- The paper introduces Predictive Spatial Field Modeling (PSFM) which learns a unified, view-invariant latent from 2D inputs to achieve robust 3D spatial reasoning.
- It uses a modular encoder-decoder architecture with asymmetric view aggregation, transformer-based latent extraction, and ray-based querying to synthesize features for arbitrary viewpoints.
- Empirical results demonstrate that Spa3R outperforms previous methods on benchmarks by significantly improving spatial reasoning accuracy and generalization.
Spa3R: Predictive Spatial Field Modeling for 3D Visual Reasoning
Motivation and Problem Setting
Despite considerable progress in general VLMs for 2D vision-language reasoning, capturing 3D spatial intelligence remains highly challenging due to the inherent limitations of 2D pre-training pipelines and the ambiguities induced by sparse view supervision. Previous approaches augment VLMs with explicit 3D modalities or partial multi-view geometric priors, but these solutions either undermine scalability due to hardware-specific requirements or confront a fundamentally ill-posed task—burdening the LLM with reconstructing holistic 3D information from limited, view-dependent cues. The critical bottleneck, therefore, is the lack of a direct, scalable mechanism for VLMs to internalize a unified, coherent spatial representation from 2D observations alone.
Predictive Spatial Field Modeling (PSFM) Paradigm
To bridge this gap, Spa3R presents a self-supervised framework based on Predictive Spatial Field Modeling (PSFM). The PSFM paradigm conceptualizes 3D scene understanding as the learning of a continuous spatial feature field: synthesizing the full set of view-centric features for arbitrary, unseen viewpoints, conditioned solely on a compact, learned spatial latent. By enforcing this predictive information bottleneck, the encoder is compelled to abstract and internalize the manifold structure of the underlying 3D geometry and semantics, surpassing the limitations of partial, view-dependent cues.
This decouples spatial representation learning from downstream linguistic reasoning, enabling the learned spatial manifold to serve as a reusable, plug-and-play module for diverse VLMs. Theoretical analysis confirms that this setting enforces global scene understanding and robust disentanglement of intrinsic versus extrinsic (view-conditioned) properties.
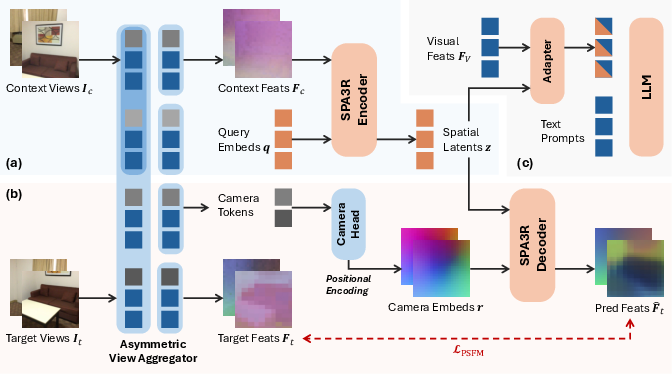
Figure 1: The Spa3R framework and Spa3-VLM: (a) Spa3R’s Encoder maps multi-view, unposed images to a unified, view-invariant latent; (b) the Decoder predicts feature fields for any target view; (c) a lightweight Adapter grounds VLM reasoning in these spatial latents.
Architecture: Spa3R Framework
Spa3R instantiates PSFM with a modular encoder-decoder design:
- Asymmetric View Aggregator: Adapts a pre-trained geometric vision foundation model (VGGT) via asymmetric attention masking to ensure context features are spatially aligned and computed without leakage from targets, supporting the construction of canonical, aligned fields.
- Spa3R Encoder: Utilizes Transformer layers with learnable queries to condense the aggregated context features into a compact spatial latent z.
- Spa3R Decoder: Synthesizes features for arbitrary target viewpoints by combining ray-based querying (using camera intrinsics to compute ray embeddings) and relative 3D positional encoding (via PRoPE), enabling robust spatial feature synthesis under a wide variety of view conditions.
- Loss Design: Multi-head prediction objectives jointly reconstruct geometric (VGGT) and semantic (DINOv3) features, using a hybrid of L1 and cosine similarity losses. This supervision scheme encourages learning both fine-grained geometric relationships and high-level abstraction.
Spa3-VLM: Integrating Spatial Context into VLMs
For downstream visual-language reasoning, the Spa3R Encoder is integrated into an existing VLM backbone (Qwen2.5-VL) using a Residual Cross-Attention Adapter. This adapter aligns the VLM’s native visual feature tokens with the Spa3R spatial latent, allowing the base model to actively query and incorporate spatial context without catastrophic forgetting or modality collapse—a frequent failure mode in naive concatenative approaches. Only the adapter and LLM are fine-tuned, while visual feature extractors and the spatial encoder remain frozen, preserving generalizability across domains.
Empirical Results
VSI-Bench: On the challenging video-based VSI-Bench spatial reasoning benchmark, Spa3-VLM achieves an average accuracy of 58.6%, outperforming all prior open-source and proprietary spatial VLMs, with substantial gains observed particularly in tasks requiring holistic spatial integration (Route Planning, Appearance Order, Relative Distance/Direction). These figures demonstrate that the unified, view-invariant field learned by PSFM confers quantifiable benefits for spatial understanding that partial geometric priors cannot match.
- Ablation Studies:
- The unified Spa3R latent leads to +3.5% improvement compared to direct view-conditioned features.
- Joint geometric-semantic supervision is crucial for further performance gain.
- Cross-attention integration mechanism contributes +7.5% over simple feature appending.
- Mask ratio tuning reveals an optimal trade-off at 50%, confirming that both predictive challenge and context sufficiency are vital.
- PRoPE-based camera encoding outperforms traditional Plücker coordinates by +1.0%, underscoring the importance of modeling relative transformations.
- Generalization: On additional benchmarks (CV-Bench, SPAR-Bench, ViewSpatial-Bench), Spa3-VLM attains the highest or near-highest accuracy, highlighting robust transfer and the inductive strength of the spatial latent representation.
Qualitative Analysis
Qualitative visualization of predicted features reveals that Spa3R reconstructs spatially continuous and coherent field layouts, even for occluded or previously unseen regions. This extrapolation capability evidences internalization of true 3D scene structure, not mere memorization or overfitting to input views.
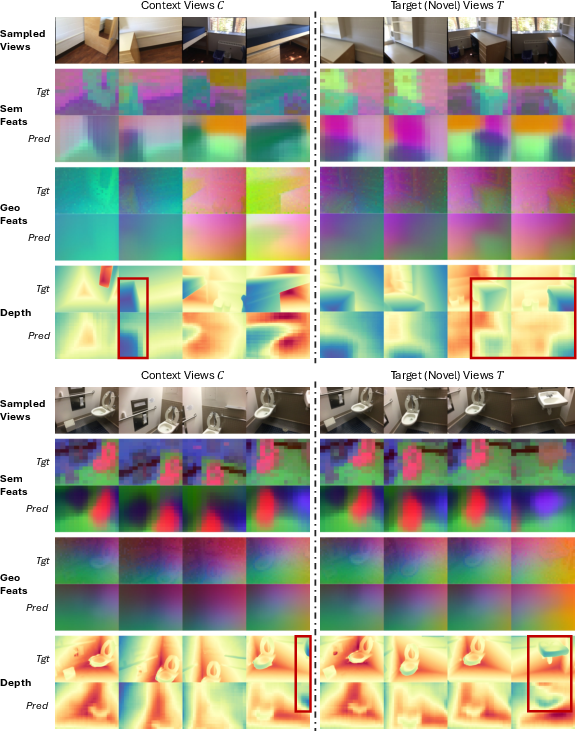
Figure 2: Qualitative visualization of learned feature fields. Spa3R’s predictions are spatially coherent and robustly extrapolate to occluded or unobserved regions—highlighted by red boxes—demonstrating non-trivial holistic 3D understanding.
Implications and Future Directions
The PSFM paradigm advances a scalable and general solution to 3D spatial reasoning by learning a robust spatial manifold from 2D observations without reliance on explicit 3D modalities or expensive annotation. This leads to VLMs with enhanced spatial intelligence, capable of zero-shot transfer to new tasks and environments. The modular integration mechanism enables broad applicability to future VLM architectures and supports extensibility to other cognitive modalities, e.g., temporal reasoning from dynamic multi-view sequences.
Further research may investigate:
- Joint optimization of the visual backbone and spatial encoder, seeking tighter task coupling.
- Extension to open-world and embodied settings with active agent control.
- Investigating the role of more advanced relative encoding mechanisms and richer multi-modal joint supervision.
Conclusion
Spa3R provides an effective, self-supervised approach to 3D visual reasoning by proposing Predictive Spatial Field Modeling, learning a unified, view-invariant latent representation solely from multi-view 2D images. The downstream integration via cross-attention enables state-of-the-art 3D spatial reasoning for vision-LLMs. This architecture delineates a clear path toward scalable spatial intelligence, reducing dependency on explicit 3D inputs and setting new benchmarks for practical and theoretical progress in multi-view visual cognition (2602.21186).