Beyond Language Modeling: An Exploration of Multimodal Pretraining
Abstract: The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper explores how to build one big AI model that can understand and create both words and visuals (like images and videos) at the same time. Instead of starting from a language-only model and adding vision later, the researchers train everything together from scratch. They want to see what actually works best when teaching a model about the real world, not just text.
What questions the researchers asked
They focused on five big questions, phrased simply:
- What is the best way to represent pictures and video inside the model so it’s good at both understanding them and creating them?
- Does mixing different kinds of data (text, videos, image–text pairs, and action–video sequences) help or hurt the model?
- Can training on these mixed data sources naturally teach the model “world modeling” (predicting how the world changes), without special tricks?
- Which model designs work best when handling multiple modalities (words and visuals) at once?
- How should we scale (grow) these models—do language and vision need the same amount of data and parameters, or are they different?
How they did it (methods in everyday language)
Think of the model as a single brain that can process sequences of tokens. Text is already a sequence of tokens (words and subwords). Images and videos are turned into sequences too, using an “encoder” that converts each picture/frame into compact tokens.
- Learning text: The model does “next-token prediction.” That means it guesses the next word, one by one, like finishing a sentence.
- Learning visuals: The model uses a diffusion-like process, which you can imagine as learning to remove noise from a blurry picture step by step until it becomes clear again. In training, they add noise to image tokens and teach the model to clean it up.
To make visual tokens, they test several encoders:
- VAE: a classic image compressor.
- Semantic encoders (like SigLIP 2, DINOv2): these focus on the meaning of the image.
- Raw pixels: feeding the model the image directly in small patches.
They also try a Representation Autoencoder (RAE) setup: use a strong semantic encoder for understanding and pair it with a decoder that can reconstruct images, so the same representation works for both understanding and generation.
Data mixtures they train on:
- Plain text.
- Raw videos (without captions).
- Image–text pairs (pictures with captions).
- Action-conditioned video (sequences where a stated action leads to a next view), used for “world modeling.”
Model design:
- A single decoder-only Transformer backbone processes both text and visual tokens.
- They compare:
- Shared layers vs. modality-specific sub-layers (so text tokens and vision tokens can get tailored processing).
- Mixture-of-Experts (MoE): imagine a big team of specialists (experts). For each token, a “router” picks a few experts to process it. This gives lots of total capacity but low active cost per token.
Scaling analysis:
- IsoFLOP analysis: keep compute the same and see how changing data/model size affects results. This helps reveal whether vision or language benefits more from more data or more parameters.
Key terms explained:
- Next-token prediction: guessing the next word in a sentence.
- Diffusion/flow matching: learning to turn a noisy picture back into a clean one, step by step.
- Encoder/decoder: encoder turns images into compact tokens; decoder turns tokens back into images.
- MoE (Mixture-of-Experts): many small “specialist” networks; the model learns which ones to use for each token.
What they found (main results)
Here are the big takeaways, explained simply:
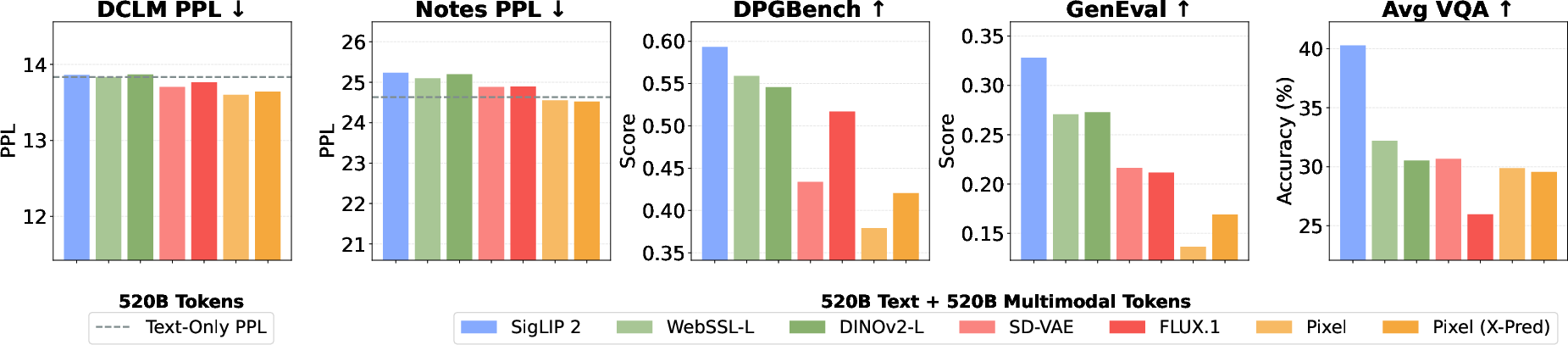
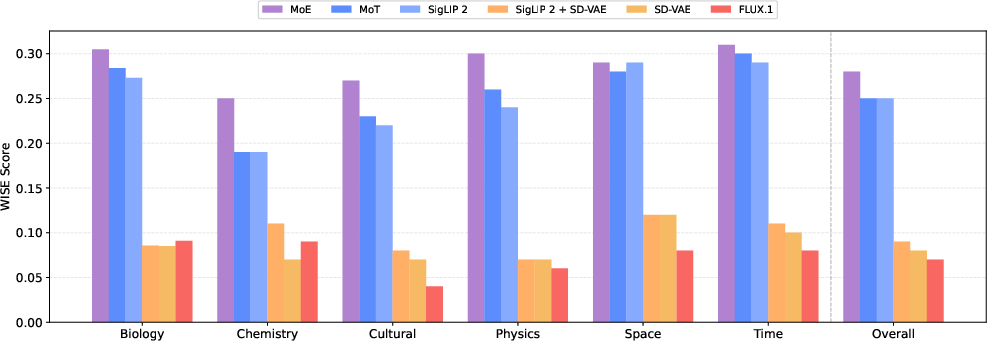
- One visual representation can do it all. Using an RAE-style approach with a semantic encoder (like SigLIP 2) gives great performance for both understanding images and generating them. You don’t need separate visual systems for the two tasks.
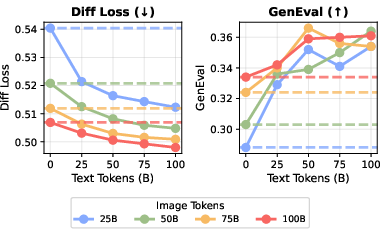
- Text and vision help each other. Adding video and image–text data doesn’t hurt the model’s language ability much, and often helps vision a lot—especially for text-to-image tasks where better language understanding improves how well the picture matches the prompt.
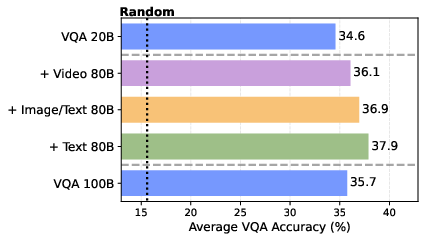
- Diverse, general training beats narrow, specialized training. For tasks like VQA (answering questions about images) and world modeling (predicting how the next view changes after an action), adding general data (text, video, image–text) helps more than just pouring in more task-specific data. In fact, the model can learn most of the “world modeling” skill from general video, needing only a tiny bit of action-labeled data to align it.
- World modeling emerges naturally. By representing actions as plain text (numbers or phrases like “go forward”), the same multimodal model can predict future frames and even follow free-form language commands (like “move into the light”), without special action modules.
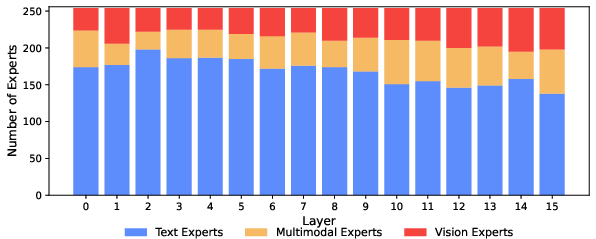
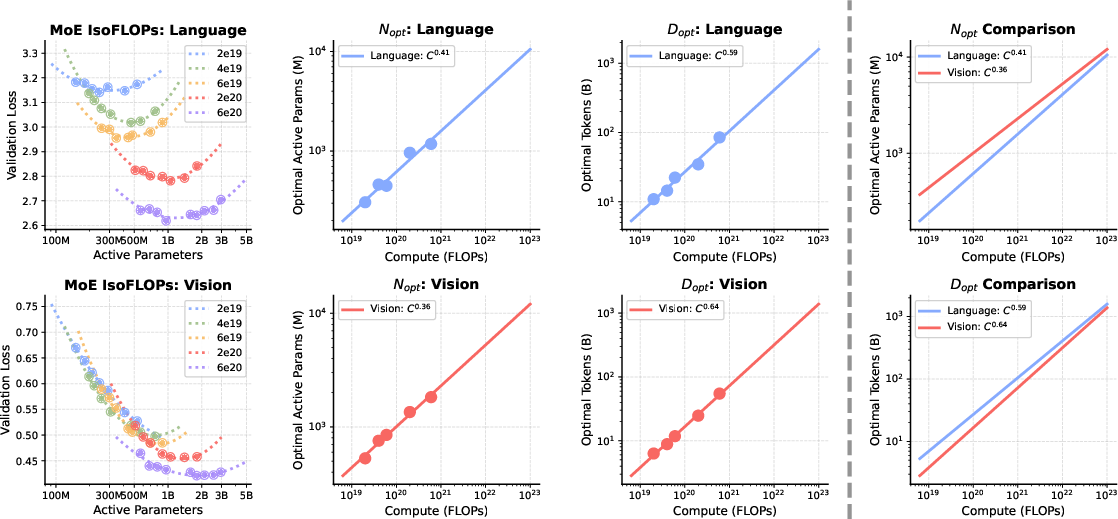
- Mixture-of-Experts makes scaling efficient and smart. MoE lets the model grow a lot of total capacity without costing more per token, and it naturally learns specialization:
- More experts focus on language (language tends to need more parameters).
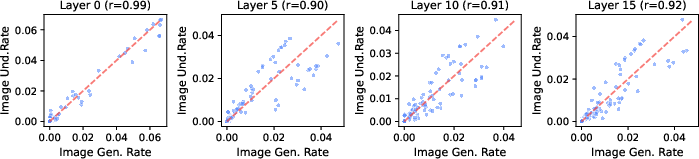
- Vision experts are more “general-purpose” across the denoising steps and are shared between image understanding and image generation.
- Having some modality-specific shared experts (one for text, one for vision) improves performance further.
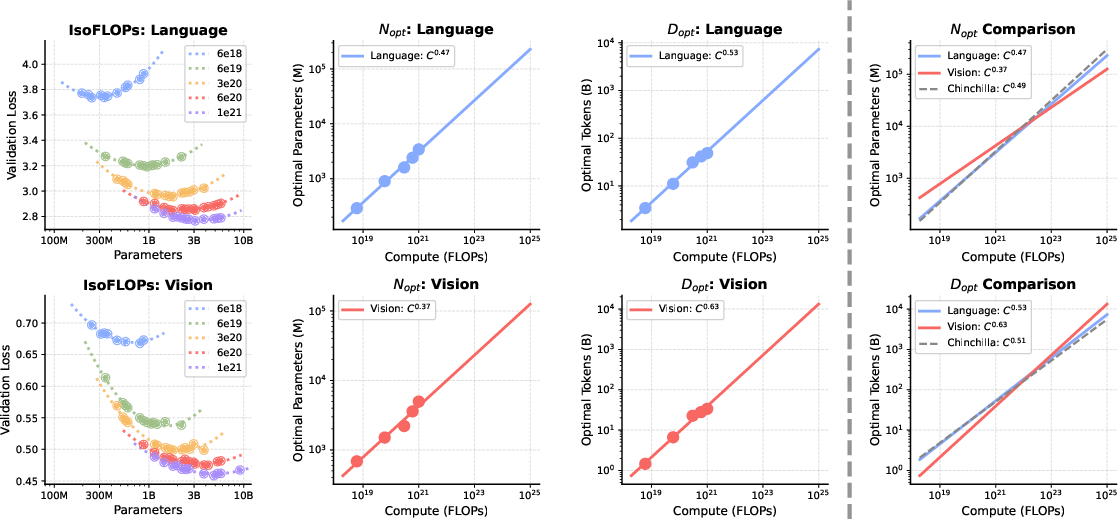
- Scaling asymmetry: vision vs. language. Vision is more data-hungry; language is more parameter-hungry. In other words, to get better at vision you mainly need more diverse visual data, while language benefits more from larger model capacity. MoE helps balance these needs nicely in a single model.
Why these results matter:
- A single, simpler visual representation reduces complexity and makes training and inference easier.
- Unified training from scratch reveals true multimodal learning dynamics, instead of being biased by starting from a language-only model.
- The synergy between text and visuals means we can build stronger, more flexible models by training them together, not separately.
Why it matters (implications and impact)
- Simpler and stronger multimodal models: Using one shared visual representation (RAE with a semantic encoder) means fewer parts to manage and better performance in both understanding and generation.
- Better use of data: The visual world is huge and endless, while high-quality text is limited. Training on videos and image–text pairs taps into that rich signal and teaches the model about real-world dynamics, not just words.
- Emergent world modeling: With mostly general multimodal training plus a small amount of action-aligned data, models can learn to predict and plan in the physical world—an important step toward helpful agents and robotics.
- Smarter scaling with MoE: Because language and vision scale differently, MoE provides a practical way to grow unified models efficiently, giving language the capacity it needs while feeding vision the data it craves.
- A roadmap for future models: The paper offers concrete design tips—use RAE-like visual representations, train on diverse multimodal data, represent actions as text, and adopt MoE with some modality-aware choices—to build truly unified AI systems that see, talk, and act.
In short
Train one model on both words and visuals from the start. Use a unified visual representation, mix diverse data, and scale with Mixture-of-Experts. You’ll get a model that reads, sees, creates images, answers questions about them, and can even predict how the world changes—often with surprisingly little task-specific data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies concrete gaps, uncertainties, and unexplored directions that remain open based on the paper’s methods, analyses, and evaluations.
- “From scratch” multimodal pretraining is confounded by frozen, pretrained visual encoders/decoders (e.g., SigLIP 2, RAE decoders). Quantify how much capability is inherited versus learned by training encoders/decoders end-to-end from random initialization and comparing to the frozen setup.
- RAE-based decoders are used off-the-shelf without reconstruction/fidelity analysis. Measure reconstruction quality, calibration, and downstream impact of decoder mismatch across domains; assess whether end-to-end finetuning of the decoder improves generation and VQA.
- Video is encoded frame-by-frame with an image encoder at 1 FPS and block-wise masking. Evaluate true spatiotemporal video latents (e.g., video VAEs/RAEs), higher frame rates, and temporal attention priors to test whether temporal modeling limitations cap world-modeling performance.
- Visual diffusion is trained with independent t per frame and bidirectional within-frame attention. Ablate alternative schedules (shared t across a clip, correlated noise across frames) and causal 2D/temporal attention to test their effects on coherence and controllability in video rollouts.
- The choice and scheduling of loss weights (λ_flow vs. λ_LM) are ad hoc. Perform sensitivity analyses and curriculum schedules to determine robust weighting strategies that minimize modality interference while maximizing synergy.
- The masking design gives bidirectional attention within frames but causal language masking. Investigate whether other masking schemes (e.g., fully causal visual masking, local 2D causal windows, bi-causal fusion layers) change cross-modal interference or alignment.
- The definition of “vision tokens” and token-to-FLOP mapping is under-specified. Provide a standardized token accounting and compute normalization across visual representations to ensure fair IsoFLOP comparisons and reproducibility.
- Raw pixel training is only briefly tested and underperforms. Explore whether 2D priors (relative position bias, local attention, convolutional stems), larger scale, and adapted noise schedules can close the gap to semantic encoders for both generation and understanding.
- The superiority claim of RAE (semantic) latents over VAEs is based on limited metrics. Include broader image/video generation metrics (e.g., FID/KID, CLIPScore, human A/B tests), and test captioning/retrieval to more comprehensively validate representation choice.
- GenEval/DPGBench may not fully capture generation quality across styles and prompts. Add human evaluations, robust text-image alignment tests, compositional generalization stress-tests, and out-of-distribution prompts.
- VQA is evaluated after finetuning; zero-shot or few-shot results from pretraining are not reported. Quantify how much capability is present natively versus acquired via finetuning, especially for cross-modal reasoning.
- Vision understanding evaluation is limited to VQA. Add captioning, retrieval, referential grounding, detection/segmentation, and long-form visual reasoning to assess general representation quality.
- The reported synergy (language helping vision) may reflect improved text conditioning rather than general visual improvements. Control by evaluating unconditional generation and non-text-conditioned visual tasks.
- World modeling is demonstrated only for navigation. Test transfer to manipulation, multimodal affordance prediction, physical dynamics forecasting, and multi-step planning tasks with varying horizons and partial observability.
- Actions are represented as text tokens; no direct comparison to continuous vector action representations under identical setups. Quantify any performance gaps and hybrid schemes (text + continuous) for robustness and precision.
- Planning uses CEM over predicted frames with LPIPS to the goal image. Compare to policy learning, latent-space planning objectives, success-rate metrics, obstacle-avoidance constraints, and closed-loop control in simulation and on real robots.
- Language-driven navigation is shown qualitatively. Provide quantitative evaluations of language instruction following (e.g., success rates, path optimality, compliance under ambiguous commands) and robustness to linguistic variability.
- Scaling asymmetry and IsoFLOP analysis are summarized but methodological details and full scaling curves are not presented. Release full fits, uncertainty bands, cross-dataset validations, and tests at larger model/data scales to confirm the asymmetry.
- MoE is applied only to FFN layers with specific granularities; attention-layer MoE and alternative routing (token/frame-level, modality-aware gates, time-aware routing) remain unexplored.
- Router stability, expert collapse, and modality imbalance under high sparsity are not analyzed. Report load-balance metrics, gate temperature effects, auxiliary loss sensitivities, and mitigation strategies.
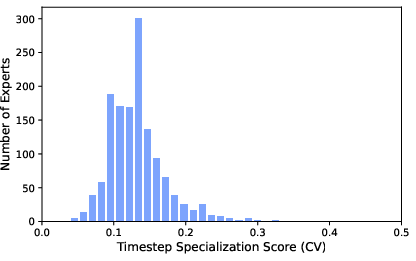
- Expert specialization analysis finds little timestep specialization; it remains unknown whether explicit timestep-conditional experts or noise-level conditioning could improve high-frequency detail or denoising efficiency.
- Shared-expert designs are limited (one shared expert per modality). Explore multiple shared experts, depth-varying shared experts, and adaptive shared-capacity schedules to optimize capacity allocation over depth and modalities.
- Data mixture scheduling is static. Test curricula, staged mixing, and adaptive sampling policies that respond to learning signals to further enhance cross-modal synergy and reduce distributional conflicts (e.g., caption text vs. pretraining corpus).
- Safety, bias, privacy, and data governance are not discussed. Audit training data, measure bias/representation harms, evaluate safety in grounded tasks (e.g., unsafe action suggestions), and establish mitigation/alignment protocols for multimodal deployment.
- Throughput, memory footprint, and wall-clock efficiency for long sequences, high FPS video, and MoE routing overhead are not reported. Profile and optimize for production constraints, and document efficiency trade-offs vs. accuracy.
- Contamination checks are absent. Verify that evaluation sets (e.g., GenEval/DPGBench prompts, VQA benchmarks) are not present in the training mixtures (MetaCLIP/Shutterstock/etc.), and quantify any contamination risks.
- Multilingual and cross-lingual capabilities are not evaluated; tokenization is LLaMA-3 BPE English-centric. Assess non-English performance, code-switching, and cross-lingual grounding in image/video tasks.
- Multi-turn, interleaved multimodal dialogues and long-context reasoning are not tested despite the masking support. Evaluate conversational grounding, reference resolution across long sequences, and memory over extended video-text interactions.
Practical Applications
Below are actionable applications that follow from the paper’s findings on unified multimodal pretraining (Transfusion with diffusion for vision and next-token for language), Representation Autoencoders (RAE), multimodal data composition, emergent world modeling, and Mixture-of-Experts (MoE) architectures. Each item notes target sectors, likely tools/workflows, and feasibility dependencies.
Immediate Applications
The following can be piloted or deployed with current tooling and compute budgets similar to those used in the paper (2–3B active parameters; existing RAE decoders; standard MoE frameworks).
- Unify vision stacks using RAE-based semantic encoders for both understanding and generation
- Sectors: software/AI platforms, creative media, advertising, e-commerce
- What: Replace dual-representation pipelines (e.g., VAE for T2I + CLIP/SigLIP for VQA) with a single high-dimensional semantic encoder (e.g., SigLIP 2) and an RAE decoder to support both text-to-image generation and image understanding.
- Tools/workflows: SigLIP 2 or DINOv2 latents + RAE decoder; 25-step Euler sampler; classifier-free guidance (CFG≈3); FlexAttention for mixed masking
- Dependencies/assumptions: Access to RAE decoders; license compatibility for encoders (e.g., SigLIP 2); image resolutions ~224 px; quality hinges on data composition and prompt alignment
- Improve text-to-image alignment by co-training/grafting extra text tokens into T2I training
- Sectors: creative tools, marketing, game asset pipelines
- What: Add text-only tokens alongside vision during pretraining or continued pretraining to boost prompt fidelity and compositional alignment (synergy effect in GenEval).
- Tools/workflows: Multimodal batches with λ_LM≈1.0, λ_flow≈3.0; data schedulers that keep a steady text stream
- Dependencies/assumptions: Sufficient high-quality text (DCLM or equivalent); prompt distribution aligned with downstream prompts
- Task-targeted image–text data curation: decouple I2T vs T2I sources
- Sectors: MLOps/data engineering, foundation model providers
- What: Use web-crawled captions (e.g., MetaCLIP) for understanding (I2T) and high-aesthetic sources (e.g., Shutterstock) for generation (T2I); avoid recaption distributions that drift far from your language corpus when language quality is critical.
- Tools/workflows: Caption-distribution diagnostics (e.g., cosine distance to pretraining corpus); per-objective dataset routing
- Dependencies/assumptions: Rights-cleared access to aesthetic datasets; monitoring language perplexity on in-domain corpora to detect drift
- Drop-in modality-specific FFNs or MoE layers to improve performance at fixed compute
- Sectors: cloud AI, enterprise AI systems, open-source model stacks
- What: Replace shared FFNs with modality-specific FFNs or adopt MoE with per-modality shared experts to improve both language perplexity and visual metrics without increasing active FLOPs.
- Tools/workflows: Top-k gated MoE (e.g., Switch/DeepSpeed-MoE/Tutel/GShard); per-modality shared expert configuration; granularity around G≈16
- Dependencies/assumptions: Stable routing with load-balancing loss; inference-time MoE support in serving stack; QA for token-level routing correctness
- Action-as-text interfaces for simulators and lab robotics
- Sectors: robotics (R&D), simulation platforms, academic labs
- What: Encode actions as textual tokens (e.g., WASD, numeric deltas) for video-conditioned next-state prediction and zero-shot planning via Cross-Entropy Method (CEM); use LPIPS to evaluate rollouts.
- Tools/workflows: NWM-style training sequences; CEM (N≈120, horizon≈8); LPIPS-based planning objective
- Dependencies/assumptions: Simulator access and logged trajectories; diffusive vision head and a semantic encoder; real-time constraints modest (planning loop may be slow)
- Preview and plan visual navigation in creative/XR pipelines
- Sectors: real estate virtual tours, cinematography previsualization, game engines, XR
- What: Use language-described camera moves to roll out future frames for storyboards or virtual tours; leverage the emergent world modeling behavior.
- Tools/workflows: Text-conditioned denoising rollouts; action prompts (“pan left 10°,” “move forward 2 m”)
- Dependencies/assumptions: Consistent scene encoding (frames at 1 FPS or similar); acceptable latency for multi-step diffusion
- Data-budgeting and collection guidance: vision is more data-hungry than language
- Sectors: MLOps, data strategy, foundation model teams
- What: Prioritize large-scale video ingestion (unlabeled is valuable) and maintain text streams; expect diminishing returns from over-scaling task-specific datasets vs. broad multimodal pretraining.
- Tools/workflows: IsoFLOP-informed planning; token-budget schedulers; out-of-domain validation (e.g., “Notes” perplexity)
- Dependencies/assumptions: Storage/ETL for large video corpora; data governance for video rights/privacy
- Rapid VQA improvements through multimodal pretraining + light finetuning
- Sectors: enterprise support tools, accessibility apps, education
- What: Pretrain on mixed video/image–text + small VQA finetune to surpass larger VQA-only models; deploy for document/image assistance and classroom tools.
- Tools/workflows: Cambrian-7M finetuning recipe; SigLIP 2 + RAE latents; few-epoch VQA fine-tunes
- Dependencies/assumptions: VQA datasets matching target domain; evaluation across bias/safety benchmarks for deployment
- Leaner infrastructure by training from scratch when LLM dependence is costly or restricted
- Sectors: startups, regulated industries
- What: Train a 2–3B-parameter backbone from scratch with multimodal data if licensing/compliance prevents using large pretrained LLMs; maintain solid VQA/generation without inherited LLM weights.
- Tools/workflows: Decoder-only architecture; Transfusion-style joint training; FlexAttention hybrid masking
- Dependencies/assumptions: Compute budget similar to paper; careful data composition to avoid language degradation
Long-Term Applications
These require additional research, scaling, engineering, or validation (e.g., larger models, higher frame rates, safety, latency optimizations, domain certification).
- Language-driven robotics and embodied AI with minimal in-domain data
- Sectors: logistics/warehousing, home robotics, field robotics
- What: Use unified multimodal models to plan and execute actions from free-form language in real environments; leverage video-heavy pretraining and a small amount of task data.
- Tools/workflows: On-robot MoE backbones; closed-loop planning replacing CEM with learned planners; safety monitors
- Dependencies/assumptions: Real-time control; robust sim2real; safety and regulatory compliance; streaming sensors at higher FPS than 1
- General-purpose world models for AR/VR navigation and assistance
- Sectors: XR/AR navigation, accessibility, tourism
- What: Predict and render future views to assist navigation or preview layouts; interpret natural language commands to guide movement and gaze.
- Tools/workflows: Low-latency diffusion or distillation to fast predictors; on-device MoE dispatch; caching/foveated rendering
- Dependencies/assumptions: Efficient distillation of diffusion to real-time models; battery/compute constraints; precise SLAM integration
- Cross-domain vision–language assistants that both understand and generate rich media
- Sectors: office productivity, customer support, education
- What: Multimodal copilots that analyze images/screens and generate images or step-by-step visual guides from text queries; unified representation reduces complexity and latency.
- Tools/workflows: Unified encoders with RAE; MoE for efficient scaling; instruction tuning and tool-use integration
- Dependencies/assumptions: Guardrails for hallucinations; privacy-preserving on-device or hybrid processing; UI/UX for visual generation feedback
- Raw-pixel training at scale to reduce encoder dependence and further unify modeling
- Sectors: foundational AI research, hyperscalers
- What: Train directly on pixels with x-pred parameterization at massive scale to close the gap with semantic encoders for generation while retaining strong understanding.
- Tools/workflows: Larger backbones; improved noise schedules; curriculum on resolutions
- Dependencies/assumptions: Substantially more compute; improved optimization stability; scalable data pipelines for high-res video
- Multisensor world models (audio, depth, proprioception) with MoE specialization
- Sectors: robotics, smart devices, autonomous systems
- What: Extend architecture to additional modalities; exploit MoE to specialize experts by modality and fuse later layers (observed separate-then-integrate pattern).
- Tools/workflows: Modality-routed MoE with per-modality shared experts; late-fusion layers; self-supervised alignment
- Dependencies/assumptions: Time-synchronized datasets; serving support for multi-branch routing; calibration across sensors
- Safety-critical forecasting and planning in transportation and healthcare
- Sectors: autonomous driving, medical imaging, surgical robotics
- What: Predict future states (e.g., frames, scans) and plan actions from language or control specifications; unify perception and generation for counterfactuals.
- Tools/workflows: Verified planners; robust uncertainty estimation; regulatory-grade evaluation suites
- Dependencies/assumptions: High-frame-rate, high-resolution data; stringent validation, interpretability, and governance; domain-specific finetuning
- Cinematography and virtual production: text-guided camera motion and scene evolution
- Sectors: film/TV, game development, virtual production
- What: Author complex camera paths and scene changes via natural language; preview multiple trajectories rapidly for creative iteration.
- Tools/workflows: Fast rollouts via diffusion distillation; integration with DCC tools (e.g., Unreal/Unity); script-to-scene pipelines
- Dependencies/assumptions: Latency reduction; consistent asset/style control; IP rights for training corpora
- Energy- and compute-aware scaling strategies informed by modality asymmetry
- Sectors: cloud providers, policy/governance
- What: Allocate compute toward more video tokens (data-hungry vision) while using MoE to supply larger parameter capacity for language without increasing active compute.
- Tools/workflows: IsoFLOP planning dashboards; autoscaling MoE expert pools; dataset/compute co-optimization
- Dependencies/assumptions: Accurate measurement of energy per training regime; standardized reporting; organizational buy-in
- Data governance and provenance frameworks for large-scale video pretraining
- Sectors: policy, legal, data marketplaces
- What: Establish rights/consent frameworks, provenance tracking, and watermarking for massive video ingestion needed by data-hungry vision components.
- Tools/workflows: Data lineage systems; policy-compliant collection; synthetic augmentation pipelines
- Dependencies/assumptions: Evolving legal norms for video; cross-institutional standards and audits
- Scalable multimodal serving with token-level routing
- Sectors: inference platforms, edge/cloud hybrid systems
- What: Production-grade serving for MoE multimodal models with per-token routing and dynamic expert activation to keep latency flat while scaling capacity.
- Tools/workflows: Partition-aware KV-cache + MoE dispatch; load balancing; expert hot-swapping
- Dependencies/assumptions: Mature serving frameworks with MoE support; observability for routing and expert health
Notes on overarching assumptions and risks:
- Compute and data: Vision benefits most from more diverse and larger video datasets; ensure rights and privacy. Models >10B total parameters (with MoE) may be needed for top-tier results.
- Distribution shift: Caption distributions can degrade language perplexity; monitor and curate text sources. Instruction tuning still needed for assistant-style behavior.
- Latency: Diffusion-based generation can be slow; distillation and specialized samplers are required for interactive use.
- Safety and alignment: Multimodal systems can hallucinate or misinterpret prompts; add guardrails, red-teaming, and domain-specific evaluation before deployment.
Glossary
- Absolute Trajectory Error (ATE): A metric that quantifies the deviation between a predicted navigation trajectory and the ground-truth path. "and report the absolute trajectory error (ATE) and relative pose error (RPE)."
- Action-conditioned video: Video data where visual sequences are paired with corresponding actions used to condition predictions. "and even action-conditioned video."
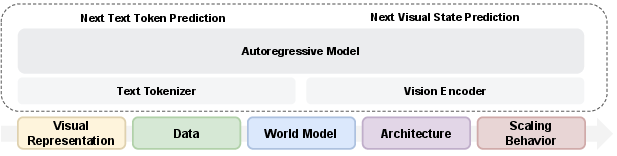
- Autoregressive: A modeling approach that predicts the next element in a sequence conditioned on all previous elements. "We train a single autoregressive model with next-token prediction for text and next-visual state prediction with flow matching."
- Block-wise causal mask: An attention masking scheme where tokens within the same block (e.g., image frame) attend bidirectionally while maintaining causal structure across blocks. "visual data uses a block-wise causal mask where each video frame (or static image) is a separate block."
- BPE tokenizer: Byte Pair Encoding; a subword tokenization method commonly used in LLMs. "Text is tokenized with a standard BPE tokenizer from LLaMA-3~\citep{grattafiori2024llama3} and trained with next-token prediction."
- Cambrian-7M: A large-scale dataset for visual question answering used for finetuning and evaluation. "All VQA results are reported with 1 epoch of finetuning on the Cambrian-7M dataset."
- Causal mask: An attention mask that prevents a token from attending to future tokens, supporting autoregressive generation. "Language modeling uses a standard causal mask."
- CC12M: A large image dataset used for validation and measuring diffusion loss. "diffusion loss on the held-out CC12M~\citep{changpinyo2021conceptual} validation set"
- CFG: Classifier-Free Guidance; a guidance strength parameter in diffusion models to balance fidelity and diversity. "We use a fixed CFG of 3.0 to run all image generation evaluations and do not tune this value."
- Classifier-free guidance: A technique in diffusion models that improves conditioning without a classifier by mixing conditional and unconditional predictions. "enable classifier-free guidance at inference time~\citep{ho2022classifier}."
- Coefficient of Variation (CV): A normalized measure of dispersion used here to assess expert specialization across diffusion timesteps. "We test this by measuring the Coefficient of Variation (CV) of expert selection rates across 10 timestep bins"
- Cross-Entropy: A loss function for training probabilistic models, especially in language modeling. "standard autoregressive cross-entropy:"
- Cross-Entropy Method (CEM): A stochastic optimization technique used for planning by iteratively sampling and refining action sequences. "For evaluation, we perform zero-shot planning using the Cross-Entropy Method (CEM)~\citep{rubinstein1997optimization}"
- DCLM: A large-scale web text corpus used for pretraining and evaluation. "large-scale web text (DCLM~\citep{li2024datacomp})"
- Decoder-only Transformer: A Transformer architecture composed solely of decoder blocks, used for autoregressive generation. "We use a decoder-only Transformer backbone~\citep{vaswani2017attention}"
- DINOv2-L: A large self-supervised visual encoder providing semantic image representations. "DINOv2-L~\citep{Dinov2} and WebSSL-L~\citep{fan2025scaling}."
- Diffusion: A generative modeling framework that iteratively denoises latent variables to produce data samples. "using next-token prediction for language and diffusion for vision"
- Diffusion Forcing: A training strategy aligning denoising dynamics by injecting independent noise schedules per image/frame. "This independent noise injection aligns the training dynamics with Diffusion Forcing~\citep{chen2024diffusion}."
- Diffusion loss: The training objective measuring error in predicted denoising velocity or target in diffusion models. "diffusion loss on the held-out CC12M~\citep{changpinyo2021conceptual} validation set"
- DPGBench: A benchmark suite for evaluating text-to-image generation quality. "image generation score on DPGBench~\citep{hu2024ella} and GenEval~\citep{ghosh2023geneval}"
- Encoder-agnostic: An architecture design that can accept visual tokens from any encoder without modification. "Our architecture is encoder-agnostic and can accept any visual input."
- Euler sampler: A numerical sampler for diffusion inference, here using 25 steps for denoising. "For visual generation, the model denoises using a 25-step Euler sampler."
- Feed-Forward Network (FFN): The per-token MLP component in Transformer blocks that expands and contracts hidden dimensions. "modality-specific FFNs (one for text and one for vision tokens) instead of shared FFNs by default."
- FlexAttention: An attention implementation enabling flexible masking strategies for multimodal sequences. "implemented via FlexAttention~\citep{dong2024flex}."
- FLUX.1: A visual autoencoding model providing low-dimensional latents for image generation tasks. "We study three families of encoders. First, we study VAEs from Stable Diffusion (SD-VAE)~\citep{LDM} and FLUX.1~\citep{flux}."
- Flow matching: A training paradigm for diffusion that learns velocity fields to transform noise into data. "Following flow matching formulations~\citep{fm,rf}, we sample "
- GenEval: A benchmark for evaluating semantic and compositional alignment in text-conditioned image generation. "image generation score on DPGBench~\citep{hu2024ella} and GenEval~\citep{ghosh2023geneval}"
- Granularity (G): The ratio setting expert size vs. count in MoE, controlling how finely capacity is partitioned. "We first analyze the role of expert granularity "
- IsoFLOP analysis: A controlled scaling methodology that keeps compute (FLOPs) constant to derive scaling laws. "Through IsoFLOP analysis, we compute scaling laws for both modalities"
- I/T (Image–Text) data: Paired image–caption data used to learn visual understanding and text-conditioned generation. "I/T data enables visual capabilities."
- LLaMA-3: A modern LLM whose tokenizer is used for text preprocessing. "from LLaMA-3~\citep{grattafiori2024llama3}"
- Load-balancing loss: An auxiliary regularizer in MoE that encourages uniform expert utilization. "despite the use of an auxiliary load-balancing loss that encourages uniform utilization."
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric for image similarity used in planning. "minimize the LPIPS distance~\citep{lpips}"
- MetaCLIP: A large-scale image–text dataset derived from web data for paired training. "paired image--text data (MetaCLIP~\citep{xu2023demystifying} and in-house Shutterstock)"
- Mixture-of-Experts (MoE): A sparse neural architecture routing tokens to specialized expert networks to increase capacity efficiently. "Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization."
- Modality-specific FFN: Separate FFN layers per modality to improve specialized processing within a unified backbone. "we use modality-specific FFNs (one for text and one for vision tokens) instead of shared FFNs by default."
- Navigation World Model (NWM): A framework and dataset for predicting future visual states from actions in navigation tasks. "We extend our evaluation to the Navigation World Model (NWM) setting"
- Noise schedule: The time-dependent noise weighting used in diffusion training that controls difficulty of denoising. "we shift the noise schedule towards the noisier end of the spectrum"
- Per-Modality Shared Expert: A MoE design where each modality has a dedicated always-active shared expert. "Per-Modality Shared Experts outperform Global Shared Experts."
- Perplexity (PPL): A measure of LLM uncertainty or quality on a text corpus. "text perplexity (PPL) on the held-out DCLM~\citep{li2024datacomp} validation set"
- Representation Autoencoder (RAE): A high-dimensional latent autoencoder enabling diffusion-based generation and strong visual understanding. "Representation Autoencoder (RAE) provides an optimal unified visual representation"
- Relative Pose Error (RPE): A metric for evaluating accuracy of relative motion estimation in navigation. "and report the absolute trajectory error (ATE) and relative pose error (RPE)."
- Scaling asymmetry: The phenomenon where different modalities scale differently with data or parameters (vision needs more data). "uncover a scaling asymmetry: vision is significantly more data-hungry than language."
- Scaling laws: Empirical relationships showing how performance improves with data, compute, or parameters. "compute scaling laws for both modalities"
- SD-VAE: Stable Diffusion Variational Autoencoder used as a visual latent encoder/decoder. "For the VAE encoders, we use the off-the-shelf pretrained decoders from SD-VAE~\citep{LDM} and FLUX.1~\citep{flux}."
- SigLIP 2 So400M: A high-capacity semantic visual encoder used as the default image encoder. "By default, we use SigLIP 2 So400M, unless otherwise specified."
- Sparsity: The MoE property of activating only a subset of experts per token to increase total capacity at fixed compute. "Sparsity scales multimodal performance."
- Top-k routing: An MoE mechanism where the router selects the top-k experts per token. " corresponds to a baseline of 16 large experts () with Top-1 routing, while yields 1024 small experts ()\footnote{Due to implementation constraints in TorchTitan~\citep{torchtitan}, we use 1008 experts for the setting.} with Top-64 routing."
- Transfusion framework: A unified training setup combining autoregressive language modeling with diffusion-based vision modeling. "We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision,"
- U-Net: A convolutional architecture often used in diffusion models; replaced here by linear projections for simplicity. "we use simple linear projection layers instead of a U-Net~\citep{unet}."
- v-pred: Diffusion target parameterization predicting velocity toward clean data, often used with flow matching. "For RAE (SigLIP 2), -pred (solid) outperforms -pred (dashed) on image generation; for VAE (FLUX.1), -pred is better."
- Variational Autoencoder (VAE): A generative encoder–decoder model that learns a low-dimensional latent distribution of images. "Variational Autoencoders (VAE) and semantic representations to raw pixels."
- Velocity field: The vector field predicted in flow matching that guides latents from noise to data. "The model predicts a velocity field "
- Visual Question Answering (VQA): A task where models answer questions about images, evaluating visual understanding. "average VQA accuracy on the 16 Cambrian evaluation benchmarks~\citep{tong2024cambrian}."
- WebSSL-L: A large self-supervised visual encoder used for high-dimensional latents. "DINOv2-L~\citep{Dinov2} and WebSSL-L~\citep{fan2025scaling}."
- World modeling: Learning predictive models of the environment’s dynamics from multimodal data. "unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training;"
- x-pred: Diffusion target parameterization predicting the clean sample directly, useful in high-dimensional latents. "predicting directly (``-pred'')~\citep{li2025jit}."
- Zero-shot planning: Planning without task-specific training, using a learned model to optimize action sequences. "For evaluation, we perform zero-shot planning using the Cross-Entropy Method (CEM)~\citep{rubinstein1997optimization}"
Collections
Sign up for free to add this paper to one or more collections.