- The paper introduces AOR, which iteratively refines robot controllers by rewriting full Python code based on multimodal trial outcomes.
- It leverages a fast reactive loop and a slow reflective loop to diagnose and correct vision and control flaws without traditional parameter updates.
- Experimental results on Lift, PickPlaceCan, and Stack benchmarks demonstrate high success rates through precise, code-level adaptations.
Act--Observe--Rewrite: Multimodal Coding Agents as In-Context Policy Learners for Robot Manipulation
Introduction and Motivation
This work introduces Act--Observe--Rewrite (AOR), a framework for in-context policy improvement in robot manipulation that departs from standard deep-learning paradigms. Rather than updating neural parameters, synthesizing skill sequences, or tuning reward functions, AOR directly rewrites the full low-level controller implementation after each episode, using a multimodal LLM to reason over both visual observations and episodic outcomes. The paper asserts that making executable code—the full Python controller class—the object of LLM reflection creates qualitatively new capacities for self-correction in physical agents, particularly enabling precise diagnosis and architectural changes unattainable in previous frameworks.
The AOR Framework
AOR operates across two timescales—a fast, within-episode control loop and a slow, between-episode reflective loop. During an episode, the robot acts according to the current controller (a Python class implementing the manipulation policy). At episode end, structured outcome data (rewards, phase logs, performance metrics) and a compact set of key-frame images are stored in a persistent episodic memory. The LLM then receives:
- The current controller source code,
- The full episodic memory (including visual evidence of failures and success),
- A structured diagnostic prompt (emphasizing explicit failure analysis).
The LLM reflects on these inputs, identifies root causes for performance issues (vision bugs, control logic flaws, parameter mis-tuning, etc.), suggests targeted improvements, and emits a rewritten controller class. The synthesized code is compiled and sandboxed for safety; fallbacks preserve previous working versions in case of errors.
This loop is illustrated in the following schematic, underscoring the separation between reactive execution and deliberative synthesis:
(Figure 1)
Figure 1: The AOR two-timescale architecture, highlighting the episodic memory and reflection-driven code rewriting that interleave with rapid low-level control.
Experimental Validation
AOR was evaluated on three robotic manipulation benchmarks using the robosuite simulator: Lift (pick up a cube), PickPlaceCan (place a can in a bin), and Stack (stack one cube on another). All experiments used only 256×256 RGB-D camera input, with no ground-truth object positions provided to the agent. The multimodal coding agent was instantiated via Anthropic’s Claude Code; OpenAI’s Codex was also tested as an ablation. Key findings include:
- Lift: Achieved 100% success after 3 LLM calls. The agent autonomously discovered and corrected a 2.5 cm vision depth bias and then a control logic flaw involving unstable grasp closures.
- PickPlaceCan: Achieved 100% success after 2 LLM calls. The agent diagnosed color misrepresentation in the camera (can rendered as red, not silver) and contamination of color segmentation by a bin marker, solving both via independent code-level revisions.
- Stack: Reached 91% success after 20 LLM calls through iterative correction of vision pipeline bugs (sign flips, calibration errors) and control refinements. Residual failures were caused by gripper contact displacing the target cube during placement—a root cause identified by the agent, though it did not successfully synthesize a solution within the tested iteration budget.



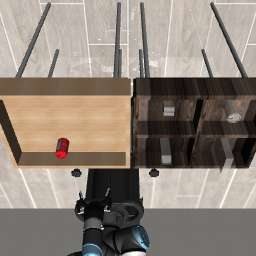
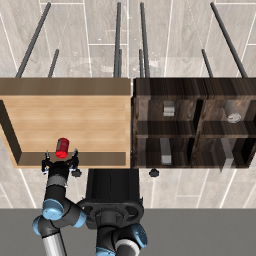
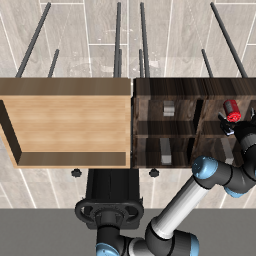



Figure 2: Three evaluation tasks (Lift, PickPlaceCan, Stack) visualized at initialization, grasp, and post-task—demonstrating AOR’s phase-by-phase trajectory optimization.
Comparative Analysis and Claims
The primary claim of AOR is architectural: the expressiveness and interpretability of “policy as code” unlock deeper in-context learning than other in-context LLM agent paradigms:
- Fine-grained diagnosis: The agent can attribute failure to specific lines or architectural modules (e.g., vision back-projection bugs, segmentation logic flaws), which would be silent in gradient-based learning.
- Architectural modification: Beyond parameter tuning, AOR enables reorganization of controller phases, introduction of new geometric corrections, or entirely new approaches to feature extraction—all discovered through episode-level feedback.
- Feedback depth: Leveraging visual and structured episodic data allows causal, rather than associative, diagnosis, fundamentally improving the sample efficiency of controller correction.
The quantitative results are competitive with demonstration- and RL-based methods for these tasks—but with the highly constraining assumption of zero demonstrations, no reward engineering, and no gradient updates.
Limitations and Failure Modes
While AOR autonomously surfaced and resolved several subtle issues (e.g., OpenGL vs. OpenCV camera axis inconsistencies), the search process is local and myopic. For Stack, the agent did not exhaustively explore placement strategies to avoid final gripper-cube collisions, resulting in plateaued performance. The framework is currently simulation-only; real-world deployment would necessitate enhanced uncertainty management and likely more robust perception techniques.
The performance of the framework is contingent on the coding agent’s reasoning capabilities; Codex, for example, failed to solve the simplest tasks, indicating substantial reliance on high-quality code LLMs.
Implications and Future Directions
AOR demonstrates that policy as code, iteratively synthesized via reflection on multimodal trial outcomes, is a viable path for closed-loop robot learning—bridging program synthesis and physical control. Its strengths are interpretability, modularity, and fine-grained diagnosis, making it well-suited not only to rapid prototyping but also to real-time debugging of existing policies.
Potential extensions include:
- Prompt steering to elicit non-classical, modern perception or control strategies from the LLM, rather than classical color-segmentation and phase-based state machines.
- Fusion with vision-language-action (VLA) foundation models for prior-based adaptation and combining sub-goal selection with low-level reflexion.
- Parallelized hypothesis generation to accelerate iteration and explicit mechanisms for diversity in controller proposals.
- Formal characterization of convergence and sample complexity for various classes of failure modes.
Conclusion
AOR delineates a distinct regime in robot learning design, relying on multimodal policy code synthesis via LLM-driven reflection over trial outcomes. Its in-context improvement capabilities match or exceed LLM-based symbolic strategy revision frameworks in scope, while affording deeper diagnosis and adaptation for geometric and code-level errors. The results suggest that as code-driven LLMs and multimodal reasoning advance, frameworks like AOR will become prominent tools for scalable, interpretable, and adaptive physical AI system deployment.