- The paper introduces a hybrid diffusion acceleration approach that leverages condition-based partitioning and dynamic scheduling to optimize speed–quality trade-offs.
- It achieves up to 2.31× latency reduction on SDXL and reduces communication costs by 19.6× compared to traditional patch-based or pipeline methods.
- The framework scales robustly to high-resolution tasks and diverse architectures, maintaining generation fidelity through adaptive switching based on denoising discrepancy.
Hybrid Data-Pipeline Parallelism for Diffusion Acceleration via Conditional Guidance Scheduling
Motivation and Background
Diffusion models have attained state-of-the-art results across generative domains, including high-fidelity image, video, and audio synthesis. Their inference, inherently iterative over many denoising steps, remains computationally expensive, especially as underlying architectures increase in complexity and output resolution. The prior art in accelerating diffusion inference via distributed parallelism has mainly explored patch-based data parallelism (as in DistriFusion [li2024distrifusion]) and pipeline parallelism (as in AsyncDiff [chen2024asyncdiff]), but both approaches suffer from bottlenecks—either in communication, fidelity, or both.
Patch-based parallelism introduces boundary artifacts and aggregates features via costly inter-device communication (Figure 1), while pipeline parallelism—partitioning the model across devices—accumulates asynchronous communication overhead and errors from stale intermediate estimates. The paper “Accelerating Diffusion via Hybrid Data-Pipeline Parallelism Based on Conditional Guidance Scheduling” (2602.21760) introduces a hybrid parallelism framework explicitly designed to optimize the speed–quality trade-off by scheduling parallel computation based on the denoising discrepancy between conditional and unconditional branches of classifier-free guided diffusion.
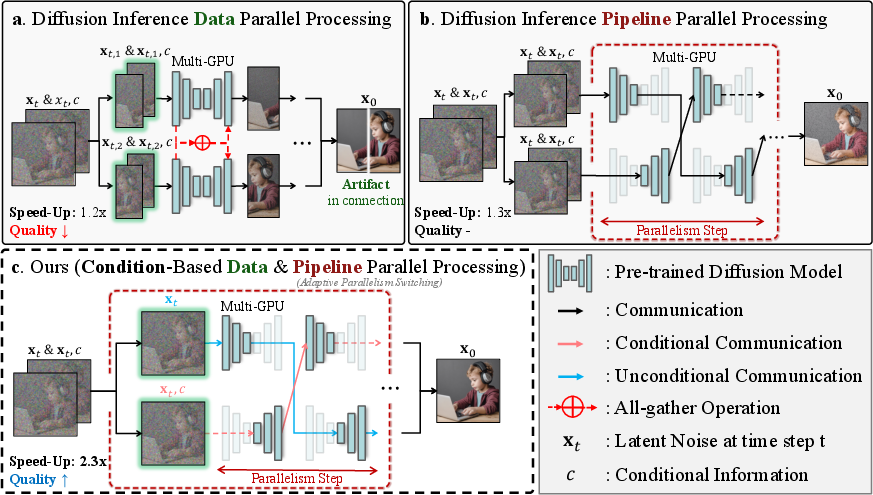
Figure 1: Comparison of parallel strategies for diffusion inference highlighting bottlenecks in patch-based and pipeline parallelism, and the hybrid conditional path partitioning approach.
Methodology
The framework leverages the structure of classifier-free guided models, which maintain conditional (prompt-guided) and unconditional denoising streams. Instead of spatial partitioning, “condition-based partitioning” exploits the divergence and convergence between these two streams to inform parallel execution. The process is divided into three stages: warm-up (initial denoising), parallel (discrepancy minimized), and fully-connecting (final refinement). The scheduling is governed by an adaptive metric, the relative mean absolute error (rel-MAEt(ϵc,ϵu)), computed between conditional and unconditional noise estimates at each timestep.
The hybrid framework operates as follows:
- Serial execution persists for early and late timesteps where discrepancy is large.
- Intermediate timesteps, identified by a U-shaped rel-MAEt curve, enable parallel execution, minimizing communication and error propagation (Figure 2, Figure 3).
- Switching points (τ1, τ2) are dynamically determined in real-time based on the discrepancy slope and a safety cap at global minima of the discrepancy curve, ensuring stable fidelity across prompt distributions.
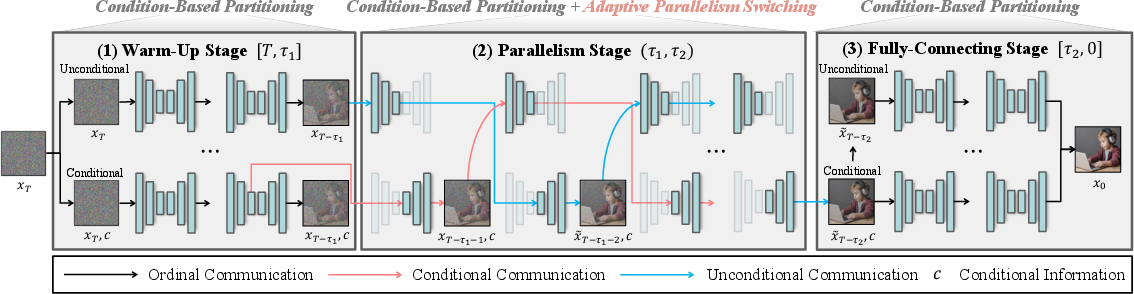
Figure 2: Overview of the hybrid parallel diffusion inference framework, showing adaptive switching at τ1 and τ2 for optimal speed–quality balance.
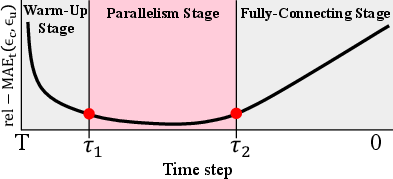
Figure 3: Illustration of the relative-MAE curve (rel-MAEt(ϵc,ϵu)), guiding parallelism activation intervals.
The theoretical analysis leverages score decomposition—relating the denoising discrepancy to the ratio between conditional information strength and unconditional score magnitude—providing a principled foundation for the switching mechanism.
Extensibility to multi-GPU settings is achieved via batch-level extension (efficient for high throughput) and layer-wise pipeline partitioning (for single-image generation), generalizing beyond U-Net to DiT and flow-matching architectures.
Empirical Evaluation and Numerical Results
Experiments were conducted on SDXL (U-Net) and SD3 (DiT-based, flow-matching) across the MS-COCO 2014 benchmark at resolutions up to 2560×2560 using NVIDIA RTX3090 and H200 hardware.
Key numerical findings:
- On SDXL, the hybrid framework achieves 2.31× latency reduction with two GPUs versus single-GPU baseline and maintains, or slightly improves, FID/LPIPS/PSNR relative to original outputs.
- On SD3, results demonstrate 2.07× speedup and superior communication efficiency.
- Communication cost is reduced by 19.6× compared to stride-based pipeline approaches.
- Ablation studies isolate the contributions from condition-based partitioning and pipeline scheduling; condition-based partitioning alone yields 1.78× acceleration, while the hybrid method achieves the full 2.31× speedup.
Qualitative results (Figure 4, Figure 5, Figure 6) show visual coherence and preservation of fine details, outperforming prior distributed methods which exhibit spatial artifacts or degraded attribute fidelity.

Figure 4: Qualitative results comparing 1024×1024 generations from SDXL; hybrid parallelism delivers superior FID and closest match to original outputs.

Figure 5: Additional qualitative results, further demonstrating improved similarity to original and artifact-free generation.

Figure 6: Comparisons across varying parallel intervals k; larger k values increase acceleration but subtly blur conditional attributes.
Pareto frontier analysis across parallelism interval k (Figure 7) quantifies the latency–quality trade-off: smaller k preserves fidelity, larger k maximizes speed.
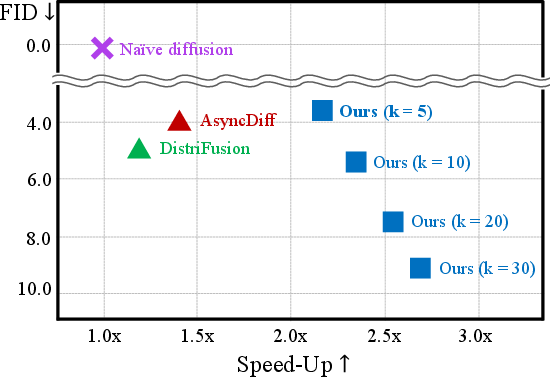
Figure 7: Visualization of speed–quality trade-off across parallel intervals; hybrid method consistently dominates prior approaches.
The framework also scales robustly to high resolutions (Figure 8), attaining up to 2.72× speedup at 1024×1024, and maintaining strong scaling performance at 2048×2048 and 2560×2560.
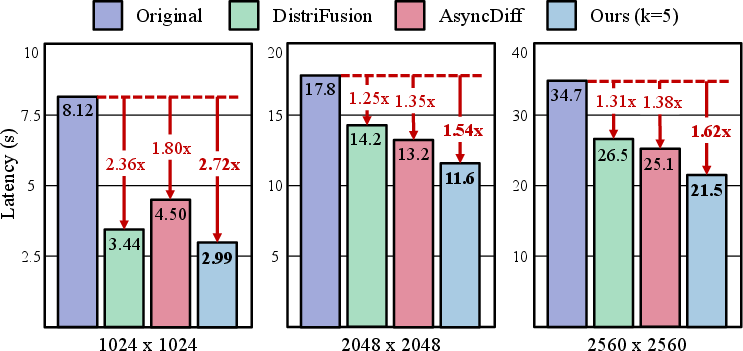
Figure 8: Comparison of high-resolution tasks, showing consistent speedup and fidelity across distributed inference methods.
Empirical visualization of the denoising discrepancy curve substantiates the adaptive switching mechanism (Figure 9).
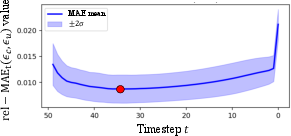
Figure 9: Denoising discrepancy curve empirically validates the adaptive parallelism schedule.
Batch-level extension scalability is visualized (Figure 10).
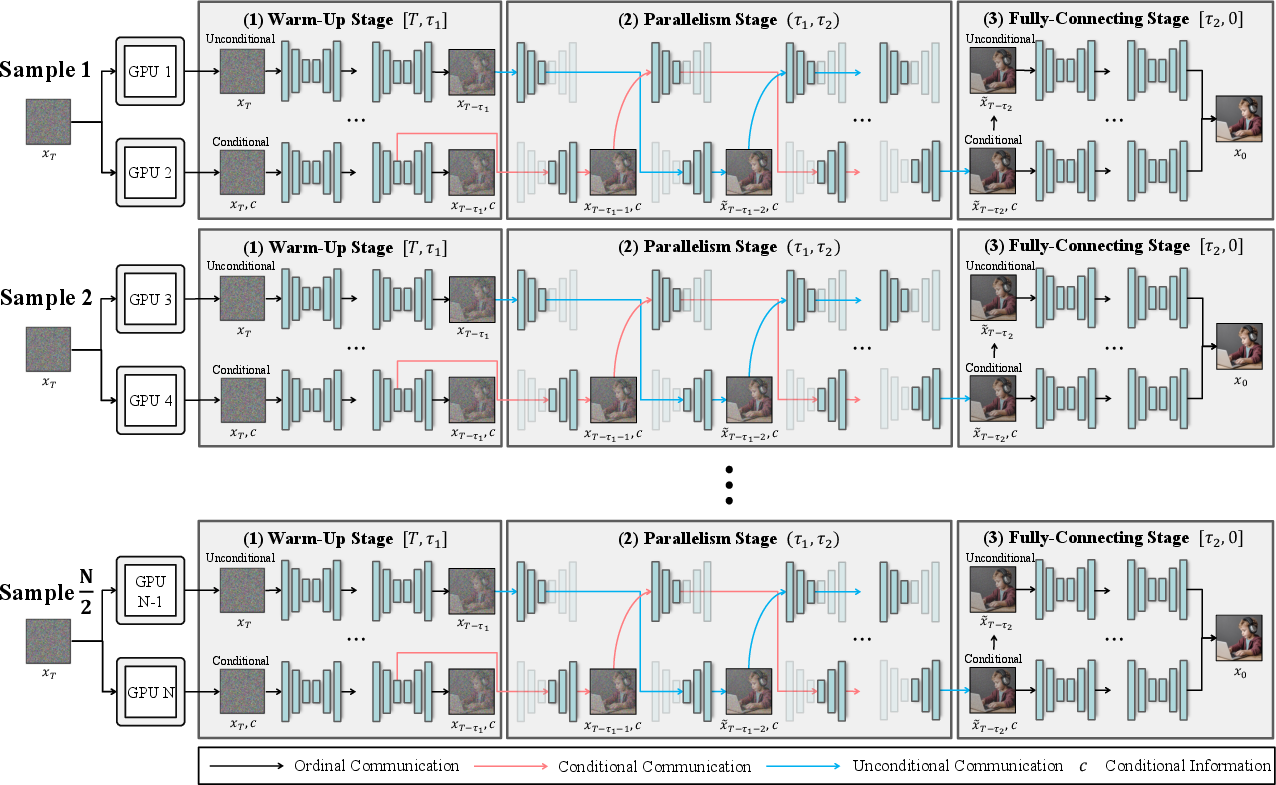
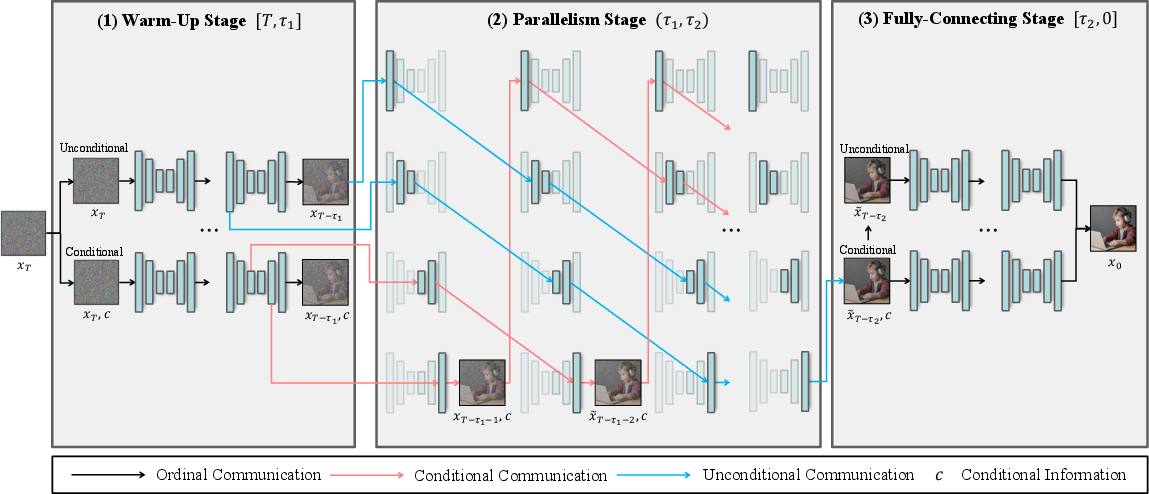
Figure 10: Batch-level extension under N GPUs demonstrates linear throughput scaling without loss of generation quality.
Practical and Theoretical Implications
This hybrid parallelism paradigm eliminates key limitations associated with patch-based and static pipeline methods. By aligning model structure with dynamic conditional guidance, the framework achieves nearly ideal scaling without compromising output fidelity, establishes robust communication efficiency, and generalizes to diverse architectures including DiT and flow-matching frameworks.
Practically, this enables resource-efficient deployment of large diffusion models in production and research settings, especially for high-resolution, conditional generative tasks.
Theoretically, the denoising discrepancy metric provides a principled tool for dynamic scheduling in iterative generative processes, which could inspire further adaptive schemes for other types of multimodal or conditional generative models.
Potential extensions include finer-grained layer-wise scheduling, more granular discrepancy metrics, and integration with emerging architectures in video and audio diffusion.
Conclusion
The paper presents a unified hybrid parallel inference framework for diffusion models, combining condition-based data partitioning with adaptive scheduling informed by denoising discrepancy. The method achieves substantial speedups while preserving generation quality, robustly scaling to high-resolution synthesis and diverse architectures. By formalizing the trade-off between conditional guidance and global consistency, the work advances the efficiency of distributed diffusion inference and sets a precedent for adaptive parallel computation in generative modeling (2602.21760).