- The paper presents preconditioning techniques for continuous-time generative models to mitigate geometric bottlenecks in optimization.
- It demonstrates that normalizing flow-based preconditioning stabilizes training by isotropizing intermediate distributions and lowering condition numbers.
- Empirical results on datasets like MNIST and LSUN validate the method’s enhanced convergence and improved sample fidelity.
Preconditioned Score and Flow Matching: Conditioning, Geometry, and Optimization in Continuous-Time Generative Models
Introduction and Motivation
Continuous-time generative modeling frameworks such as flow matching and score-based diffusion fundamentally rely on learning vector fields to transport a simple base distribution (e.g., Gaussian) to a complex target distribution. Training these models involves a regression problem over intermediate distributions pt, whose geometry can critically impede optimization. This paper demonstrates that the covariance structure Σt of these distributions governs a strong optimization bias: if Σt becomes ill-conditioned, gradient-based methods rapidly fit directions of high variance but suppress optimization along low-variance directions, resulting in suboptimal convergence and a plateauing of training loss before model capacity is exhausted.
The authors provide a formal analytic study of such bottlenecks using tractable cases (Gaussian, Gaussian mixture) and introduce preconditioning frameworks—reversible label-conditional maps that isotropize pt—to address these obstacles without altering the underlying generative model's capacity or architecture. This approach substantially mitigates optimization stagnation and enables superior trained models.
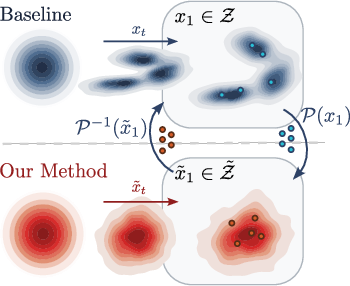
Figure 1: Standard flow matching versus preconditioned transport, outlining the direct path from reference to data manifold and the two-stage (preconditioned) process that reshapes data geometry for improved convergence.
Geometric Conditioning and Optimization Barriers
The core insight is that both flow and score matching reduce to a sequence of least-squares regression problems parameterized by t, with each step sampling from a distribution pt interpolating between base and target. When the target is highly anisotropic or multimodal, the covariance Σt for intermediate t becomes increasingly ill-conditioned. As t→1, Σt inherits the bad conditioning of the data space, which forces SGD and its variants into regimes where only high-variance principal directions are fit efficiently.
Detailed spectral analysis in the linear Gaussian case illustrates that the eigenvalues of Σt take the form:
σi(t)=(1−t)2+t2λi,
where λi are the eigenvalues of the target covariance. The condition number κ(Σt) increases with t, so as training proceeds towards the data manifold, optimization becomes progressively hampered in suppressed directions.
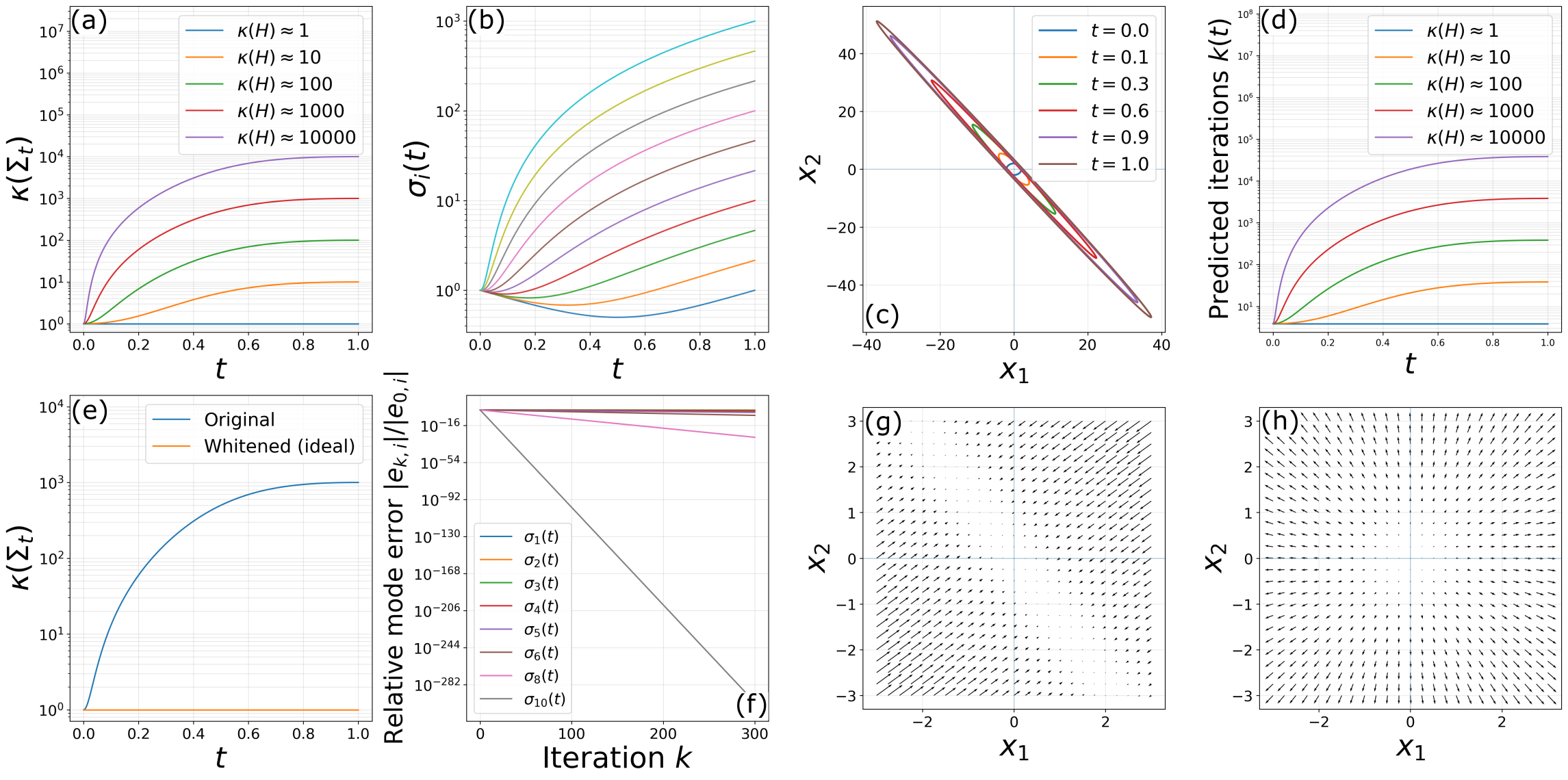
Figure 2: Growth in condition number of Σt and spectral disparities along interpolation, visualizing the transition from isotropic to highly ill-conditioned distributions.
The effect is not remedied by increased model capacity, architectural modifications, or data volume, and is exacerbated in multimodal cases (Gaussian mixtures), where convergence becomes dominated by the hardest-to-fit component.
Preconditioned Flow and Score Matching
Drawing an analogy with preconditioning for linear solvers, the authors propose to invertibly map the target data to a space where its geometry is more isotropic—specifically, to "whiten" the data with a learned (normalizing flow or flow-based) preconditioner P. The generative training is performed in this preconditioned latent space and then mapped back to the original data manifold. Theoretical guarantees demonstrate that this transformation renders the regression problems better conditioned (condition number close to 1), enabling optimization to proceed without stagnation even in previously suppressed directions.
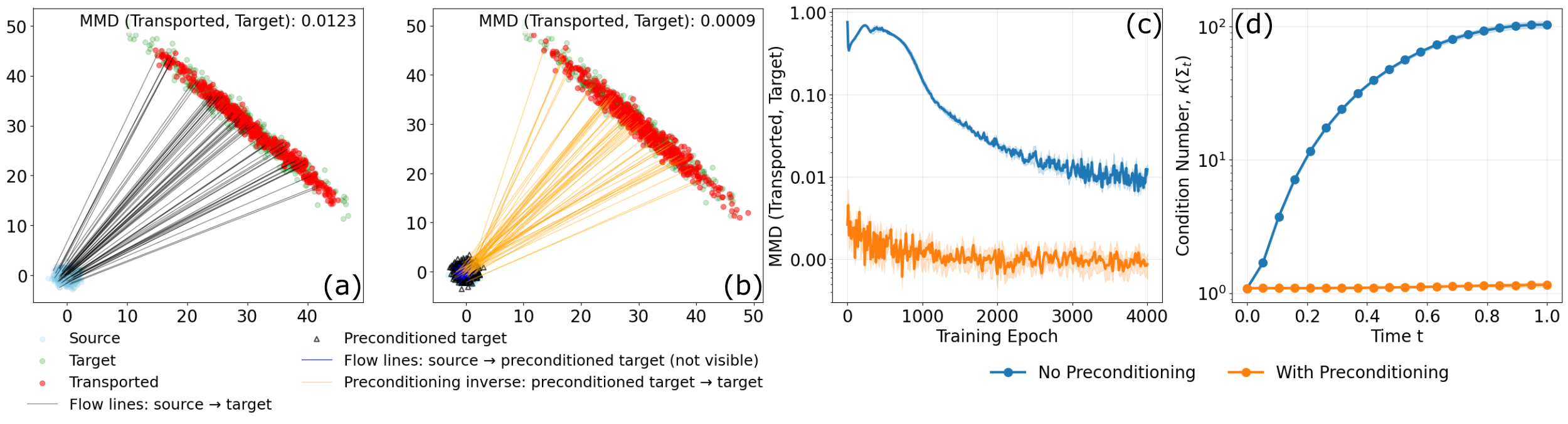
Figure 3: Comparison of 2D Gaussian transport with and without preconditioning; preconditioning yields lower MMD, prevents stagnation, and achieves dramatically improved conditioning of the transport operator.
The preconditioning operator can be constructed in several ways:
- Normalizing flow-based preconditioning: mapping the target to an approximately Gaussian distribution via invertible, tractable flows.
- Low-capacity flow-based preconditioning: using a lightweight flow matching model to push forward the target data into a more isotropic configuration, then applying standard flow matching in this transformed space.
These approaches are algorithmically simple and compatible with any core flow or score matching implementation.
Empirical Validation
The paper presents comprehensive experiments on both low-dimensional tasks (e.g., Swiss roll, Checkerboard to Swiss Roll transport) and complex image datasets (MNIST, LSUN Churches, Oxford Flowers-102, AFHQ Cats).
Swiss Roll Transport: Direct flow matching without preconditioning suffers from misaligned, distorted, and poorly covering sample trajectories.
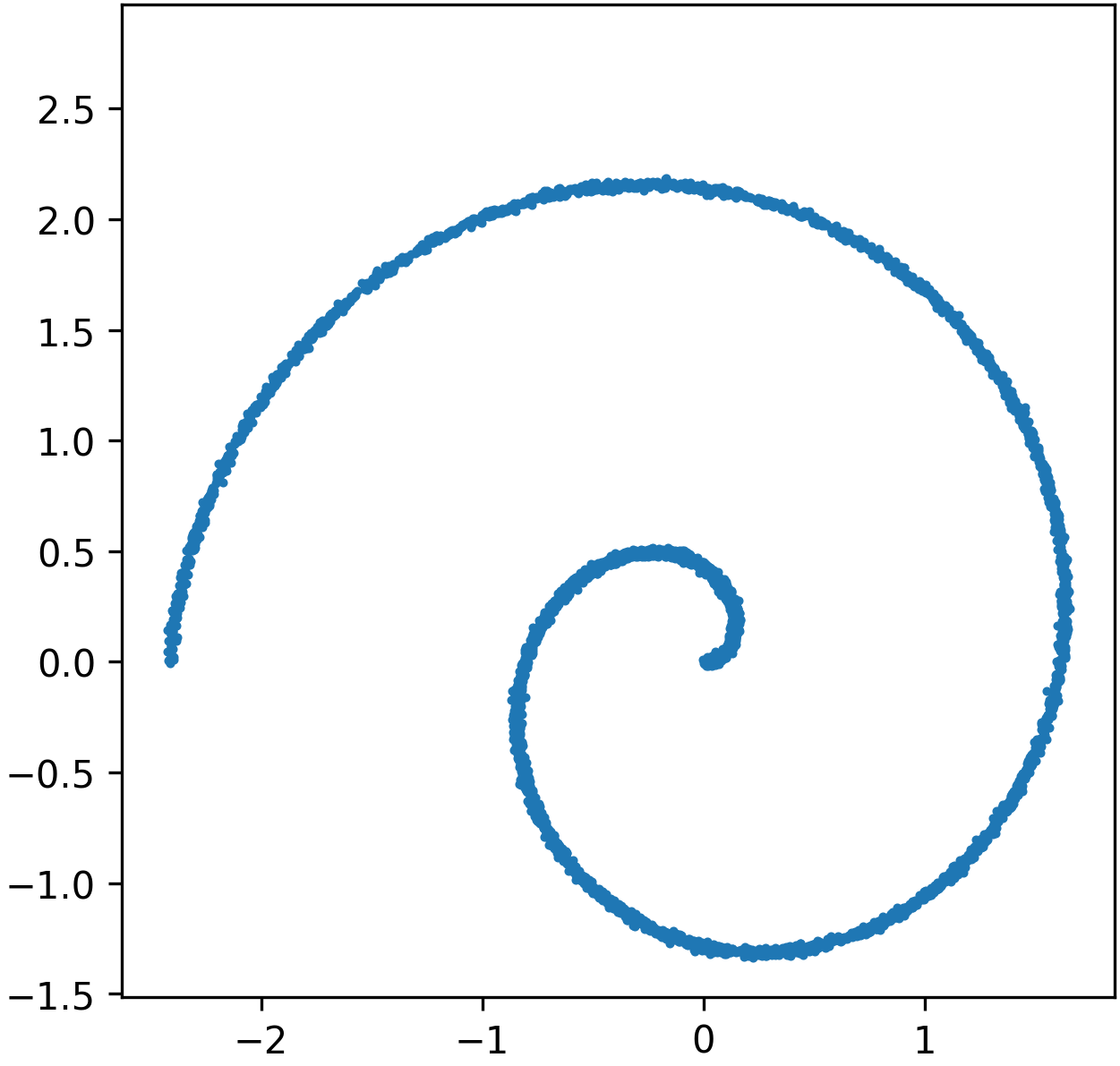
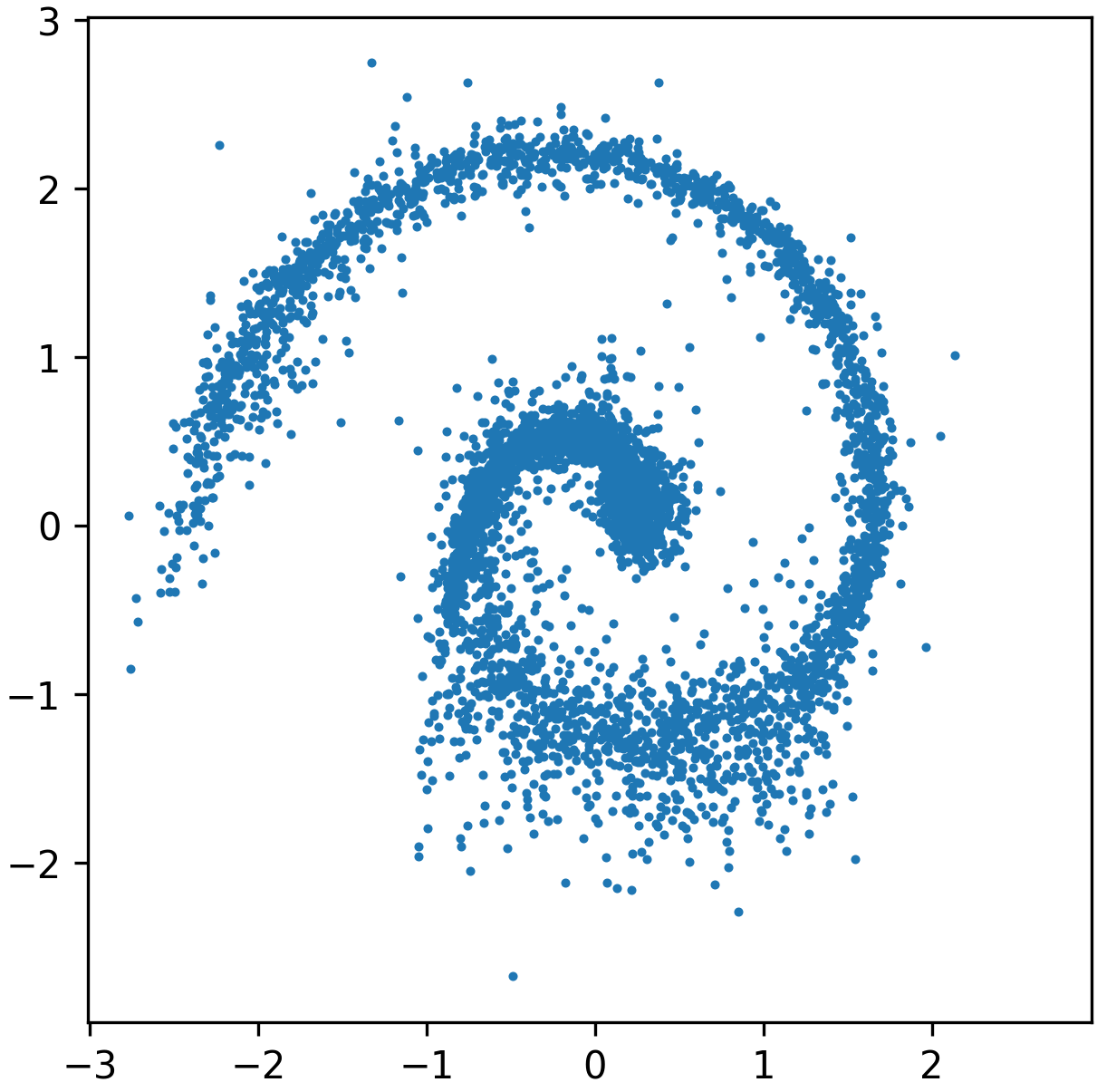
Figure 4: Flow matching without preconditioning, showing ground-truth Swiss roll samples and poor transport by the plain model.
By contrast, preconditioned approaches result in more isotropic intermediate representations and significantly improved generative alignment:
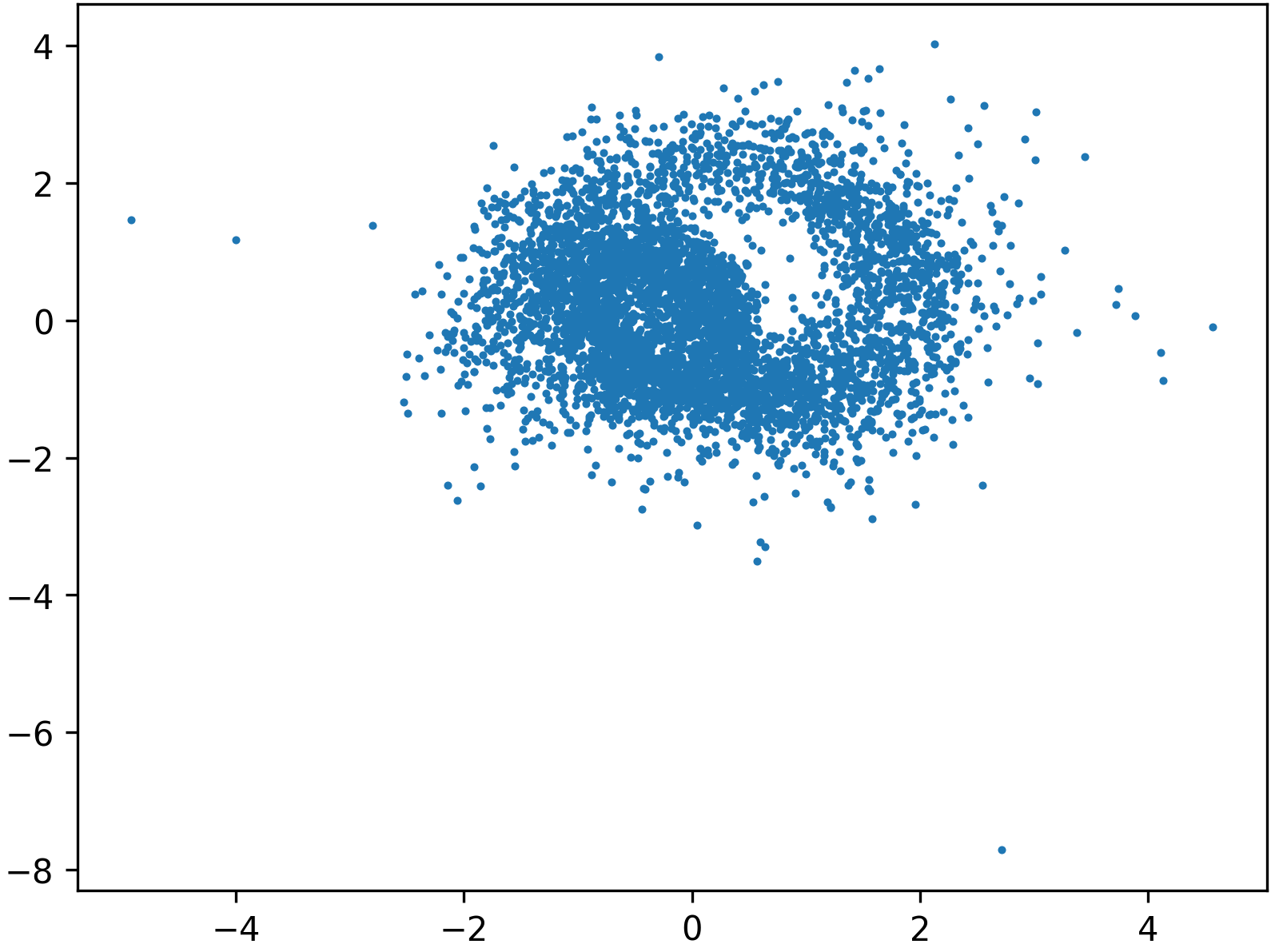
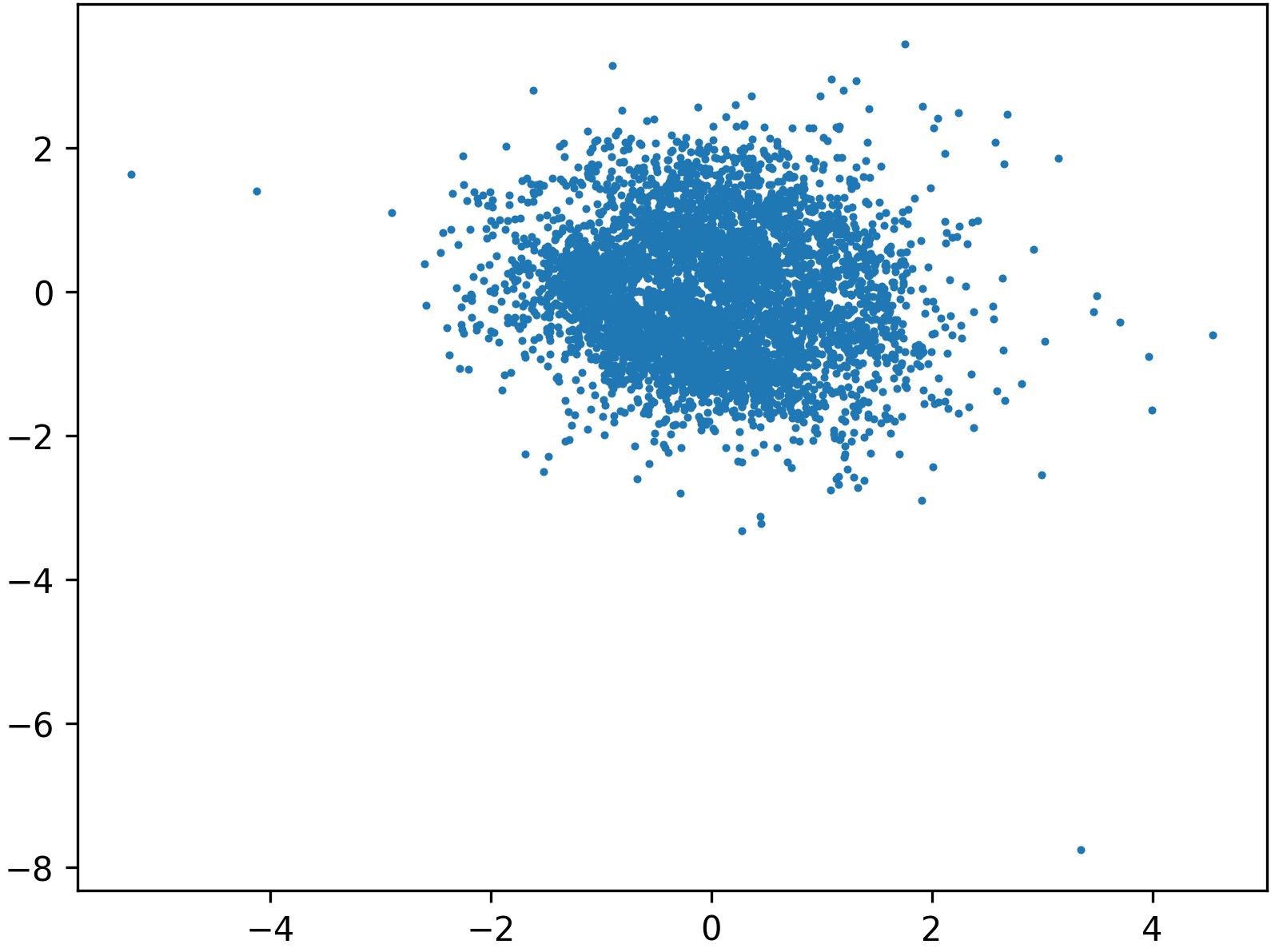
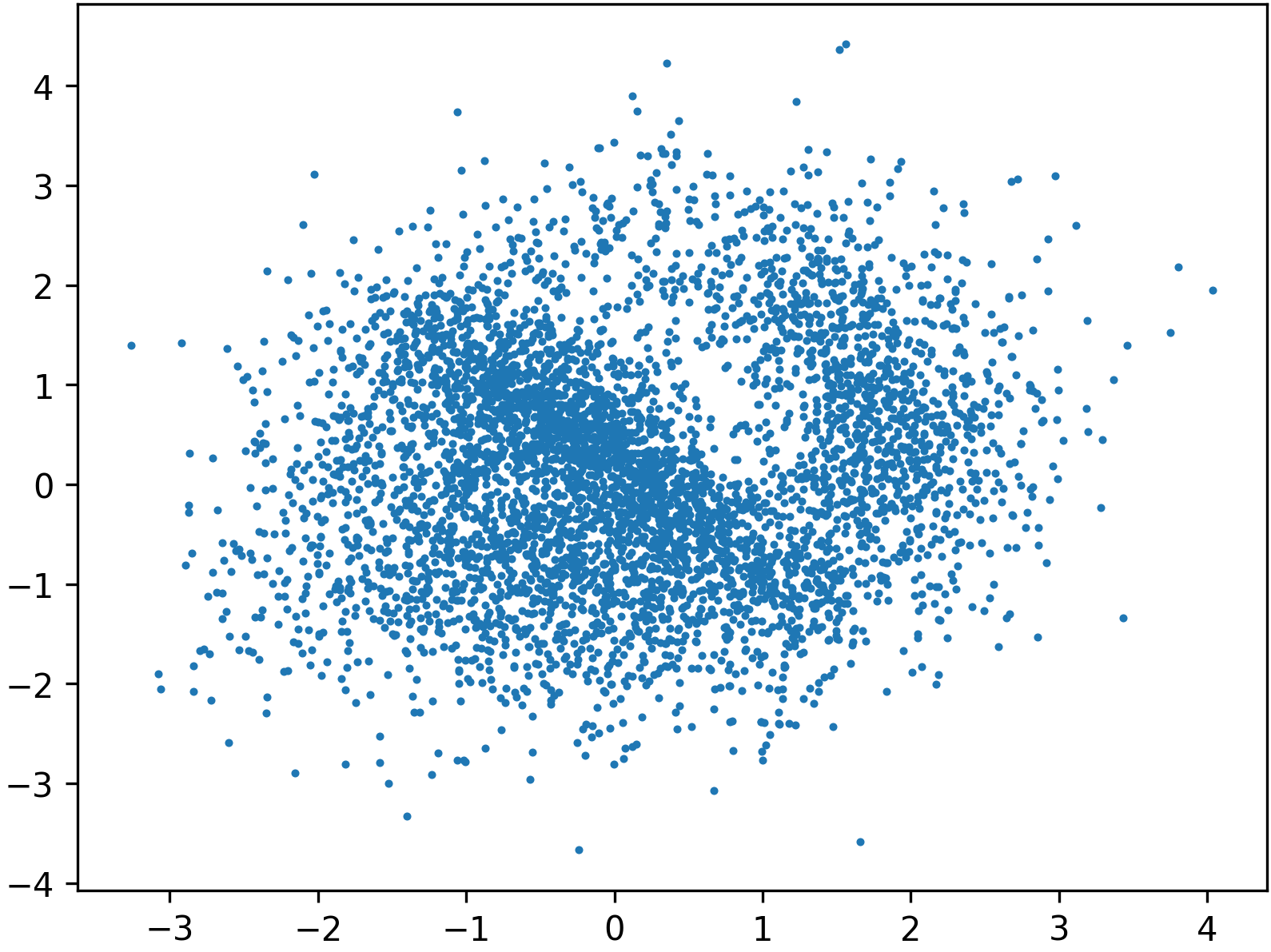
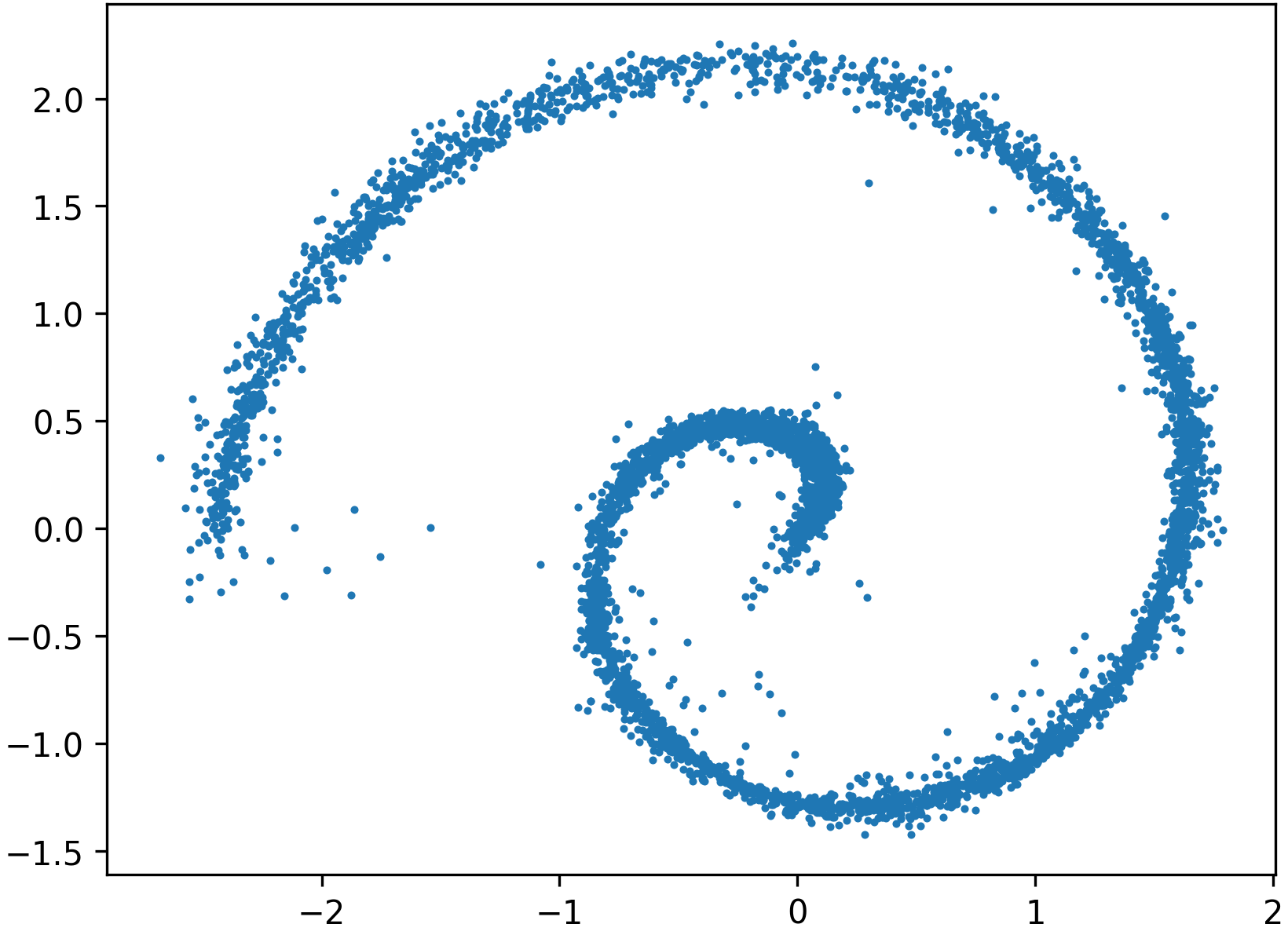
Figure 5: Preconditioning via normalizing flow straightens the Swiss roll, permitting easier learning of Gaussian transport.
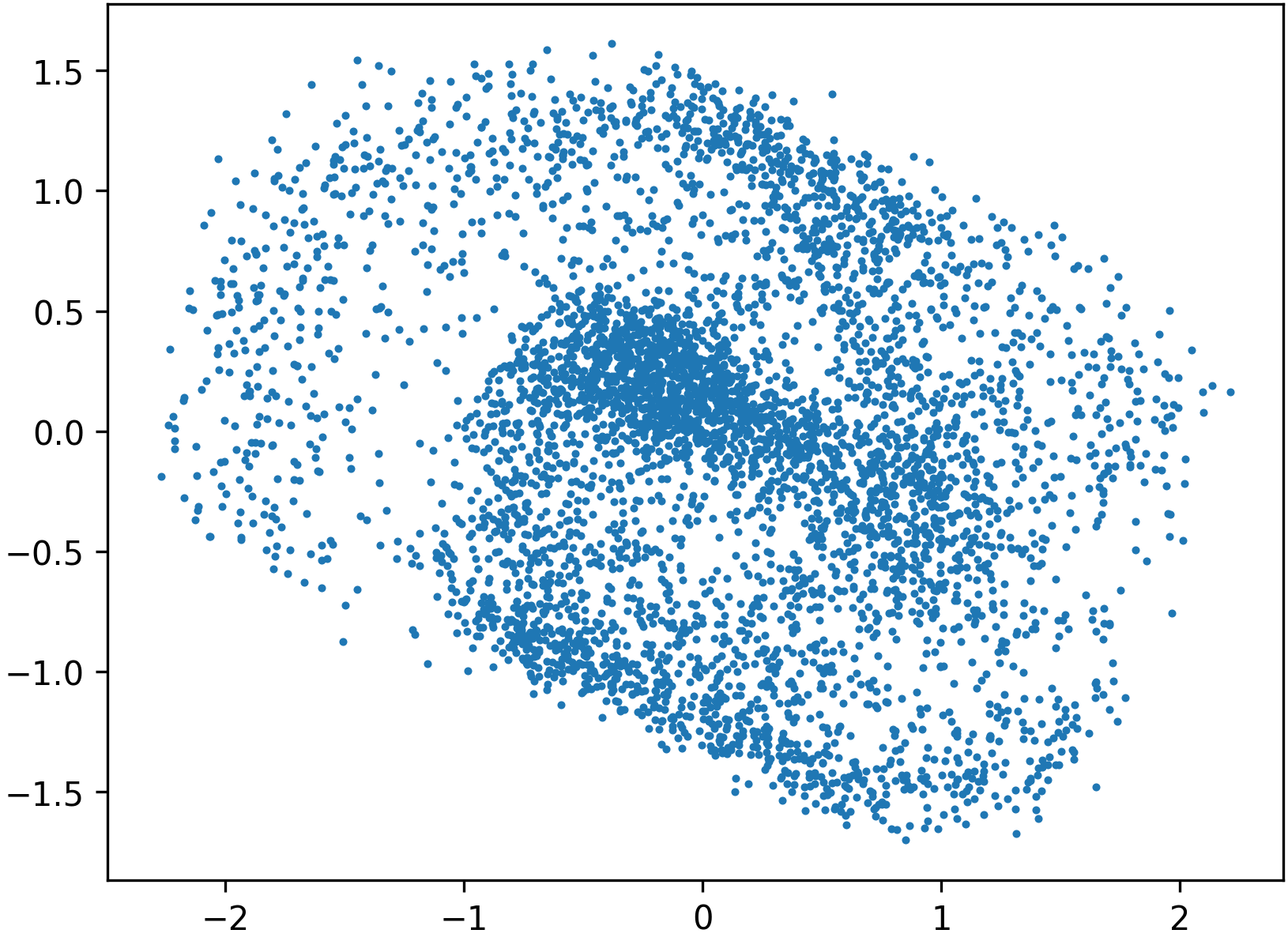
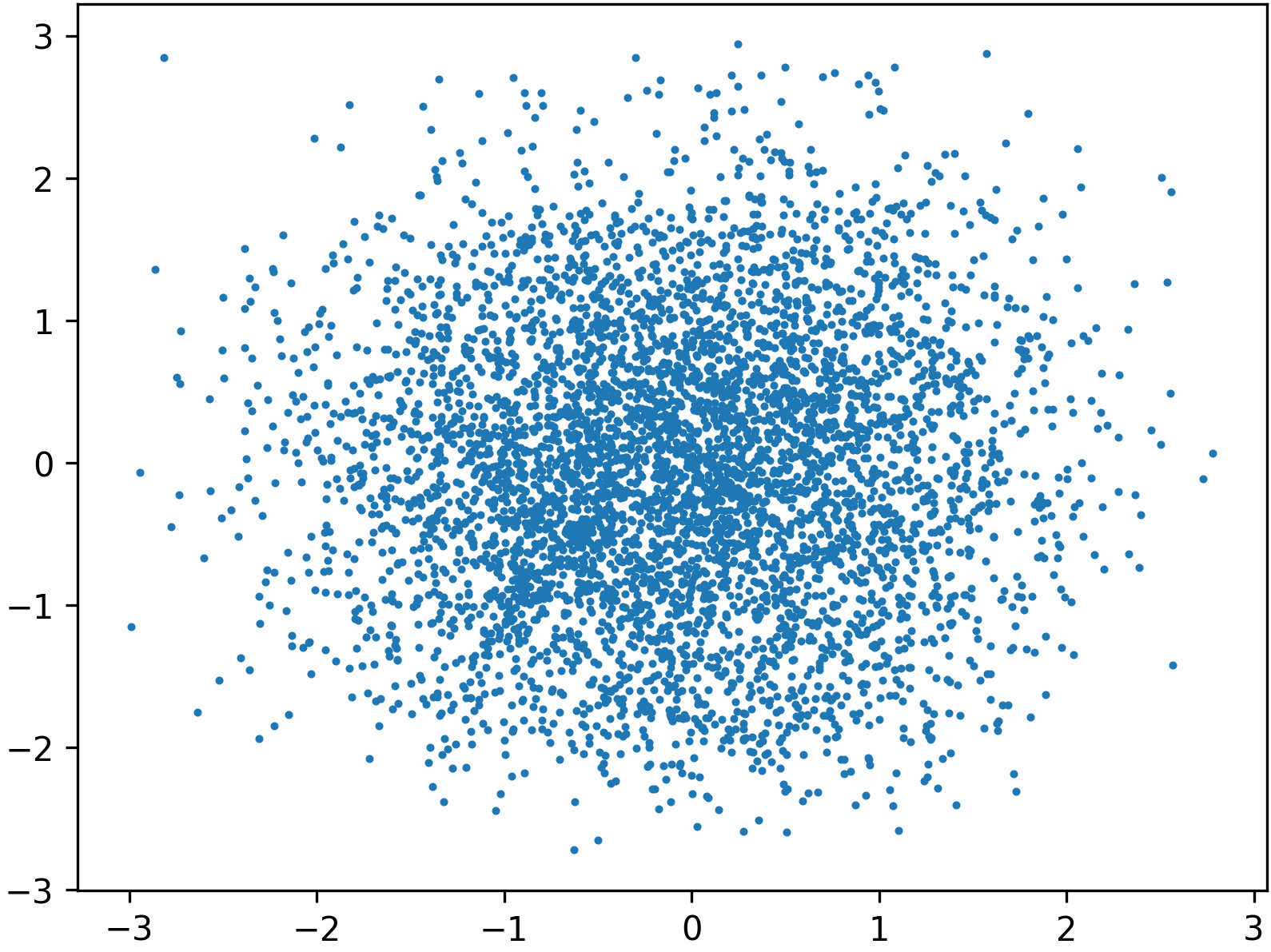
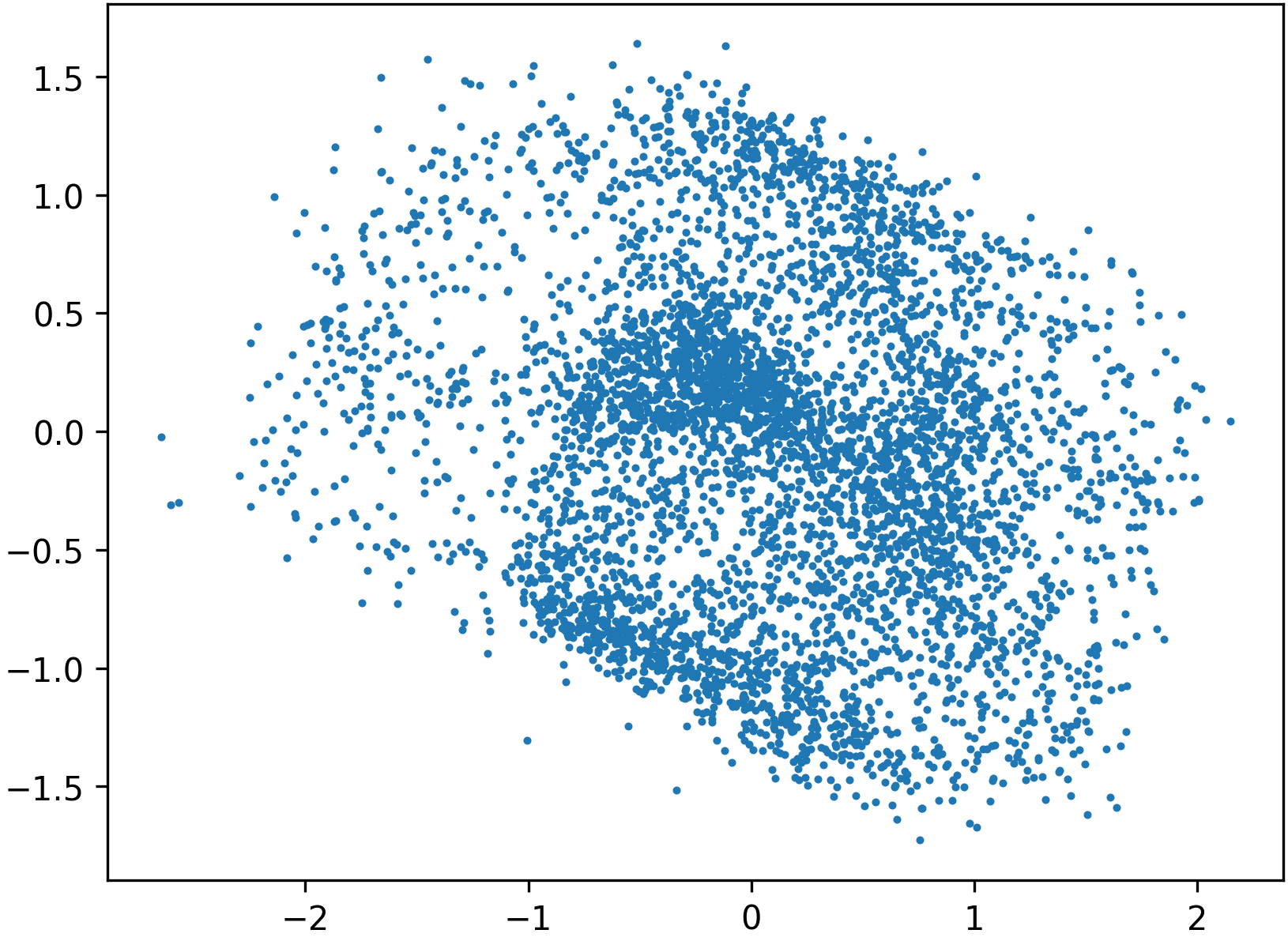
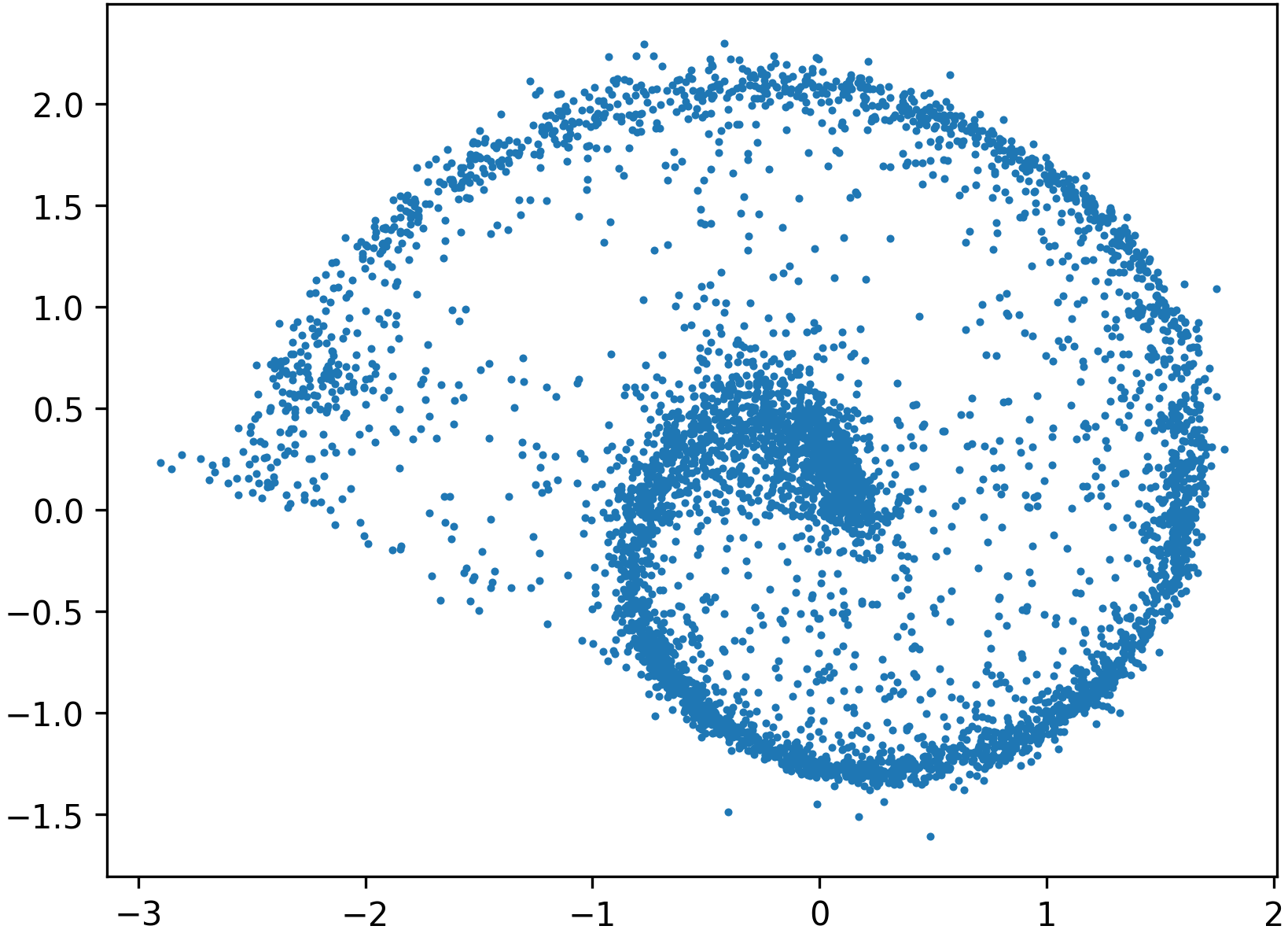
Figure 6: Even a low-accuracy, low-capacity flow used as a preconditioner can substantially improve the downstream learned transport.
Checkerboard to Swiss Roll: Preconditioning achieves not only improved target coverage but also prevents premature stagnation, as reflected in the monotonic decrease of distributional metrics (e.g., MMD).
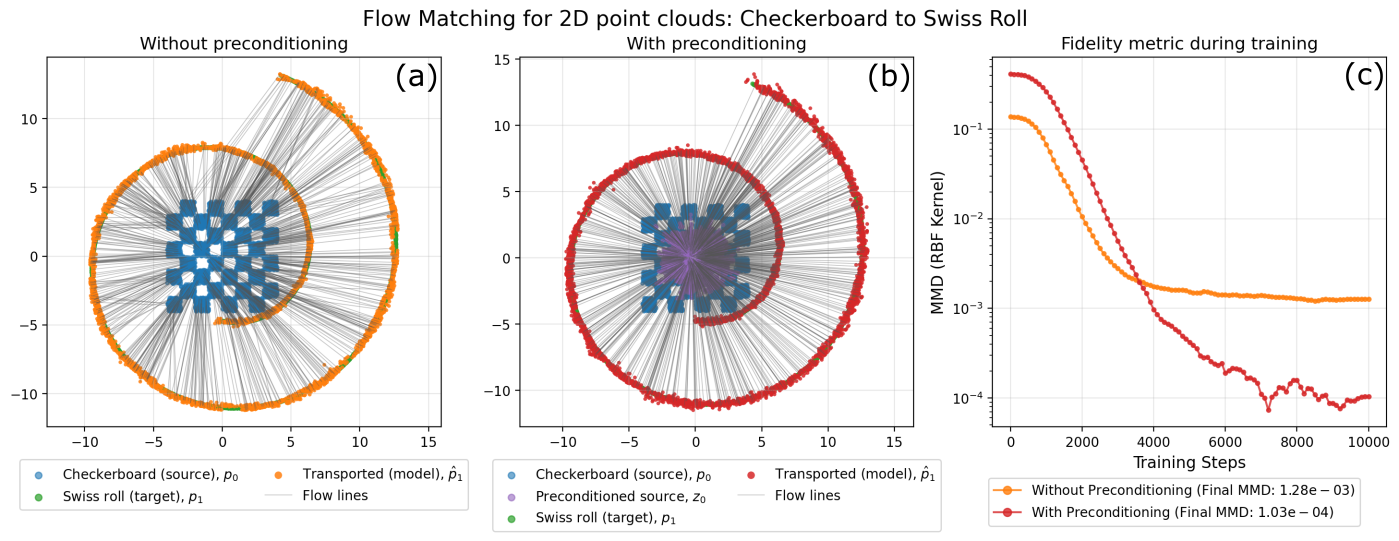
Figure 7: With preconditioning, transport flows are smoother, target alignment is enhanced, and final distributional errors are significantly lower.
MNIST and High-Resolution Images: When flow matching is performed in the latent space of a VAE with isotropic preconditioning, there is a substantial qualitative and quantitative improvement in sample fidelity (as measured by FID), with normalizing flow preconditioning yielding the lowest FID.

Figure 8: MNIST generations under different preconditioning regimes, highlighting improvements in sample clarity, diversity, and overall FID.
For complex datasets, preconditioned flows yield sharper, more coherent structure and better spatial consistency across generations.

Figure 9: LSUN Churches—preconditioning delivers improved global structure and spatial organization.

Figure 10: Oxford Flowers—preconditioning enhances visual coherence and sample consistency.

Figure 11: AFHQ Cats—preconditioned sampling produces more realistic sample morphologies and textures.
Condition number diagnostics confirm that preconditioned intermediates dramatically suppress ill-conditioning throughout the transport process.
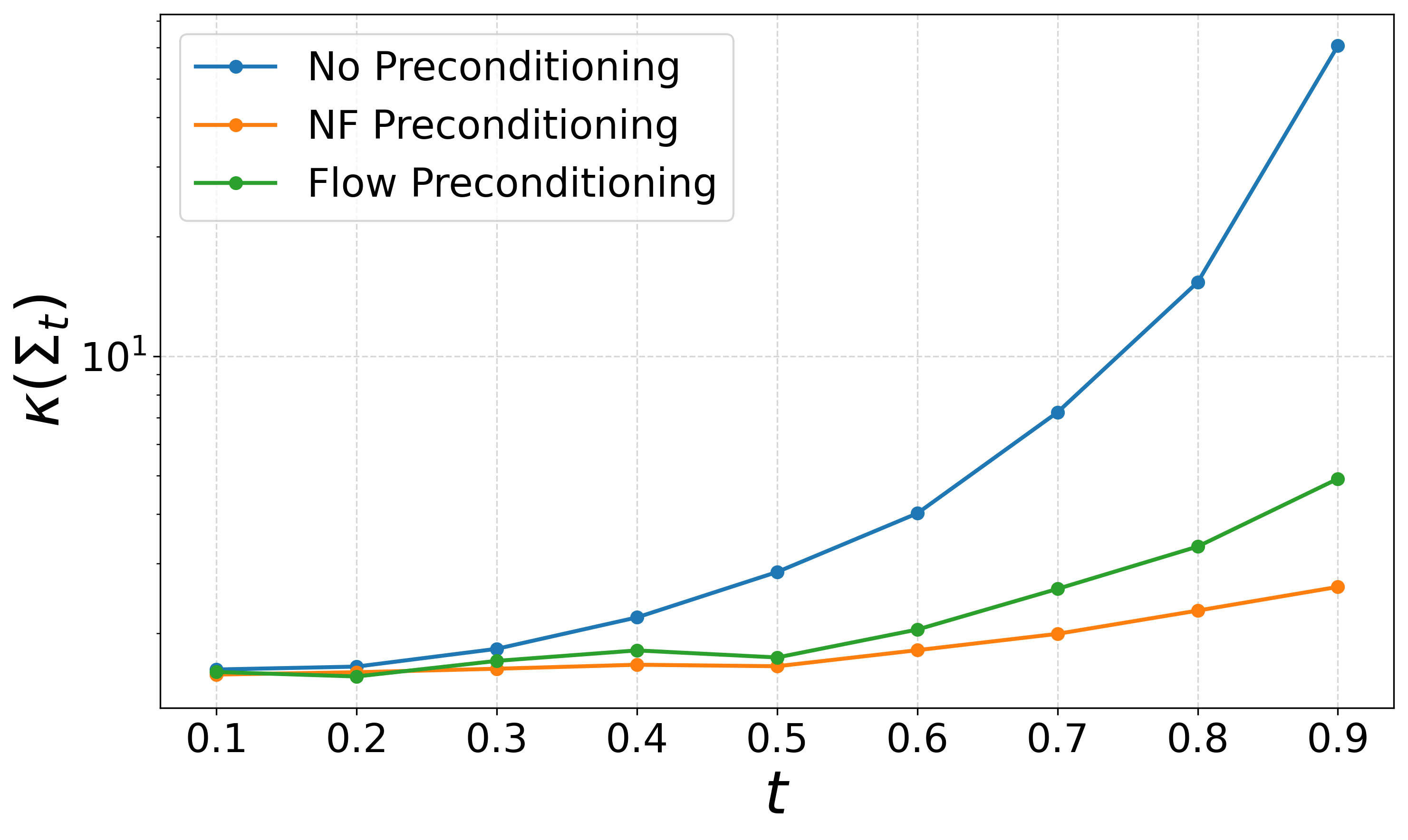
Figure 12: Preconditioning reduces the condition number of Σt at all t, leading to improved numerical stability and convergence on MNIST.
Implications and Future Directions
The results provide an explicit demonstration that optimization geometry, not only model capacity, governs the practical learnability and sample quality of continuous-time generative models. Preconditioning operates as an architectural and algorithmic layer that can be flexibly composed with arbitrary downstream generative models. This framework is theoretically sound, compatible with high-capacity neural architectures, and yields measurable empirical gains.
Bold claim: The research shows that, contrary to some current practice, loss plateaus and slow convergence in flow/diffusion-based generation are not indicative of model or data limitations, but rather, a manifestation of geometric conditioning bottlenecks—which can be counteracted entirely by geometric preconditioning transforms.
Further directions include the development of adaptive, time-dependent preconditioners, analysis of SGD in nonlinear network regimes via local linearizations, and extending these preconditioning techniques to other generative frameworks beyond ODE-based flows.
Conclusion
This study introduces a general, theoretically motivated framework for preconditioning flow and score matching objectives in continuous-time generative models. By directly addressing the conditioning of intermediate distributions, preconditioning transforms—realized via invertible normalizing flows or lightweight flows—enable efficient, robust optimization and higher-quality sample generation on both synthetic and high-resolution real datasets. The findings indicate that careful attention to problem geometry is fundamental for advancing the training and application of modern generative models, with immediate impact on both methodological understanding and practical implementation across generative modeling in machine learning.
(2603.02337)