DynaMoE: Dynamic Token-Level Expert Activation with Layer-Wise Adaptive Capacity for Mixture-of-Experts Neural Networks
Abstract: Mixture-of-Experts (MoE) architectures have emerged as a powerful paradigm for scaling neural networks while maintaining computational efficiency. However, standard MoE implementations rely on two rigid design assumptions: (1) fixed Top-K routing where exactly K experts are activated per token, and (2) uniform expert allocation across all layers. This paper introduces DynaMoE, a novel MoE framework that relaxes both constraints through dynamic token-level expert activation and layer-wise adaptive capacity allocation. DynaMoE introduces a principled routing mechanism where the number of active experts per token varies based on input complexity. Concurrently, the framework implements six distinct scheduling strategies for distributing expert capacity across network depth, including descending, ascending, pyramid, and wave patterns. We theoretically analyze the expressivity gains of dynamic routing and derive bounds on computational efficiency. Through extensive experiments on MNIST, Fashion-MNIST, CIFAR-10 (image classification), and Recycling-the-Web (language modeling) across multiple model scales, we demonstrate that DynaMoE achieves superior parameter efficiency compared to static baselines. Our key finding is that optimal expert schedules are task- and scale-dependent: descending schedules (concentrating capacity in early layers) outperform uniform baselines on image classification. For language modeling, optimal schedules vary by model size, descending for Tiny, ascending for Small, and uniform for Medium. Furthermore, dynamic routing reduces gradient variance during training, leading to improved convergence stability. DynaMoE establishes a new framework for adaptive computation in neural networks, providing principled guidance for MoE architecture design.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
Big AI models can be powerful but also slow and expensive to run. One popular trick to make them faster is called a “Mixture of Experts” (MoE): instead of using the whole model for every input, the model has many small “experts” and only asks a few of them to help for each input. This paper introduces DynaMoE, a new way to use MoE that is more flexible and smarter about when and where to spend compute. It does two main things differently:
- It lets the model decide, for each piece of input, how many experts to use instead of always using a fixed number.
- It changes how many experts are available in each layer of the network, instead of keeping the same number of experts everywhere.
The goal is to get better accuracy and efficiency by adapting to the input’s difficulty and the role of each layer in the network.
What questions the researchers asked
In simple terms, the paper asks:
- Can a model do better if it chooses how many experts to use for each input based on how hard that input is?
- Is it better to put more experts in early layers, later layers, or the middle of the network?
- Does this dynamic approach make the model more expressive (able to learn more complex patterns) without wasting compute?
- Will it train more stably and efficiently than standard MoE or plain models?
How DynaMoE works (explained with everyday ideas)
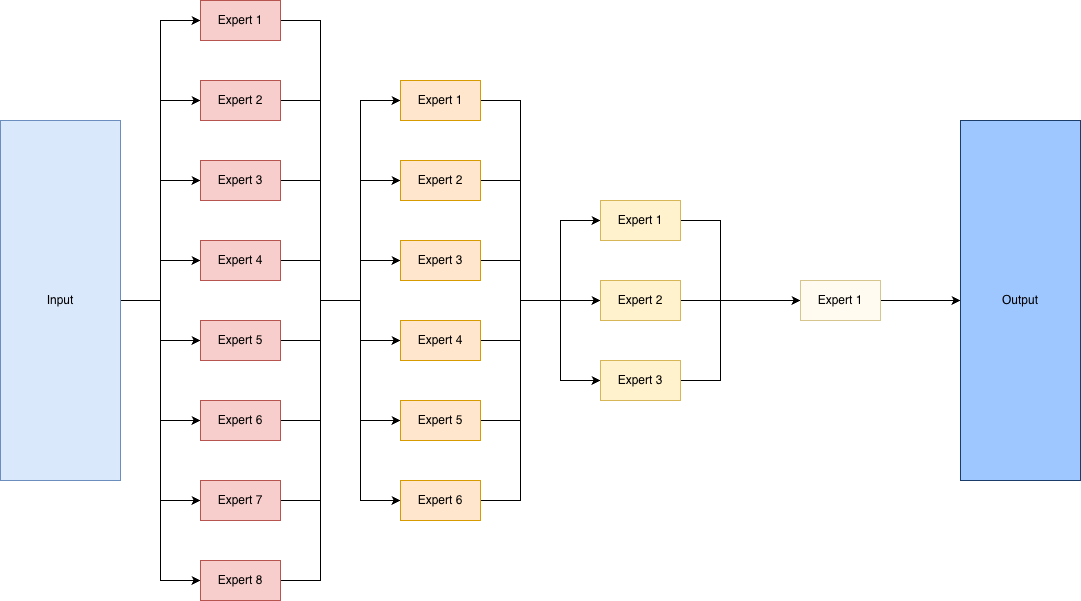
Think of the model as a school with many teachers (experts). Each student (an input token—like a word in a sentence or a small patch of an image) needs help, but not from every teacher. A “gate” acts like a guidance counselor, looking at the student’s needs and deciding which teachers to ask.
- Standard MoE (the old way): the counselor always sends every student to exactly K teachers, no matter what.
- DynaMoE (the new way): the counselor is flexible. If a student’s problem is simple, maybe only 1 teacher is enough. If it’s tricky, more teachers are called in. The number varies per student.
How does the counselor decide? It scores how relevant each teacher is for that student and then keeps all teachers whose score is above a certain cutoff (a “percentile threshold,” like keeping everyone in the top 30%). This way, the number of active teachers naturally adapts.
DynaMoE also changes how many teachers work on each floor (layer) of the school:
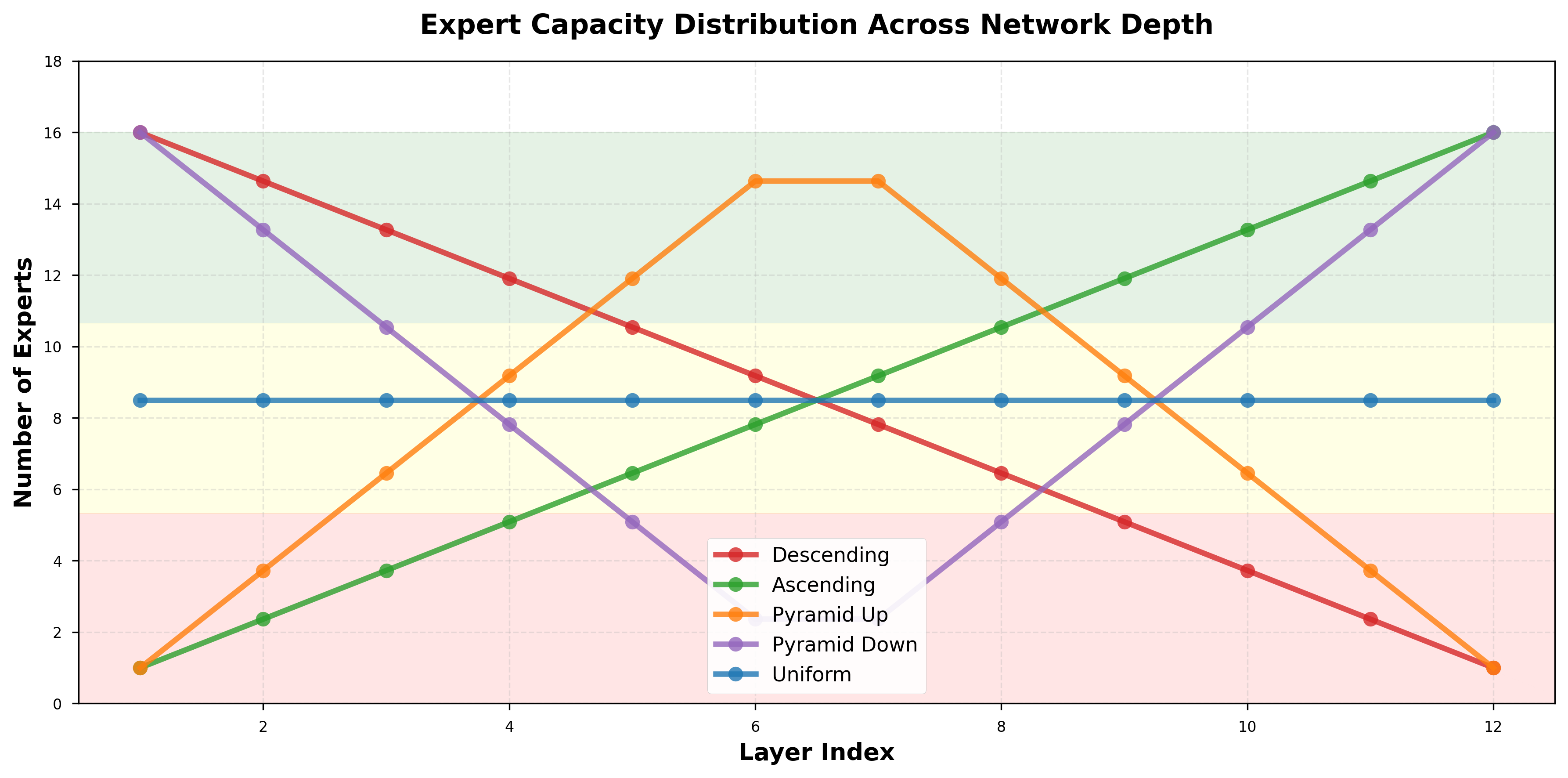
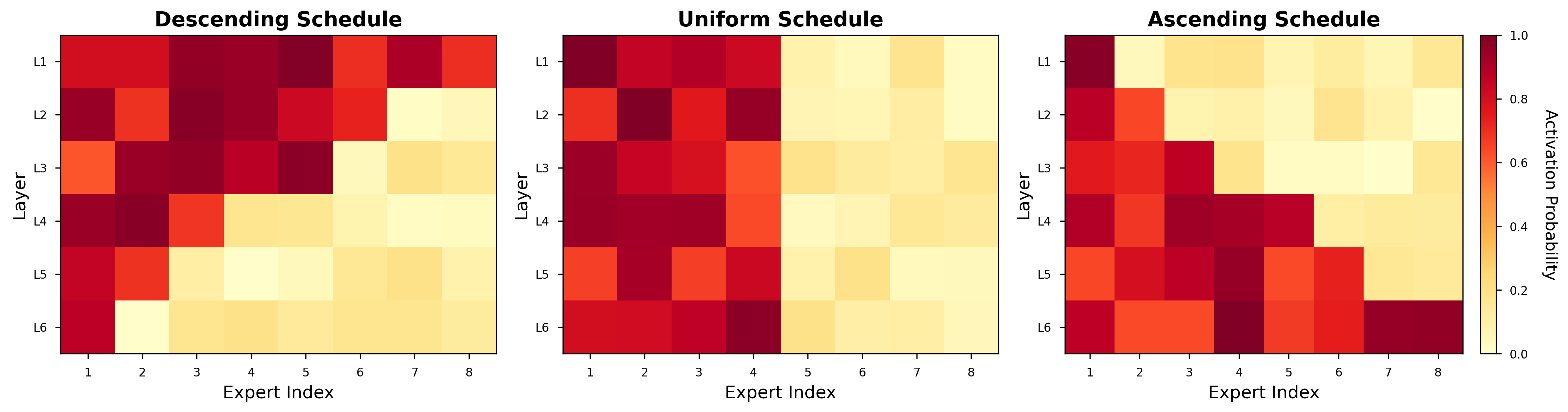
- “Descending” schedule: lots feminist teachers in early floors, fewer in later floors.
- “Ascending” schedule: the opposite—more teachers pipeline later.
- “Pyramid” schedules: most teachers in the middle.
- “Wave” schedules: capacity goes up and down across layers.
- “Uniform” (baseline): the same number of teachers on every floor.
Why do this? Early layers often deal with messy, detailed input (like raw pixels), which may need more specialists. Later layers deal with simpler summaries (like “this looks like a cat”), so they might need fewer.
To test these ideas, the authors trained models on:
- Image classification: MNIST, Fashion-MNIST, CIFAR-10
- Language modeling: a small “Recycling-the-Web” text set (predict the next word/token)
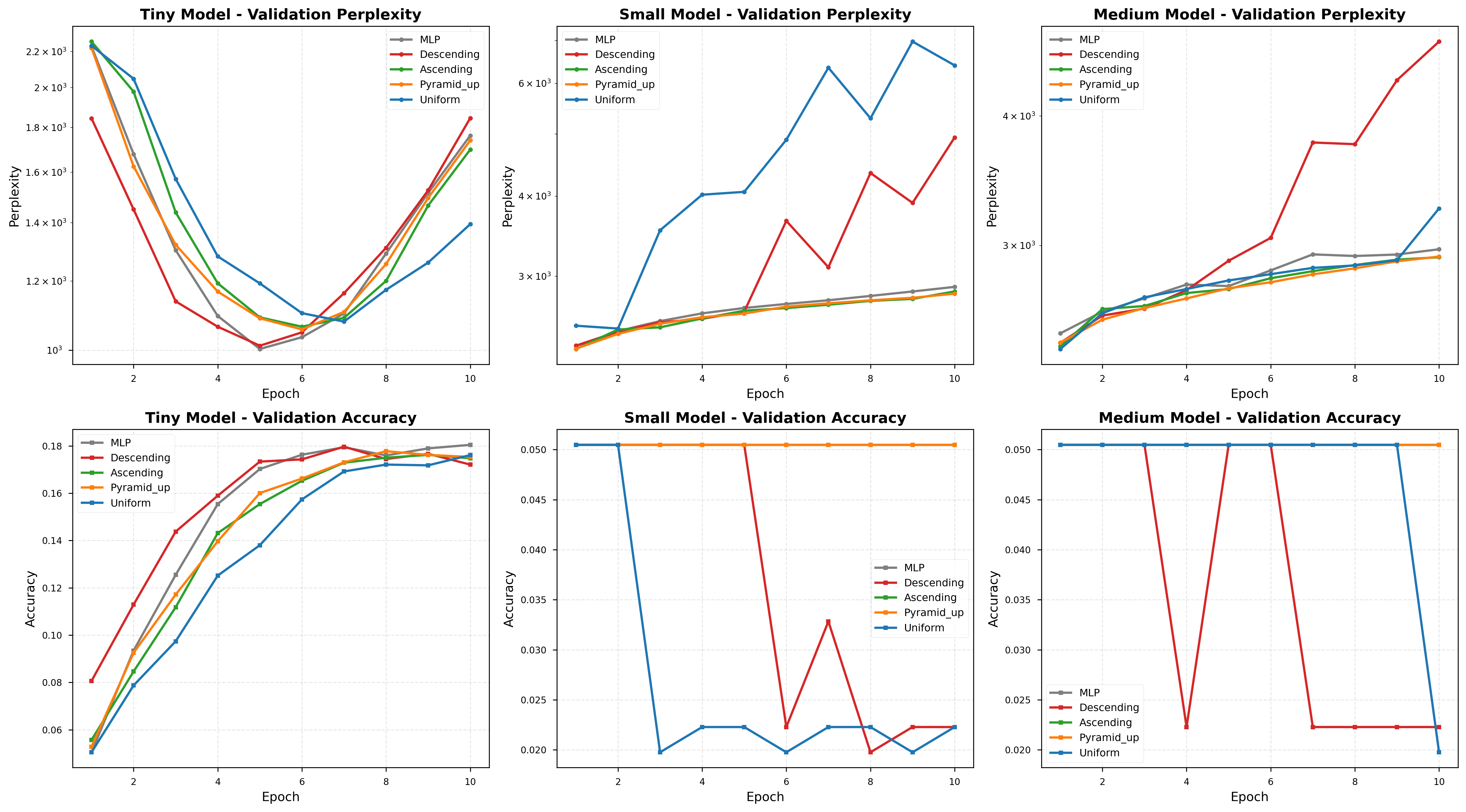
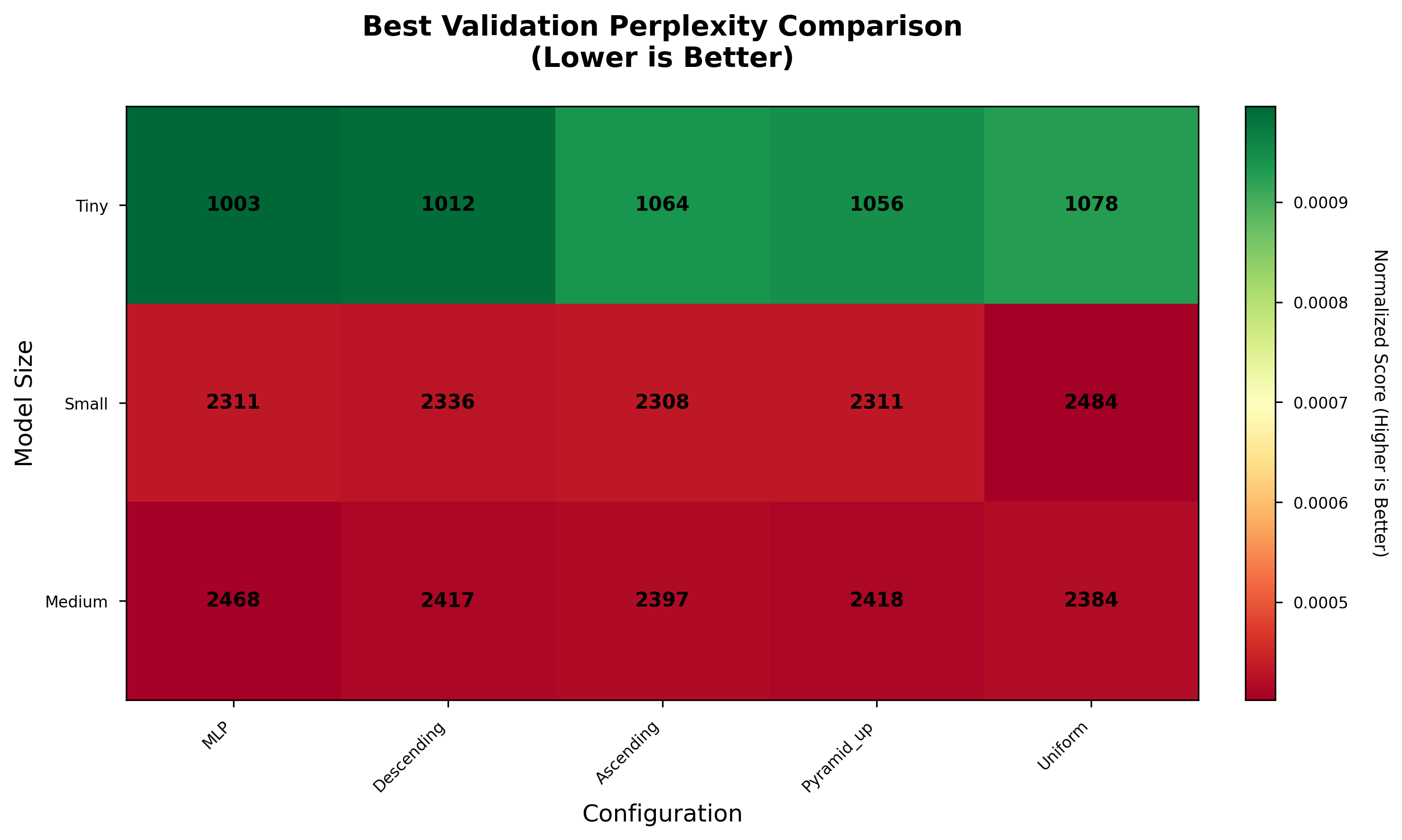
They compared different schedules and model sizes (Tiny, Small, Medium, Large) and checked accuracy, “perplexity” (how confused a LLM is—lower is better), efficiency, and training stability.
What they found and why it matters
Main takeaways:
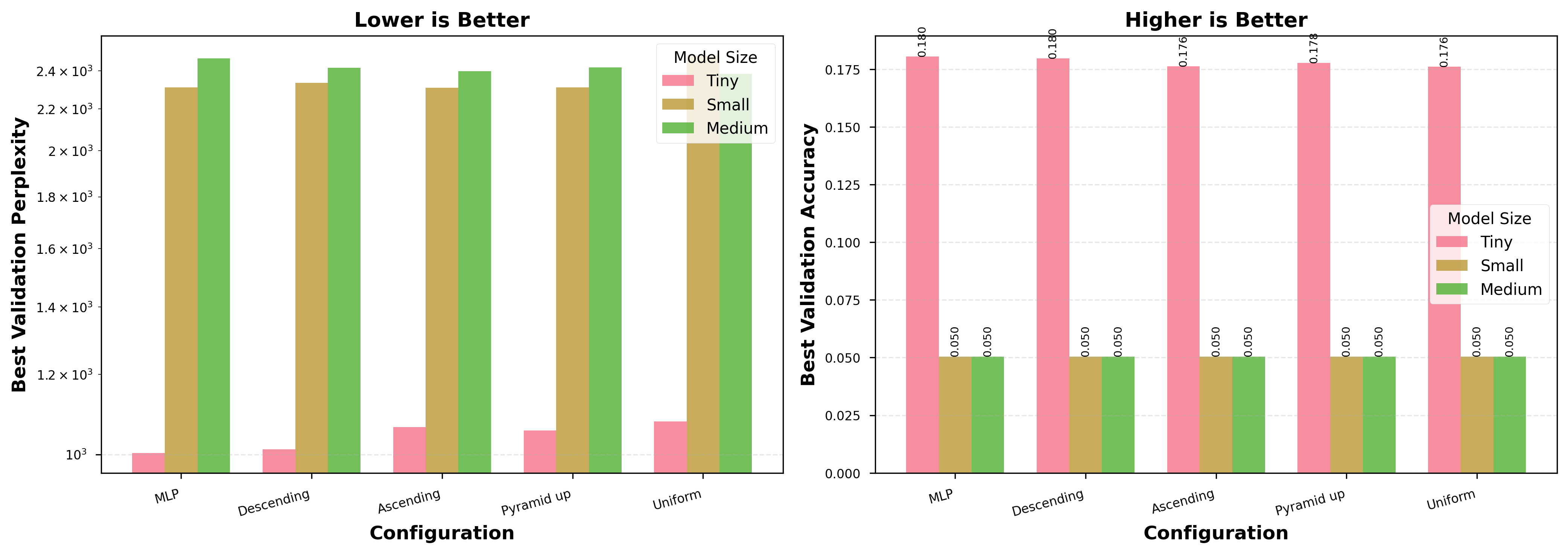
- Image tasks: Putting more experts in early layers (descending schedule) worked best. It improved accuracy across datasets and model sizes, and often trained faster. On CIFAR-10, it beat a uniform setup by up to 5.47%.
- Language tasks: The best schedule depends on model size.
- Tiny models: descending was best among DynaMoE variants and close to the baseline.
- Small models: ascending was best and slightly beat the plain MLP baseline.
- Medium models: uniform was best and improved over the MLP baseline by about 3.4%.
- Note: the language dataset was tiny, so think of these as pilot results, not final verdicts.
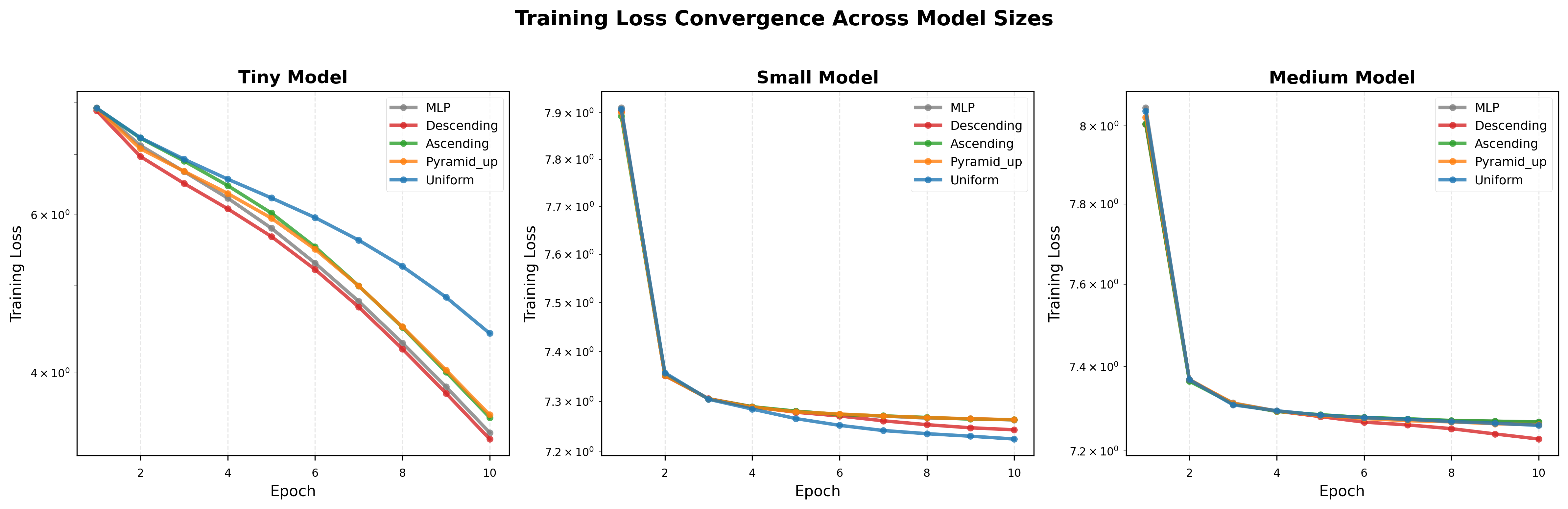
- Dynamic expert choice helps training: Letting the model flexibly pick how many experts to use per input led to more stable training (less wobble in learning). The authors explain this by showing that dynamic routing can reduce “gradient variance,” which you can think of as the training signal being less noisy and more consistent.
- Smarter use of compute: The model learns to spend more effort on harder inputs and where it pays off most (often early layers for images). That means better results without always using more compute.
Why this is important:
- It shows there is no one-size-fits-all design. The best way to distribute experts depends on the task and the model size.
- It gives a clear, practical rule-of-thumb for image models: start with more experts early on.
- For LLMs, it suggests testing different schedules as you scale up.
What this could lead to
- More efficient AI: Models that automatically adjust how much “brainpower” they use based on the input and layer can be faster and cheaper to run while still being accurate.
- Better design guidelines: Instead of guessing, designers can choose expert schedules that match the problem: descending for many vision tasks, and size-dependent choices for language.
- Future upgrades: The current DynaMoE doesn’t include some common tricks for balancing workload across experts (like capacity limits or special balancing losses). Adding those, and testing on bigger, standard language datasets and Transformer models, could make it even stronger.
- Bigger picture: This work pushes toward “adaptive computation,” where AI spends effort where it matters most—just like people do.
Overall, DynaMoE shows that giving models the freedom to choose how many specialists to consult, and where to place those specialists in the network, can make them smarter, steadier learners without wasting compute.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps the paper leaves unresolved, framed to guide future research.
- Capacity and load balancing mechanisms are absent: Implement and evaluate capacity factors, auxiliary load-balancing losses, and expert-choice routing; quantify overflow rates, expert skew, and the impact on throughput and accuracy at scale.
- Large-scale validation is missing: Test DynaMoE on standard, large benchmarks (e.g., ImageNet, WMT, WikiText-103, C4, The Pile) and larger models (≥100M parameters), measuring accuracy/perplexity, stability, and system performance.
- Transformer integration is not explored: Extend DynaMoE to attention-based architectures; compute and analyze the proposed attention probes (attention entropy, effective attention distance, head specialization, superposition pressure) and relate them to schedule optimality.
- Routing threshold design is fixed: Investigate learned or adaptive percentile thresholds (per-layer, per-token, or per-batch), temperature schedules, and dynamic / to balance compute and quality.
- Ablations separating effects are missing: Isolate the contributions of dynamic versus layer-wise scheduling via controlled studies (fixed- with schedules, dynamic- with uniform schedule, and their combinations).
- Fairness of comparisons is limited: Provide parameter-matched, FLOP-matched, and wall-clock matched baselines; include strong MoE baselines (Switch, GShard, expert-choice) with their standard balancing losses.
- System-level performance is unmeasured: Benchmark latency, throughput, memory footprint, communication overhead, and device placement in distributed settings; evaluate hardware efficiency on GPUs/TPUs and expert sharding strategies.
- Overflow handling may negate sparse compute: Quantify worst-case compute inflation when “no token dropping” is used; explore token dropping, backpressure, or prioritization schemes to maintain sparse execution guarantees.
- Training stability claims lack direct evidence: Empirically measure gradient variance with and without dynamic routing; ablate gate noise () and temperature (); assess convergence sensitivity across hyperparameters and datasets.
- Theoretical assumptions are unverified: Test the conditions underlying the gradient variance bound (A1–A3) and “descending optimality” curvature assumption; derive tighter or alternative bounds without independence or entropy assumptions.
- Function-space expressivity analysis is generic: Move beyond combinatorial activation patterns to quantify function-space volume or approximation error improvements under realistic weight distributions and input statistics.
- Expert specialization is not characterized: Measure what each expert learns (e.g., input clusters, feature types, class affinities), track specialization/diversity over training, and study co-adaptation/degeneracy; evaluate regularizers that promote diversity.
- Schedule learning is not attempted: Replace predefined schedules with learned schedules via bilevel optimization, neural architecture search, or reinforcement learning; explore curriculum/annealed schedules that evolve during training.
- Compute-budget-controlled inference is undeveloped: Develop mechanisms to target a fixed compute budget at inference (e.g., tuning to achieve desired ), and study accuracy–latency trade-offs.
- Robustness and generalization are unexplored: Evaluate DynaMoE under distribution shifts, noise, adversarial attacks, and low-data regimes; compare schedule robustness across perturbations.
- Input complexity estimation is assumed, not validated: Test whether gate values (and percentile thresholds) correlate with token complexity; design explicit complexity estimators to inform routing and schedule decisions.
- Expert heterogeneity is underexplored: Vary expert widths/depths per layer, use heterogeneous expert types (e.g., CNN/MLP hybrids), and study pruning/growing strategies; quantify gains vs. uniform expert designs.
- Language modeling evidence is inconclusive: Replace the 1k-sample corpus with standard-scale pretraining; report perplexity/accuracy on established benchmarks and analyze how schedule optimality changes with scale and data domain.
- Stability on diverse, large-vocabulary distributions is unknown: At realistic scales, measure expert collapse/over-selection, routing entropy, and load balance; evaluate mitigation strategies and their interaction with dynamic .
- Data- and phase-dependent scheduling is not examined: Explore schedules that depend on dataset characteristics or training phase (e.g., early descending, later uniform), and assess whether annealing or improves training.
- Initialization and warm-up strategies are unspecified: Study router and expert initialization, routing warm-up, and regularization to prevent early expert collapse or saturation.
- Interpretability of routing decisions is limited: Develop tools to explain why tokens select certain experts across layers/epochs; visualize routing trajectories and their relationship to learned representations.
- Reproducibility and statistical rigor need strengthening: Report multiple seeds, confidence intervals, and variance across runs; detail implementation specifics (hardware, libraries, precision) and release code for replication.
- Energy efficiency and carbon footprint are not measured: Track energy usage and emissions under different schedules/routing policies to inform sustainable scaling.
- Multi-task and cross-domain performance is untested: Evaluate DynaMoE on multi-task settings and diverse domains (vision, language, speech), assessing whether schedule optimality and dynamic routing generalize.
Practical Applications
Immediate Applications
Below are practical, deployable uses that can be adopted now, primarily for small-to-medium models and prototyping, based on the paper’s empirical findings and implementation details.
- Dynamic MoE layer for existing ML pipelines
- Sector: software, computer vision
- Application: Replace dense MLP/CNN feed-forward layers with DynaMoE layers (percentile-based dynamic routing + layer-wise expert schedules) in image classification systems to gain accuracy per parameter and improve convergence stability.
- Tools/products/workflows: PyTorch/TensorFlow module implementing DynaMoE; schedule presets (descending, uniform, ascending); gating visualization utilities.
- Assumptions/dependencies: Best gains observed with descending schedules on image tasks; current implementation lacks capacity limits and auxiliary load-balancing losses; tested on MLPs, not Transformers; small-scale datasets.
- Schedule-guided architecture selection in model design
- Sector: academia, software
- Application: Use the task/scale guidance to select expert schedules—descending for image classification; for language modeling, pick descending (Tiny), ascending (Small), or uniform (Medium).
- Tools/products/workflows: Lightweight “Schedule Selector” in model config files; automated ablations in training scripts to benchmark schedules; expert-usage entropy monitoring.
- Assumptions/dependencies: Results are task- and scale-dependent; language modeling results are on very small corpora (pilot feasibility, not production-ready); re-validation needed on larger datasets.
- Training stability enhancements via dynamic routing
- Sector: academia, MLOps
- Application: Reduce gradient variance and improve convergence stability by adopting per-token variable-K routing with temperature scaling and small gate noise during training.
- Tools/products/workflows: Training recipes adding routing temperature and Gaussian gate noise; dashboards tracking gradient variance proxies and expert-usage entropy.
- Assumptions/dependencies: Variance reduction bound is qualitative and relies on entropy and independence assumptions; stability gains observed in small-scale experiments.
- Edge-friendly adaptive computation for simple inputs
- Sector: mobile, robotics, retail (scanners, cameras)
- Application: On-device image classifiers that allocate more experts only for complex frames (e.g., motion, texture-rich scenes), while simple frames route to fewer experts, potentially reducing average compute.
- Tools/products/workflows: Runtime gating using percentile thresholds; per-frame compute budgeting; expert activation heatmaps for telemetry.
- Assumptions/dependencies: No explicit token-drop or capacity caps; compute/latency benefits must be measured on target hardware; gating overhead must be lower than saved expert FLOPs.
- Educational labs and curriculum
- Sector: education, academia
- Application: Teaching adaptive computation and MoE design principles using the six schedules and dynamic K; demonstrate parameter efficiency and schedule effects on small datasets.
- Tools/products/workflows: Open lab notebooks; interactive visualizations of expert schedules and activation distributions; reproducible scripts for MNIST/Fashion-MNIST/CIFAR-10.
- Assumptions/dependencies: Didactic use is appropriate even with current limitations; emphasize differences between small-scale and production LLM settings.
- Model analysis tooling for expert behavior
- Sector: MLOps, research tooling
- Application: Monitor expert activation entropy, per-layer active-K histograms, and schedule adherence during training to diagnose imbalance or co-adaptation.
- Tools/products/workflows: Visualization dashboards (heatmaps, histograms); alerting for persistent over-selection of specific experts.
- Assumptions/dependencies: Lacks built-in balancing losses; telemetry helps mitigate but doesn’t solve load imbalance by itself.
Long-Term Applications
These opportunities require further research, scaling, and engineering—especially integration with capacity controls, learned routing thresholds, and Transformer-based MoEs.
- Production-grade MoE for LLMs with adaptive schedules
- Sector: software, AI platforms, search, customer support
- Application: Integrate dynamic per-token K and layer-wise capacity schedules into Transformer-based MoE LLMs to balance parameter count, compute, and training stability at scale.
- Tools/products/workflows: DynaMoE-Transformer layers; learned thresholds or per-layer learned K; capacity factors, expert-choice routing, and auxiliary load balancing; schedule AutoML.
- Assumptions/dependencies: Requires large-scale pretraining; rigorous load balancing; memory/throughput benchmarking; robust routing under long sequences.
- Energy-aware AI and “Green MoE”
- Sector: energy, sustainability policy, cloud providers
- Application: Use adaptive expert activation to align compute with input complexity, aiming to reduce average FLOPs and energy consumption without sacrificing accuracy.
- Tools/products/workflows: Energy/latency profilers; carbon accounting dashboards; SLA-aware routing policies (caps on K per token, learned compute budgets).
- Assumptions/dependencies: Must quantify wall-clock and energy savings; needs hardware-aware routing and capacity caps; policy claims depend on measured reductions.
- Hardware–software co-design for conditional compute
- Sector: semiconductors, systems
- Application: Accelerator support for sparse expert activation (fast per-token gating, dynamic kernel launches, memory-aware expert caching) to maximize throughput gains from MoE sparsity.
- Tools/products/workflows: Runtime systems for expert scheduling; compiler/runtime primitives for variable-K execution; cache/placement strategies for heterogeneous experts across layers.
- Assumptions/dependencies: Co-design needed for practical speedups; current FLOP-based advantages may not translate to throughput without specialized runtimes.
- Auto-schedule and learned routing thresholds
- Sector: AutoML, software
- Application: Automatically discover optimal layer-wise expert schedules and dynamic thresholds per task/scale, potentially learning K per token and per layer.
- Tools/products/workflows: Bayesian optimization/evolutionary search over schedules; differentiable threshold learning; multi-objective optimization (accuracy, FLOPs, latency).
- Assumptions/dependencies: Requires robust search infrastructure; careful regularization to prevent collapse; evaluation across diverse tasks.
- Multimodal and multi-task adaptive capacity allocation
- Sector: healthcare (diagnostics), robotics (perception/planning), finance (fraud detection)
- Application: Use schedule variations across modality-specific towers or task heads (e.g., more experts in early vision layers, balanced schedules in language branches) to handle heterogeneous complexity.
- Tools/products/workflows: Task-conditional schedules; shared expert pools with routing constraints; telemetry to avoid expert starvation across tasks.
- Assumptions/dependencies: Complex training regimes; needs strong balancing and fairness controls; thorough validation on real-world data.
- SLA-aware routing in real-time systems
- Sector: cloud, telecom, autonomous systems
- Application: Dynamically bound K per token based on latency/throughput targets (e.g., degrade gracefully under load by lowering K, prioritize complex inputs).
- Tools/products/workflows: Policy controllers for routing budgets; feedback loops from latency monitors; tiered schedules (normal vs. constrained mode).
- Assumptions/dependencies: Requires tight coupling of routing with system telemetry; careful QoS trade-offs; expert overflow handling.
- Robustness and security via ensemble diversity
- Sector: cybersecurity, safety-critical AI
- Application: Explore whether dynamic expert ensembles improve adversarial robustness or out-of-distribution detection by diversifying early-layer processing.
- Tools/products/workflows: Adversarial testing harnesses; OOD benchmarks; expert diversity metrics; schedule tuning for robustness.
- Assumptions/dependencies: Robustness effects are hypothetical; needs empirical studies and formal analyses.
- Knowledge distillation from DynaMoE to compact dense models
- Sector: software, edge AI
- Application: Distill dynamic MoE behavior into smaller dense networks for deployment where conditional routing is impractical, retaining performance benefits.
- Tools/products/workflows: Distillation pipelines capturing expert-weighted outputs; teacher–student schedule transfer; per-layer distillation losses.
- Assumptions/dependencies: Method design required for piecewise-linear behavior transfer; performance preservation must be validated.
- Policy and governance for adaptive compute models
- Sector: public policy, AI governance
- Application: Standards for reporting conditional-compute behavior (average/peak FLOPs, energy), fairness in expert utilization, and transparency in adaptive gating decisions.
- Tools/products/workflows: Model cards including expert scheduling and routing metrics; audits for load balancing and potential bias in expert activation.
- Assumptions/dependencies: Requires consensus on metrics; empirical links between routing policies and fairness outcomes.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization. "Optimizer: AdamW with β1 = 0.9, β2 = 0.999, weight decay 10−4"
- Adaptive computation: Allocating variable compute based on input or model state to improve efficiency. "DynaMoE establishes a new framework for adaptive computation in neural networks"
- Ascending schedule: A layer-wise expert allocation pattern that increases capacity in deeper layers. "2. Ascending Schedule"
- Auxiliary loss: An additional loss term used to encourage desirable properties during training (e.g., balanced expert usage). "a differentiable auxiliary loss penalizing non-uniform expert utilization"
- Capacity allocation: How computational resources (e.g., number of experts) are distributed across layers. "impose rigid constraints on both routing and capacity allocation"
- Capacity constraints: Limits placed on how many tokens an expert can process to avoid overload. "does not impose explicit capacity constraints"
- Capacity factor: A scalar that caps the tokens-per-expert to control load. "a capacity factor c ≥ 1 capping the number of tokens an expert processes"
- Conditional computation: Activating only a subset of a model’s parameters based on the input to save compute. "address this challenge through conditional computation"
- Cosine annealing: A learning rate schedule that follows a cosine curve to gradually reduce the learning rate. "Learning rate: 10−3 with cosine annealing"
- Descending schedule: A layer-wise expert allocation pattern that concentrates capacity in early layers. "descending schedules (concentrating capacity in early layers)"
- Dynamic routing: Input-dependent selection of experts, allowing the number of active experts to vary per token. "expressivity gains of dynamic routing"
- Dynamic Token-Level Routing: A mechanism where the number of active experts per token is chosen dynamically during routing. "Dynamic Token-Level Routing: We propose a routing mechanism where the number of active experts per token varies dynamically"
- Entropy of expert usage distribution: A measure of how evenly tokens are routed across experts. "Expert Utilization: Entropy of expert usage distribution"
- Expressivity: The capacity of a model to represent complex functions. "We theoretically analyze the expressivity gains of dynamic routing"
- Expert activation probability: The likelihood that a given expert is selected for a token. "Expert activation probability heatmaps"
- Expert-choice routing: A routing method where each expert selects its own top-k tokens to ensure balanced loads. "expert-choice routing—in which each expert selects its own top-k tokens"
- Expert schedule: A function specifying how many experts are allocated to each layer. "Expert Schedule"
- Expert utilization: The extent to which experts are used during routing/training. "auxiliary loss penalizing non-uniform expert utilization"
- FLOPs: Floating point operations, a proxy for computational cost. "E[FLOPsℓ] = O(d2 * E[K(x)])"
- Gating network: The module that produces scores used to decide which experts to activate. "the gating network G: Rd → RN computes:"
- Gaussian noise: Random noise sampled from a normal distribution, often added for exploration or regularization. "we add Gaussian noise to gate values for exploration"
- GShard: A large-scale MoE framework demonstrating MoE scalability for multilingual translation. "with GShard"
- Hessian norm: A measure of curvature of the loss landscape using the second derivative matrix. "measured by the Hessian norm ∥∇2_{hℓ} L∥_F"
- Information Bottleneck principle: A theory suggesting deeper layers compress input information while preserving task-relevant content. "By the Information Bottleneck principle"
- Kolmogorov complexity: The length of the shortest description (program) that produces a given object, used to discuss transformation complexity. "Kolmogorov complexity"
- Layer Normalization: A normalization technique applied across the features of a layer’s activations. "Layer Normalization:"
- Layer-Wise Expert Distribution: Varying the number of experts across layers via a schedule. "Layer-Wise Expert Distribution"
- Load imbalance: Uneven distribution of tokens across experts, which can harm training and throughput. "A critical challenge in MoE training is load imbalance"
- Load-balancing losses: Regularizers that penalize uneven expert usage during training. "auxiliary load-balancing losses that penalize uneven expert utilization"
- Mixture-of-Experts (MoE): An architecture that routes inputs to a subset of specialized sub-networks (experts). "Mixture-of-Experts (MoE) architectures"
- Neural tangent kernel: A framework for analyzing the training dynamics and curvature of neural networks. "neural tangent kernel analysis"
- Overflow protection: Mechanisms to prevent experts from receiving more tokens than they can process. "with overflow protection in GShard"
- Percentile threshold: A threshold set by a percentile of gate values to pick variable numbers of experts. "via a percentile threshold on gate values"
- Percentile-threshold mechanism: DynaMoE’s method for variable-K selection using a percentile-based cut on gate scores. "DynaMoE's percentile-threshold mechanism"
- Perplexity (PPL): An exponentiated cross-entropy metric commonly used in language modeling. "Perplexity: For language modeling, PPL = exp(L)"
- Piecewise-linear: A function composed of multiple linear regions; relevant to MoE’s representational capacity. "piecewise-linear functions"
- Pyramid-Down schedule: A capacity pattern with more experts at shallow and deep layers, fewer in the middle. "Pyramid-Down"
- Pyramid-Up schedule: A capacity pattern peaking in the middle layers. "Pyramid-Up"
- Residual connection: A skip connection that adds a layer’s input to its output to ease optimization. "(residual connection)"
- Routing entropy: The entropy of the distribution over experts selected by the router. "the routing entropy H_dyn ≥ H_fixed"
- Scheduling Optimization: The problem of finding an expert schedule that minimizes expected loss under a capacity constraint. "Scheduling Optimization"
- Soft weighting: Combining outputs of selected experts using normalized gate scores rather than hard selection. "the soft weighting in Eq. 10 distributes credit across selected experts"
- Switch Transformers: An MoE model that routes each token to a single expert for efficiency. "Switch Transformers"
- Temperature parameter: A scalar in softmax that controls the sharpness of the distribution over experts. "where T is a temperature parameter"
- Temperature scaling: Adjusting the softmax temperature to stabilize training or calibrate probabilities. "maintaining stability through temperature scaling"
- Token overflow: A condition where too many tokens are routed to the same expert, exceeding its capacity. "token overflow: when too many tokens in a batch exceed the activation threshold for a given expert"
- Top-1 routing: Routing each token to exactly one expert. "top-1 routing"
- Top-2 routing: Routing each token to exactly two experts. "top-2 routing"
- Top-K routing: Routing each token to the K experts with the highest gate scores. "Fixed Top-K Routing"
- Wave-Down: A schedule with oscillatory capacity that trends downward across depth. "Wave-Down"
- Wave-Up: A schedule with oscillatory capacity that trends upward across depth. "Wave-Up schedule"
Collections
Sign up for free to add this paper to one or more collections.