Bridge Matching Sampler: Scalable Sampling via Generalized Fixed-Point Diffusion Matching
Abstract: Sampling from unnormalized densities using diffusion models has emerged as a powerful paradigm. However, while recent approaches that use least-squares `matching' objectives have improved scalability, they often necessitate significant trade-offs, such as restricting prior distributions or relying on unstable optimization schemes. By generalizing these methods as special forms of fixed-point iterations rooted in Nelson's relation, we develop a new method that addresses these limitations, called Bridge Matching Sampler (BMS). Our approach enables learning a stochastic transport map between arbitrary prior and target distributions with a single, scalable, and stable objective. Furthermore, we introduce a damped variant of this iteration that incorporates a regularization term to mitigate mode collapse and further stabilize training. Empirically, we demonstrate that our method enables sampling at unprecedented scales while preserving mode diversity, achieving state-of-the-art results on complex synthetic densities and high-dimensional molecular benchmarks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Bridge Matching Sampler: Scalable Sampling via Generalized Fixed-Point Diffusion Matching”
1. What is this paper about?
This paper is about teaching a computer how to draw new samples (examples) from a complicated “target” distribution when all we can do is evaluate how “likely” a point is, but we can’t easily compute the total probability. The authors introduce a new method called the Bridge Matching Sampler (BMS). It’s a way to turn simple random noise into samples that look like they came from the target, even when the target is high‑dimensional and has many separate “modes” (peaks).
Think of it like this: you start with marbles randomly scattered in a simple way (the “prior”), and you want to rearrange them so they match a tricky pattern (the “target”). BMS figures out how to move the marbles, gently and reliably, so the final arrangement matches the target pattern.
2. What questions does it try to answer?
- How can we sample from a complicated target distribution when we only know how “good” a point is (its unnormalized density), but don’t know the overall total (the normalizing constant)?
- Can we build a sampler that works with any starting distribution (not just very specific ones)?
- Can we avoid unstable training and keep all the different peaks of the distribution (avoid “mode collapse”)?
- Can the method scale to very high dimensions (hundreds or thousands) and still be fast and stable?
3. How does the method work?
Here’s the big picture in everyday language:
- Start simple, end complex:
- You begin with a simple, known distribution (the prior), like a Gaussian (bell curve).
- You want to end with the tricky target distribution (which might have many peaks).
- Diffusion as a transporter:
- The method uses a “diffusion” process, which you can imagine as adding tiny random wiggles to points while nudging them in certain directions. Over time, the nudges are learned so the points drift from the prior toward the target.
- Bridges as shortcuts:
- A “bridge” process is like planning the journey by looking at both the start and the end. The authors use a reference bridge (often a Brownian bridge, which is a fancy way of saying “random path that starts here and ends there”) to cheaply simulate what paths between start and end could look like.
- This trick lets them compute useful training signals without having to store full long trajectories all the time, saving memory and time.
- Markovianization (making the rules simple):
- The bridge is naturally “non-Markovian,” meaning it might depend on the whole path (past and future). That’s hard to learn directly.
- So they “Markovianize” it: they learn a simple rule u(x, t) that only looks at the current position x and time t to decide the next nudge. This is done by solving a least-squares regression: fit u(x, t) so it behaves like the bridge’s drift on the samples.
- You can think of it as replacing a complicated plan (“remember the whole history”) with a simple, memory‑less rule that approximates the same behavior.
- A fixed-point iteration:
- They repeat: simulate with the current rule, build a bridge using the simulated start/end points, fit a better rule, and so on. If the rule stops changing, you’ve reached a “fixed point” (it’s consistent with itself).
- A helpful identity for training:
- Inside the math, there’s an identity (a way to compute the “score,” meaning the direction where probability increases) that uses start and end information. This gives a clean regression target for learning u(x, t), even though we never directly sample from the target.
- Independent coupling and arbitrary priors:
- A key twist: they choose a simple way to pair starts and ends (an “independent coupling”) so they can work with any prior (not just a single fixed point or a special form). This keeps the algorithm general and practical.
- Damping for stability:
- They add “damping,” which means taking smaller, more cautious updates to the rule each step (like learning with a gentle step size). This helps avoid instability and mode collapse in tough, high‑dimensional problems.
Putting it all together, BMS:
- simulates with the current rule,
- forms a bridge using start/end pairs and a reference process,
- learns a new rule that best matches the bridge,
- blends old and new rules with damping, and repeats.
4. What did they find, and why is it important?
- Scales to very high dimensions:
- On tough synthetic tests like high‑dimensional Gaussian mixtures (with many peaks), BMS stayed stable and avoided collapsing onto just a few peaks. It worked up to 2,500 dimensions, which is far larger than what many prior methods handle.
- Keeps mode diversity:
- Unlike some methods that focus on the biggest peak and neglect smaller ones (“mode collapse”), BMS kept mass spread across all modes, matching the true mixture better.
- Better accuracy on physics benchmarks:
- On particle systems (like LJ‑55 with 165 dimensions), BMS achieved lower Wasserstein‑2 distances (a measure of how close the sampled distribution is to the target) and better matching of energy distributions than strong baselines.
- Strong molecular results:
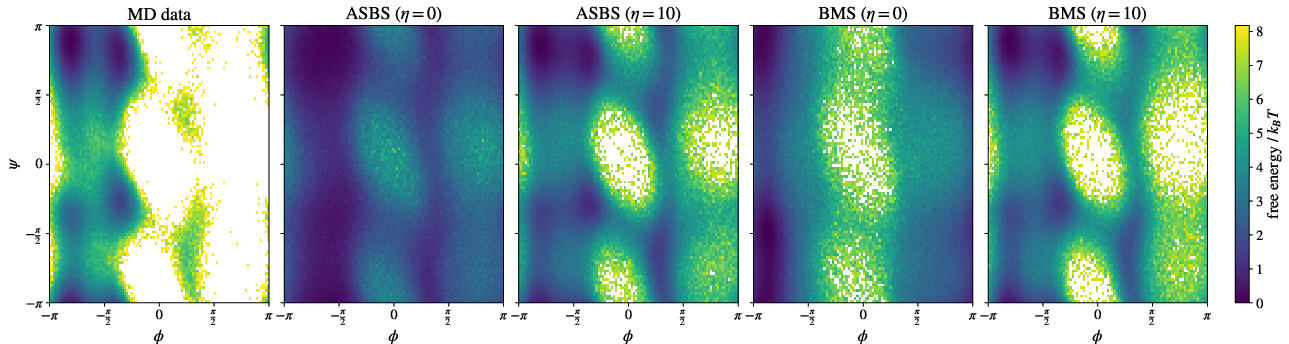
- On molecular benchmarks (Alanine dipeptide and tetrapeptide), BMS produced samples whose backbone angle distributions and free‑energy landscapes closely matched reference molecular dynamics data. This is impressive because they trained directly on all‑atom Cartesian coordinates using only energy evaluations, without extra domain tricks.
- Damping is crucial:
- Across tasks, adding damping made training more stable and improved results for both BMS and previous bridge-based methods. It’s a practical fix that reduces overshooting and instability.
Why it matters:
- These results mean we can more reliably sample from complex, multi‑modal, high‑dimensional targets—important in chemistry, physics, and Bayesian statistics—using a single, scalable training objective. It reduces memory demands, allows flexible starting distributions, and remains stable as problems grow.
5. What’s the impact?
BMS gives researchers and engineers a reliable, general tool for turning simple noise into high‑quality samples from very complicated distributions. That can speed up:
- Molecular modeling and drug discovery, by exploring realistic 3D shapes of molecules without hand‑crafted tricks.
- Statistical physics and materials science, by sampling energy landscapes that are rugged and multi‑modal.
- Bayesian inference, by drawing samples from difficult posteriors where only an unnormalized score is available.
Because BMS is stable, scalable, and flexible with priors, it opens the door to tackling larger and more complex problems than many previous diffusion-based samplers, while preserving the full variety of outcomes the real distribution contains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what the paper leaves missing, uncertain, or unexplored. Each point is phrased to be concrete and actionable for future research.
- Convergence guarantees: Under what conditions (on the target density, prior, reference process, network class, and damping parameter) does the fixed-point iteration converge to a unique solution? Are there global vs. local convergence guarantees, contraction properties, or rates for both undamped and damped iterations?
- Extension beyond Brownian references: Many key results (e.g., the generalized Target Score Identity) assume a scaled Brownian motion reference. How can the theory and algorithm be generalized to other references (e.g., Ornstein–Uhlenbeck, preconditioned diffusions, underdamped/kinetic SDEs) while retaining tractable ξ and marginal sampling from the bridge?
- Bias from independent coupling: What is the theoretical bias introduced by the independent coupling choice Π*_{0,T} = p_prior ⊗ p_target relative to the Schrödinger bridge coupling? How does this affect intermediate time marginals, path-wise statistics, and ultimate sample quality?
- Characterizing optimality vs. flexibility: Can one formally quantify the trade-off between the tractability (single objective, arbitrary priors) of BMS and the kinetic optimality of Schrödinger bridge solutions? Is there a divergence or variational criterion that BMS minimizes implicitly?
- Adaptive control variates: The identity uses a user-defined function c(t) as a control variate; how should c(t) be chosen or adapted online to minimize estimator variance and improve training stability? Can we prove optimality of a choice c*(t) and provide a practical estimator?
- Time-weighting of the regression objective: The least-squares objective integrates uniformly over t∈[0,T]. Would non-uniform time weights (or learned time schedules) reduce variance or bias, improve mode coverage, or accelerate convergence? How to choose or learn optimal weights?
- Robustness to noisy or approximate gradients: The framework assumes access to ∇ log ρ_target (or energy gradients). How does BMS perform with noisy force fields, surrogate models, or stochastic gradient oracles? Can it be extended to score-free settings (e.g., only function evaluations) via finite-difference, SPSA, or score matching?
- Replay buffer bias and refresh strategies: The use of buffers to store (X0, XT) improves sample efficiency, but what bias does stale data introduce? What buffer sizes, refresh schedules, or reweighting schemes minimize distribution drift and stabilize training?
- Practical guidelines for hyperparameters: There is limited guidance on choosing σ(t), T, damping η, prior distribution, and initialization u0. Can we develop principled heuristics or automatic tuning rules that ensure stability across targets and dimensions?
- Variance reduction and sample complexity: What is the sample complexity of BMS (as a function of dimension d, target smoothness, σ(t), and architecture)? Which variance reduction techniques (control variates beyond c(t), antithetic sampling, conditional sampling at t) most effectively reduce estimator variance?
- Conditional expectation approximation: The Markovianization step relies on minimizing squared error using samples from Πi rather than explicit conditional expectations E[ξ | X_t = x]. What is the statistical bias/variance of this approximation, and can importance weighting or conditional density estimation improve accuracy?
- Architectural and capacity considerations: How does function class choice (e.g., network depth/width, time conditioning, equivariances, preconditioning layers) impact convergence and performance in high dimension? Are there provably beneficial architectures (e.g., score-regularized, physics-informed) for BMS?
- Intermediate marginal fidelity: BMS guarantees boundary marginals by construction, but how accurately does it match intermediate marginals compared to SB/SHB solutions? Can we provide quantitative bounds or diagnostics for marginal mismatch over time?
- Theoretical error bounds: Can we derive non-asymptotic bounds on the error between the non-Markovian target Π* and its Markovian projection P{u*}, and on the learned u’s deviation from u* under finite samples and approximation error?
- Stability of alternating vs. single-objective schemes: The paper claims improved stability over alternating optimization (ASBS). Can we rigorously explain and predict when the single-objective BMS is more stable, and identify regimes where alternating schemes may still be preferable?
- Correction via MCMC or importance sampling: Since training errors can persist, can BMS be coupled with a lightweight Metropolis–Hastings correction, importance weighting, or path reweighting to guarantee asymptotically exact sampling from p_target? What are the computational and variance trade-offs?
- Normalizing constant estimation: Can the learned path measure or control fields be leveraged to estimate the partition function 𝒵 reliably (e.g., via path-space likelihood ratios or control-theoretic identities)? What are the variance properties of such estimators?
- Handling constraints and manifolds: The experiments operate in Cartesian coordinates for molecules; how can BMS handle holonomic constraints, internal coordinate manifolds, rotational symmetries, or Riemannian geometries without sacrificing tractability?
- Stiff potentials and multimodality at scale: How does BMS perform on extremely stiff or rugged energy landscapes (e.g., with widely separated scales or rare-event structure)? What modifications (preconditioning, adaptive σ(t), tempered targets) are needed to avoid trapping or instability?
- Damping selection and adaptation: While damping improves stability, how should η be scheduled or adapted over iterations/time to optimally balance exploration and convergence? Can trust-region or proximal rules be formalized with guarantees for BMS?
- Choice and design of reference bridges: Beyond Brownian bridges, which reference bridges (e.g., drifted bridges, OU bridges, learned reference bridges) yield the best trade-off between sampling efficiency, variance, and accuracy? Can reference selection be learned jointly with u?
- Scalability characterization: The paper demonstrates empirical scaling to d≈2500, but lacks detailed complexity analysis (time, memory, wall-clock). Can we characterize cost per iteration, asymptotic scaling in d and number of modes, and provide reproducible benchmarks across hardware configurations?
- Sensitivity to prior distribution: BMS allows arbitrary priors; how does prior choice affect convergence speed, stability, and mode coverage? Can we design priors that provably improve sampling (e.g., informative or preconditioned priors) without violating tractability?
- Applicability to discrete or hybrid targets: The framework relies on differentiable densities; how can it be extended to discrete or mixed continuous–discrete targets (e.g., combinatorial structures with continuous embeddings), where gradients may not exist?
- Diagnostics and failure modes: What on-the-fly diagnostics (e.g., marginal checks, bridge consistency tests, path-wise KLs) can identify training failures (instability, mode collapse) early? Can we propose remedial actions grounded in the fixed-point iteration (e.g., damping adjustments, c(t) re-optimization, reference swap)?
- Theoretical link to SOC objectives: While BMS is framed via Markovianization and reciprocal projections, can we explicitly connect the learned u to SOC optimality (e.g., minimizing a specific divergence or control cost) for independent coupling and general references?
- Generalization across targets and tasks: The experiments focus on mixtures, n-body, and peptides. How does BMS generalize to other domains (Bayesian posteriors, inverse problems, generative modeling) and what domain-specific modifications are required (e.g., likelihood-informed priors, constraints)?
- Reproducibility and parameter sweeps: The paper reports limited seeds and parameter sweeps. Comprehensive sensitivity analyses (η, σ(t), T, buffer size, architecture) are needed to establish robust default settings and identify brittle regimes.
These gaps collectively suggest avenues for strengthening the theoretical foundations, improving robustness and scalability, and broadening the applicability of the proposed Bridge Matching Sampler.
Practical Applications
Immediate Applications
The paper introduces the Bridge Matching Sampler (BMS), a scalable, stable diffusion-based method for sampling from unnormalized densities, with a damped fixed-point iteration that avoids unstable alternating optimization and supports arbitrary priors. The following applications can be deployed now, assuming access to an energy function (unnormalized log-density), basic SDE tooling, and GPU/CPU compute.
- Healthcare and Life Sciences (Molecular Modeling and Drug Discovery)
- Amortized conformer generation and equilibrium sampling from classical force fields for peptides, small molecules, and biomolecular systems.
- Replacement or complement to short molecular dynamics (MD) simulations to accelerate exploration of conformational space while preserving mode diversity.
- Potential tools/products/workflows:
- A BMS-based sampler integrated into MD frameworks (e.g., OpenMM, GROMACS) that uses force-field energies and gradients to produce ensembles.
- “Conformer-as-a-service” modules that batch-sample structures for downstream docking/scoring.
- Assumptions/dependencies:
- Availability of differentiable energy evaluations (forces) or reliable automatic differentiation of energy functions.
- Well-chosen diffusion schedules and damping parameters to ensure stable training in high dimensions.
- Software and Machine Learning (Energy-Based Models and Probabilistic Programming)
- Drop-in sampler for training and inference in energy-based models (EBMs), replacing or complementing MCMC in cases with costly memory footprints.
- Posterior sampling in probabilistic programming (e.g., Pyro/NumPyro/Stan-like models) when the normalizing constant is unknown or intractable.
- Potential tools/products/workflows:
- A PyTorch/JAX library for BMS with APIs to register the unnormalized density, prior, and reference process (e.g., Brownian bridge).
- Integration with EBM training loops (contrastive divergence variants) to improve mode coverage and gradient estimates.
- Assumptions/dependencies:
- Access to the unnormalized log-density and its gradient with respect to continuous variables.
- SDE integration and replay buffer maintenance for sample efficiency.
- Materials and Physics (Sampling Complex Energy Landscapes)
- Sampling canonical ensembles or target distributions in n-body systems (e.g., Lennard-Jones clusters) for benchmarking or preconditioning physics simulations.
- Potential tools/products/workflows:
- HPC pipelines using BMS for ensemble generation (e.g., initializations for long-run MD or MCMC).
- Integration in scientific computing libraries as a memory-efficient bridge-based sampler.
- Assumptions/dependencies:
- Accurate energy functions and gradients; appropriate scaling and damping to prevent mode collapse in large d.
- Academia (Statistical Physics, Bayesian Inference, Numerical Methods)
- Teaching and research tool to study reciprocal projections, Markovianization, and generalized target score identities in diffusion sampling.
- Rapid prototyping for high-dimensional multimodal densities (e.g., Gaussian mixtures with thousands of dimensions) where standard methods are unstable.
- Potential tools/products/workflows:
- Reproducible Jupyter notebooks showcasing Brownian bridge conditioning, generalized TSI, and damped fixed-point iterations.
- Assumptions/dependencies:
- Continuous-variable models; availability of gradient information or reliable finite-difference approximations.
- Policy and Public Sector (Applied Bayesian Modeling)
- Faster posterior sampling in models used for epidemiology, traffic/transport, or macroeconomic scenarios where likelihoods are expensive and normalizing constants are unknown.
- Potential tools/products/workflows:
- BMS-enabled samplers within probabilistic modeling toolchains to support scenario analysis under time and memory constraints.
- Assumptions/dependencies:
- Mechanistic models with differentiable log-likelihoods; vetting for robustness before policy deployment.
- Daily Life and Applied Engineering (Design Optimization and Generative Tools)
- Generating samples from constrained design spaces modeled as energy functions (e.g., parameterized shapes or circuit configurations).
- Potential tools/products/workflows:
- CAD/CAE plugins that use BMS to sample feasible designs for exploration or stress-testing.
- Assumptions/dependencies:
- Differentiable surrogate models of constraints/objectives; continuous variables.
Long-Term Applications
These opportunities will benefit from further methodological development (e.g., handling discrete variables, constraints, and stronger guarantees), scaling to larger systems, and ecosystem integration.
- Healthcare and Life Sciences (Large-Scale Drug Discovery and Protein Design)
- Scalable ensemble generation across chemical space with physics-informed priors for structure-based drug design and ADMET modeling.
- Integration with enhanced sampling (e.g., metadynamics/WT-ASBS) along collective variables, leveraging BMS’s stability as the core sampler.
- Dependencies:
- Automated selection of priors/reference processes and adaptive damping in extremely high-dimensional biomolecular spaces.
- Robust coupling to quantum-chemical energy models and multi-fidelity workflows.
- Robotics and Autonomous Systems (Sampling-Based Planning and Control)
- Real-time sampling from cost-defined distributions for motion planning and robust control under uncertainty (e.g., model predictive control with energy-based objectives).
- Dependencies:
- Efficient hardware acceleration, low-latency SDE integrators, and extensions to handle constraints and hybrid/discrete state spaces.
- Energy and Materials (Accelerated Discovery and Reliability)
- Sampling complex energy landscapes in materials (catalysts, batteries) to discover stable structures and rare events (e.g., transition paths).
- Dependencies:
- Coupling with PDE-constrained models and multi-scale simulation; advanced reference processes beyond Brownian motion.
- Finance and Insurance (Risk, Calibration, and Stress Testing)
- Posterior sampling for calibration of stochastic volatility models and Bayesian risk aggregation when normalizing constants are intractable.
- Rare-event sampling for systemic risk assessments via stable, high-dimensional samplers.
- Dependencies:
- Regulatory validation; integration with probabilistic programming ecosystems and GPU/CPU compute infrastructures.
- Scientific Computing and Inverse Problems (PDE-Constrained Bayesian Inference)
- Sampling posteriors in high-dimensional inverse problems (seismic imaging, medical imaging, climate model data assimilation) with unnormalized objectives.
- Dependencies:
- Differentiable solvers for complex forward models; extensions for hard constraints and non-Euclidean manifolds.
- Software Ecosystem (Standardization in Probabilistic Programming)
- BMS as a first-class sampler for unnormalized densities in mainstream PPLs and ML frameworks, with trust-region/damped fixed-point training as a default stability feature.
- “Sampler-as-a-service” platforms offering scalable bridge-based diffusion sampling for enterprise workloads.
- Dependencies:
- Community benchmarks, robust defaults for sigma schedules/damping, and support for discrete/structured variables.
- Policy and Public Sector (Scenario Generation and Decision Support)
- Wide adoption in governmental modeling (epidemiology, climate risk, infrastructure planning), enabling scenario generation under computational constraints.
- Dependencies:
- Auditable implementations, uncertainty quantification pipelines, and domain validation before policy use.
- Daily Life (Next-Gen Generative Tools with Physics/Constraints)
- Consumer design and simulation apps that incorporate physics-based constraints via energy functions to generate feasible, diverse solutions.
- Dependencies:
- Accessible model authoring (defining energies), UX to tune damping/stability, and on-device optimizations.
Cross-Cutting Assumptions and Dependencies
- Access to the unnormalized density (energy) and, ideally, its gradient; while the framework uses generalized target score identities, practical performance benefits from differentiable energy functions.
- Appropriate choice of prior distribution, reference process (e.g., Brownian bridge), diffusion schedule σ(t), and damping η; performance is sensitive to these hyperparameters.
- Continuous-variable models are assumed; discrete or constrained domains require further development (e.g., manifold-aware bridges, constraint handling).
- SDE solvers, GPU/CPU acceleration, and replay buffers are needed for efficient training; high-dimensional settings benefit from HPC resources.
- Stability/robustness: damped fixed-point iteration is central to avoiding mode collapse; adopting trust-region–like regularization is recommended in production.
Glossary
- Adjoint method: A technique to compute gradients efficiently by integrating backward, reducing memory usage for optimization. "leverages the adjoint method to enable memory-efficient gradient estimation."
- Adjoint Sampling (AS): A memory-efficient diffusion-based sampler derived from stochastic optimal control using adjoint gradients. "adjoint sampling (AS), a framework that leverages the adjoint method to enable memory-efficient gradient estimation."
- Adjoint Schr\"odinger Bridge Sampler (ASBS): A sampler that learns bridge processes between priors and targets via adjoint training, relaxing memoryless constraints. "recovers the Adjoint Schr\"odinger Bridge Sampler (ASBS) introduced by \citet{liu2025adjoint}"
- Bayesian inference: A statistical framework that updates beliefs about parameters using Bayes’ theorem and observed data. "and Bayesian inference~\cite{neal1993probabilistic,gelman2013bayesian}."
- Bridge Matching Sampler (BMS): The proposed method that learns a stochastic transport map using generalized fixed-point diffusion matching. "called Bridge Matching Sampler (BMS)."
- Brownian bridge: A stochastic process conditioned on its endpoints, often used as a reference for bridge sampling. "e.g., a Brownian bridge."
- Brownian motion (scaled): Continuous-time random motion with variance scaling, used as a reference diffusion. "Let the reference measure be induced by scaled Brownian motion, "
- Collective variables: Low-dimensional descriptors that capture essential system dynamics for enhanced sampling. "along collective variables."
- Control variate: A variance-reduction technique using auxiliary functions to stabilize estimates. "The function can be seen as a control variate; see~\Cref{appendix:control_variates_appendix_ctd} for further details."
- Damped fixed-point iteration: A stabilized update scheme that blends the new fixed-point with the previous iterate to improve robustness. "we extend \eqref{eq: fixed-point iteration} by introducing the damped fixed-point iteration"
- Diffusion coefficient: A scaling factor for stochastic noise in an SDE influencing exploration and stability. "these choices lead to instabilities due to large diffusion coefficients ."
- Energy-based sampling: Generative sampling from unnormalized densities defined via energy functions. "extended to energy-based sampling with the Adjoint Schr\"odinger Bridge Sampler (ASBS)"
- Fixed-point iteration: An iterative mapping where convergence occurs at a point left unchanged by the update operator. "we propose a fixed-point iteration that alternates between the construction of valid bridge processes and their Markovianization"
- Independent coupling: A boundary coupling that factorizes into independent initial and terminal marginals. ""
- Iterative proportional fitting (IPF): An alternating optimization procedure that adjusts marginals to match constraints. "proposed a variant based on iterative proportional fitting (IPF) \cite{kullback1968probability}"
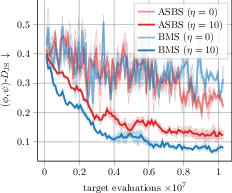
- JensenâShannon divergence: A symmetric measure of difference between probability distributions. "We report the JensenâShannon divergence of the joint backbone dihedral angle distribution ($D_{\mathrm{JS}$)"
- KL divergence: A measure of discrepancy between distributions, often minimized in variational objectives. "by the chain rule of the KL divergence"
- Markov Chain Monte Carlo (MCMC): A class of sampling algorithms that construct Markov chains with target stationary distributions. "Sampling from unnormalized densities has traditionally relied on Markov Chain Monte Carlo (MCMC) methods."
- Markovian control: A drift field depending only on the current state and time in a Markov SDE. "yielding a Markovian control with associated path measure as in \eqref{eq: forward process X}."
- Markovian projection: Mapping a non-Markovian process to a Markov process that preserves time marginals. "The Markovian projection of is a path measure corresponding to the solution of the Markovian SDE \eqref{eq: optimal Markovian SDE}"
- Markovianization: The process of approximating non-Markovian dynamics with a Markov drift via regression. "Markovianization: Finally, we obtain by minimizing a least-squares regression objective"
- Memorylessness: A property (e.g., of references) where the future is independent of the past given the present, simplifying couplings. "a property commonly known as memorylessness~\cite{domingoenrich2025adjoint}."
- Metadynamics: An enhanced sampling technique adding bias along chosen variables to escape metastable states. "metadynamics-inspired bias potentials along collective variables."
- Mode collapse: A failure mode where generative samplers concentrate on few modes, ignoring others. "regularization term to mitigate mode collapse and further stabilize training."
- Non-Markovian: Dynamics where future evolution depends on the whole path, not just current state. "non-Markovian stochastic process of the form"
- Normalizing constant: The partition function ensuring a density integrates to one, often intractable for complex targets. "normalizing constant, which is generally intractable."
- Path-dependent drift: A drift functional that may depend on the entire trajectory rather than only the current state. "The path-dependent drift corresponding to the non-Markovian SDE \eqref{eq: optimal non-Markov SDE}"
- Path measure: A probability measure over trajectories of a stochastic process. "We define the path space measure as the law of a -valued stochastic process"
- Proximal point methods: Optimization schemes that regularize updates via proximity terms to improve stability. "Similar regularization techniques are common in proximal point methods"
- Ramachandran plot: A 2D histogram of protein backbone dihedral angles used to assess conformational sampling. "Ramachandran plots with samples for Alanine dipeptide"
- Reciprocal class: The set of processes sharing the same endpoint-conditioned reference dynamics. "A path measure is in the reciprocal class of the reference process if ."
- Reciprocal projection: Projecting a path measure onto the reciprocal class by composing its endpoints with the reference bridge. "We define the reciprocal projection of onto as"
- Replay buffer: A memory of past samples used to improve sample efficiency by reusing data. "integration of replay buffers enables data reuse, thereby significantly increasing the method's sample efficiency."
- Schr\"odinger bridge (SB): A bridge process that matches both initial and terminal marginals while minimizing kinetic energy. "Schr\"odinger bridges (SBs) seek a kinetically optimal drift"
- Schr\"odinger half bridge (SHB): A bridge process constrained at one endpoint while minimizing kinetic energy. "Schr\"odinger half bridges (SHBs) solve problems of the form"
- Schr\"odinger system: Coupled equations defining potentials that characterize SB couplings. "\begin{proposition}[Schr\"odinger system]\label{prop: sb system}"
- Stochastic differential equation (SDE): A differential equation driven by noise modeling continuous-time random dynamics. "the stochastic differential equation (SDE)"
- Stochastic optimal control (SOC): A framework for optimizing controls of stochastic dynamics, e.g., by minimizing divergences. "Recent approaches based on stochastic optimal control (SOC) address this problem"
- Stochastic transport map: A random transformation pushing a prior distribution to a target distribution via an SDE. "enables learning a stochastic transport map between arbitrary prior and target distributions"
- Target Score Identity (TSI): An identity expressing the target score in terms of couplings and reference bridges to guide regression. "We term this identity generalized target score identity (TSI)"
- TICA (Time-lagged independent component analysis): A dimension-reduction method extracting slow collective modes from time series. "the Wasserstein-2 distance between the first two TIC components (TICA-)."
- Time marginal: The distribution of a process at a specific time, often matched across processes. "The objective is to match the time marginals"
- Trust-region methods: Optimization algorithms that restrict updates to a region where the model is reliable. "trust-region methods \cite{conn2000trust,schulman2015trust}"
- Wasserstein-2 distance (): A geometric metric measuring the cost to transport one distribution to another under quadratic cost. "Wasserstein-2 ()"
- Well-Tempered ASBS (WT-ASBS): An ASBS variant that augments sampling with bias potentials to mitigate mode collapse. "Well-Tempered ASBS (WT-ASBS)"
Collections
Sign up for free to add this paper to one or more collections.