- The paper introduces SilentWear, a textile-based neckband with 14 dry polymer-elastomer EMG sensors that eliminate the need for conductive gels.
- It leverages a lightweight CNN (SpeechNet) with 15K parameters and rapid incremental fine-tuning to achieve up to 84.8% accuracy across varying sessions.
- The system demonstrates low-latency, energy-efficient on-device inference (2.47 ms per 800 ms window) on GAP9, enabling real-time silent speech interaction.
SilentWear: Ultra-Low Power Textile-Based EMG Silent Speech Recognition
System Design and Wearability
SilentWear introduces a fully wearable, textile-based neckband for surface EMG acquisition, engineered for unobtrusiveness and comfort. The neckband integrates 14 differential EMG channels using dry polymer-elastomer electrodes with Ag/AgCl coating, eliminating the need for conductive gels and facilitating immediate daily use. The electrodes are strategically arranged to maximize infrahyoid muscle coverage, including the sternocleidomastoid region, critical for phonation and articulation. The acquisition hardware, based on the BioGAP-Ultra platform, provides simultaneous 16-channel biopotential acquisition, embedded deep neural network inference, and BLE wireless transmission within a compact 26×65×13 mm configuration powered by a 150 mAh Li-Po battery.
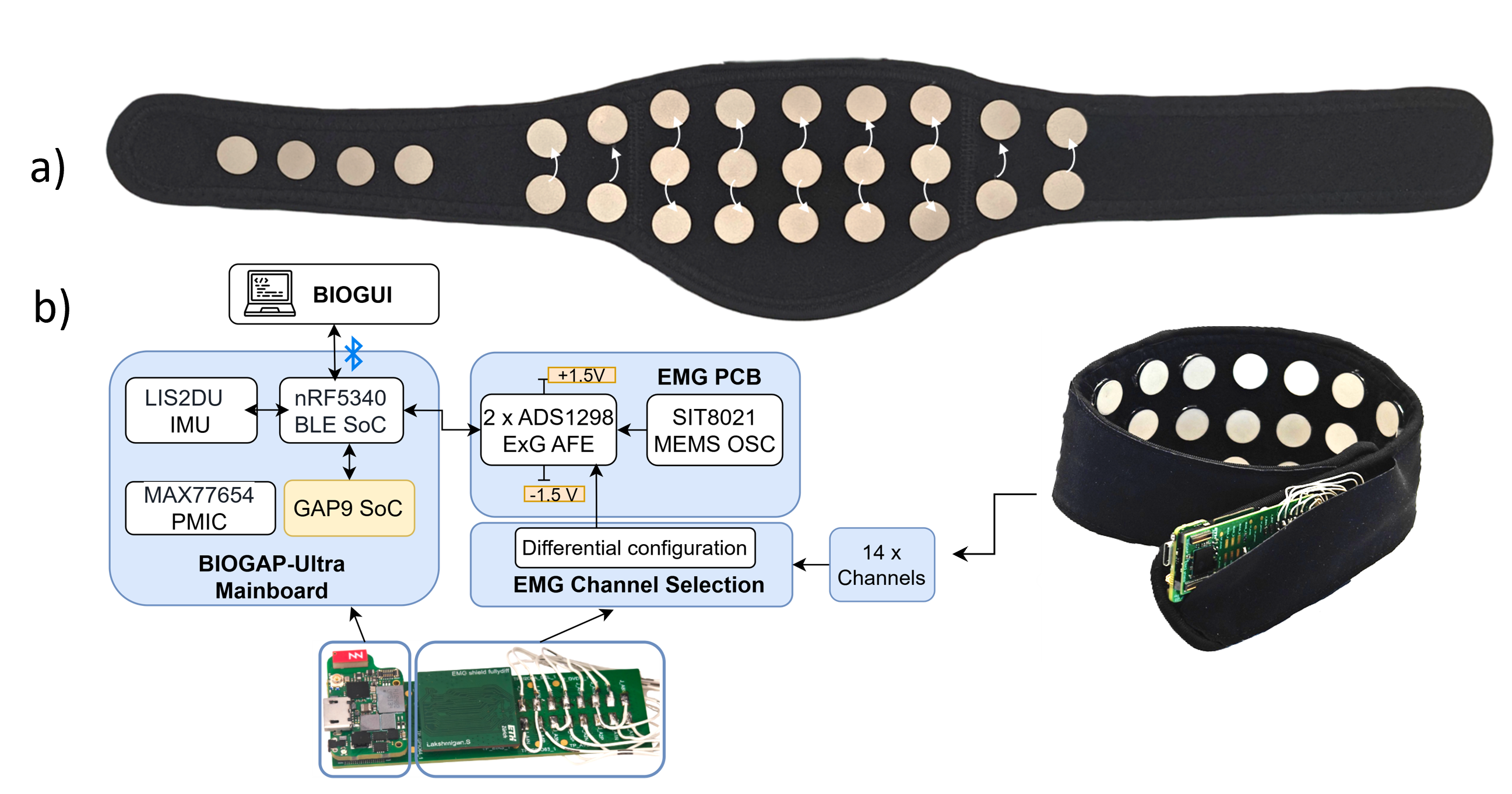
Figure 1: SilentWear neckband and hardware overview with 14 EMG acquisition channels, leveraging a textile-based form factor for daily use.
Data Collection Protocol and Dataset
The data collection protocol focuses on realistic usage, employing three sessions per subject conducted across multiple days with sensor repositioning between sessions to emulate practical variability. Each session comprises alternating vocalized and silent batches, with subjects executing 8 HMI-oriented commands in random order, repeated 20 times each. The dataset includes four subjects, yielding 2400 vocalized and 2400 silent samples per subject, augmented by rest periods.
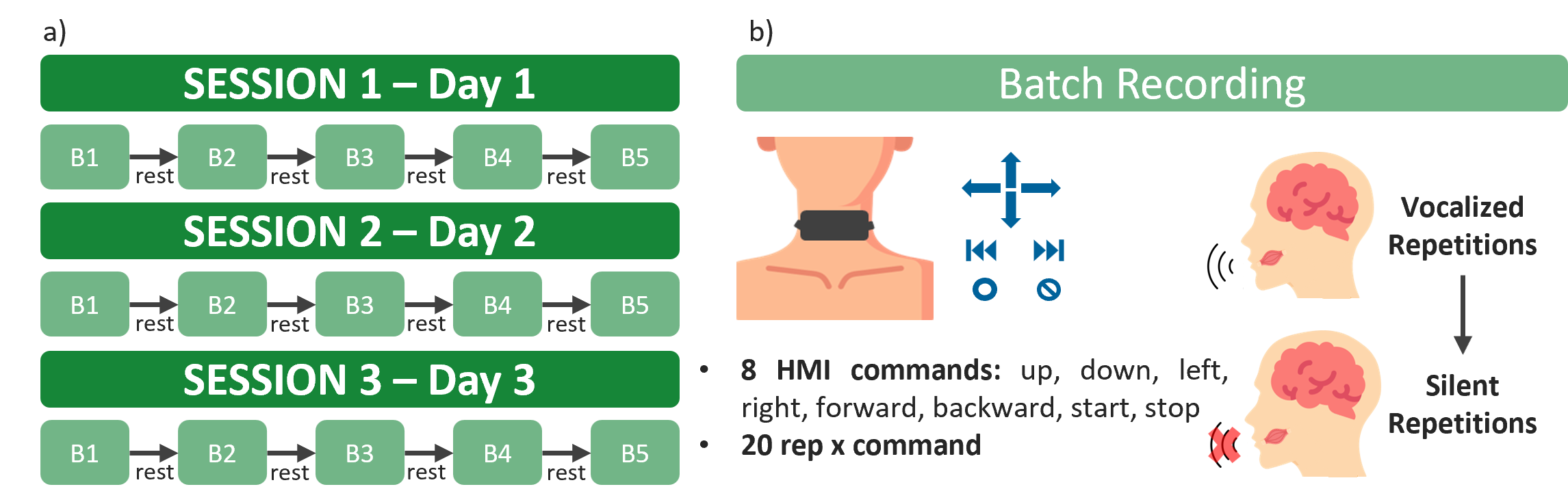
Figure 2: Protocol: multi-day sessions, alternating vocalized/silent batches, eight machine commands, random ordering, and session-level repositioning.
Signal Quality and Channel Analysis
EMG signals acquired during command articulation reveal clear distinctions between speech and rest phases in both vocalized and silent modes. Central channels consistently exhibit higher SNR, attributed to the infrahyoid muscle placement, which is physiologically relevant for capturing speech-related activity. Lateral channels provide additional coverage, particularly for sternocleidomastoid engagement.
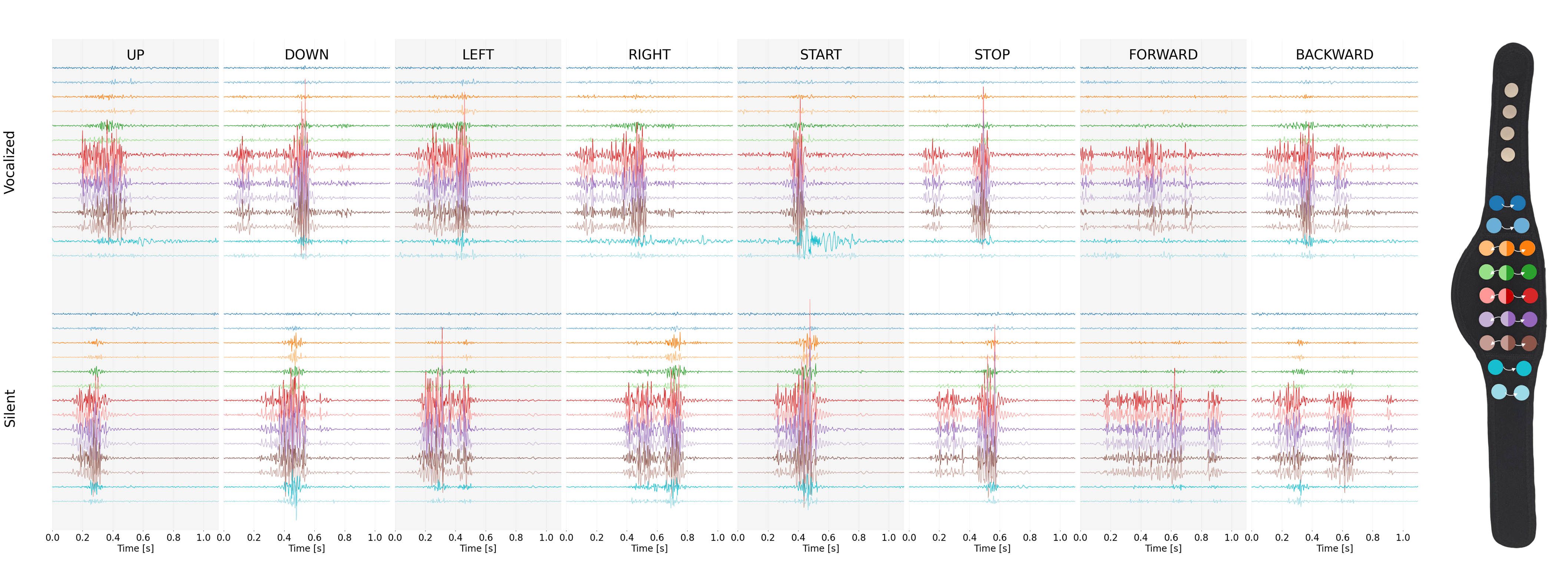
Figure 3: Visualization of EMG channel signals across 8 commands—marked SNR and activation differences between vocalized (top) and silent (bottom) modalities.
Architecture and Inference: SpeechNet
SpeechNet is a lightweight CNN (15,489 parameters), inspired by EpiDeNet, employing initial temporal convolutions per channel followed by cross-channel spatial integration. The model processes 14-channel input windows (1400ms), extracting both temporal and spatial neuromuscular patterns. Training utilizes cross-entropy loss with Adam optimizer, leveraging early stopping and learning rate scheduling. Comparative benchmarking against Random Forest classifiers demonstrates substantial performance improvements in both vocalized and silent speech.
Evaluation: Accuracy and Robustness
Three evaluation settings are adopted:
- Global (Leave-One-Batch-Out): All sessions pooled; tests unseen batches within sessions
- Inter-Session (Leave-One-Session-Out): Tests robustness to sensor repositioning and day-to-day variance
- Incremental Fine-Tuning: Assesses accuracy recovery via brief recalibration (less than 10 minutes of user data)
SpeechNet achieves 84.8±4.6% (vocalized) and 77.5±6.6% (silent) average accuracy (global), and 71.1±8.3%/59.3±2.2% (inter-session), outperforming Random Forest baselines by 11–15%. Performance degradation from sensor repositioning is mitigated by incremental fine-tuning, restoring more than 10% accuracy with minimal additional data collection.

Figure 4: Subject-specific confusion matrices for global and inter-session settings—highlighting robust speech/rest discrimination and session-induced variability.
The ITR analysis ablates EMG window sizes (400–1400 ms), balancing accuracy and throughput. Peak accuracy occurs at 1400ms, while maximal ITR (92.7 bit/min vocalized, 69.2 bit/min silent) is observed at 800ms, providing a trade-off between latency and reliability. Fine-tuning with as little as one batch yields significant accuracy gains (up to 12%), validating the practicality of rapid recalibration.
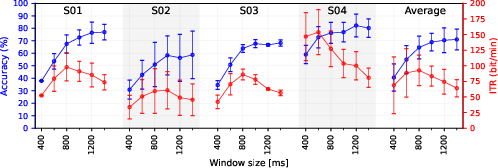
Figure 5: ITR (bit/min) and accuracy as functions of window size for vocalized speech—demonstrating throughput/accuracy trade-offs.
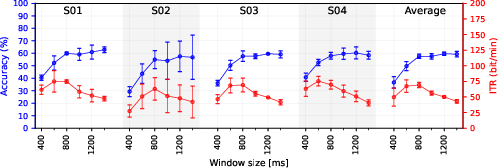
Figure 6: ITR and accuracy for silent speech—shorter window yields near-peak ITR with moderate accuracy loss.
Incremental Training and Calibration
Incremental fine-tuning from pre-trained models achieves superior mean accuracy compared to both zero-shot evaluation and training from scratch. After four to five fine-tuning rounds (10 minutes), vocalized accuracy improves to 84%, silent to 79%, with one round sufficing for substantial gains (e.g., 70% to 80% vocalized).

Figure 7: Incremental training—fine-tuning delivers consistent accuracy improvement relative to scratch/zero-shot models.

Figure 8: Silent speech incremental training mirrors vocalized trends, underscoring fine-tuning efficacy.
On-Device Deployment and Power Analysis
SpeechNet is deployed on GAP9 (RISC-V multi-core + NE16 accelerator), with 8-bit quantization reducing model footprint to 15.13 kB. The 800ms input window yields 2.47ms inference time and 63.9 μJ per inference (energy-optimal). Aggregate system power is 20.5mW (acquisition, inference, transmission), allowing 27.1 hours continuous operation per charge. Sliding window inference every 100 ms ensures real-time responsiveness for HMI use-cases.
Comparative Analysis and Context
SilentWear advances the state-of-the-art in EMG-based SSI by combining textile-based dry electrode neckband, extensive multi-day dataset collection with session variability, and embedded on-device deep learning. Comparisons with prior work highlight advantages in wearability, session robustness, dataset scale, and privacy-preserving local inference. Existing solutions (e.g., face-based, tattoo, and headphone-based form factors) often lack embedded AI, operate under restrictive conditions, or do not address session-induced domain shifts. SilentWear uniquely targets practical, everyday use with rigorous session-level generalization and rapid real-world recalibration.
Practical Implications and Future Directions
The implementation achieves low-latency, privacy-preserving, real-time silent speech recognition viable for wearable HMI in noisy or sensitive environments. Practical implications include restoration of communication for speech-impaired users and seamless machine interaction in public or industrial settings. The open release of hardware, software, and dataset supports further development and benchmarking. Four key open directions:
- Dataset expansion to larger and more diverse subject pools, extended vocabulary, and continuous speech
- Integration of multimodal sensor fusion (e.g., IMU, EEG) to enhance robustness and reliability
- Exploration of advanced models (transformers, foundation models) as dataset scale enables
- Real-time, closed-loop evaluations for adaptive recalibration in daily-life scenarios
Conclusion
SilentWear presents a fully functional, wearable SSI platform for EMG-based silent and vocalized speech recognition, integrating a textile neckband and embedded low-power deep learning processing. SpeechNet improves accuracy over prior baselines and provides rapid adaptation to session variability. Real-time inference on GAP9 demonstrates feasibility for continuous use with minimal power requirements, supporting privacy and responsiveness. The open-source ecosystem established by this work positions it as a foundation for further research in wearable biosignal-based HMI, silent speech interfaces, and adaptive edge-AI systems.