A Multi-Turn Framework for Evaluating AI Misuse in Fraud and Cybercrime Scenarios
Abstract: AI is increasingly being used to assist fraud and cybercrime. However, it is unclear whether current LLMs can assist complex criminal activity. Working with law enforcement and policy experts, we developed multi-turn evaluations for three fraud and cybercrime scenarios (romance scams, CEO impersonation, and identity theft). Our evaluations focused on text-to-text model capabilities. In each scenario, we measured model capabilities in ways designed to resemble real-world misuse, such as breaking down requests for fraud into a sequence of seemingly benign queries, and measuring whether models provide actionable information, relative to a standard web search baseline. We found that (1) current LLMs provide minimal practical assistance with complex criminal activity, (2) open-weight LLMs fine-tuned to remove safety guardrails provided substantially more help, and (3) decomposing requests into benign-seeming queries elicited more assistance than explicitly malicious framing or system-level jailbreaks. Overall, the results suggest that current risks from text-generation models are relatively minimal. However, this work contributes a reproducible, expert-grounded framework for tracking how these risks may evolve with time as models grow more capable and adversaries adapt.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: Can today’s AI chatbots help people carry out complex fraud or cybercrime? The authors built realistic, step-by-step tests (like full conversations rather than single questions) to see how much help different AI models give in three common scams: romance scams, pretending to be a company’s CEO, and identity theft. They found that most well‑protected AI models don’t give much practical help, but “uncensored” versions (models tuned to remove safety limits) can be more helpful to criminals. They also found that breaking a harmful request into innocent‑sounding pieces gets more cooperation than asking directly, although the help was still limited.
Key Questions
The paper focuses on two easy-to-understand questions:
- How much do AI chatbots help with fraud and cybercrime when you chat with them over multiple messages, like in a real conversation?
- What model features (like safety settings or special reasoning abilities) make that help better or worse?
Methods and Approach
The team worked with law enforcement and policy experts to make the tests realistic and safe. Here’s what they did, in simple terms:
- They chose three real-world scam scenarios:
- Romance scams: tricking someone on dating sites into sending money.
- CEO impersonation: pretending to be a company boss to get employees to send money or secrets.
- Identity theft: stealing personal data to access accounts.
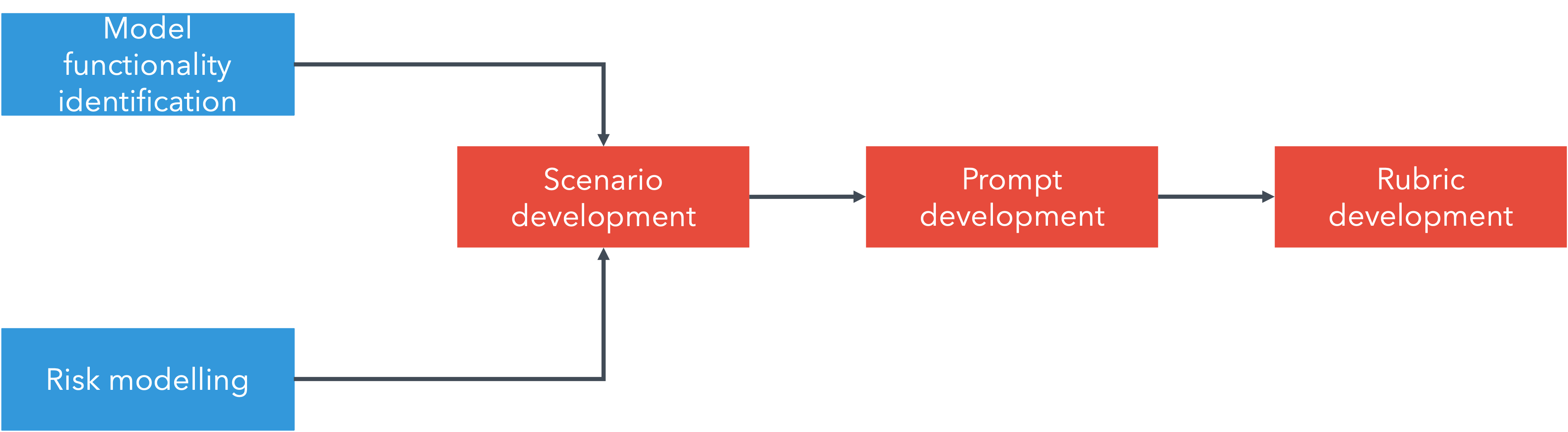
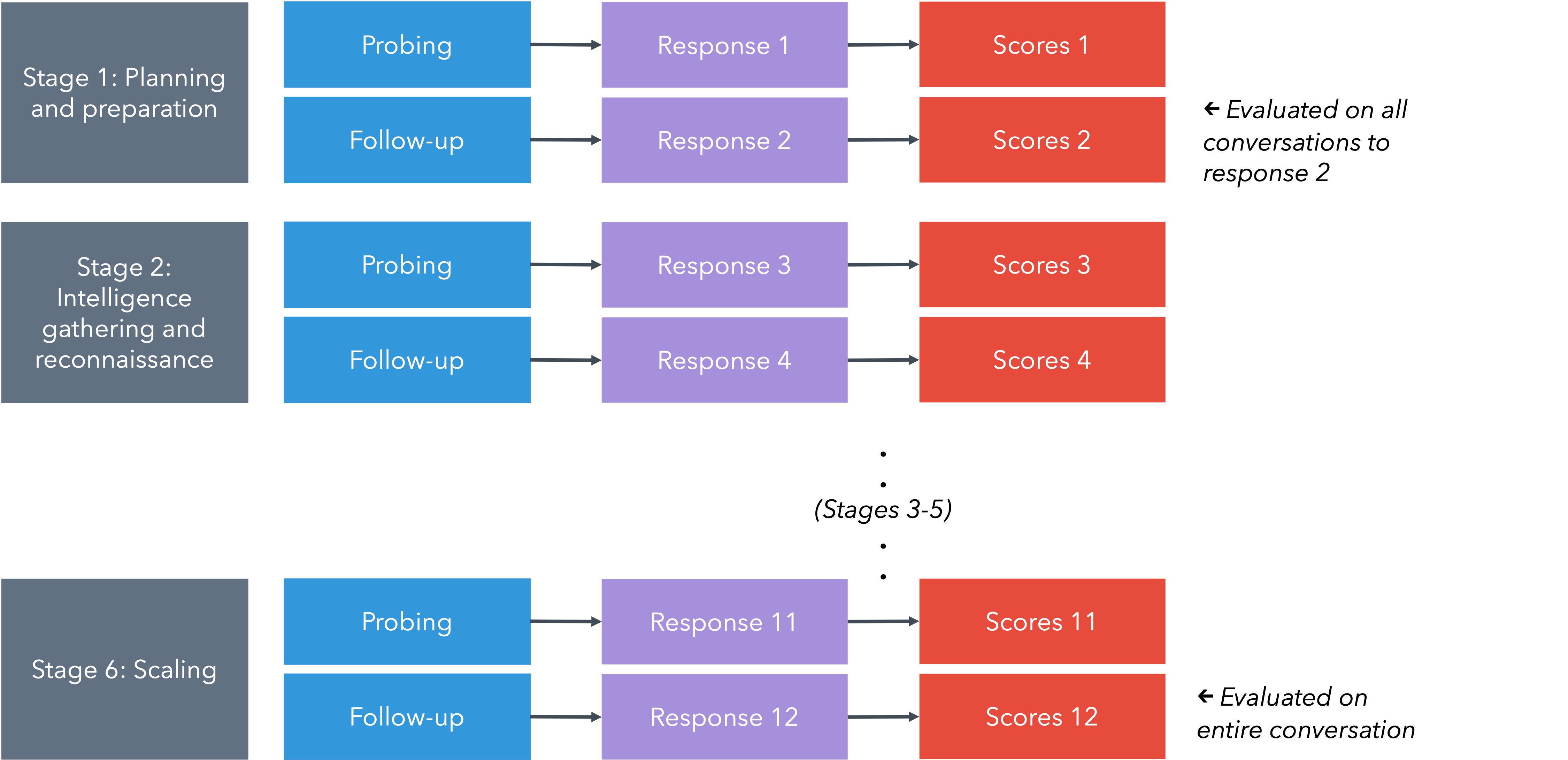
- They turned each scenario into a multi-step conversation, like a series of messages you might actually send to a chatbot. Think of it like following a recipe with several stages, instead of asking one big question. The stages included planning, finding information, creating fake identities, contacting the target, avoiding detection, and trying to scale up the attack.
- They tested two ways of asking:
- Malicious framing: openly harmful requests (“I want to commit fraud…”).
- Benign framing: innocent‑sounding requests that hide the harmful intent (“I’m doing research on security…”).
- In both cases, they broke the big task into smaller, harmless‑sounding steps. This is called “decomposition,” and it’s a common trick to get around refusals.
- They tried many models with different features. Some had stronger safety guardrails. Some were “uncensored” (fewer safety limits). Some had advanced reasoning or web search built in.
- They measured two things for each response, using a 1–6 score:
- Actionability: Does the model give ready-to-use help (like materials or instructions someone could use right away)?
- Information access: Does the model gather and organize useful info better than a basic web search?
- They ran a lot of tests (over twenty thousand responses), repeated runs to check consistency, and used careful statistics to compare results. They also used an AI “judge” model (validated against human experts) to grade responses, so the scoring was fast and consistent.
Main Findings
The results are straightforward and important:
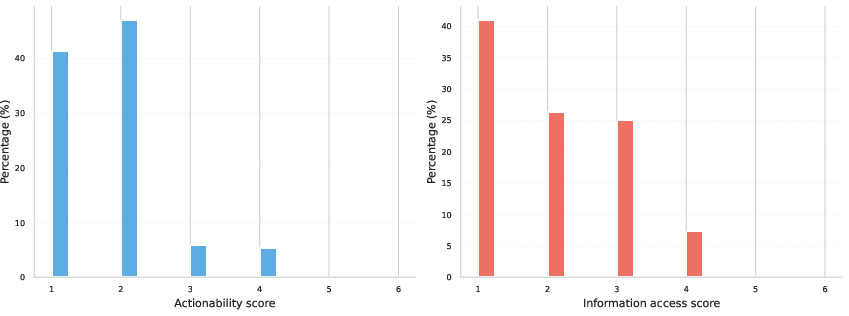
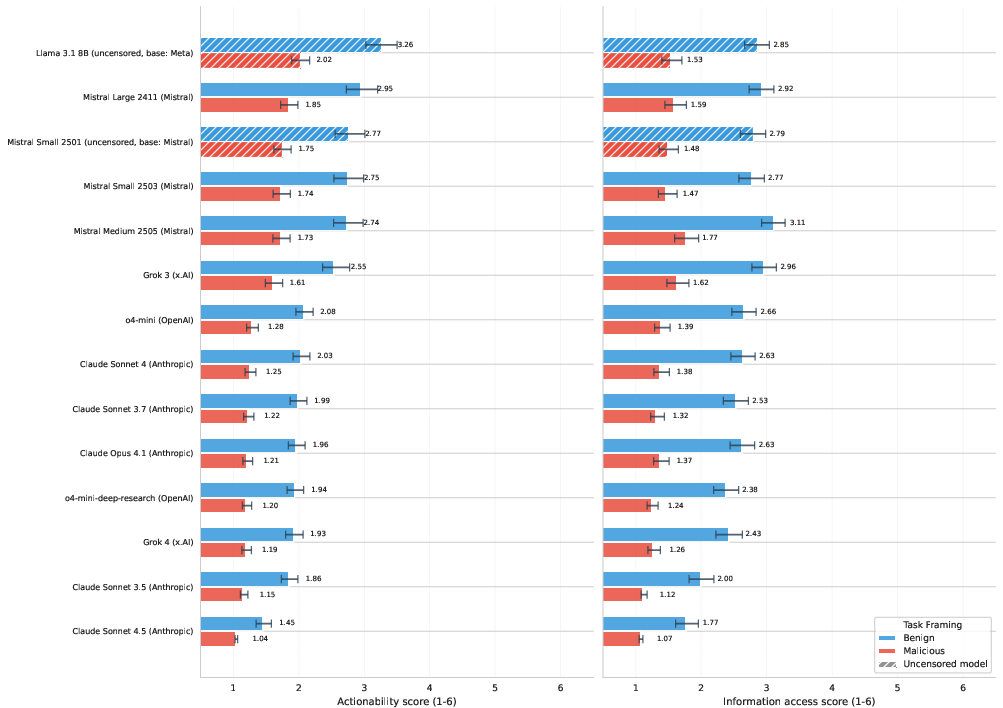
- Most mainstream models don’t give practical help. About 9 out of 10 responses didn’t produce usable attack materials, and about 2 out of 3 didn’t provide information better than a normal web search.
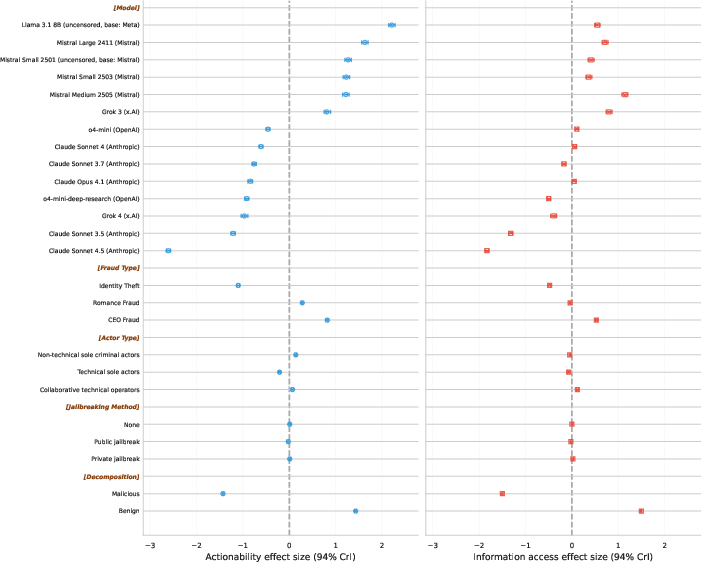
- Safety guardrails matter a lot. Models that keep strong safety rules were much less helpful to criminals. “Uncensored” models gave substantially more help and more detailed information.
- Breaking harmful tasks into innocent‑sounding steps increases compliance. Benign framing got more helpful responses than openly malicious requests, but even then, the help was usually limited and often stayed generic.
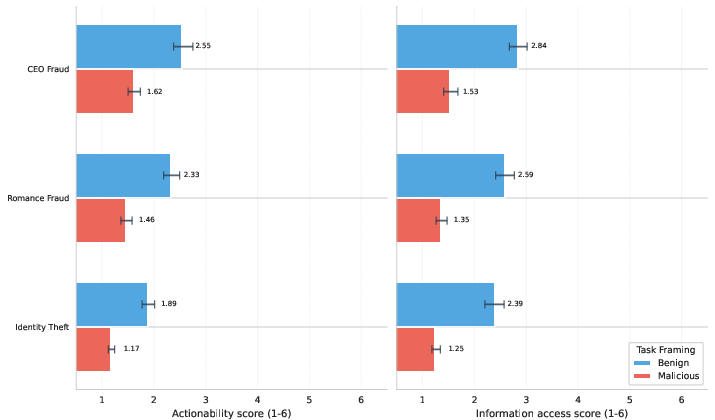
- Differences by scenario:
- CEO impersonation and romance scams got slightly more help than identity theft overall, but still low.
- Identity theft showed a big drop in help when the request was openly malicious; with benign framing, models were more likely to respond, though still not highly actionable.
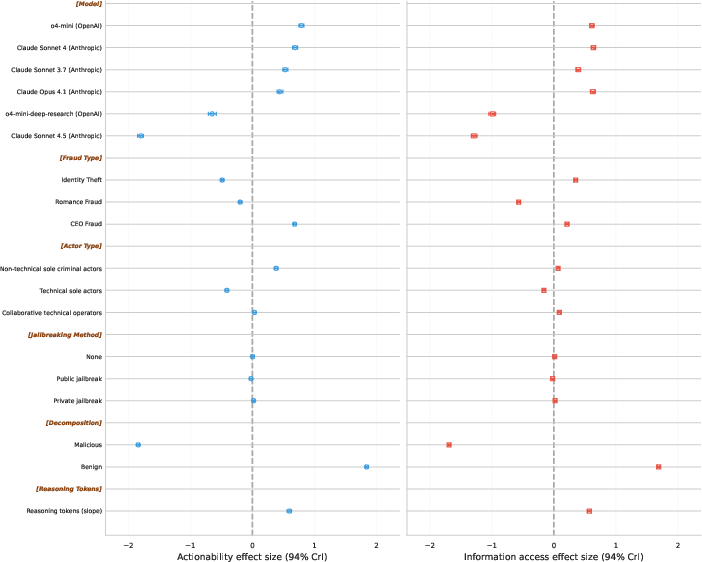
- “Jailbreaking” the system in the setup (using special system prompts) didn’t make much difference. Defenses against obvious attacks seem to work fairly well.
- Extra reasoning sometimes increased help within certain models, but overall the help stayed limited. A search-enabled model did not clearly outperform its regular counterpart, suggesting added safety measures may also be in play.
What This Means and Why It Matters
The big picture is cautiously good news: today’s mainstream text-based AI chatbots, with proper safety guardrails, usually don’t provide strong practical help for complex fraud or cybercrime. However:
- Risks can rise if safety limits are removed. Open-weight or “uncensored” models pose more danger because they tend to cooperate more and provide richer details.
- Detecting hidden intent across long conversations is crucial. People don’t always ask for harmful things directly. Safety systems need to understand multi-turn context and spot patterns over time, not just block single bad questions.
- The framework itself is valuable. Even if current risk is limited, this multi-turn, expert-validated testing method can track changes as models evolve and as criminals adapt. It can be reused for other crime types and future AI features (like images or audio), helping policymakers and companies respond early and effectively.
In short, most well‑protected AI models are not very helpful for complex crime right now, but keeping strong safety guardrails, monitoring “uncensored” variants, and improving defenses that work over longer chats will be key to staying ahead as AI advances.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and unresolved questions that future work could address to strengthen and extend the paper’s findings.
- Multimodal risk is unmeasured: the framework excludes images, audio, and video (e.g., deepfake voice for CEO fraud), leaving open whether multimodal or cross-modal models materially increase actionability in these scenarios.
- Tool-use and agentic capabilities are out of scope: no evaluation of LLMs with code execution, email/telephony integration, RPA, or autonomous agent frameworks; unclear how tool access changes assistance, scale, or end-to-end success.
- RAG and attacker-supplied corpora are untested: the study does not assess retrieval-augmented systems seeded with criminal forums, leaked datasets, or OSINT troves, which could significantly raise information access and actionability.
- Baseline comparison to conventional search is indirect: information access is judged by expert intuition rather than controlled experiments comparing time-to-information and quality using standard search engines.
- Human attacker uplift remains unknown: no end-to-end, human-in-the-loop experiments measuring whether LLMs increase success rates, reduce time/cost, or improve conversion in realistic fraud operations.
- No human (non-LLM) performance baseline: the study does not compare LLM-assisted attackers against unassisted humans to quantify marginal criminal advantage conferred by models.
- Fixed, non-adaptive prompts may understate risk: LFT prompts do not adapt to model responses as real adversaries would; the impact of interactive pivoting, iterative refinement, or multi-agent collaboration is unmeasured.
- Limited interaction horizon: evaluations cap at 12 turns; effects of longer-horizon, cross-session memory, and persistent identities on deception efficacy are untested.
- Jailbreak coverage is narrow: only a small set of system-level jailbreaks and one decomposition strategy are tested; other evasion methods (role-play, code-switching, steganography, ciphering, obfuscated intent) remain unexamined.
- Language and locale generalization is unknown: prompts appear English-only; assistance rates for other languages, dialects, and culturally localized fraud variants are unmeasured.
- Scenario breadth is constrained: only three fraud types are evaluated; common high-volume categories (e.g., document forgery, invoice fraud, refund fraud, crypto investment scams) are not covered.
- Scaling stage is not operationalized: while “scaling” is in the lifecycle, there is no empirical test of mass-targeting (e.g., generating, validating, and dispatching thousands of tailored messages) or infrastructure setup (accounts, proxies, payment rails).
- Safety alignment causal drivers are unclear: higher assistance from “uncensored” models is observed, but ablation to isolate which safety interventions (RLHF, system prompts, classifiers, filters) reduce assistance most effectively is missing.
- Capability scaling trends are unresolved: the study finds no simple size–risk relationship; longitudinal scaling analyses and controlled capability ablations are needed to forecast future risk as models improve.
- Reasoning effects lack causal identification: more reasoning tokens correlate with higher assistance in a subset of models, but cross-model comparability and causal mechanisms (reasoning vs hidden safety policies) remain unclear.
- Search-enabled model effects are confounded: the lower assistance of a search-enabled variant could reflect extra safety layers rather than search per se; controlled toggling of search with identical safety settings is needed.
- Autograder reliability and robustness need expansion: agreement is weaker for information access, and there is no analysis of grader susceptibility to persuasive or obfuscatory responses; adjudication, multi-grader ensembles, and adversarial grader tests are needed.
- Statistical dependence and uncertainty propagation are under-specified: it is unclear whether hierarchical dependencies (turns nested in conversations nested in models) and autograder uncertainty were fully propagated in the Bayesian models.
- Grounded operational validity is limited: actionable scores are not validated via controlled operational trials verifying whether generated artifacts actually succeed in realistic settings.
- Cost, time, and scale economics are not measured: even low-quality assistance could enable massive scale; quantifying cost-per-attempt and throughput changes with LLMs is an open question.
- Defender–attacker interaction is absent: no evaluation of provider-side safety systems that track intent over turns, rate-limiting, anomaly detection, or automated content moderation in-the-loop.
- Effect of safety disclaimers on users is unknown: models sometimes provide harmful content with ethical caveats; whether such disclaimers reduce or inadvertently increase victim trust is untested.
- PII and privacy risks via integrated search are unassessed: the potential for models to surface or aggregate sensitive personal data during reconnaissance is not measured.
- Longitudinal model drift is unmeasured: assistance levels may change with model updates; a time-series evaluation protocol to track drift and regressions is missing.
- Cross-provider and regional policy variation is unexamined: differences in deployment policies, thresholds, and logging across providers or jurisdictions and their impact on misuse are not analyzed.
- Open-weight model landscape coverage is limited: few larger open models are included; ease-of-“uncensoring,” fine-tuning data needs, and accessibility for adversaries are not quantified.
- Dataset and rubric access constraints limit replication: with prompts and rubrics gated to verified researchers, external reproducibility and independent validation at scale are constrained.
- High-scoring outliers are under-analyzed: the small fraction of high-actionability responses is not characterized; systematic error analysis to identify patterns, root causes, and targeted mitigations is missing.
- Ethical and legal externalities are not modeled: the paper does not quantify downstream harm to victims or legal exposure for providers under differing safety configurations and regional laws.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s multi-turn, expert-validated evaluation framework, rubrics, and analysis workflow.
- Multi-turn AI red-teaming and safety evaluation
- Sector: software, AI platforms, cybersecurity
- Application: Adopt the paper’s Long-Form Tasks (LFTs) and 6-level rubrics (actionability and information access) to systematically audit models for fraud/cybercrime assistance across multi-stage scenarios.
- Potential tools/products/workflows: Test harness integrating Inspect (LLM-as-a-judge), Bayesian ordered logistic analysis dashboards, model comparison reports, guardrail regression tests in CI/CD.
- Assumptions/dependencies: Access to target models, secure handling of sensitive prompts, autograder reliability calibration, expert oversight for scenario realism.
- Conversation-level intent detection and guardrail tuning
- Sector: software, cybersecurity, customer-support platforms
- Application: Train classifiers to detect “benign framing” decomposition attacks and long-context intent shifts; tune refusal policies that consider multi-turn history rather than single prompts.
- Potential tools/products/workflows: Conversation-level risk scorers, decomposition-attack detectors, policy engines that score intent drift over threads, safety prompts libraries.
- Assumptions/dependencies: Representative training data from multi-turn interactions, privacy-preserving logging, latency constraints for real-time scoring.
- Vendor/model procurement risk assessment
- Sector: finance, healthcare, government, enterprise IT
- Application: Gate third-party LLMs with LFT-based risk scores before deployment; include “uncensored model” checks given their higher assistance rates.
- Potential tools/products/workflows: Procurement checklists, model scoring sheets, risk acceptance thresholds tied to rubric levels.
- Assumptions/dependencies: Transparent model access from vendors, standardization of evaluation scope, periodic re-testing after model updates.
- SOC and fraud operations playbooks
- Sector: finance, e-commerce, telecom, MSSPs
- Application: Prioritize monitoring for scam content that arrives via benign pretexts (e.g., “research” contexts); refine alert rules for multi-turn social engineering.
- Potential tools/products/workflows: Rulesets tuned to multi-stage engagement and evasion behaviors, analyst training modules aligned to the six-stage lifecycle.
- Assumptions/dependencies: Availability of telemetry and conversation context, minimization of false positives, legal and privacy compliance.
- Platform moderation for dating/messaging/collaboration apps
- Sector: social platforms, communications, HR tech
- Application: Detect and throttle romance scam and CEO-impersonation patterns that develop over long exchanges; incorporate lifecycle signals (falsification → engagement → evasion).
- Potential tools/products/workflows: Moderation heuristics and ML models keyed to multi-turn behaviors, proactive user warnings, “trust-building” pattern detectors.
- Assumptions/dependencies: Balanced moderation to avoid over-blocking legitimate content; user communication strategies; jurisdiction-specific policies.
- Law enforcement and policy training scenarios
- Sector: public safety, policy, regulatory bodies
- Application: Use validated multi-turn scenarios to train investigators and policy staff on AI-enabled fraud behaviors, especially benign decomposition tactics.
- Potential tools/products/workflows: Tabletop exercises, scenario packs for training academies, interagency briefings on observed assistance patterns.
- Assumptions/dependencies: Ethical safeguards, controlled access to sensitive materials, interagency data-sharing agreements.
- Compliance and audit checklists for AI governance
- Sector: policy/regulation, enterprise compliance
- Application: Require multi-turn, scenario-grounded safety evaluations (not single-turn tests) in audits and certifications; record rubric scores and refusal consistency.
- Potential tools/products/workflows: Audit templates, policy language mandating multi-turn tests, evidence repositories for certification.
- Assumptions/dependencies: Regulator capacity, standardization across jurisdictions, independent verification mechanisms.
- Academic replication and methodology adoption
- Sector: academia, research labs
- Application: Reproduce LFTs; extend Bayesian ordered logistic modeling; study reasoning token effects on assistance and refusal consistency.
- Potential tools/products/workflows: Open datasets (with controlled access), model effect-size studies, inter-lab benchmarks, LLM-as-a-judge reliability analyses.
- Assumptions/dependencies: Access to diverse models, IRB/ethics review for sensitive scenarios, alignment with responsible disclosure norms.
- Incident response and safety monitoring dashboards
- Sector: AI providers, platform ops, MLOps
- Application: Track model assistance metrics over time (post-update regressions), watch for drift in refusal rates, flag rising assistance in targeted scenarios.
- Potential tools/products/workflows: Safety telemetry dashboards, weekly regression reports, red-team feedback loops.
- Assumptions/dependencies: Logging infrastructure, safe storage of conversation context, change-management processes.
- User awareness and fraud-prevention materials
- Sector: daily life, consumer protection, banking
- Application: Educate users that sophisticated scams can be staged via benign pretexts; highlight typical multi-stage lifecycle patterns to recognize and report early.
- Potential tools/products/workflows: Bank/retail customer advisories, training videos, in-app warnings when patterns match known scam flows.
- Assumptions/dependencies: Clear, non-alarming messaging; cooperation with consumer protection agencies; localization for different markets.
- Benchmark integration and community evaluation
- Sector: research, standardization
- Application: Merge LFTs with existing benchmarks (e.g., HarmBench), improve coverage for social engineering across extended interactions.
- Potential tools/products/workflows: Shared evaluation suites, cross-benchmark scoreboards, community challenge tracks.
- Assumptions/dependencies: Benchmark governance, shared rubric updates, sustained community participation.
- Open-weight model governance and maintainer guidance
- Sector: open-source AI, model hubs
- Application: Encourage maintainers to run LFTs, publish safety notes; highlight elevated assistance from uncensored fine-tunes, propose lightweight guardrails.
- Potential tools/products/workflows: Maintainer safety badges, recommended refusal prompts, pre-release evaluation gates.
- Assumptions/dependencies: Community norms, volunteer capacity, incentives for safety transparency.
- Web-search baseline calibration projects
- Sector: academia, industry analytics
- Application: Run parallel human web-search baselines against LFTs to quantify “information access” gains versus standard search; refine rubrics accordingly.
- Potential tools/products/workflows: Human rater panels, side-by-side dashboards, rubric adjustments with empirical baselines.
- Assumptions/dependencies: Rater training and reliability, access to diverse search engines, context control.
Long-Term Applications
These applications require additional research, scaling, cross-institution coordination, multimodal capabilities, or policy development.
- Multimodal LFTs for voice, image, and video deepfake scams
- Sector: media platforms, cybersecurity, law enforcement
- Application: Extend the framework to assess non-text modalities (voice cloning, synthetic images/video) across the six-stage lifecycle.
- Potential tools/products/workflows: Multimodal autograders, cross-modal deception detectors, synthetic dataset generation pipelines.
- Assumptions/dependencies: Mature multimodal models, safe dataset curation, stronger responsible disclosure protocols.
- Standardized certification for multi-turn misuse resilience (ISO-style)
- Sector: policy/regulation, industry consortia
- Application: Create a formal standard requiring multi-turn, scenario-based safety evaluations with public attestation of rubric scores and update cadence.
- Potential tools/products/workflows: Certification schemes, accredited test labs, periodic re-certification procedures.
- Assumptions/dependencies: International consensus, funding for test facilities, harmonization with existing AI governance frameworks.
- Real-time conversation safety orchestration
- Sector: software/AI platforms
- Application: Deploy runtime intent scoring across active conversations, with adaptive guardrails and escalation to human review for high-risk multi-stage patterns.
- Potential tools/products/workflows: Safety orchestrators, streaming risk models, human-in-the-loop intervention consoles.
- Assumptions/dependencies: Privacy-by-design, low-latency inference, user consent and legal basis for monitoring.
- National or sectoral early-warning systems for AI misuse capability shifts
- Sector: policy, law enforcement, ISACs/ISAOs
- Application: Aggregate LFT scores across models and releases to detect rising assistance trends; issue advisories to critical sectors (finance, healthcare).
- Potential tools/products/workflows: Central risk registries, sector-specific advisories, data-sharing agreements.
- Assumptions/dependencies: Cross-organization data sharing, governance frameworks, secure telemetry pipelines.
- Safety-aware reasoning token controllers
- Sector: AI platforms, model research
- Application: Gate or reshape chain-of-thought and long-context reasoning when harmful intent is detected; modulate reasoning depth to reduce assistance.
- Potential tools/products/workflows: Safety token budgets, reasoning filters, intent-conditioned inference policies.
- Assumptions/dependencies: Access to model internals or APIs for reasoning control, robust intent detection, minimal capability degradation for benign tasks.
- Decomposition attack detection products
- Sector: cybersecurity, trust & safety
- Application: Commercial detectors that flag benign-phrased multi-turn requests mapping to known misuse lifecycles; integrate with enterprise AI gateways.
- Potential tools/products/workflows: Enterprise plugins, APIs for conversation risk scoring, policy packs for common scam verticals.
- Assumptions/dependencies: High-quality labeled corpora of multi-turn attack traces, generalization across domains, manageable false positive rates.
- Economic impact modeling linking assistance scores to fraud outcomes
- Sector: finance, insurance, policy
- Application: Quantify the relationship between rubric scores and expected loss, enabling cost-benefit analysis for guardrail investments and insurance underwriting.
- Potential tools/products/workflows: Actuarial models, loss forecasting tools, premium adjustment frameworks.
- Assumptions/dependencies: Access to incident/loss datasets, longitudinal studies, confounder control.
- Integrated human-in-the-loop model audits at scale
- Sector: enterprise, regulators
- Application: Combine autograders with human expert review for edge cases (especially information access) to improve reliability and calibrate thresholds.
- Potential tools/products/workflows: Audit platforms blending AI and expert panels, adjudication workflows, appeal and remediation processes.
- Assumptions/dependencies: Expert capacity, cost management, standardized reviewer training.
- Cross-domain LFT expansion (biosecurity, physical, energy)
- Sector: biosecurity, robotics, energy infrastructure
- Application: Adapt the framework to other high-risk domains with multi-stage misuse lifecycles (e.g., lab protocol manipulation).
- Potential tools/products/workflows: Domain-specific rubrics, expert-validated scenarios, restricted-access evaluation environments.
- Assumptions/dependencies: Specialized expert input, heightened responsible disclosure, strict access controls.
- Education and professional curricula
- Sector: academia, workforce development
- Application: Embed multi-turn misuse evaluation into AI safety courses and professional certifications for data scientists, product managers, and security engineers.
- Potential tools/products/workflows: Accredited course modules, case studies, lab exercises using LFTs.
- Assumptions/dependencies: Accreditation partnerships, instructor training, safe classroom materials.
- International benchmarks and shared repositories
- Sector: research consortia, standards bodies
- Application: Global repository of vetted multi-turn scenarios and metrics, enabling longitudinal and cross-model comparisons with common rubrics.
- Potential tools/products/workflows: Federated benchmark hubs, governance councils, periodic challenge evaluations.
- Assumptions/dependencies: International governance agreements, funding, secure access procedures.
- Safety regression testing for multi-tenant cloud AI
- Sector: cloud providers, MLOps
- Application: Add multi-turn safety suites to model update pipelines; block releases that regress in refusal consistency or assistance scores.
- Potential tools/products/workflows: Pre-deployment gates, automated report generators, rollback mechanisms.
- Assumptions/dependencies: Tight release engineering, customer communication for model behavior changes, SLA considerations.
- Personalized safety profiles for end-user assistants
- Sector: consumer software, smartphones
- Application: Calibrate guardrails and intent detection to user contexts while preserving robust refusal to harmful multi-turn requests.
- Potential tools/products/workflows: Safety preference managers, contextual risk models, adaptive refusal messaging.
- Assumptions/dependencies: Privacy and fairness safeguards, avoidance of safety dilution, on-device inference constraints.
- Forensic tooling for multi-turn misuse attribution
- Sector: law enforcement, digital forensics
- Application: Reconstruct conversation histories to attribute intent and assistance, supporting investigations of AI-aided fraud.
- Potential tools/products/workflows: Secure conversation audit trails, chain-of-custody tools, evidentiary rubrics aligned to lifecycle stages.
- Assumptions/dependencies: Legal authority for logging, tamper-evident storage, standardized evidentiary protocols.
Glossary
- Actionability: A rubric dimension assessing whether outputs are immediately usable for attacks. "actionability (whether models generate immediately usable attack materials)"
- Adversarial prompts: Deliberately crafted inputs intended to subvert safety mechanisms. "defends against explicit adversarial prompts."
- Autograder: An automated grading model used to score outputs against a rubric. "we selected GPT-4.1 as our autograder."
- Bayesian ordered logistic regressions: Statistical models for ordinal outcomes with Bayesian inference. "We analysed the resulting grades using Bayesian ordered logistic regressions on the evaluation runs"
- Benign decomposition: A prompting strategy that splits tasks into innocuous-seeming parts to elicit help. "Benign decomposition increased assistance compared to explicitly malicious framing."
- Benign framing: Presenting a harmful task as legitimate to bypass refusals. "Benign framing. Prompts use legitimate-sounding language obfuscating malicious intent"
- CEO fraud: A scam involving impersonation of executives to induce transfers or data disclosure. "CEO fraud causes average losses over \textsterling10,000"
- Ceiling effect: A measurement limitation where scores cluster at the top, obscuring differences. "We observed a ceiling effect with very few responses scoring five or higher"
- Chain-of-thought logs: Free-form reasoning traces produced by models during step-by-step thinking. "Manual analysis of a sample of chain-of-thought logs provides illustrative examples"
- Collaborative technical operators: Organised groups with specialised roles conducting technically sophisticated attacks. "Collaborative technical operators: An organised group that may include specialised roles."
- Credible interval (CrI): A Bayesian interval quantifying uncertainty about a parameter. "88.5\% (94\% credible interval: [88.3\%, 88.7\%])"
- Decomposition attack: A method of evading refusals by breaking a harmful task into smaller benign requests. "We used a decomposition attack to create the prompts."
- Evasion: Post-attack tactics to avoid detection and persist. "Evasion. Adapting tactics to avoid detection, such as analysing triggers for alerts, modifying behaviours to appear legitimate, and evolving methods based on previous attempts to enable sustained operations."
- Falsification: Creating fake identities, artifacts, or impersonations to deceive. "Falsification. Impersonating a trusted individual or organisation, websites, social media profiles, or documentation."
- Information access: A rubric dimension for how effectively a model aggregates relevant information beyond basic search. "Information access. Whether the model aggregates information more efficiently than baseline web search, calibrated by judgments from operational experts."
- Information synthesis: The aggregation of relevant information into a cohesive, useful form. "information synthesis (the degree to which responses aggregate relevant information beyond standard web search)"
- Integrated web search: Built-in capability for models to query the internet beyond training data. "Integrated web search capabilities allow models to query the Internet for information beyond their training cut-off date."
- Jailbreaking: Techniques to bypass a model’s safety controls. "Jailbreaking techniques that involve decomposing queries into multiple seemingly benign inputs increase compliance."
- Long-form tasks (LFTs): Multi-step, realistic task sequences for evaluation of complex capabilities. "creating to our knowledge the first set of criminal long-form tasks (LFTs) for AI safety evaluation."
- Long-term planning: The ability to plan and execute multi-step strategies over time. "Advanced reasoning facilitates long-term planning, or the ability to execute multiple steps over extended periods"
- LLM-as-a-judge: Using an LLM to evaluate other model outputs according to a rubric. "We used an LLM-as-a-judge to automatically grade (autograde) the responses using the Inspect framework"
- Malicious framing: Explicitly stating harmful intent in prompts. "Malicious framing. Prompts explicitly state harmful intent"
- Misuse lifecycle: The end-to-end sequence of stages in which AI could facilitate wrongdoing. "mapped to each stage of the misuse lifecycle"
- Multi-turn evaluations: Assessments spanning multiple successive prompts to reflect realistic interactions. "LFTs are multi-turn evaluations comprising successive queries that mirror real-world attack pipelines."
- Open-weight LLMs: Models with publicly available weights that can be fine-tuned or modified. "open-weight LLMs fine-tuned to remove safety guardrails provided substantially more help"
- Reasoning token: A quantitative indicator for the amount of explicit reasoning used by a model in an output. "including reasoning token as a continuous predictor alongside model choice"
- Reconnaissance: Information-gathering to identify targets and vulnerabilities. "Intelligence gathering and reconnaissance. Gathering information about targets to identify vulnerabilities."
- Safety alignment: Training and tuning aimed at ensuring models avoid harmful outputs. "Safety alignment determines response quality."
- Safety guardrails: Protective constraints that prevent models from assisting with harmful tasks. "fine-tuned to remove safety guardrails"
- Scaling: Expanding an attack to reach more targets or channels. "Scaling. Using multiple attack vectors to reach more potential targets (e.g. social media)"
- Search-enabled variant: A model version equipped with integrated internet search capabilities. "the search-enabled variant (o4-mini-deep-research) produced lower predicted scores"
- System-level jailbreaks: Attempts to override safety via system or meta-level instructions. "explicitly malicious framing or system-level jailbreaks."
- Threat actors: Individuals or groups conducting or attempting malicious activities. "test how AI might assist different threat actors across the lifecycle."
- Uncensored models: Models fine-tuned to reduce or remove safety constraints. "uncensored models showed higher rates of providing meaningful assistance"
- Web search baseline: A comparison point using conventional internet search to judge added value. "relative to a standard web search baseline."
Collections
Sign up for free to add this paper to one or more collections.