- The paper introduces a scalable framework using robot-free human demonstrations to learn whole-body mobile manipulation.
- It leverages multimodal egocentric sensing, embodiment-agnostic visual embeddings, and a relaxed head gaze representation to overcome kinematic incompatibility.
- Empirical results show high success rates in tasks like Laundry, Delivery, and Tablescape, outperforming traditional baselines.
HoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations
HoMMI addresses the challenge of scaling whole-body mobile manipulation learning by enabling data collection and policy learning directly from robot-free human demonstrations. The complexity arises from the need for bimanual and whole-body coordination, active perception, and long-horizon navigation. Prior approaches relying on teleoperation or stationary setups, such as UMI, VR, or external cameras, lack scalability and fail to capture global context, navigation, and full-body coordination sufficiently. Naively fusing egocentric sensing with portable demonstration devices exacerbates the human-to-robot embodiment gap—differences in visual appearance and kinematics—limiting policy transfer fidelity.
System Architecture and Data Collection
HoMMI extends the UMI framework by integrating a head-mounted camera for egocentric sensing, establishing a portable and scalable demonstration interface via multi-device synchronization (ARKit), capturing RGB, depth, and pose (6-DoF) trajectories across all modalities at 60Hz. This enables dense, multimodal, and in-the-wild data collection for bimanual mobile manipulation without teleoperation overhead.
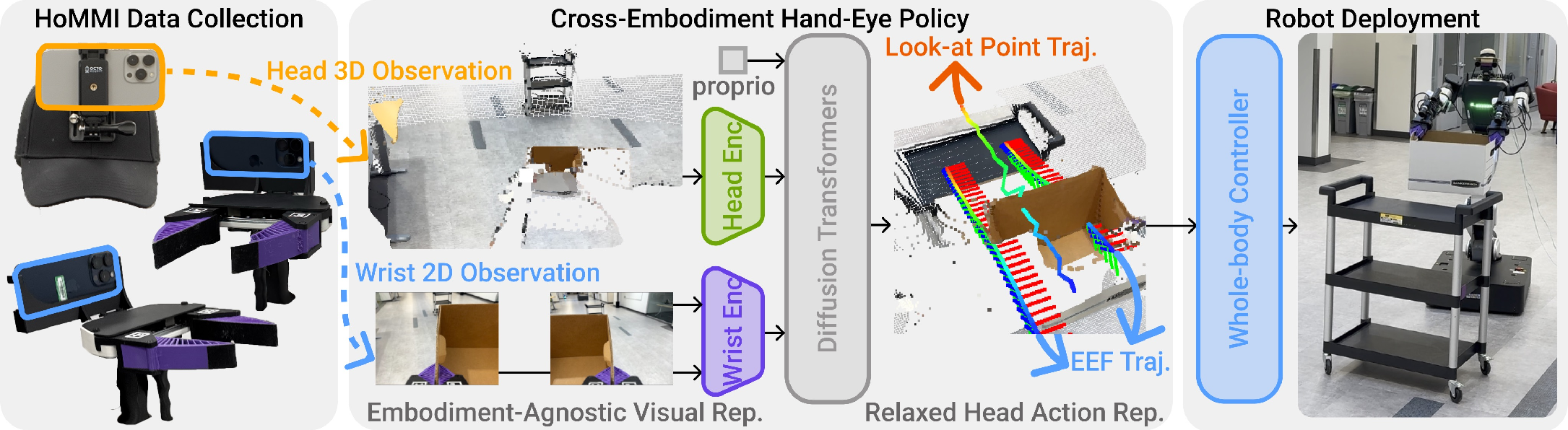
Figure 1: HoMMI architecture supporting robot-free, egocentric demonstration collection, cross-embodiment policy learning, and constraint-aware whole-body control.
Embodiment-Agnostic Policy Design
Visual Embedding
To bridge the visual gap, the system employs a 3D visual representation for egocentric observations. Egocentric RGB is lifted to process geometry-aware tokens (via depth and patch features) and masked to remove embodiment-specific cues (arms/body), transforming all sensory input into a gripper-centric coordinate frame. Attention pooling aggregates task-relevant visual information.
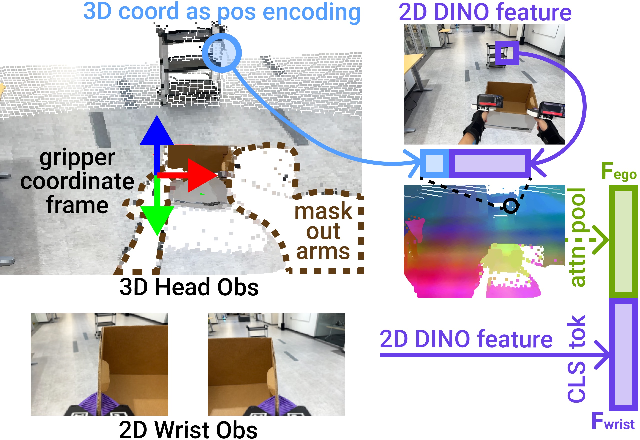
Figure 2: 3D representation for egocentric visual input, masking arms/body and converting to gripper-centric frame.
Action Representation
To resolve kinematic incompatibility, HoMMI implements a relaxed head action via a "3D look-at point" abstraction. Human head pose trajectories are replaced by view-agnostic gaze targets that the robot translates to feasible neck motions, respecting hardware constraints and preserving active perception strategies. This circumvents infeasible joint tracking and improves transferability between different embodiments.
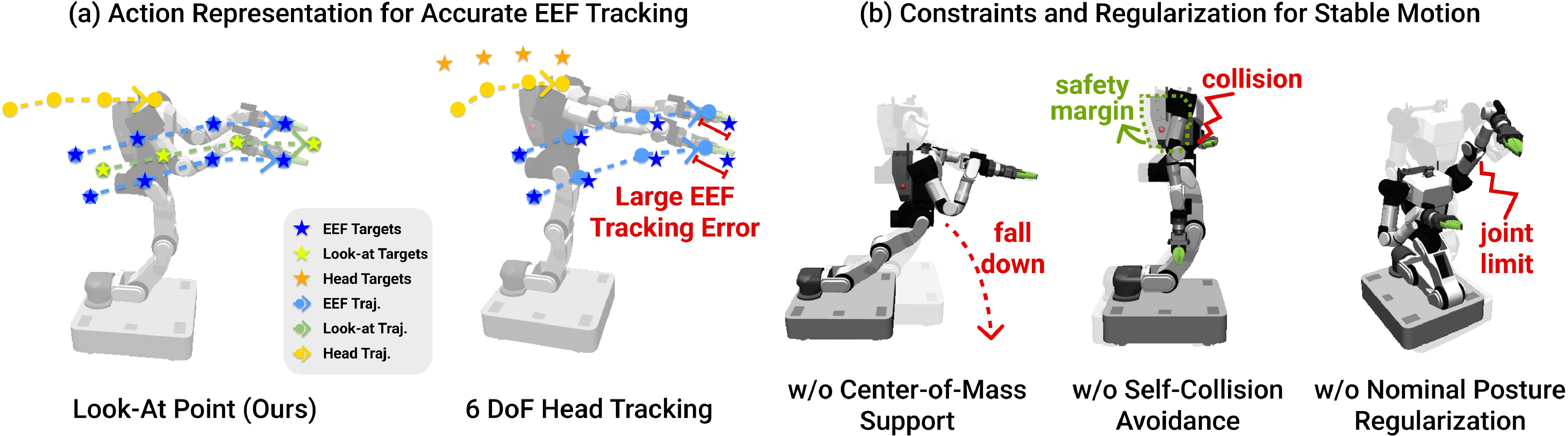
Figure 3: Relaxed head gaze representation enables precise hand-eye tracking and effective perception, avoiding kinematic constraints violations.
Whole-Body Control and Policy Learning
The robot hardware consists of a high-DoF bimanual manipulator with holonomic base, torso, 2-DoF neck, and wrist-mounted cameras. A differential whole-body IK solver (Mink) transforms policy-generated end-effector poses and head look-at points to joint and base velocities, optimizing tracking, stability, smoothness, and posture via weighted cost functions and explicit constraints. Policy inference is decoupled from control, using timestamped, latency-matched observations and actions to preserve real-time consistency.
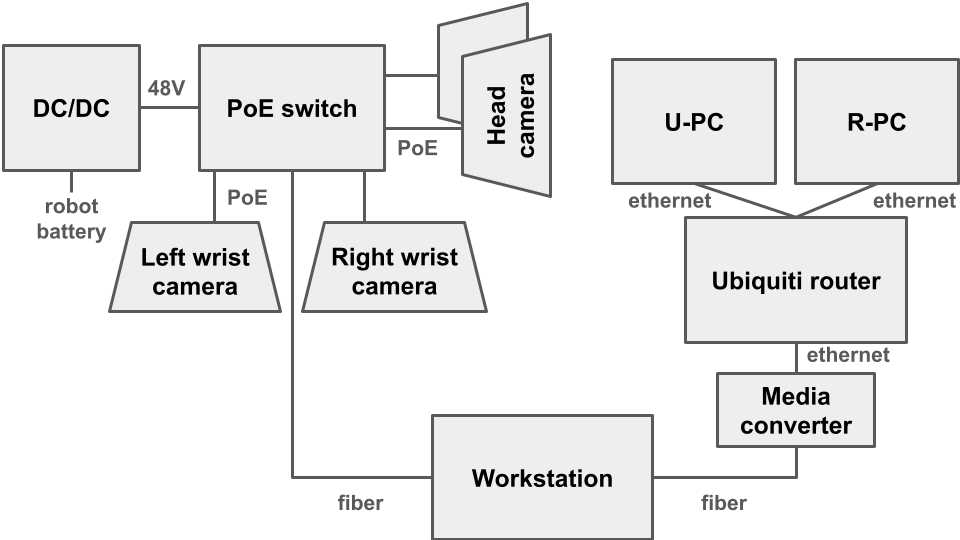
Figure 4: Hardware schematic for high-bandwidth perception and closed-loop control on mobile manipulator.
Empirical Evaluation
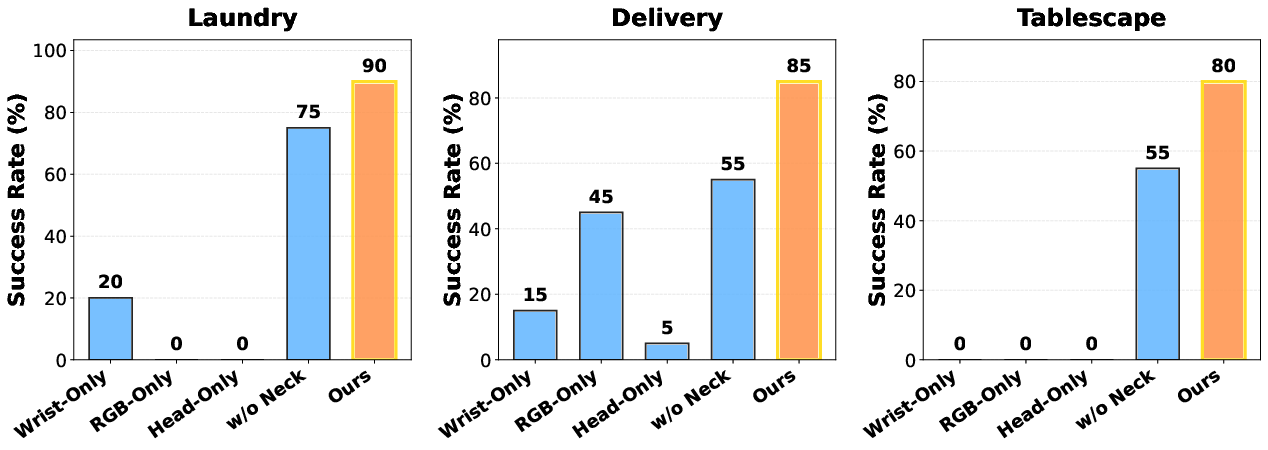
HoMMI is benchmarked across three long-horizon mobile manipulation tasks: Laundry (cloth placement in bin), Delivery (box delivery to trolley), and Tablescape (mat unfolding on table). Each task involves variations in object placement and initial configuration, probing robustness and generalization.

Figure 5: Representative rollout for Laundry task, demonstrating whole-body and active perception integration.

Figure 6: Policy rollout for Delivery task, highlighting navigation and active perception in variable workspace.

Figure 7: Tablescape task rollout, illustrating fine-grained bimanual and spatial coordination.
Baselines and Ablations
Comparisons include Wrist-Only (classic UMI), RGB-Only (adding head RGB but regressing head pose), Head-Only (no wrist input), and w/o Active Neck (disabling head motion). Each ablation isolates modality and embodiment effects.
Quantitative Results
HoMMI achieves high success rates: 90% (Laundry), 85% (Delivery), 80% (Tablescape), consistently outperforming baselines that suffer from grasp failures, navigation drift, object misalignment, or inability to recover from out-of-view targets. Key findings:
Policy Attention and Observability
Policy attention maps reveal that HoMMI's cross-embodiment hand-eye policy focuses cleanly on task-relevant objects and contacts, validating the synergy of egocentric and wrist modalities, and gripper-centric framing for spatial awareness. Baseline attentions are diffuse and less informative.

Figure 9: Attention maps for egocentric observations, highlighting sharp task-focused attention in HoMMI.
Implications, Limitations, and Future Directions
HoMMI demonstrates that robot-free human demonstrations, when augmented with egocentric sensing and embodiment-agnostic policy design, suffice for learning versatile, long-horizon whole-body mobile manipulation. The system scales data collection, enhances transferability, and establishes precise, coordinated behaviors in unconstrained environments, pushing toward democratized mobile manipulation learning.
The short observation history limits policy memory and long-term recovery; integrating extended sequence modeling or memory architecture is an evident future direction. The reliance on vision-only input also restricts safety and compliance for contact-rich manipulation; tactile and force sensing could augment robustness. Residual hardware embodiment gaps persist—generative hardware co-design and domain adaptation may further reduce them.
Conclusion
HoMMI introduces a scalable framework for learning mobile manipulation directly from robot-free demonstrations, leveraging embodiment-agnostic visual and action abstractions and constraint-aware whole-body control. Empirically, it achieves robust, transferable performance across diverse manipulation scenarios, surpassing prior art and baselines in both accuracy and task success. This architecture enables practical, rapid deployment for real-world mobile manipulation and sets new standards for cross-embodiment policy learning.