When an AI Judges Your Work: The Hidden Costs of Algorithmic Assessment
Abstract: We use an online experiment with a real work task to study whether workers change their behavior when they know AI will be used to judge their work instead of humans. We find that individuals produce a higher quantity of output when they are assigned an AI evaluator. However, controlling for quantity, the quality of their output is lower, regardless of whether quality is measured using humans or LLM grades. We also find that workers are more likely to use external tools, including LLMs, when they know AI is used to judge their work instead of humans. However, the increase in external tool use does not appear to explain the differences in quantity or quality across treatments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple but important question: Do people work differently when they know an AI, not a person, will judge their work? The authors run a real online task—writing captions for pictures—to see how being graded by an AI “robot grader” versus a human changes how much people write, how good their writing is, and whether they use outside help like ChatGPT.
What questions the researchers wanted to answer
In clear terms, the study focuses on three main questions:
- Does knowing an AI will grade you change how you work (for example, how long you write or how fast)?
- Does it change the quality of your work?
- Are people more likely to use outside tools (like ChatGPT) when AI is judging them instead of a human?
They also look at whether AI grading is cheaper and faster than human grading, and what trade-offs that creates.
How the researchers did the study
Here’s the setup, explained in everyday language:
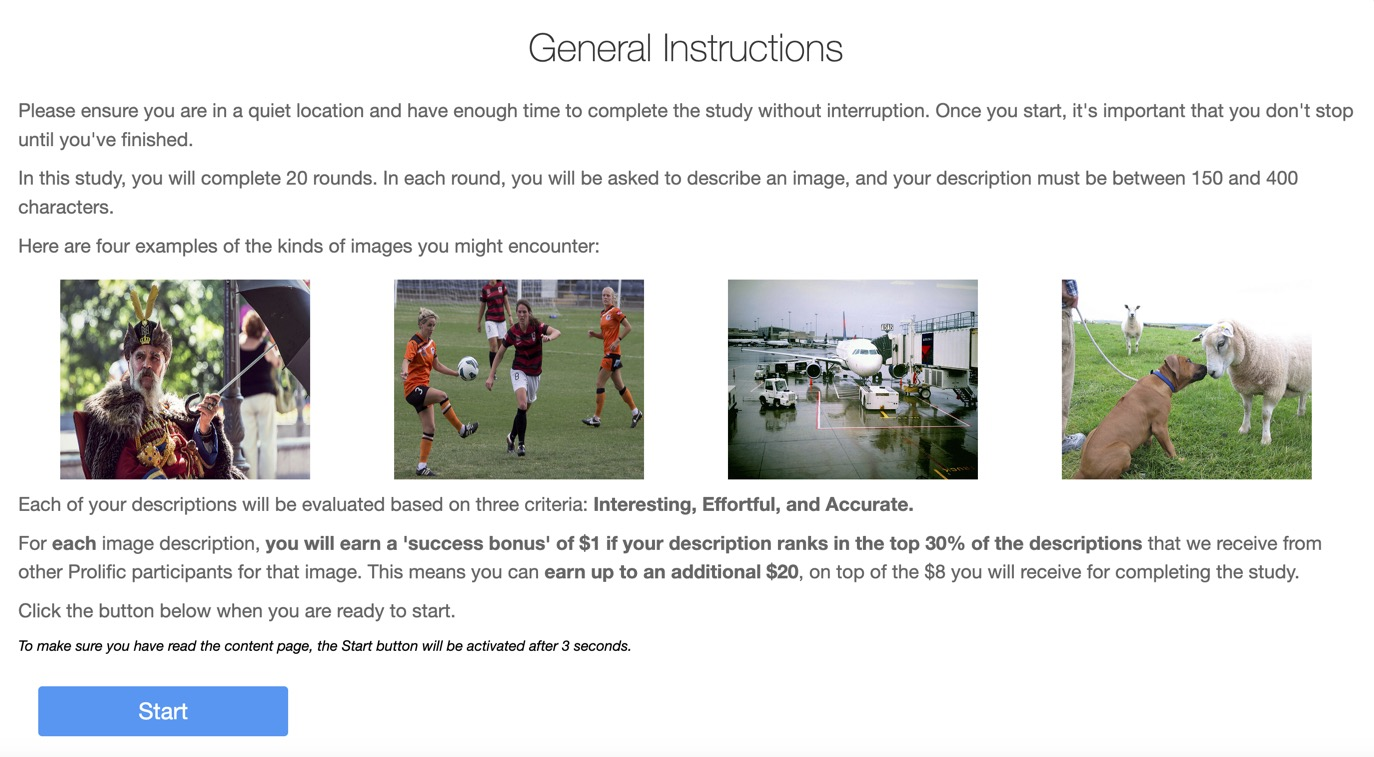
- People were hired online to write 20 short captions for everyday photos (like kids with skateboards or someone squeezing oranges). Each caption had to be 150–400 characters.
- Everyone was told what “good” meant: captions should be interesting, show effort, and be accurate.
- For each photo, if your caption scored in the top 30% (compared to others on the same photo), you got a $1 bonus. You could earn up to$20, on top of an $8 base payment.
- Crucially, people were randomly told one of two things:
- “A human (a college graduate) will grade your captions,” or
- “ChatGPT (an AI) will grade your captions.”
- Each person had the same evaluator for all 20 photos and didn’t know the other kind of evaluator existed.
- The researchers quietly measured:
- How long each caption was
- How much time people spent
- Whether any text was pasted in (as a clue they might have used outside help)
- After the task, both human graders and an AI model also graded every caption, so the researchers could compare quality from different judges.
- The team also tried to find out who used AI tools. They asked people if they used something like ChatGPT and, in a clever twist, offered a $1 bonus if their answer matched what an AI-detection tool guessed about their writing. This encouraged more honest answers.
Two important ideas explained simply:
- “Controlling for length” means comparing captions of similar length so you’re judging quality fairly. For example, if one person writes 300 characters and another writes 150, the longer one might look better just because it’s longer. So the researchers compare captions of similar length to see which is truly better written.
- “External tools” means anything outside help, especially AI like ChatGPT. Pasting text was used as a simple sign that someone might have used outside help.
What the study found and why it matters
Here are the main results, in plain language:
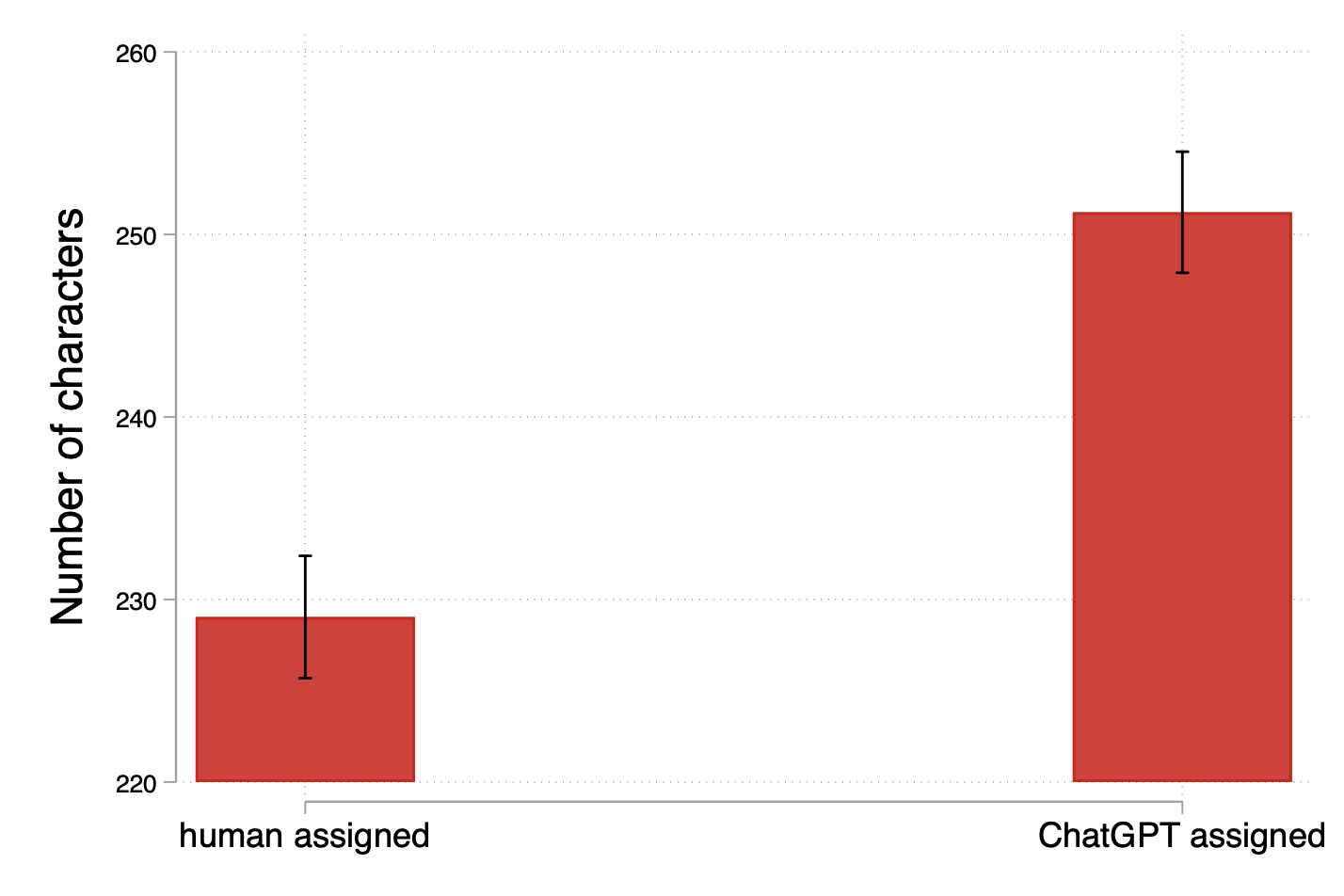
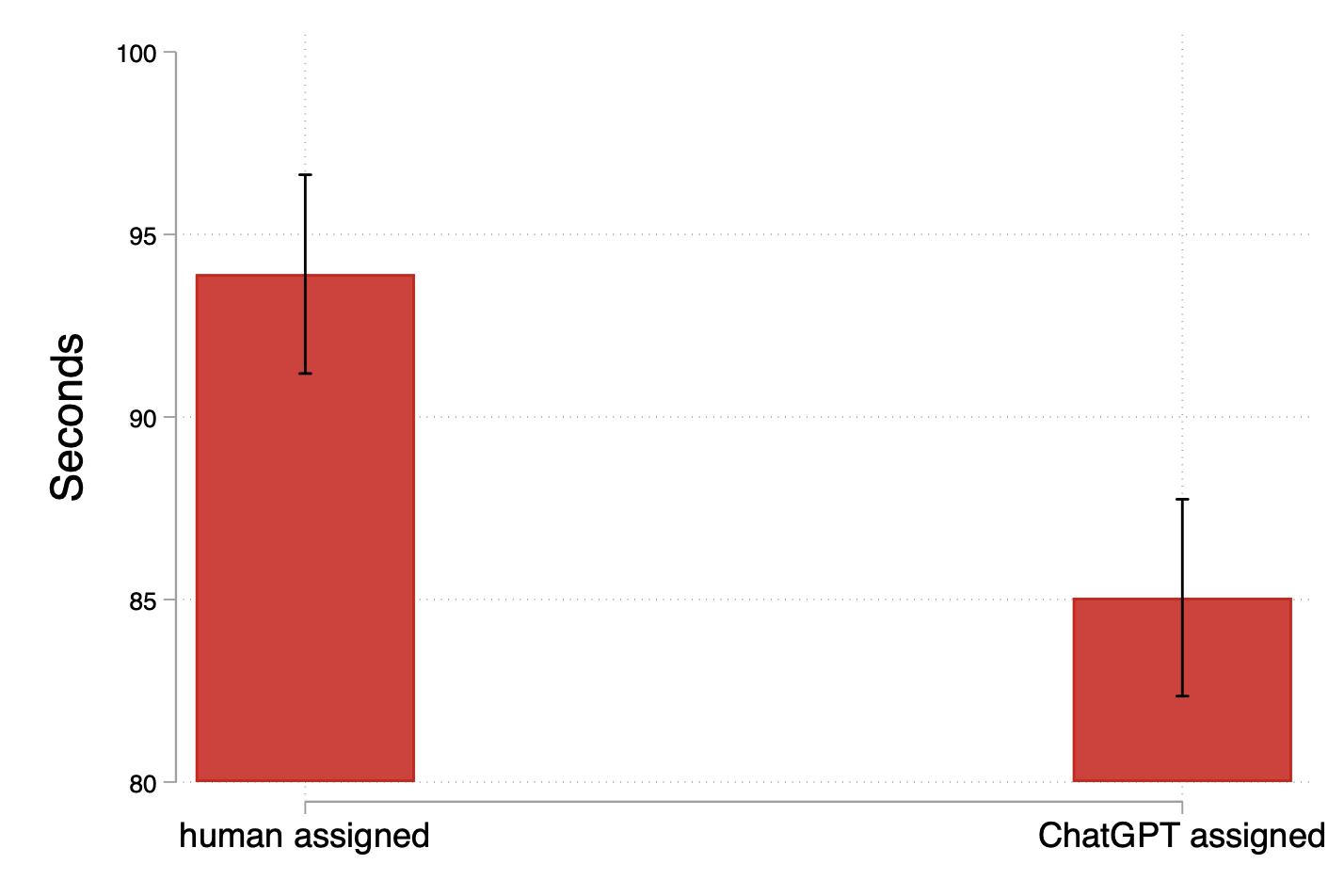
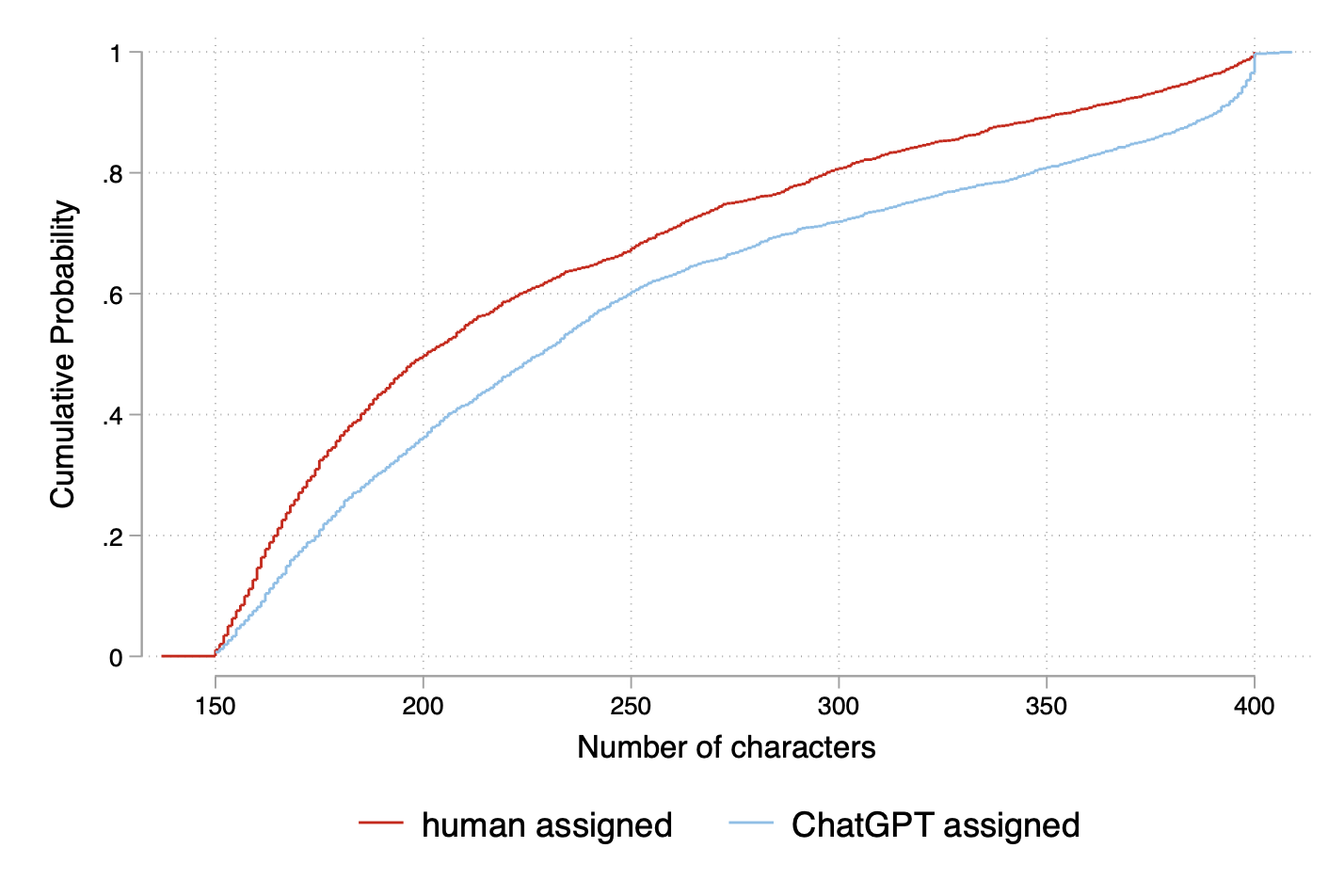
- People wrote more (and a bit faster) when AI was grading.
- Captions were longer under AI grading than under human grading.
- People spent slightly less time per caption with AI as the grader.
- Translation: when the “robot grader” is in charge, people tend to produce more text, more quickly.
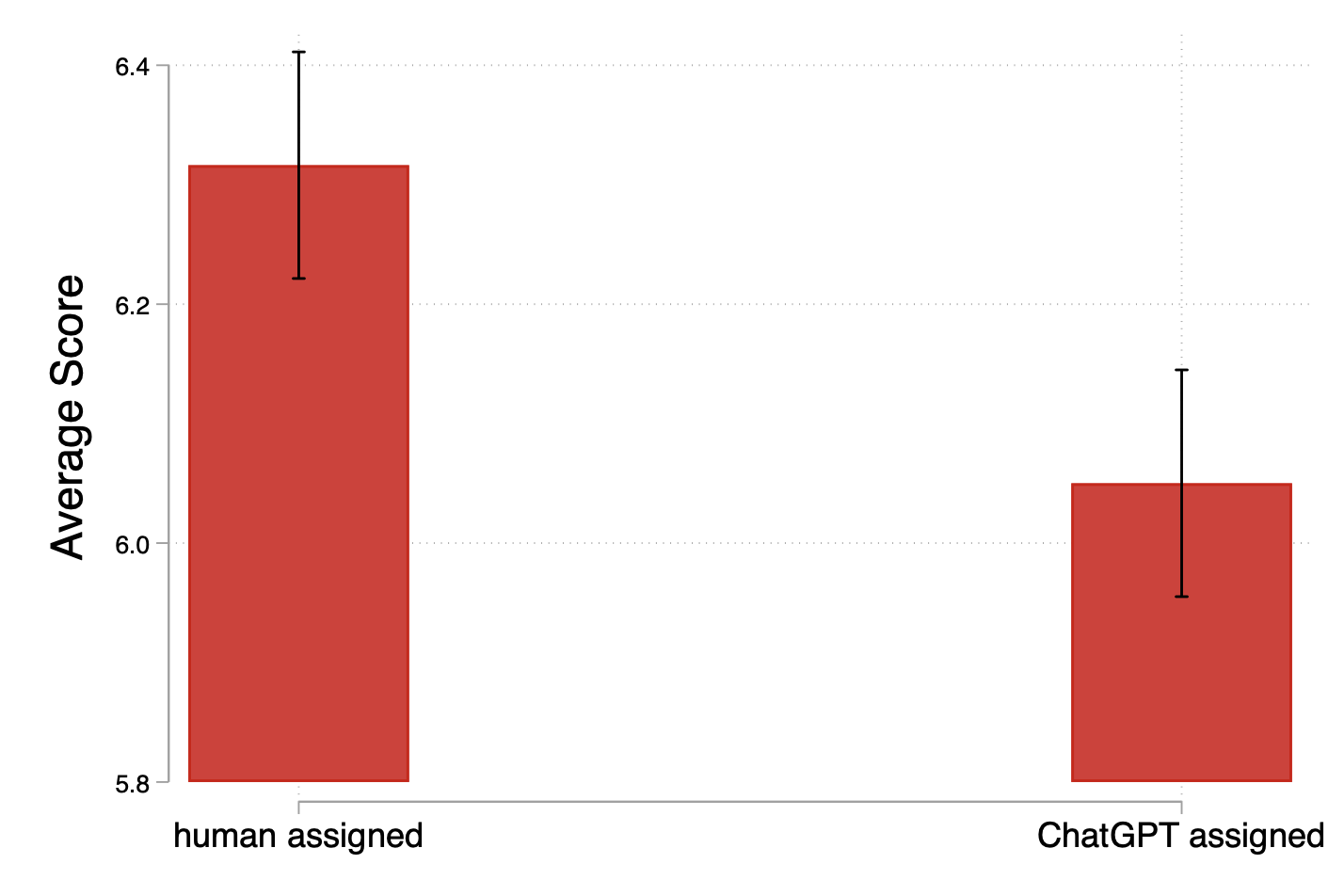
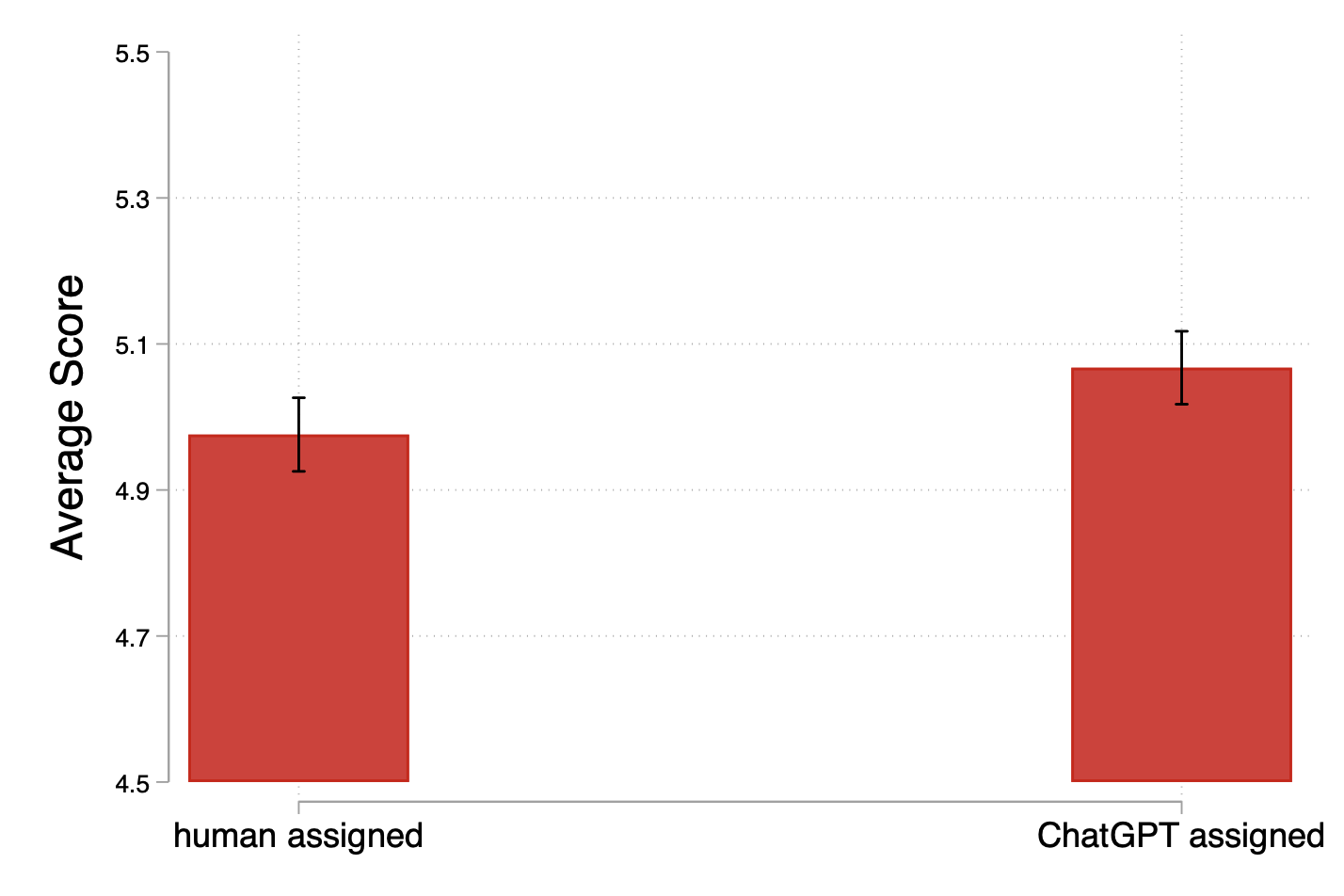
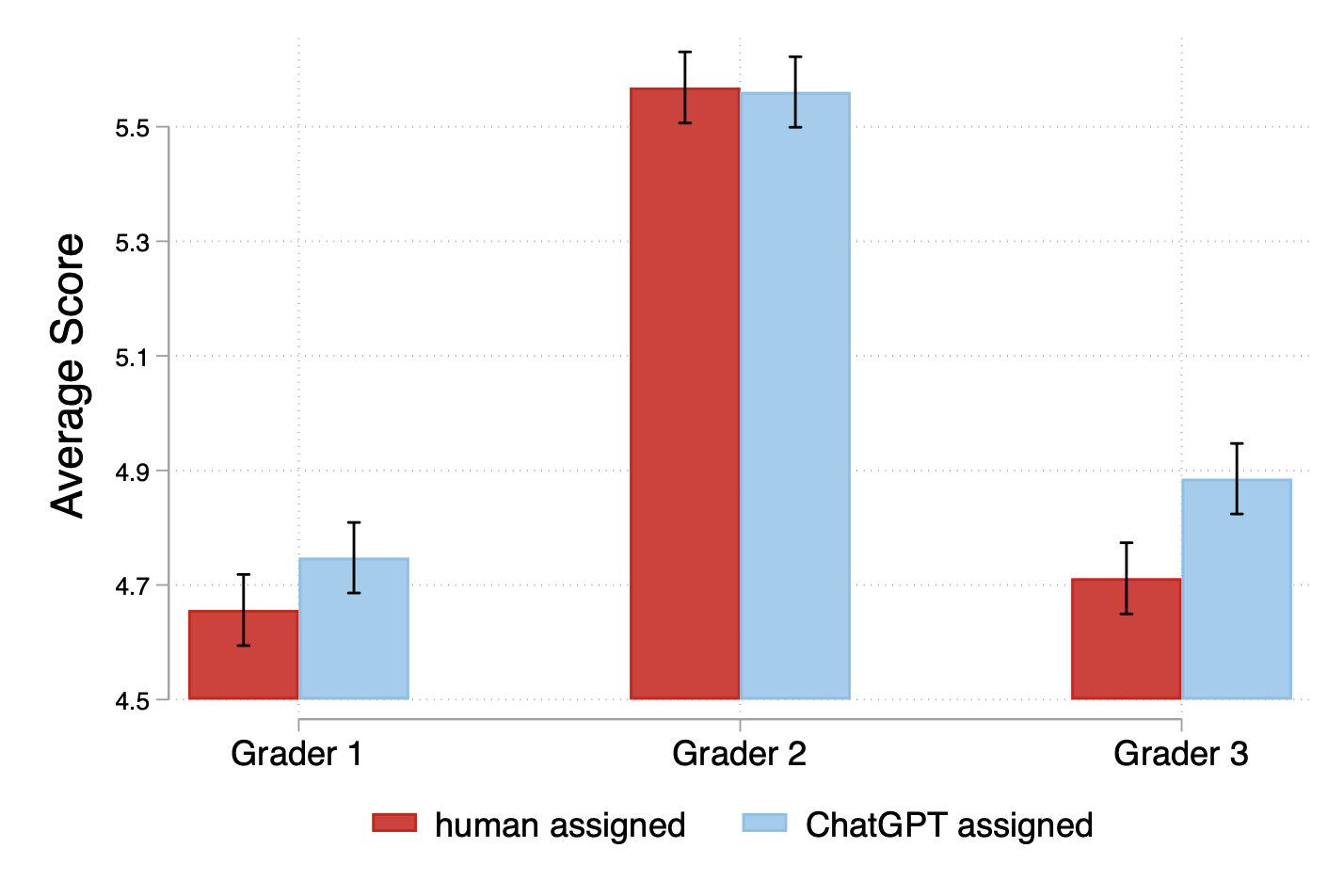
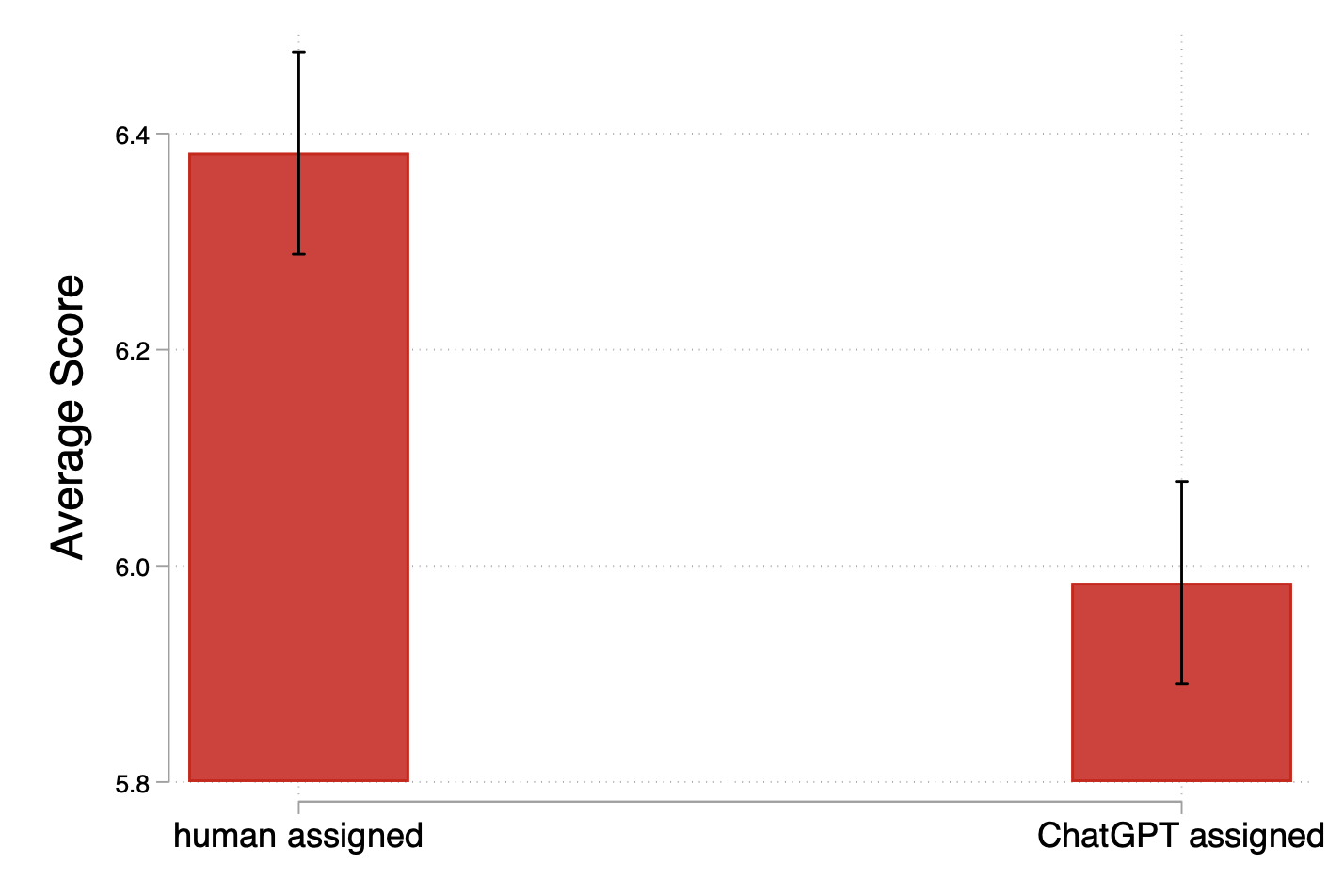
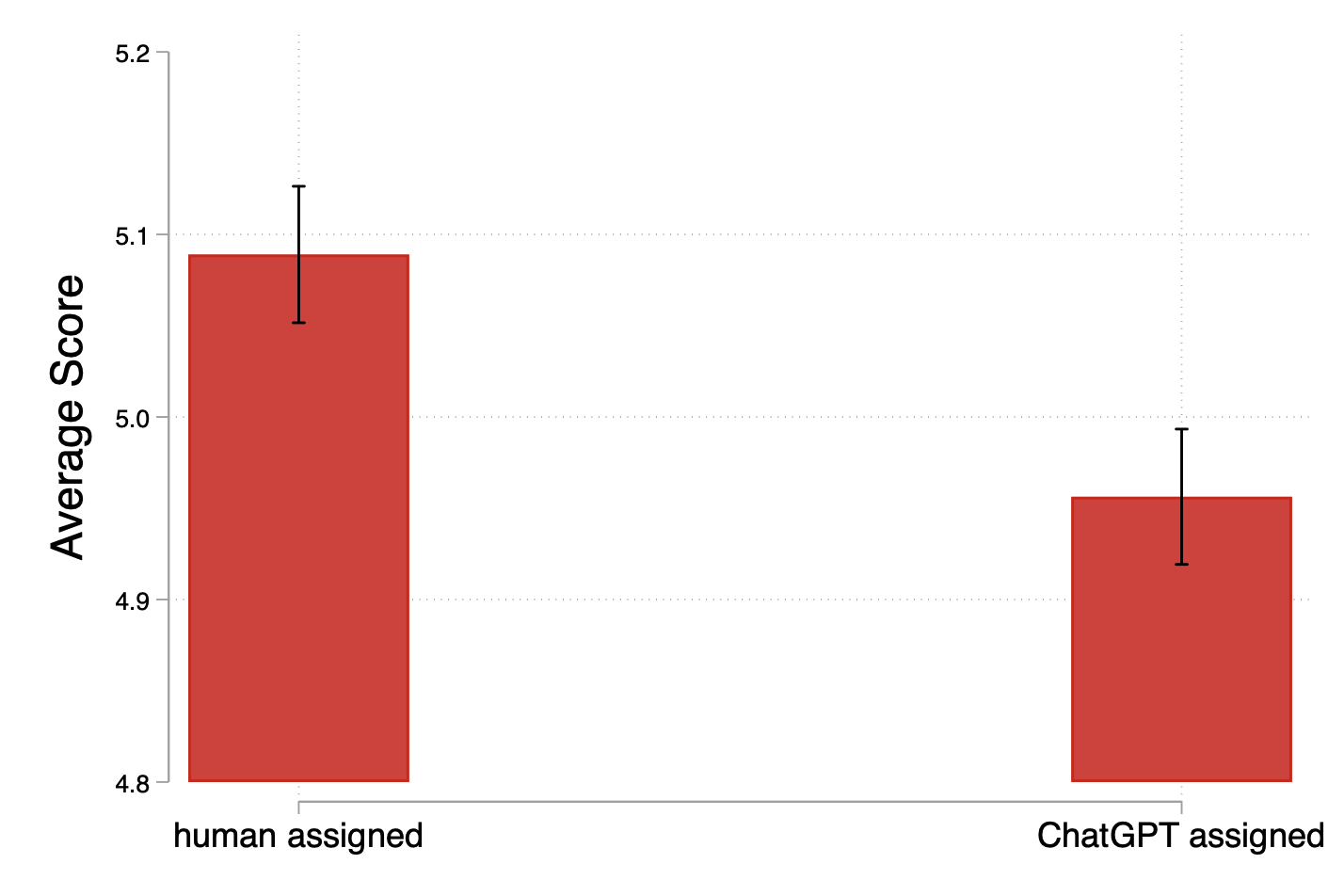
- But once you compare captions of similar length, quality was lower when AI was the evaluator.
- When the researchers compare “apples to apples” (captions of the same length), the writing quality is worse if the writer thought an AI would grade them.
- This shows that the extra quantity under AI didn’t translate into better quality—in fact, quality dropped.
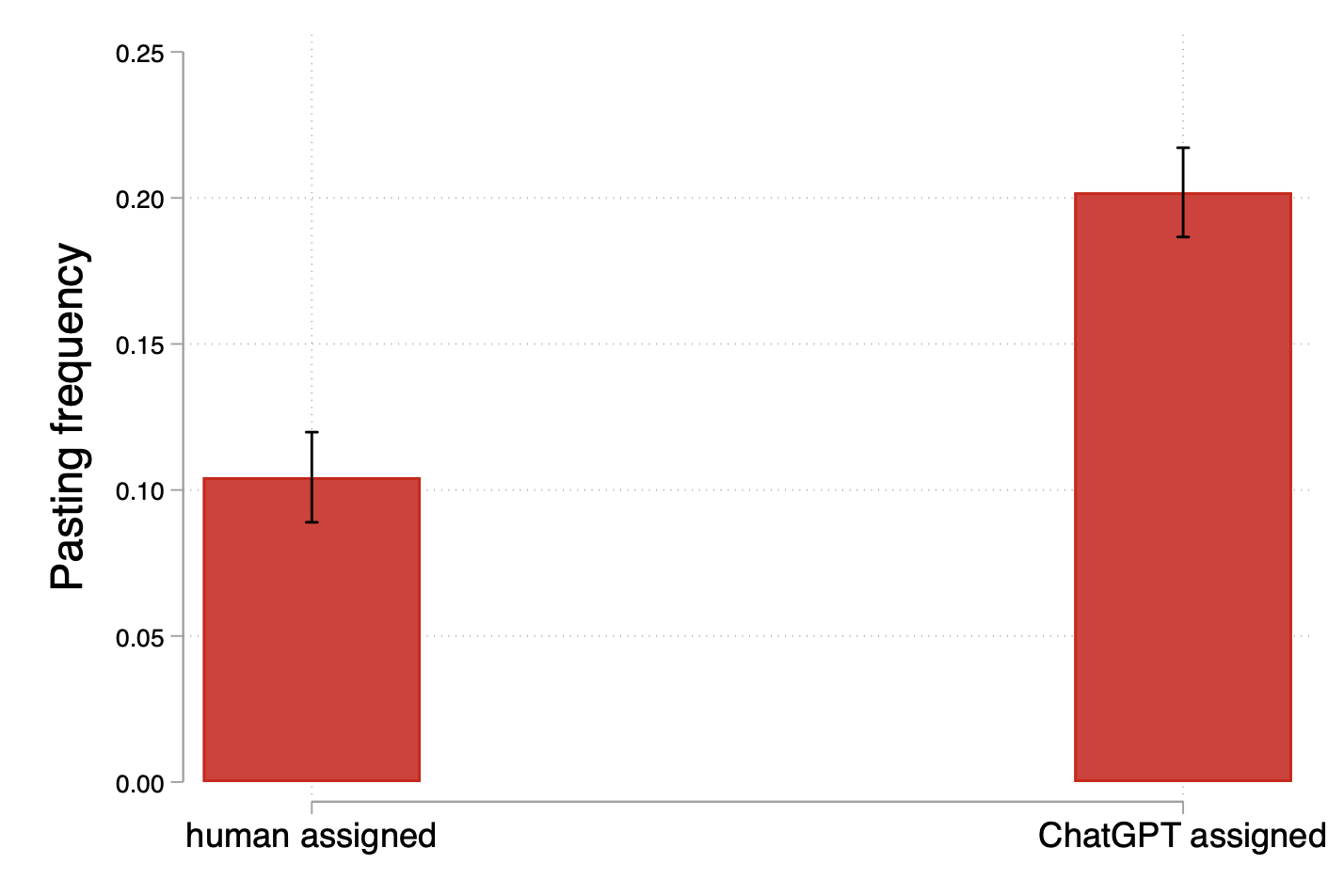
- People used outside tools more when AI was grading.
- Participants were almost twice as likely to paste text (a proxy for using tools like ChatGPT) when they thought an AI was grading them.
- Interestingly, captions that used outside help were often judged higher quality by humans, so the rise in tool use does not explain the lower quality under AI grading. In other words, “more tool use” isn’t the reason quality fell.
- People care more about human approval.
- Participants said they felt happier about getting a high score from a human than from an AI. That suggests people may try harder or be more careful when a real person is judging them.
- AI grading is much cheaper and faster for organizations.
- In this study, having AI grade everything cost about $11.67 and one day of coding.
- Human grading took three grad students around 54 hours total and cost $6,480.
- So AI grading saves a ton of money and time—one reason schools and companies might want to use it.
- A new way to detect AI help worked pretty well.
- Paying people a small bonus if their “I used AI” answer matched an AI detector made more people admit they used tools. This gives researchers and teachers a better way to check for AI assistance when simple copy-paste tracking won’t work.
Why these results matter:
- The big trade-off is clear: AI grading saves time and money and changes how people work, but it may also lead to lower-quality writing when you account for length. That’s a hidden cost organizations need to consider.
What this could mean for schools, jobs, and everyday life
- For schools and teachers: If students know an AI will grade their work, they might write more but not necessarily better. To keep quality high, schools might combine AI with human review, set clear rules about using tools like ChatGPT, or design assignments that reward careful thinking, not just length.
- For companies: AI grading can cut costs and speed up feedback. But if quality is crucial—like in creative work, customer communication, or reports—companies may need to keep some human oversight or adjust incentives so people still aim for thoughtful, careful work.
- For policy and fairness: People behave differently when AI is the judge. That means leaders should think not only about “Can AI do this?” but also “How will people react?” Good design and clear guidelines can reduce unintended side effects.
In short: When a “robot grader” is watching, people tend to write more and lean on tools more, but their work can be less carefully crafted. AI grading offers big savings, but organizations should balance those benefits with strategies to keep quality high.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored, structured so future researchers can act on it.
- External validity: The study uses one short, creative writing task (image captioning) with US Prolific workers. Replicate across diverse tasks (e.g., coding, data labeling with ground truth, analytics, essays), industries, and populations (non-US, multilingual) to assess generalizability.
- Short-term design: Outcomes reflect a single 75-minute session. Test longitudinal effects under repeated or career-relevant evaluation (e.g., quarterly reviews, promotions) to see if the quantity–quality trade-off persists or attenuates.
- Mechanisms: The paper hypothesizes non-monetary motives (e.g., pride from human validation) but does not isolate mechanisms. Explicitly measure and manipulate social evaluation concerns, perceived fairness/competence, embarrassment, trust in evaluator, and intrinsic motivation to identify causal drivers.
- Evaluator disclosure: Being told “who evaluates you” may itself drive behavior. Randomize transparency (disclosed vs undisclosed evaluator), framing (human/manager vs “algorithm” vs “AI expert”), and the salience of evaluator identity to quantify demand effects.
- Asymmetric messaging: Human evaluators were described as “college graduates,” but ChatGPT received no analogous competence framing. Equalize and vary evaluator descriptors to test the impact of perceived evaluator expertise on effort and tool use.
- Quality measurement lacks ground truth: “Interesting, Effortful, Accurate” are subjective. Create objective labels (e.g., annotated objects/relations in images) to quantify accuracy precisely and separate accuracy from interest/effort.
- Inter-rater reliability: The paper does not report agreement among human graders or between humans and GPT. Compute inter-rater metrics (e.g., Cohen’s kappa, ICC) and adjust for measurement error to assess robustness of quality conclusions.
- Prompt/model sensitivity: Results rely on GPT-4o with specific prompts and temperature. Systematically vary LLM models (e.g., GPT variants, Claude, Gemini), temperatures, and rubric prompts to quantify grading sensitivity and ensure replicability.
- Hybrid evaluation designs: Examine human-in-the-loop and ensemble graders (human + AI or AI pre-screen + human final review) to test whether mixed systems mitigate the quantity–quality trade-off.
- Incentive scheme design: Bonuses are relative (top 30% per image within evaluator). Compare against absolute thresholds, continuous scoring, and task-based payments to see if effects are specific to rank-based incentives.
- Beliefs about evaluator criteria: Elicit and manipulate participants’ beliefs about what each evaluator values (e.g., length, creativity, accuracy) to test whether strategic tailoring explains treatment effects.
- Control for output length: Key findings hinge on controlling for length. Pre-register and test robustness to alternate controls (e.g., quadratic length terms, readability, lexical diversity) and text-content features to rule out residual confounding.
- Image-level heterogeneity: Investigate whether effects vary by image complexity/content (e.g., crowded scenes vs simple scenes) using interaction models and pre-specified difficulty metrics.
- External tool use measurement validity: Pasting is an imperfect proxy and AI detectors have known false positives/negatives. Develop validated instrumentation (e.g., keystroke/clipboard logging, browser telemetry with consent), triangulate with self-reports, and benchmark detectors on ground-truth datasets.
- Distinguish types of assistance: Disaggregate external tools (LLMs, grammar/style tools, search, domain info lookups) and quantify their differential impacts on quality and time.
- Policy variation on assistance: Randomize regimes (allowed, discouraged, prohibited, disclosed use) and enforcement (e.g., paste restrictions, audits) to estimate how assistance policies shape behavior and quality.
- Timing and feedback: No evaluator feedback was given. Test immediate vs delayed feedback, qualitative comments vs scores, and iterative grading to measure effects on learning and effort.
- Cost–quality trade-off modeling: Extend the cost savings analysis with a structural/decision model that accounts for quality changes, error costs, reputational risks, and throughput to inform adoption under different objective functions.
- Power and heterogeneity: With N=208, the study may be underpowered for subgroup analyses. Pre-register and test heterogeneity by demographics, baseline writing skill, AI familiarity/attitudes, and prior tool usage.
- Baseline balance and attrition: Provide and assess treatment balance on pre-task covariates and any differential attrition to rule out selection-driven differences.
- Multiple testing and preregistration clarity: Clarify which analyses (e.g., length controls, subgroup splits) were pre-registered vs exploratory, and apply multiple-comparison corrections to reduce false positives.
- Changes in elicitation mid-study: The AI-use question was initially unincentivized, then incentivized with a detector. Document timing, randomization, and comparability across participants, and assess whether the change affected measured outcomes.
- Validate detector choice: Specify the AI detector used and validate its accuracy on known human/LLM texts from the study context; compare multiple detectors to reduce classification uncertainty.
- Text-level forensics: Conduct content analyses (e.g., stylistic markers, readability indices, topic coverage, object mentions) to identify how captions differ under AI vs human evaluation beyond length, and which features drive graders’ scores.
- Reputational and fairness perceptions: Measure perceived fairness, legitimacy, transparency, and morale under AI vs human assessment; test whether these mediate changes in effort, tool use, and quality.
- Real-world field settings: Run field experiments in firms (hiring screens, performance reviews, creative tasks) to validate whether lab-observed behavioral shifts appear under organizational constraints and stakes.
Practical Applications
Immediate Applications
- Hybrid evaluation workflows for creative and knowledge tasks (software, media, data labeling)
- Use case: Adopt AI for fast, low-cost triage and feedback, but keep human review for final decisions where quality matters (e.g., social media captions, product descriptions, annotation for ML datasets, UX copy).
- Product/workflow: “AI-first, human-final” pipeline with length-normalized scoring, multi-criteria rubrics (interesting/effort/accuracy), and auditing of AI grades on a random sample.
- Assumptions/dependencies: Quality-sensitive contexts; availability of qualified human reviewers; AI graders can handle task modality (e.g., image+text).
- Evaluation rubric and prompt engineering playbook (education, enterprise software)
- Use case: Standardize multi-criterion grading and avoid shortcut behavior in LLM evaluation by prompting each criterion separately and controlling temperature to reduce drift.
- Product/workflow: Prompt templates for separate scoring of criteria, temperature tuned (≈0.75 or task-specific), criterion-specific instructions, and structured outputs for downstream analytics.
- Assumptions/dependencies: LLM access with multimodal capability when needed; organizational buy-in for rubric consistency.
- Length-normalized quality metrics and guardrails (content ops, academic grading)
- Use case: Counteract quantity-over-quality gaming when AI is the evaluator by normalizing grades for length and penalizing verbosity without substance.
- Product/workflow: Grade regressions or heuristics that control for caption length; minimum/maximum length with adaptive penalties; dashboards monitoring length–quality correlations.
- Assumptions/dependencies: Reliable estimation of quality signals; tasks where length–quality confounding is observed.
- Instrumentation to monitor external tool use and writing process (platforms, research labs)
- Use case: Track pasting events, erasures, and writing time to infer assistance and adjust quality assurance or incentives in crowd work and experiments.
- Product/workflow: “Pasting and Interaction Telemetry SDK” for web tasks capturing copy/paste, edit histories, and time per item; policy hooks to flag for review.
- Assumptions/dependencies: Privacy-compliant telemetry; clear disclosure to workers; legal review for monitoring.
- Incentivized disclosure of AI assistance (academia, hiring, freelancing platforms)
- Use case: Encourage honest reporting of AI tool use by paying for disclosures that align with detector outputs, augmenting low-reliability detectors.
- Product/workflow: “Assisted-use Disclosure Incentives” module: post-task questionnaire with bonus tied to detector agreement; combine with telemetry for triangulation.
- Assumptions/dependencies: Detector choice and accuracy; IRB/ethical approval; workers trust the incentive scheme.
- Messaging and incentive design to improve quality under AI assessment (HR, education)
- Use case: Mitigate quality drops when AI judges by explicitly valuing concision, depth, and accuracy and by highlighting human oversight to boost intrinsic motivation.
- Product/workflow: Task headers that state human oversight or random human audit; non-monetary recognition for high-quality work; rubrics emphasizing substance over length.
- Assumptions/dependencies: Behavioral effects generalize beyond captioning; messaging does not create legal/ethical issues.
- Cost–benefit adoption framework for algorithmic assessment (operations, procurement)
- Use case: Quantify savings from AI grading versus human time and wages; set thresholds for when human review is economically justified based on quality risk.
- Product/workflow: ROI calculators incorporating time-to-grade, wage rates, expected quality impact, and downstream error costs; decision templates for managers.
- Assumptions/dependencies: Accurate local cost parameters; ability to estimate quality-driven rework/error costs.
- Policy and practice guidance for immediate deployment (organizational governance, compliance)
- Use case: Internal policies that require human-in-the-loop for high-stakes outcomes and disclose assessment modality to workers; track external tool use impacts.
- Product/workflow: Governance checklist (disclosure, oversight, detector use, telemetry consent), risk registers for fairness/legal/morale, and incident review procedures.
- Assumptions/dependencies: Legal counsel alignment; worker council or union input where relevant.
Long-Term Applications
- Standards and regulation for algorithmic assessment (policy, labor, education)
- Use case: Develop sector-specific guidelines that require impact assessments on worker behavior (quantity vs. quality), transparency about evaluators, and human oversight in high-stakes contexts.
- Product/workflow: National/industry standards (e.g., auditing protocols, disclosure norms, quality-adjusted metrics) and accreditation for compliant systems.
- Assumptions/dependencies: Multistakeholder consensus; evolving legal frameworks; evidence across diverse tasks.
- Adaptive evaluator systems that shape behavior toward desired outcomes (enterprise platforms, edtech)
- Use case: Systems that dynamically adjust criteria, messaging, and audit rates to discourage gaming and increase substantive quality when AI is the judge.
- Product/workflow: “Adaptive Assessment Orchestration Layer” with behavioral policy levers (e.g., human audit probability), feedback personalization, and outcome monitoring loops.
- Assumptions/dependencies: Robust behavioral models; safe experimentation; data infrastructure.
- Cross-modal and robust AI-use detection beyond pasting (security, compliance, research)
- Use case: Detect assistance via stylometry, semantic fingerprints, interaction traces, and multimodal signals, reducing reliance on copy/paste.
- Product/workflow: Integrated detection suite combining telemetry, stylometry, and model-based attribution; uncertainty-aware reporting to avoid false positives.
- Assumptions/dependencies: Technical advances in reliable detection; ethical safeguards; acceptance by institutions.
- Behavior-aware incentive systems for workplaces (HR tech, gig platforms)
- Use case: Rebalance incentives to prevent “quantity inflation” under algorithmic judgment, e.g., quality-weighted piece rates or effort proxies validated by human audits.
- Product/workflow: Compensation models that incorporate quality scores adjusted for confounds; audit-triggered bonuses; learning-oriented feedback cycles.
- Assumptions/dependencies: Valid proxies for quality; worker acceptance; mitigation of unintended strategic behavior.
- AI evaluators calibrated to human standards via alignment and RLHF (software, education)
- Use case: Reduce divergence between AI and human grading by training AI evaluators on human rubric outcomes and penalizing verbosity without substance.
- Product/workflow: Fine-tuned evaluator models with human-grade datasets; evaluation consistency checks; periodic retraining to track drift.
- Assumptions/dependencies: Access to high-quality human-labeled evaluation data; resources for fine-tuning and monitoring.
- Sector-specific adoption frameworks (healthcare, finance, public services)
- Use case: In domains like radiology or claims processing, define when AI assessment is appropriate, where hybrid review is mandatory, and how to measure downstream impact from quality changes.
- Product/workflow: Domain playbooks tying evaluator choice to risk classes, audit intensities, and escalation paths; integration with case management systems.
- Assumptions/dependencies: Task risk stratification; regulatory oversight; ground-truth validation pipelines.
- Experimental methods toolkit for academia and industry research (R&D, behavioral science)
- Use case: Generalize the paper’s elicitation and telemetry methods to study AI’s behavioral impacts across tasks (coding tests, summarization, design critiques).
- Product/workflow: Open-source experimental templates (Flask or modern stacks), telemetry modules, incentivized disclosure questionnaires, and analytic pipelines.
- Assumptions/dependencies: Funding for tooling; community adoption; IRB approvals.
- Worker-centric design to harness intrinsic motivation (organizational design)
- Use case: Incorporate signals of human presence (e.g., periodic human feedback, named reviewers, narrative feedback) to improve effort and quality under algorithmic systems.
- Product/workflow: Blended feedback interfaces; recognition systems; transparent evaluation narratives; choice architectures that emphasize craftsmanship.
- Assumptions/dependencies: Measurable motivation effects across roles; careful UX to avoid deception; cultural fit.
Notes on assumptions and dependencies across applications:
- Findings are from an image captioning task with US-based online workers; behavioral effects may vary by task complexity, stakes, and workforce demographics.
- LLM capabilities and grading reliability evolve; quality impacts may attenuate as evaluators improve or align with human rubrics.
- External tool detection has false positives/negatives; ethical and privacy constraints require transparent consent and careful use of telemetry.
- Relative-performance bonus mechanics were used; alternative incentive schemes may produce different behaviors.
- Communication about evaluator type influences behavior; organizations must balance transparency with the desired behavioral outcomes and legal considerations.
Glossary
- Algorithmic assessment: The use of algorithms to evaluate work outputs instead of human evaluators. "algorithmic assessments can be perceived as less fair"
- Between-subject design: An experimental setup where different participants are assigned to different conditions, allowing treatment comparisons across groups. "Using a between-subject design, we randomly assigned subjects to have their captions evaluated by a human or by ChatGPT"
- Clustering standard errors: An econometric technique that adjusts standard errors for within-cluster correlation to avoid overstating statistical significance. "including demographic controls, image fixed effects, and clustering standard errors at the individual level."
- Crowding-out: A behavioral economics phenomenon where external incentives or monitoring reduce intrinsic motivation and effort. "This ``crowding-out'' phenomenon was later carefully tested by \textcite{Dickinson2008}"
- Empirical CDF: The empirical cumulative distribution function, an estimate of the CDF constructed from sample data. "Caption length empirical CDF by treatment."
- Field experiment: An experiment conducted in a real-world environment rather than a lab, often with naturally occurring subjects. "Using a field experiment on call centers, \textcite{Nagin2002} find that workers may strategically respond to monitoring"
- First-order stochastic dominance: A relationship between distributions where one yields greater or equal values for all thresholds, implying uniformly better outcomes. "there is also a first-order stochastic dominance relationship as seen in Figure \ref{fig:LengthFOSD}."
- Fixed effects: Controls that absorb constant attributes of units (e.g., images) to identify effects from within-unit variation. "including demographic controls, image fixed effects, and clustering standard errors at the individual level."
- Generative AI (GenAI): AI systems that can create new content (text, images, etc.) rather than merely analyze existing data. "The emergence of Generative AI (GenAI), primarily driven by LLMs, has radically expanded the set of tasks that AI can evaluate"
- General equilibrium effects: Economy- or system-wide indirect effects that arise when a change (like AI adoption) affects multiple markets or behaviors simultaneously. "it is essential to evaluate the general equilibrium effects of integrating AI into workflows"
- Hierarchical firms: Organizations structured in levels of authority and responsibility; often modeled to study information and decision flows. "provide organizational insights into how AI may reshape hierarchical firms."
- Incentivized elicitation method: A mechanism that pays participants based on the accuracy of their reports to encourage truthful disclosure. "This provides a novel incentivized elicitation method to identify AI usage."
- Institutional Review Board (IRB): A committee that reviews and approves research involving human subjects to ensure ethical standards. "IRB approval was obtained at the University of California, Santa Barbara."
- LLMs: Very large neural network models trained on extensive text data to perform language understanding and generation tasks. "primarily driven by LLMs"
- p-value: The probability, under a specified null hypothesis, of observing results as extreme as (or more extreme than) those found. "with a two-sided test of means p-value < 0.0001"
- Piece-rate work: Compensation based on the number of units produced rather than time worked. "including those who complete piece-rate work through platforms"
- Principal-agent theory: A framework analyzing incentive and information problems between a principal (e.g., employer) and an agent (e.g., worker). "Contrary to the predictions of principal-agent theory, \textcite{Frey1993} proposed that monitoring might negatively impact workers' effort"
- Preregistration: Publicly committing to a study’s design and analysis plan before data collection to reduce researcher degrees of freedom. "We conducted our pre-registered online experiment"
- Prolific (platform): An online platform for recruiting and paying research participants commonly used in academic studies. "In our experiment, conducted on the Prolific platform, we asked subjects to write captions"
- Rational cheaters: Individuals who strategically exploit monitoring and incentives to their advantage when it is beneficial to do so. "consistent with a model of ``rational cheaters''."
- Relative performance payments: Compensation schemes based on a worker’s performance rank relative to peers. "Relative performance payments may raise concerns about participants trying to infer the performance of others."
- System prompt: The special instruction message supplied to an LLM to define its role and constraints for a task. "every request contained the correct system prompt, image, and caption."
- Temperature (LLM): A sampling parameter controlling output randomness; higher values increase diversity and creativity. "we set the temperature at 0.75."
- Treatment effect: The causal impact attributable to being assigned to a particular experimental condition. "Section \ref{sec:results} examines the treatment effect of evaluator assignment on writing habits, quality, and the use of external assistance."
- Two-sided test of means: A hypothesis test that checks for differences in either direction between group means. "with a two-sided test of means p-value < 0.0001"
- Willingness to pay (WTP): The maximum amount an individual would pay for a good, service, or feature. "we elicited participants' willingness to pay (WTP) for their preferred evaluator"
- Winsorized: A data transformation that limits extreme values to specified percentiles to reduce the influence of outliers. "We winsorized the time variable at the 5th and 95th percentiles due to extreme outliers."
Collections
Sign up for free to add this paper to one or more collections.