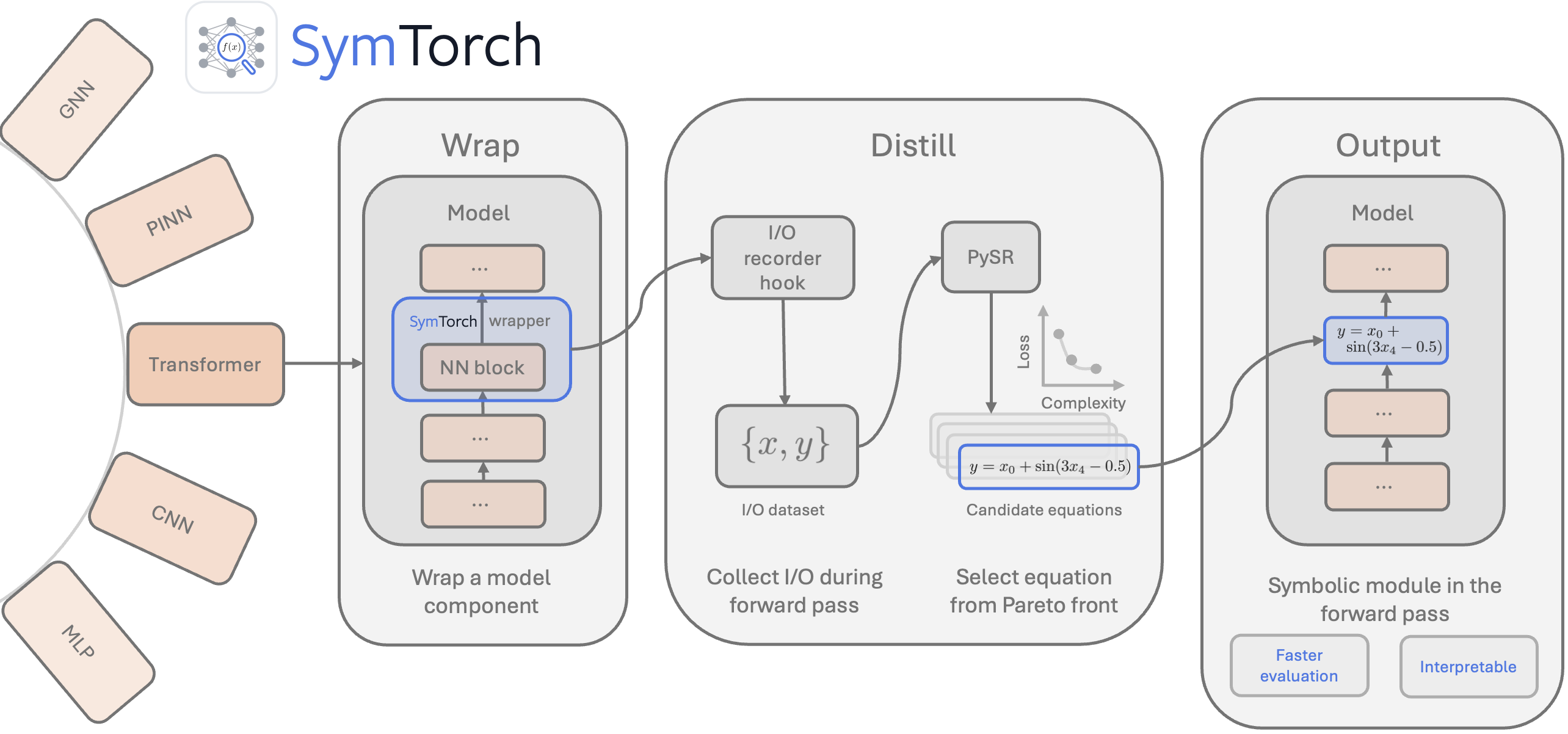
SymTorch: A Framework for Symbolic Distillation of Deep Neural Networks
Abstract: Symbolic distillation replaces neural networks, or components thereof, with interpretable, closed-form mathematical expressions. This approach has shown promise in discovering physical laws and mathematical relationships directly from trained deep learning models, yet adoption remains limited due to the engineering barrier of integrating symbolic regression into deep learning workflows. We introduce SymTorch, a library that automates this distillation by wrapping neural network components, collecting their input-output behavior, and approximating them with human-readable equations via PySR. SymTorch handles the engineering challenges that have hindered adoption: GPU-CPU data transfer, input-output caching, model serialization, and seamless switching between neural and symbolic forward passes. We demonstrate SymTorch across diverse architectures including GNNs, PINNs and transformer models. Finally, we present a proof-of-concept for accelerating LLM inference by replacing MLP layers with symbolic surrogates, achieving an 8.3\% throughput improvement with moderate performance degradation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SymTorch, a tool that helps people understand what deep neural networks are doing by turning parts of these networks into simple, human-readable math formulas. Instead of treating a neural network like a mysterious black box, SymTorch watches how a chosen part behaves and then finds a compact equation that behaves the same way most of the time. Sometimes, those simple equations can even replace the original network parts to make the model faster.
What were the main questions?
The authors focused on three big questions:
- Can we automatically turn pieces of a neural network into clear, short equations that humans can read and reason about?
- Can these equations help scientists discover or confirm real-world rules (like force laws in physics)?
- If we replace some network parts with simple equations, can we make models run faster while keeping good accuracy?
How did they do it?
The team built SymTorch, a library that plugs into PyTorch (a common deep learning framework). Here’s the idea in everyday terms:
- Watching inputs and outputs: Imagine a machine with knobs (inputs) and dials (outputs). SymTorch records what goes in and what comes out of a specific part (like a layer) of the neural network.
- Finding a simple rule: Using a technique called symbolic regression (via a package named PySR), SymTorch searches for a short math formula that maps inputs to outputs. Think of it like trying different combinations of math “building blocks” (such as +, ×, sin, 1/x) to find a neat recipe that imitates the network’s behavior.
- Picking the best formula: It balances accuracy and simplicity—shorter formulas are preferred if they are almost as accurate as longer ones. This is a bit like choosing the simplest recipe that still tastes great.
- Swapping in the formula: If you want, SymTorch can replace the original network part with the found equation during the forward pass (the calculation step when the model makes predictions). This creates a hybrid model that’s part neural, part symbolic (equation-based).
- Local explanations (SLIME): SymTorch also supports a method for explaining what the whole model does around a particular input by fitting a small equation just for that neighborhood—useful for local, “what’s happening here?” explanations.
To handle practical headaches (like moving data between GPU and CPU, saving models, caching data, and cleanly swapping components), SymTorch automates those engineering steps so users can focus on the science.
What did they find, and why is it important?
The authors tested SymTorch in several settings to show it works and is useful:
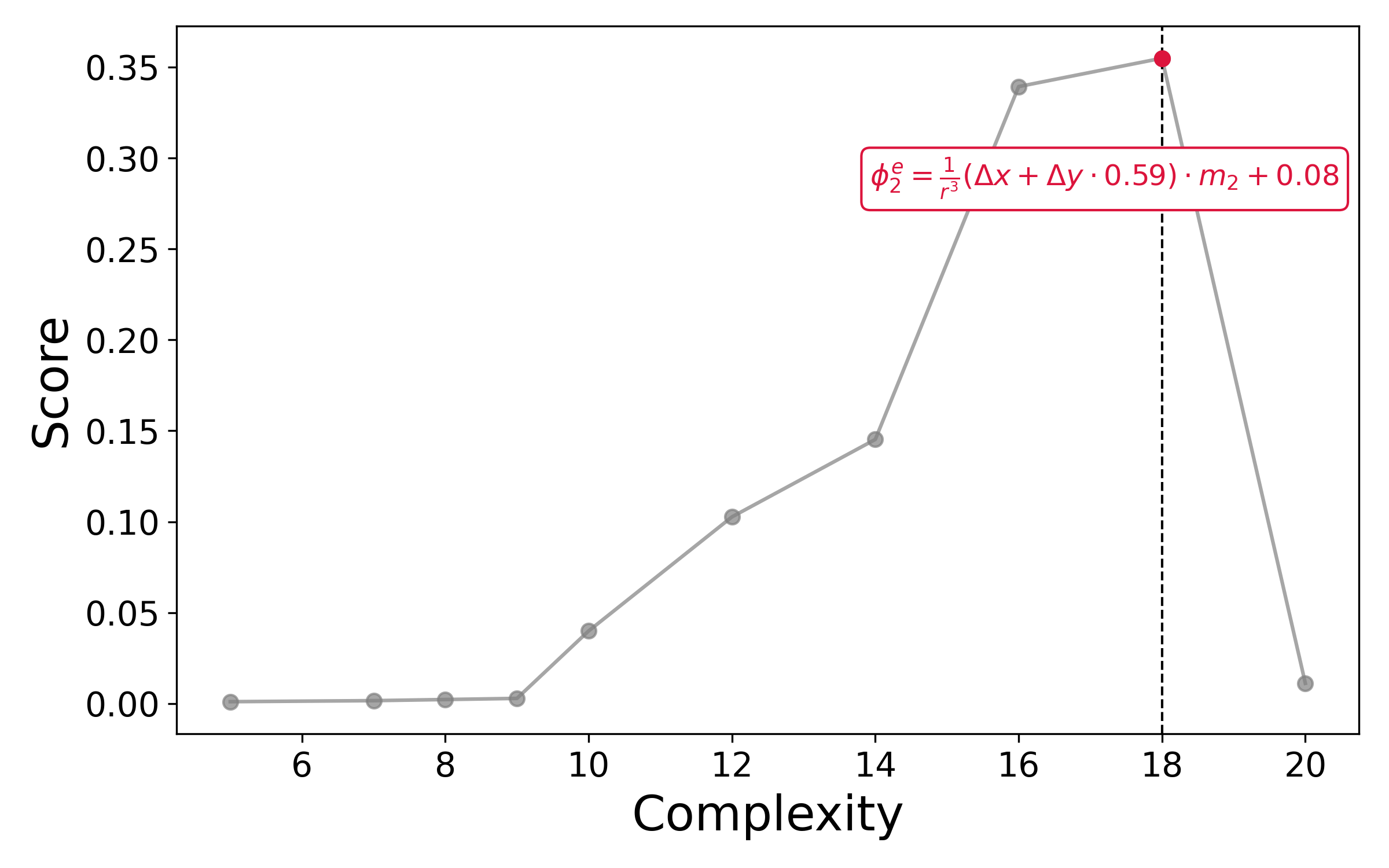
- Physics with Graph Neural Networks (GNNs): They trained a network to predict how particles move and then used SymTorch to extract equations that describe the forces between particles. In many cases, the equations matched known physical laws (for example, relationships that depend on distance between particles), showing that the network had learned meaningful rules that humans can read. This matters because scientists care about compact, understandable laws, not just accurate predictions.
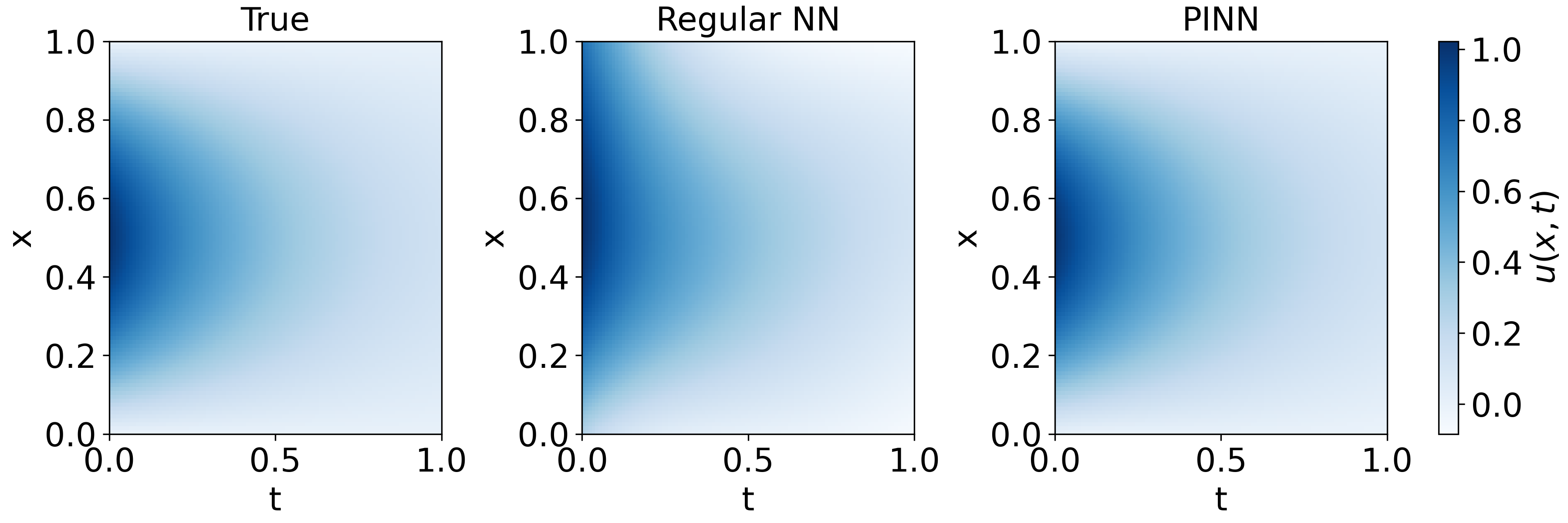
- Physics-Informed Neural Networks (PINNs) for the heat equation: They trained a special network that “knows” some physics rules and then distilled it into a formula that matched the known solution to a 1D heat equation. This shows distillation can recover clean math expressions from physics-guided models even with little data.
- Understanding what a LLM “does” for simple math tasks: For a small LLM, they asked it to add, multiply, count symbols, or convert temperatures. SymTorch found the formulas the model was effectively using. The results revealed that the model often approximated the right rule but included small systematic errors—especially for counting, which is known to be hard for this kind of model. This turns “right/wrong” answers into concrete, inspectable math rules.
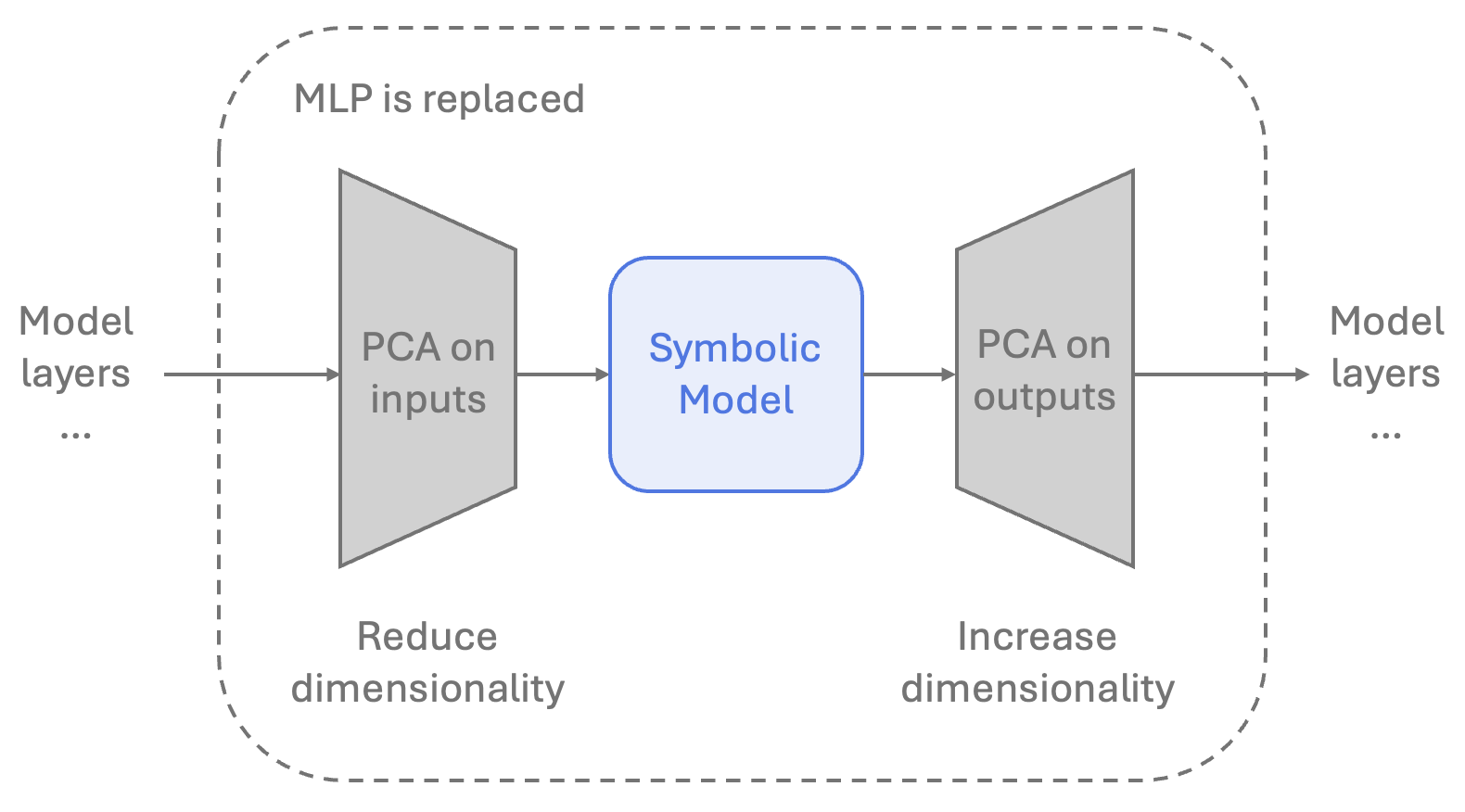
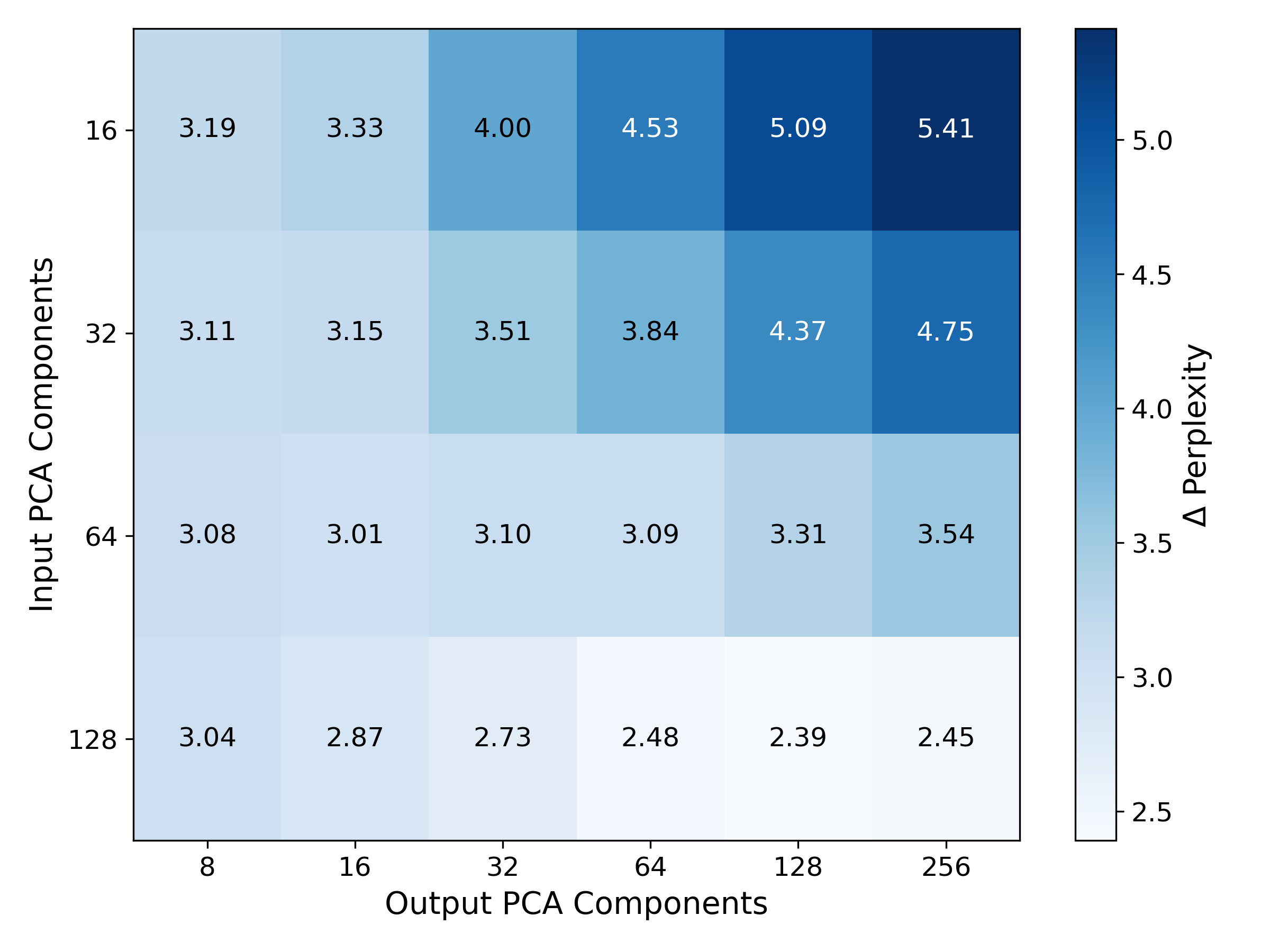
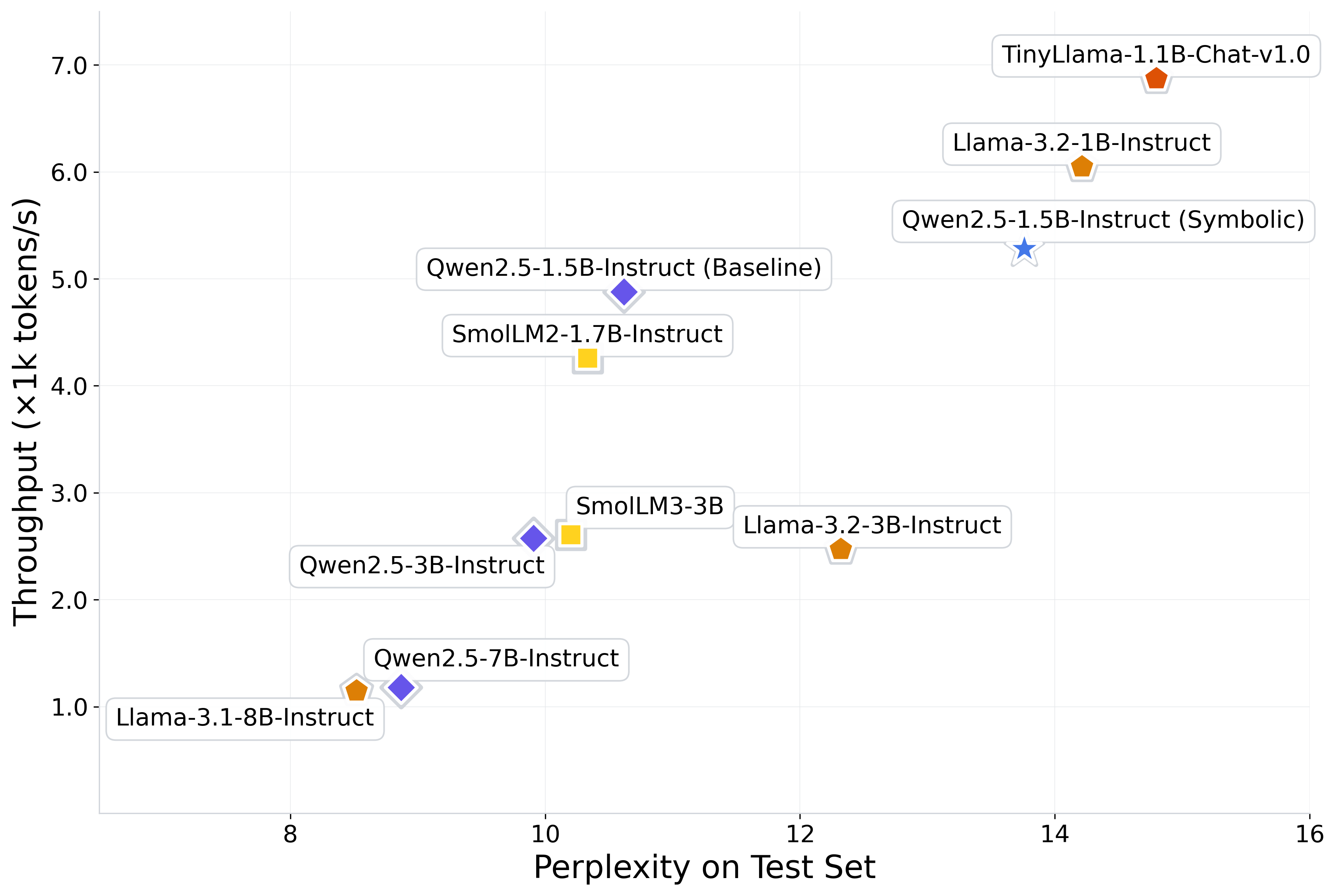
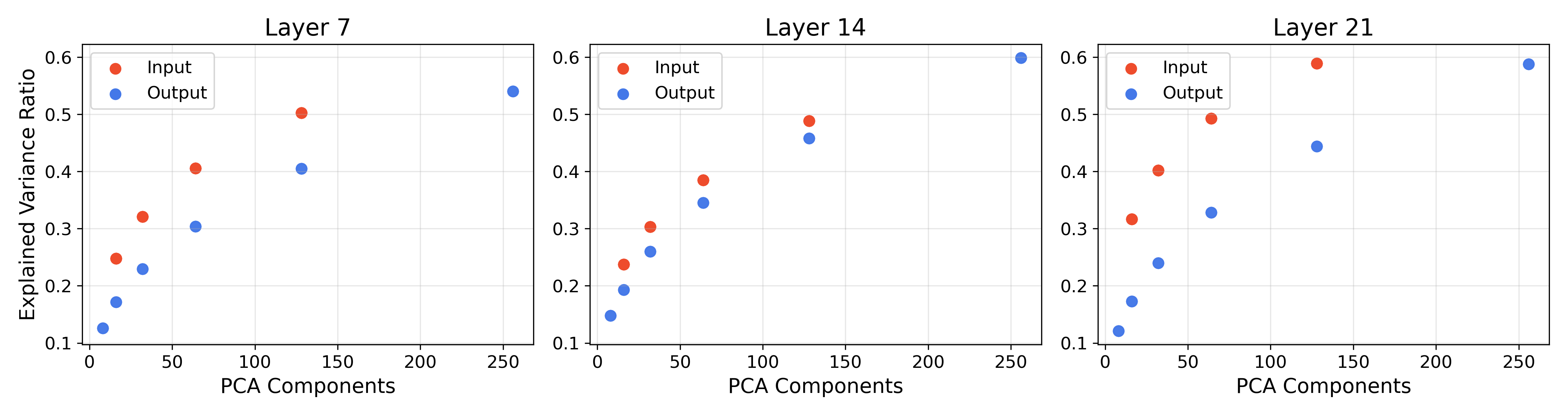
- Speeding up a transformer (LLM) by replacing MLP layers with equations: They tried replacing some of the model’s dense layers (MLPs) with symbolic equations. To make this feasible, they first compressed the inputs/outputs using PCA (a way to keep the most important directions of the data while shrinking its size). After swapping in simple equations, they saw about an 8.3% increase in token throughput (faster generation), with a moderate drop in quality (perplexity rose from 10.62 to about 13.76 on a benchmark). While this isn’t better than the best compression methods yet, it’s a promising first step that shows symbolic surrogates can speed things up.
Overall, the key importance is twofold:
- Interpretability: You can see in plain math what a network part is doing.
- Practicality: Sometimes, those equations can run faster than the original neural layers.
What could this change in the future?
- More understandable AI: If we can replace complicated chunks of networks with clean formulas, scientists and engineers can reason about models like they do about real-world laws (think ). This helps with trust, debugging, and scientific discovery.
- Faster models in the right settings: Simple equations can be quicker to compute. In some applications—especially when speed matters more than absolute best accuracy—hybrid models could be a good trade-off.
- Better tools for discovery: In physics and other sciences, recovering equations from models might help uncover new relationships or confirm suspected ones using data-driven methods.
Limits and next steps
- Symbolic search is hard: Finding a simple formula gets much tougher as the number of inputs grows. It can be slow and compute-heavy.
- Not all parts are simple: Some neural operations may be too complex to compress into short, accurate formulas.
- Measuring “simplicity” isn’t perfect: A short formula isn’t always the easiest for humans to understand, and tuning this trade-off takes care.
- LLM speedups are early-stage: The current approach depends heavily on dimensionality reduction (PCA), which causes some quality loss. Future work could try better compression, choose better layers to replace, and test on larger models.
Bottom line
SymTorch makes it much easier to turn parts of deep neural networks into clear, compact equations. That helps people understand what models have learned and, in some cases, run them faster. The tool works across different kinds of models—from physics simulators to LLMs—and opens the door to more transparent, hybrid AI systems that combine the strengths of neural networks and classical math.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open questions left unresolved by the paper that future researchers could address.
Theory and Guarantees
- Lack of formal guarantees on when symbolic regression (SR) can accurately recover a component’s function from input–output traces; derive conditions (e.g., smoothness, sparsity, Lipschitz constants) under which recovery is provably possible.
- No sample-complexity bounds relating input dimensionality, operator set size, noise level, and target expression complexity to required data and runtime.
- Absence of identifiability analysis: when are multiple expressions observationally equivalent on the collected activations, and how can one disambiguate them?
- No error propagation theory for hybrid models: quantify how per-block SR approximation error compounds when multiple components are replaced.
- No robustness guarantees under input distribution shift; characterize OOD error bounds for distilled expressions vs original networks.
- Unclear conditions under which per-output SR is optimal; investigate multi-target SR that exploits correlations among outputs to reduce complexity and error.
- No principled method for selecting operator sets; develop procedures for operator-set discovery (e.g., Bayesian model selection or structure priors) with guarantees on generalization and interpretability.
- No unit- or symmetry-aware constraints; create SR formulations that enforce invariances (e.g., rotational, permutation, scale) or dimensional consistency to reduce search space and improve faithfulness.
Methodology and Engineering
- Missing analysis of activation-capture bias: forward hooks may alter compute graphs with torch.compile or mixed precision; quantify fidelity and overhead of hook-based capture.
- No study of GPU/CPU transfer overhead and caching strategies at scale; profile throughput–latency trade-offs and memory footprints under large-batch or long-sequence regimes.
- Lack of ablations on SR hyperparameters (population size, mutation rates, operator complexities) and their impact on expression stability and runtime.
- No reporting of randomness sensitivity (seeds) for PySR runs; quantify variance in the recovered expressions across runs and propose stabilization techniques.
- No cross-validation or holdout protocol for SR to prevent overfitting to cached activations; define standardized train/val/test splits for distillation data.
- No joint training of symbolic surrogates with the rest of the model (e.g., differentiable constants or hybrid fine-tuning); explore end-to-end training strategies with gradient flow through symbolic expressions.
- Limited discussion of differentiability: some operators (e.g., inv) may cause unstable gradients; define safe operator sets and gradient clipping strategies for continued training after replacement.
- No mechanism for incremental or online distillation during long training runs; design streaming SR with rolling caches and budgeted compute.
- Missing comparisons with other SR systems (e.g., AI Feynman, Eureqa, SRBench baselines); benchmark competitiveness in accuracy, runtime, and expression simplicity.
- No alternative complexity metrics beyond node count; evaluate human-centered metrics (e.g., description length, algebraic depth, cognitive load) and their effect on selected expressions.
Evaluation and Benchmarks
- No standardized benchmark suite for symbolic distillation across architectures; curate diverse tasks with ground-truth expressions to systematically evaluate fidelity and interpretability.
- Absence of human evaluation for interpretability; design user studies assessing whether distilled equations improve understanding and debugging.
- Limited fidelity metrics: rely primarily on loss/perplexity; add global vs local fidelity, sensitivity/elasticity alignment, and counterfactual consistency metrics.
- Lack of calibration and reliability analyses (e.g., selective prediction, confidence vs error) for hybrid models after replacement.
- Energy efficiency and memory usage not measured; report power consumption and memory bandwidth effects for symbolic vs neural components.
LLM Surrogate Framework
- Surrogates trained only on WikiText-2 and evaluated in-domain; test cross-domain generalization (e.g., books, code, instructions) and on downstream tasks.
- Only one model size (Qwen2.5-1.5B) and three layers replaced; systematically map which layers are most replaceable and how many can be replaced before sharp degradation.
- PCA chosen for dimensionality reduction; compare learned linear projections (e.g., CCA, low-rank adapters) and non-linear reductions (e.g., autoencoders) that preserve SR tractability.
- No analysis of quantization/pruning synergy; test whether symbolic surrogates compound or conflict with 8-bit/4-bit quantization and structured pruning.
- Throughput measured on a single GPU and setup; evaluate across varying batch sizes, sequence lengths, KV-cache settings, hardware (consumer GPUs/TPUs/CPUs), and inference engines (TensorRT, DeepSpeed-Inference).
- Lack of kernel-level optimization for evaluating expressions (e.g., operator fusion, CUDA kernels for symbolic ops); quantify the speed gap between naïve and optimized symbolic execution.
- No assessment of effects on calibration, toxicity, and factuality; measure broader quality impacts beyond perplexity (e.g., MMLU, TruthfulQA, HellaSwag, GSM8K).
- Surrogates only target MLPs; explore attention block components (e.g., value projections or attention score transformations) and their amenability to SR.
GNN Case Study
- Validation only on synthetic pairwise forces in 2D; test robustness to noise, measurement error, and real experimental datasets.
- No evaluation on higher-order (non-pairwise) interactions, non-conservative forces, or time-varying laws; extend to many-body/graphical models with latent interactions.
- Limited exploration of message dimensionality mismatch; quantify failure modes when message size deviates from system dimensionality and propose regularizers to recover forces anyway.
- No systematic study of invariant/equivariant GNNs (e.g., E(n)-equivariant) and their impact on SR success rates and expression simplicity.
- Lack of automated variable transformation discovery; learn or search over transformations (e.g., distances, angles) that simplify recovered laws.
PINN Case Study
- Demonstration only on the 1D heat equation; extend to multi-dimensional PDEs, nonlinear PDEs, unknown coefficients, and PDE discovery (recovering PDE forms, not just solutions).
- No assessment under noisy/partial boundary or initial conditions; test robustness and identifiability in sparse-data regimes.
- Distillation focuses on solutions u(x,t); formulate SR to recover governing PDE operators and parameters directly from the PINN.
- No comparison with baseline SR applied directly to data augmented by physics priors (e.g., synthetic data from PDE solvers); disentangle the specific gain from using PINNs.
SLIME Implementation
- No quantitative evaluation of SLIME fidelity vs LIME/SHAP on standard explanation benchmarks; add metrics (faithfulness, stability, sparsity) and runtime comparisons.
- Sensitivity of locality parameters (J, σ, synthetic point count, M) unexplored; provide guidelines or automatic calibration for high-dimensional inputs.
- No counterfactual testing to verify local surrogate validity boundaries; characterize the radius within which distilled explanations remain accurate.
Reliability, Safety, and Ethics
- Potential for interpretability illusions: distilled expressions that fit but misrepresent causal mechanisms; define diagnostics to detect spurious plausibility.
- Hybrid models may introduce brittle failure modes under rare or adversarial inputs; stress-test safety under adversarial perturbations and rare events.
- No guidance on uncertainty quantification for symbolic outputs (e.g., intervals over constants); integrate posterior uncertainty over expressions and constants.
Usability, Reproducibility, and Packaging
- Reproducibility risks due to dependence on Julia/PySR versions; provide frozen Docker images, seeds, and environment manifests.
- Lack of end-to-end tutorials on large-scale pipelines (activation logging at scale, dataset sharding, distributed SR); document and benchmark distributed workflows.
- No APIs for interactive expression editing and constraint injection (e.g., unit constraints, monotonicity); add user-facing tools for constrained SR.
These gaps provide concrete directions for advancing the theory, engineering, and empirical evaluation of symbolic distillation with SymTorch.
Glossary
- Activation caching: Storing intermediate activations to avoid repeated forward passes and enable efficient analysis or distillation. Example: "GPU-CPU data transfer, activation caching, forward hook management, and hybrid neural-symbolic model serialization."
- Boundary Conditions (BCs): Constraints specified at the boundaries of the domain for differential equations, used to ensure well-posed solutions. Example: "Boundary Conditions (BCs)"
- Closed-form expression: An analytic formula composed of a finite combination of standard functions and operations. Example: "closed-form mathematical expressions."
- Crossover: A genetic algorithm operation that combines parts of two candidate solutions to produce new ones. Example: "mutation, crossover, simplification, and constant optimization."
- Edge model: In a GNN, an MLP that computes edge-wise messages from connected node features. Example: "the edge model (or edge function), φe:V×V→E"
- Expression tree: A tree representation of a mathematical expression where nodes are operators or operands; used to define complexity. Example: "expression tree."
- Forward hook: A mechanism in PyTorch to intercept and record inputs/outputs of modules during forward passes. Example: "forward hooks and pre-forward hooks"
- Genetic algorithm: An evolutionary search method using selection, mutation, and crossover to optimize candidate solutions. Example: "uses genetic algorithms to search the space of symbolic expressions."
- Graph Neural Network (GNN): A neural architecture operating on graph-structured data via message passing between nodes and edges. Example: "Graph Neural Networks (GNNs)"
- Inductive bias: Architectural or training assumptions that guide a model toward certain solutions or behaviors. Example: "appropriate inductive biases"
- Initial Conditions (ICs): Values specified at the start (e.g., t=0) for differential equation problems to determine unique solutions. Example: "Initial Conditions (ICs)"
- Kullback–Leibler (KL) regularization: A regularization term that penalizes divergence from a chosen prior distribution. Example: "Kullback-Leibler (KL) regularization"
- KV caching: Caching key–value tensors in transformer models to accelerate incremental decoding. Example: "with KV caching disabled."
- L1 regularization: A sparsity-inducing penalty proportional to the absolute value of parameters or activations. Example: "we add a L1 regularization term to the messages"
- LIME: Local Interpretable Model-Agnostic Explanations; approximates model behavior near a point with simple local models. Example: "LIME and SHAP are common model-agnostic methods of explaining whole-model behavior."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that inserts trainable low-rank adapters into pretrained models. Example: "Low-Rank Adaptation (LoRA)"
- Mechanistic interpretability: Analyzing the internal mechanisms (circuits, neurons, features) that give rise to model behavior. Example: "mechanistic interpretability"
- Node model: In a GNN, an MLP that updates node features based on the node state and aggregated messages. Example: "the node model (or node function), φv:V×E→D"
- Out-of-distribution: Inputs that differ from the training data distribution, often challenging for generalization. Example: "out-of-distribution settings."
- Pareto front: The set of optimal trade-offs between competing objectives (e.g., accuracy vs. complexity) where no objective can be improved without worsening another. Example: "Pareto front"
- Partial Differential Equation (PDE): An equation involving multivariable functions and their partial derivatives, governing many physical systems. Example: "Partial Differential Equation (PDE)"
- Perplexity: An intrinsic language-model metric equal to the exponentiated average negative log-likelihood; lower is better. Example: "We used perplexity"
- Physics-Informed Neural Network (PINN): A neural network trained with PDE-based constraints in its loss to enforce physical consistency. Example: "Physics-Informed Neural Network (PINN)"
- Principal Component Analysis (PCA): A linear dimensionality reduction technique that projects data onto directions of maximal variance. Example: "Principal Component Analysis (PCA)"
- Pruning: Removing parameters or reducing dimensions to simplify a model and encourage sparsity or efficiency. Example: "Pruning, the dimensionality of the edge messages are incrementally reduced during training"
- Proximity-weighted kernel: A weighting function that emphasizes samples close to a point of interest, often Gaussian. Example: "a proximity-weighted kernel"
- PySR: A symbolic regression library that performs evolutionary search over analytic expressions and tracks a Pareto front. Example: "PySR performs multi-population evolutionary search over analytic expressions"
- Quantization: Reducing numerical precision of model parameters/activations to decrease memory and compute cost. Example: "quantization"
- SHAP: SHapley Additive exPlanations; a method assigning feature-attribution scores based on cooperative game theory. Example: "SHAP"
- SLIME: Supralocal Interpretable Model-Agnostic Explanations; uses symbolic surrogates to capture non-linear local behavior. Example: "Supralocal Interpretable Model-Agnostic Explanations (SLIME)"
- Speculative decoding: An inference technique that drafts tokens with a cheap model and verifies them with a large model to speed up generation. Example: "speculative decoding"
- Symbolic distillation: Replacing neural components with interpretable analytic equations learned from their I/O behavior. Example: "Symbolic distillation replaces neural networks, or components thereof, with interpretable, closed-form mathematical expressions."
- Symbolic regression (SR): Searching over analytic expressions to fit data, balancing accuracy and expression complexity. Example: "Symbolic Regression (SR)"
- SwiGLU: A gated activation function variant used in transformer MLPs combining SiLU and GLU components. Example: "SwiGLU activations"
- Token throughput: The number of tokens processed per unit time during inference. Example: "token throughput"
- Tournament selection: A genetic algorithm selection method where a subset competes and the fittest is chosen (probabilistically) to reproduce. Example: "a tournament selection process is run"
- Variable transforms: Feature engineering mappings applied to inputs before SR to structure the search space (e.g., r from coordinates). Example: "Users may pass variable_transforms to create derived features"
Practical Applications
Immediate Applications
The following applications can be deployed with the current SymTorch library, PySR integration, and workflows demonstrated in the paper’s case studies.
- Plug-and-play component-level interpretability for PyTorch models (Software, Academia)
- Use SymTorch to wrap layers/blocks, cache I/O, and distill them into closed-form expressions for inspection and debugging.
- Tools/workflow: SymTorch + PySR; forward hooks; variable_transforms; Pareto front selection; torch.save/load; torch.compile.
- Assumptions/dependencies: Models built in PyTorch; tractable input dimensionality; adequate sample coverage; operator set tuned for domain; SR compute budget.
- Model auditing and documentation in regulated settings (Healthcare, Finance, Policy)
- Produce human-readable equations for critical components and SLIME-based supralocal explanations to support audits, model cards, and regulatory filings.
- Tools/workflow: SymTorch SLIME flag; proximity-weighted kernels; neighborhood sampling; activation caching for reproducibility.
- Assumptions/dependencies: Approximation accuracy acceptable to stakeholders; governance processes can incorporate surrogate explanations; transparent SR hyperparameters.
- Scientific law discovery from trained models with inductive biases (Academia/Physics)
- Recover empirical interaction laws by distilling GNN edge functions into equations; validate learned physics in simulators or empirical datasets.
- Tools/workflow: GNN training with message dimensions matching system; variable_transforms (e.g., r, Δx/Δy); SR per-output dimension; Pareto equation selection.
- Assumptions/dependencies: Appropriate architectural bias (e.g., GNN message dimension equals system dimension); sufficient data; stable learned representations.
- PINN solution extraction and deployment as analytic surrogates (Engineering, Energy, Academia)
- Distill trained PINNs into closed-form PDE solutions for lightweight calculators, fast simulation, and embedded engineering tools.
- Tools/workflow: PINN training with IC/BC regularization; end-to-end wrapping with SymTorch; export equations for downstream use.
- Assumptions/dependencies: Low-dimensional PDE problems; high-quality PINN training; SR tractability; domain consistency between training and deployment.
- LLM arithmetic and operation analysis for error diagnosis (Software, Education)
- Symbolically approximate operations learned by small LLMs (e.g., addition, multiplication, unit conversion) to identify systematic errors and guide prompt/tool design.
- Tools/workflow: Wrap callable mappings of token-level representations; fit surrogates; compare expected vs. distilled equations; error taxonomy.
- Assumptions/dependencies: Stable behavior on chosen prompts; accessible activations; task-specific operator sets; finite-precision constraints may limit exact counting.
- Targeted LLM inference speedups in latency-critical, single-task deployments (Software, Edge/IoT)
- Replace selected MLP blocks with symbolic surrogates to achieve modest throughput gains (e.g., 8.3%) where small accuracy tradeoffs are acceptable.
- Tools/workflow: PCA compression of inputs/outputs; SymTorch distillation of reduced mappings; A/B testing; LoRA fine-tunes for single-task targeting.
- Assumptions/dependencies: Acceptable perplexity increase; distribution stability (train/test match); careful layer selection; GPU environment and batching consistent with benchmarks.
- Model compression and edge deployment via equation replacement (Robotics, Mobile, Embedded)
- Convert heavy matrix operations into compact equations to reduce memory footprint and improve runtime on constrained devices.
- Tools/workflow: Distill candidate layers; emit equations to C++/Rust; integrate with ONNX/Triton kernels; unit tests against baseline outputs.
- Assumptions/dependencies: Accurate surrogates under device math libraries; manageable numerical stability; operator coverage on target hardware.
- Non-linear local explanations for black-box models using SLIME (Policy, Healthcare)
- Provide interpretable, supralocal symbolic surrogates around points of interest for case reviews, adverse event analyses, and consent explanations.
- Tools/workflow: Neighbor selection; synthetic sampling; proximity weighting; report generation with equation and fit diagnostics.
- Assumptions/dependencies: Proper choice of neighborhood size J and weights M; faithful local behavior; reproducible random seeds and sampling.
- Continuous interpretability monitoring and drift detection (MLOps)
- Periodically distill the same components and track changes in equations/complexity/fit to detect model drift or unintended behavior shifts.
- Tools/workflow: Scheduled activation capture; SR re-runs with cached data; equation diffing; alert thresholds; dashboards.
- Assumptions/dependencies: Stable sampling protocol; consistent operator set; robust complexity metrics; scalable SR pipeline.
- ML education and training materials (Education)
- Use SymTorch notebooks to teach mechanistic interpretability and neuro-symbolic methods with hands-on exercises in GNNs, PINNs, and LLMs.
- Tools/workflow: Course labs; reproducible notebooks; curated datasets; Pareto front exploration exercises.
- Assumptions/dependencies: Student access to PyTorch and Python; manageable compute requirements; preconfigured environments.
Long-Term Applications
These applications require further research, scaling, development, or standardization beyond the current proof-of-concepts.
- Neuro-symbolic compilers that translate NN components into optimized equation kernels (Software, Hardware)
- Automatically compile distilled expressions to vectorized code (e.g., Triton, CUDA) and integrate with ONNX/torch.compile for end-to-end acceleration.
- Dependencies: Robust SR scaling to higher dimensions; symbolic simplification/constant optimization; numerical stability; formal accuracy guarantees.
- Standardized interpretability governance and certification (Policy, Industry)
- Mandate symbolic distillation reports, complexity scores, and fit metrics for safety-critical models; create audit-ready artifacts and templates.
- Dependencies: Regulatory consensus; agreed-upon interpretability metrics; calibration of accuracy/complexity tradeoffs; reproducibility standards.
- Domain-specific LLM component surrogates for throughput-optimal deployments (Healthcare, Finance, Legal)
- Train and validate symbolic surrogates on domain corpora to meet latency SLAs for bounded tasks (e.g., triage, form parsing, entity extraction).
- Dependencies: Privacy-compliant data; cross-domain generalization studies; optimized layer selection; improved dimensionality reduction beyond PCA.
- Autonomous scientific discovery platforms (Academia)
- End-to-end pipelines that train models (GNNs/PINNs), distill symbolic laws, generate hypotheses, and loop through validation experiments.
- Dependencies: High-quality data generation; hypothesis management tools; human-in-the-loop review; automated equation verification.
- Verified control policies via distilled symbolic controllers (Robotics, Energy)
- Distill policy networks into interpretable controllers for formal verification, safety proofs, and runtime monitors in safety-critical systems.
- Dependencies: Ability to distill closed-loop policies; integration with formal methods toolchains; robustness under disturbances and OOD conditions.
- Interpretable digital twins with symbolic surrogate cores (Manufacturing, Energy, Smart Infrastructure)
- Embed distilled equations in digital twins for fast simulation, real-time optimization, and explainable maintenance strategies.
- Dependencies: High-fidelity alignment between twin and plant; periodic surrogate refresh; hybrid NN-symbolic co-simulation frameworks.
- Model marketplaces offering symbolic surrogates and hybrid blueprints (Software)
- Distribute plug-in symbolic replacements for common architectures (MLP blocks, GNN edges, PINN heads), with benchmarks and compliance metadata.
- Dependencies: IP/licensing clarity; API standards for component replacement; shared operator sets; community validation.
- Personalized on-device AI via hybrid neuro-symbolic models (Daily Life, Mobile)
- Deliver faster, battery-friendly assistants by converting selected layers to equations, enabling offline operation with lower resource use.
- Dependencies: Mobile math libraries; tight hardware integration; privacy-preserving local training for surrogates; UX testing for accuracy tradeoffs.
- STEM education platforms linking ML and physics with discoverable laws (Education)
- Interactive tools where students train models and immediately distill the laws they learned, bridging theory and practice.
- Dependencies: Pedagogical content; scalable web backends; sandboxed compute; assessment tooling for equations.
- Evidence-based AI transparency policies anchored in symbolic reporting (Policy)
- Introduce requirements for equation-level explanations, complexity caps, and fit thresholds in public-sector AI, procurement, or clinical AI guidelines.
- Dependencies: Measurement standards; legal frameworks; auditing capacity; stakeholder alignment on acceptable approximation error.
Collections
Sign up for free to add this paper to one or more collections.