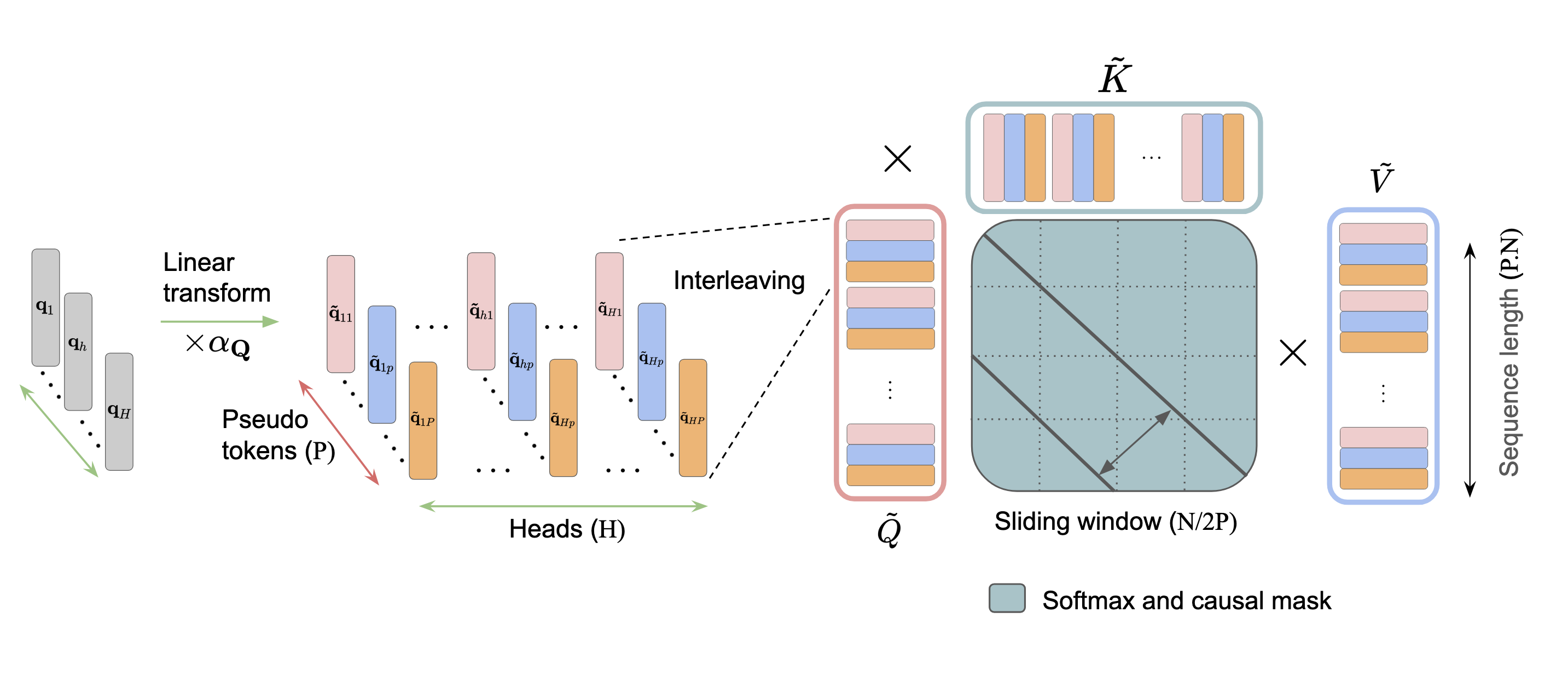
Interleaved Head Attention
Abstract: Multi-Head Attention (MHA) is the core computational primitive underlying modern LLMs. However, MHA suffers from a fundamental linear scaling limitation: $H$ attention heads produce exactly $H$ independent attention matrices, with no communication between heads during attention computation. This becomes problematic for multi-step reasoning, where correct answers depend on aggregating evidence from multiple parts of the context and composing latent token-to-token relations over a chain of intermediate inferences. To address this, we propose Interleaved Head Attention (IHA), which enables cross-head mixing by constructing $P$ pseudo-heads per head (typically $P=H$), where each pseudo query/key/value is a learned linear combination of all $H$ original queries, keys and values respectively. Interactions between pseudo-query and pseudo-key heads induce up to $P2$ attention patterns per head with modest parameter overhead $\mathcal{O}(H2P)$. We provide theory showing improved efficiency in terms of number of parameters on the synthetic Polynomial task (IHA uses $Θ(\sqrt{k}n2)$ parameters vs. $Θ(kn2)$ for MHA) and on the synthetic order-sensitive CPM-3 task (IHA uses $\lceil\sqrt{N_{\max}}\rceil$ heads vs. $N_{\max}$ for MHA). On real-world benchmarks, IHA improves Multi-Key retrieval on RULER by 10-20% (4k-16k) and, after fine-tuning for reasoning on OpenThoughts, improves GSM8K by 5.8% and MATH-500 by 2.8% (Majority Vote) over full attention.
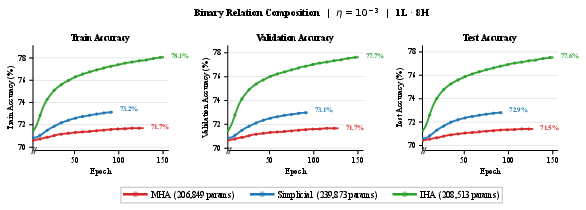
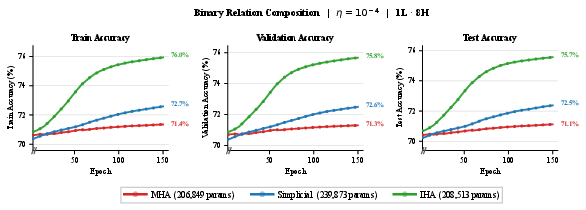
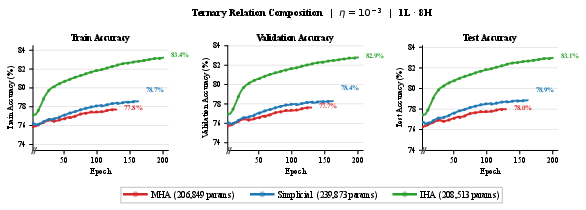
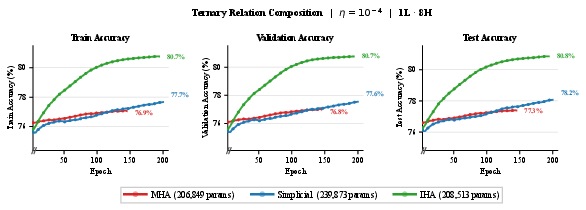
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper looks at a core piece of how LLMs (like ChatGPT) read and connect words called “multi‑head attention” (MHA). The authors argue that standard MHA has a bottleneck: each “head” works on its own, so it’s hard to combine clues across heads in a single step. They introduce a new way called Interleaved Head Attention (IHA) that lets heads mix information with each other during attention. This helps the model do multi‑step reasoning (like linking facts together) more efficiently and effectively.
What questions are the authors asking?
They focus on three simple questions:
- Can we let attention heads share and combine information while they’re computing attention, not just after?
- Will that help models handle multi‑step reasoning (when answers require chaining several facts)?
- Can we prove and measure that this helps, both in theory and in real benchmarks?
How does the new method work? (In everyday terms)
First, a quick refresher on attention and heads:
- Think of a long document as a big set of notes. An attention “head” is like a mini‑reader that looks for a certain kind of pattern (names, locations, matching brackets, and so on). In standard MHA, you have H heads—H mini‑readers—working in parallel, but each one pays attention only using its own view. They don’t “talk” while deciding what to read.
- The attention mechanism uses three kinds of internal vectors for each token: queries (what this token is looking for), keys (what this token offers), and values (the information carried). In standard MHA, each head builds its own queries/keys/values and computes one attention pattern.
What IHA changes:
- IHA creates P “pseudo‑heads” inside each head by taking learned mixes of all the original heads’ queries, keys, and values. In plain language: before the reading happens, each head gets extra blended versions of everyone else’s “questions” and “notes.”
- These mixed pseudo‑queries and pseudo‑keys can interact in up to P² different ways per head. That means instead of 1 attention pattern per head, you can get many attention patterns per head.
- The “interleaving” trick: the model temporarily treats each token as P mini‑tokens (one per pseudo‑head), runs normal attention on this larger sequence, then merges things back. This stays compatible with fast attention code (like FlashAttention), which is useful for speed.
Why this helps multi‑step reasoning:
- When a question needs multiple hops (like “The Hobbit → J.R.R. Tolkien → born in South Africa”), you often need to combine several relationships at once. Standard MHA typically needs one head for each “hop pattern,” so more steps mean more heads. IHA, by mixing heads before attention, can cover many “hop patterns” within fewer heads.
How they test it:
- Polynomial filters (simple math models of multi‑step spreading): Imagine a social network where information travels step by step. A k‑step task asks you to gather info from up to k steps away. Standard MHA usually needs about k heads to do this in one layer. IHA can do the same with about √k heads—much fewer.
- CPM‑3 (an order‑sensitive counting task): A controlled test where the model must count how many ordered pairs satisfy a certain rule. The authors show a construction where standard MHA needs a number of heads that grows linearly with the sequence length, but IHA needs only about the square root of that many heads—again, far fewer.
Parameter cost:
- IHA adds only a modest number of extra parameters to mix heads (roughly proportional to H²P, where H is the number of heads and P is the number of pseudo‑heads, often set to H). This is small compared to the full model size.
What did they find, and why does it matter?
Main findings:
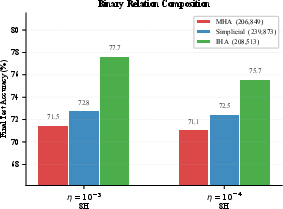
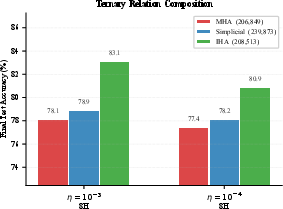
- Theory: IHA is strictly more expressive than standard MHA—meaning it can represent everything MHA can, and more. For tasks that need k different multi‑step patterns, IHA can cover them with about √k heads instead of k. That’s a big efficiency gain.
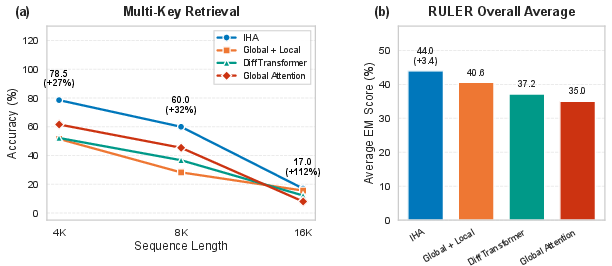
- Long‑context tests (RULER benchmark): On a “Multi‑Key Retrieval” task with long inputs (4k–16k tokens), IHA gets 10–20% relative improvements over standard full attention. In simple terms: it’s better at pulling multiple pieces of relevant info from long documents.
- Reasoning benchmarks after fine‑tuning (OpenThoughts): IHA improves performance on GSM8K (grade‑school math word problems) by 5.8% and on MATH‑500 by 2.8% using majority voting. This suggests better multi‑step reasoning in practice.
Why it matters:
- Better reasoning with fewer specialized heads: IHA lets each head cover many patterns, which can reduce the need for lots of heads or extra layers just to handle longer reasoning chains.
- Works with fast attention: Because IHA keeps the standard attention operator, it can use optimized kernels like FlashAttention, helping it stay efficient.
- Helps on long documents: The improvements on long‑context benchmarks show it’s good at finding and combining multiple clues across long inputs—something many real tasks need.
What’s the bigger impact?
If future LLMs adopt IHA, they could:
- Reason over multiple steps more reliably (helpful for math, logic, and multi‑hop question answering).
- Handle long documents better, pulling together multiple far‑apart facts.
- Be more parameter‑efficient for complex reasoning patterns, potentially saving compute or freeing capacity for other skills.
In short, Interleaved Head Attention gives attention heads a way to “talk” before they act, letting models combine evidence more flexibly. That makes multi‑step reasoning easier and more efficient—both in theory and in real tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following points unresolved; addressing them would clarify the scope, practicality, and limits of Interleaved Head Attention (IHA):
- Theory in an idealized regime only: Most proofs (e.g., polynomial filters and superset results) assume linear attention (no softmax), fixed adjacency/shift matrices, and single-layer settings. It remains open whether the same asymptotic advantages and separations hold under standard softmax attention with causal masking, positional encodings (e.g., RoPE), and multi-layer stacks.
- CPM-3 theorem completeness and tightness: The CPM-3 section contains missing quantities/notation (placeholders like “”), leaving the exact head/parameter complexity unclear. A complete, rigorous statement with tight upper and lower bounds—ideally matching or improving known lower bounds for MHA—remains to be provided.
- Practical compute/latency costs of pseudo-token interleaving: IHA expands the effective sequence length from to and suggests sliding-window attention to control cost. The paper does not quantify wall-clock throughput, memory, or energy overheads vs. MHA across , , , nor does it characterize when the -pattern benefit outweighs the -length penalty.
- KV-cache and autoregressive decoding behavior: It is unclear how interleaving affects KV-cache size, update cost, and decode-time latency for token-by-token generation. Concrete algorithms and measurements for cache layout, reuse, and amortized per-token cost under IHA are missing.
- Sensitivity to the choice of and : The paper typically sets , but provides no ablation mapping task performance vs. or guidance for selecting under compute budgets. Whether sublinear (e.g., ) yields favorable trade-offs for real tasks is untested.
- Placement within the stack: No guidance on which layers benefit most from IHA (early vs. middle vs. late), whether to apply IHA to all layers, and how gains depend on depth. Ablations across layer placements and combinations with standard MHA are absent.
- Stability and initialization of mixing tensors: The paper introduces and but does not discuss initialization strategies, regularization (e.g., sparsity/orthogonality), or optimization stability. Failure modes (e.g., collapse to a few heads, exploding norms) are not analyzed.
- Are patterns realized in practice?: While IHA can induce up to attention patterns per head by construction, the paper does not empirically verify whether training actually utilizes this capacity. Probes/visualizations quantifying distinct attention maps and head specialization under IHA are missing.
- Comparison to existing cross-head mixing: Empirical head-to-head comparisons with Talking-Heads and Knocking-Heads (which mix at logits/weights) are absent. Without these, it is unclear whether pre-attention mixing (IHA) provides superior accuracy/efficiency vs. post-attention mixing under equal budgets.
- Interaction with GQA/MQA and KV compression: The paper positions IHA as complementary to grouped/multi-query attention but does not empirically evaluate joint configurations. Whether pseudo-head mixing conflicts with reduced-KV schemes or alters their benefits remains unknown.
- Impact of interleaving order and causal masking: Interleaving creates a sequence , which imposes causal constraints among pseudo-tokens of the same position. Alternative layouts (e.g., block vs. interleaved) and their effect on modeling and efficiency are not explored.
- RoPE and positional encoding interactions: The paper argues interleaving works with RoPE by assigning each a unique position, yet it provides no formal analysis of phase interactions, length extrapolation behavior, or empirical sensitivity to positional scales under IHA.
- Pretraining vs. fine-tuning scope: Results come from long-context retrieval (RULER) and reasoning fine-tuning (OpenThoughts→GSM8K/MATH). The impact of IHA during pretraining from scratch, and its effects on broad generalization (e.g., coding, multilingual, instruction following), remain untested.
- Scaling to larger models: The study lacks results on larger foundation models and does not establish whether gains persist, diminish, or grow with model size and training data. Scaling-law analyses for accuracy vs. compute/params are missing.
- Compute/parameter overhead accounting: Although the parameter overhead () is “modest” compared to , the runtime cost of Step 2 mixing (einsum over ) and the -length attention is not quantified. Profiling on modern GPUs/TPUs with FlashAttention kernels is needed.
- Compatibility with optimized kernels: The paper claims compatibility with FlashAttention but does not demonstrate end-to-end speedups or give kernel-level details for the interleaved sequence, especially under sliding-window sparsity.
- Robustness and safety: No evaluation under distribution shift, adversarial prompts, or noise is provided. Whether cross-head mixing amplifies or mitigates spurious correlations or attention-path brittleness is unknown.
- Interpretability and head specialization: Cross-head mixing could blur the functional roles of heads. The paper does not investigate interpretability tools (e.g., attention pattern clustering, probing) to understand how IHA modifies head specialization vs. MHA.
- Theoretical extensions beyond single-layer constructions: Many results assume one layer and crafted linear maps. It remains open how benefits compose across layers, whether depth can reduce requirements, and how IHA interacts with residual mixing and feed-forward pathways.
- Generality beyond polynomial and CPM-3 proxies: Theoretical gains are shown for polynomial filters and CPM-3. Whether similar quadratic pattern benefits extend to other compositional tasks (e.g., multi-hop QA graphs, program execution) under realistic token distributions is an open question.
- Training recipe transparency and reproducibility: The paper mentions “FLOP-matched training” and OpenThoughts fine-tuning but omits detailed hyperparameters, ablation protocols, and statistical significance analyses, limiting reproducibility and fair comparisons.
Practical Applications
Immediate Applications
The following applications can be implemented with current tooling and infrastructure, leveraging IHA’s compatibility with standard attention operators and efficient kernels (e.g., FlashAttention). They reflect the paper’s empirical gains on long-context retrieval and multi-step reasoning benchmarks.
- Long-context, multi-key retrieval in enterprise search and document QA
- Sector: Software; Enterprise; Legal; Finance; Healthcare
- What to deploy: Integrate IHA into LLMs used for long-context retrieval (4k–16k tokens), especially in RAG pipelines where answers depend on evidence aggregated across multiple distant passages.
- Workflow: Replace MHA layers with IHA in the model backbone; keep FlashAttention kernels; use sliding-window attention tuned to NP (pseudo-expanded) sequence length; evaluate with RULER’s Multi-Key Retrieval and domain-specific corpora (contracts, filings, patient notes).
- Why now: The paper shows 10–20% relative gains on RULER Multi-Key retrieval under FLOP-matched training.
- Assumptions/dependencies:
- Gains are strongest when answers require composing multiple references across a large context.
- Need to generate positional encodings (e.g., RoPE) for NP-length sequences.
- Memory/compute trade-offs managed via windowed attention; P selection affects cost and accuracy.
- Better math and logic reasoning in tutoring and assistant products
- Sector: Education; Consumer software
- What to deploy: Fine-tune IHA-enabled LLMs on math/logic datasets (e.g., OpenThoughts) and serve models for tutoring, homework help, and exam practice.
- Workflow: Swap MHA for IHA in open-source backbones (e.g., Llama/Mistral family), fine-tune on reasoning-heavy corpora, use majority-vote inference (n>1 sampling) in production for higher reliability.
- Why now: Reported improvements over full attention of +5.8% on GSM8K and +2.8% on MATH-500 (Maj@16).
- Assumptions/dependencies:
- Improvements depend on fine-tuning for reasoning (e.g., OpenThoughts).
- Majority-vote increases inference cost; budget accordingly.
- Gains may be task-dependent; monitor for regressions on non-reasoning tasks.
- Multi-hop question answering and knowledge aggregation for customer support and analytics
- Sector: Software; Customer support; Business intelligence
- What to deploy: Use IHA-enabled LLMs to answer multi-hop queries that require chaining facts (e.g., “Which products shipped late after supplier X’s price increase?”).
- Workflow: Introduce IHA in the QA model, ensure input contexts include heterogeneous sources, benchmark against multi-hop QA datasets and internal tickets/logs.
- Assumptions/dependencies:
- Benefits are largest when queries require explicit composition (evidence chaining).
- Model and data pipeline must feed sufficient context for multi-step inference.
- Code assistants for cross-file dependency reasoning
- Sector: Software engineering
- What to deploy: Apply IHA to models used for code navigation, refactoring suggestions, and cross-file bug localization in large repositories.
- Workflow: Extend context windows (or use retrieval) to include multiple files; evaluate on tasks like linking symbol definitions to their usage chains.
- Assumptions/dependencies:
- Real-world codebases demand strong retrieval and multi-hop reasoning; P tuning may be needed per repo size.
- Compatibility with existing GPU kernels remains (uses standard attention operator).
- Clinical and biomedical literature assistants for evidence chaining
- Sector: Healthcare; Life sciences
- What to deploy: IHA-enabled LLMs to synthesize findings that require chaining across patient records or multiple papers (e.g., linking a drug, its mechanism, and outcomes).
- Workflow: Incorporate IHA in models used for clinical decision support and literature reviews; evaluate on curated multi-document tasks.
- Assumptions/dependencies:
- Regulatory constraints require rigorous validation and provenance.
- Performance gains likely when tasks require multi-hop evidence; ensure reliable retrieval.
- Policy and compliance document analysis
- Sector: Public policy; Finance; Legal
- What to deploy: Use IHA-enabled models to trace multi-step implications across statutes, regulations, and contractual clauses.
- Workflow: Deploy in compliance monitoring tools; benchmark on synthetic and real multi-step legal reasoning tasks; combine with audit trails.
- Assumptions/dependencies:
- Requires carefully curated corpora with consistent references across documents.
- Transparent reasoning workflows (e.g., chain-of-thought) may be needed for auditability.
- Practical library integration for researchers and engineers
- Sector: Academia; Software
- What to deploy: An IHA layer module for PyTorch/JAX that is drop-in for MHA with support for pseudo-head mixing, interleaving, and collapse, preserving FlashAttention compatibility.
- Workflow: Provide recipes for P, H selection; enable RoPE generation for NP length; include FLOP-matched training configs and evaluation harnesses (RULER, GSM8K, MATH-500).
- Assumptions/dependencies:
- Additional parameters scale as O(H2 P); monitor memory footprint and initialization.
- Sliding windows may be necessary to keep compute in check.
Long-Term Applications
These applications will benefit from further research, scaling, and integration into broader systems. They build on IHA’s theoretical expressivity and efficiency improvements for compositional reasoning.
- Pretraining strategies that reduce head count for the same expressivity
- Sector: AI infrastructure; Cloud; Edge
- Vision: Use IHA’s O(√k) head requirement (vs. O(k) for MHA) on compositional tasks to design pretraining curricula and architectures that maintain reasoning capacity with fewer heads/parameters.
- Potential product: “IHA-optimized” foundation models for edge deployment with lower memory/latency.
- Dependencies:
- Requires demonstrating pretraining efficiency gains at scale, not just fine-tuning.
- Stability and convergence under large-scale training need validation.
- Adaptive attention mechanisms for task-aware compositional complexity
- Sector: Software; Research tools
- Vision: Auto-tune P and H on-the-fly based on detected reasoning complexity (e.g., estimated chain length), or learn task-specific pseudo-mixing patterns.
- Potential tool: A runtime controller that adjusts pseudo-head expansion per input (dynamic NP).
- Dependencies:
- Robust complexity estimators; kernel-level support for dynamic sequence length.
- Careful latency management to avoid unpredictable inference times.
- Graph-structured and multi-token interaction models beyond language
- Sector: Graph ML; Scientific computing; Time-series
- Vision: Apply IHA to graph transformers and temporal models to efficiently realize polynomial filters and multi-hop aggregations (e.g., network anomaly detection, supply chain risk propagation).
- Potential workflows: Hybrid GNN–Transformer systems leveraging IHA for k-hop reasoning with fewer heads.
- Dependencies:
- Need domain-specific benchmarks showing consistent wins over alternatives.
- Integration with graph-specific positional encodings and kernels.
- Multi-modal compositional reasoning (vision, audio, robotics)
- Sector: Robotics; Autonomous systems; Media
- Vision: Use IHA to improve plan synthesis and multi-step perception (e.g., chaining visual detections and temporal cues), or audio models requiring compositional pattern matching.
- Potential products: Better high-level planners combining language and perception for multi-step tasks.
- Dependencies:
- Cross-modal alignment strategies; compatibility with vision/audio transformer kernels.
- Safety validation for real-world deployment.
- Evidence synthesis platforms for high-stakes domains
- Sector: Healthcare; Public policy; Law; Finance
- Vision: End-to-end systems that trace and compose evidence across heterogeneous sources, with IHA enhancing multi-step aggregation while providing provenance and uncertainty quantification.
- Potential workflows: Decision-support dashboards integrating IHA-enabled reasoning with citation tracking and structured outputs.
- Dependencies:
- Formal evaluation frameworks, calibration methods, and regulatory acceptance.
- Robust handling of failure modes (e.g., hallucinations amplified by cross-head mixing).
- Tools for diagnostic evaluation and interpretability of compositional reasoning
- Sector: Academia; Model assurance
- Vision: Benchmarks and probes (e.g., CPM-3 variants, polynomial filters) and visualization tools to inspect how pseudo-heads compose attention maps.
- Potential tools: “IHA Reasoning Inspector” to audit P2 interaction patterns and head utilization.
- Dependencies:
- Methodological work to relate low-level attention maps to high-level reasoning steps.
- Community adoption and standardized reporting practices.
- Kernel and systems-level optimizations for NP-expanded sequences
- Sector: AI systems; GPU/TPU vendors
- Vision: Specialized kernels that exploit the interleaving pattern, reduce memory movement, and optimize sliding-window attention for NP sequences.
- Potential products: Vendor-supported “Interleaved Attention” primitives in mainstream libraries.
- Dependencies:
- Collaboration with hardware vendors; thorough benchmarking across batch sizes and context lengths.
- Balancing throughput and latency for production-grade deployments.
Notes on feasibility across applications:
- IHA’s benefits are strongest for tasks that require multi-step, compositional reasoning or multi-key retrieval across long contexts.
- Parameter and compute overheads depend on P and H; while the added O(H2 P) parameters are modest relative to d_model, effective sequence length grows to NP, often necessitating windowed attention and careful memory management.
- Reported theoretical results rely on constructions without softmax; empirical improvements demonstrate practical utility, but broader validation across diverse workloads is needed.
- Compatibility with FlashAttention and standard attention operators lowers integration friction, but positional encoding and kernel configuration must be adapted to the NP expansion.
Glossary
- bAbI: A synthetic benchmark dataset designed to evaluate multi-step reasoning in question answering. "as well as multi-hop QA benchmarks such as bAbI"
- Causal mask: A masking scheme in autoregressive attention that prevents tokens from attending to future positions. "with the causal mask applied implicitly."
- Collapse map: A learned linear mapping used in IHA to combine outputs from multiple pseudo-heads back into per-head representations. "and a collapse map \bm{R}\in\mathbb{R}{H\times HP}"
- Compositional reasoning: Reasoning that involves chaining multiple intermediate inferences or relations to derive an answer. "multi-step, compositional reasoning"
- Count Permutation Match-3 (CPM-3): A synthetic task that requires counting order-sensitive triples satisfying a modular predicate, probing composition and counting capabilities. "Count Permutation Match-3 (CPM-3)"
- Cyclic permutation matrix: A matrix that circularly shifts vector entries, used to model ordered shifts in sequences. "Let \bm P\in\mathbb R{\times} be the cyclic permutation matrix."
- Differential Attention: An attention variant that modifies attention maps to capture differences or gradients in attention behavior. "Differential Attention"
- Einstein summation (einsum): A concise tensor operation notation used to express index contractions and permutations. "einsum for Einstein summation following NumPy conventions"
- Expressivity: The capacity of a model class to represent a wide range of functions or attention patterns. "strictly more expressive than MHA"
- FlashAttention: An optimized attention kernel that improves memory and speed efficiency for attention computation. "compatible with efficient kernels such as FlashAttention"
- FLOP-matched training: A fair comparison protocol where models are trained with the same floating-point operation budget. "Under FLOP-matched training, IHA improves Multi-Key retrieval on RULER by 10--20%"
- GQA/MQA: Grouped-Query Attention and Multi-Query Attention, efficiency-oriented attention variants that share or group key-value projections. "MQA/GQA \citep{shazeer2019mqa,ainslie2023gqa} reduce KV cost."
- Graph signal processing: A field that studies signals defined on graphs, including filtering and spectral methods. "Polynomial graph filters are a core primitive in graph signal processing."
- GSM8K: A math word problem benchmark for evaluating arithmetic and reasoning capabilities. "improves GSM8K by 5.8%"
- Hard attention (softmax temperature 0): An attention regime approximating argmax selection by using a zero-temperature softmax. "hard attention (softmax temperature 0)"
- Indicator function: A function that returns 1 if a condition is true and 0 otherwise. "denotes the indicator function"
- Interleaved Head Attention (IHA): An attention mechanism that mixes information across heads by forming pseudo-queries/keys/values as learned combinations, enabling multiple attention patterns per head. "we propose Interleaved Head Attention (IHA), which enables cross-head mixing"
- Interleaving: The process of merging the pseudo-head dimension into the sequence dimension to run standard attention over an expanded sequence. "These tokens are then interleaved to create an expanded sequence of length P \cdot N."
- Knocking-Heads: A method that mixes information across attention heads at the level of logits/weights rather than queries/keys/values. "Talking-Heads, Knocking-Heads"
- KV cost: The computational and memory cost associated with key and value projections in attention mechanisms. "reduce KV cost."
- LLMs: Neural network models with billions of parameters trained on large corpora to perform a variety of language tasks. "modern LLMs"
- Majority voting: An evaluation method that aggregates multiple sampled outputs by choosing the most frequent answer. "under majority voting."
- Match-3: A synthetic reasoning primitive involving matching triples of items, used to probe compositional capabilities. "Match-3"
- MATH-500: A benchmark subset of math problems used to evaluate mathematical reasoning performance. "MATH-500"
- Multi-head Attention (MHA): The standard attention mechanism that computes multiple independent attention heads without interaction during attention computation. "Multi-Head Attention (MHA) is the core computational primitive underlying modern LLMs."
- Multi-hop QA: Question answering tasks that require chaining information across multiple supporting facts. "multi-hop QA benchmarks"
- OpenThoughts: A reasoning-focused fine-tuning dataset used to improve chain-of-thought capabilities. "After fine-tuning on OpenThoughts"
- Parameter complexity: The asymptotic or explicit count of parameters required by a model or construction. "with parameter complexity 2N(N+d)k + d(N+d)k"
- Polynomial graph filters: Operators expressed as polynomials of a graph adjacency matrix to aggregate information from multi-hop neighborhoods. "Polynomial graph filters are a core primitive in graph signal processing."
- Positional encodings: Additional input features that encode token positions to enable order-aware attention. "We augment \bm{X} with positional encodings"
- Pseudo-heads: Learned linear combinations of original heads’ projections that create multiple pseudo-queries/keys/values per head. "constructing P pseudo-heads per head (typically P=H)"
- Pseudo-queries/keys/values: Mixed projections formed by combining original heads’ queries, keys, and values to enable cross-head interactions. "pseudo-queries, pseudo-keys, and pseudo-values"
- RoPE (Rotary Position Embeddings): A positional encoding technique that rotates query/key vectors by position-dependent phases. "RoPE depends on the position index"
- RULER: A long-context evaluation benchmark that tests retrieval and reasoning over large sequences. "On the RULER long-context benchmark"
- Scaled dot-product attention: The attention mechanism that computes similarity via dot-products scaled by the inverse square root of the head dimension. "standard scaled dot-product causal self-attention"
- Simplicial/trilinear attention: Attention mechanisms that model interactions among three or more tokens simultaneously. "simplicial/trilinear attention"
- Softmax (row-wise softmax): The normalization function applied across each row of the attention score matrix to form probability distributions. "the softmax is applied row-wise"
- Strassen-style constructions: Techniques inspired by Strassen’s fast matrix multiplication to design efficient multi-token interactions. "Strassen-style constructions"
- Talking-Heads: A method that mixes attention heads at the level of logits/weights to enhance head interaction. "Talking-Heads, Knocking-Heads"
Collections
Sign up for free to add this paper to one or more collections.