- The paper shows that diffusion models exhibit biased generalization, with outputs favoring training data before overt overfitting occurs.
- Using sample-split analysis on real and synthetic data, the study reveals that cosine similarity and denoiser divergences effectively quantify early-stage bias.
- It highlights significant implications for privacy and deployment by demonstrating that systematic bias arises from the sequential nature of feature learning.
Biased Generalization in Diffusion Models: Characterization and Mechanisms
Overview
"Biased Generalization in Diffusion Models" (2603.03469) investigates the interplay between generalization and memorization in diffusion-based generative models, challenging conventional assumptions about early stopping based on test loss. The study identifies, quantifies, and mechanistically analyzes a regime of biased generalization, demonstrating that models can exhibit systematic proximity to training data before showing canonical signs of overfitting. This phase manifests as generative bias at the sample and score levels, fundamentally orthogonal to standard generalization measures (e.g., test loss), and has significant implications for privacy and deployment.
Empirical Evidence for Biased Generalization
The authors leverage sample-split analysis and controlled diagnostics on both real image data (CelebA) and synthetically structured hierarchical data. By training identical architectures on disjoint datasets, they compare generated samples' mutual distances (cosine similarity) and proximity to respective training sets. Critically, biased generalization emerges before the test loss minimum: generated outputs between distinct models become maximally similar early in training, while bias in outputs (favoring training-proximal samples) materializes even as test loss is still decreasing. This reveals a subtle bias toward training data that precedes overt memorization.
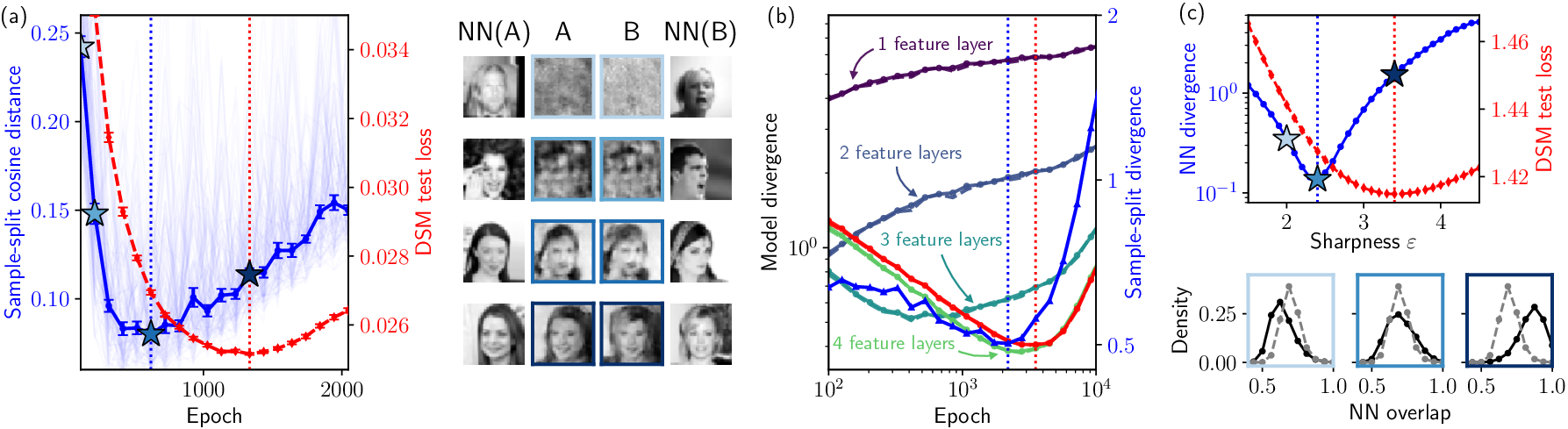
Figure 1: Biased generalization emerges before overfitting; models trained on data splits exhibit maximal sample similarity early in training, with generative bias increasing as finer features are learned.
The qualitative and quantitative findings are corroborated at the score level: divergence between denoisers trained on disjoint splits grows before the test loss minimum, confirming the onset of training-dependent bias. Conditioning on origin (training vs. test) reveals asymmetries that become significant near the biased-generalization transition.
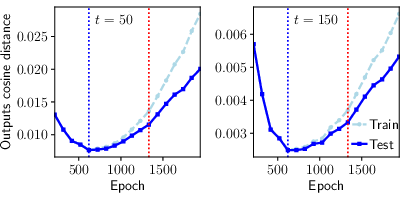
Figure 2: Cosine distances between denoiser outputs trained on distinct splits, highlighting separation between unbiased and biased regimes across noise levels.
Controlled Hierarchical Data Analysis
A hierarchical graphical model, amenable to exact inference via belief propagation, enables precise diagnostics. By exploiting multi-scale tree structures and compositional feature learning, the authors identify sequential regimes in the reverse diffusion process:
- Long-time regime: Outputs are uniform, denoisers indistinguishable from oracle.
- Intermediate regime: Learning begins to resolve structural correlations, with trained denoisers approximating coarser BPk oracles.
- Short-time regime: Symbol-wise rounding suffices; denoisers show triviality in proximity to clean samples.
Sample-split and KL divergence analyses in this setting confirm that model divergence and nearest-neighbor bias arise before the test loss minimum, independent of architecture or optimizer. When denoisers achieve maximal alignment to the best-matching filtered oracle (BPk⋆), further training induces data-dependent bias toward finer, insufficiently sampled features.
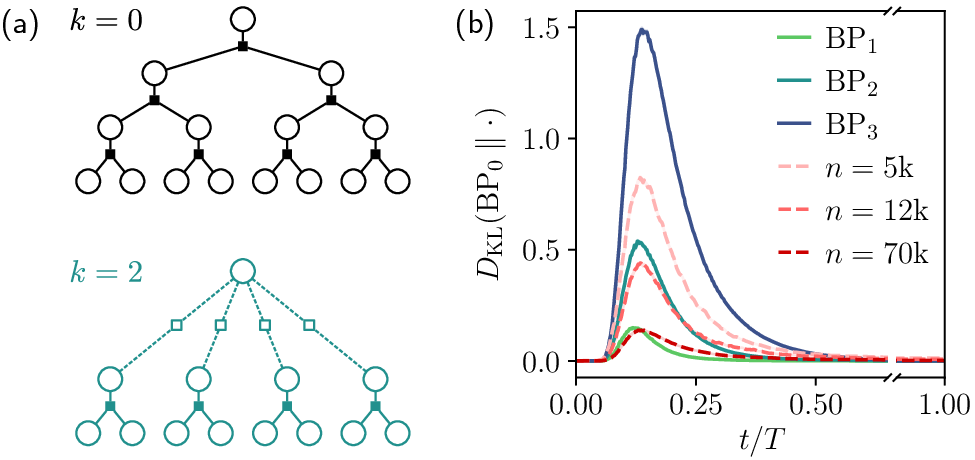
Figure 3: Hierarchical tree-based data generation and comparison of model-BPk divergences along reverse diffusion.
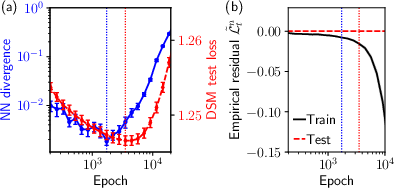
Figure 4: Bias metrics for diffusion models trained on hierarchical data, showing divergence minima preceding test loss minima.
Mechanistic Origin: Sequential Feature Learning
The root cause of biased generalization is the sequential nature of feature extraction in deep architectures. Networks learn coarse, short-range features in a data-independent manner in early epochs, remaining unbiased. As training proceeds, finer, long-range correlations require more data; insufficient statistics induce sample-dependent approximations, manifesting as increasing bias before actual overfitting (test loss increase).
Empirical validation across dataset sizes confirms that the transition to bias systematically follows the completion of population-level learning of the deepest reliably sampled hierarchy level.
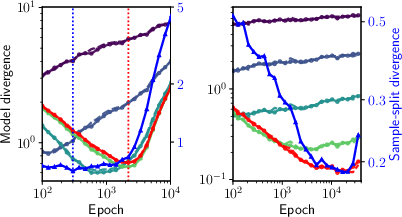
Figure 5: Evolution of model-score divergences for various BPk levels, highlighting sequential feature learning and onset of bias.
Diagnostic Metrics and Implications
The study employs both sample-level (nearest-neighbor overlap, KL divergence) and score-level (denoiser divergence) diagnostics, including “U-turn” experiments (noise–reverse trajectories) to dynamically probe recovery likelihood relative to BP oracles. Models at test loss minima show higher overlap for training data than test samples; bias arises before test loss minima, and persists even as generalization improves.
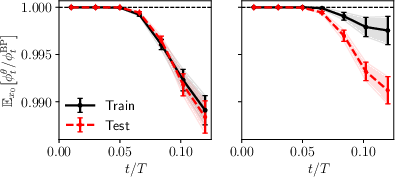
Figure 6: U-turn experiment average overlaps showing model bias in recovering training samples over test samples.
Practical and Theoretical Implications
These findings expose limitations of early stopping based solely on test loss for privacy-critical applications. Biased generalization—systematic proximity to training examples without outright replication—can lead to unwanted memorization, undermining assurances about data provenance and novelty. The paper underscores that minimizing distributional metrics such as DSM test loss does not guarantee unbiased sampling, especially as model sizes and dataset complexities grow. The results have ramifications for model deployment in contexts sensitive to copyright, privacy, and fairness.
Future Directions
Critical open questions involve extending diagnostics to other generative mechanisms (e.g., discrete diffusion, autoregressive models), evaluating bias in large-scale settings, and understanding amplification via conditioning/guidance (e.g., classifier-free guidance). Developing mitigation strategies and robust metrics for detecting and quantifying bias beyond local proximity will be essential for safe and reliable generative AI.
Conclusion
"Biased Generalization in Diffusion Models" systematically demonstrates that generalization and memorization are orthogonal axes in generative model behavior. Biased generalization—where outputs remain close to training data before overt overfitting—is a ubiquitous phenomenon in diffusion models, rooted in sequential feature learning. This challenges the sufficiency of early stopping based on test loss alone, especially in privacy-sensitive domains. Addressing and quantifying biased generalization will be critical for advancing model evaluation, deployment, and theoretical understanding in generative AI.