ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
Abstract: Achieving autonomous and versatile whole-body loco-manipulation remains a central barrier to making humanoids practically useful. Yet existing approaches are fundamentally constrained: retargeted data are often scarce or low-quality; methods struggle to scale to large skill repertoires; and, most importantly, they rely on tracking predefined motion references rather than generating behavior from perception and high-level task specifications. To address these limitations, we propose ULTRA, a unified framework with two key components. First, we introduce a physics-driven neural retargeting algorithm that translates large-scale motion capture to humanoid embodiments while preserving physical plausibility for contact-rich interactions. Second, we learn a unified multimodal controller that supports both dense references and sparse task specifications, under sensing ranging from accurate motion-capture state to noisy egocentric visual inputs. We distill a universal tracking policy into this controller, compress motor skills into a compact latent space, and apply reinforcement learning finetuning to expand coverage and improve robustness under out-of-distribution scenarios. This enables coordinated whole-body behavior from sparse intent without test-time reference motions. We evaluate ULTRA in simulation and on a real Unitree G1 humanoid. Results show that ULTRA generalizes to autonomous, goal-conditioned whole-body loco-manipulation from egocentric perception, consistently outperforming tracking-only baselines with limited skills.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
ULTRA: A simple explanation for teens
What is this paper about?
This paper introduces ULTRA, a new “all-in-one” control system for humanoid robots. These robots don’t just walk—they also use their whole bodies to move, lift, and carry objects at the same time. ULTRA helps a robot do these tasks in many different situations: when it has detailed step-by-step instructions, when it only knows the final goal, and when it sees the world through its own cameras instead of perfect sensors. The big idea is to make one robot “brain” that can smoothly switch between these modes.
What questions are the researchers asking?
- How can we turn human motion data (like motion-capture recordings of people moving and manipulating objects) into robot motions that are safe and physically realistic, especially when the robot must touch and carry things?
- Can we train a single controller that works with many kinds of input: detailed motion references, short commands, accurate motion-capture sensors, or just a robot’s own noisy camera?
- Will this controller work not only in simulation but also on a real humanoid robot?
How did they do it? (In everyday terms)
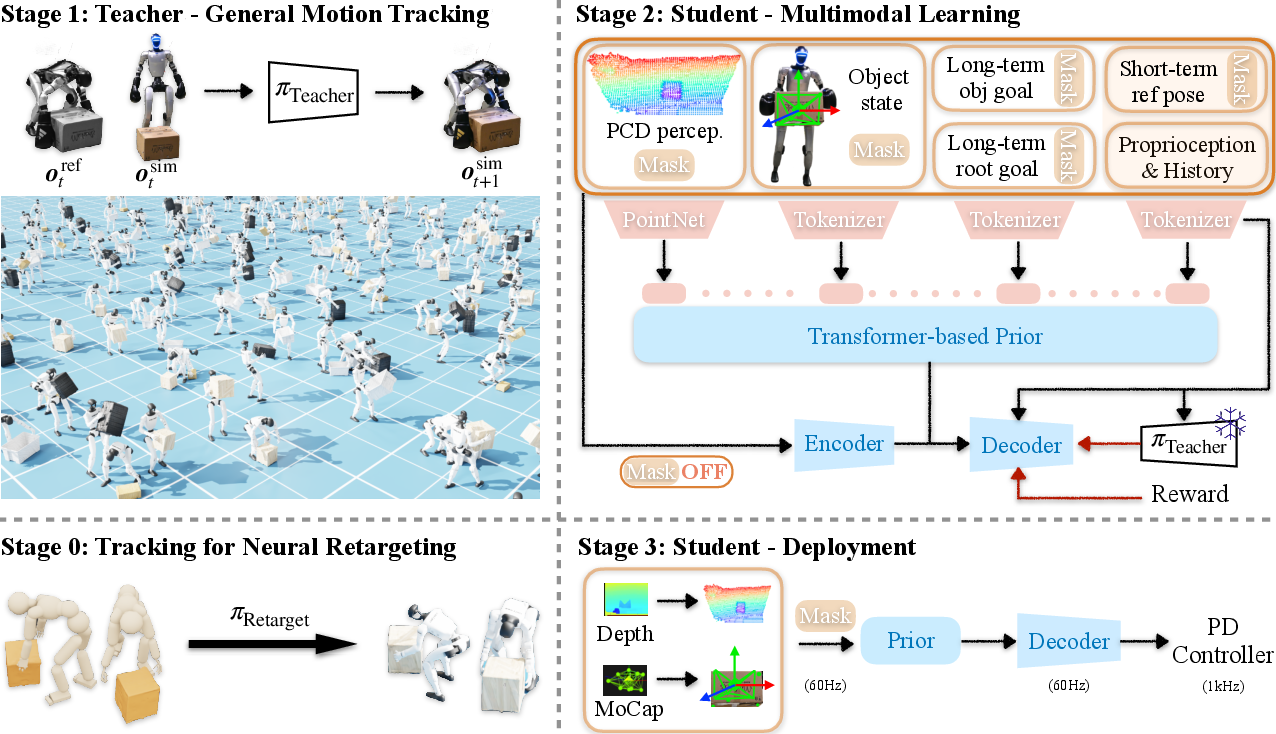
The approach has two main parts, plus a training strategy that connects them.
- Translating human moves to robot moves (retargeting)
- Imagine teaching a smaller, differently shaped person to perform a dance recorded from a taller dancer, but making sure every step is physically possible—no slipping, no hands passing through a box, and feet that don’t slide on the ground.
- They use a physics simulator and “trial-and-error learning” (reinforcement learning) to train a policy that turns human motion-capture data into robot versions that obey physics and contacts.
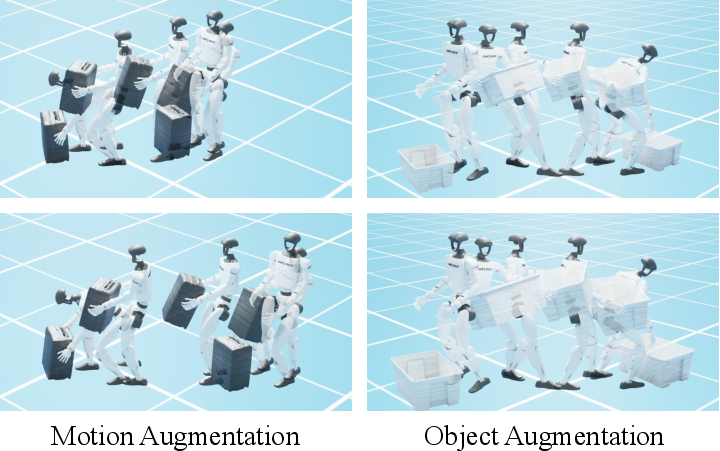
- Because it’s physics-aware, this translator creates big, high-quality, physically plausible robot motion datasets. It can also “augment” the data by resizing movements or the objects—like practicing with different box sizes—without breaking the physics.
- A unified robot controller that understands many inputs
- First, a “teacher” controller learns to precisely track the high-quality robot motions created above. The teacher gets perfect information (like having a cheat sheet during practice).
- Then, a “student” controller learns from the teacher, but under realistic conditions: sometimes it gets detailed references, sometimes only a target (“put the box here”), and sometimes it must rely on its own camera depth data. Think of the student as learning to perform without the cheat sheet.
- The student uses:
- An “availability mask,” which tells it which inputs it currently has. This makes one policy work whether some inputs are missing or noisy.
- A compact “skill code” (latent space), like a short internal label for a move, that helps it stay consistent even when the instructions are vague.
- A training loop where, during practice, the student can ask the teacher what it should have done (like getting coaching feedback).
- Finally, they fine-tune the student with reinforcement learning so it gets better at reaching goals and recovering from surprises it didn’t see in the training data.
What did they find, and why does it matter?
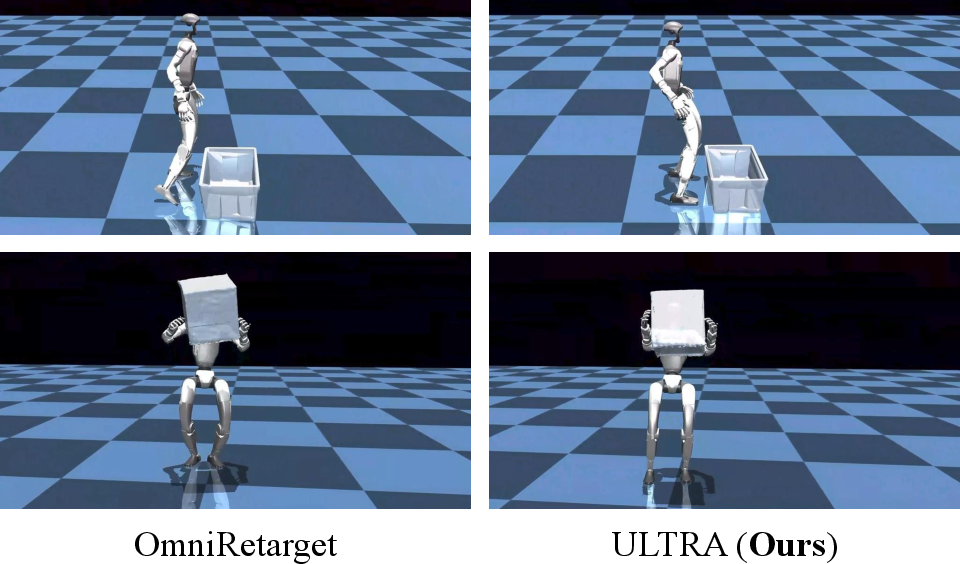
- Better motion translation: Their physics-driven translator produced more realistic motions than popular kinematic methods. In plain terms, the robot’s feet stayed planted without sliding, hands kept stable contact with carried objects, and bodies didn’t pass through things.
- Strong tracking and beyond: The student controller closely matched a powerful teacher when detailed references were available, and it stayed smoother and more stable (less jitter). It also beat tracking-only baselines because it could handle the object and contacts better.
- Works with less information: When given only high-level goals instead of step-by-step motion, the controller still performed the tasks—showing it can switch from “follow-the-script” to “figure-it-out” mode.
- More robust with practice: After reinforcement learning fine-tuning, the controller got much better at out-of-distribution cases—new goal positions and object sizes it didn’t see during training.
- Real robot tests: On a Unitree G1 humanoid, ULTRA succeeded at whole-body tasks like lifting and carrying boxes or a suitcase. It worked both with motion-capture object tracking and with the robot’s own depth camera perception. There were some failures due to slippery grasps and camera noise, but overall it showed reliable performance.
Why is this important?
- One controller, many uses: Instead of building separate systems for “follow a detailed plan” and “just reach the goal,” ULTRA does both. This reduces the need for perfectly prepared motion scripts at test time.
- Closer to real-world autonomy: The robot can act with its own sensors and handle changes, which is key for homes, warehouses, or disaster sites where conditions aren’t perfect.
- Scales with data: The physics-based translator turns massive human motion datasets into robot-ready training data that include real contact and object handling. That means more varied, realistic practice for the robot.
- A step toward practical humanoids: By unifying walking and manipulation with flexible sensing and goals, ULTRA moves humanoids closer to being useful helpers rather than scripted performers.
In short, ULTRA teaches a humanoid robot to move and manipulate objects using its whole body, whether it has step-by-step instructions or just a final goal, and whether it sees the world through perfect sensors or its own noisy camera. It does this by translating human motions into physics-correct robot motions and then distilling those skills into a single, flexible controller that works in both simulation and the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be directly actionable for future research.
- Object diversity and dexterity: The system is evaluated on four box-shaped objects and avoids objects that require dexterous hands. Extend to non-box geometries (articulated, deformable, soft, slippery, transparent/reflective), tasks requiring fingertip dexterity, and variable friction/texture, and quantify performance across these categories.
- Environmental variety: Experiments occur on flat ground with uncluttered scenes. Test on uneven terrain (stairs, ramps), narrow passages, cluttered environments, varying surface properties (e.g., compliant floors), and obstacle-rich settings; integrate obstacle-aware planning and contact sequence generation.
- Real-world sensing robustness: Egocentric perception uses a simple depth-to-point-cloud pipeline (ROI crop, ground removal, clustering) and fails under occlusion/noise. Incorporate RGB-D fusion, instance segmentation, 6D pose tracking, multi-view sensing, temporal filtering, SLAM, and active gaze control; stress-test with severe occlusions, reflective/transparent objects, and sensor calibration drift.
- Generalization across embodiments: ULTRA is trained and evaluated only on Unitree G1. Demonstrate retargeting and controller transfer to humanoids with different morphologies/actuation, quantify adaptation cost, and develop morphology-aware conditioning or rapid adaptation methods (e.g., minimal fine-tuning or meta-learning).
- Hardware-aware retargeting fidelity: The retargeting stage uses idealized actuation without domain randomization, which may produce references that are infeasible or suboptimal on hardware. Evaluate the impact of hardware-aware constraints (torque/velocity limits, compliance, actuator dynamics) during retargeting, and quantify downstream effects on teacher/student training and real-world success.
- High-level planning integration: Current control follows long-horizon transforms but lacks global path or contact planning. Investigate hierarchical integration (planner + controller), obstacle avoidance, and task-level sequencing (e.g., grasp-lift-carry-place), ensuring physical feasibility and reducing error accumulation.
- Sparse-goal precision: Goal success is defined by a 0.3 m positional tolerance, without strict orientation or contact quality criteria. Tighten success metrics (orientation thresholds, contact stability, slip/force limits) and evaluate precise placement tasks.
- Sample size and statistical rigor: Real-world trials are few and aggregate reporting is limited. Increase the number of trials across diverse conditions, report confidence intervals, ablate factors (object mass/size, surface friction, lighting), and perform significance testing to substantiate claims.
- Robustness to sensing failures and latency: Availability masking assumes modality presence is correctly declared; robustness to corrupted inputs, delays, dropped frames, miscalibrations, and adversarial noise is not evaluated. Add explicit tests and mitigation (sensor health checks, input validation, redundancy, predictive filtering).
- Sim-to-real gap analysis: While domain randomization is used for the teacher, the sim-to-real strategy is not systematically quantified. Perform system identification, compare different randomization regimes (physics and perception), measure transfer gaps, and explore online adaptation (e.g., residual learning, policy optimization on hardware with safety constraints).
- Tactile/compliance control: Failures due to friction gaps and grasp slip suggest the need for tactile feedback, grip force control, and compliant whole-body controllers. Integrate tactile sensing, impedance control, and contact-aware safety monitors; evaluate robustness to unexpected contact and disturbances.
- Latent skill interpretability and control: t-SNE shows semantic clustering, but user control over latent skills is not addressed. Develop interfaces to steer the latent (task tokens, language, discrete skill selectors), test composability and smooth transitions, and quantify whether latents correspond to stable, reusable motor primitives.
- Multi-object and dynamic interaction: Tasks involve a single object in mostly static scenes. Evaluate multi-object manipulation (stacking, handovers), interaction with moving obstacles or humans, and coordination under dynamic scene changes.
- Long-horizon memory and state estimation: The controller appears reactive without explicit memory modules. Test tasks requiring long-horizon memory (multi-step assembly) and add recurrent or belief-state estimation to improve performance under partial observability.
- Mode switching behavior: The unified controller supports both dense tracking and sparse goals, but explicit analyses of stability and hysteresis during mode transitions are missing. Characterize transition dynamics, failure modes, and add safeguards or scheduling logic for switching.
- Training efficiency and scaling laws: There is no quantitative analysis of data/computation requirements or scaling with dataset size/augmentation. Report training time, GPU hours, curriculum schedules, and DAgger ratios; study scaling laws and sample efficiency trade-offs.
- RL finetuning design: The partition of simulators into distillation vs. RL is not ablated. Systematically vary the ratio, reward shaping, goal perturbation ranges, and curriculum to identify optimal balances and their impact on OOD robustness.
- Object mass/inertia and grasp variability: Object physical randomization is mentioned but not deeply analyzed. Evaluate performance across wide mass distributions, off-center mass, varying friction/coatings, and fragile/compliant items; establish failure envelopes.
- Contact quality metrics: Interaction quality is primarily measured by penetration, skating, and contact floating. Add force/impulse profiles, energy consumption, contact patch stability, and micro-slippage metrics to better quantify contact fidelity.
- Perception generalization beyond depth: Only depth is used for egocentric control; RGB, thermal, or event cameras are untested. Assess multi-modal perception benefits and failure modes, especially for objects where depth sensing is unreliable (e.g., transparent/reflective surfaces).
- Blind mode capability: The paper claims support for “blind” settings (proprioception-only) but does not provide results. Explicitly evaluate blind mode tasks, define reachable goals under no external sensing, and characterize limits.
- Safety and human-robot interaction: Formal safety guarantees, collision avoidance with humans, and ethical deployment considerations are unaddressed. Incorporate safety constraints, dynamic human detection, and conservative control policies; perform human-in-the-loop studies.
- Cross-dataset generalization: Retargeting and training rely on OMOMO (with augmentation). Test transfer to other corpora (e.g., different motion styles/domains), quantify generalization to novel interaction semantics, and assess robustness to annotation noise.
- Real-time system characterization: Compute budget, latency, and throughput on the robot are not reported. Profile the inference pipeline end-to-end (perception, encoding, control), optimize for embedded deployment, and characterize performance under CPU-only or constrained compute scenarios.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now with controlled scope, leveraging ULTRA’s unified multimodal controller, physics-driven retargeting, and demonstrated real-world performance on the Unitree G1. Each item includes sector links, potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
- Warehouse tote lifting and short-haul transport — Logistics, Retail
- Use ULTRA’s sparse-goal mode with egocentric depth sensing for box pick-up, carry, and set-down between nearby stations. Integrate with a Warehouse Management System (WMS) that publishes object/root transform goals per task.
- Tools/Products/Workflows: ULTRA Student Controller packaged as a ROS 2 node; goal API that translates WMS intents to long-horizon transforms; safety cage/marked workcell; optional MoCap/AR-tag object pose for higher reliability.
- Assumptions/Dependencies: Box-shaped items; moderate loads compatible with G1; reliable friction for grasp; stable floor; adequate onboard compute; operator oversight for exceptions; successful point-cloud extraction in typical lighting.
- Back-of-house luggage or cart moving — Hospitality, Retail Operations
- Operator-in-the-loop control via sparse keyboard/voice commands to move suitcase-shaped items along short routes; ULTRA handles whole-body bimanual carrying and long-horizon goal following.
- Tools/Products/Workflows: Goal-conditioned interface with preset waypoints; shallow autonomy with human supervisor; ROS 2 teleoperation UI with safety stops.
- Assumptions/Dependencies: Clear corridors; low pedestrian density; objects with graspable geometry; basic perception stack calibrated; speed limits to meet safety policies.
- Demonstration-to-robot reproduction of complex motions in labs — Academia, Robotics R&D
- Retarget human-object MoCap sequences (e.g., lift-and-carry) to humanoids with ULTRA’s physics-driven retargeter, then replay in controlled environments to evaluate contact fidelity and motion quality.
- Tools/Products/Workflows: Retargeting pipeline for IsaacGym/MuJoCo; dataset augmentation via trajectory/object scaling; benchmarking with penetration/foot-skating/contact-floating metrics; reproducible sim-to-real workflow.
- Assumptions/Dependencies: Access to MoCap datasets (OMOMO or internal); calibration for embodiment mapping; known object properties; idealized control in sim for retargeting, with later transfer to hardware controller.
- Physically consistent dataset generation for humanoid-object interaction — Software/AI Research, Robotics
- Amortize dataset-scale retargeting to produce large corpora of contact-rich rollouts and zero-shot augmented variants that improve coverage for training foundation-style controllers.
- Tools/Products/Workflows: “Retargeting-as-a-Service” cluster job; auto augmentation (anisotropic trajectory scaling, object resizing); data curation with quality metrics; distribution-shift test suites.
- Assumptions/Dependencies: GPU compute; simulator licenses; consistent reward/observation templates; box-like objects or clear correspondences for contact mapping.
- Multimodal controller SDK for Unitree G1 — Robotics Software
- Package ULTRA’s Student policy as an SDK that supports both dense motion tracking and sparse goal execution under modality masking (proprioception, object state, egocentric point cloud).
- Tools/Products/Workflows: ROS 2 drivers; tokenized input schema with availability masks; reference-tracking shortcut for deterministic replay; calibration scripts for depth cameras.
- Assumptions/Dependencies: Hardware compatibility (G1 or similar); real-time inference performance; standard PD/controller interfaces; maintenance and updates for perception stacks.
- Hybrid teleoperation with autonomy-assisted loco-manipulation — Human–Robot Interaction
- Operators specify intents (e.g., “carry box to shelf”) and ULTRA stabilizes whole-body motion, contacts, and recovery. Useful for pilots where full autonomy is not yet approved.
- Tools/Products/Workflows: Command UI (tablet/voice); safety controller with fall detection and stop; minimal training for operators; logging and oversight.
- Assumptions/Dependencies: Clear division of control; reliable fallback; well-defined tasks; safety protocols for shared spaces.
- Previsualization of physics-consistent character actions — Media/Entertainment, Simulation
- Apply ULTRA’s retargeting and tracking in engines (MuJoCo/Isaac) to plan scenes with realistic contacts (lifting, carrying, transport) before in-studio stunts or robot shoots.
- Tools/Products/Workflows: Export pipelines to Unreal/Unity; automated contact diagnostics; variant generation via augmentation to explore different set pieces.
- Assumptions/Dependencies: Sim-only use (no hardware); compatible character rigs; parameterized object geometry; physics calibration for believable results.
- Course modules and lab assignments on unified control — Education
- Teach unified multimodal control, teacher–student distillation, and RL finetuning under partial observability; students reproduce ULTRA-style pipelines on open humanoid models in sim.
- Tools/Products/Workflows: Starter kits with IsaacGym/MuJoCo; t-SNE latent analysis exercises; benchmark tasks and metrics; small-scale datasets.
- Assumptions/Dependencies: Access to GPU workstations; academic licensing; simplified tasks for classroom constraints.
Long-Term Applications
The following use cases require further research, scaling, or development (e.g., dexterous hands, robust perception, safety certification, broader object/task coverage). They build on ULTRA’s core ideas: physics-driven retargeting, unified multimodal control, and goal-conditioned autonomy without test-time references.
- Household humanoid assistants for fetch-and-carry, tidying, and moving items — Consumer Robotics
- Product vision: “ULTRA Home” providing general loco-manipulation from egocentric perception and natural-language commands across diverse household objects and layouts.
- Tools/Products/Workflows: Semantic perception and mapping; tactile/force sensing for grasp reliability; skill libraries and latent motion priors; integrated voice/planning; home-safe policies.
- Assumptions/Dependencies: Broad object generalization beyond boxes; robust grasping; fall prevention; battery life; cost and maintenance model; regulatory approval for domestic use.
- Safe patient support and logistics in hospitals — Healthcare
- Assist with supply delivery, bed-to-chair transfers, and supporting mobility under clinician supervision, with strict safety envelopes and compliant control.
- Tools/Products/Workflows: Medical-grade hardware; multimodal perception with depth + tactile; certified safety controllers; audit logs; integration with hospital tasking systems.
- Assumptions/Dependencies: Regulatory certification (FDA-equivalent); liability frameworks; high reliability under occlusions and crowds; infection control and cleaning protocols.
- Assembly-line support with dexterous tool use — Manufacturing
- Whole-body loco-manipulation coupled with dexterous end-effectors for part transport, fixture placement, and tool handling, guided by sparse goals and vision.
- Tools/Products/Workflows: Extension to dexterous hands; force/torque control; task tokens and structured goals from MES/BOM; tight integration with quality checks.
- Assumptions/Dependencies: Precision requirements; tool safety; variability in parts; coordination with humans and other robots; cycle-time constraints.
- Disaster response and field operations (debris clearing, door opening, object relocation) — Emergency Response, Defense
- Ruggedized humanoids performing goal-driven loco-manipulation with egocentric sensing in cluttered, variable terrain.
- Tools/Products/Workflows: Robust perception (multi-sensor fusion, SLAM under smoke/dust); adaptive gait and grasp; teleoperation-assist fallback; mission planning interface.
- Assumptions/Dependencies: Environmental extremes; heavy loads; unpredictable contacts; operator bandwidth; specialized safety requirements.
- Cross-embodiment “foundation controller” for humanoid platforms — Software/AI Platforms, Robotics OEMs
- A universal, multimodal controller retargeted across humanoids via physics-aware transfer, with skill latents and availability masks for flexible inputs.
- Tools/Products/Workflows: Standardized robot descriptors (kinematics, dynamics, contacts); cloud training and distillation pipelines; skill marketplace; benchmarking suites.
- Assumptions/Dependencies: OEM collaboration; dataset sharing; scalable compute; common APIs; performance guarantees across embodiments.
- Sector-wide standards and certification for contact-rich humanoid tasks — Policy/Regulation
- Establish metrics (penetration, foot skating, jitter, contact floating) and test protocols for approval of loco-manipulation in shared spaces.
- Tools/Products/Workflows: Conformance testbeds; reporting formats; graded capability levels (tracking-only vs goal-conditioned autonomy); incident logging requirements.
- Assumptions/Dependencies: Multi-stakeholder process; alignment with workplace safety authorities; periodic re-certification; transparency and auditability.
- Human–robot collaboration in construction (material handling, positioning panels) — Construction
- Goal-driven cooperation where humans set sparse intents or BIM-derived placements and humanoids execute whole-body tasks with contact-aware autonomy.
- Tools/Products/Workflows: BIM-to-goal transform pipeline; AR guidance for operators; site safety geofencing; skill libraries for common construction actions.
- Assumptions/Dependencies: Heavy payload handling; variable terrain; weather; glove/hand design; union and safety standards.
- Scalable education and workforce training via simulated humanoids — Education, Workforce Development
- Web-based labs offering realistic loco-manipulation tasks, with progression from sim-only to supervised hardware trials; focus on multimodal control, safety, and HRI.
- Tools/Products/Workflows: Cloud simulation clusters; standardized exercises and metrics; certification pathways; integration with university curricula and vocational programs.
- Assumptions/Dependencies: Funding and infrastructure; accessible hardware; curricular alignment; sustained community support.
Notes on common assumptions and dependencies across applications
- Sensors and perception: ULTRA’s strongest real results currently rely on egocentric depth and, in some modes, accurate object pose (MoCap/AR tags). Robust object state estimation from onboard sensors under occlusions and clutter is a key dependency for broader autonomy.
- Object/scene scope: Demonstrations focus on box-like objects; generalization to varied shapes, deformables, and tool interactions will require additional data, tactile sensing, and policy adaptation.
- Hardware and actuation: Policies must run at control frequencies with reliable PD/low-level controllers; grasp/friction reliability and compliant control are critical for safety.
- Safety, regulation, and oversight: Pilot deployments should include geofenced workcells, speed limits, and human supervision; sector-specific certification is required for healthcare and public spaces.
- Compute and integration: Real-time inference on onboard or edge compute; ROS 2 integration; calibration of cameras and IMU; maintenance of perception stacks.
- Data and training: Access to large, diverse MoCap datasets; physics-driven retargeting and augmentation to broaden coverage; RL finetuning for out-of-distribution robustness.
Glossary
- Adversarial RL: A reinforcement learning approach that uses adversarial objectives (often discriminator-based) to shape behavior or priors. "Others shape latent priors with adversarial RL"
- Anisotropic scaling: Non-uniform scaling along different coordinate axes to augment trajectories or objects. "apply anisotropic scaling along coordinate axes"
- Availability mask: A binary indicator vector signaling which input modalities are present at a given time. "via an availability mask randomly sampled during training"
- Availability masking: A training technique that masks unavailable modalities to enable a single policy to operate under varying inputs. "unified tokenization with availability masking"
- Co-tracking: Simultaneously tracking the dynamics of multiple entities (e.g., humanoid and object) to preserve interactions. "co-tracking humanoid and object dynamics"
- Contact chattering: High-frequency, unstable switching of contact states that can cause jittery behavior. "jitter and contact chattering"
- Contact-rich: Describing tasks or motions that involve sustained or complex physical contacts. "well suited for contact-rich loco-manipulation"
- DAgger: A dataset aggregation imitation-learning algorithm that queries an expert while rolling out the learner. "We collect data with a DAgger-style loop"
- Domain randomization: Training-time randomization of simulation properties to improve robustness and transfer. "We train without domain randomization or perturbations"
- Egocentric perception: Perception from sensors mounted on the agent, aligned with its own viewpoint. "long-horizon goal following with egocentric perception"
- Egocentric point cloud: A 3D point cloud captured from an egocentric depth sensor for object/scene understanding. "an egocentric point cloud from a depth sensor"
- End effector: The terminal link(s) of a kinematic chain (e.g., hands, feet) used to interact with the environment. "tracks end-effector positions"
- Goal-conditioned policy: A policy that conditions its actions on a goal specification rather than only the current state. "by learning a goal-conditioned policy that unifies dense tracking and sparse task specifications"
- Heading-aligned frame: A coordinate frame aligned with the agent’s heading to remove global yaw and simplify tracking. "All quantities are expressed in a heading-aligned frame"
- In-Distribution (ID): Data or tasks drawn from the same distribution as training, used for standard evaluation. "In-Distribution (ID)"
- Inverse kinematics: Computing joint configurations that achieve desired end-effector poses subject to kinematic constraints. "inverse-kinematics optimization"
- K-Means: A clustering algorithm that partitions data into K clusters by minimizing within-cluster variance. "cluster the resulting text embeddings into 5 classes with K-Means"
- KL divergence: A measure of difference between two probability distributions used to align latent posteriors and priors. "D_{\text{KL}!\left(q_\phi(\boldsymbol{z}t\mid \boldsymbol{o}_t{\text{student},\boldsymbol{o}_t{\text{teacher}) \ |\ p\theta(\boldsymbol{z}_t\mid \boldsymbol{o}_t{\text{student})\right)}"
- Latent space: A compressed representation space capturing essential features or skills for control. "compress motor skills into a compact latent space"
- MiniLM: A lightweight LLM used here to embed motion text descriptions. "We encode each motion’s text description with MiniLM"
- Model Predictive Control (MPC): An optimization-based control method that plans actions over a receding horizon. "trajectory optimization and MPC"
- MoCap: Motion capture; a system for recording motion to drive animation or robot behaviors. "motion capture (MoCap)"
- MuJoCo: A physics engine for model-based control and simulation. "validate key results in MuJoCo"
- Out-of-Distribution (OOD): Data or tasks that differ from the training distribution, used to test generalization. "Out-of-Distribution (OOD)"
- Partially Observable Markov Decision Process (POMDP): A decision-making framework where the agent has incomplete state information. "goal-conditioned Partially Observable Markov Decision Process (POMDP)"
- PD controller: Proportional-derivative controller that tracks target joint positions/velocities. "target joint positions executed by a PD controller"
- PPO: Proximal Policy Optimization; a policy-gradient RL algorithm for stable training. "how we use PPO~\cite{ppo}"
- Proprioception: Internal sensing of the robot’s own state (e.g., joint angles, velocities, IMU). "Beyond proprioception, we consider two regimes for object sensing"
- Privileged teacher: A teacher policy trained with access to full state and dense references for supervision. "we train a separate privileged teacher"
- Residual shortcut: A direct pathway that bypasses the latent to stabilize decoding for near-deterministic tracking. "We add a residual shortcut (with the mask) from the full-body goal directly to the decoder"
- Retargeting (motion retargeting): Transferring motion from one embodiment to another while preserving semantics. "we introduce a physics-driven neural retargeting algorithm"
- RL finetuning: Reinforcement learning updates applied after imitation/distillation to improve robustness or coverage. "and apply reinforcement learning finetuning to expand coverage"
- Sim-to-real transfer: Deploying policies trained in simulation on real robots successfully. "We further validate sim-to-real transfer on Unitree G1"
- t-SNE: A dimensionality reduction technique for visualizing high-dimensional embeddings. "We visualize the learned motion embeddings with t-SNE"
- Teacher-student distillation: Training a student policy to mimic a stronger teacher, often under different observations. "follows the scalable teacher-student distillation paradigm"
- Tokenization: Converting heterogeneous inputs into a shared set of tokens for transformer processing. "unified tokenization with availability masking"
- Transformer: An attention-based neural architecture used to fuse multimodal tokens. "We implement \pi_{\text{student} with a transformer-based encoder"
- Trajectory optimization: Optimizing a sequence of actions or states to achieve objectives under constraints. "cast retargeting as RL-based trajectory optimization"
- Variational skill bottleneck: A latent-variable constraint encouraging compact, disentangled skill representations. "a variational skill bottleneck plus RL finetuning"
- Zero-shot augmentation: Generating novel data variants at test time without retraining. "supports zero-shot augmentation"
Collections
Sign up for free to add this paper to one or more collections.