Learning in the Null Space: Small Singular Values for Continual Learning
Published 25 Feb 2026 in cs.LG and cs.CV | (2602.21919v1)
Abstract: Alleviating catastrophic forgetting while enabling further learning is a primary challenge in continual learning (CL). Orthogonal-based training methods have gained attention for their efficiency and strong theoretical properties, and many existing approaches enforce orthogonality through gradient projection. In this paper, we revisit orthogonality and exploit the fact that small singular values correspond to directions that are nearly orthogonal to the input space of previous tasks. Building on this principle, we introduce NESS (Null-space Estimated from Small Singular values), a CL method that applies orthogonality directly in the weight space rather than through gradient manipulation. Specifically, NESS constructs an approximate null space using the smallest singular values of each layer's input representation and parameterizes task-specific updates via a compact low-rank adaptation (LoRA-style) formulation constrained to this subspace. The subspace basis is fixed to preserve the null-space constraint, and only a single trainable matrix is learned for each task. This design ensures that the resulting updates remain approximately in the null space of previous inputs while enabling adaptation to new tasks. Our theoretical analysis and experiments on three benchmark datasets demonstrate competitive performance, low forgetting, and stable accuracy across tasks, highlighting the role of small singular values in continual learning. The code is available at https://github.com/pacman-ctm/NESS.
The paper introduces NESS that directly parameterizes the null space to restrict updates and minimize interference from previous tasks.
It computes the SVD of prior task data to freeze nearly orthogonal directions, ensuring stable adaptation and preservation of learned knowledge.
Empirical results on benchmarks demonstrate competitive accuracy and positive backward transfer while using far fewer parameters.
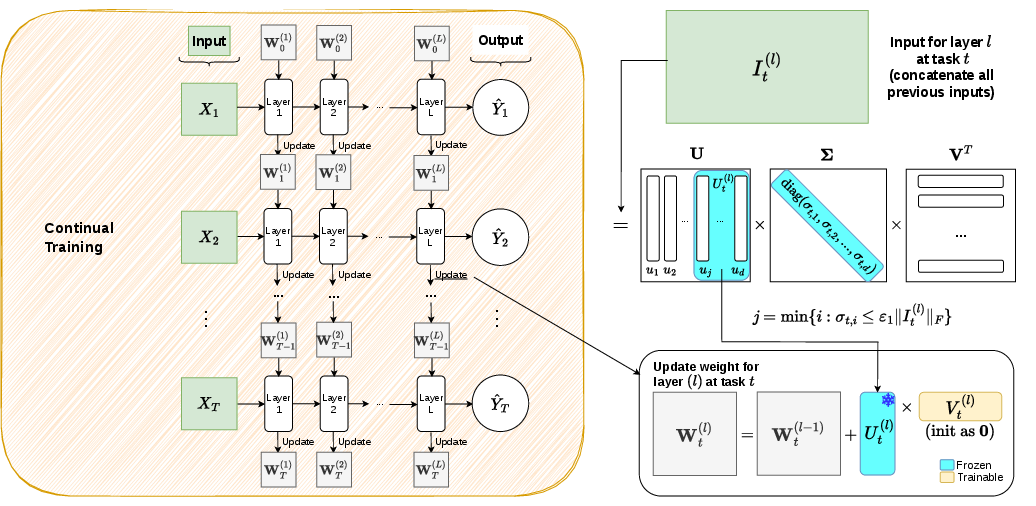
Direct Parameterization of Orthogonal Subspaces for Continual Learning: NESS
Background and Motivation
Catastrophic forgetting delineates the core obstacle in continual learning (CL), where sequential task updates compromise retention by erasing knowledge encoded from prior tasks. Traditional strategies addressing this challenge span memory-based replay, architecture-based expansion, regularization approaches, and subspace/orthogonality-based methods. Among these, enforcing update orthogonality—often via gradient projection into the null space of prior task input subspaces—has demonstrated robust theoretical and empirical properties.
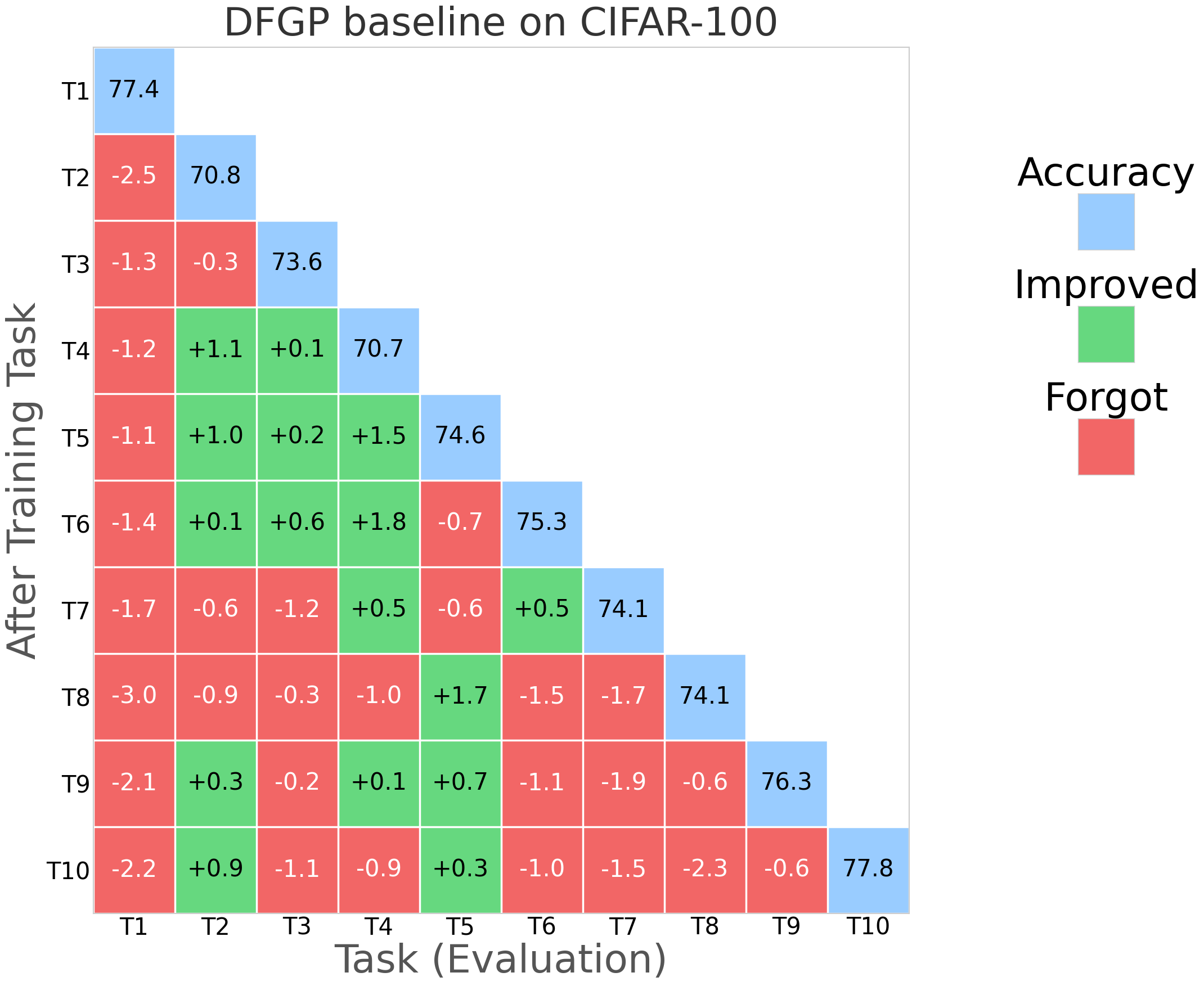
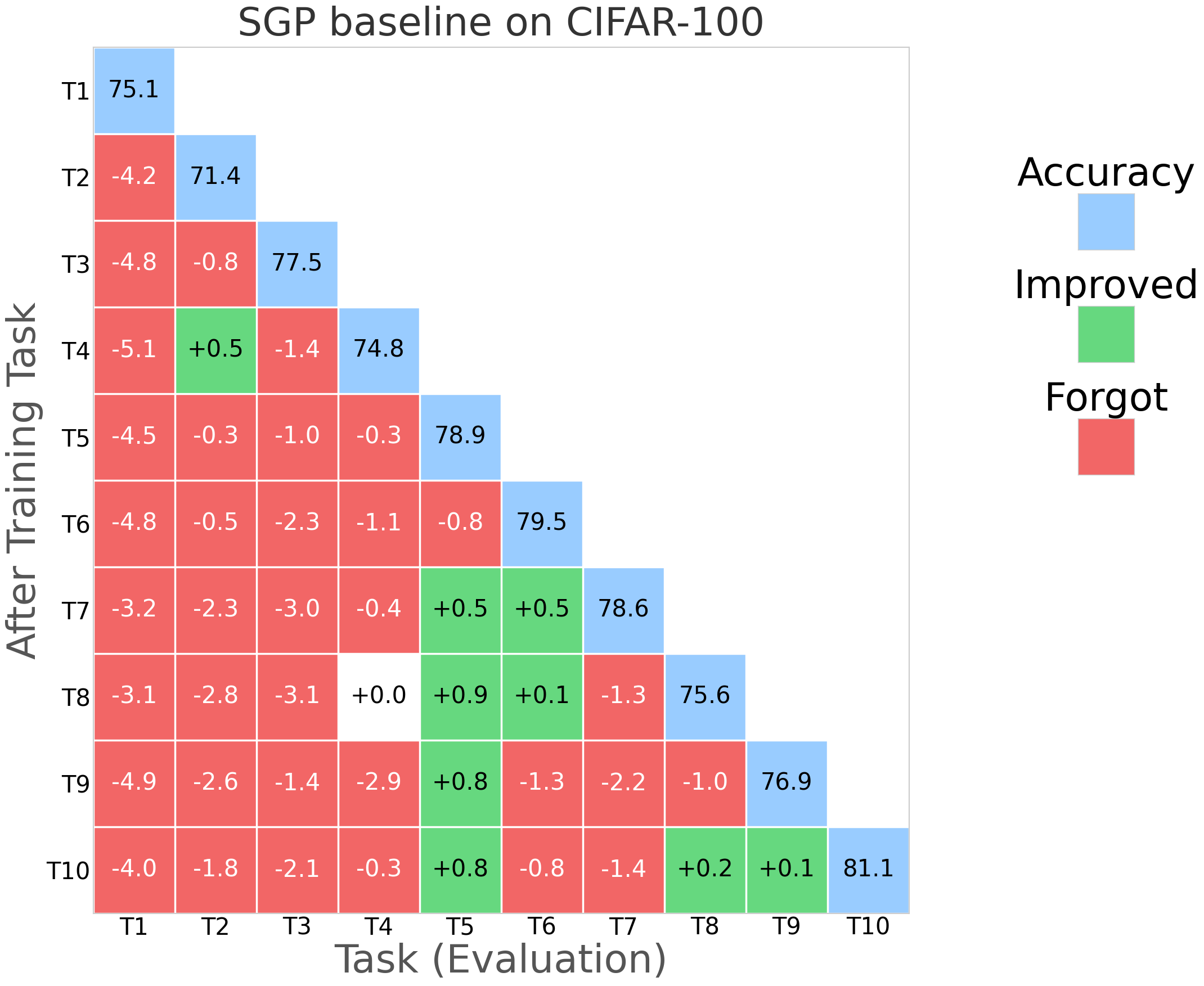
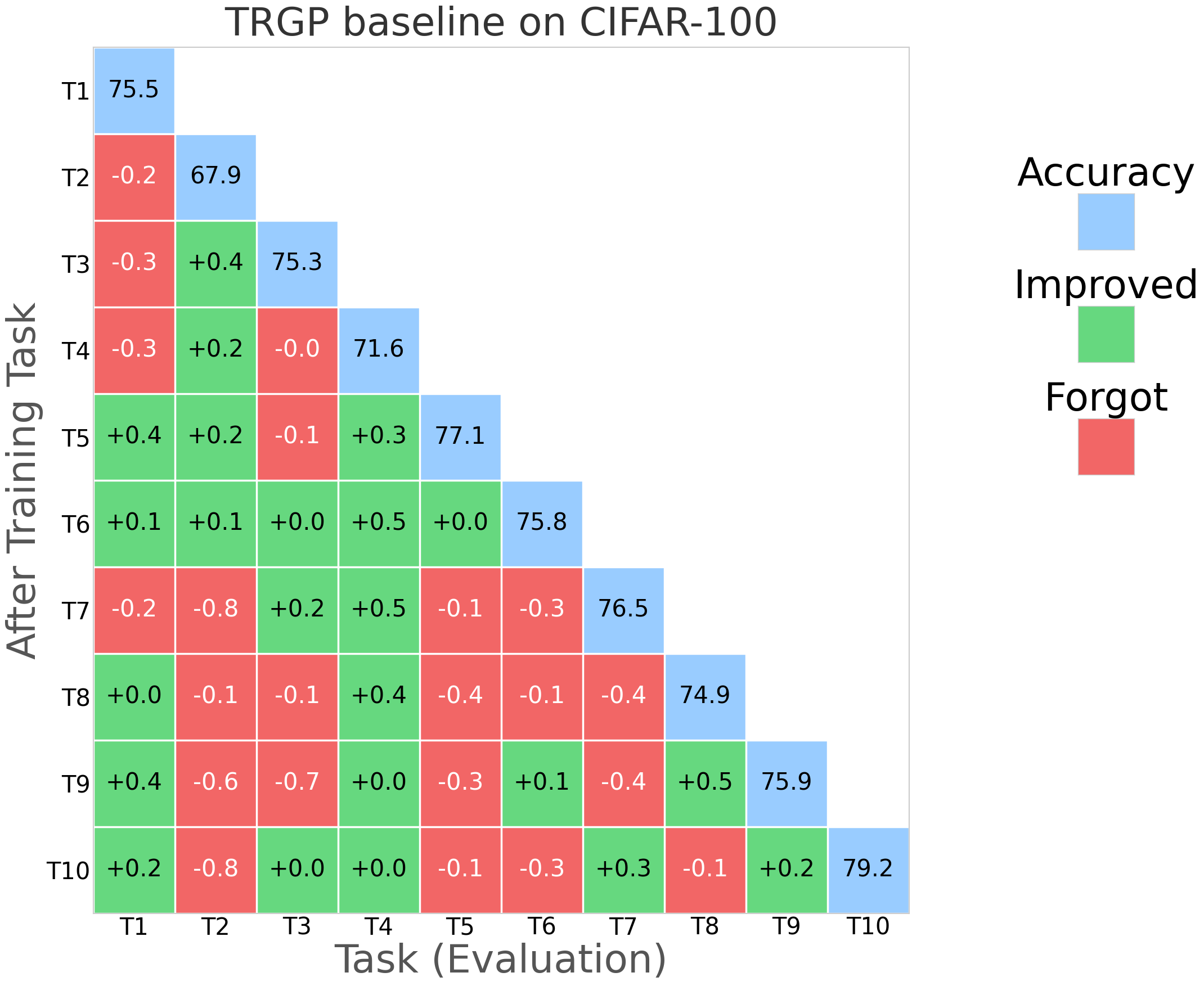
While gradient projection methods (e.g., GPM, SGP, TRGP, DFGP) frame the update as an optimization constraint, they typically require repeated SVDs, subspace tracking, and explicit gradient manipulation, which can be computationally intensive and sensitive to optimizer choices. The paper "Learning in the Null Space: Small Singular Values for Continual Learning" (2602.21919) proposes a paradigm shift: imposing the orthogonality constraint directly at the parameterization level rather than through gradient adjustment, thereby ensuring stability by construction.
NESS: Null-space Estimated from Small Singular Values
NESS operationalizes the insight that directions associated with small singular values in the input covariance correspond to nearly orthogonal directions for prior tasks, forming an approximate null space. By restricting parameter updates to this subspace, interference with earlier learned representations is minimized.
Concretely, for each layer and new task, NESS (Null-space Estimated from Small Singular values):
Collects previous task inputs for the layer, concatenates them, and computes the SVD of their covariance matrix.
Identifies the basis vectors associated with small singular values (below threshold ε1) and freezes them as the orthogonal basis Ut.
Parameterizes the update as ΔWt=UtVt, where Vt is the only trainable matrix per layer for the new task.
Enforces bounded norm constraints on Vt via weight decay, which guarantees low perturbation on outputs for previous task data.
This scheme ensures all updates lie in the approximate null space of prior inputs, trivially satisfying the orthogonality constraint without further optimization manipulation or subspace tracking during training.
Figure 1: Overview of NESS: sequential task updates generate frozen bases from SVD on previous inputs, restricting updates to the null-space via low-rank decomposition.
By construction, NESS is amenable to modern low-rank adaptation style implementations (cf. LoRA), compatible with a variety of optimizers and efficient in terms of both parameter count and memory usage, as it only maintains dynamic trainable adapters in each layer.
Theoretical Guarantees
The paper formalizes NESS with explicit output preservation bounds: for each previous input x, the output perturbation ∥x⊤ΔWt∥2 is upper-bounded as a function of the threshold ε1 and the norm of Vt. Satisfying ∥Vt∥2≤ε/(ε1∥It∥F) ensures the per-input output deviation is strictly controlled, providing inherent stability guarantees for CL.
This parameterization achieves the stability-plasticity trade-off via controllable selection of null-space dimension (determined by ε1), balancing the model's ability to adapt to new tasks while retaining prior knowledge. The approach also avoids computational overhead associated with full SVDs or explicit projection operations; the covariance and its eigen-decomposition suffice.
Empirical Evaluation and Numerical Results
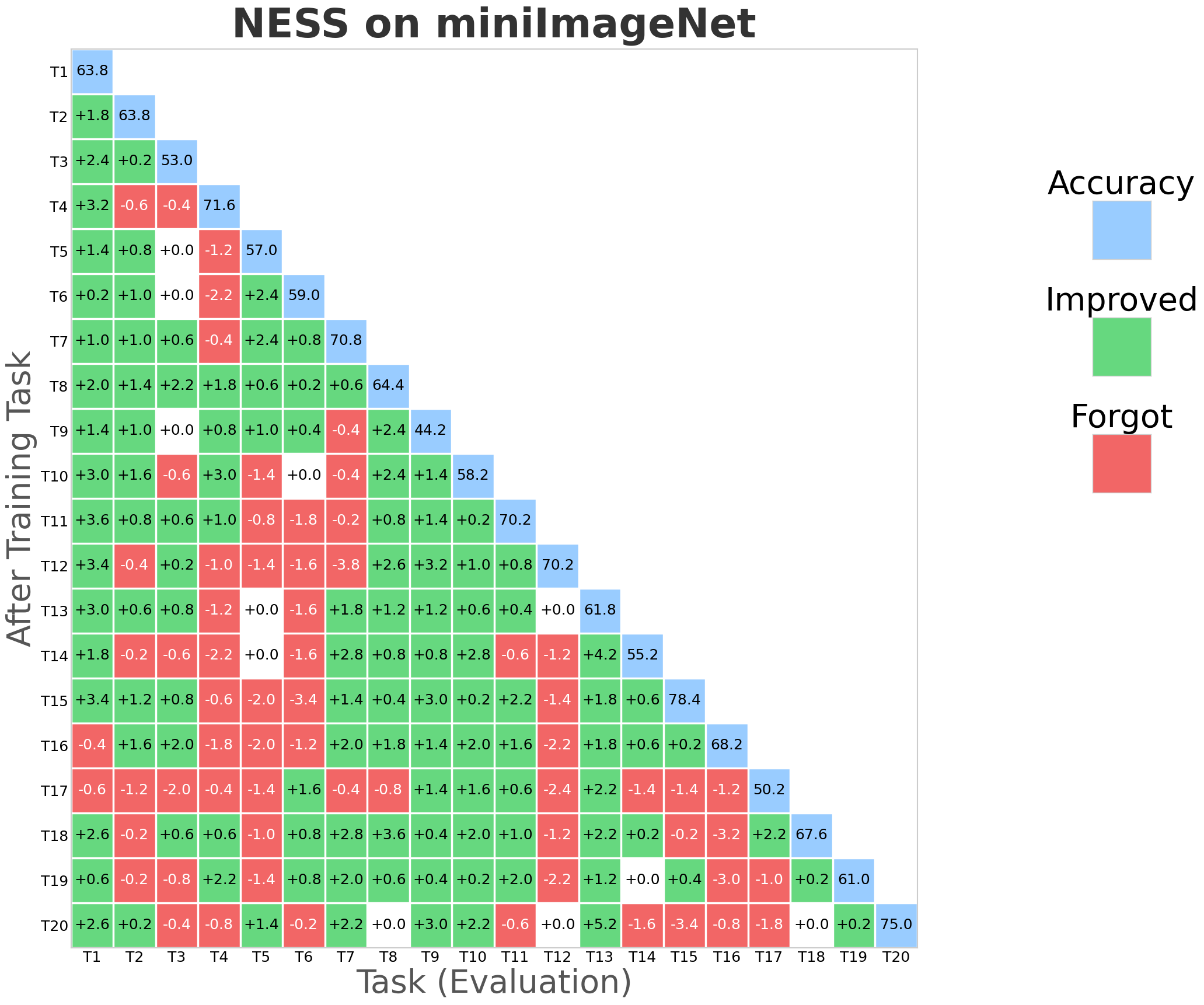
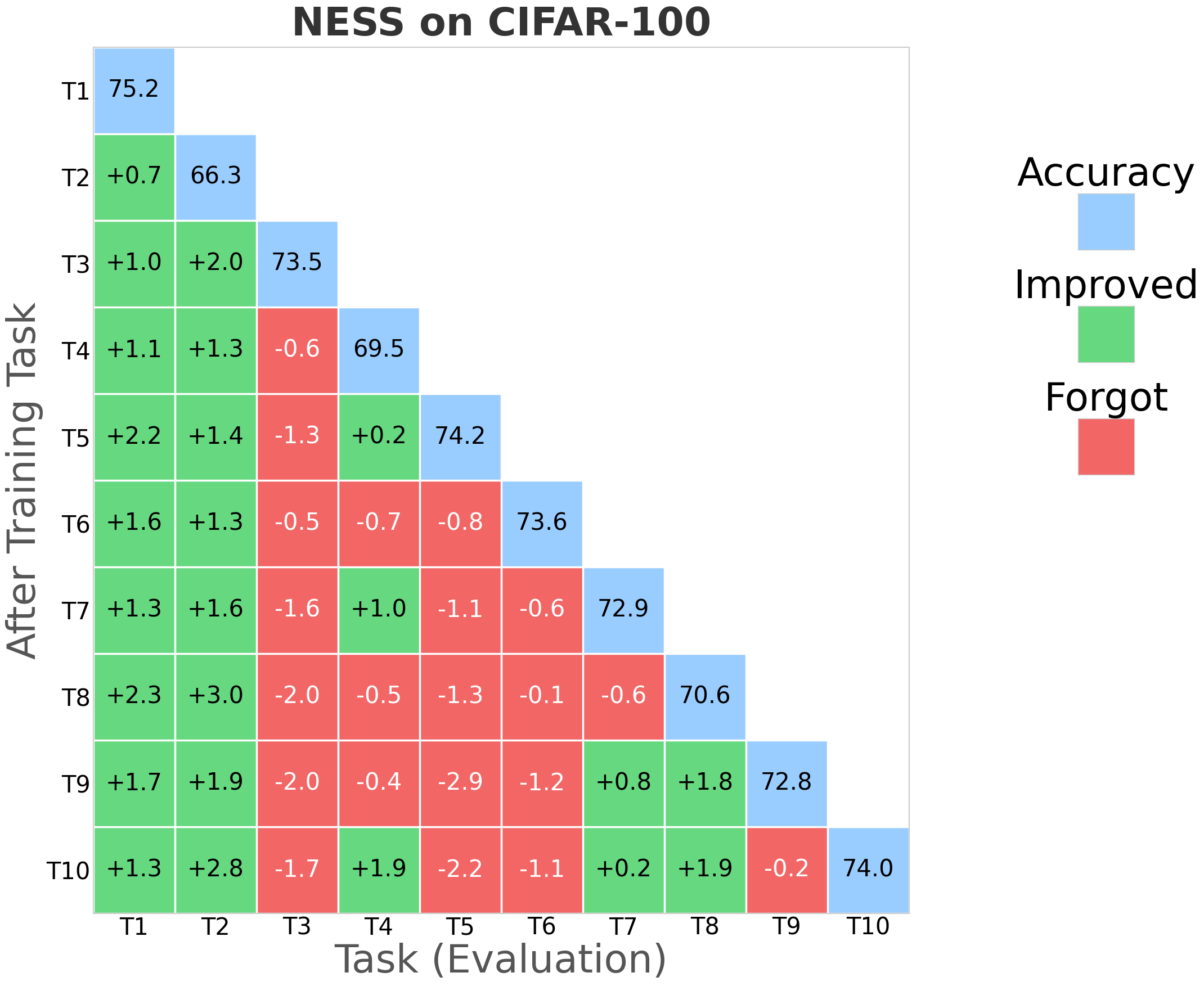
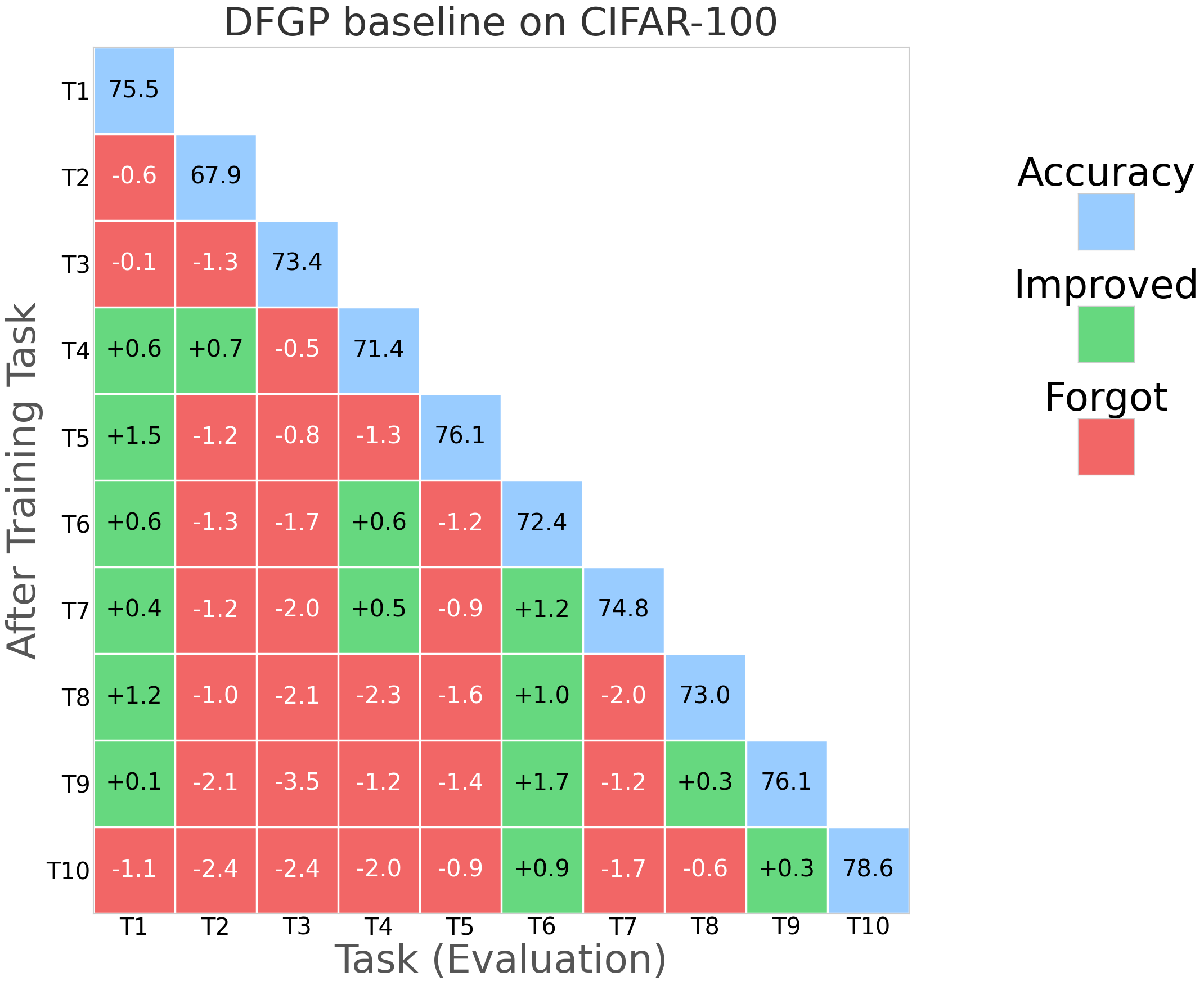
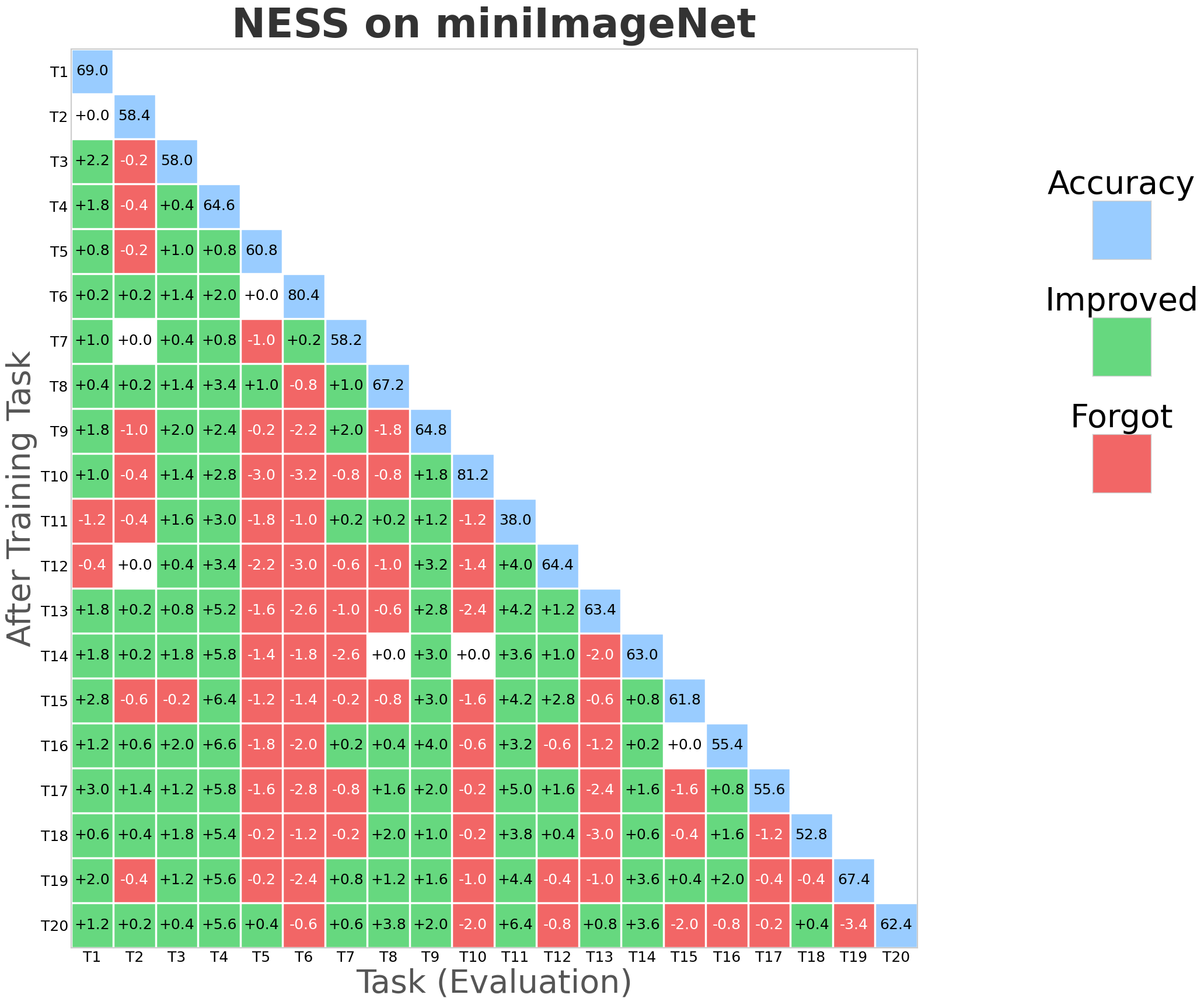
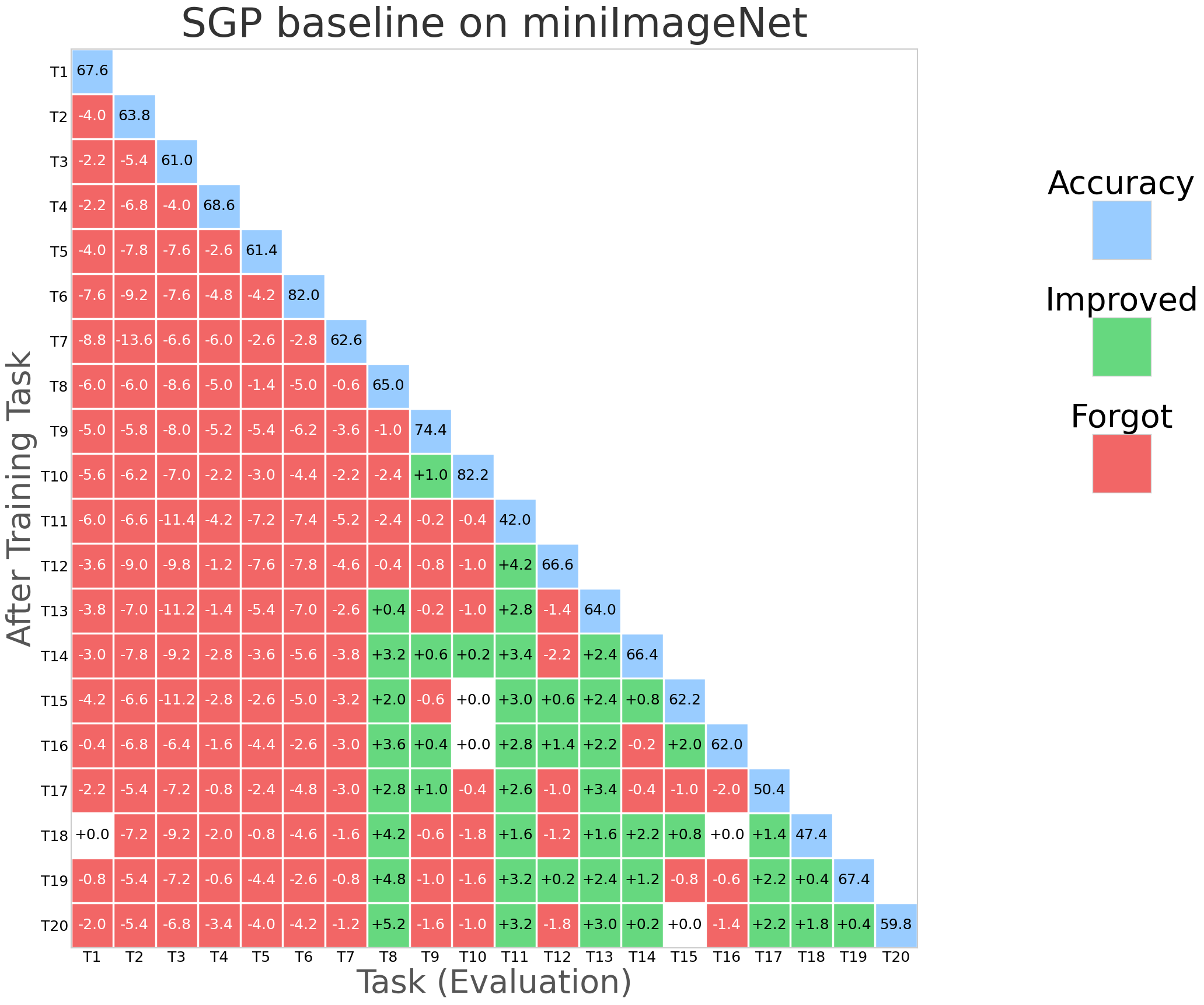
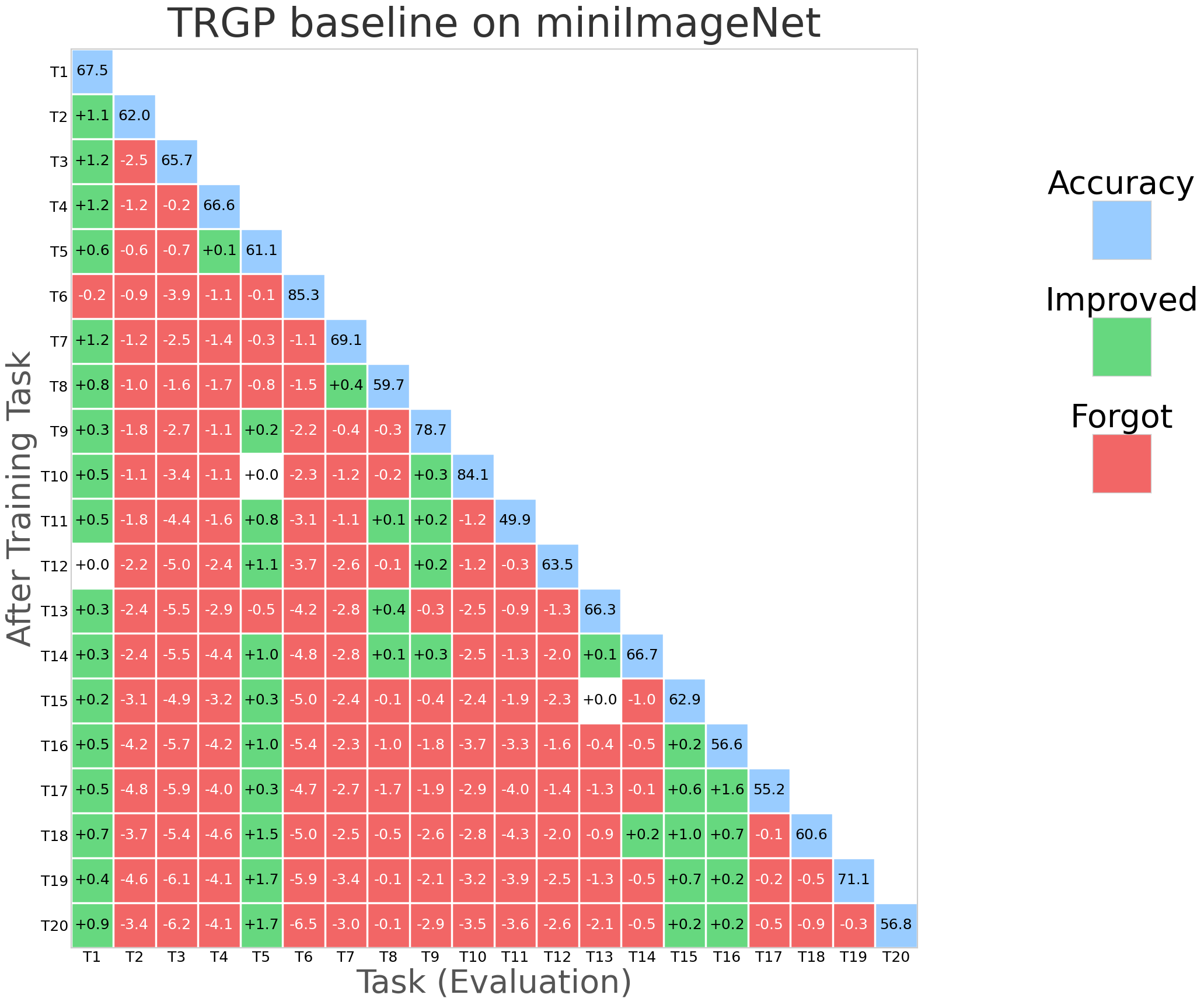
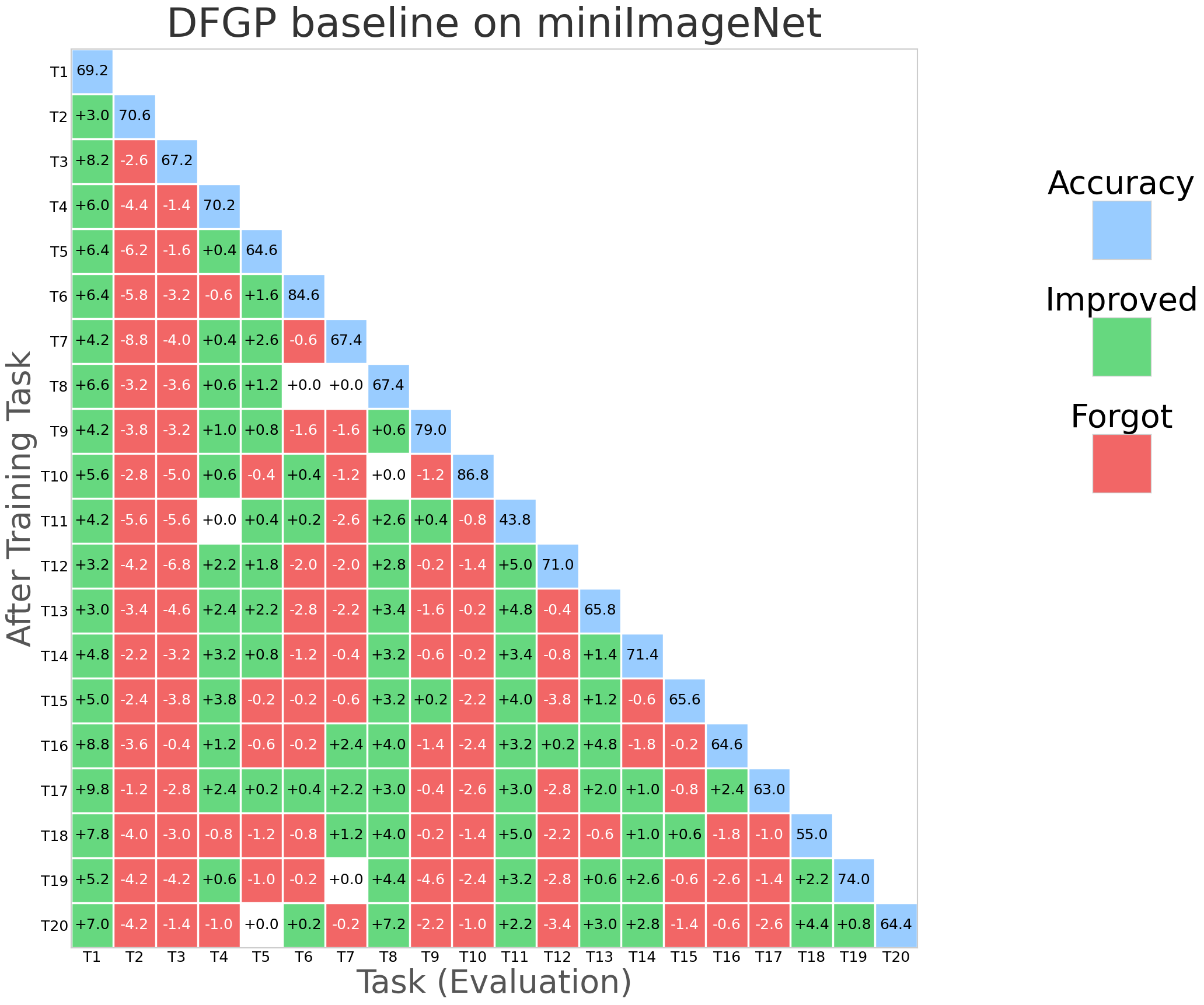
NESS was evaluated on standard CL benchmarks: CIFAR-100 (10 tasks), 5-datasets (5 tasks), and MiniImageNet (20 tasks), using appropriate network architectures (AlexNet, Reduced ResNet18). Evaluation metrics primarily include Average Accuracy (ACC) and Backward Transfer (BWT), the latter measuring the degree of forgetting.
Key findings:
NESS attains the best or comparable BWT relative to strong orthogonal-based baselines (TRGP, DFGP) across all datasets, frequently achieving positive BWT (indicative of performance improvement on prior tasks after learning new tasks).
Average accuracy remains competitive, with negligible drop relative to the highest-performing models.
Parameter efficiency: NESS's trainable adapter per layer is much smaller than the full weight matrix, with parameter count proportional to null-space dimension; selecting a lower threshold yields further reduction.
Optimizer robustness: Performance is stable across optimizers (SAM, SGDm), and always yields BWT above -1%, outperforming all baselines that exhibit negative BWT in at least some settings.
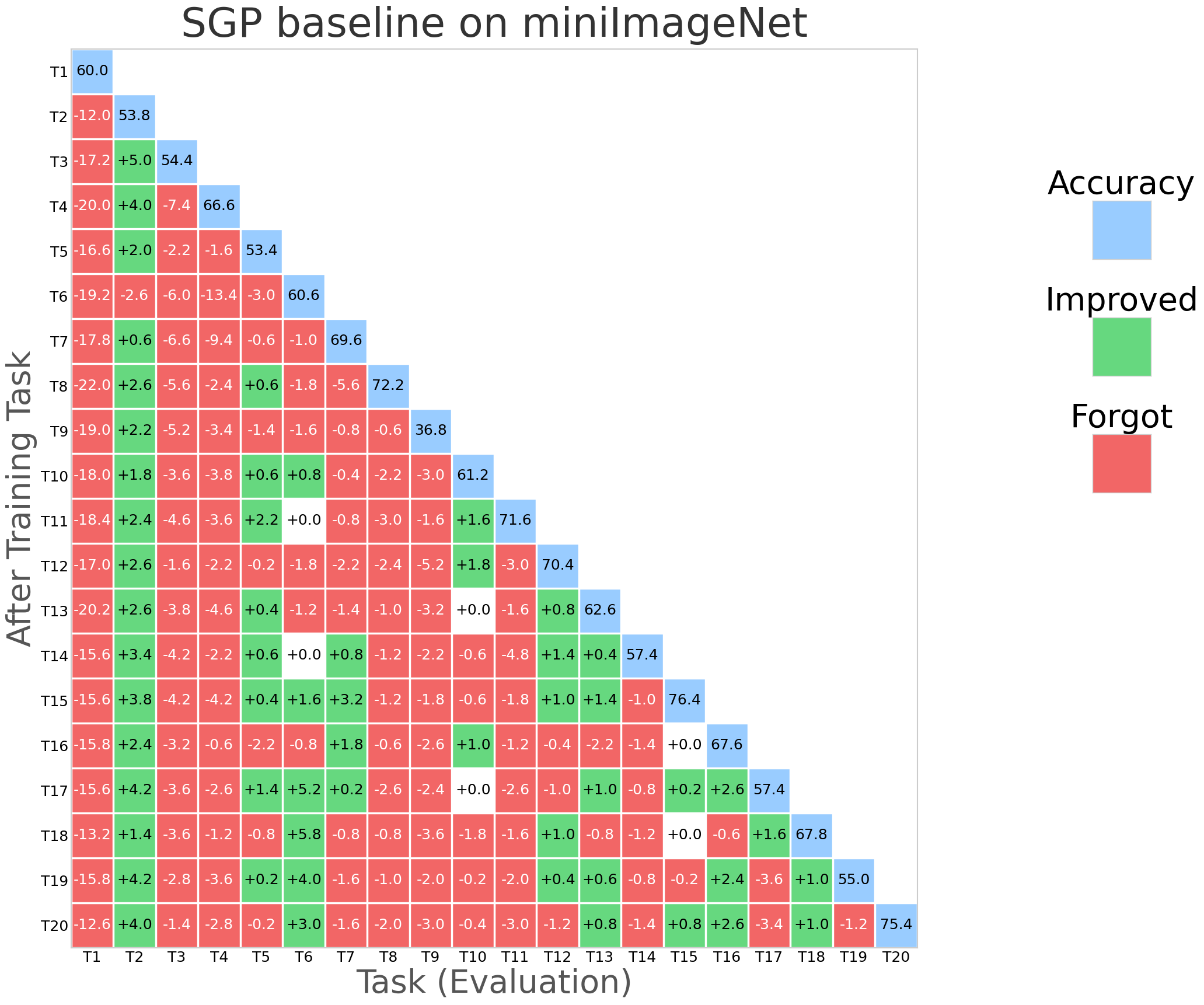
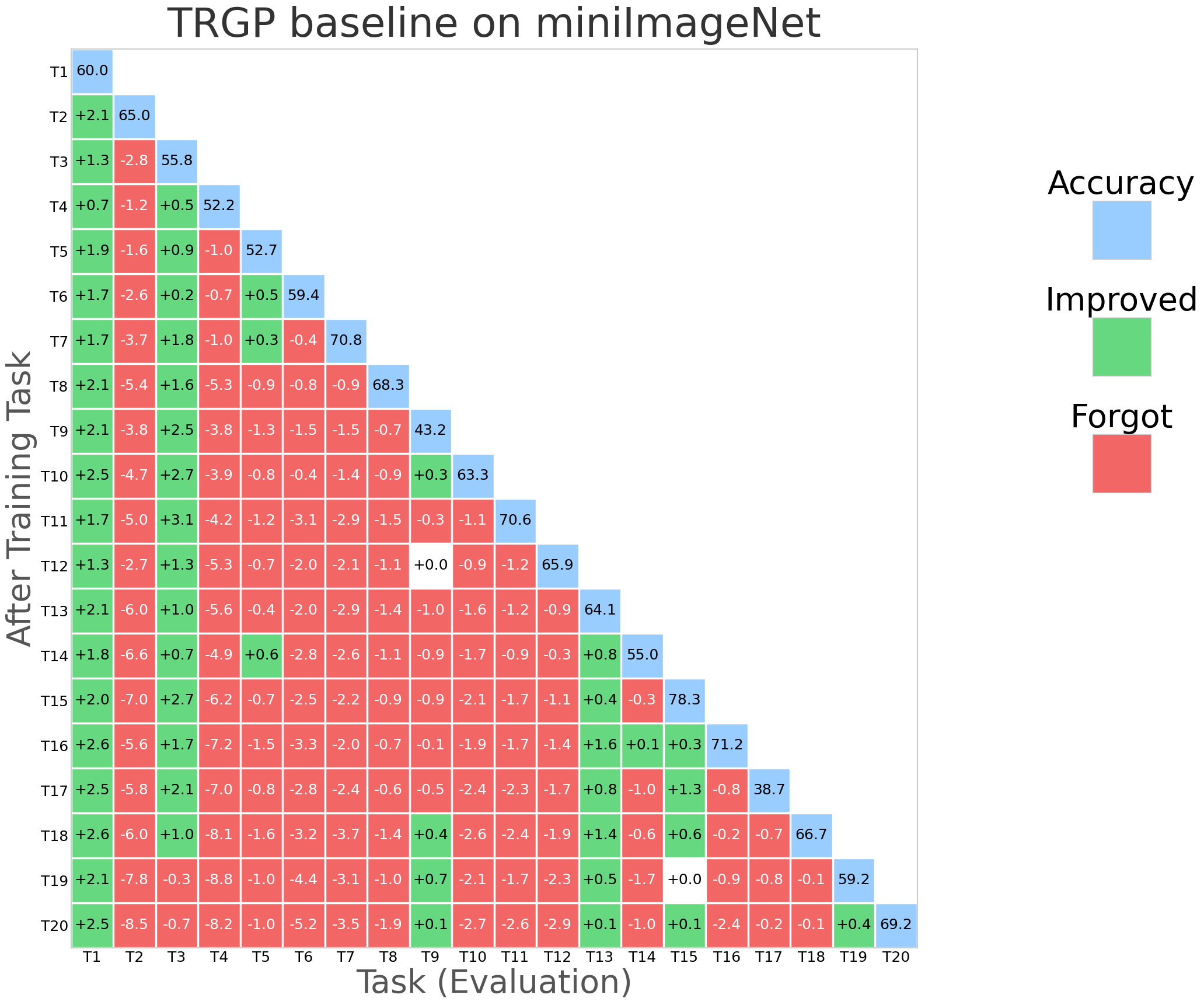
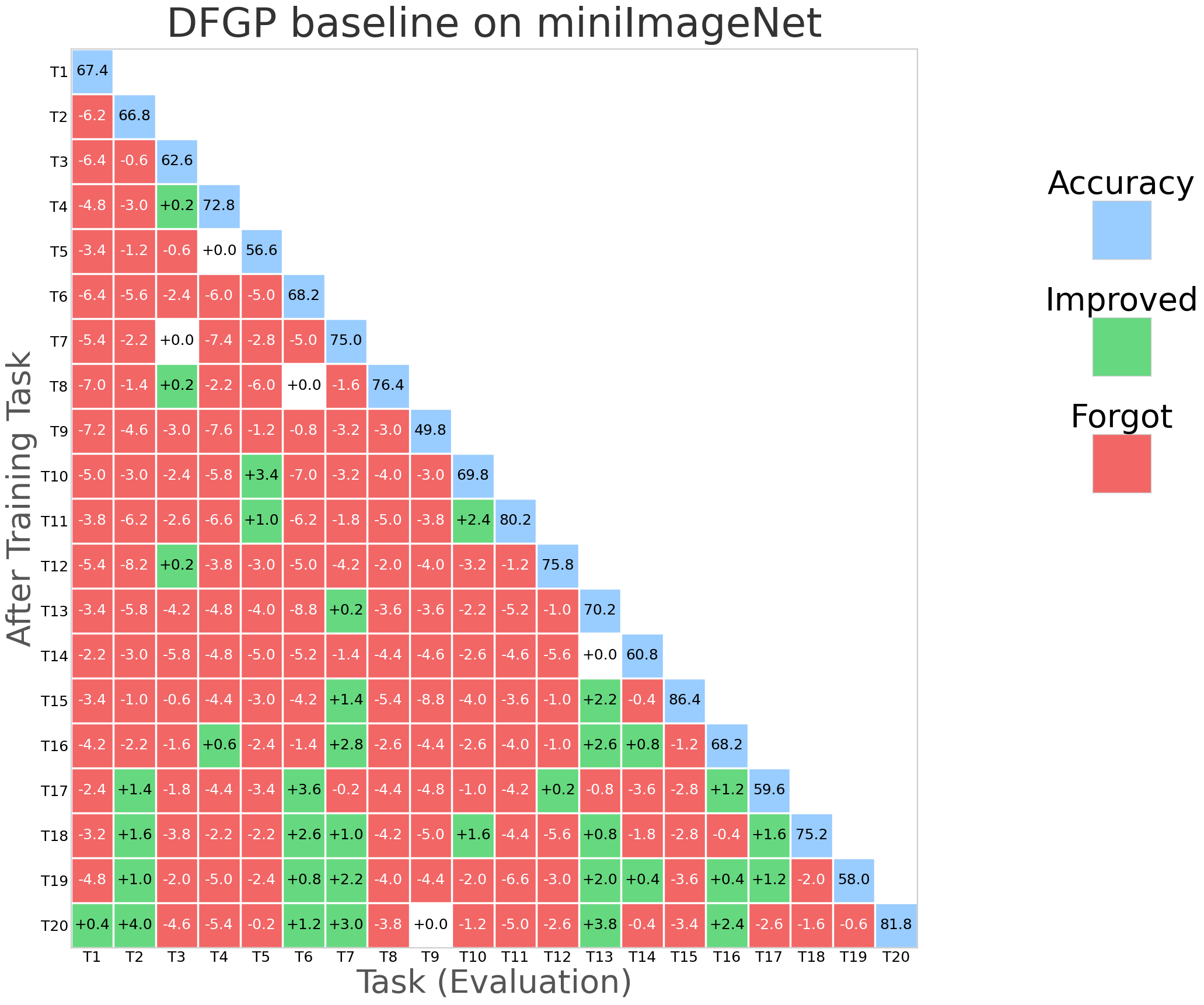
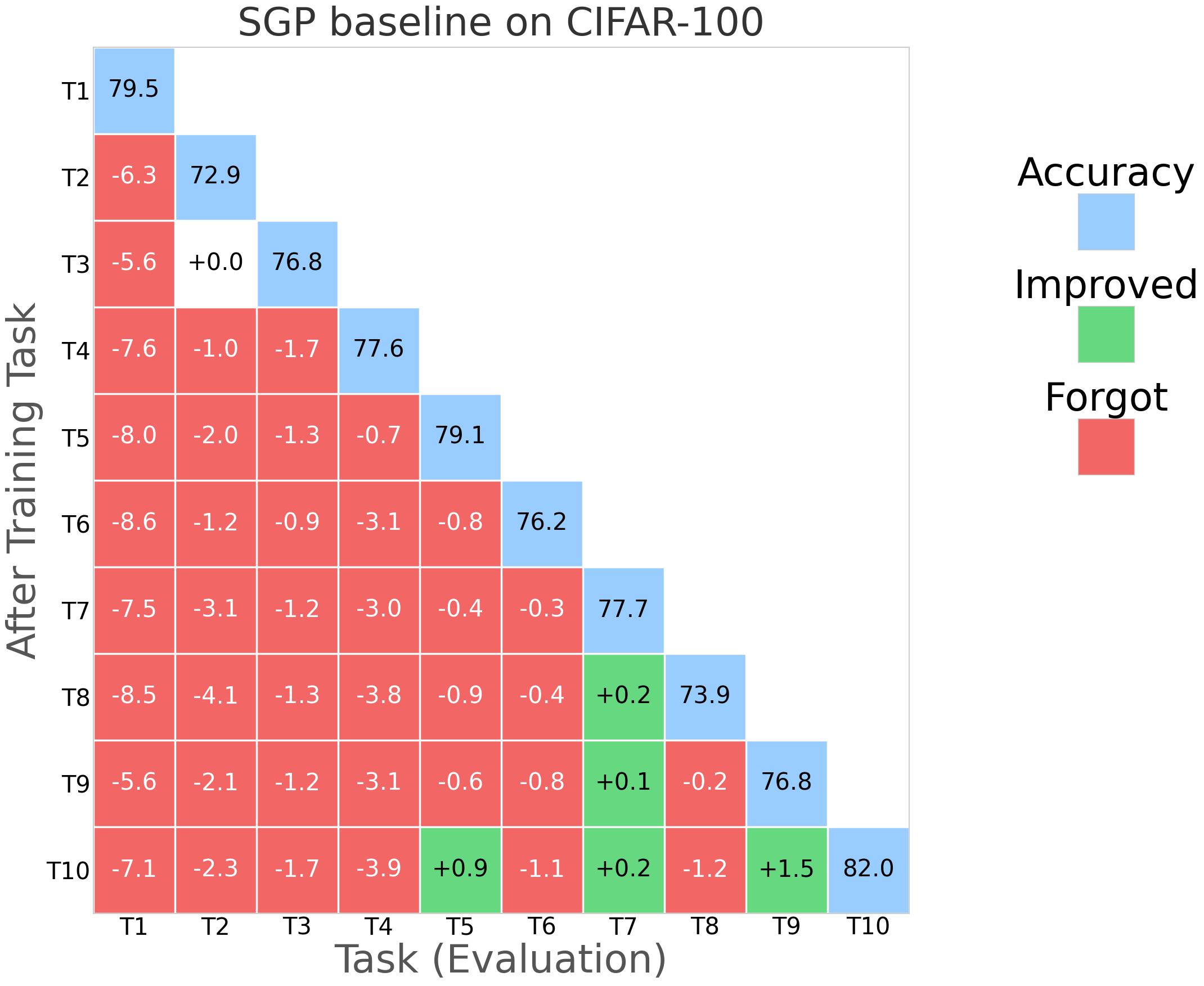
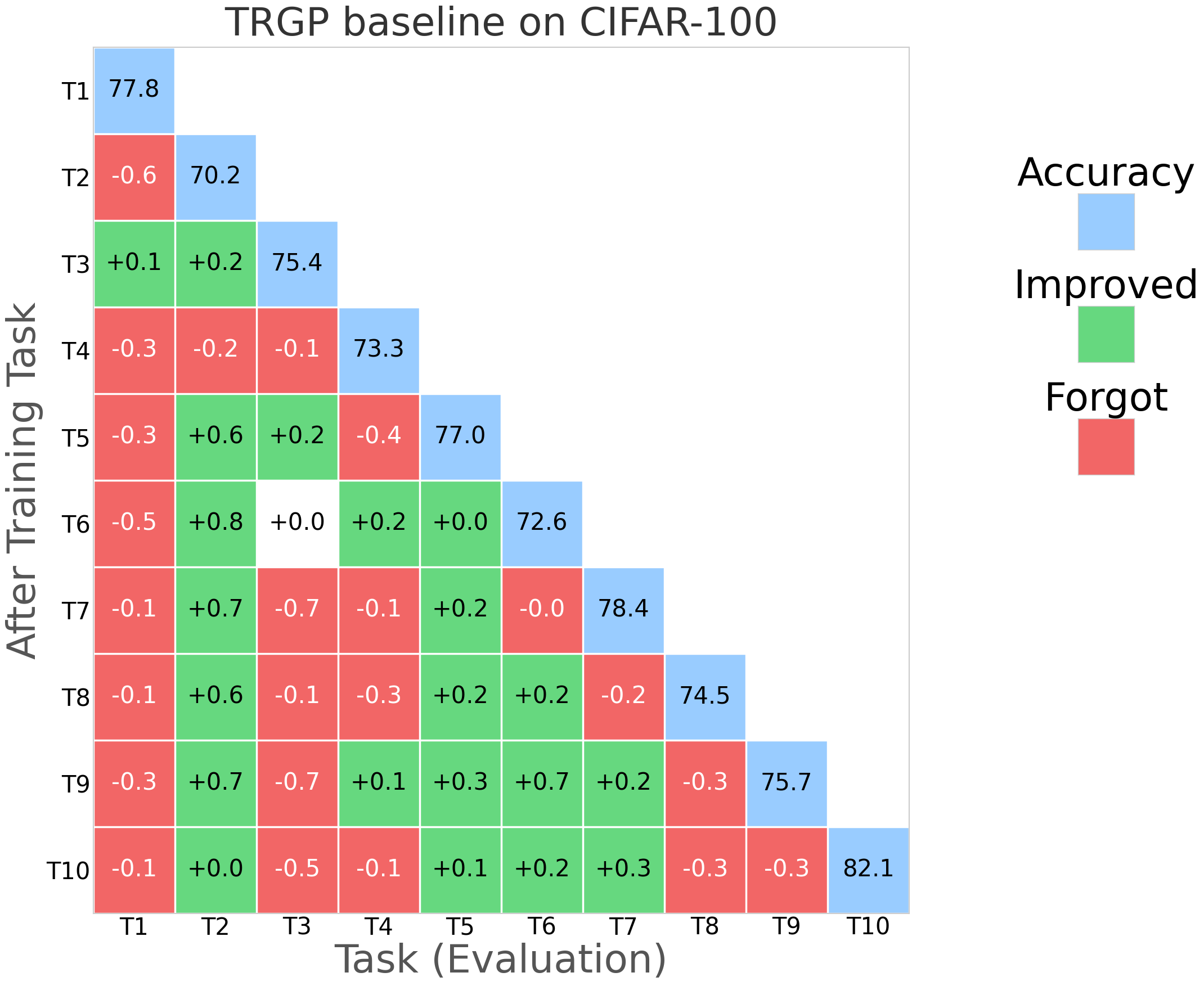
Figure 2: NESS performance (forgetting rate and task stability) compared with SGP, TRGP, and DFGP baselines on miniImageNet.
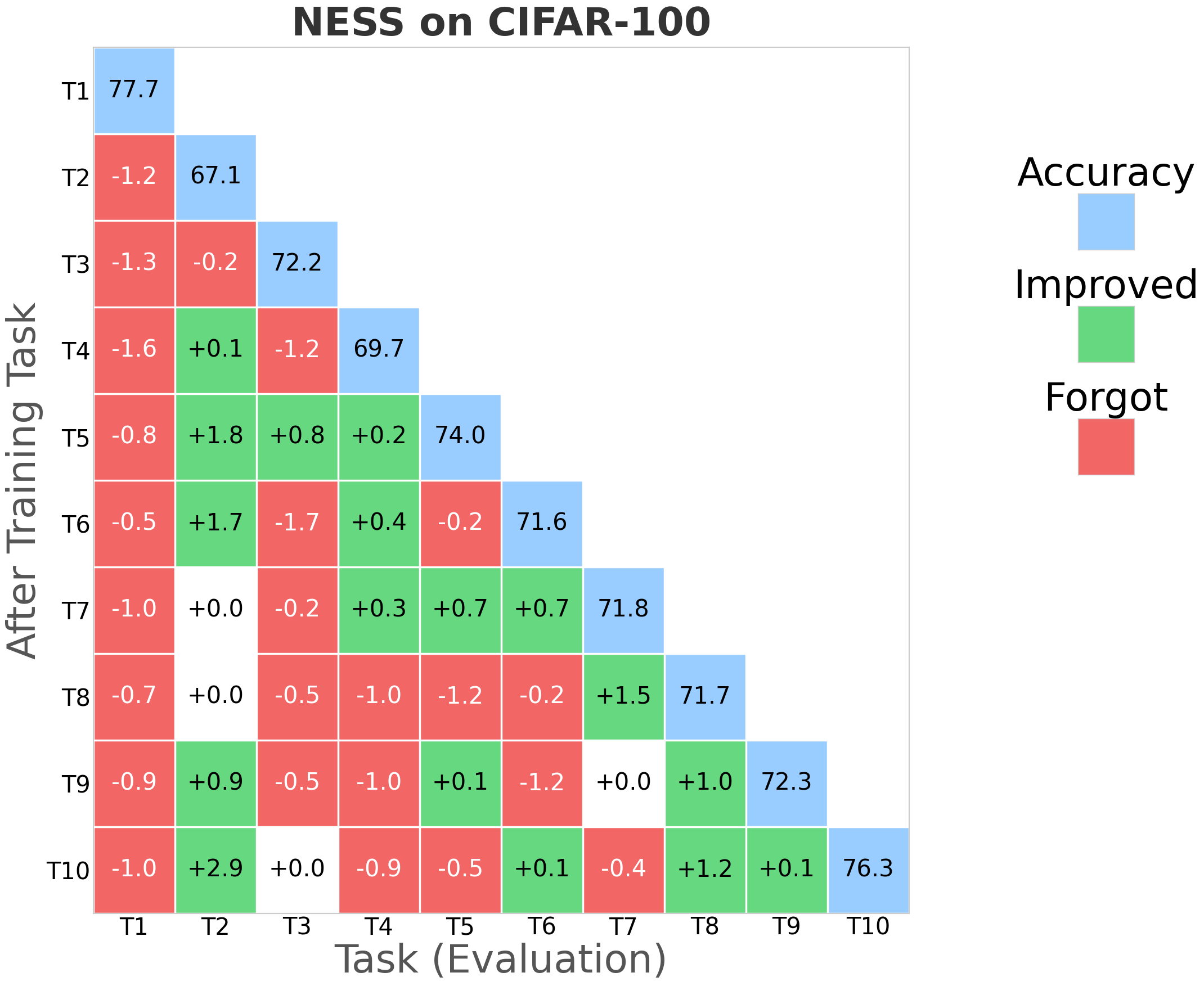
Figure 3: NESS performance (forgetting rate) across CIFAR-100 for multiple random seeds; green indicates improving task accuracy, red denotes loss.
Figure 4: Adapter size and relative efficiency of NESS; trainable parameters are substantially reduced compared to unconstrained continual adaptation.
Practical and Theoretical Implications
The direct null-space parameterization eliminates the need for complex subspace tracking or episodic memory, offering a plug-and-play orthogonality constraint compatible with diverse architectures. The technique is especially synergistic with parameter-efficient adaptation frameworks (e.g., LoRA, HiRA, Butterfly factorization), suggesting efficient continual adaptation for large-scale models.
Further, the stability guarantee enables robust deployment in scenarios where task boundaries are unclear or access to prior inputs is limited (though constructing the null-space basis currently requires at least a single pass over prior data).
Potential future directions:
Threshold tuning: Selecting ε1 dynamically per layer or task may optimize the adaptation-stability tradeoff.
Extension to other layer types: Applying NESS to biases and normalization layers may increase model expressivity.
Memory-free continual learning: Investigating null-space basis construction with limited access or statistical summaries of prior data.
Scalable deployment for LLMs and multimodal architectures: Given parameter efficiency, NESS is promising for CL in resource-constrained settings or for continual adaptation of foundational models.
Figure 5: Comparative visualization of forgetting rates across methods and tasks; NESS consistently maintains low forgetting.
Conclusion
The NESS algorithm introduces a principled, parameter-efficient approach to continual learning by constraining updates directly to the approximate null space of previous inputs, as determined by small singular values. This method achieves strong empirical performance and robust stability, confirming the significance of small singular directions in CL. Theoretical guarantees and practical efficiency highlight its potential across domains, although further research on threshold selection, memory-free settings, and extension to other components is warranted.