Improving Parametric Knowledge Access in Reasoning Language Models
Abstract: We study reasoning for accessing world knowledge stored in a LLM's parameters. For example, recalling that Canberra is Australia's capital may benefit from thinking through major cities and the concept of purpose-built capitals. While reasoning LLMs are trained via reinforcement learning to produce reasoning traces on tasks such as mathematics, they may not reason well for accessing their own world knowledge. We first find that models do not generate their best world knowledge reasoning by default: adding a simple "think step-by-step" cue demonstrates statistically significant improvement in knowledge recall but not math. Motivated by this, we propose training models to reason over their parametric knowledge using world-knowledge question answering as a verifiable reward. After reinforcement learning on TriviaQA (+9.9%), performance also improves on Natural Questions, HotpotQA, SimpleQA, and StrategyQA by 4.2%, 2.1%, 0.6%, and 3.0%, respectively. Reasoning models are under-optimized for parametric knowledge access, but can be easily trained to reason better.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Helping AI Remember: What This Paper Is About
This paper looks at how LLMs (AIs that read and write text) can better “think” to remember facts they already know. Imagine the AI has a big internal memory. The authors ask: can we teach it to reason in steps so it can pull the right facts out of that memory more often—like recalling that Canberra is the capital of Australia?
What Questions Did the Researchers Ask?
The paper focuses on three simple questions:
- Do LLMs automatically use their best kind of reasoning when trying to remember facts, or do they need a nudge?
- Does a simple prompt like “think step-by-step” help models recall facts more reliably?
- Can reinforcement learning (a training method that gives rewards for good answers) teach models to access their internal knowledge better?
How Did They Test This?
The researchers used “closed-book” question answering, which means the model must answer without looking things up—no searching the web or external documents. Think of it like a quiz where you can’t use notes.
They did two main things:
- Prompting experiment:
- They tried adding a short cue: “think step-by-step.”
- They tested this across several models on trivia-style datasets:
- TriviaQA: lots of general-knowledge trivia
- Natural Questions: real questions people ask (answers come from Wikipedia)
- They also tested on MATH problems to see if the cue helped there, too.
- Reinforcement Learning (RL) training:
- They trained one model (GPT-OSS-20B) using RL on TriviaQA.
- In RL, the model gets a reward (like “points”) when it gives a correct answer, and small penalties if it breaks formatting rules (e.g., not using required answer tags).
- Over time, the model learns patterns that lead to more correct answers.
- They checked whether this training improved performance not just on TriviaQA, but also on:
- Natural Questions
- HotpotQA (questions that usually need reasoning across multiple pieces of info)
- SimpleQA (short, factual questions)
- StrategyQA (questions requiring simple reasoning)
To measure performance, they used:
- Exact Match (EM): the answer is exactly right (like spelling “Canberra” exactly).
- Extracted Recall (Ex-Recall): a gentler check that looks for the correct answer span inside the model’s output, even if the full sentence isn’t an exact match.
Think of EM as “did you say the exact right word?” and Ex-Recall as “did the correct answer appear in what you said?”
What Did They Find, and Why Does It Matter?
Here are the main takeaways:
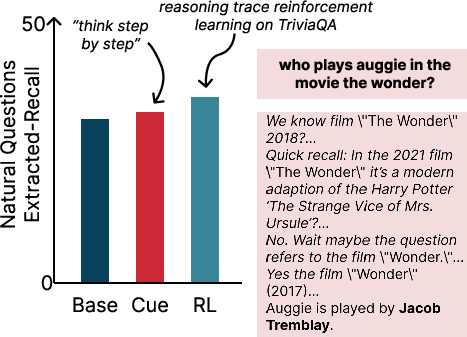
- The simple “think step-by-step” cue helps with factual recall.
- Across different models and datasets, adding this cue gave small but consistent improvements in recalling facts.
- However, this cue did not help with math problems—in some cases it slightly hurt math accuracy. That suggests these models already know how to reason in math without extra prompting, likely because they’ve been trained heavily on math reasoning.
- Reinforcement Learning (RL) made a bigger difference.
- Training the model with rewards on TriviaQA improved results across several datasets:
- TriviaQA: EM up by about 27 percentage points; Ex-Recall up by about 9.9 points
- Natural Questions: EM up by about 12.2; Ex-Recall up by about 4.2
- HotpotQA: EM up by about 9.5; Ex-Recall up by about 2.1
- SimpleQA: EM up by about 1.5; Ex-Recall up by about 0.6
- StrategyQA: EM up by about 3.0
- These gains beat a simpler training approach that just copied correct, existing reasoning traces (called “Reasoning-SFT”), showing RL’s on-the-fly feedback is more powerful.
- The model’s “thinking” got a bit longer after RL (more tokens), but not always more human-like.
- Sometimes the trained model just arrived at the right answer faster without showing detailed, step-by-step logic.
- That’s okay: for remembering facts, the “right” reasoning is whatever reliably pulls out the correct memory—even if it’s not the kind of explanation a person would write.
- Unexpected bonus: the RL-trained model also did slightly better on math in one setting, even though RL focused on trivia. That suggests some general benefits to the training.
Why it matters:
- Many AI assistants answer questions using the knowledge stored inside them. Helping them “think to remember” can make them more reliable—even without internet access.
- The results show current models don’t automatically use their best strategy to recall facts, but simple cues and RL training can help a lot.
What Does This Mean Going Forward?
- Better everyday helpers: AI systems could answer more factual questions correctly without needing to search online, which is useful in offline or privacy-sensitive settings.
- Training for memory access: RL with verifiable rewards (like “is the answer correct?”) is a practical way to improve how models tap into their internal knowledge.
- Next challenge: make the reasoning traces not just effective, but clearer and more “human-understandable.” The authors suggest exploring “spreading activation” style thinking (like mentally jumping between related ideas to jog memory) and designing rewards that encourage that kind of reasoning.
- Overall: LLMs can be taught to reason better for remembering facts, and doing so improves performance across many kinds of questions.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single, concrete list of open problems, missing analyses, and limitations that future work can directly act on:
- Reward design and ablations are underexplored: How do different verifiable rewards (e.g., EM-only, token-level F1, contrastive rewards against near-miss distractors, penalizing verbosity) affect recall gains, verbosity, and reasoning-trace quality? Systematic ablations of the format penalty and partial-credit “recall” term are missing.
- Mechanism of improvement is unclear: The model’s post-RL “reasoning” is longer but not reliably more coherent or interpretable. What internal processes (e.g., spreading-activation-like retrieval vs. calibrated guessing) are responsible for the observed gains? Mechanistic probes, activation patching, or knowledge-neuron analyses are needed.
- Trace validity and causality are untested: Do visible reasoning tokens actually contribute to better recall, or are they epiphenomenal? Interventions that hide, shuffle, or truncate chains (and tests of “latent CoT” vs. visible CoT) could establish causal necessity.
- Limited baseline strength: The SFT and Reasoning-SFT baselines are narrow (single dataset, LoRA ranks, limited hyperparameter sweeps). A stronger comparison should include high-capacity SFT with chain-of-thought on QA, instruction-tuned QA models, and multi-epoch/QLoRA SFT to clarify whether RL is strictly necessary.
- RL algorithm choices are not compared: Only a GRPO-style objective is used. How do PPO, DPO/IPO-style preference objectives, token-regulated GRPO, or KL schedules influence stability, sample efficiency, and trace quality on knowledge recall?
- Generalization breadth is narrow: RL is done only on TriviaQA and evaluated on a small set of English benchmarks. Assess transfer to long-tail and adversarial factual QA (e.g., AmbigQA, PopQA, EntityQuestions), specialized domains (science, medicine, law), and multilingual settings (e.g., X-FACTR, mLAMA).
- Temporal robustness is unmeasured: Does RL overfit to stale facts or improve/impair handling of time-sensitive knowledge? Evaluate on temporally split datasets (e.g., TimeQA, TempLAMA) and measure recency calibration.
- Safety and privacy risks are unassessed: Does optimizing closed-book recall increase memorization/redisclosure of PII or copyrighted content? Test on PII leakage audits and memorization probes.
- Calibration and abstention are not evaluated: Do models become more or less overconfident after RL? Measure ECE/Brier scores, answerability/IDK behavior, and selective prediction metrics.
- Error taxonomy is missing: Which factual error types improve (entity disambiguation, dates, numeric facts) and which persist? A fine-grained error analysis would target where reasoning-for-recall helps most.
- Multi-hop recall is not rigorously tested: HotpotQA EM gains are shown, but there is no evaluation of intermediate hop correctness, supporting-fact prediction, or explicit multi-step factual chains without retrieval.
- Cue engineering space is unexplored: Only “think step-by-step” is tested. Do alternative prompts (“list candidates then decide,” “recall related entities,” “justify then answer”) elicit better recall or shorter traces?
- Cost–performance trade-offs are unquantified: RL increases thinking-token length. What is the marginal gain per additional token and the effect of budget forcing across budgets? Provide latency, throughput, and cost curves.
- Interactions with other skills are not characterized: A small MATH check suggests mixed effects; impacts on coding, tool-use, and other RLVR-trained domains (e.g., SWE-bench) are unknown. Evaluate for positive/negative transfer and interference.
- Closed-book vs. retrieval-augmented interplay is open: Does RL for parametric recall help or hurt search-augmented QA? Joint training or sequential curricula with retrieval remains unexplored.
- Extracted-Recall metric dependency is fragile: Ex-Recall relies on a separate LLM (GPT-5-mini) for answer extraction, introducing potential bias and reproducibility issues. Validate with multiple extractors, deterministic extractors, and report extractor error rates.
- Reward gaming risk not measured: Partial credit for “recall” may incentivize verbose or list-like outputs. Quantify gaming by checking answer length distributions and the relation between verbosity and reward under controlled prompts.
- Data leakage checks are limited: Training uses a random split within TriviaQA’s train set; broader contamination audits (pretraining overlap, test leakage across datasets) are not provided.
- Scaling laws are unstudied: Only one model (GPT-OSS-20B) is trained with RL. How do gains scale with parameter count and compute? Train across sizes to chart recall-reasoning scaling trends.
- Sample efficiency and stability are unclear: How do gains evolve over steps, group size K, KL penalties, and LoRA ranks? Learning curves and stability diagnostics are missing.
- Robustness to paraphrase/adversarial rewording is not tested: Evaluate on paraphrased/controlled-perturbation benchmarks and adversarially crafted questions to assess brittleness.
- Mixture-of-tasks RL is untested: Does combining multiple QA datasets or interleaving math/code with knowledge recall during RL produce better generalization and reduce forgetting?
- Human evaluation of reasoning quality is absent: Collect human judgments on trace plausibility, specificity, and factual correctness to complement token-length proxies.
- Interpretability-guided objectives are not realized: The paper proposes spreading-activation–style reasoning but does not instantiate or evaluate objectives that reward semantically-linked intermediate mentions or structured recall plans.
- Reproducibility dependencies exist: The pipeline uses Tinker infrastructure and a proprietary extractor model; provide open-source alternatives and seeds/checkpoints to ensure replicability.
- Catastrophic forgetting and knowledge drift are unmeasured: Does RL for recall harm unrelated knowledge or introduce spurious biases? Audit with broad fact probes (e.g., LAMA), MMLU subsets, and pre/post comparisons.
- Uncertainty handling in outputs is not explored: Train/evaluate with abstention-aware rewards, calibrated thresholds, or selective answering to reduce confident errors on hard questions.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, leveraging the paper’s findings that simple “think step-by-step” prompting and RL from verifiable rewards (RLVR) substantially improve closed-book factual recall in reasoning LLMs.
- Enterprise “parametric knowledge recall” fine-tuning pipeline (software, customer support, knowledge management)
- Description: Use the paper’s RLVR setup (LoRA + on-policy GRPO-style optimization) to fine-tune an organization’s open-weight model (e.g., GPT-OSS-20B) on curated, verifiable Q&A pairs about products, policies, and procedures. Add “think step-by-step” prompting in production to further boost recall.
- Tools/workflows: Curate QA datasets; enforce answer formatting (e.g.,
<answer></answer>tags); RL training via Tinker-like platforms; deploy a closed-book assistant for internal help desks or customer chat. - Assumptions/dependencies: Adequate Q&A coverage and quality; compute budget for RL; permissions/licensing for the base model; monitoring for drift and hallucinations; limited explainability of traces.
- Prompting policy update for closed-book agents (software, education, consumer assistants)
- Description: Incorporate an explicit “think step-by-step” instruction into prompts for any closed-book factual query mode, as it improves recall across multiple QA benchmarks.
- Tools/workflows: Prompt templates from the paper; small A/B tests to validate impact; “budget forcing” or token caps for verbose models.
- Assumptions/dependencies: The model contains sufficient parametric knowledge; gains are modest but consistent; prompt sensitivity varies by model/version.
- Factual recall evaluation using Extracted-Recall (academia, compliance, product QA)
- Description: Adopt the paper’s Ex-Recall metric by running an auxiliary LLM extractor to collapse verbose outputs into a single answer span for match checking—useful where EM alone underestimates performance.
- Tools/workflows: Build an evaluation harness with an extraction prompt; compare EM vs. Ex-Recall; use McNemar’s test for paired significance testing.
- Assumptions/dependencies: Availability of a small, reliable extractor LLM; careful prompt design to avoid gaming; domain-specific normalization rules.
- Cost-aware search reduction in retrieval-augmented agents (software, finance, customer support)
- Description: Prioritize closed-book recall first (with step-by-step prompting and RLVR-tuned parametric knowledge) before issuing search calls; reduce latency and API costs.
- Tools/workflows: Decision policy in the agent: recall → fallback to search; RLVR fine-tuning for recall robustness; logging for fallback rates.
- Assumptions/dependencies: Sufficient recall coverage; robust fallback to search for edge cases; continuous monitoring of accuracy.
- Domain tutoring and study aids with improved factual recall (education)
- Description: Apply the cue and RLVR fine-tuning on subject-specific trivia/history/geography QAs to build closed-book study aids that recall facts more consistently.
- Tools/workflows: Curriculum Q&A sets; LoRA-based RLVR; student-facing assistant with constrained outputs and verification.
- Assumptions/dependencies: Non-safety-critical content; periodic refresh to handle outdated facts; careful messaging about reliability limits.
- Internal API and codebase Q&A assistants (software engineering)
- Description: Fine-tune models via RLVR on verifiable Q&A about APIs, release notes, semantic conventions, and internal coding standards to improve recall without full retrieval.
- Tools/workflows: QA dataset generation from docs; answer formatting rewards; CI/CD gate for assistant updates; use “think step-by-step”.
- Assumptions/dependencies: Fast-moving codebases require frequent re-training; closed-book recall can still miss rare edge cases; access controls for internal data.
- Policy and public information portals with verifiable Q&A rewards (public sector, policy communication)
- Description: Train closed-book assistants on official Q&A (FAQs, statutes summaries) with correctness-based rewards, improving consistent recall of public information.
- Tools/workflows: Government-curated QAs; answer formatting checks; Ex-Recall evaluation; disclaimers and escalation to human agents for ambiguous queries.
- Assumptions/dependencies: High-quality, up-to-date QAs; transparent governance; audit requirements due to limited interpretability of traces.
- On-device/offline assistants with better closed-book recall (consumer, mobile)
- Description: Use step-by-step prompting and RLVR-tuned compact models to improve offline factual responses (e.g., device settings, local trivia, travel facts).
- Tools/workflows: LoRA on smaller open-weight models; compression/distillation; prompt templates; token budget controls.
- Assumptions/dependencies: Model capacity constraints; local evaluation; periodic updates to avoid stale facts.
Long-Term Applications
The following use cases require further research, scaling, or development—particularly around explainability, safety, and coverage—building on the paper’s insight that RLVR enhances parametric knowledge access but current traces are not always human-interpretable.
- Explainable “spreading activation”-style recall (healthcare, legal, compliance)
- Description: Design RL reward functions that explicitly encourage interpretable, concept-linking reasoning traces (e.g., human-auditable chains for drug facts or legal precedents).
- Tools/workflows: New RL objectives incorporating graph-based reasoning constraints; verifier models; trace quality metrics beyond EM/Ex-Recall.
- Assumptions/dependencies: Research breakthroughs in reasoning trace supervision; trade-offs between accuracy and interpretability; domain expert validation.
- Safety-critical decision support with verified recall (healthcare, aviation, energy)
- Description: Deploy closed-book assistants for non-diagnostic but high-stakes recall (procedures, checklists) only after achieving stringent accuracy, calibration, and trace audit standards.
- Tools/workflows: Formal evaluation protocols; uncertainty estimation; human-in-the-loop; post-deployment monitoring.
- Assumptions/dependencies: Regulatory approvals; robust fail-safes; extensive domain coverage and periodic re-certification.
- Corporate knowledge memory systems with continuous RL updates (enterprise KM, HR, operations)
- Description: A “knowledge OS” that regularly ingests curated Q&A from evolving policies and documents, re-optimizing the parametric memory via RLVR to maintain accurate recall.
- Tools/workflows: Data pipelines to generate/validate QAs; scheduled RL runs; drift detection; change logs linked to model versions.
- Assumptions/dependencies: Stable training infrastructure; careful data governance; measurable ROI versus retrieval-first architectures.
- Standardization of closed-book recall metrics and audits (policy, AI governance, academia)
- Description: Establish Ex-Recall-like metrics and audit practices as industry standards for evaluating closed-book assistants, enabling consistent benchmarking and procurement decisions.
- Tools/workflows: Community benchmarks; public test suites; statistical significance testing (e.g., McNemar’s); third-party audits.
- Assumptions/dependencies: Multi-stakeholder alignment; transparency; incentives for vendors to report standardized metrics.
- Hybrid self-play generation of recall QAs (academia, software)
- Description: Use LLMs to propose candidate QAs from internal corpora and filter for verifiability, scaling the coverage of rewardable training examples for RLVR.
- Tools/workflows: Synthetic QA generation; verifier models; contamination checks; progressive curriculum learning.
- Assumptions/dependencies: High-quality filters; contamination avoidance (not training on exact evaluation items); compute budget.
- Offline high-recall edge models (consumer devices, robotics, remote operations)
- Description: Develop compact, energy-efficient models with strong closed-book recall for constrained environments (robots, remote sites) where connectivity is limited.
- Tools/workflows: Distillation from RLVR-trained larger models; memory-optimized architectures; on-device evaluation pipelines.
- Assumptions/dependencies: Hardware constraints; periodic update channels; domain-specific recall content.
- Finance and regulatory compliance assistants (finance, legal)
- Description: RLVR-tuned assistants that recall internal compliance rules, reporting calendars, and regulatory thresholds; evolve toward interpretable traces for auditability.
- Tools/workflows: Curated compliance QAs; trace logging & audit trails; integration with GRC (governance, risk, compliance) tooling.
- Assumptions/dependencies: Legal liability considerations; ongoing regulatory changes; guarantee of timeliness and correctness.
- Cross-task transfer research programs (academia, AI labs)
- Description: Systematic investigation of how RLVR on knowledge recall transfers to other reasoning tasks (e.g., observed math improvement in no-cue setting), informing better multi-domain training curricula.
- Tools/workflows: Multi-benchmark suites; ablation studies; shared training artifacts; open-weight checkpoints.
- Assumptions/dependencies: Availability of compute and open datasets; reproducibility; community engagement for shared baselines.
Glossary
- Advantage (in policy gradients): A baseline-adjusted reward signal used to reduce variance in gradient estimates by comparing each trajectory’s reward to a reference level. "Advantages are computed relative to the group-average reward"
- AIME: The American Invitational Mathematics Examination, a challenging high school math competition used as a benchmark for reasoning capabilities. "frontier models achieve near-perfect accuracy on the AIME mathematics competition"
- Budget forcing: A decoding constraint that limits or regularizes the length or verbosity of generated reasoning traces. "For verbose models, we apply budget forcing"
- Closed-book QA: Question answering where the model must answer from its internal parameters without retrieving external documents. "two closed-book QA datasets for testing knowledge recall"
- Exact Match (EM): A strict metric that checks whether the predicted answer exactly matches a reference after normalization. "we evaluate using Exact Match (EM) and Extracted-Recall (Ex-Recall)."
- Ex-Recall (Extracted-Recall): A relaxed exact-match metric computed after extracting a single answer span from the model’s output. "Ex-Recall is a slightly relaxed Exact Match."
- GPQA: A “Google-proof” graduate-level question answering benchmark used to assess advanced reasoning. "transfer these abilities to other reasoning-heavy domains, such as GPQA"
- GRPO: Group Relative Policy Optimization; a reinforcement learning method that uses group-wise relative rewards to compute policy gradients. "We optimize the objective using a GRPO-style"
- HotpotQA: A dataset requiring multi-hop reasoning over multiple documents to answer questions. "HotpotQA is a multi-hop QA dataset;"
- Humanity's Last Exam: A difficult, broad-coverage evaluation benchmark for advanced reasoning in LLMs. "such as GPQA and Humanity's Last Exam"
- Importance sampling: A technique for reweighting samples from one distribution to estimate expectations under another, used here in policy gradient estimation. "importance-sampling policy gradient method."
- KL penalty: A Kullback–Leibler divergence regularization term that penalizes deviation from a reference policy to stabilize RL training. "KL penalty coefficient of 0.01"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that adapts large models by training low-rank updates. "We train with LoRA (rank=32)"
- MATH: A benchmark of competition-level math problems to evaluate mathematical reasoning in LLMs. "MATH contains competition-level mathematical reasoning problems."
- McNemar's test: A statistical test for paired nominal data used to assess significance of performance differences between two models. "statistically significant at the 95% level by McNemar's test"
- Multi-hop QA: Question answering that requires reasoning across multiple pieces of evidence or steps. "HotpotQA is a multi-hop QA dataset;"
- Natural Questions (NQ): A benchmark of real user questions with answers from Wikipedia, used in both open- and closed-book settings. "NQ = Natural Questions."
- Offline RL: Reinforcement learning using fixed datasets of trajectories without online environment interaction. "This also outperforms an offline RL baseline in which we finetune a model on correct reasoning traces generated by the initial model."
- On-policy: An RL training regime where data are sampled from the current policy being optimized. "in our on-policy setting yields importance weights close to one."
- Online RL: Reinforcement learning where the agent continually collects new data from the environment or model during training. "We conduct online RL training using Tinker"
- Open-book question answering: QA where systems can retrieve or consult external sources during answering. "RL has been applied to open-book question answering"
- Parametric knowledge: Factual information stored implicitly in a model’s parameters, accessible via prompting or reasoning. "Reasoning to access parametric knowledge is qualitatively different from reasoning used in common RLVR training"
- Policy gradient: A class of RL algorithms that optimize the expected reward by ascending the gradient of the policy’s parameters. "policy gradient method."
- RLVR: Reinforcement Learning from Verifiable Rewards; training LMs with rewards derived from automatically checkable outcomes. "Reasoning LLMs trained with Reinforcement Learning from Verifiable Rewards (RLVR)"
- Reasoning tokens: Special reasoning segments or modes in model outputs (e.g., think/analysis tokens) that encourage step-by-step reasoning before answering. "with and without the think step-by-step cue and reasoning tokens."
- Reasoning-SFT: A supervised fine-tuning baseline that trains on model-generated reasoning traces filtered for correctness. "We first evaluate the model trained on Reasoning-SFT"
- Reinforcement Learning (RL): An optimization framework where policies are trained to maximize expected reward signals. "We train GPT-OSS-20B on TriviaQA with online RL"
- SFT (Supervised finetuning): Training a model directly on labeled input–output pairs to improve task performance. "SFT Baseline Details"
- Spreading activation: A cognitive theory where activating one concept triggers related concepts in a semantic network, inspiring knowledge retrieval strategies. "spreading activation—where activating one concept in a semantic network causes activation to spread to related concepts."
- StrategyQA: A dataset assessing implicit reasoning strategies for yes/no questions. "StrategyQA (+3.0% EM)"
- SWE-bench: A benchmark of real-world software engineering tasks for evaluating code reasoning and problem solving. "SWE-bench, a benchmark of real-world software engineering tasks"
- Temperature: A decoding parameter controlling randomness by scaling logits before sampling; higher values yield more diverse outputs. "For GPT-5.2, temperature and top-p could not be explicitly set"
- Think step-by-step cue: A prompt instruction that elicits chain-of-thought reasoning to improve knowledge recall. "adding a simple think step-by-step cue demonstrates statistically significant improvement in knowledge recall"
- Top-p: Also called nucleus sampling; a decoding method that samples tokens from the smallest set whose cumulative probability exceeds p. "For GPT-5.2, temperature and top-p could not be explicitly set"
- Verifiable reward: A reward signal that can be automatically checked (e.g., answer correctness), enabling scalable RL training for reasoning. "using answer correctness as the verifiable reward"
Collections
Sign up for free to add this paper to one or more collections.