RoboMME: Benchmarking and Understanding Memory for Robotic Generalist Policies
Abstract: Memory is critical for long-horizon and history-dependent robotic manipulation. Such tasks often involve counting repeated actions or manipulating objects that become temporarily occluded. Recent vision-language-action (VLA) models have begun to incorporate memory mechanisms; however, their evaluations remain confined to narrow, non-standardized settings. This limits their systematic understanding, comparison, and progress measurement. To address these challenges, we introduce RoboMME: a large-scale standardized benchmark for evaluating and advancing VLA models in long-horizon, history-dependent scenarios. Our benchmark comprises 16 manipulation tasks constructed under a carefully designed taxonomy that evaluates temporal, spatial, object, and procedural memory. We further develop a suite of 14 memory-augmented VLA variants built on the π0.5 backbone to systematically explore different memory representations across multiple integration strategies. Experimental results show that the effectiveness of memory representations is highly task-dependent, with each design offering distinct advantages and limitations across different tasks. Videos and code can be found at our website https://robomme.github.io.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (the big idea)
This paper introduces RoboMME, a large set of robot tasks (a “benchmark”) designed to test how well robots can remember things while doing jobs. The authors also build and compare many robot control models to see which kinds of “memory” help most. The goal is to make robots better at long, multi-step tasks that require remembering what happened before—like counting how many times they did something, tracking where an object moved, recognizing a specific item later, or copying a movement they saw in a video.
What questions the paper tries to answer
The paper focuses on a few simple questions:
- What kinds of memory do robots need for everyday tasks?
- How can we add memory to robot control systems?
- Which memory styles work best for different kinds of tasks?
- Is there a single best memory method, or do different tasks need different memory tools?
How the researchers approached the problem (in everyday terms)
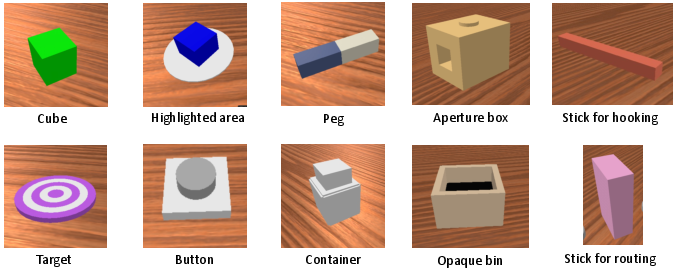
First, they built a “test course” for robots called RoboMME. Think of this like a video game level pack for a robot arm with 16 different challenges. Each challenge is designed to test a specific type of memory:
- Temporal memory (remembering “when”): For example, “move this cube exactly three times” or “press the button on the third pass.”
- Spatial memory (remembering “where”): For example, “track the location of a cube even when it’s hidden or swapped with another.”
- Object memory (remembering “what”): For example, “pick the same cube that was highlighted earlier” or “follow a clue from a video or a sentence to pick the right target.”
- Procedural memory (remembering “how”): For example, “copy a motion you saw in a video, like tracing a pattern or inserting a peg in a box.”
They recorded 1,600 example demonstrations (good solutions) for these tasks, totaling about 770,000 time steps, so their robot models could learn and be fairly tested.
Then, they tested different ways to give robots memory using a popular robot brain called a “Vision-Language-Action” model (VLA). A VLA model:
- sees camera images (vision),
- reads instructions (language),
- and outputs movements (action).
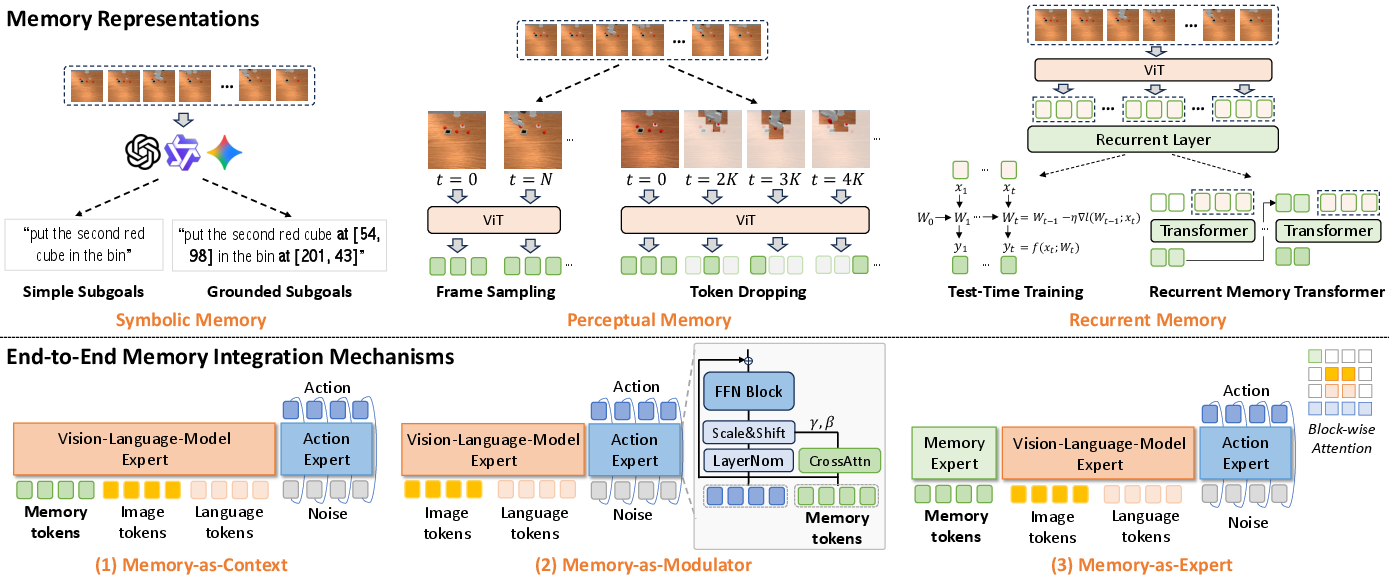
They tried three main “memory styles”:
- Symbolic memory: the robot uses short, human-like notes (tiny sentences) to remember what to do next, like “pick up the green cube” or “go to the second target.” Think of it as a to-do list written in plain language.
- Perceptual memory: the robot stores small snapshots of recent images (not full pictures, just compact features) so it can look back at what it saw before.
- Recurrent memory: the robot compresses the past into a small internal state (like a backpack of clues that gets updated every step).
They also tested three ways to plug memory into the robot brain:
- Memory-as-context: just stick the memory onto the inputs and process everything together.
- Memory-as-modulator: use memory to gently “tune” the robot’s inner layers (like adjusting dials) so it reacts differently based on what it remembers.
- Memory-as-expert: add a small extra pathway focused on memory that talks to the main action pathway.
Finally, they compared lots of combinations to see what works best on each task.
What they found and why it matters
Here are the key findings, explained simply:
- There is no one-size-fits-all memory. Different tasks need different memory tools.
- Perceptual memory (storing compact visual history) was the best overall, especially when used with the “modulator” approach. This combo reached about 45% average success across the 16 challenging tasks—better than the other designs tested.
- Symbolic memory (short language subgoals) was great for counting and shorter tasks where clear steps can be written down, but it struggled when precise movements or timing were critical.
- Recurrent memory (tiny internal state) didn’t work as well in their setup, likely because it needed deeper changes or stronger pretraining to shine.
- A human study (with high-level choices handled by people and perfect low-level robot control) scored about 90.5%, showing the tasks are challenging even for humans when memory and attention are tested over long sequences.
- In real robot tests (not just simulation), the same pattern held: symbolic memory did best on counting; perceptual memory did best on motion-heavy tasks like drawing a pattern.
Why this matters: For robots to be truly helpful at home, in factories, or in labs, they need to remember what happened before—just like people do. This paper shows which memory tools to use for different jobs and provides a standard test set so the research community can measure progress fairly.
What this means for the future
- Benchmarks like RoboMME help everyone test ideas on the same tough tasks, speeding up progress.
- Since no single memory method wins everywhere, future robots will likely combine multiple memory types (language notes for planning, visual history for details, and possibly improved recurrent states) to get the best of all worlds.
- The researchers suggest expanding beyond tabletop arms to mobile robots and trying more base models and memory-bank methods.
- As these tools improve, we can expect robots to handle longer, more complex, and more realistic jobs without forgetting crucial steps.
A quick guided tour of the four task suites (with examples)
To make the differences clear, here are the four suites with simple examples:
- Counting (temporal memory): “Move the green cube back and forth three times” or “Press the button the third time the cube arrives.”
- Permanence (spatial memory): “Find the blue cube after it was hidden or swapped with another—like the classic cup-and-ball trick.”
- Reference (object memory): “Pick the exact cube that was highlighted earlier” or “Place the cube on the target that comes after the button press mentioned in the video/instruction.”
- Imitation (procedural memory): “Copy a demonstrated motion, such as inserting a peg or tracing a pattern.”
Together, these cover the big questions: when, where, what, and how—just like how people use memory in everyday life.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored based on the paper. Each point is phrased to guide concrete follow-up work.
- Benchmark scope is limited to tabletop, single-arm Franka manipulation with fixed assets and two RGB cameras; there is no evaluation on mobile manipulation, multi-arm coordination, deformable objects, or human–robot interaction scenarios.
- Sensory modalities are restricted to RGB and proprioception; the impact of depth, tactile, audio, force/torque, or event cameras on memory formation and use is not studied.
- Scene variability and realism are constrained (e.g., static lighting/camera extrinsics, limited clutter distributions); robustness to real-world visual shifts (lighting, motion blur, occlusions from humans) is not assessed.
- Tasks emphasize short- to mid-horizon single-episode memory; cross-episode long-term memory (episodic memory across days/tasks) and semantic memory acquisition are not evaluated.
- The benchmark blends memory types within suites only sparsely (e.g., O+T in some tasks); there is no “all-four-at-once” suite to stress simultaneous temporal, spatial, object, and procedural memory demands.
- Numeric generalization in Counting is unclear: whether policies extrapolate to counts outside the training range, variable timing, or changing dynamics (e.g., different cube velocities in StopCube) is not tested.
- Spatial memory tasks focus on occlusion and swaps for simple rigid objects; tracking under heavy clutter, similar-object distractors, deformable motion, and 3D rearrangements (including camera motion) remains unexplored.
- Object memory does not probe linguistic ambiguity, coreference resolution over long dialogues, cross-lingual instructions, or compositional references (e.g., “the cube moved second after the first press” combined with spatial qualifiers).
- Procedural memory is evaluated on a few canonical motion patterns; generalization to longer, more complex multi-stage skills and tool-use with changing tool morphology is not addressed.
- Data are generated via replay of keyframe waypoints with only 5% noise and only successful trajectories retained; the resulting covariate shift vs. real execution errors and the role of on-policy data aggregation (e.g., DAgger) are not explored.
- Imitation learning is the sole training paradigm; the potential of reinforcement learning, offline RL, or hybrid IL+RL to acquire memory from sparse success signals is left open.
- Memory-specific metrics are absent; beyond success rate, no task-specific measures of memory fidelity (e.g., counting accuracy over time, identity recall accuracy under occlusion, trajectory reproduction error) are reported.
- The study fixes a 512-token memory budget for fairness but does not characterize memory–performance scaling beyond this cap or explore adaptive memory allocation/forgetting policies.
- Perceptual memory uses simple token selection (uniform sampling or RGB-difference dropping); learned retrieval, compressive/retentive transformers, clustering-based selection, or saliency-driven tokenization are not evaluated.
- Recurrent memory underperforms substantially; the paper hypothesizes architectural/pretraining causes but does not test deeper recurrence, long-sequence pretraining, or alternative state-space/SSM variants (e.g., RWKV, Gated Mamba, compressive memory).
- Proprioceptive histories are excluded from perceptual memory by design; whether including proprioception/action histories improves time-sensitive or contact-rich tasks is not studied.
- Integration mechanisms are limited to context concatenation, AdaLN modulation, and a separate expert; comparisons with FiLM-style conditioning, gating, adapter-based routing, or hierarchical controllers are missing.
- Symbolic memory relies on subgoal annotations and auxiliary VLMs; scalability to domains without subgoal supervision, robustness of subgoal generators to domain shift, and training with noisy/ambiguous subgoals are open issues.
- Oracle subgoals create an upper bound but are not realizable in practice; the gap between oracle and learned subgoal generators is not dissected to pinpoint primary failure modes (grounding errors vs. language generation vs. control).
- Comparability across methods may be uneven: methods using external VLMs incur extra compute and may leverage more supervision; a normalized evaluation of supervision cost vs. performance is not provided.
- Efficiency is reported in TFLOPs, but real-time latency, memory footprint, and throughput on robot hardware are not measured; end-to-end wall-clock constraints for closed-loop control remain unclear.
- Human evaluation reformulates tasks as VideoQA with an oracle motion planner; how humans perform with full low-level control (including dexterity and timing constraints) is unknown.
- Real-world validation uses 4 tasks with 10 trials each and a single robot; broader sim-to-real generalization across robots, sensors, grippers, and environments is not established.
- Robustness to instruction perturbations (synonyms, paraphrases, noisy grammar), unseen object colors/shapes, and novel task compositions is not systematically tested.
- Failure analysis is limited; there is no taxonomy of memory-specific errors (e.g., miscounting vs. identity swaps vs. premature forgetting) or diagnostics to probe what the model stores/forgets.
- Memory interference in multi-task training is not assessed; whether tasks with different memory demands cause negative transfer or catastrophic forgetting remains open.
- Combining memory types is suggested but not implemented; concrete architectures for hybrid symbolic–perceptual–recurrent memory (e.g., dynamic routing, learned memory arbitration) are not explored.
- Online memory management is static; methods to learn when to write, read, compress, or discard memory (and how to schedule VLM inferences) are not investigated.
- Alternative action parameterizations (e.g., delta EEF, force/impedance control) and their interaction with memory for precise, time-critical tasks are not studied.
- Benchmark adoption details (code/data availability, reproducibility protocols, licensing) are not discussed; community standardization around memory diagnostics is left open.
- Safety and robustness aspects (e.g., memory poisoning, resilience to adversarial frames/subgoals, failure recovery policies) are not considered.
- Interaction with external world models or maps (e.g., 3D scene graphs, object-centric memory, NeRF/SDF-based persistent maps) is not examined as a route to longer-horizon spatial memory.
- The impact of alternate VLA backbones (e.g., RT-X, Octo, diffusion policies) on memory integration efficacy is untested; conclusions may be backbone-specific.
- Generalization to dynamic-human and multi-agent settings (requiring tracking and remembering human actions/intentions) is not part of the benchmark.
- The role of curriculum, data scale, and pretraining on memory-intensive corpora (e.g., long egocentric videos) in improving memory performance is not analyzed.
Practical Applications
Immediate Applications
The following applications can be deployed with current methods and tooling described in the paper, often with moderate engineering and integration effort.
- Memory-aware benchmarking and model selection for deployed robots
- Sectors: Robotics, Manufacturing, Warehousing, Software (R&D/QA)
- What: Use RoboMME to systematically evaluate candidate VLA policies (e.g., FrameSamp+Modul for perceptual memory, GroundSG for symbolic) against task-specific memory demands (temporal, spatial, object, procedural).
- Tools/Workflows:
- Adopt RoboMME’s 16-task suite and success metrics to compare internally developed policies.
- Establish regression tests and acceptance criteria focused on memory-dependence (e.g., time-sensitive vs. motion-centric tasks).
- Assumptions/Dependencies: Requires access to simulation (ManiSkill), pi_0.5-compatible policies, and training/inference compute; transferability depends on similarity between benchmark tasks and production tasks.
- Counting and short-horizon control via symbolic subgoals
- Sectors: Warehousing, Retail Fulfillment, Service/Home Robotics, Hospitality
- What: Execute tasks with discrete repetition/ordering (e.g., “place N items,” “wipe X passes”) using symbolic memory (e.g., GroundSG with subgoals).
- Tools/Products:
- Lightweight subgoal generators (e.g., fine-tuned Qwen3-VL-based SimpleSG/GroundSG) integrated with a VLA controller.
- Workflows that combine language instructions with grounded coordinates for precise manipulation.
- Assumptions/Dependencies: Subgoal generation requires task-specific annotations or fine-tuning; performance degrades in cluttered scenes or under grounding errors; may need fallback policies for ambiguous visual scenes.
- Motion-centric skill reproduction from demonstrations
- Sectors: Manufacturing (assembly, handling), Facilities (cleaning), Education/Training
- What: Use perceptual memory with memory-as-modulator (e.g., FrameSamp+Modul) to reproduce demonstrated motion patterns (e.g., linear/circular trajectories, peg insertions).
- Tools/Products:
- Programming-by-demonstration “pattern player” for robots to follow learned paths (Imitation suite tasks).
- Video-conditioned initialization at episode start to bootstrap trajectories.
- Assumptions/Dependencies: Requires high-quality demonstrations and consistent sensing; low-level control accuracy (contact, orientation) remains a bottleneck for precise insertions; camera viewpoints should match training setup.
- Occlusion-robust object tracking and retrieval
- Sectors: Warehousing, Hospitality, Home Robotics
- What: Track objects through occlusion and dynamic scene changes (e.g., swaps) using spatial-memory-focused policies; symbolic methods with grounding or hybrid (MemER-like) approaches help when identity and location must persist.
- Tools/Workflows:
- Combine keyframe buffers and symbolic subgoals for long visual histories (as in MemER); or deploy FrameSamp+Modul for end-to-end perceptual memory.
- Assumptions/Dependencies: Performance depends on viewpoint coverage, calibration, and visual token budget; external VLM pipelines increase latency and cost; clutter and identical objects can still confuse policies.
- Memory-focused QA and procurement protocols
- Sectors: Robotics Vendors/Buyers (Industrial, Logistics, Consumer)
- What: Incorporate RoboMME tasks into vendor benchmarks and procurement checklists to verify memory competencies (e.g., time-critical counting, occlusion tracking, imitation accuracy).
- Tools/Workflows:
- Acceptance thresholds per memory category (temporal/spatial/object/procedural), measured on standard tasks.
- Efficiency-performance trade-off audits (TFLOPs vs. success rate) to ensure real-time viability.
- Assumptions/Dependencies: Requires standardization of task seeds and scoring; tests may need adapters for different hardware form factors.
- Memory-aware MLOps and runtime optimization
- Sectors: Software, Robotics Platforms
- What: Integrate memory budgets, caching, and fallback strategies into deployment stacks to balance performance and latency (e.g., reduce VLM calls; reuse visual tokens).
- Tools/Workflows:
- Telemetry for token budgets and memory utilization; scheduled or event-triggered subgoal inference; token reuse to avoid redundancy.
- Assumptions/Dependencies: On-device acceleration and caching frameworks; careful monitoring to prevent stale-memory errors.
- Research, education, and reproducibility
- Sectors: Academia, Corporate Research Labs, EdTech
- What: Use RoboMME to teach and evaluate memory in robotic manipulation; run controlled ablations of memory representations and integration mechanisms on a common backbone.
- Tools/Workflows:
- Course modules centered on the four memory suites; baseline code with pi_0.5; standardized evaluation for publications.
- Assumptions/Dependencies: Availability of compute and simulator; students may need simplified subsets of tasks for coursework.
- Real-world service tasks aligned with demonstrated transfer
- Sectors: Healthcare Logistics, Facilities, Retail Ops, Home Robotics
- What: Deploy best-performing memory setups per task type, as shown in real-world experiments: symbolic for counting (e.g., stocking items), perceptual for motion-centric (e.g., drawing/cleaning patterns), mixed approaches for object re-pick and tracking.
- Tools/Products:
- Robot workflows mapping to PutFruits, TrackCube, RepickBlock, DrawPattern; demonstration capture kits; safety wraps for contact tasks.
- Assumptions/Dependencies: Compliance and safety constraints in healthcare; consistent sensors and well-calibrated kinematics; domain-specific demos and validation.
Long-Term Applications
These applications require further research, scaling, or engineering beyond the current results.
- Hybrid, adaptive memory systems that combine symbolic, perceptual, and recurrent memory
- Sectors: Robotics (cross-domain), Software Platforms
- What: Runtime policies that switch or blend memory designs based on task characteristics (event-salient vs. time-sensitive vs. motion-centric), integrating symbolic subgoals with long-history visual tokens and stable recurrence.
- Tools/Products:
- Memory “routers” selecting integration mechanisms (context/modulator/expert) on the fly; adaptive token budgets.
- Assumptions/Dependencies: Better training curricula and robust orchestration across memory types; improved interpretability to avoid unexpected behaviors.
- Mobile manipulation with long-horizon tasks in dynamic, unstructured environments
- Sectors: Home Robotics, Field Service, Hospitality, Retail
- What: Extend RoboMME principles beyond tabletop Franka Panda to mobile platforms (navigation + manipulation) that require cross-room memory and persistent referential identity under heavy occlusion.
- Tools/Products:
- Integrated nav-manip pipelines with memory-as-modulator in the control stack; long video conditioning across episodes.
- Assumptions/Dependencies: Sensor fusion (RGB-D, LiDAR), spatial memory maps, reliable tracking under motion blur and lighting changes.
- Standards and certification for “memory competence” in consumer/industrial robots
- Sectors: Policy/Regulation, Industry Consortia, Procurement
- What: Define graded memory competency levels across temporal/spatial/object/procedural dimensions for certification and safety audits.
- Tools/Workflows:
- Public test suites derived from RoboMME; reporting on efficiency-performance trade-offs; scenario libraries (time-critical, occlusion-heavy, long-horizon).
- Assumptions/Dependencies: Multi-stakeholder adoption; test reproducibility across vendors; safety cases linking memory failures to risk.
- Hardware–software co-design for efficient memory processing
- Sectors: Robotics Hardware, Edge AI, Semiconductors
- What: Accelerators and system designs optimized for visual token processing and AdaLN-based modulation, plus low-latency on-device VLM inference when symbolic subgoals are needed.
- Tools/Products:
- Memory-token encoders, cache hierarchies for frame sampling; energy-aware schedulers for hybrid memory stacks.
- Assumptions/Dependencies: Hardware availability; quantization/pruning techniques tailored for memory-rich vision encoders and fusion layers.
- Pretrained recurrent memory backbones for real-time, very-long-horizon control
- Sectors: Robotics, Autonomous Systems
- What: Develop deeply integrated recurrent models (e.g., Mamba-style SSMs) pre-trained for long-horizon manipulation to overcome instability seen with shallow recurrence.
- Tools/Workflows:
- Large-scale pretraining on long, diverse teleoperation and simulation logs; recurrent adapters compatible with VLA experts.
- Assumptions/Dependencies: Substantial datasets, compute, and careful optimization to ensure stability and generalization.
- Agentic pipelines with scheduled subgoal inference and uncertainty-aware control
- Sectors: Software (Agent Frameworks), Robotics Platforms
- What: Orchestrate VLM-based subgoal generation at event boundaries or when model uncertainty spikes; interleave symbolic planning with end-to-end visuomotor control.
- Tools/Products:
- Uncertainty monitors triggering VLM calls; keyframe buffers; cost-aware planners balancing inference latency with task success.
- Assumptions/Dependencies: Reliable uncertainty estimation; robust failure recovery; safety layers to manage incorrect subgoals.
- Digital twins and memory-centric simulation-to-real validation
- Sectors: Manufacturing, Facilities, Smart Buildings
- What: Use simulated replicas of workcells/homes (digital twins) to stress-test memory under occlusions, swaps, and long-horizon procedures before deployment.
- Tools/Workflows:
- Scenario generators mimicking benchmark suites; automated comparison of memory budgets and throughput vs. KPI success.
- Assumptions/Dependencies: High-fidelity twins reflecting real dynamics; sim2real gap minimization via domain randomization and calibration.
- Memory-aware safety and interpretability tooling
- Sectors: Safety/Compliance, QA, DevOps
- What: Instrumentation to visualize which memory tokens/subgoals drive actions (e.g., saliency over history), detect hallucinated references, and enforce safety constraints when memory is unreliable.
- Tools/Products:
- Token-level attribution dashboards; watchdogs that pause or simplify actions when confidence drops; policy verification suites.
- Assumptions/Dependencies: Reliable introspection hooks in VLA models; human-in-the-loop oversight and escalation paths.
- Data generation and augmentation services for memory-demanding tasks
- Sectors: Data Platforms, Robotics Integrators
- What: Services that produce high-quality demonstrations with controlled perturbations (as in RoboMME) to enrich failure recovery and long-horizon dependencies.
- Tools/Products:
- Synthetic occlusion and swap scenarios; scripted curricula across memory types; continuous dataset updates for new environments.
- Assumptions/Dependencies: Access to simulators and task authoring tools; careful curation to avoid overfitting to synthetic artifacts.
- Domain-specific benchmark extensions (e.g., healthcare, maintenance)
- Sectors: Healthcare, Energy/Utilities, Construction
- What: Extend RoboMME-style tasks to domain-critical procedures (e.g., cleaning/sterilization passes, tool use around sensitive equipment, multi-step inspections) emphasizing memory.
- Tools/Workflows:
- Task suites with regulatory context; role-based acceptance tests (e.g., sterilization cycles counted correctly).
- Assumptions/Dependencies: Regulatory approval, safety engineering, and collaboration with domain experts; stringent failure handling and logging.
Cross-cutting Assumptions and Dependencies
- Sensor and calibration quality: Multi-view RGB and accurate proprioception are crucial for memory-driven policies; degraded sensing reduces performance.
- Task similarity: Performance and transferability are higher when deployment tasks align with benchmarked memory demands.
- Compute and latency budgets: Perceptual memory scales well with token budgets; VLM-driven symbolic pipelines add latency/cost unless carefully scheduled and cached.
- Low-level control reliability: Memory helps choose the right high-level action, but precise contact and motion execution remain limiting factors for tasks like insertions.
- Data availability: High-quality demonstrations (including perturbations and recovery) significantly improve imitation and robustness.
- Safety and compliance: Especially in healthcare and public spaces, memory-induced errors (miscounts, misidentification) must be mitigated via monitoring and fail-safes.
Glossary
- Action expert: The branch of a multi-expert policy responsible for producing action outputs, often conditioned by other modules or memories. "action expert"
- Adaptive LayerNorm (AdaLN): A conditioning mechanism that modulates normalized features with learned scale and shift parameters based on external context. "adaptive LayerNorm (AdaLN)"
- Block-wise causal attention: An attention pattern that restricts information flow by blocks and respects causal (past-to-future) ordering between components. "block-wise causal attention"
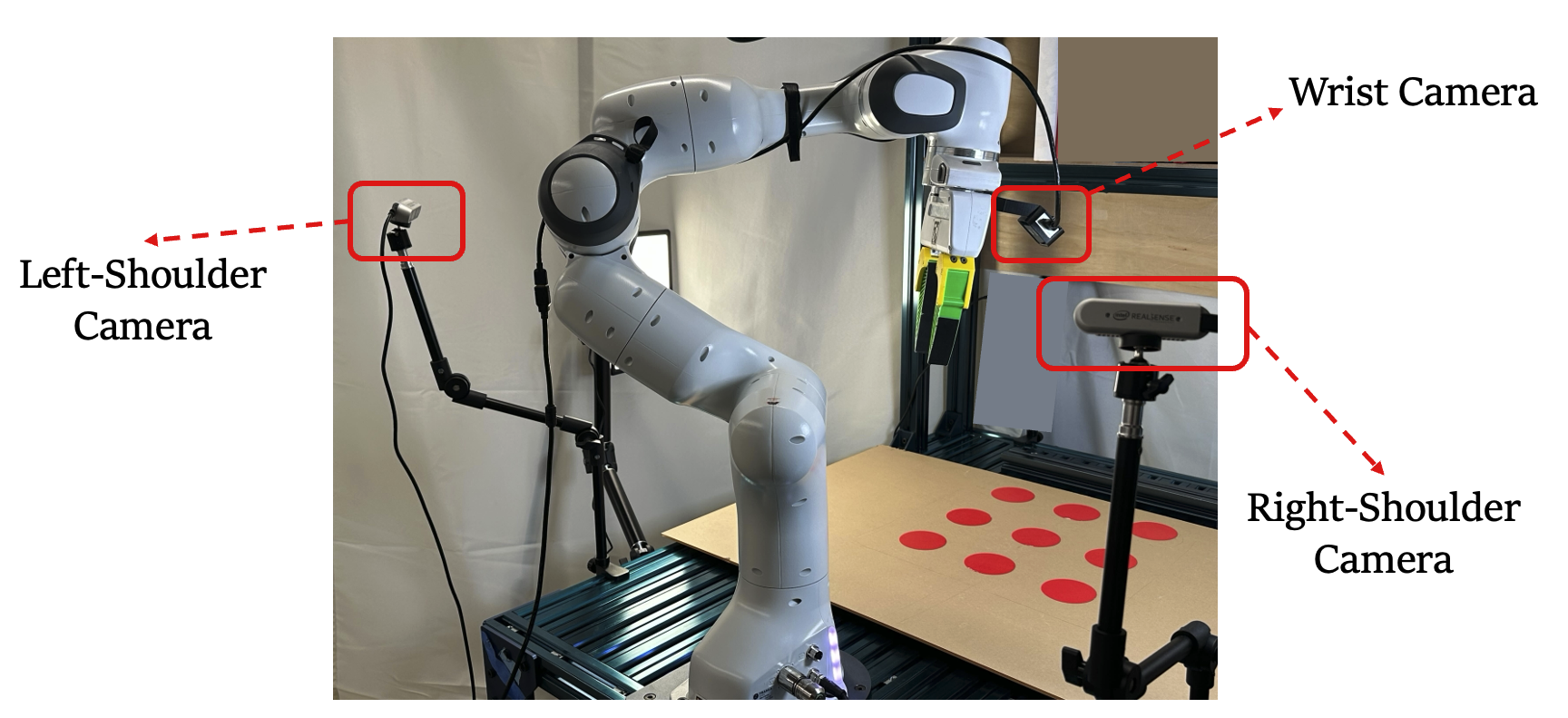
- Degrees of freedom (7-DOF): The number of independent joint variables of a robot arm; 7-DOF allows complex positioning and orientation control. "a 7-DOF Franka Panda arm."
- Domain shift: A mismatch between training and test distributions that degrades model performance. "suffers from domain shift"
- End-effector (EEF): The robot’s terminal tool or gripper whose pose defines its position and orientation in space. "end-effector (EEF) pose"
- Euler orientation: A representation of 3D orientation using Euler angles (roll, pitch, yaw). "Euler orientation"
- External motion planner: A separate planning module that converts high-level actions into precise low-level trajectories. "executed by an external motion planner"
- Fast weights: Quickly updated parameters used at inference to adapt a model online. "updates fast weights online"
- Franka Panda: A commonly used 7-DOF robotic manipulator platform. "Franka Panda arm"
- Grounded subgoal: A language subgoal augmented with explicit spatial grounding (e.g., pixel coordinates). "grounded subgoal and keyframe annotations"
- Keyframe images: Selected frames stored as salient snapshots to support memory and reasoning over time. "keyframe images"
- Keyframe waypoints: Predefined important waypoints used to generate or replay demonstration trajectories. "predefined keyframe waypoints"
- Learnable memory slots: Parameterized vectors that store and update compressed sequence information across segments. "learnable memory slots"
- Long-horizon: Tasks or behaviors spanning many steps that require extended temporal reasoning. "long-horizon tasks"
- ManiSkill: A simulation platform for robotic manipulation research and dataset construction. "ManiSkill simulator"
- Mamba-style state-space models: Sequence models that use state-space formulations (in the Mamba family) to capture long-range dependencies efficiently. "Mamba-style state-space models"
- Memory-as-context: An integration strategy that concatenates memory tokens with inputs for joint processing. "memory-as-context"
- Memory-as-expert: An integration strategy that adds a dedicated memory-processing expert interacting with other experts through constrained attention. "memory-as-expert"
- Memory-as-modulator: An integration strategy that conditions action computations by modulating internal activations using memory-derived signals. "memory-as-modulator"
- Memory bank: A cache of feature embeddings from past observations for later retrieval. "memory banks"
- Memory budget: The fixed capacity (e.g., token count) allocated to store or process memory per step. "we fix a memory budget of 512 tokens"
- Multi-head attention: An attention mechanism with multiple parallel heads to capture diverse relationships in the data. "via multi-head attention"
- Non-Markovian: A setting where the current observation is insufficient; decisions depend on history. "non-Markovian"
- Object memory: The ability to preserve object identity and references over time across different contexts. "object memory"
- Occlusion: Temporary hiding of objects from view, complicating tracking and recall. "under occlusion"
- Partial observability: A condition where the agent cannot access the full state of the environment from current observations alone. "partial observability"
- Perceptual memory: Differentiable representations of history using visual or multimodal features. "perceptual memory"
- Procedural memory: Memory for motor skills and action patterns learned through demonstration or practice. "procedural memory"
- Proprioceptive states: Internal robot states such as joint angles and gripper status used alongside vision. "proprioceptive states"
- Prompt engineering: Crafting prompts to guide large models’ behavior without task-specific fine-tuning. "prompt-only Gemini suffers from domain shift and often predicts incorrect labels, further reducing performance."
- Recurrent Memory Transformers (RMT): Transformers that process sequences in segments and recurrently update memory slots. "Recurrent Memory Transformers (RMT)"
- Recurrent memory: A compact latent state that is iteratively updated to summarize history. "recurrent memory"
- Self-supervised loss: A training objective that does not require labeled targets, often used for adaptation at test time. "self-supervised loss"
- Spatial memory: Memory for object locations and spatial relationships, especially under changing scenes. "spatial memory"
- Symbolic memory: Non-differentiable, interpretable summaries of history (e.g., language subgoals). "symbolic memory"
- Temporal memory: Memory of event counts, orderings, and temporal dependencies. "temporal memory"
- Test-Time Training (TTT): Online adaptation during inference using an auxiliary loss to improve performance. "Test-Time Training (TTT)"
- TFLOPs: Trillions of floating-point operations, used to measure computational cost. "the TFLOPs of a single forward pass"
- Token dropping: A strategy to prune redundant visual tokens from history based on change metrics. "token dropping"
- Uniform frame sampling: Evenly downsampling a video sequence and concatenating tokens from sampled frames. "uniform frame sampling"
- Vision-language-action (VLA): Models that map visual and language inputs to control actions. "vision-language-action (VLA) models"
- Vision-LLM (VLM): Models that jointly process images and text for perception and reasoning. "vision-LLM (VLM)"
- Visual tokens: Patch-level embeddings produced by vision encoders that represent images. "visual tokens"
- VideoQA: Video question answering, where agents answer questions based on video content. "VideoQA problem"
Collections
Sign up for free to add this paper to one or more collections.

