Adaptive Spectral Feature Forecasting for Diffusion Sampling Acceleration
Abstract: Diffusion models have become the dominant tool for high-fidelity image and video generation, yet are critically bottlenecked by their inference speed due to the numerous iterative passes of Diffusion Transformers. To reduce the exhaustive compute, recent works resort to the feature caching and reusing scheme that skips network evaluations at selected diffusion steps by using cached features in previous steps. However, their preliminary design solely relies on local approximation, causing errors to grow rapidly with large skips and leading to degraded sample quality at high speedups. In this work, we propose spectral diffusion feature forecaster (Spectrum), a training-free approach that enables global, long-range feature reuse with tightly controlled error. In particular, we view the latent features of the denoiser as functions over time and approximate them with Chebyshev polynomials. Specifically, we fit the coefficient for each basis via ridge regression, which is then leveraged to forecast features at multiple future diffusion steps. We theoretically reveal that our approach admits more favorable long-horizon behavior and yields an error bound that does not compound with the step size. Extensive experiments on various state-of-the-art image and video diffusion models consistently verify the superiority of our approach. Notably, we achieve up to 4.79$\times$ speedup on FLUX.1 and 4.67$\times$ speedup on Wan2.1-14B, while maintaining much higher sample quality compared with the baselines.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making image and video generators faster without making the results look worse. It focuses on a popular kind of generator called a diffusion model, which creates pictures or videos step by step. The problem is that these models usually need dozens or even hundreds of steps, which makes them slow. The authors introduce a new, training‑free method called Spectrum that speeds things up by smartly “predicting” some steps instead of running the whole network every time.
What questions does it try to answer?
In simple terms, the paper asks:
- Can we skip some of the expensive steps in diffusion models and still get high‑quality images/videos?
- How can we predict what the model’s internal features will look like several steps into the future, not just the next step?
- Can we do this in a way that keeps errors small, even when we skip many steps?
How does the method work? (Explained simply)
Think of creating an image with a diffusion model like gradually clearing fog from a photo. The model removes a little noise at each step. Normally, you’d repeat a heavy computation at every step to get a clean result. That’s slow.
Past methods tried a shortcut: save (cache) some of the model’s internal “notes” (features) from earlier steps and reuse or slightly adjust them later. But these methods used very local rules—like guessing the next move from the last one or two moves—so their errors grew quickly if you skipped too many steps.
Spectrum takes a different approach:
- Treat each internal feature as a curve over time:
- Imagine tracking a single number inside the network as it changes from the first step to the last. That’s a curve. Spectrum says: let’s model that entire curve, not just the last tiny segment.
- Use “spectral” building blocks to model the curve:
- “Spectral” here means expressing a curve as a mix of simple, known shapes. The paper uses Chebyshev polynomials—think of them like Lego bricks that can be combined to build many different curve shapes.
- Fit the curve using past points, then forecast the future:
- As the model runs some real steps, Spectrum collects internal features and fits the best combination of those “brick” shapes to match them. This is done with a simple, stable math tool called ridge regression (you can think of it as “curve fitting that avoids overfitting by adding a small penalty for overly wiggly curves”).
- Once it has the fitted curve, Spectrum can predict the feature values for several future steps, letting the system skip many expensive network calls.
- Adaptive scheduling:
- Errors early on can snowball, so Spectrum does more “real” steps near the beginning and skips more later, when predictions are safer.
Everyday analogy:
- Imagine forecasting the weather. A basic approach looks only at today and yesterday (local). Spectrum builds a model from several days to capture the overall trend (global), then uses that model to predict the next few days more reliably.
Key terms in plain language:
- Feature caching: saving intermediate results so you don’t have to recompute them later.
- Chebyshev polynomials: simple curve shapes that can be combined to mimic complex curves.
- Ridge regression: a way to fit a line/curve to data that stays stable and avoids wild swings.
What did they find, and why is it important?
The authors tested Spectrum on top-tier image and video generators and compared it to other shortcut methods. Here’s what they found:
- It’s much faster while keeping high quality:
- For images (like FLUX.1): up to about 4.79× faster while keeping quality nearly the same as the usual 50‑step process.
- For videos (like Wan2.1‑14B and HunyuanVideo): up to about 4.67× faster with little to no noticeable quality drop.
- It works better at high speedups than previous methods:
- Earlier shortcuts (like copying features or using Taylor expansions) did okay for small skips but lost quality when skipping more steps. Spectrum stayed stable even with bigger skips.
- It comes with a stronger error guarantee:
- The paper shows that Spectrum’s prediction error depends mostly on how many “building blocks” it uses to model the curve, not on how far ahead it predicts. That’s different from Taylor‑style methods, where error grows fast as you skip more steps.
Why this matters:
- Faster diffusion means quicker, cheaper image and video generation for creative tools, games, education, and more.
- Because Spectrum doesn’t require retraining the model, it’s easy to plug into existing systems.
What’s the potential impact?
- Real-time or near real-time generation: Spectrum could make interactive image/video tools more responsive, especially on large models that currently feel slow.
- Broad compatibility: It doesn’t change or retrain the original model and can work with different samplers, so it’s easy to adopt.
- Can stack with other speed-ups: Methods like quantization or pruning reduce per-step cost; Spectrum reduces the number of expensive steps. Together, they could make generation much faster.
- Better user experience: Creators can iterate more quickly without losing detail or accuracy.
Bottom line
Spectrum predicts internal features globally, not just locally, by fitting them with simple curve “building blocks.” This makes skipping many steps safer and yields big speedups—often 3–5×—while keeping the images and videos looking great, all without extra training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. These points are grouped to aid follow-up research.
Theory and assumptions
- The analytic-function assumption behind the Chebyshev error bound (extension to a Bernstein ellipse with parameter ρ>1) is not validated for real denoiser feature trajectories; no empirical estimation of ρ or bound tightness for actual models is provided.
- The theoretical bound depends on σ_min(Φ_tj), K, M, and λ, yet there is no analysis linking practical caching schedules to well-conditioned Φ_tj; conditions that guarantee a favorable σ_min for real step schedules are not established.
- The Taylor lower bound compares to an ideal Taylor predictor with true derivatives; the practical finite-difference approximations used in prior work (and noise in cached features) are not accounted for in the bound or empirical comparison.
- No formal stability analysis when forecasting over many consecutive skipped steps (e.g., compounding numerical errors across the ODE solver and forecasted features) is provided.
- The bound is derived under deterministic ODE sampling; behavior and guarantees under stochastic SDE/ancestral samplers or noisy solvers remain unaddressed.
Method design and choices
- Basis choice: Chebyshev polynomials are motivated but not compared against other global bases (Legendre, Fourier, wavelets, splines) or learned bases; criteria for when Chebyshev is optimal are not given.
- Scalar per-channel fitting ignores cross-channel or token correlations; whether multivariate regression (e.g., low-rank subspaces, PCA, CCA, or blockwise multivariate ridge) yields better accuracy/speed trade-offs is unexplored.
- A global, fixed polynomial degree M is used; no adaptive per-channel or per-block selection of M based on residuals or conditioning is explored.
- The mapping g(t)=2t−1 is assumed; the impact of alternative time parameterizations widely used in diffusion (e.g., σ-space, log-SNR, v-parameterization) on forecast accuracy and conditioning is not studied.
- The choice of ridge regularization λ is fixed or grid-searched; no online, data-driven λ selection (e.g., via cross-validation, RLS with forgetting, or residual monitoring) is proposed or evaluated.
- Coefficient fitting is recomputed per cache update; incremental/recursive least squares (RLS) or rank-1 updates that reduce overhead are not investigated.
- Schedule vs. nodes: Chebyshev approximations are known to benefit from Chebyshev nodes, but the paper does not explore aligning actual evaluation times to near-Chebyshev nodes to improve conditioning and accuracy.
- Forecast horizon control and error monitoring: there is no mechanism to estimate forecast error on-the-fly (e.g., via hold-out cached points or residuals) to decide when to force actual evaluations.
Implementation clarity and reproducibility
- Final-block-only caching is advocated, but the mechanism for producing the final score without running earlier blocks at forecasted steps is under-specified (e.g., which intermediate activations are bypassed vs. reused, how residual/skip connections are handled).
- Classifier-free guidance typically doubles passes (conditional/unconditional). It is unclear whether coefficients/caches are maintained separately for both branches, and what memory/latency impact this has.
- For video models with temporal attention, it is not specified whether coefficients are shared across frames, per-frame, or per-token, nor how temporal attention caches interact with the proposed forecasting.
- Practical memory footprint for high-res images and long videos (K×F + (M+1)×F) is not quantified end-to-end; no ablation on memory/time trade-offs at different K, M, and layer selections is provided.
- The pseudo-code omits several integration details (e.g., how predicted features are “ensembled throughout the network,” how attention KV caches are managed), which complicates reproduction.
Evaluation scope and metrics
- Benchmarks are limited to a small set of large Diffusion Transformer models (FLUX.1, SD3.5-Large, Wan2.1-14B, HunyuanVideo); applicability to UNet-based models and other architectures is not empirically validated.
- Only ODE-style deterministic samplers are tested; performance under stochastic samplers (ancestral SDEs), different solvers (Heun, RK, EDM schedulers), and very low-step regimes common in modern samplers is not assessed.
- Image/video metrics focus on PSNR/SSIM/LPIPS versus a 50-step “reference,” ImageReward/CLIP, and VBench Quality; standard distributional metrics like FID/KID (images) or FVD/KVD (videos) and human preference studies are absent.
- Temporal consistency metrics for video (e.g., tLPIPS, FVD) are not reported; potential motion artifacts or temporal flicker induced by forecasting are not systematically evaluated.
- Robustness across seeds, prompts (e.g., multi-object composition, long prompts, fine-grained style control), and guidance scales is not systematically analyzed.
- Failure modes under extreme acceleration (beyond ~4.8×) are not documented; thresholds where spectral forecasting breaks down remain unknown.
- Fair timing comparisons: wall-clock speedups are reported but may depend on implementation and kernel optimizations; a breakdown of overhead sources (ridge solve, cache ops, I/O) vs. baseline forward compute is missing.
Scheduling and policy design
- The adaptive schedule controlled by α is hand-crafted; there is no principled method to choose α for a given compute budget or model, nor a closed-loop controller that adapts the schedule based on error/residuals during sampling.
- Dynamic caching policies (when to cache or reuse) are not learned or optimized; combining spectral forecasting with existing learned/dynamic caching or pruning strategies is not studied.
Generalization and extensions
- Generalization to other modalities (audio, 3D, point clouds) or tasks (image editing, inpainting, ControlNet/conditioning-heavy pipelines, region-adaptive sampling) is not demonstrated.
- Integration with complementary accelerations (quantization, pruning, token pruning, optimized kernels, parallel solvers) is suggested but not empirically validated for combined gains.
- Applicability to flow-matching or rectified flow models is only mentioned; no empirical evaluation or specialized adaptation to their time parameterization is provided.
- The approach is training-free; whether light training (e.g., learning basis projections, channel groupings, or predictive priors) can further improve stability/accuracy at higher speedups is left unexplored.
Robustness and safety
- Sensitivity to distribution shift (e.g., out-of-domain prompts, adversarial or safety-critical prompts) and its interaction with forecasting errors is not evaluated.
- Potential impacts on diversity (mode collapse or over-regularization due to spectral smoothing) are not measured beyond per-sample similarity to a reference.
Open methodological questions
- Can per-block or per-attention-head spectral forecasting (vs. final-block-only) yield better accuracy/speed trade-offs under tighter memory budgets?
- Are there structured low-rank or token-selective variants (e.g., forecast only salient tokens or heads) that preserve semantics while further reducing overhead?
- Would hybrid local-global forecasters (e.g., local finite differences plus global spectral bases) improve stability in non-smooth regions of the trajectory?
- Can forecast-aware solvers (that account for forecast uncertainty) reduce error accumulation or enable larger skips safely?
Practical Applications
Overview
The paper introduces Spectrum, a training‑free, solver‑agnostic method to accelerate diffusion model sampling by forecasting denoiser features over time using Chebyshev polynomials and ridge regression. By caching features (typically from the final attention block) at selected timesteps and forecasting future features with globally fitted spectral bases, Spectrum reduces the number of expensive denoiser evaluations while maintaining quality. It achieves 3.4–4.8× wall‑clock speedups on state‑of‑the‑art text‑to‑image and text‑to‑video models (e.g., FLUX.1, SD3.5‑Large, HunyuanVideo, Wan2.1‑14B) with minimal quality degradation. Theoretical analysis shows forecast errors do not compound with skip size (unlike local Taylor methods), enabling long‑range reuse.
Below are practical applications organized by deployment horizon.
Immediate Applications
The following use cases can be deployed now with modest engineering effort, especially on open‑source or self‑hosted diffusion pipelines where intermediate features are accessible.
- Faster text‑to‑image/video generation services
- Sector: media/entertainment, advertising, gaming, social platforms, e‑commerce
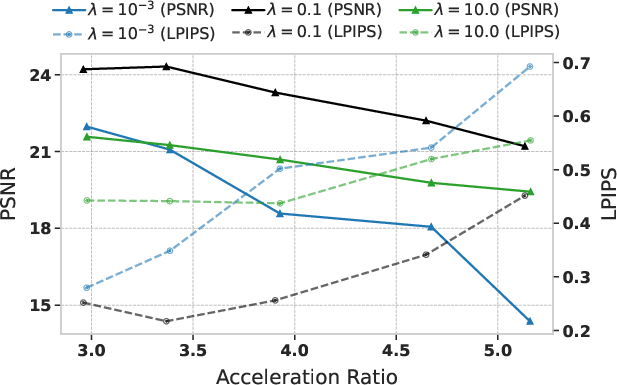
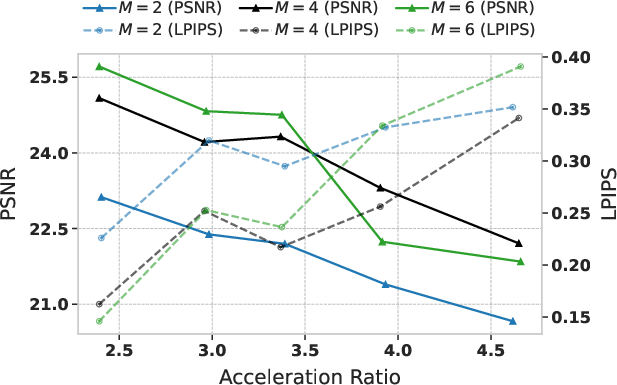
- Tools/workflows: integrate Spectrum as a feature‑caching forecaster into existing inference stacks (e.g., Hugging Face Diffusers, ComfyUI, InvokeAI/Automatic1111, custom PyTorch samplers). Use M≈4 and λ≈0.1 with adaptive scheduling (α≈0.75–3.0) to target 10–14 denoiser calls, yielding ~3–4.8× speedups.
- Assumptions/dependencies: access to model internals (attention block outputs) and control over the sampler; tested primarily on diffusion Transformers; quality targets validated on FLUX.1, SD3.5‑Large, HunyuanVideo, Wan2.1‑14B.
- Real‑time prompt iteration in creative tools
- Sector: software/creator economy, UX/design
- Tools/workflows: add a “Fast Preview” mode that uses Spectrum during iterative prompt editing, inpainting/outpainting, or control‑net driven edits; switch to full evaluation for the final render.
- Assumptions/dependencies: UI support for dual‑mode generation; stable behavior at low denoiser counts for previews.
- Cloud inference cost and energy reduction
- Sector: cloud platforms, finance (cost control), energy/sustainability
- Tools/workflows: enable Spectrum as a toggle in hosted generative services; report GPU‑hour and energy savings per request; auto‑select Spectrum under low‑risk prompts (e.g., simple scenes).
- Assumptions/dependencies: SLAs and quality thresholds must be maintained; energy and cost metrics instrumentation; some closed‑source APIs may prohibit internal modifications.
- Edge and on‑device generative experiences
- Sector: mobile, XR/AR filters, social apps
- Tools/workflows: combine Spectrum with quantization/token pruning to reach sub‑second image previews on laptops or high‑end phones; employ adaptive scheduling to keep more “real” denoiser calls early and forecast later for stability.
- Assumptions/dependencies: device GPU/NPUs, memory budgets for feature caches; integration with mobile‑optimized backends.
- Accelerated video generation pipelines
- Sector: marketing, e‑commerce, media production (pre‑viz), education content
- Tools/workflows: use Spectrum in batch storyboarding, product spins, or short video ads where near‑reference fidelity is sufficient; schedule more forecasts late in the trajectory to maximize throughput.
- Assumptions/dependencies: alignment with VBench‑like quality targets; longer sequences may require additional guardrails for temporal consistency.
- Research acceleration (academia/industry R&D)
- Sector: academia, applied ML teams
- Tools/workflows: faster ablations/benchmarks, sampler comparisons, and synthetic dataset generation using training‑free acceleration; plug into experiment harnesses to cut wall‑clock time.
- Assumptions/dependencies: reproducibility requires fixing seeds and reference baselines (e.g., 50‑step sampler).
- Synthetic data generation for perception and robotics
- Sector: robotics, autonomy, computer vision
- Tools/workflows: generate more varied synthetic images quickly for detection/segmentation pre‑training; Spectrum increases throughput without retraining generators.
- Assumptions/dependencies: validate domain‑shift and annotation quality; per‑task fidelity requirements may vary.
- Privacy‑preserving synthetic data in healthcare (pilot use)
- Sector: healthcare, life sciences
- Tools/workflows: accelerate generation of synthetic radiology or microscopy images for method development and benchmarking (not for diagnosis); Spectrum reduces compute without modifying model weights.
- Assumptions/dependencies: strict validation, bias and safety audits; institutional approvals; many clinical pipelines avoid unverified accelerations—best suited for non‑clinical research.
- Education and classrooms
- Sector: education
- Tools/workflows: enable students to run diffusion demos on limited hardware (lab PCs, laptops) with responsive feedback; labs comparing samplers and caching strategies.
- Assumptions/dependencies: open models; simplified UIs; content safety filters maintained.
- Open‑source library integration
- Sector: software tooling
- Tools/workflows: contribute a “SpectralForecastingScheduler” to Diffusers; PyTorch/TensorFlow hooks capturing final‑block features and solving small ridge regressions (Cholesky) per cache update; reference configs (M=4, λ=0.1).
- Assumptions/dependencies: community acceptance; testing across diverse models and schedulers.
Long‑Term Applications
These directions require further validation, scaling, or ecosystem development.
- Real‑time, high‑fidelity video for AR/VR and live media
- Sector: XR, live streaming, virtual production
- Tools/products: interactive T2V for live backdrops, avatars, and scene edits; Spectrum‑based forecast controllers tuned for sub‑100 ms latency with temporal consistency guarantees.
- Dependencies/risks: more stringent coherence/latency targets; may require model retraining and joint temporal controllers.
- Cross‑modal spectral forecasting (audio, 3D, molecules)
- Sector: audio/music generation, 3D content, drug discovery/materials
- Tools/products: apply Spectrum to audio diffusion (music/speech), text‑to‑3D pipelines (e.g., Score Distillation Sampling), and molecular/protein diffusion; spectral bases customized to modality dynamics.
- Dependencies/risks: verify smoothness/analyticity assumptions; adapt caching points and feature choices; new quality metrics.
- Co‑training for forecastability
- Sector: foundational model development
- Tools/products: train diffusion transformers with spectral regularizers to encourage Chebyshev‑smooth feature trajectories; learn basis‑aware layers to maximize forecast accuracy and skip rates.
- Dependencies/risks: potential trade‑offs with diversity/fidelity; additional training costs.
- Hardware–software co‑design
- Sector: semiconductors, systems
- Tools/products: GPU/NPU kernels for on‑the‑fly ridge solves and Chebyshev recurrences; memory controllers optimized for feature cache movement; firmware‑level “forecast slots.”
- Dependencies/risks: vendor support; benchmarks showing consistent wins across models.
- Pipeline templates combining accelerations
- Sector: MLOps
- Tools/workflows: standardized cascades that mix Spectrum with high‑order ODE solvers, distillation, quantization, token pruning, and dynamic caching to target ≥10× speedups at fixed quality targets.
- Dependencies/risks: careful interaction testing; guardrails to prevent compounding errors.
- Generalized iterative forecasting beyond diffusion
- Sector: scientific computing, engineering
- Tools/products: apply spectral feature forecasting to iterative refinement networks, PDE solvers, or test‑time adaptation loops where intermediate states evolve smoothly.
- Dependencies/risks: mathematical validation per domain; interface to capture hidden states.
- Sustainable AI and policy tooling
- Sector: policy, sustainability
- Tools/workflows: “green inference” modes in cloud APIs reporting energy/GPU‑hour reductions; procurement guidelines encouraging spectral acceleration for generative services.
- Dependencies/risks: standardization of reporting; ensuring acceleration doesn’t compromise safety filters or watermarking.
- Safety and governance responses to faster generation
- Sector: policy, trust & safety
- Tools/workflows: capacity planning and rate‑limit policies acknowledging higher throughput; enhanced detection, watermarking, and provenance tooling as generation volume increases.
- Dependencies/risks: risk of misuse/deepfakes; alignment with emerging AI content regulations.
- Commercial products and SDKs
- Sector: developer platforms
- Tools/products: SpectrumKit SDKs for Python/C++ with plug‑and‑play hooks for popular T2I/T2V models; profiles for “preview,” “balanced,” and “max‑speed.”
- Dependencies/risks: ongoing maintenance across model updates; QA for enterprise SLAs.
Notes on Assumptions and Dependencies
- Model access: Spectrum requires access to intermediate features (typically the final attention block); black‑box APIs may not expose these internals.
- Model class: Results are shown on diffusion Transformers; adaptation to U‑Nets and other denoisers is promising but should be validated.
- Hyperparameters: Degree M and regularization λ affect stability/accuracy; the paper’s defaults (M≈4, λ≈0.1) are good starting points; adaptive scheduling (α) is important to curb early‑step error accumulation.
- Quality baselines: Reported metrics compare to 50‑step references; different baselines or solvers may shift absolute numbers.
- Hardware and wall‑clock: Speedups were measured on A100/H800 GPUs; absolute latency varies by hardware, batch size, and framework kernels.
- Safety and compliance: Accelerating generation does not alter model content filters or watermarking; verify that such safeguards remain intact in production.
- Memory/computation: Overheads are small (store K cached features and (M+1)×F coefficients), but must be budgeted for edge deployments.
By adopting Spectrum now in controllable environments (self‑hosted/open‑source pipelines), organizations can realize significant cost and latency reductions without retraining models. Longer‑term, co‑designed models, modality extensions, and hardware support could make spectral forecasting a standard component of fast, sustainable generative AI.
Glossary
- Adaptive scheduling: A strategy that allocates more actual network evaluations earlier in sampling and increases forecasting later to reduce accumulated error. "We further study the efficacy of our proposed adaptive scheduling strategy, with results displayed in Table~\ref{tab:ablate_adaptive_scheduling}."
- Attention blocks: Transformer submodules that implement attention operations; many are stacked in Diffusion Transformers and dominate compute. "is typically a Diffusion Transformer~\cite{peebles2023scalablediffusionmodelstransformers,liu2025regionadaptivesamplingdiffusiontransformers} with deep stacks of attention blocks."
- Basis row vector: A vector of basis-function evaluations at a given time used to build the regression design matrix. "we first construct the basis row vector as"
- Bernstein ellipse: A complex-plane region used to characterize analytic extension and exponential approximation rates for polynomial approximations. "extends analytically to the Bernstein ellipse "
- Chebyshev polynomials of the first kind: A family of orthogonal polynomials on [-1,1] with a stable recurrence, used here as spectral bases for time functions. "Chebyshev polynomials of the first kind~\cite{mason2002chebyshev} are defined by the following recurrence,"
- Cholesky decomposition: A numerical method for solving symmetric positive-definite linear systems efficiently. "which can be efficiently solved via Cholesky decomposition."
- CLIP Score: A text-image alignment metric based on CLIP embeddings used to assess prompt consistency. "We also include the ImageReward~\cite{xuImageRewardLearningEvaluating2023} and CLIP Score~\cite{hessel2021clipscore} of the generated images."
- Consistency models: Distillation-based generative models that enforce consistency along the diffusion trajectory to enable few-step sampling. "consistency models~\cite{song2023consistency,song2024improved} and subsequent efforts~\cite{kim2023consistency,lu2025simplifying} enforce consistency along the diffusion trajectory,"
- Design matrix: The matrix of basis evaluations over cached timesteps used in regression to fit spectral coefficients. "The design matrix is then instantiated as a stack of basis row vectors along time axis:"
- Denoiser: The neural network in diffusion models that predicts noise (or score) at each timestep during sampling. "the denoiser is usually parameterized by Diffusion Transformers~\cite{peebles2023scalablediffusionmodelstransformers}"
- Denoising score matching: A training objective where the model learns the score (gradient of log density) by denoising perturbed data. "through, e.g., denoising score matching~\cite{song2021scorebased,song2019generative},"
- Diffusion Transformer: A Transformer architecture adapted for diffusion models, often serving as the denoiser backbone. "a Diffusion Transformer~\cite{peebles2023scalablediffusionmodelstransformers,liu2025regionadaptivesamplingdiffusiontransformers}"
- DPMSolver: A family of high-order ODE solvers tailored for diffusion model sampling. "e.g., DPMSolver~\cite{lu2022dpm,lu2022dpm++,zheng2023dpmsolvervF}, have introduced high-order solvers"
- DrawBench: A benchmark prompt suite for evaluating text-to-image models. "We employ DrawBench~\cite{saharia2022photorealistic} as the prompt suite"
- Euler solver: A first-order numerical ODE integrator used as a simple baseline for diffusion sampling. "For instance, in the case of Euler solver, each step can be formulated as the following iteration:"
- Feature caching: Reusing intermediate network activations from selected timesteps to avoid expensive forward passes. "feature caching-based approaches~\cite{lvFasterCacheTrainingFreeVideo2025,zou2024accelerating,zou2024DuCa,liu2024timestep,liu2025taylor} have stood out and shown great promise"
- Flow matching models: Generative models trained to match a transport flow between distributions, related to diffusion/ODE formulations. "adopt these techniques to flow matching models~\cite{refitiedflow,lipman2023flow} and have demonstrated success."
- Forward differential operator: A finite-difference operator that approximates derivatives from discrete samples. "where is the -th order forward differential operator, which is defined as"
- ImageReward: A learned metric that scores image quality and prompt alignment. "We also include the ImageReward~\cite{xuImageRewardLearningEvaluating2023} and CLIP Score~\cite{hessel2021clipscore} of the generated images."
- LPIPS: A perceptual similarity metric that estimates human-judged similarity between images using deep features. "We first evaluate PSNR, SSIM, LPIPS between the generated images"
- ODE solvers: Numerical integrators used to simulate the probability flow ODE in diffusion sampling. "Another family of work decreases the number of integration steps by leveraging more accurate ODE solvers of the probability flow ODE~\cite{song2021scorebased}."
- Probability-flow ODE: The ordinary differential equation whose solution transports noise to data along the diffusion trajectory. "parameterized by the probability-flow ODE~\cite{song2021scorebased}:"
- PSNR: Peak Signal-to-Noise Ratio, a distortion metric comparing generated outputs to references. "We first evaluate PSNR, SSIM, LPIPS between the generated images"
- Regularization strength: The coefficient controlling penalty magnitude in ridge regression to stabilize fitting. "where is the regularization strength."
- Ridge regression: A regularized least-squares method adding an L2 penalty to improve stability and reduce overfitting. "we solve the following ridge regression objective:"
- Singular value (smallest singular value): The minimum singular value of a matrix, capturing its conditioning and affecting regression error bounds. "where is the smallest singular value of ."
- Spectral bases: Basis functions (here, Chebyshev polynomials) spanning functions in the frequency-like domain for global approximation. "a powerful tool that serves as a set of spectral bases for the temporal functions of our interest."
- Spectral domain: A representation emphasizing global, frequency-like components rather than local time neighbors. "we move beyond local approximations and instead construct the forecaster in the spectral domain."
- SSIM: Structural Similarity Index Measure, assessing perceptual similarity between images. "We first evaluate PSNR, SSIM, LPIPS between the generated images"
- Taylor expansion (discrete): A finite-difference extrapolation using nearby points to approximate future values. "while the recent work~\cite{liu2025taylor} performs discrete Taylor expansion using a few nearest cached points."
- Truncated Chebyshev series: A finite-degree Chebyshev expansion that approximates a function with exponentially decaying error under analyticity. "for the truncated Chebyshev series of degree ,"
- VBench: A standardized benchmark and protocol for evaluating text-to-video generation quality. "We adopt VBench~\cite{huang2023vbench} as the benchmark suite"
Collections
Sign up for free to add this paper to one or more collections.