AI Must Embrace Specialization via Superhuman Adaptable Intelligence
Abstract: Everyone from AI executives and researchers to doomsayers, politicians, and activists is talking about AGI. Yet, they often don't seem to agree on its exact definition. One common definition of AGI is an AI that can do everything a human can do, but are humans truly general? In this paper, we address what's wrong with our conception of AGI, and why, even in its most coherent formulation, it is a flawed concept to describe the future of AI. We explore whether the most widely accepted definitions are plausible, useful, and truly general. We argue that AI must embrace specialization, rather than strive for generality, and in its specialization strive for superhuman performance, and introduce Superhuman Adaptable Intelligence (SAI). SAI is defined as intelligence that can learn to exceed humans at anything important that we can do, and that can fill in the skill gaps where humans are incapable. We then lay out how SAI can help hone a discussion around AI that was blurred by an overloaded definition of AGI, and extrapolate the implications of using it as a guide for the future.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper argues that we should stop chasing “AGI” (Artificial General Intelligence) as “a machine that can do everything a human can.” The authors say humans aren’t actually “general,” and aiming for that idea confuses people and slows real progress. Instead, they propose a clearer goal called Superhuman Adaptable Intelligence (SAI): AI that can quickly learn to beat humans at any important task we can do—and also learn to assign value to and perform useful tasks humans can’t do at all.
Key Questions the Paper Asks
- Are humans really a good example of “general” intelligence?
- Do current definitions of AGI make sense, help us plan research, and let us measure progress?
- If “being general at everything” isn’t realistic or even necessary, what should our new goal for AI be?
- How could we build and evaluate that kind of AI in practice?
How the Authors Approach the Problem
The paper is a position piece (an argument), not an experiment. Here’s what they do:
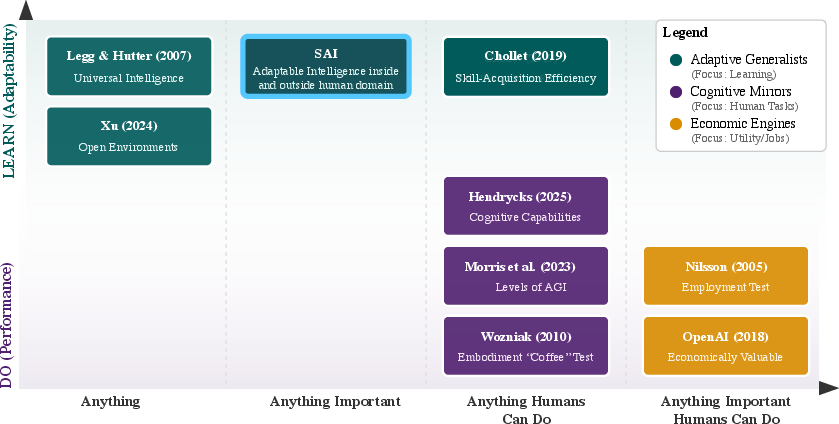
- They examine popular definitions of AGI and organize them on two simple axes:
- Learn vs. Do: Does the system learn new tasks quickly, or is it judged only on what it can do right away?
- Scope: Is the system meant for literally anything, anything important, anything humans can do, or just economically valuable tasks?
- They set three commonsense rules for a good definition of progress: 1) Feasible: Is it possible with limited time, data, and computing? 2) Consistent: Does “general” actually mean general, not just “human-like”? 3) Measurable: Can we track improvement with clear numbers?
- They bring in ideas from biology and computer science to argue that specialization works best when resources are limited:
- No Free Lunch: There’s no single best method for every problem—like expecting one pair of shoes to be perfect for running, hiking, and ballet.
- Specialization beats spread-thin generality: Like pro athletes who train for one sport, specialized systems perform better in their domain.
- Negative transfer: Learning many unrelated things together can hurt performance on each.
- They propose a new “North Star” called SAI and a simple way to measure it: how fast an AI can learn new, important tasks.
- They suggest practical paths toward SAI, such as:
- Self-supervised learning (SSL): Learning patterns from raw data without human labels, like a student learning grammar by reading tons of books and spotting what “sounds right.”
- World models: Internal “mini-simulators” of how the world works, like a mental physics engine that helps plan ahead and adapt quickly.
- Modular, specialized systems: Composing many specialists rather than forcing one model to do everything.
Main Findings and Why They Matter
- Humans aren’t truly “general”: We’re amazingly adaptable within a narrow slice of tasks that mattered for our survival (walking, seeing, planning), but we’re weak or incapable in many others. For instance, computers easily beat the best chess players; bats use echolocation, and humans can’t.
- The term “AGI” is overloaded and inconsistent: Different groups mean different things, from “human-like at most tasks” to “better than humans at economically valuable jobs.” This muddles the debate and makes it hard to measure progress.
- Most AGI definitions fail one of the authors’ three rules:
- Not feasible (tries to cover literally everything with limited resources),
- Not consistent (calls human-like performance “general” even though it isn’t),
- Not measurable (depends on ever-growing lists of tasks).
- Specialization wins in practice: In nature, markets, and AI, focusing energy on specific goals works better than trying to be okay at everything. Even “big” AI models often work best by routing different inputs to different expert parts.
- A better goal: Superhuman Adaptable Intelligence (SAI)
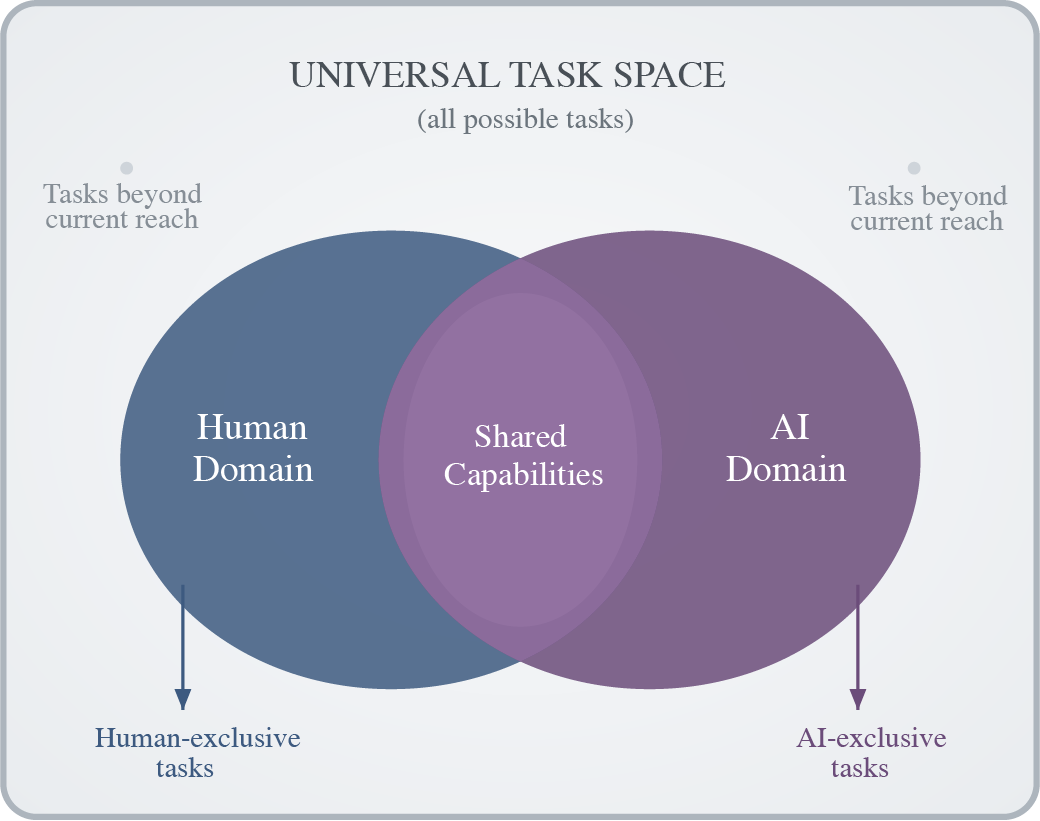
- Definition: AI that can adapt to surpass humans on any task we can do that matters, and also adapt to useful tasks outside human ability.
- Metric: Speed of adaptation—how fast it learns new, important tasks.
- Likely ingredients for SAI:
- Self-supervised learning to build broad, reusable knowledge without needing lots of labeled examples.
- World models to support planning, zero- or few-shot learning, and quick transfer to new tasks.
- Diversity and modularity, not one “model to rule them all.”
Why it matters: Shifting from “be like humans at everything” to “learn fast and specialize where it counts” gives AI research a clearer, testable target. It helps avoid hype and fear, encourages practical progress, and leads to systems that are both more capable and more reliable where it matters.
Implications and Potential Impact
- Clearer goals and evaluations: Focusing on adaptation speed makes progress measurable. We can ask, “How quickly did the system learn this new important task?” rather than chasing endless checklists.
- Better real-world performance: Specialized, modular AIs can reach superhuman performance in high-impact areas like science, medicine, engineering, and logistics—sometimes far beyond human limits.
- Smarter research strategy: Encourages a variety of architectures and methods (not just one dominant approach), speeding innovation and reducing “everyone doing the same thing.”
- Safer and more useful AI: Building specialists for specific tasks can make systems more dependable and easier to control than one generalist meant to do everything.
In short: Don’t build one AI to fold both proteins and laundry. Build fast-learning specialists that can adapt to important tasks, outperform humans where needed, and take on useful jobs we can’t do at all. That’s Superhuman Adaptable Intelligence.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, formulated to guide actionable future research.
- Precise formalization of SAI: a mathematical definition of “adaptation speed” including units, normalization across tasks, and explicit resource budgets (compute, time, data, memory) and priors.
- Operational definition of “utility” and “importance”: criteria, measurement frameworks (e.g., economic value, societal impact, safety-criticality), and processes for task selection that are transparent, robust, and non-anthropocentric.
- Evaluation of “exceeding humans”: concrete, consistent metrics for cognitive and physical tasks; protocols for tasks without human baselines; standards for tasks outside the human domain.
- SAI benchmark suite: standardized, continually refreshed task distributions; reproducible zero-/few-shot protocols; fixed and reported budgets for data, compute, and wall-clock time; methods to generate genuinely novel tasks.
- Empirical validation of SAI pathways: comparative studies demonstrating that SSL, latent prediction, and world models reduce adaptation time versus SL, RL, and autoregressive baselines across diverse domains.
- Architecture for modular specialization: concrete designs for routing, meta-control, inter-module communication, shared latent spaces, and composition strategies that preserve specialist gains while enabling coordination.
- Managing negative transfer and interference: training strategies, curricula, and theoretical bounds to mitigate cross-task gradient conflicts, catastrophic forgetting, and representational competition.
- World model requirements: target properties (causality, counterfactual consistency, uncertainty calibration), learning objectives, planning interfaces, fidelity metrics, and rigorous sim-to-real transfer evaluations.
- Latent- vs token-level prediction: task-conditional criteria for when latent prediction yields faster adaptation; ablations and diagnostics quantifying benefits and failure modes relative to token-level models.
- Long-horizon error compounding in autoregression: formal quantification of divergence, conditions under which it arises, and tested mitigations (e.g., plans-in-latent, hierarchical controllers).
- Scaling laws for adaptation: empirical and theoretical relationships between model size, data diversity, compute, and adaptation speed; identification of diminishing returns and optimal scaling regimes.
- Resource-aware SAI: frameworks to trade off adaptation speed, accuracy, energy, and monetary cost; dynamic scheduling of specialists under real constraints.
- Safety, alignment, and governance for specialists: risks from composing specialized modules; meta-controller oversight; misuse prevention; evaluation protocols and fail-safe mechanisms tailored to specialization.
- Robustness and reliability: adaptation under distribution shift, partial observability, adversarial conditions; certification methods and guarantees for rapidly adapted capabilities.
- Discovering “outside human domain” tasks: systematic approaches to identify high-utility non-human tasks; ground-truth construction and outcome-based evaluation where human baselines do not exist.
- Embodiment and physical tasks: requirements for data, simulation fidelity, tactile sensing, morphology, and control; sim-to-real adaptation speed metrics for robotics and dexterous manipulation.
- Cross-modal adaptation: mechanisms for transferring competence across language, vision, audio, action, and symbol manipulation; shared representations and alignment objectives.
- Interpretability of specialists and world models: tools to inspect latent states, plans, and policies; methods to detect and explain failure modes during rapid adaptation.
- Human–AI co-adaptation: interfaces and protocols for teaching specialists; measuring how human guidance affects adaptation speed and reliability.
- Consistency of SAI scope with infeasibility arguments: reconciliation of “exceed humans at any task humans can do” with finite resources; principled scope-limiting strategies (task importance filters, budget-aware selection).
- Task-space ontology: formalization and measurement of the human vs AI vs universal task overlaps depicted; methods to quantify coverage, gaps, and progress toward utility-relevant regions.
- Data acquisition for fast adaptation: active learning policies, synthetic data generation, task simulators, and data quality metrics tuned to adaptation speed rather than static performance.
- Normalizing adaptation metrics across heterogeneous tasks: standards to compare speeds across tasks with different priors, difficulty, observability, and data availability; meta-metrics for fairness and comparability.
- Concrete roadmap and milestones: staged targets (e.g., adapt to N novel tasks per fixed budget and time), public leaderboards, and open benchmarks to catalyze progress.
- Comparative analysis with AGI definitions: empirical tests demonstrating practical advantages of SAI over AGI-style goals in feasibility, consistency, and assessability; decision-making implications for research and policy.
Practical Applications
Immediate Applications
The following applications can be implemented with current methods and infrastructure by emphasizing specialization, self-supervised learning, world models in narrow domains, and measurable adaptation speed.
- Specialized AI portfolios in industry
- Sectors: software, healthcare, finance, manufacturing, logistics
- Application: Replace “one general model” strategies with portfolios of domain-specific models routed by task; deploy expert models for coding assistants, radiology reads, fraud detection, demand forecasting, and quality control.
- Tools/workflows: Mixture-of-Experts routing, model registries, service-level specialization, task taxonomies, capability scoping; fine-tuning and distillation pipelines for narrow tasks; retrieval-augmented inference.
- Assumptions/dependencies: Reliable task segmentation, robust routing accuracy, observability, drift monitoring, and governance to prevent negative transfer.
- Adaptation-speed benchmarking as a KPI
- Sectors: academia, software platforms, model evaluation labs
- Application: Evaluate models by time/data/compute required to reach target performance on new tasks; add “time-to-competence” benchmarks to leaderboards and procurement criteria.
- Tools/workflows: Evaluation harnesses, standardized datasets with staged task novelties, A/B testing of training schedules, compute-normalized reporting; runbooks for reproducibility.
- Assumptions/dependencies: Agreement on utility-relevant task sets, standardized metric definitions, reproducible training environments.
- SSL-first data pipelines in enterprise AI
- Sectors: healthcare imaging, industrial IoT, retail, telecom, security
- Application: Pretrain models on large unlabeled corpora (text, images, sensor streams) to reduce label dependence and accelerate fine-tuning for specialized tasks.
- Tools/workflows: SimCLR, BYOL, masked autoencoders, JEPA-style implementations; data lake connectors; privacy-preserving pretraining (DP, federated learning).
- Assumptions/dependencies: Access to compliant unlabeled data, data quality controls, privacy/regulatory adherence.
- World-model-based planning in constrained environments
- Sectors: robotics (warehouses, micro-fulfillment), gaming/simulation, autonomous inspection
- Application: Use latent world models for short-horizon planning in well-specified domains (navigation, pick-and-place, path optimization) to improve sample efficiency and stability.
- Tools/workflows: Dreamer 4, Genie 2, model predictive control, safety cages; synthetic scenario generation.
- Assumptions/dependencies: Accurate simulators for target environments, robust sim-to-real transfer, human oversight for safety.
- Modular orchestration and routing in MLOps
- Sectors: software, cloud providers, platform teams
- Application: Introduce an inference router that dispatches tasks to specialized models; track cost/performance per specialist; enforce capability boundaries.
- Tools/workflows: API gateways, function calling and skill routing, service meshes, monitoring dashboards, cost-aware planners.
- Assumptions/dependencies: Latency/throughput budgets, reliable fallback paths, audit trails.
- Domain-specific assistants with scoped capabilities
- Sectors: healthcare (radiology triage), law (research), finance (quant analytics), security (threat intel)
- Application: Deploy assistants specialized to the modalities, data structures, and objectives of a given profession; evaluate by adaptation speed to new sub-tasks (new guidelines, instruments, asset classes).
- Tools/workflows: Fine-tuned LLM/LMM stacks, retrieval with domain ontologies, constrained tool-use, checklists; continual learning pipelines.
- Assumptions/dependencies: Domain data access, regulatory compliance (HIPAA, SOX, GDPR), strong human-in-the-loop practices.
- Specialist-first procurement and reporting (policy)
- Sectors: government, public institutions, regulated industries
- Application: Require adaptation-speed metrics, scope declarations, and negative-transfer risk assessments in RFPs and vendor evaluations.
- Tools/workflows: Standardized audit templates, capability-scoping documentation, incident reporting for misrouting.
- Assumptions/dependencies: Consensus on reporting standards; integration with existing procurement frameworks.
- Education modules on specialization and meta-learning
- Sectors: higher ed, professional training, bootcamps
- Application: Teach specialization strategy, task decomposition, and adaptation-speed measurement; incorporate rapid skill acquisition labs.
- Tools/workflows: Adaptive tutoring systems, benchmarked mini-projects, curriculum on SSL/world models.
- Assumptions/dependencies: Instructor upskilling, assessment alignment, access to sandbox data.
- Capability scoping for AI risk management
- Sectors: all high-stakes deployments
- Application: Limit overreach by generalists; use gated deployment workflows to ensure specialists operate within validated domains.
- Tools/workflows: Capability maps, red-teaming focused on misrouting/negative transfer, policy gates.
- Assumptions/dependencies: Governance buy-in, clear utility definitions, incident response processes.
Long-Term Applications
These applications require further research, scaling, or integration—particularly mature world models, meta-learning, robust safety/verification, and standards for adaptation-speed evaluation.
- Superhuman Adaptable Intelligence (SAI) agents across utility domains
- Sectors: scientific R&D, engineering design, legal analysis, complex operations
- Application: Agents that rapidly acquire and exceed human capabilities on important tasks and fill human skill gaps (e.g., high-dimensional optimization, complex mechanistic modeling).
- Tools/workflows: Scalable SSL, powerful latent world models, meta-learning for rapid adaptation, simulation/self-play ecosystems.
- Assumptions/dependencies: Massive compute/data, benchmark suites for adaptation speed, strong safety and governance frameworks.
- Automated scientific discovery pipelines
- Sectors: drug discovery, materials science, synthetic biology
- Application: World-model-driven hypothesis generation and experiment planning; closed-loop labs with robotic execution and rapid model adaptation to new assays.
- Tools/workflows: Lab automation, multi-scale simulators, active learning, experiment schedulers.
- Assumptions/dependencies: High-fidelity simulators, standardized lab interfaces, trustworthy causal inference.
- Few-shot adaptive household/service robotics
- Sectors: consumer robotics, eldercare, hospitality
- Application: Robots that learn new tasks in minutes (new appliances, tools, surfaces) via latent world models and compositional skill libraries.
- Tools/workflows: Skill primitives, safe teleoperation for teaching, on-device adaptation, formal safety envelopes.
- Assumptions/dependencies: Robust hardware, reliable perception, safety certification, user training protocols.
- Patient-specific adaptive medicine
- Sectors: healthcare
- Application: Multi-modal models that adapt rapidly to patient-specific trajectories for diagnosis, treatment planning, and monitoring.
- Tools/workflows: EHR integration, imaging/genomics fusion, continual learning under privacy constraints.
- Assumptions/dependencies: Secure data access, FDA/EMA pathways, bias and fairness controls, real-world evidence.
- Adaptive grid and infrastructure optimization
- Sectors: energy, transportation, urban planning
- Application: World-models of grids and networks that adapt to shocks (weather, demand spikes) and reconfigure control strategies in few-shot settings.
- Tools/workflows: Digital twins, online optimization, safety-constrained planners.
- Assumptions/dependencies: Comprehensive sensor coverage, regulatory approval, cyber-resilience.
- Real-time systemic risk and market adaptation
- Sectors: finance
- Application: Specialized agents that adapt to regime shifts, liquidity squeezes, and novel instruments; stress-testing via multi-agent simulations.
- Tools/workflows: Market world models, scenario generators, adaptive hedging.
- Assumptions/dependencies: Timely, high-quality data; compliance (MiFID, SEC), robust model governance.
- SAI-powered education: personal adaptive tutors
- Sectors: education
- Application: Tutors optimizing a learner’s “time-to-competence,” adapting curricula and modalities to individual cognitive profiles.
- Tools/workflows: Meta-learning on pedagogical strategies, learning analytics, content generation aligned to utility.
- Assumptions/dependencies: Privacy-preserving data pipelines, pedagogy validation, equity safeguards.
- Standards for adaptation-speed metrics and reporting (policy)
- Sectors: standards bodies, regulators, industry consortia
- Application: ISO-like standards for adaptation-speed measurement, scope declarations, negative-transfer auditing; certification for specialist systems.
- Tools/workflows: Benchmark catalogs, audit protocols, common data/compute normalization.
- Assumptions/dependencies: Multi-stakeholder consensus, international coordination, enforcement mechanisms.
- Platforms for specialization orchestration
- Sectors: cloud/software
- Application: End-to-end platforms to compose, route, monitor, and govern specialist models; marketplaces for domain experts and task packs.
- Tools/workflows: Orchestration runtimes, policy engines, cost/performance optimizers, model provenance tracking.
- Assumptions/dependencies: Interoperability standards, vendor-neutral APIs, security and billing infrastructure.
- Formal safety and verification for adaptable systems
- Sectors: safety-critical AI
- Application: Methods to verify behavior as models adapt, including guarantees on capability boundaries and mitigation of compounding errors in long-horizon plans.
- Tools/workflows: Formal methods integrated with learning, interpretable latent dynamics, runtime monitors.
- Assumptions/dependencies: New theory and tooling, accepted certification processes, testbeds.
- Workforce co-adaptation and job design
- Sectors: HR, operations, professional services
- Application: Redesign roles to leverage specialist AI; train workers to compose specialists; measure team-level adaptation speed.
- Tools/workflows: Skill-routing frameworks, competency maps, continuous training ecosystems.
- Assumptions/dependencies: Change management, labor agreements, reskilling programs.
Glossary
- Adaptation speed: The rate at which an AI acquires new skills or learns new tasks. Example: "Finally, adaptation speed---the speed with which an agent can acquire new skills and learn new tasks, can be measured"
- AGI (Artificial General Intelligence): A proposed form of AI aiming for broad, human-like generality across tasks. Example: "Central to all of these views is the concept of Artificial General Intelligence or AGI."
- anthropocentric: Human-centered; focusing evaluation or goals around human tasks and constraints. Example: "limiting evaluation to anthropocentric tasks and constraints."
- autoregressive models: Sequence models that predict the next token given previous tokens. Example: "GPTs and similar autoregressive models are no exception, they have many flaws"
- bitter lesson: The idea that general methods leveraging computation tend to outperform approaches relying on hand-crafted domain knowledge. Example: "this claim does not dispute the bitter lesson"
- Coffee Test: A proposed embodied benchmark for AI: making a cup of coffee in an unfamiliar kitchen. Example: "Steve Wozniak's Coffee Test---whether a machine could make a cup of coffee if sent to a random kitchen---"
- Dreamer 4: A latent world-model-based reinforcement learning architecture for prediction and control. Example: "such as Dreamer 4, Genie 2, or Joint Embedding Prediction Architecture (JEPA)"
- embedding space: A continuous vector space representing data in compact form, used for learning and prediction. Example: "learning in the embedding space as opposed to in the token space may drive performance gains"
- evolutionary mismatch hypothesis: The view that traits adapted for past environments can be maladaptive in modern contexts. Example: "the evolutionary mismatch hypothesis argues that many psychological mechanisms were tuned for past selection regimes and can therefore produce maladaptive outputs in contemporary environments"
- few-shot adaptation: Adapting to a new task using only a small number of examples. Example: "it is the hallmark of zero shot and few shot adaptation"
- Genie 2: A latent world-model/prediction architecture for interactive environments. Example: "such as Dreamer 4, Genie 2, or Joint Embedding Prediction Architecture (JEPA)"
- JEPA (Joint Embedding Prediction Architecture): A framework that learns to predict future or missing information by aligning embeddings rather than reconstructing tokens. Example: "such as Dreamer 4, Genie 2, or Joint Embedding Prediction Architecture (JEPA)"
- latent prediction architectures: Models that predict in compact latent spaces instead of raw pixels/tokens. Example: "moving from token level prediction to latent prediction architectures such as Dreamer 4, Genie 2, or Joint Embedding Prediction Architecture (JEPA)"
- LLMs: Large neural models trained on text to perform language tasks. Example: "Autoregressive LLMs and LMMs have become the dominant architecture"
- LMMs (Large Multimodal Models): Models that handle multiple modalities (e.g., text, images) jointly. Example: "Autoregressive LLMs and LMMs have become the dominant architecture"
- meta learning: Methods that learn to learn, enabling fast adaptation to new tasks. Example: "Designing maximally adaptable algorithms remains a central pursuit of meta learning"
- Moravec's Paradox: The observation that tasks easy for humans (e.g., perception, locomotion) are hard for machines, and vice versa. Example: "This observation has given rise to Moravec's Paradox,"
- negative transfer: When training on additional tasks or data harms performance on a target task. Example: "it can lead to 'negative transfer' when tasks compete for representational capacity"
- No Free Lunch theorem: The result that no single algorithm is best across all possible problems/distributions. Example: "fall prey to the 'No Free Lunch' theorem"
- probabilistic planning: Planning under uncertainty in stochastic environments. Example: "and probabilistic planning inherits similarly severe complexity barriers"
- propositional STRIPS: A classical planning formalism defining actions via preconditions and effects in propositional logic. Example: "(e.g., propositional STRIPS variants)"
- qualia: Subjective, first-person experiential qualities associated with consciousness. Example: "if it lacks subjective experience (qualia)"
- routing (to specialized parameters): Mechanisms that direct inputs to specific subsets of model parameters (modules/experts). Example: "Models that route queries to specialized subsets of model parameters depending on the task"
- SAI (Superhuman Adaptable Intelligence): The paper’s proposed goal: AI that adapts to exceed humans on important tasks, including beyond the human domain. Example: "We refer to this as Superhuman Adaptable Intelligence (SAI)."
- self-play: Training by having agents play against themselves to improve performance. Example: "improve through self-play, evolutionary search, or large-scale exploration in simulation"
- self-supervised learning (SSL): Learning from unlabeled data by predicting parts of the data from other parts. Example: "self-supervised learning (SSL) as a promising way to acquire generic knowledge"
- SOTA (state of the art): The best known performance achieved to date on a task/domain. Example: "has reached SOTA performance in most domains."
- state (in dynamical systems/MDPs): The sufficient information about the environment needed to predict future dynamics or make optimal decisions. Example: "Pixels are not state."
- token space: The discrete symbol space (e.g., text tokens) in which autoregressive models predict. Example: "in the token space"
- Turing Machine: An abstract model of computation used to define computability and complexity; Turing-completeness implies the ability to compute any computable function given resources. Example: "general in the Turing Machine sense"
- Turing Test: A conversational test of machine intelligence via indistinguishability from human responses. Example: "Language-based tests, such as the Turing Test, where a machine has to pretend to be a human"
- Universal Intelligence: A formal definition measuring an agent’s ability to achieve goals across all computable environments. Example: "Universal Intelligence refers to the ability to act intelligently over all computable environments"
- Winograd Schema Challenge: A benchmark for commonsense reasoning using pronoun disambiguation in paired sentences. Example: "the Winograd schema challenge that tests common-sense reasoning and natural language understanding"
- world model: An internal predictive model of environment dynamics enabling simulation and planning. Example: "A world model allows for simulation, and therefore planning"
- zero-shot task transfer: Applying learned knowledge to a new task without any task-specific training/examples. Example: "zero-shot task transfer"
Collections
Sign up for free to add this paper to one or more collections.