A Variational Estimator for $L_p$ Calibration Errors
Published 27 Feb 2026 in stat.ML and cs.LG | (2602.24230v1)
Abstract: Calibration$\unicode{x2014}$the problem of ensuring that predicted probabilities align with observed class frequencies$\unicode{x2014}$is a basic desideratum for reliable prediction with machine learning systems. Calibration error is traditionally assessed via a divergence function, using the expected divergence between predictions and empirical frequencies. Accurately estimating this quantity is challenging, especially in the multiclass setting. Here, we show how to extend a recent variational framework for estimating calibration errors beyond divergences induced induced by proper losses, to cover a broad class of calibration errors induced by $L_p$ divergences. Our method can separate over- and under-confidence and, unlike non-variational approaches, avoids overestimation. We provide extensive experiments and integrate our code in the open-source package probmetrics (https://github.com/dholzmueller/probmetrics) for evaluating calibration errors.
The paper proposes a variational estimator that accurately quantifies calibration errors defined by L_p norms, overcoming biases associated with traditional binning methods.
It employs cross-validation to separate training and evaluation data, ensuring unbiased lower-bound estimates and rapid convergence with fewer samples.
Empirical results demonstrate that the method outperforms standard techniques in both binary and multiclass scenarios, enabling refined calibration analysis.
Variational Estimation of Lp Calibration Errors in Classification
Problem Formulation and Background
Calibration is a fundamental requirement in predictive modeling, where the predicted probability vector returned by a classifier, f(X)∈Δk, is expected to align with true outcome frequencies, quantified via the conditional expectation C=E[Y∣f(X)]. A classifier is perfectly calibrated when f(X)=C, almost surely. Calibration errors, denoted CEd(f)=E[d(f(X),C)], are commonly measured using divergence-based metrics such as L1 or L2 norms, as well as those induced by proper losses (e.g., Brier score, log-loss). However, estimating calibration errors accurately—especially in multiclass settings—remains a nontrivial challenge due to the curse of dimensionality, binning inconsistency, and the difficulty of estimating C.
The traditional estimator, Expected Calibration Error (ECE), employs binning, which is known to be biased, inconsistent, and not extendable to non-binning metrics in multiclass regimes. Recent work [berta2025rethinking] introduced variational approaches for proper calibration error estimation leveraging empirical risk minimization with cross-validation, sidestepping overestimation and yielding unbiased lower bounds on the true calibration error. The present paper generalizes these variational estimators to include calibration errors induced by arbitrary Lp norms, providing a theoretically grounded extension beyond proper losses.
Theoretical Framework and Variational Estimator Construction
The paper rigorously formalizes calibration error estimation via variational methods, relying on the decomposition of expected risk under proper losses: E[ℓ(f(X),Y)]=E[dℓ(f(X),C)]+E[eℓ(C)], where dℓ is the divergence induced by proper loss ℓ. Crucially, the variational estimator of calibration error can be written as the gap between risks for f and a recalibrated predictor g⋆∘f, with g⋆ defined via conditional expectation. Empirically, one estimates g⋆ by fitting a classifier g^ to predict Y given f(X), then computes:
Cross-validation is employed to separate training and evaluation data, ensuring unbiasedness and preventing overestimation due to overfitting. This process guarantees, in expectation, a lower bound for the true calibration error.
For Lp calibration errors, which do not arise directly from proper losses, the paper extends the framework by constructing "proper losses" parameterized by f(X) that recover Lp distances in expectation by a variational formulation. Explicitly, for p≥1, they define:
$\ell_{f(X)}(z, Y) = \mathds{1}_{z \neq f(X)} \langle \nabla_z \| z - f(X) \|_p, f(X) - Y \rangle$
and demonstrate (Proposition 1) that the expected gap yields the desired calibration error:
CE∥⋅∥p(f)=E[ℓf(X)(f(X),Y)−ℓf(X)(g⋆∘f(X),Y)]
This construction is shown to generalize to any convex distance function, substantially broadening the scope of variational calibration error estimation.
Experimental Results and Empirical Evaluation
The paper presents a comprehensive suite of experiments evaluating the variational estimators for both binary and multiclass scenarios. Synthetic datasets with known calibration functions are employed as ground truth, enabling precise comparisons. Key findings include:
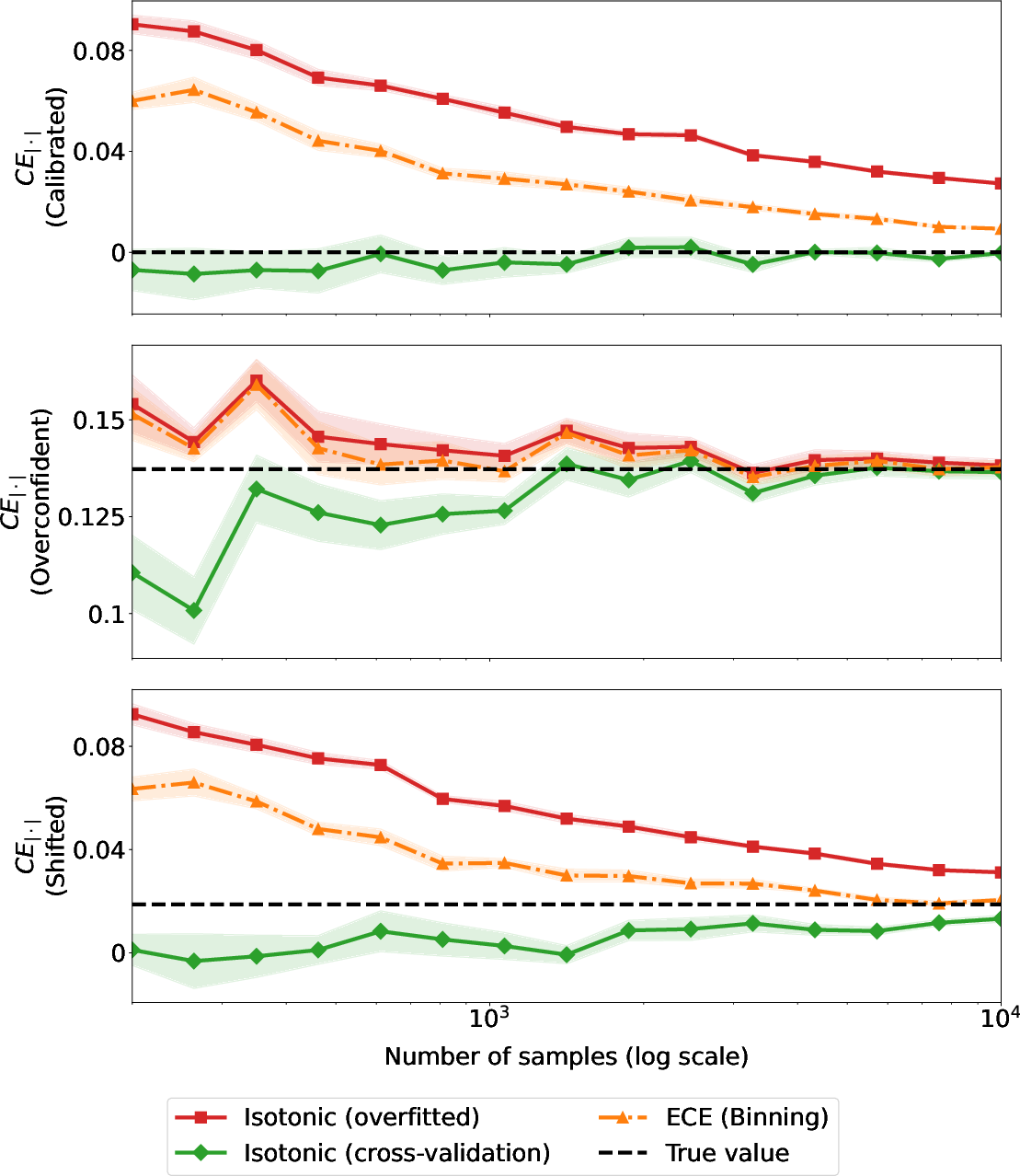
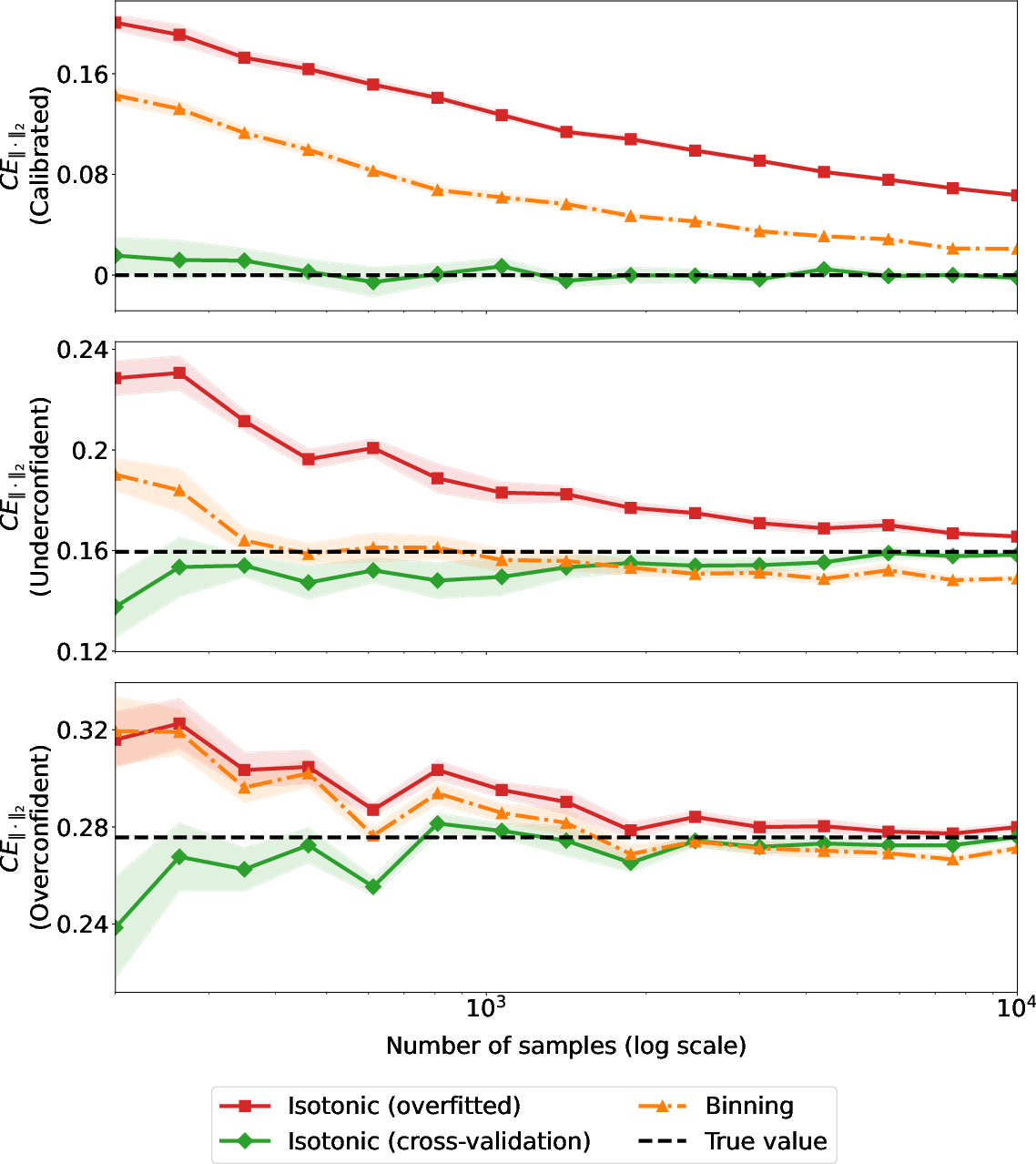
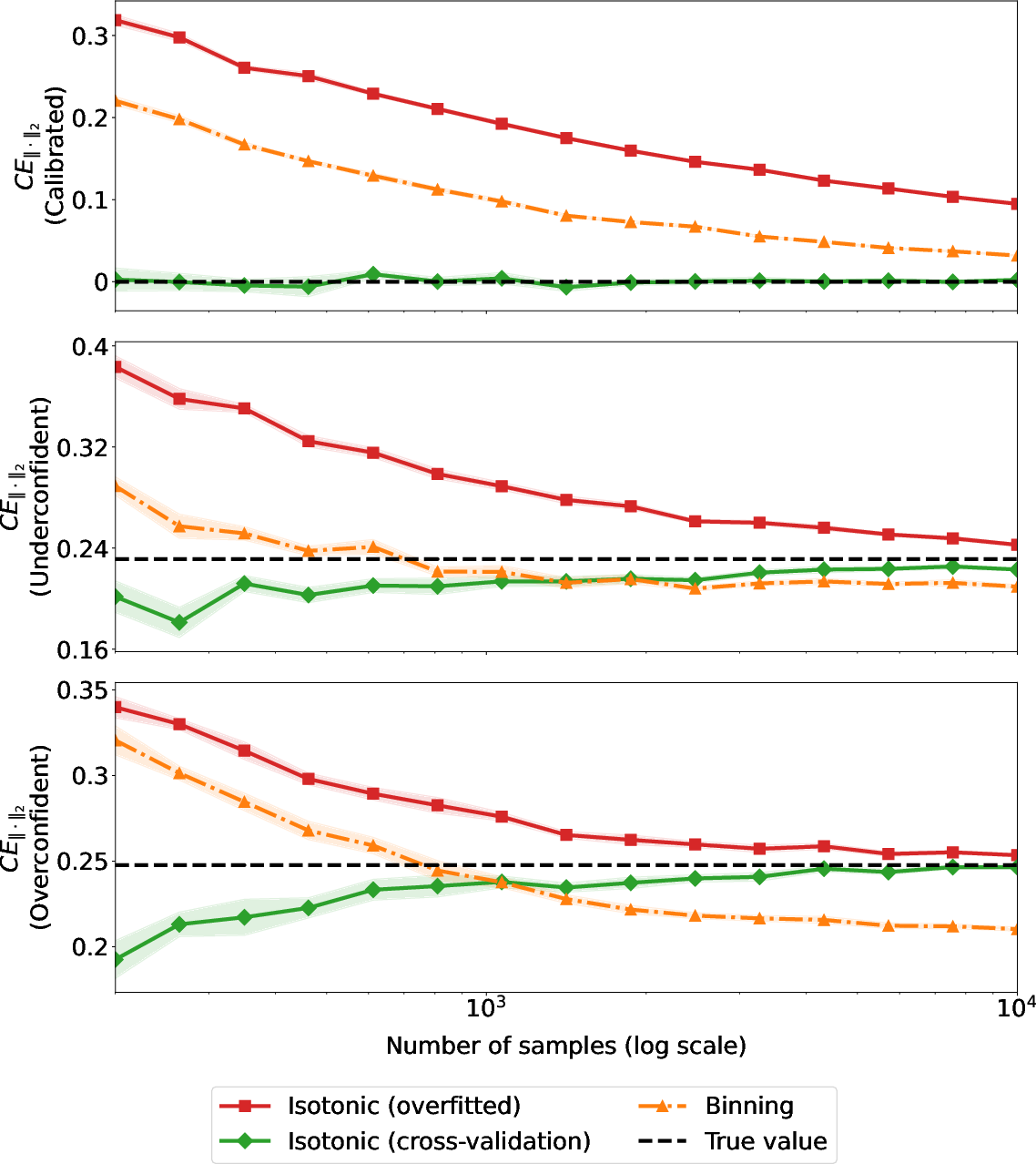
Cross-validation consistently yields unbiased (lower bound) estimates of calibration error, while binning and non-cross-validated approaches overestimate, especially when the classifier is well-calibrated or sample size is small.
The variational estimator converges more rapidly to the true calibration error, requiring fewer samples than traditional approaches.
Figure 1: Estimated CE∣⋅∣ across sample sizes for calibrated, over-confident, and shifted predictions, showing unbiased lower bound behavior with cross-validation.
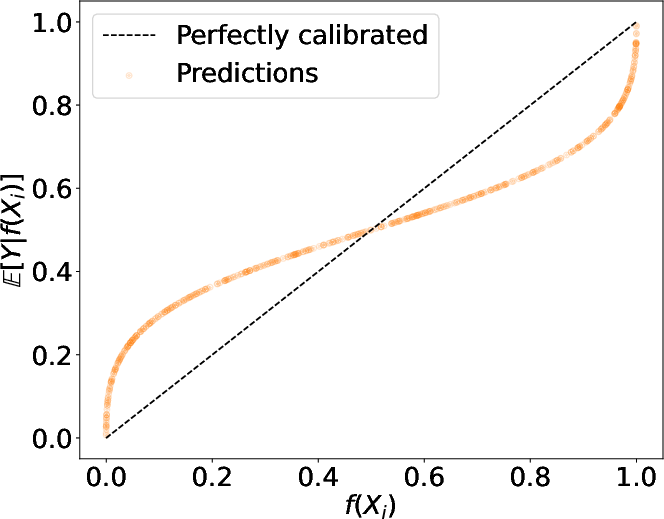
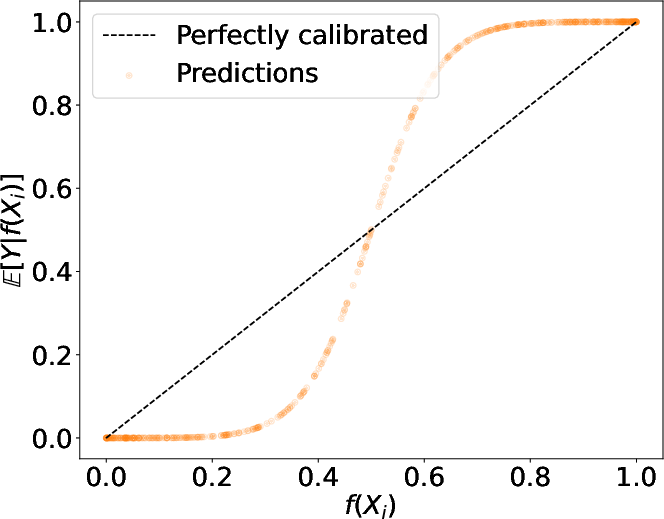
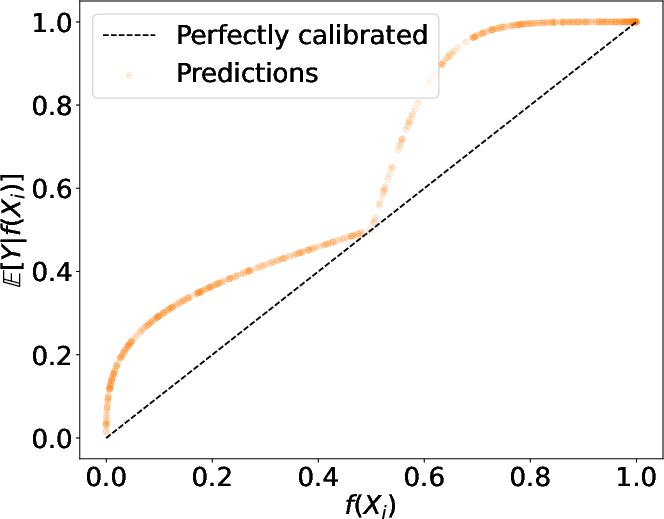
Additionally, the approach enables refined analysis, separating over- and under-confidence components of miscalibration. This is crucial in practical applications where miscalibration may be directional, e.g., overestimating or underestimating outcome probabilities.
Figure 2: Different simulated mis-calibration scenarios: over-confidence, under-confidence, and mixed-confidence.
The method's sample efficiency and accuracy are benchmarked across tabular datasets, using state-of-the-art classifiers such as TabICLv2, RealTabPFN-2.5, and gradient boosting methods (CatBoost, LightGBM), with various training strategies. Results indicate:
Top-performing classifiers yield higher calibration error estimates, approaching the true value, demonstrating superior approximation of the recalibration function.
GPU-based foundation models are most effective but less accessible; warm-started gradient-boosted trees provide a practical balance of speed and accuracy.
Standard estimators (Nadaraya-Watson, temperature scaling, isotonic regression, partition-wise binning) are faster but substantially less accurate, particularly for multiclass and non-proper error metrics.
Calibration errors for multiclass synthetic data are similarly analyzed, demonstrating convergence and lower-bound property even for high-dimensional prediction spaces.
Figure 3: Estimation of CE∥⋅∥2 on synthetic multiclass datasets, underscoring variational estimator performance vis-à-vis binning.
Implications and Extensions
The presented variational estimator for Lp calibration errors has significant theoretical and practical implications. Theoretically, it unifies calibration error estimation for arbitrary divergences under a single variational, risk minimization-based framework. Practically, it offers a robust and sample-efficient methodology for estimating calibration errors in binary and multiclass settings—avoiding systematic overestimation, supporting granular miscalibration analysis, and enabling scalable estimation via standard classification paradigms.
This advances calibration assessment's reliability and informativeness, especially as multiclass and structured prediction tasks proliferate in risk-sensitive domains (e.g., medical diagnosis, probabilistic forecasting). Furthermore, the extension to general convex distances opens the door for application-specific calibration metrics, tailored to operational requirements or decision-theoretic utilities.
The presented integration into the open-source probmetrics package will accelerate adoption and facilitate reproducibility in research and applied practice.
Future Developments
Future directions include:
Further optimization of recalibration model architectures for improved sample efficiency and computational tractability.
Extension to structured prediction settings and continuous output spaces.
Automatic selection and tuning of calibration error metrics based on downstream application requirements.
Investigation of hybrid estimators combining fast non-parametric methods with variational lower-bounding for practical deployment.
Conclusion
The paper provides a rigorous and flexible variational framework for estimating calibration errors induced by Lp norms and other convex distances, expanding beyond metrics rooted in proper losses. Empirical evaluation demonstrates unbiased estimation, superior convergence, and adaptability to diverse classification settings. These advances refine the assessment of predictive reliability in modern machine learning systems, offering both theoretical insight and practical tools for calibration evaluation and improvement.