Spin Glass Concepts in Computer Science, Statistics, and Learning
Abstract: Spin glass theory studies the structure of sublevel sets and minima (or near-minima) of certain classes of random functions in high dimension. Near-minima of random functions also play an important role in high-dimensional statistics and statistical learning, where minimizing the empirical risk (which is a random function of the model parameters) is the method of choice for learning a statistical model from noisy data. Finally, near-minima of random functions are obviously central to average-case analysis of optimization algorithms. Computer science, statistics, and machine learning naturally lead to questions that are traditionally not addressed within physics and mathematical physics. I will try to explain how ideas from spin glass theory have seeded recent developments in these fields. (This article was written on the occasion of the 2024 Abel Prize to Michel Talagrand.)
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper explains how ideas from “spin glasses” in physics help us understand and solve big, messy problems in computer science, statistics, and machine learning. A spin glass is a physical system with many tiny magnets (“spins”) that interact in complicated, partly random ways. Mathematically, that looks like a huge, bumpy landscape made by a random function: some places are high (bad), some are low (good), and we want to find the best spots.
The same kind of “random landscape” shows up when:
- You try to split a network into two communities,
- You train a model by minimizing a loss built from noisy data,
- You design algorithms that must work on typical (random) inputs.
The paper surveys big ideas that connect these fields, especially a famous physics result called Parisi’s formula, and algorithmic tools called message passing and approximate message passing (AMP).
The main questions the paper asks
In everyday language, the paper asks questions like:
- How high or low can you score in a “game” where the rules (the function you’re optimizing) are partly random?
- Can you find (or even closely approximate) the best score quickly, or is that too hard?
- What do physics formulas say about the best possible score, and do these predictions help build good algorithms?
- In statistics, when there’s hidden structure in data (like communities in a network), how much can we detect and how fast?
- When is it easy to sample (draw) typical configurations from a complex probability distribution, and when does it become too hard?
How the paper approaches these questions
To make the ideas concrete, the paper focuses on well-studied examples and explains the tools used to analyze them.
- Parisi’s formula: Think of a super-detailed “thermometer” that tells you the ultimate, average best score you can get in a famous random model (the Sherrington–Kirkpatrick or SK model). It doesn’t give a step-by-step solution, but it tells you the value you’re aiming for, precisely, in the limit of very large problems. This result, predicted by physics and proved mathematically, is a central landmark.
- Convex relaxations (like semidefinite programming, SDP): Imagine a spiky shape (the set of possible solutions) that’s hard to optimize over. A convex relaxation sands down the spikes into a smoother shape that’s easier to handle. You can then optimize on the smooth shape to get a good guess and a certified upper bound, though sometimes the guess is not super close to the true best.
- Sum-of-squares (SoS): This is an advanced family of progressively tighter convex relaxations. They can, in principle, capture more of the original hard shape. But they can also be very expensive, and in some random problems they surprisingly don’t help much unless you go to very high levels.
- Belief propagation and the cavity method: These are physics-inspired ways to pass “messages” along the edges of a graph to estimate local probabilities or make decisions. On trees, this method is exact; on more complex graphs, it often works well in practice and suggests how to design algorithms.
- Approximate Message Passing (AMP) and State Evolution: AMP is a streamlined message-passing algorithm tailored for dense, high-dimensional problems (like big random matrices). The magic is that its performance can be tracked by a simple, one-number-per-iteration “state evolution” rule. That makes it possible to:
- Predict exactly how much progress the algorithm makes each step,
- Choose the best nonlinearity (“denoiser”) at each step,
- Match fundamental limits in many estimation tasks.
These methods are tied together by the same core idea: treat complicated, high-dimensional randomness with tools that make its typical behavior predictable.
Key results and why they matter
Here are the main takeaways the paper highlights, in plain language:
- Parisi’s formula pinpoints the best possible average score in a classic random optimization problem (the SK model). It’s a rigorous bridge from physics to math and computer science. Even better, it’s “universal”: similar values show up in other random settings (like certain random graphs). This lets you test for hidden structure by comparing observed scores to Parisi’s baseline.
- Worst-case vs. average-case: In worst-case computer science, you often can’t approximate hard problems well in polynomial time. But for random instances (average-case), the story can be much better. For example, a standard convex relaxation (SDP) gets about 83% of the SK optimal score on random inputs—much better than what worst-case theory guarantees.
- Limits of convex certifications: Even powerful hierarchies like SoS often don’t improve the approximation for random models unless you go to very high (and impractical) levels. Also, there is strong evidence that fast algorithms that always produce valid upper bounds (“certificates”) will be very loose on SK-type random instances. This suggests a gap between finding good solutions and certifying their optimality on random inputs.
- Message passing works and can be predicted: Belief propagation (and its variants) is a practical algorithmic idea rooted in physics. AMP refines it for dense problems and comes with exact predictions via state evolution. This makes it possible to design near-optimal procedures for tasks like:
- Low-rank estimation (finding a hidden signal in noisy data),
- Community detection in networks,
- Other high-dimensional learning problems.
- Design by prediction: Because AMP’s progress can be tracked by a simple recursion, you can pick the best “denoiser” at each step (essentially: the best way to clean up noise) and reach the best achievable accuracy among a broad class of fast algorithms.
Overall, these results show both the power and the limits of different approaches: physics formulas set performance targets, message passing hits those targets in many cases, and convex relaxations give useful—but sometimes limited—certificates.
Why this matters and what it could change
- A common language for fields: Spin glass ideas give a shared framework to reason about random, high-dimensional problems across physics, computer science, and statistics.
- Better algorithms with guarantees: AMP and related methods let us design fast algorithms whose average-case performance can be predicted accurately, helping practitioners choose the right tool for large-scale data problems.
- Realistic expectations: Understanding when convex relaxations can or cannot certify near-optimality prevents overpromising and guides research toward methods that are both effective and explainable.
- Practical impact areas: Community detection, matrix/tensor estimation, recommendation systems, and parts of deep learning all benefit from these insights, especially when data are large and noisy.
- A roadmap from physics to computation: Parisi’s formula and the cavity method don’t just explain the “shape” of random landscapes; they inspire practical algorithms and clarify the frontiers between what is efficiently solvable, what is solvable but hard to certify, and what is likely out of reach.
In short, the paper shows how deep ideas from the study of random physical systems lead to precise predictions, sharper algorithms, and a clearer understanding of both possibilities and limits in modern data science.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions for future research that emerge from the paper’s discussion.
- Finite-sample calibration for Parisi-based detection: derive the limiting distribution (e.g., CLT or moderate deviations) of the ground-state energy and explicit scaling for δ_n to achieve a target error probability in tests that compare to .
- Algorithmic approximation of SK ground states: determine whether a polynomial-time algorithm can achieve a (1−ε)-approximation for arbitrarily small ε on GOE inputs; clarify if message passing or convex optimization can provably reach arbitrarily close to the Parisi optimum.
- Sum-of-Squares hierarchy on random SK instances: characterize the degree k (as a function of n) at which optimization over S{(k)}_n begins to improve on SDP (k=2) for GOE inputs; establish tight lower bounds and trade-offs between k, runtime, and approximation ratio.
- Average-case certification barriers: formalize and prove impossibility results for polynomial-time certifiers that output valid upper bounds on for all A but are tight on SK instances; delineate the broadest algorithmic classes that fail to certify nontrivial bounds under average-case models.
- No-overlap gap conjecture: provide a precise formulation and proof (or refutation) of the conjecture about the Parisi minimizer’s overlap structure; quantify its algorithmic implications for convex methods that rely on it to achieve near-optimal approximations.
- Survey propagation rigor: establish convergence guarantees, correctness of marginals, and approximation quality for survey propagation on random K-SAT; identify regimes of superiority over BP/AMP and characterize failure modes.
- Belief propagation on loopy/dense graphs: prove convergence and accuracy guarantees (or limits) for BP on dense random graphs and mean-field models; quantify the error introduced by cycles and its dependence on model parameters.
- AMP with non-Lipschitz or learned denoisers: extend state evolution to handle non-Lipschitz, data-dependent, or learned f_k; develop pathwise control beyond pseudo-Lipschitz test functions and quantify robustness to adaptive updates.
- AMP iteration depth: move beyond current control over O(nδ) iterations to analyze behavior up to convergence; characterize stability, divergence thresholds, and finite-iteration rates (including damping and step-size schemes).
- Robustness to model misspecification: develop universality results and performance guarantees for AMP under heavy-tailed noise, heteroskedasticity, dependent entries, or mis-specified priors; provide adaptive estimation strategies for Onsager coefficients.
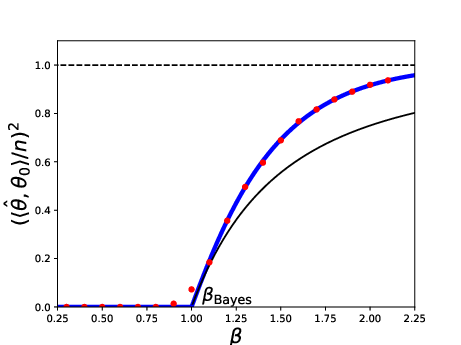
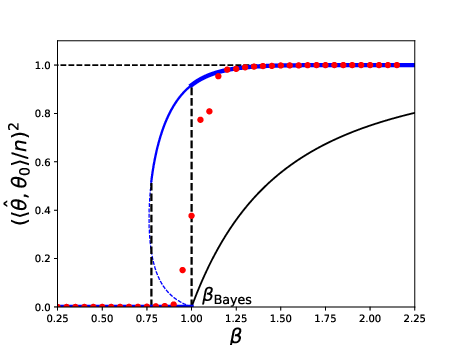
- Low-rank estimation beyond finite K: analyze the K→∞ limit of the optimal denoiser recursion (γ_k) for rank-one models; obtain convergence rates, exact phase transitions, and comparisons to Bayes-optimal estimators across λ and prior families.
- Higher-rank and tensor extensions: generalize optimal AMP design and state evolution to multi-rank matrices and higher-order tensors; map computational-statistical phase diagrams and identify gaps between tractable algorithms and information-theoretic limits.
- Parisi-based SBM detection: design computationally tractable proxies for ground-state energy that enable near-optimal community detection; determine statistical thresholds, optimality, and the performance of polynomial-time surrogates under sparse regimes.
- Fluctuation theory for maxima: obtain central limit theorems or sharp tail bounds for the maximum/ground-state energy in SK/SBM-type models to enable precise inferential procedures (e.g., δ_n selection) and confidence calibration.
- Universality boundaries for SE: sharpen conditions under which SE holds for orthogonally invariant ensembles with dependence, semi-random constructions, and structured spectra; specify minimal assumptions needed for AMP universality.
- Certifying near-Parisi values: investigate whether any tractable convex relaxation can certify nontrivial upper bounds close to on random instances; quantify the inherent certification gap.
- Sampling phase transitions: extend rigorous mixing-time thresholds for MCMC beyond SK (e.g., other mean-field glasses and external field settings); establish algorithmic optimality and barriers across temperature regimes.
- Rounding strategies from SDP: construct rounding schemes that close the gap between the SDP value (≈1) and the Parisi limit (≈0.763) on GOE inputs; provide finite-sample performance guarantees and explicit approximation ratios.
- Algorithmic Parisi formula: formalize and generalize the “algorithmic Parisi” connection—identify conditions under which AMP (or related algorithms) attain the variational optimum, and quantify discrepancies when they do not.
- Practical implementation analysis: theoretically characterize the impact of finite precision, initialization choices, damping, and step-size schedules on convergence and accuracy of AMP/MP in high-dimensional limits and finite samples.
Glossary
- Approximate Message Passing (AMP): An iterative algorithmic framework for high-dimensional inference on dense matrices/tensors that admits precise asymptotic analysis via state evolution. "Approximate message passing (AMP) is the name of a class of algorithms that"
- Belief propagation: A message-passing algorithm on graphical models to approximate marginal distributions by iteratively exchanging local messages. "known as sum-product algorithm or ‘belief propagation’."
- Bethe–Peierls method: A classical physics technique for analyzing spin models on trees using local consistency conditions. "Bethe-Peierls method \cite{bethe1935statistical,peierls1936statistical} had been used"
- Borell–TIS inequality: A Gaussian concentration inequality for suprema of Gaussian processes, used to establish concentration of maxima/free energy. "Borell-TIS inequality."
- Cavity method: A non-rigorous physics approach that relates properties of an n-variable system to an (n−1)-variable “cavity” system to derive macroscopic quantities. "The cavity method was developed in the 1980s"
- Cut polytope: The convex hull of all ±1 cut matrices (second-moment matrices of cut vectors), representing feasible cuts in a graph. "the cut polytope of Eq.~\eqref{eq:CutPolytope}"
- Elliptope: The set of correlation matrices (PSD with unit diagonal) used as a semidefinite relaxation of the cut polytope. "The best known example is the elliptope "
- Erdős–Rényi random graph: A random graph model where edges are included independently with a fixed probability. "a sparse Erd\H{o}s-Renyi random graph"
- Free energy density: The normalized log-partition function that encodes thermodynamic properties; its limit characterizes phases. "apply to the free energy density"
- Gaussian Orthogonal Ensemble (GOE): A distribution over symmetric Gaussian random matrices with independent entries up to symmetry and specified variances. "Gaussian Orthogonal Ensemble (we will write )."
- Generic chaining: A powerful technique to bound suprema of stochastic processes via multiscale chaining constructions. "generic chaining theory"
- Gibbs measure: A probability measure over configurations weighted exponentially by the Hamiltonian (energy) and external fields/temperature. "the (classical) Gibbs measure"
- Grothendieck inequality: A fundamental inequality bounding certain bilinear forms, underpinning approximation guarantees for SDP relaxations. "an inequality due to Grothendieck"
- Ground state energy: The extremal (minimum or maximum, up to sign) energy of a system; in optimization, the optimal objective value. "this is the ‘ground state energy’ of the Hamiltonian "
- Hamiltonian: The energy function of a system; in these models typically a random quadratic form over spins/variables. "can be regarded as the Hamiltonian of a spin model"
- Ising model: A spin system with binary variables ±1 interacting via pairwise couplings; a canonical model in statistical physics. "and in particular a Ising model when ."
- Markov Chain Monte Carlo (MCMC): A class of algorithms that sample from complex distributions by constructing an ergodic Markov chain with the target as stationary distribution. "Markov Chain Monte Carlo is predicted to mix rapidly"
- Markov random field: An undirected graphical model specifying a joint distribution that factorizes over edges/cliques of a graph. "an `undirected graphical model' (or Markov random field) is the following probability distribution"
- Mean-field spin glass: A disordered spin system where interactions are long-ranged (dense), enabling mean-field approximations/limits. "mean field spin glasses"
- Message passing algorithms: Iterative local-update schemes on graphs that propagate “messages” along edges to compute estimates or marginals. "A convenient abstraction of some important properties of belief propagation is given by message passing algorithms"
- Minimum bisection: The problem of partitioning the vertices into two equal halves minimizing the number of crossing edges. "is the minimum bisection problem"
- Onsager coefficients: Correction terms (from statistical physics) added in AMP to cancel correlations and enable state evolution analysis. "where the Onsager coefficients are estimated by"
- Parisi functional: A variational functional whose minimizer yields the limiting ground state energy/free energy in mean-field spin glasses. "Define the Parisi functional"
- Parisi’s formula: A variational formula giving the limiting (ground state or free) energy of mean-field spin glass models. "Parisi's formula"
- Replica symmetry breaking (RSB): A hierarchical symmetry-breaking structure in the solution space of spin glasses, indexed by steps k. "commonly referred to as `-step replica symmetry breaking'"
- Semidefinite programming (SDP): Convex optimization over the cone of positive semidefinite matrices, used for powerful relaxations. "using semi-definite programming \cite{boyd2004convex}"
- Sherrington–Kirkpatrick (SK) model: The canonical mean-field spin glass with Gaussian random couplings, equivalent to GOE interactions. "This is the celebrated SK model."
- State evolution: The deterministic recursion characterizing the asymptotic empirical law of AMP iterates. "The state evolution process is the stochastic process"
- Stochastic block model (SBM): A random graph model with communities where edge probabilities depend on community memberships. "balanced two-communities stochastic block model "
- Sum-of-squares hierarchy: A sequence of increasingly tight semidefinite relaxations capturing higher-moment constraints. "The sum-of-squares hierarchy"
- Sum-product algorithm: Another name for belief propagation, computing approximate marginals via local message updates. "known as sum-product algorithm or ‘belief propagation’."
- Survey propagation: A message-passing heuristic inspired by 1RSB physics for solving random constraint satisfaction problems. "The `survey propagation' algorithm"
- Wasserstein-2 distance: A metric on probability measures based on optimal transport with quadratic cost. "converges in (Wasserstein-$2$) distance"
Practical Applications
Practical Applications Derived from the Paper’s Findings and Methods
The following applications translate the paper’s key ideas—Parisi’s formula, message passing (BP), approximate message passing (AMP) with state evolution, and insights on convex relaxations—into concrete, sector-specific use cases. They are grouped into immediate deployments and longer-term opportunities that require further development or validation.
Immediate Applications
These can be deployed now with existing algorithms, numerical tools, and standard datasets, subject to the assumptions noted.
- High-dimensional denoising and estimation with AMP (software, telecom, recommenders)
- Use AMP with state evolution to perform low-rank matrix/tensor denoising, sparse recovery, and generalized linear estimation at scale (e.g., collaborative filtering, signal separation in sensor arrays, compressed sensing).
- Tools/workflows: implement separable AMP iterations with Onsager correction; calibrate performance and stopping via state evolution; integrate with Python/NumPy/PyTorch and GPU backends.
- Sectors: software (ML systems), telecom (massive MIMO detection), media platforms (recommenders), imaging (MRI/CT compressed sensing).
- Assumptions/dependencies: large-n regime; approximate orthogonal invariance or i.i.d. noise; Lipschitz nonlinearities; prior or empirical knowledge of signal distribution; accurate noise strength estimation (e.g., λ in spiked models).
- Community detection and hypothesis testing in networks (software, cybersecurity, healthcare, social platforms)
- Apply energy-based tests (ground state energy of bisection) to detect structure in graphs (e.g., presence of communities) using Parisi’s asymptotics as a null benchmark; then recover labels with BP/AMP methods or spectral pipelines.
- Tools/workflows: pipeline that computes relaxed cut scores (e.g., SDP or spectral), compares to calibrated thresholds informed by Parisi’s constant; if significant, run BP/AMP/EM-style refinement.
- Sectors: cybersecurity (intrusion or botnet subgraph detection), healthcare (patient stratification via co-expression networks), social platforms (community detection), enterprise IT (knowledge graph clustering).
- Assumptions/dependencies: graphs are “random-like” (Erdős–Rényi/SBM); balanced communities or known proportions; sparse to moderately dense regimes; robustness checks when data are not worst-case adversarial.
- Algorithm performance forecasting via state evolution (software engineering, data science platforms)
- Use state evolution to predict the convergence, correlation, and error curves of iterative estimators before deployment, enabling principled hyperparameter selection and compute budgeting.
- Tools/workflows: “State Evolution Simulator” that takes priors, noise levels, and nonlinearities
f_k, returns predicted correlations and risks; plug into AutoML or MLOps to guide algorithm selection. - Sectors: software (ML ops, AutoML), finance (risk modeling pipelines), telecom (decoder tuning).
- Assumptions/dependencies: validity of Gaussian or orthogonally invariant approximations; sufficiently large dimension; correct modeling of priors and noise.
- Massive MIMO and coded communications decoding with BP/AMP (telecom)
- Deploy BP/AMP receivers for massive MIMO and LDPC-like codes, exploiting message passing with Onsager corrections for faster convergence and predictable performance.
- Tools/workflows: integrate AMP/VAMP into baseband processing stacks; use state evolution to select thresholds and nonlinearities.
- Assumptions/dependencies: channel models close to random matrix ensembles; accurate SNR estimation; stable numerical routines for high throughput.
- Baseline combinatorial optimization with SDP and informed rounding (software, logistics)
- Use SDP relaxations and improved rounding heuristics (physics-inspired) to obtain practical solutions to max-cut/min-bisection in large, non-adversarial graphs (transport routing, partitioning workloads).
- Tools/workflows: semi-definite solvers (CVX/CVXOPT), spectral initializations, randomized rounding; empirical calibration against known benchmarks.
- Assumptions/dependencies: instances not adversarial; acceptance of approximate solutions without formal certificates in random-like regimes.
- Policy and governance guidance on algorithmic certification (policy, standards)
- Incorporate the paper’s insights that general-purpose polynomial-time certification/refutation (upper bounds valid for every instance) can be weak on random instances (e.g., SK), and encourage standards that assess average-case performance and probabilistic guarantees.
- Tools/workflows: benchmark suites emphasizing random-instance performance; guidelines for reporting probabilistic accuracy rather than worst-case-only certificates.
- Assumptions/dependencies: recognition that many real-world data are stochastic or random-like; willingness to adopt average-case evaluation frameworks.
Long-Term Applications
These require additional theoretical validation, scaling, or productization (e.g., stronger universality results, new proofs, robust implementations).
- Algorithmic Parisi formula–guided optimizers for binary quadratic problems (software, logistics, energy)
- Build practical algorithms that achieve near-optimal SK-like approximation ratios for max-cut/min-bisection in large, dense random-like graphs, using AMP-derived algorithmic Parisi approaches or convex methods inspired by ivkov (2024).
- Tools/products: “Algorithmic Parisi Optimizer” library for dense graph partitioning; hybrid AMP–convex routines; automatic threshold selection via PDE-based Parisi functional numerics.
- Sectors: energy (grid partitioning), logistics (hub clustering), software (graph partitioning for parallel computing).
- Assumptions/dependencies: “no-overlap gap” conjecture or related structural assumptions; robust numerical solvers for Parisi PDE; extension beyond SK universality to realistic graphs.
- Rigorous survey propagation and 1RSB-based solvers (software, operations research)
- Transition survey propagation from heuristic to rigorously understood solvers, enabling reliable performance on large random SAT-like instances and combinatorial search problems.
- Tools/products: stabilized SP solvers with convergence monitors; certified stopping criteria tied to structure; integration into industrial constraint solvers.
- Assumptions/dependencies: mathematical guarantees for SP in broader regimes; handling non-random or partially adversarial constraints.
- Scalable sampling in complex energy landscapes (ML, Bayesian inference, physics-informed AI)
- Leverage new progress on spectral gaps and phase transitions to design samplers that mix efficiently below critical temperatures and detect hard regimes automatically (adaptive annealing, tempering schemes).
- Tools/products: “Phase-Aware Sampler” that monitors effective temperature/complexity; automatic selection of annealing schedules using Parisi-informed phase diagrams.
- Sectors: ML (Bayesian posterior sampling), physics (spin systems), computational biology (posterior sampling in network models).
- Assumptions/dependencies: validated mixing-time predictions across models; diagnostic metrics correlating with theoretical thresholds; efficient GPU/TPU samplers.
- Finance and risk optimization in high dimensions via AMP and random matrix tools (finance)
- Use AMP/state evolution to design and analyze high-dimensional portfolio optimization and risk estimation (e.g., shrinkage strategies, factor models) with predictable out-of-sample behavior.
- Tools/products: “AMP Risk Planner” for asset allocation under heavy-tailed or correlated noise; performance dashboards fed by state-evolution forecasts.
- Assumptions/dependencies: appropriate random matrix modeling of returns/covariance; robustness to deviations from Gaussianity; regulatory acceptance of average-case methodologies.
- Biomedical network inference and stratification (healthcare)
- Apply AMP-based inference to reconstruct gene regulatory networks or patient similarity graphs; use Parisi-informed detection thresholds to decide when structure is present before running expensive estimators.
- Tools/workflows: scalable AMP modules for multi-omics integration; hypothesis tests using ground-state energy thresholds; clinician-facing dashboards for subgroup identification.
- Assumptions/dependencies: sufficient sample sizes for large-n asymptotics; data approximate random ensembles (after preprocessing); ethical and regulatory considerations.
- Robust general first-order methods designed via state evolution (software engineering, ML)
- Generalize AMP-guided design (optimal denoisers
h_k) to broader first-order algorithms (including non-separable updates), providing principled construction of iterations with provable finite-iteration optimality in random models. - Tools/products: “SE-based Optimizer Designer” that outputs update rules tailored to priors/noise; bridges to autodiff frameworks.
- Assumptions/dependencies: extended SE validity for non-Gaussian, semirandom, and non-separable settings; tractable identification of optimal nonlinearities; control beyond constant iterations.
- Generalize AMP-guided design (optimal denoisers
- Standards for average-case algorithm assessment and dataset curation (policy, academia)
- Create benchmark repositories and evaluation protocols centered on random-like instances to complement worst-case analyses, aligning practice with the paper’s insights on SDP/SoS limits and certification gaps.
- Tools/workflows: curated datasets emulating SBM/SK-like structures; reporting templates for average-case performance; incentives in grants/venues for probabilistic guarantees.
- Assumptions/dependencies: community adoption; careful design to avoid overfitting to specific random models; governance for transparency and reproducibility.
Each application relies on domain-appropriate modeling choices and the large-scale behavior underlying spin glass–inspired analyses. Deployments should explicitly check the assumptions (randomness/universality, dimensionality, prior calibration, noise characterization) and include fallback baselines (e.g., SDP or spectral) when conditions are violated.
Collections
Sign up for free to add this paper to one or more collections.