Aletheia tackles FirstProof autonomously
Abstract: We report the performance of Aletheia (Feng et al., 2026b), a mathematics research agent powered by Gemini 3 Deep Think, on the inaugural FirstProof challenge. Within the allowed timeframe of the challenge, Aletheia autonomously solved 6 problems (2, 5, 7, 8, 9, 10) out of 10 according to majority expert assessments; we note that experts were not unanimous on Problem 8 (only). For full transparency, we explain our interpretation of FirstProof and disclose details about our experiments as well as our evaluation. Raw prompts and outputs are available at https://github.com/google-deepmind/superhuman/tree/main/aletheia.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper describes how an AI research agent named Aletheia tried to solve a set of real, high-level math problems called FirstProof. The goal was to see if an AI could work on tough math questions on its own—without getting ideas or hints from people—and produce solutions that are good enough for academic publication.
Key Objectives
The authors wanted to answer a few simple questions:
- Can an AI solve genuine research-level math problems by itself?
- If the AI provides a solution, does it meet the standards used by mathematicians (clear, precise, with proper references)?
- How reliable is the AI at knowing when it has a valid solution versus when it should admit “no solution”?
Methods and Approach
Think of this like an exam where the AI gets 10 hard math questions and has to submit its answers before a deadline, without any help from a teacher.
Here’s how they set it up:
Autonomous Setup
- The team gave Aletheia the 10 FirstProof problems exactly as written, with no changes and no hints.
- Aletheia used a powerful reasoning model (Gemini 3 Deep Think) to generate solutions completely on its own—no human feedback or guidance while solving.
Verification and Formatting
- After Aletheia produced its answers, a separate automatic “checker” prompt reviewed each solution for rigor (like a strict editor), looking for logical gaps and making sure the write-up was in LaTeX (the standard format for math papers).
- This checker could mark a solution as [CORRECT], [FIXABLE], or [WRONG]. If [FIXABLE], the AI would revise it automatically into a more complete and rigorous version.
Expert Evaluation (after the deadline)
- Human mathematicians then read the final AI-produced solutions to judge whether they would be publishable after minor edits (like what happens in normal peer review).
- Importantly, humans did not help the AI during solving—evaluation happened only after the AI’s work was done.
Two Versions, Best-of-2
- The team ran two versions of the agent (built on different model snapshots).
- They picked the better answer (“best-of-2”) for each problem where both produced a candidate solution.
Measuring Effort
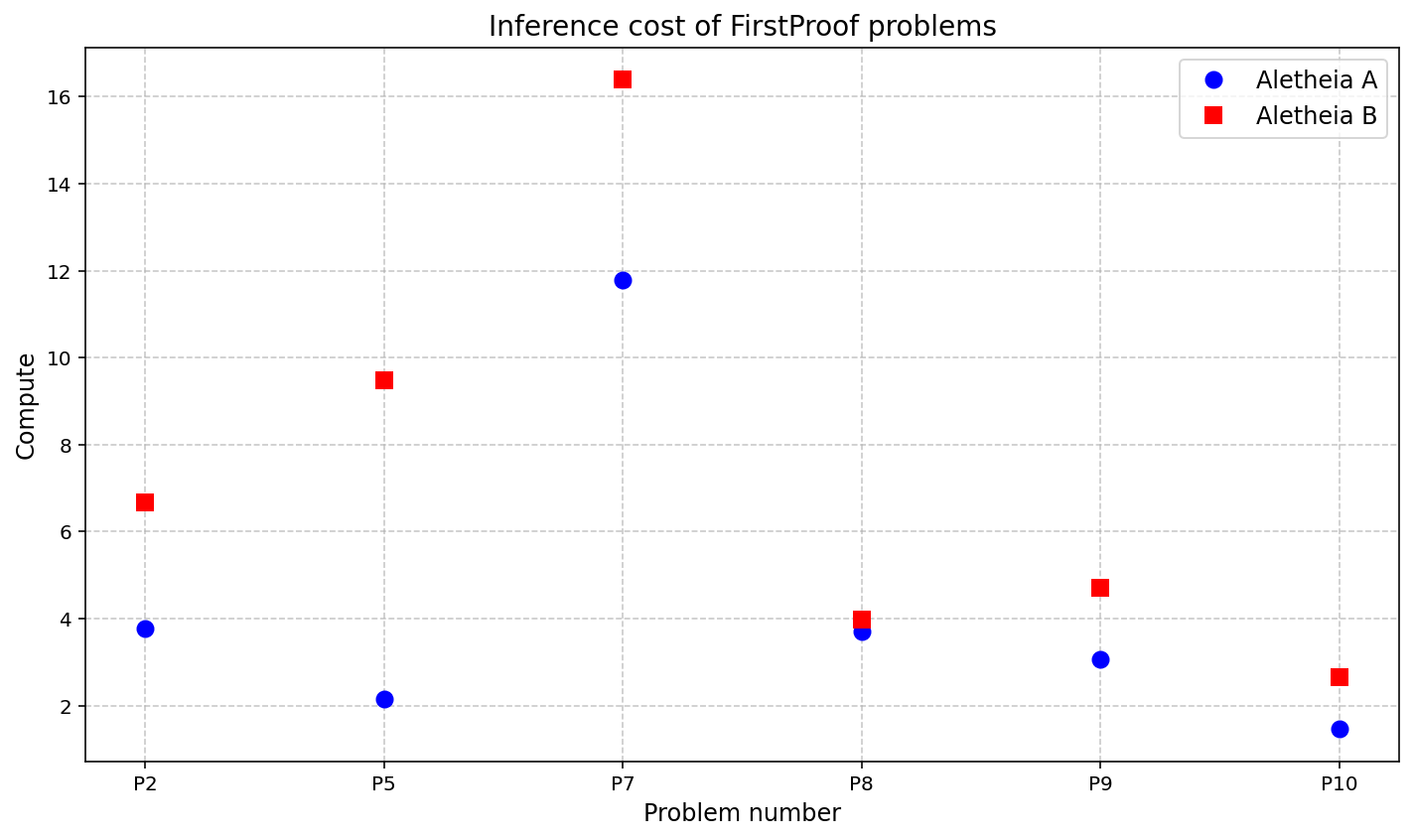
- They tracked how much computing effort the AI spent per problem as a rough indicator of difficulty (from the AI’s point of view). Some problems required far more effort than the team had previously seen.
Main Findings and Why They Matter
Aletheia’s performance:
- It produced candidate solutions for 6 out of the 10 problems and returned “no solution” for the other 4 (by design, to avoid guessing).
- Expert evaluators judged that Aletheia solved 6 problems correctly (Problems 2, 5, 7, 8, 9, 10), with one of them (Problem 8) having mixed opinions among experts about the level of detail. Most experts thought it was correct but needed more clarity.
- For the 4 problems with no output (Problems 1, 3, 4, 6), Aletheia either explicitly said it couldn’t find a solution or ran out of time.
- The strict “no human help while solving” rule was followed: humans only evaluated the final answers.
- The agent’s “self-filtering” (deciding to say “no solution” rather than produce a weak answer) improved reliability, which many researchers value.
Why this is important:
- It shows an AI can tackle multiple genuine research-level math problems under time pressure and produce work that experts find publishable with minor revisions.
- It highlights the need for clear standards about what “autonomous” and “correct” mean in AI research on math.
- It suggests that using multiple runs or model versions (best-of-2) can improve overall accuracy.
Implications and Potential Impact
- Better tools for mathematicians: AI agents like Aletheia could help explore ideas, draft proofs, and check details—saving time and opening new directions in research.
- Reliability over raw power: The agent’s choice to output “no solution” when unsure could make AI support more trustworthy, especially for experts who don’t have time to check many low-quality attempts.
- Clearer benchmarks: Challenges like FirstProof push the community to refine rules for judging AI math solutions (for example, what counts as “publishable after minor revisions”).
- Future progress: With stronger models and better “checker” prompts, AI could solve tougher problems, write cleaner proofs, and cite sources with full precision, bringing us closer to AI that can contribute to mathematics independently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide concrete follow-up work.
- Definition of “autonomy” remains underspecified: the paper allows human selection of a “preferred solution” from multiple autonomous attempts, but does not quantify how much this human curation boosts headline performance (6/10). Action: evaluate single-shot and automated selection baselines (e.g., use the verifier’s score only), report success rates with/without human selection.
- Evaluation rubric is subjective and nonstandardized: “publishable after minor revisions” varies across experts and domains (e.g., P8). Action: develop and pre-register a rubric with operational criteria (e.g., completeness, citation granularity, reliance on external lemmas, gap count/severity), and require blinded, independent reviews with inter-rater agreement statistics.
- Non-unanimous outcome on P8 not resolved: the paper does not specify what proof details were missing or how often similar gaps occur across domains like symplectic geometry. Action: categorize missing-steps by type and domain; create domain-specific checklists for geometric smoothing/interpolation steps; test whether the agent can autonomously fill those gaps on re-prompting.
- Citation rigor falls short of challenge requirements: many solutions lack precise statement numbers or rely on imprecise attributions. Action: add a citation-grounding module that (i) retrieves precise theorems/statement numbers, (ii) cross-checks existence/versions (journal/arXiv), and (iii) blocks “correct” verdicts unless references meet format constraints.
- Verifier reliability is unquantified: the extraction/verification prompt labeled some outputs [CORRECT] where experts later flagged issues (and vice versa), yet no precision/recall estimate is provided for the verifier’s judgments. Action: assemble a labeled set from expert verdicts and measure the verifier’s true/false positive/negative rates; ablate prompt variants and thresholds.
- Failure analysis for P1, P3, P4, P6 is absent: “No output” conflates timeouts, search failures, and self-filtering thresholds; no root-cause breakdown is provided. Action: log and categorize failure modes (e.g., stalled search, verifier rejection loops, misinterpreted definitions, missing canonical strategy), and quantify their frequencies.
- Problem misinterpretation (P5) is unresolved: the agent adopted an “archaic” meaning of “slice filtration.” Action: add a disambiguation step that (i) extracts key terms, (ii) retrieves and ranks candidate definitions from recent literature, and (iii) asks the agent to justify chosen definitions against context; report the rate of semantic misreads.
- Reproducibility is limited: core scaffolding and base models are not fully specified (e.g., seeds, temperatures, call limits, stopping criteria, budgets per subagent), hindering exact replication. Action: release a full runbook with hyperparameters, random seeds, per-problem budgets, and agent state machine; provide deterministic replay logs.
- Compute/efficiency reporting is relative and incomplete: the paper reports inference costs as multiples of a prior task, not absolute tokens, calls, wall-time, or energy, nor per-subagent breakdowns. Action: publish absolute compute metrics (tokens, API calls, wall-time, energy) and profiles by subagent stage to enable cost-quality trade-off analysis.
- Stability across runs is unknown: a best-of-2 protocol hides variance; no distribution over seeds/attempts is reported. Action: run ≥20 independent seeds per problem, report success probability curves, and plot performance vs. number of attempts to quantify sample complexity.
- Effect of increased inference budgets (“Aletheiaf”) is not measured: early-stopped for cost without systematic study; no performance-vs-compute scaling law is provided. Action: sweep budgets systematically, chart success vs. tokens/steps, and identify diminishing returns and problem-dependent scaling regimes.
- Interaction policy under “autonomy” remains an open design choice: the paper disallows any expert clarification, but the challenge FAQ suggests this might be acceptable if it adds no mathematical content. Action: compare “strict no-interaction” vs. “reviewer clarifications allowed” protocols, measuring net correctness and reviewer effort.
- Domain performance heterogeneity is unstudied: the agent’s strengths/weaknesses across areas (e.g., representation theory vs. symplectic geometry vs. topology vs. numerical linear algebra) are not analyzed. Action: tag problems by domain and technique, and report domain-specific success and gap types.
- Generalization beyond a 10-problem snapshot is unclear: no tests on independent suites (e.g., RealMath, IMProofBench) or longitudinal evaluation are provided. Action: run on multiple research-level benchmarks, report cross-benchmark performance with the same protocol and verifier.
- Formal verification is not integrated: none of the proofs are checked in a proof assistant or with lightweight mechanized verifiers, limiting object-level certainty. Action: pilot pipelines that translate agent proofs into Lean/Isabelle/Coq sketches with automated gap-localization, starting with algebraic and combinatorial cases.
- No automated detection of “unstated finiteness assumptions” and similar subtle pitfalls: e.g., the P7 flawed attempt relied on unjustified multiplicativity of Euler characteristic. Action: add a library of “red-flag” lemmas (conditions required for common properties) and an automated assumption-checker that annotates each invocation with required hypotheses.
- Data contamination and provenance safeguards are informal: emailing solutions before the deadline helps, but there’s no cryptographic timestamping, data-access logging, or model training-data audit. Action: adopt signed, time-stamped hashes of outputs, immutable execution logs, and attestations of training cutoffs and fine-tune datasets.
- Human evaluator pool and process may introduce bias: evaluators include internal or affiliated experts, reviews are not blinded, and sample sizes vary (2–7). Action: institute double-blind reviewing, predefine the number and expertise profiles of reviewers per problem, and report inter-rater agreement (e.g., Cohen’s κ).
- Self-filtering thresholds are not calibrated: “No solution found” may reduce false positives but could hide solvable cases; trade-offs are unquantified. Action: sweep self-filter thresholds, measure false-positive/false-negative rates against expert labels, and tune for researcher-preferred operating points.
- Automated literature retrieval is not evaluated: the pipeline does not report how effectively it finds the most relevant, recent sources or handles conflicting conventions. Action: benchmark retrieval quality (coverage, recency, exactness of citations) and add cross-referencing checks for definitional consistency.
- Selection bias from “preferred solution” is not audited: two agents produced different candidates, and the chosen one influenced reported success. Action: precommit to an automated selection rule (e.g., verifier score, length penalties) or report aggregate metrics over all candidate solutions per problem.
- Ambiguity handling for problem statements is ad hoc: the paper notes ambiguity on P5 but provides no general mechanism for detecting or resolving ambiguous problem phrasing. Action: add an ambiguity-detection pass that flags terms likely to have multiple definitions and prompts the agent to state and justify chosen conventions.
- Lack of granular error taxonomy: beyond labels like “Critically Flawed” and “Inadequate,” there’s no structured categorization of gaps (e.g., missing hypotheses, unjustified limit interchange, non-constructive step). Action: build and use a standardized taxonomy for proof errors to direct targeted verifier checks and agent training.
- Limited transparency on base model differences: two different Gemini bases are used (January and February 2026), but the paper does not isolate which architectural or training changes drove observed gains. Action: perform controlled A/B tests with fixed scaffolding and report per-problem deltas attributable to base model changes.
- Missing exploration of partial outputs: the pipeline accepts “No output” or full solutions, but it’s unknown whether partial lemmas were produced that could be helpful to humans. Action: enable partial-proof harvesting with confidence tagging and evaluate utility in human-in-the-loop settings.
Practical Applications
Immediate Applications
The following use cases can be deployed now, leveraging the paper’s agent design (generator–verifier scaffolding), reliability-first behavior (self-filtering “no solution found”), the verification/extraction prompt with Critique–Verdict–Resolution, LaTeX-native output, and transparent Human–AI Interaction (HAI) logging.
- Academic research (mathematics and theoretical CS)
- Use case: Pre-review and gap-finding for proofs, seminar notes, and technical appendices via the Critique–Verdict–Resolution workflow; generate LaTeX-ready, rigor-conforming drafts.
- Sector: Academia; software tools for research documentation.
- Tools/workflows: “AI Peer-Review Assistant” based on the verification/extraction prompt that yields [CORRECT]/[FIXABLE]/[WRONG] and produces corrected LaTeX when fixable; “Best-of-N” agent orchestration to boost reliability; “Inference-cost triage” to prioritize expert time.
- Assumptions/dependencies: Access to a capable model (e.g., Gemini 3 Deep Think), institutional acceptance of AI-assisted drafts, curated math corpora/citations, expert oversight for final publication.
- Journal editorial triage and pre-screening
- Use case: Automated screening of submissions to flag citation precision, format compliance, and likely rigor status before full human review.
- Sector: Academic publishing.
- Tools/workflows: Verification/extraction prompt integrated with editorial systems (e.g., Overleaf/ArXiv pipelines); “Citation Precision Enforcer” to require precise statement numbers and vetted sources.
- Assumptions/dependencies: Editorial buy-in, integration with submission platforms, clear policies for AI-assisted screening.
- Graduate education and research training
- Use case: Teaching proof-writing via structured critique; interactive assignments where students compare their proofs against agent-generated critiques and revisions.
- Sector: Education.
- Tools/workflows: Classroom “Critique–Verdict–Resolution” modules; LaTeX-ready exemplars; best-of-2 agent comparisons to illustrate multiple approaches.
- Assumptions/dependencies: Instructor supervision, access to institutional compute, clear guidelines to prevent overreliance.
- Reliability-first AI deployments in technical writing
- Use case: Safe default “no solution found” behavior to prevent low-quality/hallucinated proofs in high-stakes contexts (grant writing, compliance reports, technical whitepapers).
- Sector: Enterprise documentation and compliance.
- Tools/workflows: Self-filtering agents and explicit confidence gating; audit trails via HAI cards.
- Assumptions/dependencies: Organizational policy endorsing reliability over coverage, logging and audit requirements.
- R&D support for algorithmic papers and numerical methods
- Use case: Structured exploration and verification of lemmas in optimization or numerical linear algebra, including identifying simplifications (e.g., precomputation steps akin to P10).
- Sector: Software/engineering R&D.
- Tools/workflows: Generator–Verifier scaffolding for algorithmic proofs; “Fixable” resolution workflow to produce corrected proofs.
- Assumptions/dependencies: Domain experts to validate final claims, reproducible experimental artifacts.
- Internal benchmarking and capability tracking
- Use case: Replicate FirstProof-like challenges to track progress; use inference cost as a proxy for problem difficulty and resource budgeting.
- Sector: AI labs, research management.
- Tools/workflows: Challenge repositories with raw prompts/outputs; compute dashboards showing per-problem inference multipliers; best-of-2 orchestration.
- Assumptions/dependencies: Stable benchmarks, consistent model versions, careful contamination controls.
- Transparency and audit compliance using HAI cards
- Use case: Maintain full interaction logs for autonomy claims, contamination prevention, and reproducibility audits.
- Sector: Policy/governance for research organizations.
- Tools/workflows: HAI Card Generator with raw prompts/outputs; timestamped disclosures; pre-deadline escrow submissions.
- Assumptions/dependencies: Organizational process alignment; privacy and IP handling.
- LaTeX-native technical authoring
- Use case: Produce turnkey LaTeX proofs and documents conforming to scholarly standards without manual reformatting.
- Sector: Academic authoring software.
- Tools/workflows: “Proof Verifier & Extractor” LaTeX pipeline; Overleaf plugins to run Critique–Verdict–Resolution and auto-fix formatting/citations.
- Assumptions/dependencies: Integration with LaTeX toolchains; dependable bibliography/citation databases.
- Ensemble safety for high-stakes reasoning
- Use case: Best-of-2 (or N) agents to reduce false positives in mathematical or policy analyses where single-agent outputs are risky.
- Sector: Risk analysis, compliance, safety engineering.
- Tools/workflows: Meta-orchestration and result arbitration; disagreement detection and escalation to human review.
- Assumptions/dependencies: Compute budgets; governance stipulating multi-agent checks.
- Open evaluation and community feedback loops
- Use case: Share solutions pre-publication with domain specialists (e.g., via Zulip), collect consensus ratings, and converge on correctness via transparent dialogue.
- Sector: Academic communities.
- Tools/workflows: Public comments channels; consensus tracking; calibrated “publishable after minor revisions” criteria.
- Assumptions/dependencies: Active community participation; clarity on evaluation standards; conflict-of-interest management.
Long-Term Applications
These use cases require further research, scaling, integration, or policy development before broad deployment.
- Autonomous cross-disciplinary research assistants
- Vision: Extend Aletheia-like agents to physics, economics, and biology for conjecture formulation, proof-like arguments, and protocol design.
- Sector: Multidisciplinary R&D.
- Dependencies: Domain grounding, trusted corpora, hybrid symbolic+neural reasoning, robust error guarantees.
- Formal proof integration at scale
- Vision: Pair the verifier prompt with formal methods (Lean, Coq) for machine-checked proofs, closing gaps between “publishable” and “formally verified.”
- Sector: Software correctness, safety-critical systems.
- Dependencies: Formal libraries covering advanced mathematics; scalable proof search; human-in-the-loop tactics.
- Safety-verified robotics and control
- Vision: Use generator–verifier agents to produce safety invariants and proofs for motion planners and controllers.
- Sector: Robotics, autonomous systems.
- Dependencies: Modeling languages that bridge continuous dynamics and formal proofs; regulatory acceptance; real-time verification.
- Finance and energy systems with provable properties
- Vision: Derive guarantees (stability, risk bounds, convergence proofs) for market-making algorithms or grid optimization schemes.
- Sector: Finance, energy.
- Dependencies: High-fidelity models, access to proprietary data, conservative governance around AI-generated proofs.
- Next-generation peer review workflows
- Vision: Journals standardize AI-assisted triage and require HAI cards; introduce machine-verifiable citation checks and autonomy disclosures.
- Sector: Academic publishing policy.
- Dependencies: Community consensus, tooling standards, ethical frameworks for credit and responsibility.
- Education at scale with research-grade tutors
- Vision: Graduate-level AI co-instructors that teach proof strategies, critique student work, and scaffold research projects.
- Sector: Higher education.
- Dependencies: Pedagogical alignment, assessment integrity, access equity, model safety systems to prevent overfitting to training data.
- Government standards for AI-assisted discovery
- Vision: Procurement and funding agencies adopt autonomy definitions, contamination controls, and audit requirements for AI contributions to funded research.
- Sector: Public policy, science governance.
- Dependencies: Legal frameworks, interoperable audit tooling (HAI cards), privacy/IP regimes.
- Reliability-first AI design patterns across industries
- Vision: Self-filtering, best-of-N ensemble arbitration, and inference-cost-aware triage become standard in high-stakes AI applications (healthcare, legal, transportation).
- Sector: Healthcare, legal, transportation safety.
- Dependencies: Domain-specific validation sets, clear escalation protocols, audited logging, liability models.
- Benchmark ecosystems for research-level reasoning
- Vision: Continuous benchmarks (à la FirstProof/RealMath/IMProofBench) to measure agent progress on authentic problems, tied to compute-cost metrics and expert consensus.
- Sector: AI evaluation.
- Dependencies: Sustainable expert participation, standardized scoring, mechanisms to prevent leakage/contamination.
- End-to-end “proof-to-publication” pipelines
- Vision: Agents progress from problem ingestion to verified proof, citation normalization, and submission packaging with minimal human intervention.
- Sector: Research operations.
- Dependencies: Stronger verifiers, dynamic citation resolution, institutional policies on authorship and accountability.
Glossary
- additive character: A group homomorphism from the additive group of a field to the multiplicative circle group, often used with a specified conductor. "Let be a nontrivial additive character of conductor "
- admissible representation: In p-adic representation theory, a smooth representation where the fixed vectors under any compact open subgroup form a finite-dimensional space. "Let be a generic irreducible admissible representation of "
- agentic scaffolding: The orchestration and control architecture that structures how an AI agent plans, verifies, and iterates on tasks. "Aletheia and Aletheia featured improvements to both the agentic scaffolding and the base models."
- automorphism (order 2 automorphism): A structure-preserving bijection of an object to itself whose square is the identity. "if is an order 2 automorphism acting freely on a manifold "
- compact quotient: A quotient space that is compact; in representation theory, integrals over compact quotients are finite and manageable. "restricts the domain of integration strictly to the compact quotient "
- conductor (of a representation): An invariant measuring the minimal level (power of the maximal ideal) at which the representation admits nontrivial invariants. "Because the conductor of is exactly "
- conductor ideal: The ideal encoding the conductor level of a representation, often denoted by a power of the maximal ideal. "Let denote the conductor ideal of "
- equivariant stable homotopy theory: The study of spectra with group actions and their homotopy-theoretic properties, stable under suspension. "In equivariant stable homotopy theory, commutative ring spectra can be parameterized by operads"
- essential newform: The distinguished (minimal level) Whittaker vector in a local representation, normalized to have value 1 at the identity. "Let be the essential newform"
- finite Fourier transform: The discrete Fourier transform over a finite abelian group or module. "the finite Fourier transform of is identically zero on all unimodular vectors "
- Fourier inversion formula: The identity allowing recovery of a function from its Fourier transform. "Applying the Fourier inversion formula over , we obtain:"
- free action: A group action where no non-identity element fixes any point. "acting freely on a manifold "
- Gelfand--Kazhdan restriction: A principle relating representations via restriction, often used with the Kirillov/Whittaker models. "By the Gelfand--Kazhdan restriction theory for the Kirillov model"
- geometric fixed points: An equivariant homotopy-theoretic functor extracting fixed-point data while killing contributions from proper isotropy. "in terms of the geometric fixed points."
- GL_n(F): The general linear group of invertible n×n matrices over a field F. "Let be a generic irreducible admissible representation of "
- indexing systems: Combinatorial data classifying admissible norm/transfer structures for -operads. "its subsequent combinatorial classification by Rubin \cite[Theorem 3.7]{Rubin2020} via indexing systems,"
- Kirillov model: A realization of a generic representation (of a p-adic group) on functions on a vector space, compatible with a Whittaker character. "for the Kirillov model"
- Lagrangian: In symplectic geometry, a submanifold on which the symplectic form vanishes and whose dimension is half that of the ambient space. "polyhedral Lagrangian surface need to be extended to smoothings along the edges."
- maximal ideal: The unique maximal ideal of the ring of integers of a non-archimedean local field. "and maximal ideal "
- mirabolic congruence subgroup: A subgroup of GL_n consisting of matrices with prescribed last row modulo a power of the maximal ideal. "the mirabolic congruence subgroup "
- operad: An operad encoding equivariant E-infinity structures together with specified admissible norm maps. "an incomplete transfer system associated to an operad."
- non-archimedean local field: A locally compact field with a non-archimedean absolute value (e.g., Q_p), admitting a ring of integers and uniformizer. "Let be a non-archimedean local field"
- norm maps: Equivariant multiplicative transfer maps associated to subgroup inclusions in -algebra structures. "specify the sets of admissible norm maps."
- PCG loop: An iterative preconditioned conjugate gradient routine used to solve linear systems efficiently. "removes the dependency from the iterative PCG loop."
- Rankin--Selberg integral: A local zeta integral pairing Whittaker functions used to study L-functions and representations. "the local Rankin--Selberg integral"
- ring of integers: The valuation ring of a non-archimedean local field, consisting of elements of nonnegative valuation. "with ring of integers ."
- spherical vector: A vector in a representation fixed by a maximal compact subgroup, often unique up to scaling in unramified cases. "the normalized spherical vector "
- symplectic geometry: The study of manifolds with a closed, nondegenerate 2-form and related structures. "specialists in symplectic geometry"
- transfer system: A partial order on subgroups specifying allowed transfers/norms in the equivariant operadic setting. "A transfer system on a finite group is a partial order"
- uniformizer: An element of the ring of integers generating its maximal ideal. "We fix a uniformizer "
- unipotent: An element whose eigenvalues are all 1; in matrix groups, typically upper-triangular with ones on the diagonal. "consisting of upper-triangular unipotent elements."
- unramified: Having trivial ramification; for representations, level zero with a nonzero vector fixed by GL_n(𝔬). "Step 2: The unramified case ()."
- Whittaker model: A realization of a generic representation via functions transforming by a nondegenerate character on the unipotent subgroup. "realized in its -Whittaker model ."
Collections
Sign up for free to add this paper to one or more collections.