Replaying pre-training data improves fine-tuning
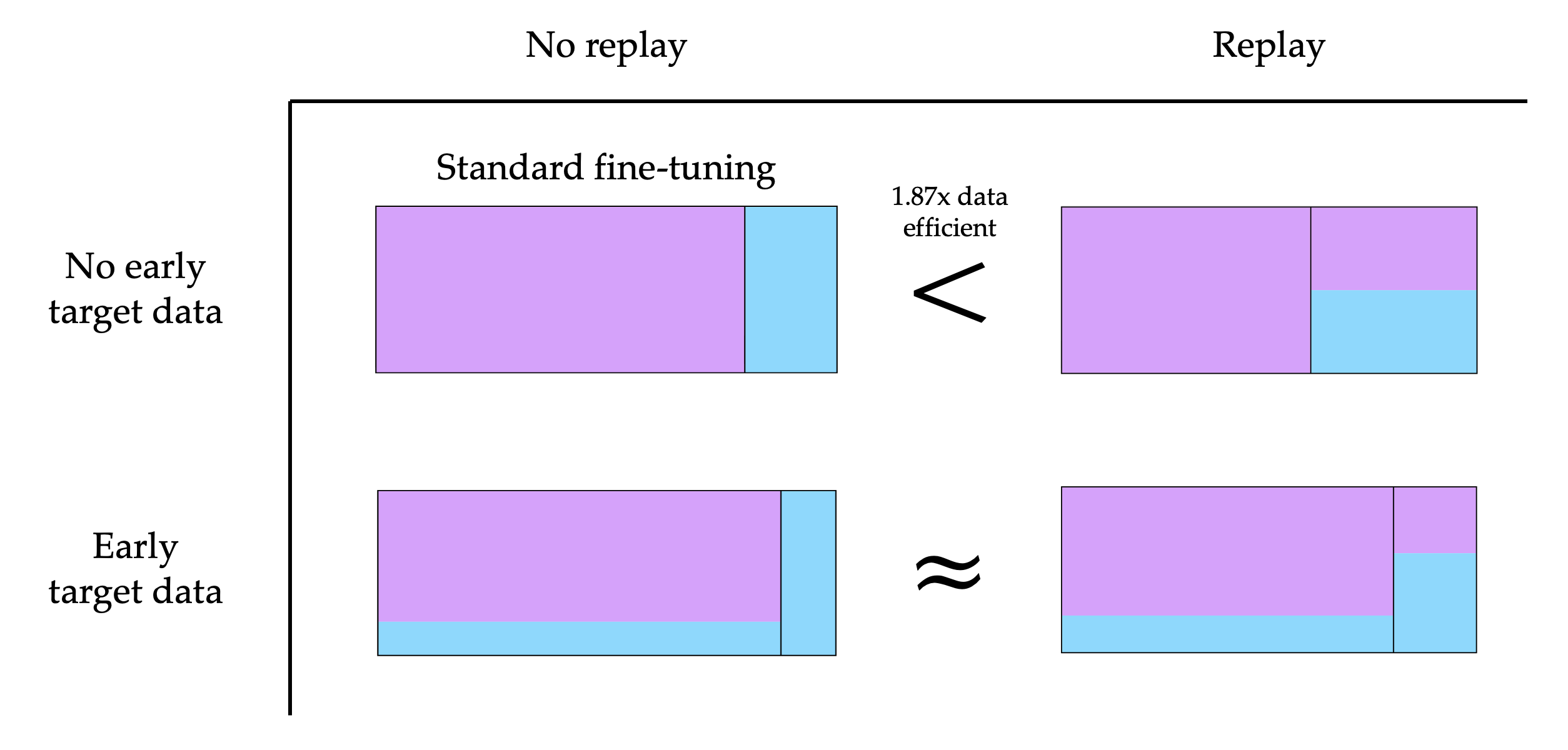
Abstract: To obtain a LLM for a target domain (e.g. math), the current paradigm is to pre-train on a vast amount of generic web text and then fine-tune on the relatively limited amount of target data. Typically, generic data is only mixed in during fine-tuning to prevent catastrophic forgetting of the generic domain. We surprisingly find that replaying the generic data during fine-tuning can actually improve performance on the (less related) target task. Concretely, in a controlled pre-training environment with 4M target tokens, 4B total tokens, and 150M parameter models, generic replay increases target data efficiency by up to $1.87\times$ for fine-tuning and $2.06\times$ for mid-training. We further analyze data schedules that introduce target data during pre-training and find that replay helps more when there is less target data present in pre-training. We demonstrate the success of replay in practice for fine-tuning 8B parameter models, improving agentic web navigation success by $4.5\%$ and Basque question-answering accuracy by $2\%$.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big idea)
The paper asks a simple question: when you’re training a LLM for a special task (like math, coding, or following instructions), is it better to only practice that special task at the end, or should you keep mixing in some general reading too?
Surprisingly, the authors find that mixing in some “generic” data (ordinary web text) during the final practice actually helps the model do better on the special task. This makes the training more “data‑efficient,” meaning the model needs fewer special examples to reach the same level of skill.
What questions they asked
In clear terms, the researchers wanted to know:
- If you add some general web text while fine-tuning on a specific task, will the model perform better on that task?
- Does the best plan change if you can also adjust what happens earlier in training, not just at the end?
- How much does the benefit depend on how much special-task data the model saw earlier?
- Do these ideas still help bigger, more realistic models (not just small ones)?
What they did (how they tested it)
Think of training a model like studying for school:
- Pre-training = reading lots of general material (like a huge textbook).
- Fine-tuning = practicing a smaller set of focused problems (like math worksheets or coding exercises).
Here’s their approach, in everyday terms:
- They trained small models (150 million parameters) on:
- A very large pool of general web text (called C4).
- A small pool of target data (one of three: math problems “FineMath,” code “StarCoder,” or instruction-following “Flan”).
- Usually, the standard plan is “all general first, then all target.” They tried different “study schedules,” especially:
- Mixing some general data back in during the final target practice. They call this “replay” (because you’re replaying the earlier kind of data).
- Moving some target practice earlier in training as well, not only at the end.
They measured success using “validation loss” on the target task, which you can think of as “how wrong the model is on a test it hasn’t seen before.” Lower is better.
They also tried this idea on a much larger model (Llama 3.1–8B) for two real tasks:
- Web navigation for a digital assistant.
- Learning Basque (a low‑resource language).
A few terms in plain language:
- Replay: mixing in some general reading while you’re doing your final focused practice.
- Data efficiency: how many special examples you’d need to reach a certain score. If a method is 2× more data‑efficient, you’d need only half as many special examples to do just as well.
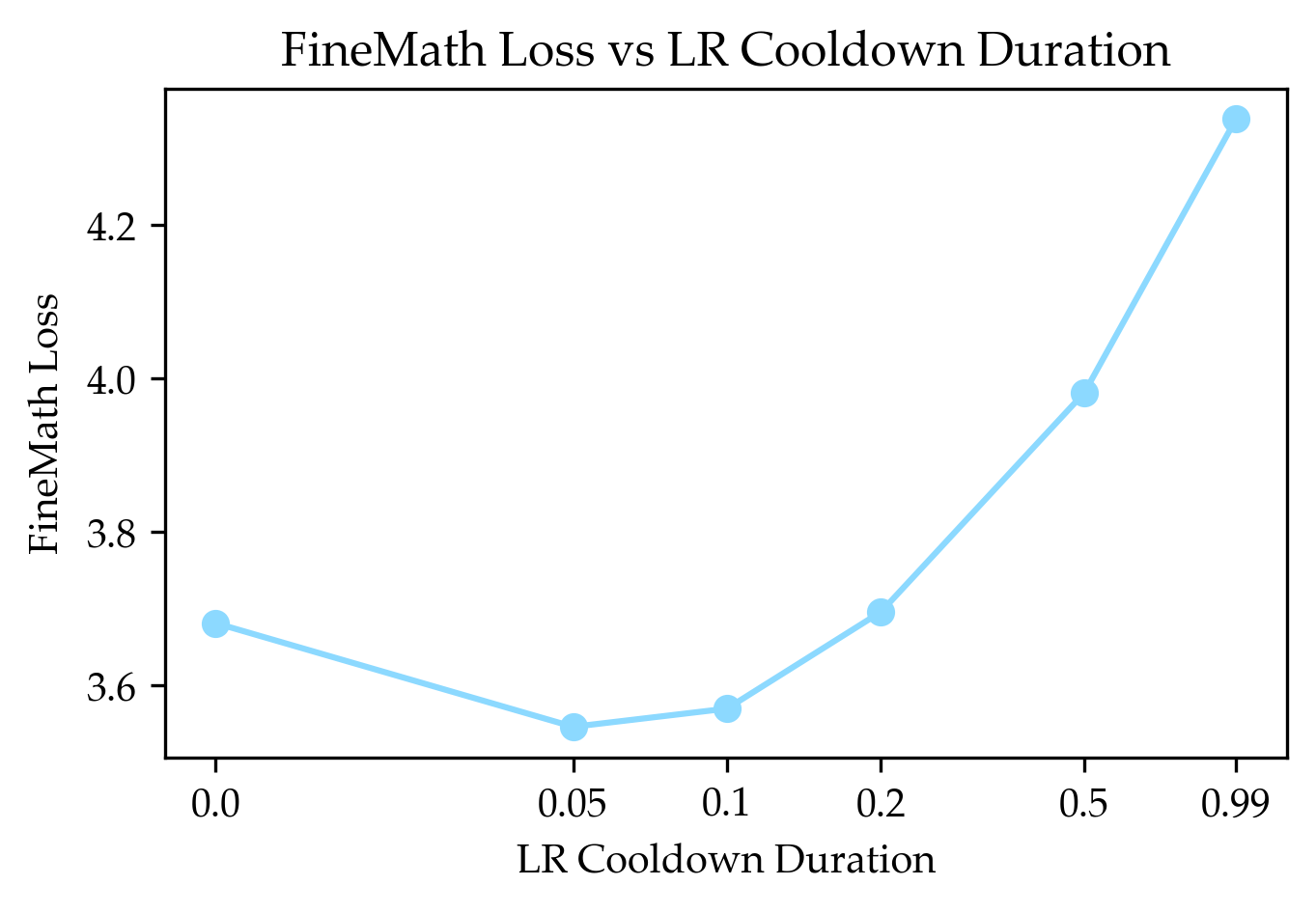
- Learning rate (and WSD schedule): learning rate is like how fast you’re trying to learn from each example. WSD means “Warm up → Cruise at a steady pace → Cool down quickly at the end.” Placing the most important target data during that final “cool down” can give a boost.
What they found (main results)
Here are the key takeaways, written simply:
- Mixing in generic data during final practice helps on the target task.
- In small models, this improved data efficiency by up to about 1.87× when only the fine-tuning stage was changed.
- When they also adjusted the earlier parts of training (mid-training), replay still helped—improving data efficiency up to about 2.06×.
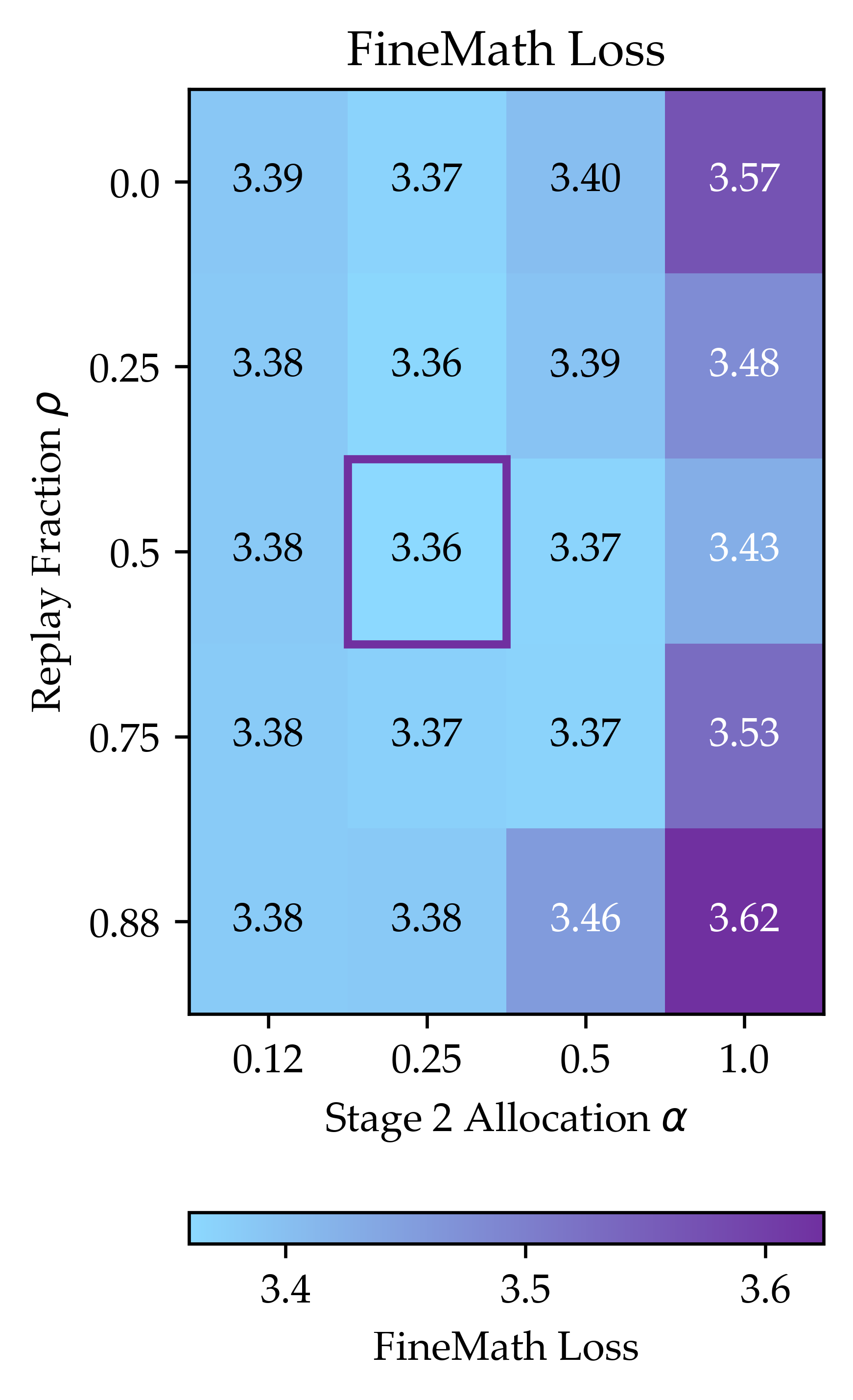
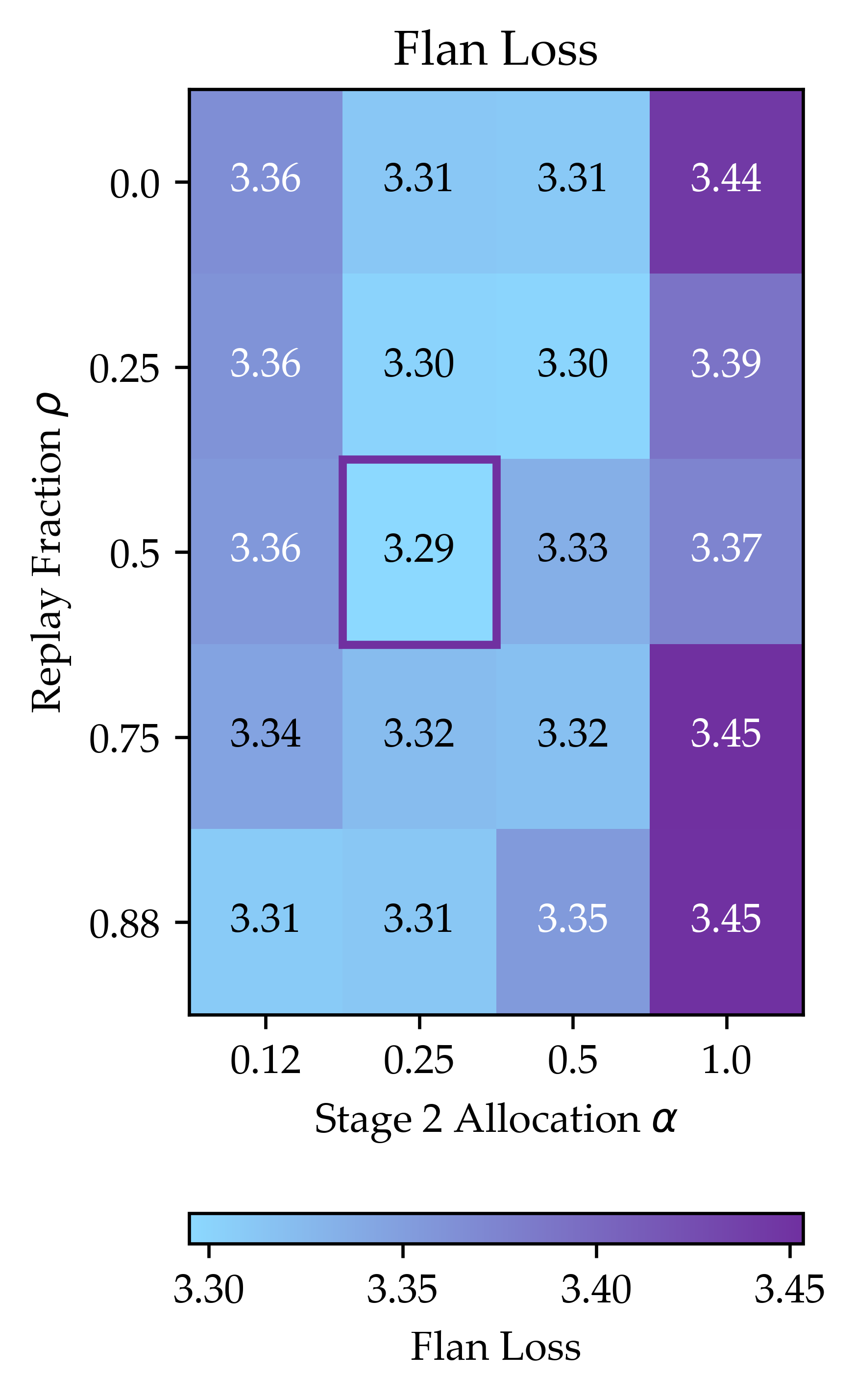
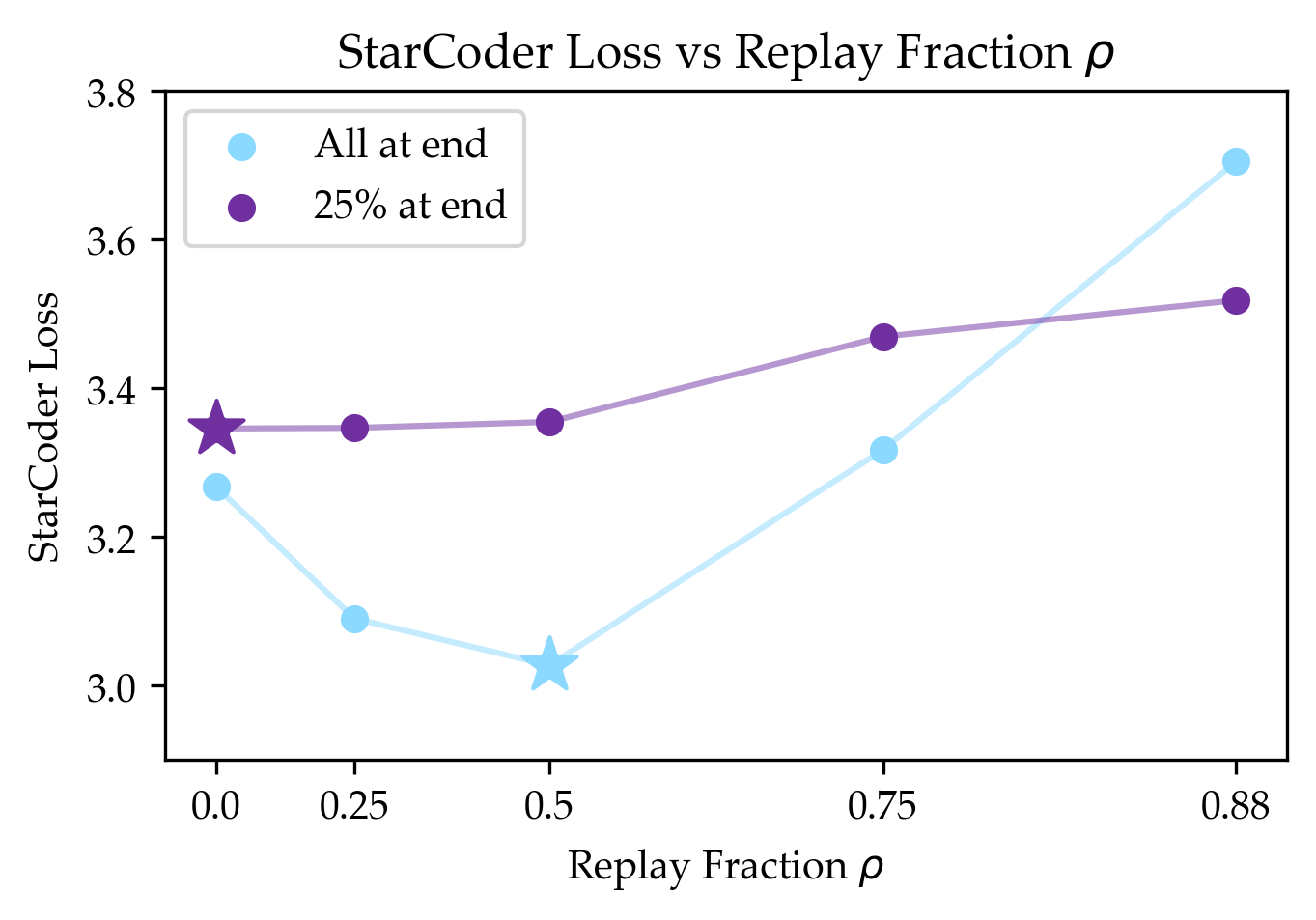
- The benefit depends on how similar the target task is to the general data:
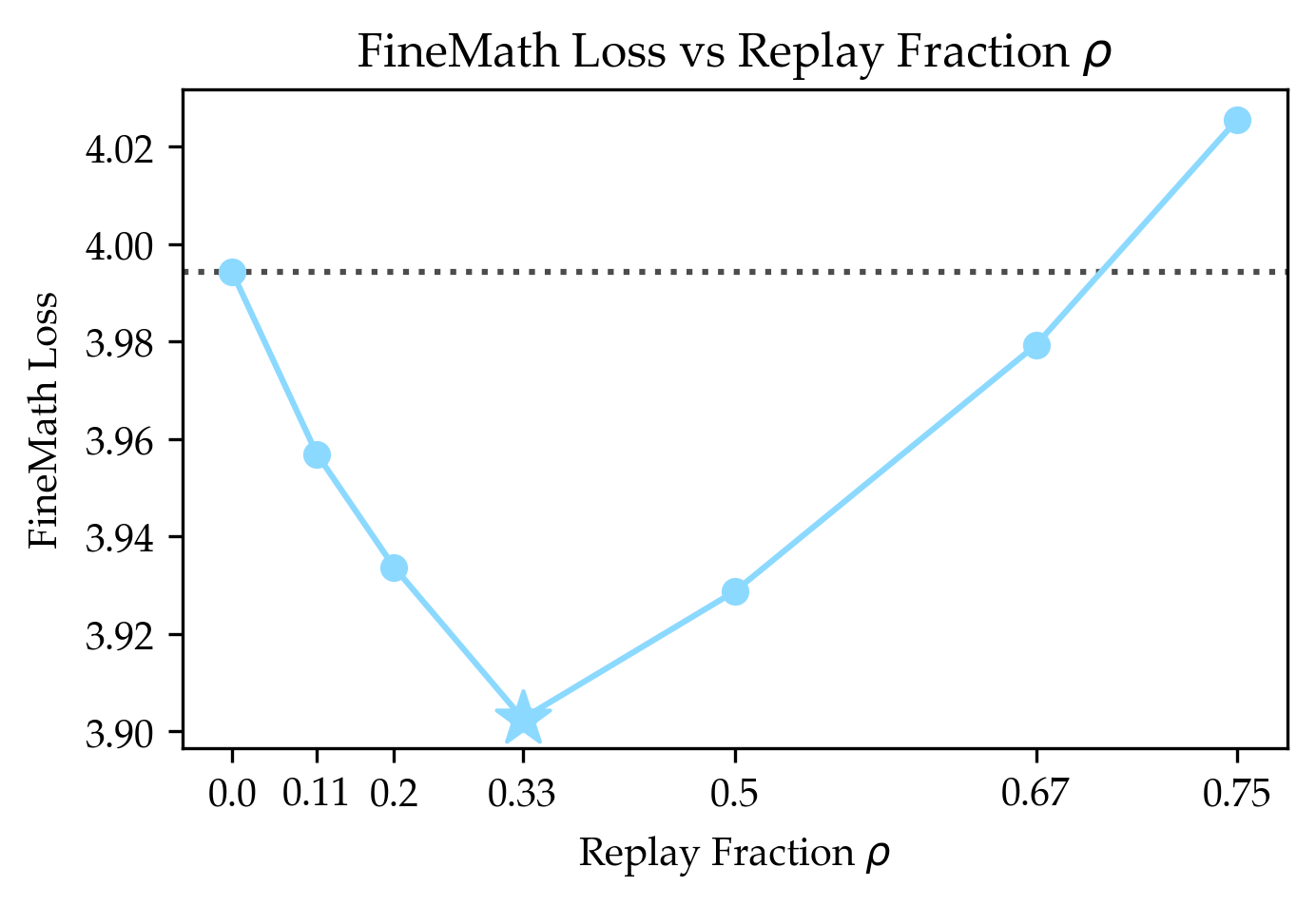
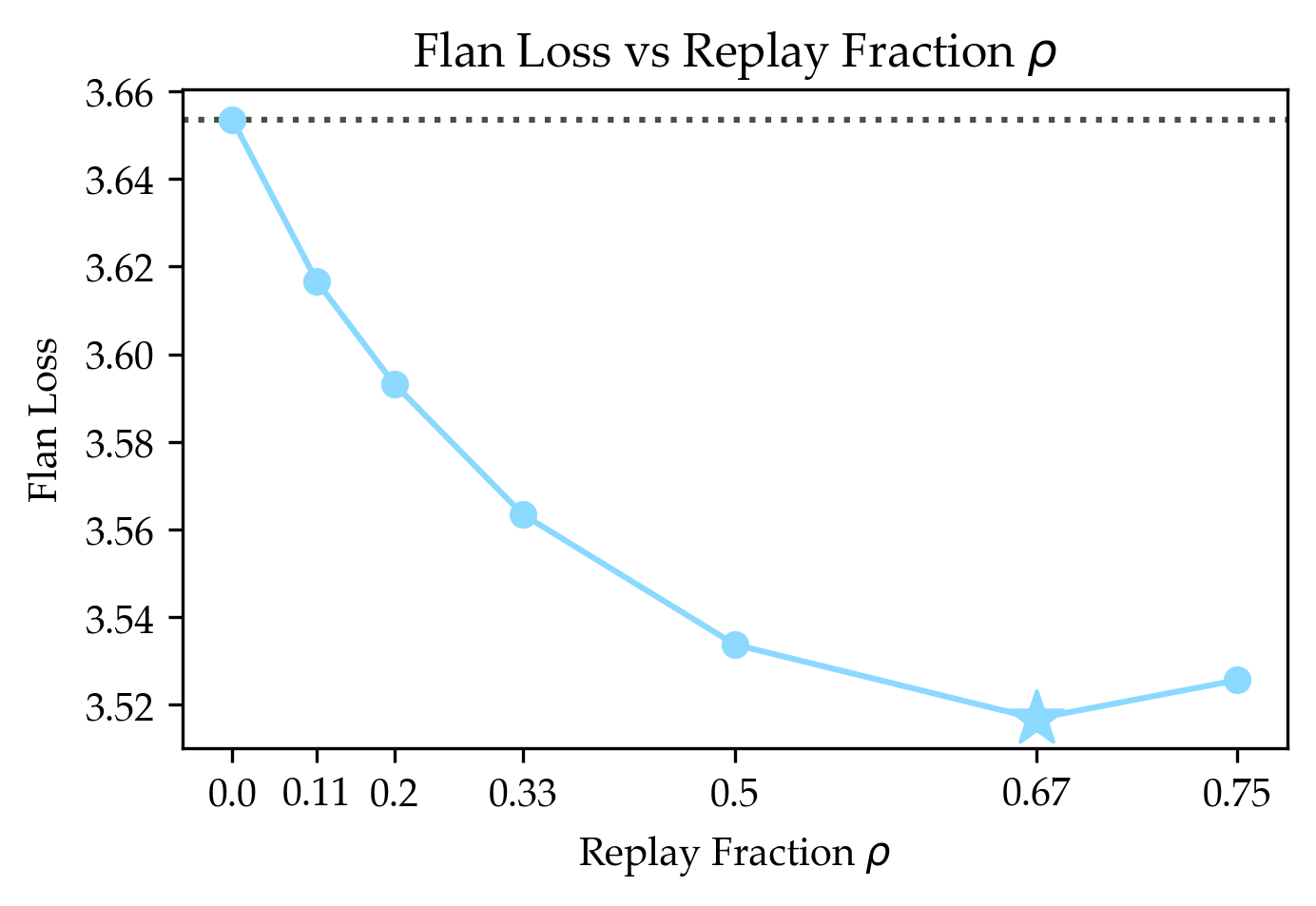
- Instruction following (Flan), which is close to general web text, benefited a lot.
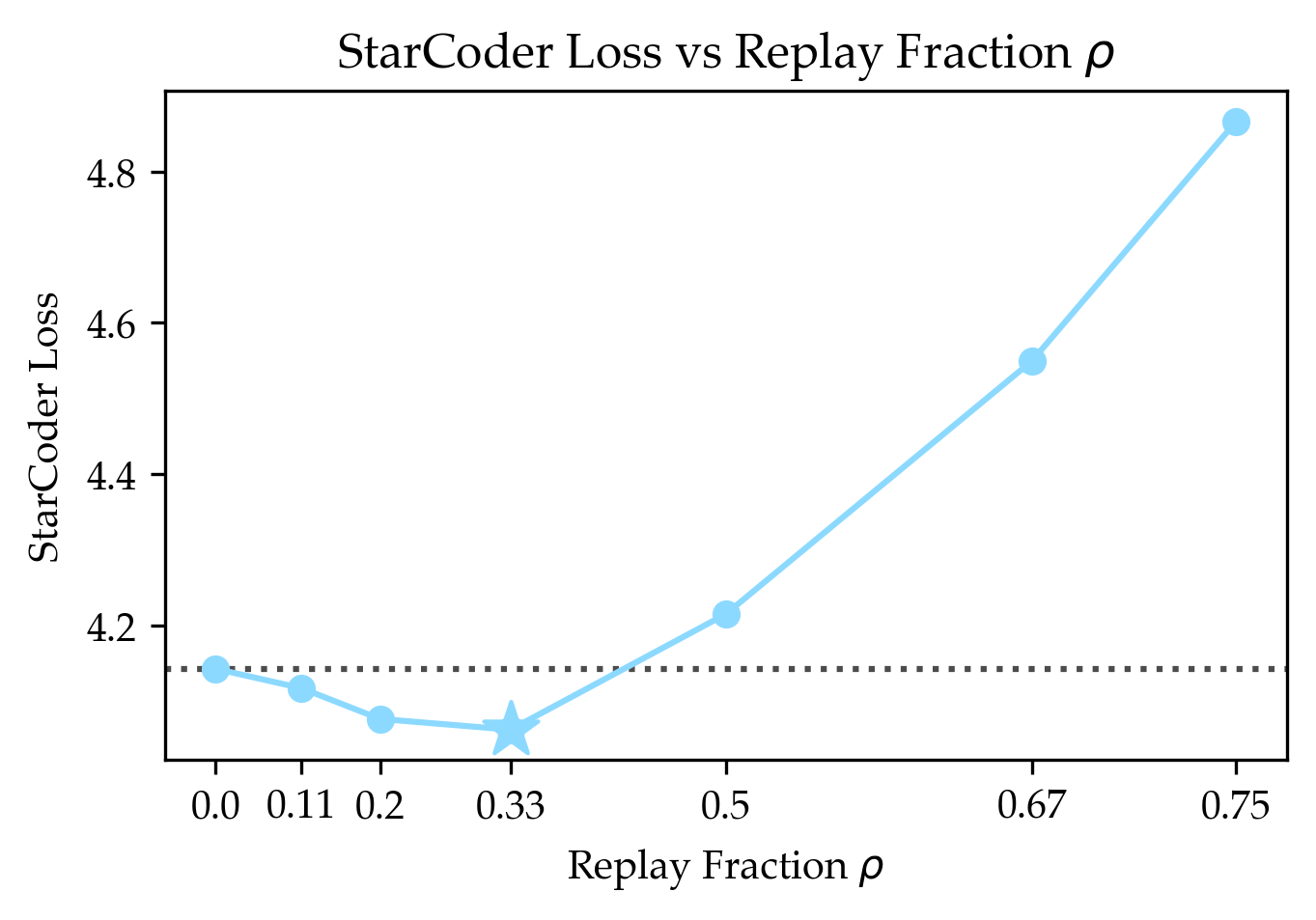
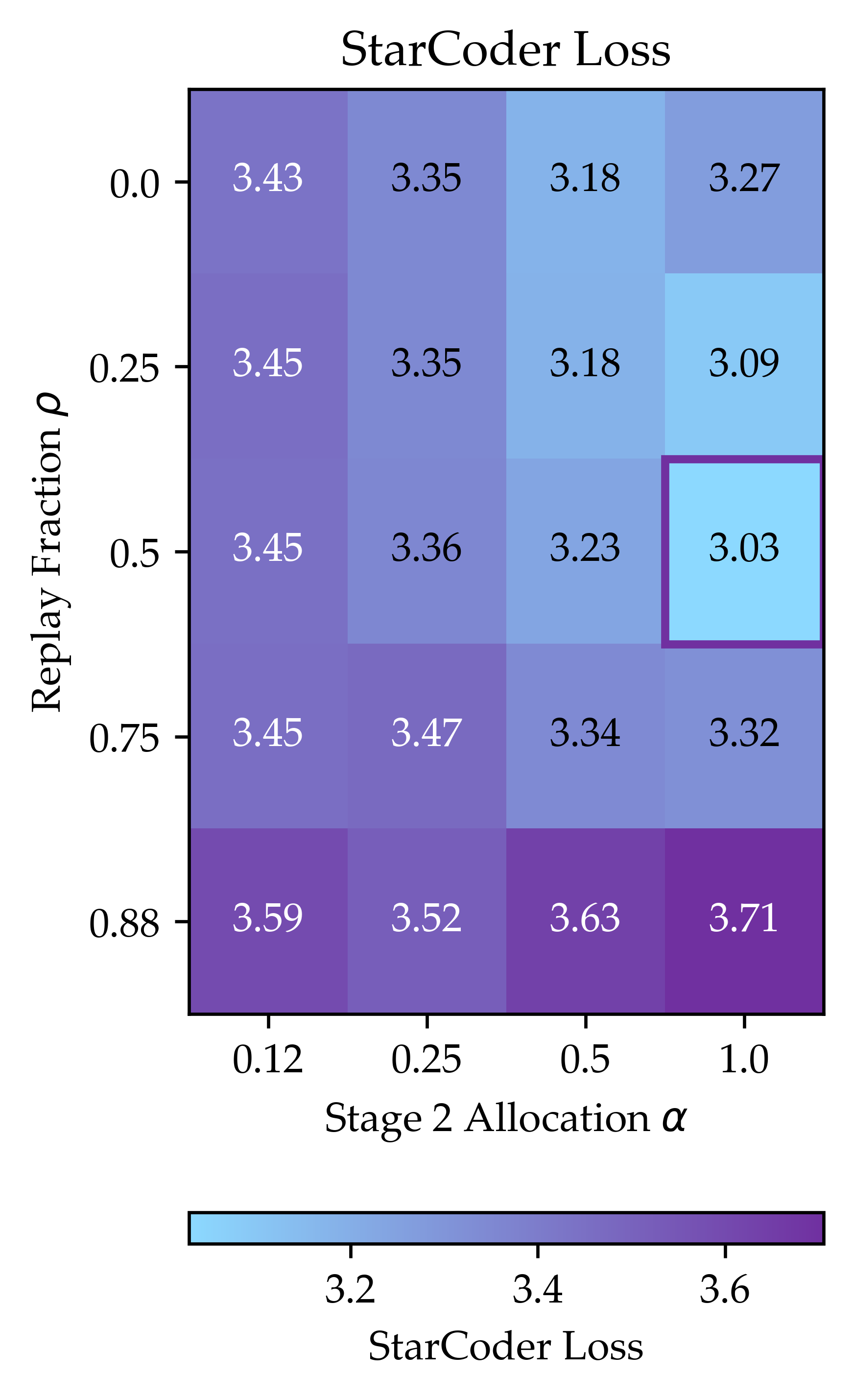
- Coding (StarCoder), which is less similar to the general data (because the general set filters out code), still benefited—but less.
- Moving some target data earlier in training can help too:
- Using a “two-stage” plan (some target data early, some late) plus replay beat the plain “all target at the end” setup. In some cases, this gave even bigger gains than replay alone.
- Replay matters most when the model saw little target data earlier:
- If the model didn’t encounter much of the special task during pre-training, adding general data during fine-tuning helps stabilize and improve learning.
- If the model already saw a lot of target data earlier, replay helps less (and can even be unnecessary).
- Bigger, more realistic tests support the idea:
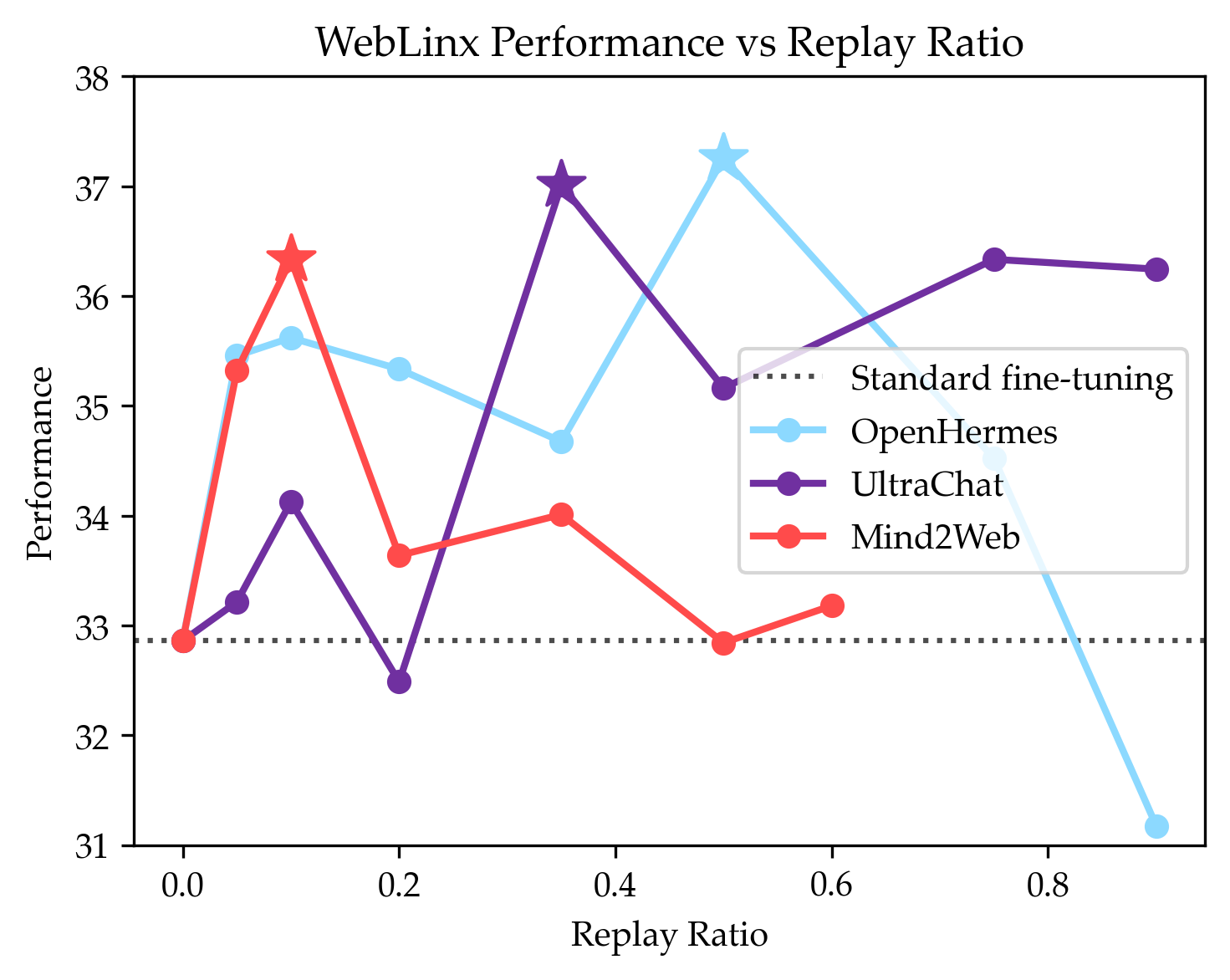
- Web agents: adding replay improved web navigation success by up to 4.5%.
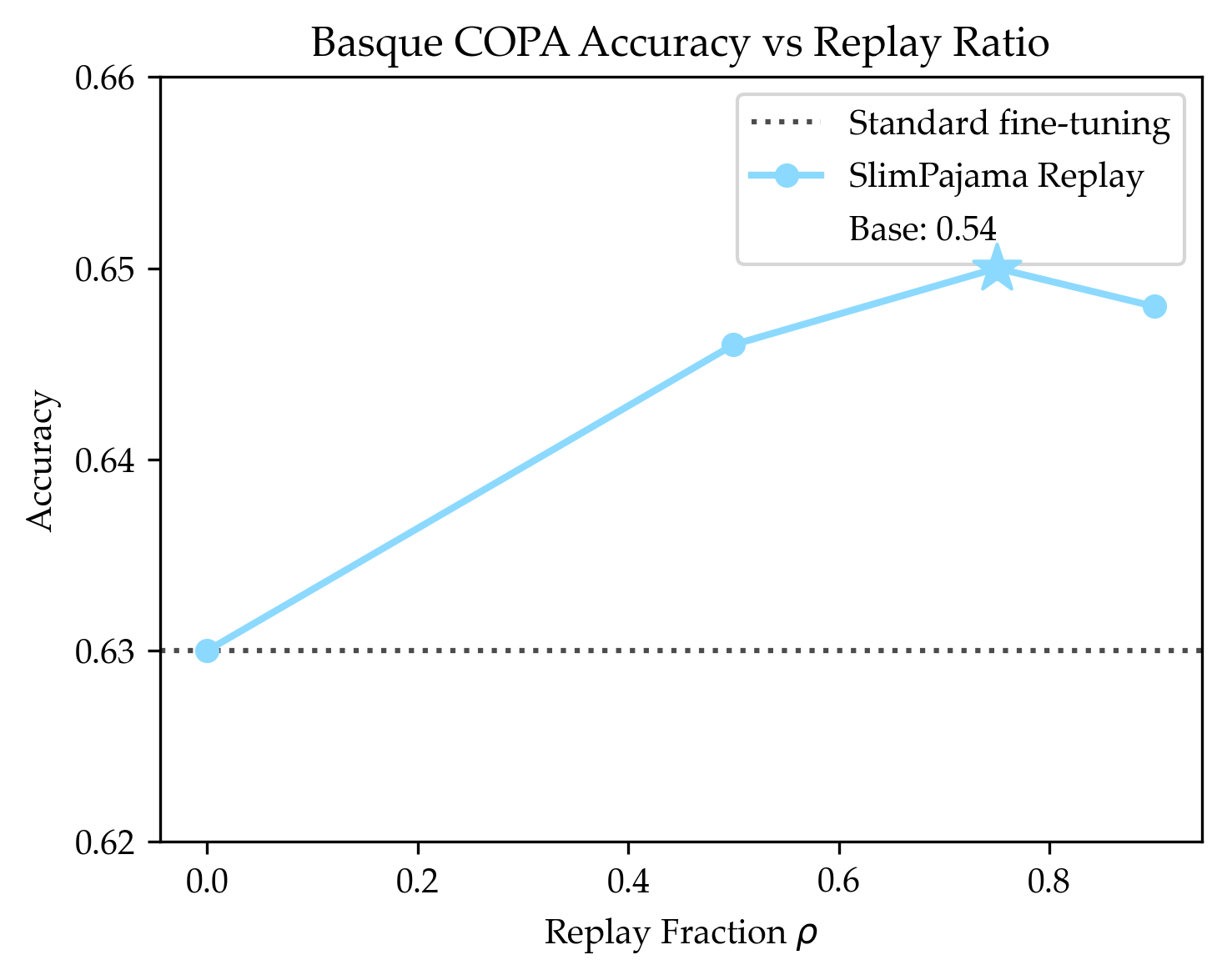
- Basque: adding replay improved accuracy by about 2% on a Basque reasoning test.
Why these results matter
- Practical training tip: If you can only change the fine-tuning stage (which is common in practice), you can still get better performance by mixing in some generic data at the end. This is especially helpful when your special-task data is small or rare.
- Better learning with less data: Replay makes the model use the limited target examples more effectively, so you don’t need as many to get good results.
- Helpful for low-resource areas: This approach is especially promising for tasks or languages that don’t have much training data (like Basque).
- Training schedule design: The paper also shows that choosing your “study schedule” (e.g., using a WSD learning rate and placing target data in the final cooldown) really matters for how well models learn.
How to picture it (simple analogy)
Imagine you’re preparing for a math competition:
- First, you read a big general math book (pre-training).
- Then you practice a small set of contest problems (fine-tuning).
- The paper’s surprise: if you mix in some pages from your general book while practicing the contest problems, you often get better at the contest problems. It keeps your thinking balanced and avoids overfitting to a tiny set of examples.
- If you also sprinkle some contest problems earlier in your study plan and save a batch for the very end (when you’re most focused), you do even better.
Final thoughts (impact and limits)
- Impact: This simple change—replaying generic data during fine-tuning—can make models stronger at their target tasks without needing lots more special data. That’s good news for projects with limited datasets.
- Limits to remember:
- Their controlled tests used small models and simplified data setups; real-world data is more varied.
- They mostly measured validation loss (a strong, but indirect, indicator of task performance).
- Replay increases total training steps if you want to keep the same number of target steps, so it can cost more compute.
Overall, the paper offers a clear, practical tip: don’t throw out general data at the very end. Mixing some of it back in can help your model learn the special task faster and better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Based on the paper’s methods and results, the following concrete gaps remain unresolved and suggest directions for future research:
- Generalization across model scales: Do replay gains observed at 150M and spot-checked at 8B persist, grow, or diminish at larger frontier scales and across multiple checkpoints along the pretraining curve?
- Breadth of target domains: How does replay affect tasks beyond math/code/instruction-following and the two downstream tests (web navigation, Basque COPA), e.g., multimodal tasks, retrieval-augmented models, safety alignment, and long-context reasoning?
- Multi-domain pretraining realism: The controlled setup uses two distributions (generic vs. one target). How do replay effects behave when pretraining involves many domains/tasks with varying overlaps and quality levels?
- Measuring domain overlap: The paper qualitatively orders overlap (e.g., Flan ≈ close, StarCoder ≈ far) but does not quantify it. Can replay fraction be predicted from a quantitative divergence/overlap metric (e.g., embedding-based similarity, KL, or classifier two-sample tests)?
- Replay data selection: Replay is uniform over “generic” data. Would prioritization (e.g., difficulty/quality-based, target-similar subsets, de-duplication-aware) outperform uniform replay, and how should those policies be learned?
- Quality mismatch sensitivity: In practical settings, “generic” proxies (OpenHermes, UltraChat, SlimPajama) approximate pretraining data. How sensitive are gains to quality/style/licensing/format mismatch between proxies and the true past distribution?
- Compute vs. data-efficiency trade-off: Replay increases steps by ~1/(1−ρ). What is the Pareto frontier between wall-clock/compute cost and target performance, and when does replay cease to be compute-efficient?
- Optimizer and schedule interactions: Results rely heavily on WSD and optimizer-state choices. How do replay effects change with different optimizers (e.g., Adafactor, AdamW variants), learning-rate schedules (cosine/one-cycle), and momentum/EMA settings?
- Fine-tuning instability: The paper notes early-step instabilities; replay mitigates them but mechanisms remain unclear. Which factors (gradient noise scale, norm spikes, layer-wise LR, clipping, weight decay, preconditioner reset) are causal, and what minimal mitigation matches replay?
- Epoch/repetition policies: The observed overfitting beyond certain repeat counts lacks a prescriptive rule. Can one learn or predict optimal repetition and replay jointly from small pilot runs?
- Data-efficiency metric robustness: The “effective data” metric depends on fitting a reference scaling law. How sensitive are conclusions to the chosen functional form, fit range, and noise? Would alternative metrics (e.g., compute-aware, bootstrapped CIs) change rankings?
- Statistical significance and variance: Reported improvements lack systematic confidence intervals/variance analyses across seeds. What is the distribution of gains and failure rates under repeated runs?
- Negative-transfer regimes: For domains far from generic data (e.g., code), replay tolerances are lower. How to detect and avoid harmful replay a priori, and can adaptive schedules prevent degradation in low-overlap settings?
- Stage granularity: Only two-stage schedules are considered. Do continuous or multi-stage curricula (e.g., gradually ramping ρ, or annealing target/generic mixtures) outperform the best two-stage policy?
- Scheduling policy learning: Can we learn α(t), ρ(t) online from signals (loss curvature, gradient alignment with target, validation performance) instead of grid searches over static α, ρ?
- Interaction with parameter-efficient tuning: Do replay benefits persist for LoRA/adapters, prefix tuning, or low-rank updates, and how should replay be allocated when only a subset of parameters is trainable?
- Interaction with post-training methods: How does replay interact with SFT variants, preference optimization (DPO, PPO/RLHF), and weight averaging/ensembling? Is replay complementary or redundant to these techniques?
- Checkpoint selection for fine-tuning: The paper recommends releasing pre-anneal checkpoints but does not quantify “how far” before cooldown is best. What is the optimal checkpoint choice for different targets?
- Tokenizer and vocabulary shift: Effects of tokenization differences between generic and target distributions (especially for code and low-resource languages) are not analyzed. Does replay mitigate or exacerbate tokenization mismatch?
- Language coverage and tasks: Basque results are limited to COPA. Do replay gains generalize across more low-resource languages and task types (translation, QA, morphological tagging), and with different degrees of pretraining coverage?
- Out-of-domain and safety impacts: Replay aims to improve target performance, but its effects on general capabilities, calibration, safety alignment, and robustness (adversarial prompts, jailbreaking) are unmeasured.
- Memorization and privacy: Does replay increase memorization of generic web data or leakages, particularly when mixing high-duplication corpora? How does replay interact with memorization mitigation techniques?
- Data contamination control: Overlaps between target and generic (or evaluation) datasets are acknowledged but not quantified. How do replay gains change after strict de-duplication and contamination checks?
- Generalization theory: The paper offers hypotheses (instability, overfitting to rare/noisy target samples) and a toy model. A more formal analysis of SGD on mixture distributions (e.g., gradient alignment, bias–variance trade-offs) is missing.
- Replay policy transferability: Are α and ρ chosen for one target transferable to similar targets (e.g., across math datasets) or must they be re-tuned per domain?
- Early-exposure necessity: For two domains, optimal schedules require some target data in Stage 1, but for code they do not. What task properties determine when early exposure is necessary vs. when replay suffices?
- Generic dataset choice: C4 serves as generic data in controlled runs. Do results hold with other corpora (e.g., RedPajama, CCNet, The Pile), especially those with different filtering and domain mixes?
- Multi-objective training: When optimizing for multiple targets (e.g., reasoning + safety + languages), how should replay be allocated among multiple “generic” pools and targets under step/data constraints?
- Practical heuristics: The paper offers qualitative guidance (replay helps when target is scarce in pretraining) but no operational heuristic for choosing ρ given target size/overlap. Can a simple rule-of-thumb be derived and validated?
- Evaluation breadth for agents: Web agent gains are measured via offline scoring; interactive, end-to-end success rates and robustness to environment changes are not reported. Do replay benefits carry to online and RL settings?
- Reporting and reproducibility: While runs/code are linked, the main text omits full training budgets, seed counts, and error bars. A standardized reporting template would strengthen replicability and interpretation.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that teams can implement now, with suggested sectors, workflows, and key assumptions/dependencies.
- Replay-aware supervised fine-tuning (SFT) for LLM agents
- Sector: software, robotics, customer support, e-commerce
- Use case: When fine-tuning web agents or task agents from scarce human trajectories, interleave a fraction of generic instruction-following data (e.g., OpenHermes, UltraChat) during SFT to improve task performance.
- Evidence from paper: +4.5% web navigation accuracy with Llama 3.1-8B by replaying instruction-following data while fine-tuning on WebLinx trajectories.
- Workflow
- Identify target dataset (limited trajectories).
- Select replay corpus that approximates prior pretraining/post-training style (e.g., instruction-following data).
- Interleave replay at fraction ρ during Stage 2 (fine-tuning), e.g., start with ρ ∈ {0.1, 0.2, 0.3, 0.5} and grid search.
- Adjust step budget to account for replay: total steps multiply by 1/(1−ρ).
- Monitor target-validation metrics; pick ρ that maximizes target performance.
- Tools: TRL/PEFT/DeepSpeed for SFT; custom dataloader for mixed batches; W&B or MLflow for tracking.
- Assumptions/dependencies: Access to a licensed, representative generic corpus; additional compute budget for the replay overhead; replay benefits are larger when the target domain is scarce in pretraining.
- Low-resource language adaptation with replay
- Sector: public sector, education, NGOs, cultural institutions, localization
- Use case: Improve low-resource language capability by mixing generic pretraining-like data while fine-tuning on limited language data.
- Evidence from paper: +2% accuracy on Basque COPA by replaying generic (SlimPajama-like) data during continual pretraining of Llama 3.1-8B on 200M Basque tokens.
- Workflow
- Curate limited target-language corpus (e.g., Latxa).
- Choose a broad, multilingual or general web corpus similar to the base model’s pretraining.
- Interleave replay with ρ tuned via small sweeps (wider beneficial ranges observed).
- Evaluate on target-language benchmarks (e.g., COPA, XNLI variants).
- Tools: Hugging Face datasets; evaluation harnesses (lm-eval-harness).
- Assumptions/dependencies: Availability of permissive, broad-coverage generic corpora; benefit size depends on similarity and scarcity of target-language data in pretraining.
- Domain adaptation when target data is scarce (e.g., healthcare coding, legal drafting, scientific writing)
- Sector: healthcare, legal, scientific R&D, enterprise software
- Use case: When fine-tuning on small, sensitive or costly target datasets, interleave licensed generic text to reduce overfitting and improve generalization.
- Workflow
- Secure/curate small domain dataset (e.g., de-identified clinical notes).
- Select a licensed general corpus similar to base model pretraining.
- Interleave with replay fraction ρ; for distant domains (like code vs C4), start with small ρ (e.g., 0.1–0.2); for closer domains (e.g., instruction-following), explore higher ρ (e.g., up to ~0.4).
- Validate on domain-specific held-out sets; confirm no memorization of sensitive content.
- Tools: Privacy-preserving data pipelines; differential privacy (if required); standard SFT frameworks.
- Assumptions/dependencies: Data licensing/consent; privacy/security constraints; replay corpus must not leak sensitive domain data.
- Robust instruction tuning and alignment with replay
- Sector: software, education, customer support
- Use case: During instruction tuning on curated, narrow instruction sets, mix in generic instruction data to avoid overfitting to narrow prompt formats and improve robustness.
- Workflow
- Identify target instruction set (e.g., policy or company-specific instructions).
- Interleave generic instruction-following data with tuned ρ; evaluate instruction adherence and helpfulness.
- Tools: Preference optimization/RLHF pipelines; SFT with mixed data loaders.
- Assumptions/dependencies: Robustness gains are empirical; measure both in-distribution and out-of-distribution behavior.
- MLOps and training platform updates to support replay
- Sector: software/tools, MLOps
- Use case: Add “replay fraction (ρ)” and “replay source” as first-class config knobs in training platforms to standardize replay-aware fine-tuning.
- Workflow
- Extend dataloaders/orchestrators to accept α (Stage 2 allocation) and ρ (replay fraction).
- Provide automated hyperparameter sweeps and dashboards tracking target validation loss and compute cost.
- Tools: Ray Tune/Optuna; Airflow/Kubeflow; experiment tracking.
- Assumptions/dependencies: Reliable target validation signal; extra compute for hyperparameter sweeps.
- Guidance for model users: Request “pre-cooldown” checkpoints
- Sector: open-source model hubs, enterprise AI consumers
- Use case: Ask model providers to publish pre-cooldown (pre-annealed) checkpoints and optimizer states, which the paper shows can significantly improve mid-training adaptation.
- Workflow
- Prefer initializing fine-tuning from pre-cooldown checkpoints where available.
- Assumptions/dependencies: Provider willingness to release; storage and distribution constraints.
- Personalization with consumer fine-tuning
- Sector: consumer apps, daily life
- Use case: When fine-tuning small models or adapters (LoRA) on a user’s personal data (e.g., writing style), mix a modest amount of generic chat text to avoid overfitting and preserve general conversational skills.
- Workflow
- Collect small personal corpus.
- Add licensed generic chat data; start with ρ≈0.2 and adjust based on qualitative evaluation.
- Tools: On-device or cloud LoRA fine-tuning; simple evaluation prompts.
- Assumptions/dependencies: Limited hardware budgets; small batch sizes may need more careful tuning.
- Procurement and public-sector guidelines
- Sector: policy/public sector
- Use case: Include replay practices in RFPs and compliance guidelines for AI systems targeting low-resource languages or scarce-domain tasks.
- Workflow
- Require vendors to document replay fraction, data sources, and compute overhead; enforce licensing checks on replay data.
- Assumptions/dependencies: Availability of public-domain or licensed replay corpora; oversight for data provenance.
Long-Term Applications
These opportunities require further research, scaling, standardization, or ecosystem shifts beyond immediate deployment.
- Automated two-stage schedule optimization (α, ρ) at scale
- Sector: foundation model training, software/tools
- Idea: Build automated search to jointly optimize target allocation across stages (α) and replay fraction (ρ), integrated with warmup-stable-decay (WSD).
- Potential tools/products: “AutoSchedule” modules for Deepspeed/Composer; bandit/RL controllers that adjust α, ρ online using target loss or gradient similarity.
- Assumptions/dependencies: Efficient online metrics; budget for exploratory training runs; reproducible validation signals across domains.
- Standardizing pre-cooldown checkpoint release
- Sector: model providers, open-source hubs
- Idea: Establish community standards and hub support for publishing pre-cooldown checkpoints with optimizer states to enable mid-training benefits.
- Potential products: “Mid-training snapshot” formats on model hubs; storage-efficient optimizer-state compression.
- Assumptions/dependencies: Storage costs; IP and security policies; demand from downstream users.
- Privacy-preserving replay for regulated domains
- Sector: healthcare, finance, government
- Idea: Develop differentially private or federated replay pipelines where generic data is de-identified or synthesized to maintain legal compliance while preserving the benefits of replay.
- Potential tools/products: DP-enabled data mixers; federated SFT orchestration; compliance dashboards.
- Assumptions/dependencies: DP utility trade-offs; secure data connectors; regulatory acceptance.
- Dynamic replay controllers during SFT/RLHF
- Sector: software, alignment/safety
- Idea: Online controllers that adapt replay fraction in response to signals like forgetting, loss curvature, or out-of-distribution drift; extend to RLHF/preference optimization.
- Potential products: Plug-ins to TRL/Accelerate that adjust data sampling in real time; gradient-similarity-based schedulers.
- Assumptions/dependencies: Reliable, low-latency metrics; stability under non-stationary training.
- Domain-sensitive replay catalogs and data marketplaces
- Sector: data industry
- Idea: Curated, licensed “replay packs” aligned to major base models’ pretraining distributions for different languages and sectors, with provenance and compliance metadata.
- Potential products: Replay catalogs for instruction-following, multilingual, code-adjacent text; APIs for MLOps integration.
- Assumptions/dependencies: Licensing clarity; alignment with base model pretraining; ongoing maintenance.
- Curriculum learning fused with replay
- Sector: academia, foundation model R&D
- Idea: Design multi-stage curricula that control both difficulty and distribution similarity, combining early exposure to target data with end-of-training replay for stability and generalization.
- Potential outcomes: New theories linking replay to overfitting control and optimization dynamics; improved convergence for scarce targets.
- Assumptions/dependencies: Task-specific curation; compute to explore curricula.
- Cross-domain and multilingual public-good models
- Sector: international organizations, public sector
- Idea: Use replay to systematically boost capabilities for low-resource languages or public-domain tasks (e.g., disaster response, public health info) without massive target data collection.
- Potential products: Open checkpoints tuned with replay for underserved languages; evaluation suites reflecting real-world tasks.
- Assumptions/dependencies: Sustained funding; public-domain replay corpora; community evaluation standards.
- Edge/on-device adaptation with lightweight replay
- Sector: mobile/IoT, robotics
- Idea: Lightweight replay mechanisms for small models that can cache and reuse a small, local generic corpus to stabilize on-device personalization or robot instruction adaptation.
- Potential products: Memory-constrained replay buffers; streaming replay schedulers.
- Assumptions/dependencies: Storage constraints; energy budgets; careful ρ tuning.
- Cost–performance optimization and energy-aware scheduling
- Sector: energy/compute management, finance
- Idea: Develop models that predict target performance vs. ρ to optimize total cost-of-training under compute and energy constraints, including when replay reduces required target data collection.
- Potential tools/products: Budget planners that trade off data acquisition costs, compute expenses, and performance targets.
- Assumptions/dependencies: Reliable performance–cost models; organizational constraints on compute.
- Knowledge updating and fact injection with replay
- Sector: enterprise knowledge management, compliance
- Idea: When incorporating new facts or regulations into a model, use replay to avoid overfitting to small update sets and maintain broader capabilities.
- Potential workflows: Periodic update cycles that mix new facts with generic replay, validated against regression tests.
- Assumptions/dependencies: Curated update datasets; regression benchmarks; data governance.
Practical parameter heuristics and caveats (from the paper’s findings)
- When the target domain is rare in pretraining, replay helps more; start with higher ρ in closer-to-generic settings (e.g., instruction-following) and lower ρ for distant domains (e.g., code filtered out of the generic corpus).
- Compute overhead scales as 1/(1−ρ); factor this into budgets.
- If you can modify mid-training, consider warmup-stable-decay (WSD) with ~10% cooldown and place target data near the cooldown; otherwise, for typical SFT-only setups, interleaving replay still yields measurable gains.
- Always validate on in-domain targets; although the paper shows improvements in validation loss and select downstream tasks, the magnitude of gains can vary with domain similarity, data quality, and model scale.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates, widely used for training transformers. "with AdamW, with full training details in Appendix \ref{sec:appendix-general-training-settings}"
- Annealing (learning rate): Gradual reduction of the learning rate during training. "Default practice (i.e. cosine, linear) is to slowly anneal to zero over the course of training."
- Catastrophic forgetting: Abrupt loss of previously learned skills when training on new data. "to prevent catastrophic forgetting of the generic domain"
- Compute-matched comparisons: Comparing methods under equal compute budgets (e.g., total tokens or steps). "to total 4 billion tokens for compute-matched comparisons."
- Continual learning: Training on a sequence of tasks or distributions without forgetting previous ones. "Though replay is a common method in continual learning, it is almost always used to prevent catastrophic forgetting of old tasks"
- Continual pre-training: Continuing pre-training a model on additional data after initial pre-training. "We are interested in how to continually pre-train Llama 3.1 8B with access to a limited number of Basque tokens (i.e. 200M)."
- Cooldown period: The final, sharply decaying phase of a WSD learning-rate schedule. "This consists of a short linear warmup, a stable training phase, and a sharp linear decay for a variable fraction of training referred to as the cooldown period."
- Cosine learning rate schedule: A learning-rate schedule that follows a cosine decay pattern over time. "with a cosine learning rate schedule for steps"
- Curriculum learning: Ordering training data from easier to harder to potentially aid convergence. "Curriculum learning is concerned with proposing a sequence of training distributions from easy to hard"
- Data-constrained scaling laws: Predictive relationships for performance as a function of data volume under a data budget. "This is not captured by the functional form of prior data-constrained scaling laws,"
- Data efficiency: How effectively a method uses limited target data to achieve low loss. "improving data efficiency by up to ."
- Data schedule: The planned ordering and mixing of data distributions during training. "Standard fine-tuning often uses a data schedule of training on all of the generic data followed by all of the target data."
- Distributional replay: Drawing fresh samples from a past distribution rather than reusing specific past samples. "better thought of as distributional replay."
- Double-descent: Phenomenon where error decreases, increases, then decreases again as capacity or data grows. "double-descent literature."
- Effective target data: The amount of target data a reference strategy would need to match a given loss. "we can estimate the effective target data the reference strategy would need to match the loss"
- Experience replay: Reusing past samples to stabilize or improve training, common in continual learning. "Experience replay typically refers to reusing previously seen samples"
- Held-out validation set: A reserved subset used only for evaluation during training. "we measure via loss on a held-out validation set from the target distribution."
- In-distribution: From the same distribution as the target training data. "improves performance on the new in-distribution training task"
- Instruction-tuning: Fine-tuning on instruction–response data to improve following instructions. "instruction-tuning data needs to be seen during pretraining."
- Mid-training: An intermediate training phase where schedules and data mixes are adjusted. "The benefit of replay still persists in the mid-training setting"
- Offline scoring procedure: Evaluating agent outputs without online interaction with the environment. "under their offline scoring procedure."
- Optimizer state reset: Re-initializing optimizer accumulators (e.g., moments) between stages. "we reset the optimizer state (i.e. for AdamW, the estimate of the first/second moments of the gradients) in between the stages."
- Out-of-distribution: Data differing from the training distribution. "in-distribution and out-of-distribution accuracy"
- Pre-annealed pre-training checkpoint: A checkpoint saved before the learning rate has fully decayed. "we believe fine-tuning in practice would benefit from initializing at a pre-annealed pre-training checkpoint instead of the final checkpoint."
- Replay fraction (): Proportion of steps in a stage that use replayed generic data. "Specifically, we introduce a replay fraction for what fraction of training steps during Stage 2 will be on generic data."
- Scaling law: A relationship predicting loss as a function of resources such as data or model size. "We then fit a scaling law that predicts the loss of the reference algorithm"
- Target stage 2 allocation (): Fraction of total target data assigned to Stage 2. "introduce target stage 2 allocation (what fraction of the total target data is allocated to Stage 2)."
- Validation loss: Loss on validation data used to assess generalization. "improves target validation loss"
- Warmup-Stable-Decay (WSD): A learning-rate schedule with brief warmup, long plateau, then sharp decay. "use an improved baseline with a single learning rate schedule with Warmup-Stable-Decay (WSD)"
- Weight averaging: Averaging parameters across checkpoints to improve robustness/generalization. "Weight averaging has been one such technique to improve post-training performance"
- Web agent: An LLM-driven agent that performs tasks like navigating websites. "web agent navigation"
Collections
Sign up for free to add this paper to one or more collections.