- The paper introduces a unified framework that formalizes uncertainty quantification in reward models for RLHF, integrating accuracy and calibration metrics.
- It benchmarks four distinct UQ architectures (ENS-MLP, ENS-LoRA, MCD-DPO, BAY-LIN) across varied LLM scales, highlighting the benefits of task-aligned initialization.
- The results underscore practical tradeoffs between overconfident predictions and calibration, offering actionable insights for safer RLHF deployment.
RewardUQ: A Unified Evaluation Framework for Uncertainty-Aware Reward Models
Introduction
RewardUQ introduces a unified, systematic framework to evaluate uncertainty quantification (UQ) methods for reward modeling in RLHF contexts. The work responds to the increasing reliance on reward models to align LLMs with human preferences but highlights the epistemic uncertainty that arises due to limited or noisy human annotations. Despite the promise of UQ both for refining data collection and for mitigating reward overoptimization, previous research often used a single method in isolation and lacked standardized evaluation. RewardUQ formalizes the UQ problem, standardizes existing approaches, proposes comprehensive accuracy and calibration metrics, and empirically benchmarks leading UQ algorithms across architectures, datasets, and model scales.
Reward Modeling with Uncertainty Quantification
Reward models in RLHF are conventionally trained from datasets of pairwise human preferences using a parameterization such as the Bradley-Terry model. These models predict the relative preference between completions, but pointwise predictions ignore the inherent epistemic uncertainty due to the limited coverage of the reward model over the vast space of possible completions.
RewardUQ analytically distinguishes between metrics that evaluate "accuracy"—including win rate and correctness-confident cross-classification rates—and "calibration"—such as expected calibration error (ECE) and expected bound calibration error (EBCE). Of particular note is the ranking score introduced, which combines measures of accuracy and uncertainty to yield an operational metric sensitive both to confident correct predictions and robust to overconfident errors.
Overview of UQ Architectures for Reward Models
RewardUQ encompasses and benchmarks four major classes of uncertainty-aware reward models:
- MLP Head Ensemble (ENS-MLP): Ensembles of MLP heads atop frozen LLM embeddings, where epistemic uncertainty is estimated via variance across heads.
- LoRA Adapter Ensemble (ENS-LoRA): Ensembles train modular LoRA adapters for scalability while capturing parameter uncertainty via multiple low-rank adapted models.
- DPO-based MC Dropout (MCD-DPO): Leverages MC dropout at inference in fine-tuned LLMs to implicitly compute uncertainty via stochasticity in reward extraction from policy heads.
- Bayesian Linear Head (BAY-LIN): Poses the reward head as a Bayesian linear regressor with Laplace approximation for the posterior, allowing analytic estimation of predictive uncertainty.
Each approach is distinguished by differing tradeoffs between model finetuning flexibility, computational cost, and the quality of uncertainty estimates. The framework standardizes the quantification of confidence bounds for all models, enabling apples-to-apples comparison.
Experimental Methodology
RewardUQ conducts a unified benchmarking campaign across multiple public preference datasets (UltraFeedback, Skywork, Tulu 3), several LLM backbone families (Qwen3 base, Skywork task-aligned), a sweep of model scales (0.6B to 32B parameters), and the full suite of UQ methods described above. Hyperparameters and architecture-specific regularizations are consistently optimized under calibration-based constraints, followed by final ranking on RewardBench. This isolation of UQ performance, decoupled from RL fine-tuning confounds, prioritizes intrinsic evaluation relevant for both downstream RL and active learning use cases.
Comparative Results
Across all settings, no single UQ method is universally superior. Rather, ranking score is determined principally by base model initialization, with task-aligned reward models yielding consistently higher accuracy and more reliable uncertainty signals, especially for fixed-feature architectures such as ENS-MLP and BAY-LIN. Finetuning-based approaches (ENS-LoRA, MCD-DPO) show robustness to non-aligned initialization, but their advantage diminishes as model scale increases.
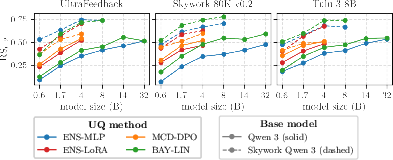
Figure 1: Model ranking scores (RS0.2) on RewardBench as a function of UQ methodology, dataset, and base model.
Additionally, increasing model size results in diminishing improvements to the ranking score, which is attributed to the increasing overconfidence of large LLMs—a phenomenon penalized by metrics that reward calibrated uncertainty. BAY-LIN is the top performer in the majority of cases, but is surpassed by ENS-MLP on certain datasets, establishing that optimal choice remains instance-dependent.
Calibration of Probability and Confidence Bounds
All examined UQ models achieve ECE below 0.1 and EBCE below 0.01, indicating satisfactory global calibration. Notably, smaller models are less confident—probabilities are concentrated around 0.5—while overconfidence emerges with scale, especially for architectures relying on frozen, non-task-aligned embeddings.
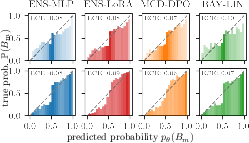
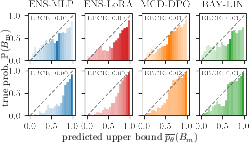
Figure 2: Calibration diagnostics for predicted probabilities on different model scales and base UQ techniques.
Decomposition of Accuracy Metrics
Disaggregating the ranking score shows that task-aligned initialization elevates confident true prediction rates and suppresses confident false classifications, marking a dual role for model selection.
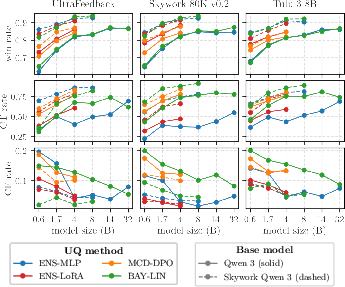
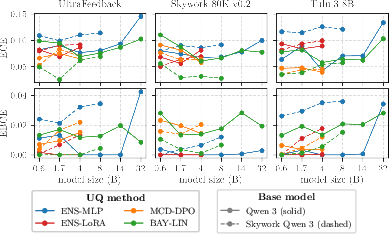
Figure 3: Breakdown of accuracy (win rate, confident-true, and confident-false rates) for each UQ method and setting.
Theoretical Implications
RewardUQ's unified metrics make explicit the tradeoff space between confident exploration (active learning, data curation) and safe exploitation (robust RLHF alignment). The empirical evidence underscores the critical importance of task-aligned base models (i.e., reward-specialized embeddings) for producing meaningful uncertainty estimates in fixed-head approaches. These results challenge the default use of generic LLM backbones in uncertainty-sensitive applications.
Additionally, RewardUQ's framework formalizes subtle aspects of preference learning, such as the antisymmetry of confidence intervals for preference relations and the inherent coupling between calibration error metrics for upper and lower bounds. This enables a deeper theoretical understanding of what constitutes epistemic uncertainty in the context of pairwise reward modeling.
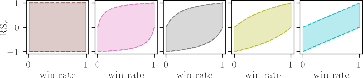
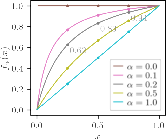
Figure 4: Distribution ranges of ranking scores, highlighting effects of architecture and initialization.
Practical Implications and Outlook
Practically, organizations developing RLHF pipelines should prioritize both reward-task-aligned models and rigorous calibration testing before deploying uncertainty-based sample selection, annotation-budgeted learning, or uncertainty-penalized RL objectives. The open-source RewardUQ library lowers the activation energy for reproducible benchmarking and future algorithmic advances in this space.
Looking ahead, further research should explore the generalization of findings across model families, reward function classes (beyond scalar alignments), and the tight coupling of UQ property selection with real-world RL loop outcomes. Moreover, theoretical decomposition of epistemic versus aleatoric sources in reward preference modeling remains underdeveloped, especially in the high-dimensional LLM regime.
Conclusion
RewardUQ provides the first standardized, methodologically rigorous framework for benchmarking uncertainty quantification in reward models for LLM alignment. By carefully decomposing accuracy and calibration, introducing robust operational ranking metrics, and subjecting modern UQ methods to broad empirical assessment, the work reveals that base model initialization outweighs architectural choices and that no single method is "best" independently of context. The release of RewardUQ as an open framework is expected to accelerate progress toward practical, safe, and efficient alignment solutions in the evolving landscape of uncertainty-aware machine learning.