0 contour, word-level, and phoneme-level timestamps demonstrates accurate implicit alignment between melody and transcribed lyrics.

Figure 4: Example transcript output using Whisper, highlighting segmentation errors present in external datasets versus the clean alignment in Suno70k.
The scope for expressive, micro-level cover reinterpretation is currently constrained by the foundational model (ACE-Step), especially in vocal timbre manipulation. Incorporation of speaker encoders or paired original-cover datasets will permit finer-grained adaptation—potentially enabling emotional and technical nuances typical of professional human covers. Theoretical advances in conditional normalization, as applied here, offer broad utility for controllable generation tasks in music, speech, and beyond.
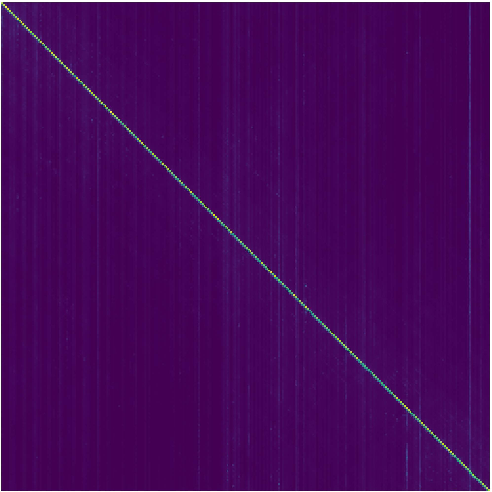
Figure 5: Attention map visualization of MuseControlLite under full-audio conditioning exposes its reliance on copying, incapable of flexible melody control as required by SongEcho.
Conclusion
SongEcho establishes a parameter-efficient, instance-adaptive modulation framework for cover song generation, advancing both conditional injection and representation with IA-EiLM. The method yields consistent improvements across melody control, audio quality, and text-music coherence, validated by objective and subjective metrics. The architecture and dataset curation mitigate longstanding copyright and data access issues for full-song AI generation. Broad implications include extensibility of instance-adaptive normalization to other conditional generative domains and practical approaches for high-fidelity musical reinterpretation in automated systems.