Sparse-BitNet: 1.58-bit LLMs are Naturally Friendly to Semi-Structured Sparsity
Abstract: Semi-structured N:M sparsity and low-bit quantization (e.g., 1.58-bit BitNet) are two promising approaches for improving the efficiency of LLMs, yet they have largely been studied in isolation. In this work, we investigate their interaction and show that 1.58-bit BitNet is naturally more compatible with N:M sparsity than full-precision models. To study this effect, we propose Sparse-BitNet, a unified framework that jointly applies 1.58-bit quantization and dynamic N:M sparsification while ensuring stable training for the first time. Across multiple model scales and training regimes (sparse pretraining and dense-to-sparse schedules), 1.58-bit BitNet consistently exhibits smaller performance degradation than full-precision baselines at the same sparsity levels and can tolerate higher structured sparsity before accuracy collapse. Moreover, using our custom sparse tensor core, Sparse-BitNet achieves substantial speedups in both training and inference, reaching up to 1.30X. These results highlight that combining extremely low-bit quantization with semi-structured N:M sparsity is a promising direction for efficient LLMs. Code available at https://github.com/AAzdi/Sparse-BitNet
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at two tricks to make LLMs faster and cheaper to run:
- making their weights use very few possible values (quantization), and
- setting many weights to zero in a structured pattern (sparsity), so special chips can skip work.
The authors show that a specific ultra-low-precision model called “BitNet b1.58” (where most weights are just -1, 0, or +1) works surprisingly well with a popular kind of structured sparsity called N:M sparsity. They build a training method, called Sparse-BitNet, that combines both ideas and stays stable while training big models.
What questions did the researchers ask?
- If we enforce the same kind of structured sparsity, do ultra-low-precision models like BitNet b1.58 lose less accuracy than normal full-precision models?
- Can we train such models from scratch in a stable way while applying both extreme quantization and N:M sparsity?
- Do these combinations give real speedups on GPUs without breaking model quality?
How did they approach the problem?
Think of a neural network as a giant calculator with millions or billions of “knobs” (weights). The paper combines two ways to make this calculator simpler and faster:
- Quantization (BitNet b1.58): Instead of letting weights be any real number, each weight can only be -1, 0, or +1. That’s like turning a smooth volume knob into a 3-step switch. Because there are 3 choices, storing each weight needs about log2(3) ≈ 1.58 bits on average—hence “1.58-bit.”
- Semi-structured N:M sparsity: Break weights into small groups of size M (like 8). In each group, only keep the N strongest weights (like the top 6) and set the rest to zero. This fixed “keep N of every M” pattern matches special GPU hardware that can skip zeros and run faster.
Key ideas in their training recipe, explained simply:
- Dynamic mask each step: At every training step, they re-pick which weights to keep in each group by checking which ones are currently largest in magnitude. This keeps the “who’s kept” list fresh as the model learns.
- Let all weights keep learning: Even if a weight is currently zeroed (masked), the training still sends it a learning signal so it can grow and maybe become useful later. This prevents the model from “locking in” bad choices too early.
- Decide what to keep using full-precision “master” weights: They keep a hidden full-precision copy of weights for ranking which are largest. This avoids messy ties and instability that would happen if they ranked using only {-1, 0, +1}.
- Apply “quantize then mask”: In the forward pass, they first turn weights into {-1, 0, +1}, then apply the keep/drop pattern. This produces clean, hardware-friendly sparse weights for fast computation.
They tested this on Qwen2.5 models of different sizes (0.5B, 1.5B, 3B parameters), trained on a big web dataset, and evaluated on common benchmarks (like HellaSwag, ARC-E, PIQA, BoolQ, COPA). They also measured speed on NVIDIA GPUs using custom 6:8 sparse kernels.
What did they find?
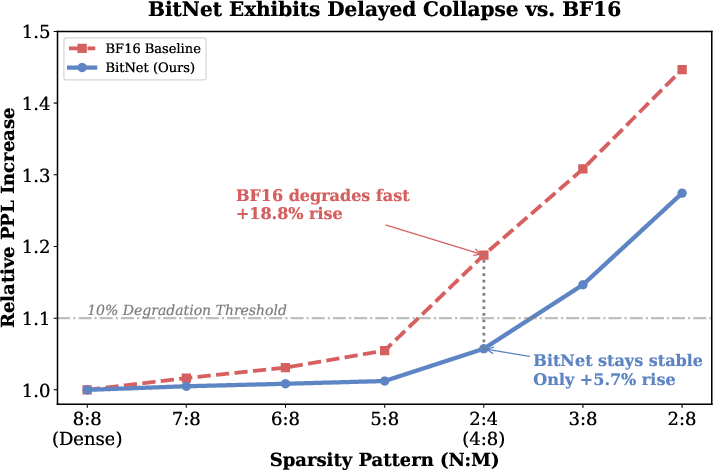
- BitNet b1.58 handles sparsity better: When they enforce the same N:M sparsity, the ultra-low-precision BitNet models lose less accuracy than full-precision models. In other words, BitNet is more “sparsity-friendly.”
- Example: With a strong 2:4 pattern (keep 2 of every 4, i.e., 50% zeros), a standard full-precision model’s “confusion” (perplexity) increases a lot, while BitNet’s increase is much smaller.
- With a 6:8 pattern (keep 6 of every 8, i.e., 25% zeros), BitNet’s performance drop is consistently smaller than full-precision across model sizes and tasks.
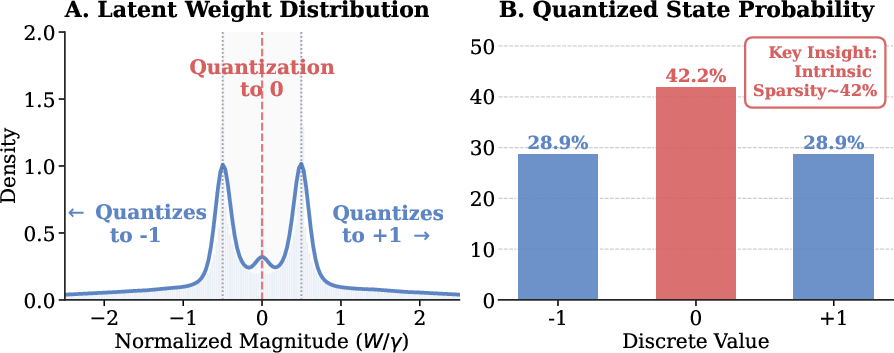
- BitNet naturally has many zeros: Because BitNet weights are only -1, 0, or +1, a big chunk naturally become 0 during training. This “built-in sparsity” makes it easier to choose which weights to keep in each N:M group without hurting performance.
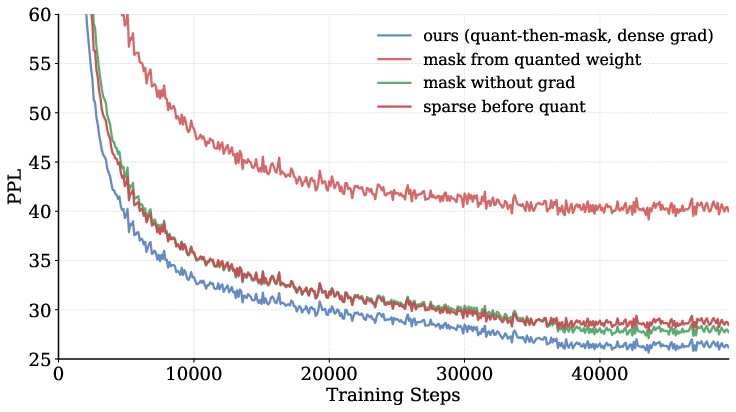
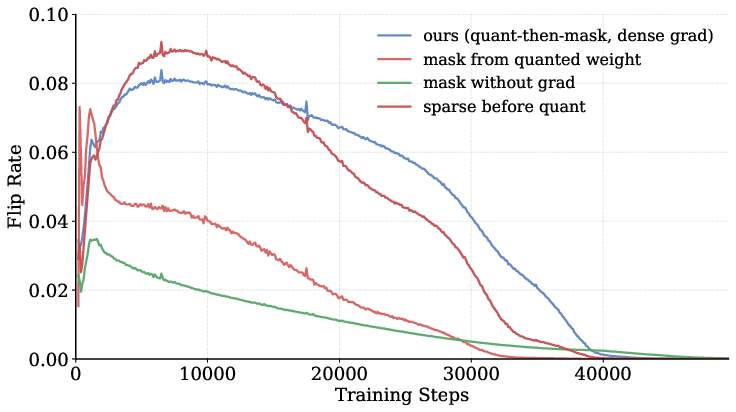
- More stable training with their method:
- Recomputing the sparse mask every step and letting all weights receive gradients avoided “getting stuck.”
- Choosing which weights to keep based on the hidden full-precision copy, not the ternary values, prevented unstable tie-breaking.
- Training sparsely from the very beginning worked better than training dense first and switching to sparse late.
- Real speedups on GPUs: With their 6:8 sparse implementation, they saw up to about 1.30× faster throughput (more tokens processed per second) in both training and inference on NVIDIA GPUs, depending on sequence length and batch size.
Why does this matter?
- Faster and cheaper AI: Combining extreme low-bit weights with structured sparsity means LLMs can run faster and use less memory and energy. That makes it easier to train and deploy models in real-world applications.
- Better trade-offs: The study shows you don’t have to choose between extreme compression and decent accuracy. BitNet b1.58 plus N:M sparsity finds a sweet spot: smaller models that still perform well and run quickly on modern hardware.
- Practical guidance for builders: The paper gives a clear recipe for training such models stably:
- recompute masks every step,
- let all weights learn even when masked,
- compute masks from full-precision master weights,
- quantize first, then apply the mask in the forward pass.
In short, the paper shows that ternary LLMs with 1.58-bit weights are naturally suited to semi-structured sparsity, and when you train them the right way, you can keep quality high while making them faster and cheaper to use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored.
- Scaling and absolute performance: Quantify whether Sparse-BitNet can match or surpass dense BF16 at larger scales (e.g., 7B–70B+) and longer training budgets; provide scaling-law analyses separating quantization vs. sparsity contributions.
- Generalization beyond Qwen2.5: Validate on diverse architectures (e.g., LLaMA, Mistral, MoE, encoder–decoder) and attention variants (MHA/MQA/GQA) to assess architectural dependence.
- Post-training applicability: Evaluate sparse ternary training as a post-training method on existing dense checkpoints (PTQ/QAT with N:M) and during downstream fine-tuning (instruction tuning, RLHF/alignments).
- Broader evaluation suite: Measure on reasoning, math, coding, multilingual, and knowledge-heavy tasks (e.g., MMLU, GSM8K, HumanEval, MBPP, BIG-bench, ARC-C) and long-context benchmarks; report few-shot and chain-of-thought robustness.
- Absolute vs. relative quality: While BitNet degrades less under sparsity, its absolute PPL and downstream scores remain below dense BF16; test whether distillation, curriculum, or regularization can close the absolute performance gap.
- Activation quantization and sparsity: Study sub-8-bit activations (e.g., 4–6 bit), activation sparsity, and KV-cache quantization, and how they interact with
N:Mweight sparsity in both accuracy and speed. - Layer- and module-wise policies: Explore heterogeneous
N:Mper layer/module (Q/K/V, MLP, embeddings, output head, norms), selective sparsity per tensor, and learnable layerwise sparsity schedules. - Mask criterion beyond magnitude: Compare magnitude-based masks to gradient/Hessian/OBD/OBS importance, Fisher pruning, lottery-ticket-inspired tickets, and learned gating; analyze trade-offs in stability vs. quality.
- Mask recomputation frequency: Ablate stepwise recomputation vs. periodic updates (e.g., every k steps) to reduce overhead; quantify accuracy/flip-rate/cost trade-offs.
- Tie-breaking and grouping choices: Analyze robustness to different grouping axes (row/column, per-channel, per-head), block sizes, and deterministic tie-breaking policies for ternary ties.
- Alternatives to Dual STE: Investigate proximal/continuous relaxations (e.g., soft top-k, sparsemax, Gumbel-top-k), straight-through variants, or surrogate losses; quantify gradient bias/variance and convergence properties.
- Theory and guarantees: Formalize the “quantization-valley/magnitude stratification” hypothesis; provide theoretical understanding or guarantees for dynamic
N:Mprojection with dual STE and its convergence/stability. - Dense-to-sparse curricula: Design and test progressive schedules (e.g.,
8:8 → 7:8 → 6:8), adaptive triggers (loss/flip-rate-based), or sparsity warmups; identify best practices for switching points. - More aggressive sparsity: Extend robustness sweep to
1:4,1:8, and mixed patterns (hybridN:Macross layers); identify breakpoints and recovery strategies (e.g., auxiliary losses, rewinding). - Hardware portability and support: Benchmark on stock vendor libraries (cuBLASLt sparse, Hopper/Blackwell 2:4 cores), AMD ROCm, and TPU; evaluate how to map
6:8onto widely supported2:4hardware without custom kernels. - End-to-end system metrics: Report latency (single-token and batch), energy/power, peak and resident memory, memory bandwidth utilization, kernel fusion effects, and compile time; analyze serving scenarios (paged attention, KV paging).
- Storage and packing: Quantify real compression ratio including ternary packing +
N:Mmetadata; specify on-disk and in-memory formats and load-time overheads; compare to 3–4 bit dense baselines. - Distributed training at scale: Evaluate data- and model-parallel efficiency, communication overhead with ternary sparse weights, optimizer-state precision/size, and fault tolerance at multi-node scale.
- Stability and reproducibility: Report variance across seeds, failure/collapse rates, and sensitivity to hyperparameters (LR, wd, clipping, warmup); release full configs and ensure reproducibility without in-house kernels.
- Kernel generality: Provide public implementations or describe how to re-create the custom
6:8kernels; test portability across GPUs and driver/toolchain versions; compare to2:4speed on the same setup. - Comparison to alternative compression baselines: Benchmark against strong 3–4 bit dense methods (AWQ, GPTQ, SmoothQuant), block-sparse or structured pruning baselines with retraining, and hybrid schemes (quant + block/pruning).
- Compatibility with fine-tuning methods: Assess LoRA/QLoRA and adapter-based fine-tuning atop Sparse-BitNet (accuracy, stability, and memory), including PEFT on small datasets.
- Long-context behavior: Test stability and accuracy for ≥128k tokens (e.g., Needle-in-a-Haystack, LV-Eval), examining RoPE precision, attention stability, and KV-cache interactions under sparsity + ternarization.
- Safety and calibration: Evaluate calibration, uncertainty, toxicity, and jailbreak susceptibility under extreme compression; quantify impacts of ternary +
N:Mon safety-critical deployment. - Multimodal and non-causal settings: Extend to encoder-only, encoder–decoder, and multimodal transformers (vision-language, speech); analyze whether sparsity/ternary dynamics transfer to cross-attention and modality-specific towers.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage the paper’s findings (1.58-bit ternary weights + semi-structured N:M sparsity with dynamic masks and dual-STE), supported by today’s GPU ecosystems and standard software stacks.
- GPU cost and latency reduction for mid-size LLM inference (1–3B parameters)
- Sectors: software, finance, education, healthcare
- What: Serve customer support bots, tutoring agents, compliance summarizers, and clinical documentation assistants with Sparse-BitNet checkpoints to cut per-token latency and cost.
- Tools/workflows: Export N:M-sparse, ternary weight matrices with metadata; run on NVIDIA A100/Hopper/B200 with sparse kernels (e.g., custom 6:8, or vendor 2:4) integrated into PyTorch/Triton backends.
- Dependencies/assumptions: Speedups (up to 1.30×) observed with an in-house 6:8 kernel; production speedups depend on availability/quality of sparse kernels in your stack and the exact N:M pattern supported (2:4 widely supported on NVIDIA; 6:8 may require custom kernels). Some absolute accuracy loss versus dense BF16 remains; assess task tolerance.
- Faster prefill/decoding in retrieval-augmented pipelines and batch analytics
- Sectors: software, finance
- What: Use Sparse-BitNet for large-context prefill (RAG, summarization) and batched decode workloads to improve throughput (noted 1.09–1.30× ranges across seq length and batch sizes).
- Tools/workflows: Sequence-aware routing that selects sparse kernels for prefill-heavy phases; batching strategies tuned to exploit sparse tensor core efficiency.
- Dependencies/assumptions: Gains vary by sequence length, batch size, and hardware; profiling needed to hit the favorable regimes shown in the paper.
- On-premise desktop/server assistants on consumer or enterprise NVIDIA GPUs
- Sectors: daily life, software, education
- What: Run local voice/chat assistants, coding copilots, or study aids on gaming/workstation GPUs with lower latency and power draw.
- Tools/workflows: Fine-tune Sparse-BitNet models on domain data; deploy via CUDA backends that support semi-structured sparsity and INT8 activations.
- Dependencies/assumptions: Sparse kernel support and driver versions must align with the N:M pattern; quality trade-offs vs. larger cloud models.
- Domain-specific fine-tuning with sparse-aware quantization-aware training (QAT)
- Sectors: healthcare, finance, enterprise software
- What: Fine-tune BitNet + N:M models on proprietary corpora, exploiting the paper’s dynamic mask recomputation and dual-STE to maintain stability.
- Tools/workflows: Integrate the Sparse-BitLinear layer into PyTorch training; maintain dense master weights, recompute masks per step, quant-then-mask forward, STE through quantization and masks.
- Dependencies/assumptions: Sparse-from-scratch shows best results; dense-to-sparse works but needs sufficient sparse budget to avoid larger PPL penalties.
- Academic labs: cheaper training runs for methodology and ablation studies
- Sectors: academia/education
- What: Run more experiments per GPU-hour for pretraining, ablation studies (e.g., mask flip-rate analysis), and curriculum research on sparsity/quantization.
- Tools/workflows: Use provided code to replicate BitNet + N:M in small (0.5–3B) Qwen2.5-like backbones; monitor mask dynamics to study optimization behavior.
- Dependencies/assumptions: Results demonstrated at 0.5B–3B; care needed when extrapolating to larger models or different data mixtures.
- MLOps-ready model compression/export pipeline
- Sectors: software/DevOps
- What: Add a build step that exports N:M masks and ternary weights as deployment-ready artifacts (with metadata), validated against target kernels.
- Tools/workflows: CI checks for “N:M compliance,” mask stability (flip-rate), and regression tests on latency/accuracy; registries that tag models with N:M pattern and quantization scheme.
- Dependencies/assumptions: Requires standardized serialization of N:M metadata and availability of runtime kernels across environments.
- Cloud service SKUs optimized for semi-structured sparse + low-bit LLMs
- Sectors: cloud providers, energy
- What: Offer “sparse-LLM-optimized” instance types or inference endpoints leveraging sparse tensor cores, marketed with energy-per-token metrics.
- Tools/workflows: Autoscaling and placement policies that route compatible models to sparse-core-optimized nodes; billing aligned to lower energy/cost.
- Dependencies/assumptions: Customer models must adhere to supported N:M patterns; monitoring to ensure kernel coverage.
- Green-AI measurement and reporting
- Sectors: policy, energy, enterprise sustainability
- What: Quantify and report energy and emissions reductions from Sparse-BitNet deployments (tokens/J, kgCO2e/task).
- Tools/workflows: Integrate power telemetry with model serving and training logs; publish baselines and deltas for compliance and ESG reporting.
- Dependencies/assumptions: Accurate power/telemetry instrumentation; standardized reporting methods.
Long-Term Applications
These opportunities require additional research, engineering, or ecosystem adoption (e.g., hardware, software kernels, or validation on larger models and safety-critical tasks).
- Scale to larger instruction-tuned and multimodal LLMs (7B–70B+)
- Sectors: software, healthcare, finance, education
- What: Bring BitNet + N:M to LLMs that power high-end assistants and multimodal apps (e.g., document VQA, medical summarization).
- Tools/products: Sparse-BitNet variants of popular open models (Llama, Qwen, Mistral) with instruction tuning; distillation recipes to reduce accuracy gaps.
- Dependencies/assumptions: Demonstrations so far are 0.5–3B; scaling may introduce new stability/quality challenges and require refined recipes.
- Hardware co-design for ternary + semi-structured sparsity
- Sectors: semiconductors, robotics, mobile/edge
- What: NPUs/GPUs/ASICs that natively support ternary math and flexible N:M patterns (beyond 2:4), enabling larger speedups and lower power.
- Tools/products: Compiler support for mixed patterns (e.g., 6:8) and ternary accumulators; set-level scheduling for masked GEMMs.
- Dependencies/assumptions: Vendor roadmaps, standardization of N:M layouts; software ecosystem alignment (CUDA/cuBLAS/cuDNN, ROCm).
- Robust 2:4 deployment at high sparsity with minimal loss
- Sectors: cloud, robotics, embedded
- What: Achieve near BitNet’s robustness at the widely supported 2:4 pattern (50% sparsity) for production speedups on existing NVIDIA hardware.
- Tools/workflows: Training curricula that gradually increase sparsity, enhanced magnitude ranking, and improved mask stability under 2:4.
- Dependencies/assumptions: Paper shows strong BitNet robustness under sparsity sweeps; translating to high-accuracy 2:4 at scale needs more work.
- Federated and bandwidth-constrained training with ternary updates
- Sectors: mobile/edge, healthcare, finance (privacy-sensitive)
- What: Reduce communication by transmitting ternary weights/mask deltas during on-device or cross-site training.
- Tools/workflows: Compression-aware optimizers; secure aggregation of sparse, low-bit updates.
- Dependencies/assumptions: Convergence and privacy guarantees under aggressive quantization/sparsity; device-side kernel support.
- Robotics and autonomous systems with real-time onboard LLMs
- Sectors: robotics, automotive
- What: Run planning/interaction LLMs on Jetson/edge GPUs with structured sparsity and low-bit weights for latency and energy constraints.
- Tools/workflows: 2:4 sparse kernels optimized for embedded NVIDIA platforms; co-design with control stacks.
- Dependencies/assumptions: Verified kernel support and thermal envelopes on embedded devices; task-specific fine-tuning.
- End-to-end compiler and runtime stacks for N:M-aware LLMs
- Sectors: software infrastructure
- What: Graph compilers that propagate N:M metadata, schedule sparse kernels, autotune block sizes, and fuse quant-then-mask ops.
- Tools/products: XLA/TensorRT/Triton passes that select sparse paths; profilers that attribute gains to sparsity and guide pattern selection.
- Dependencies/assumptions: Stable operator sets and IRs that model semi-structured sparsity; broad backend support.
- Safety-critical deployments with validated accuracy and robustness
- Sectors: healthcare, finance, public sector
- What: Use Sparse-BitNet models for decision support where reliability is paramount, after rigorous validation and monitoring.
- Tools/workflows: Conformance tests, bias/robustness audits, shadow deployments, and fallback strategies.
- Dependencies/assumptions: Evidence that quantization+sparsity does not adversely affect domain-specific safety metrics; regulatory acceptance.
- Interpretable model analysis via magnitude stratification
- Sectors: academia, policy
- What: Use the paper’s observed “magnitude stratification” to study which weights carry signal vs. redundancy, informing compression policies and interpretability research.
- Tools/workflows: Visualization and analysis suites that track per-block thresholds, mask flip-rates, and tri-modal distributions over training.
- Dependencies/assumptions: Correlation between magnitude structure and semantic function must be established for each task/model.
- Hybrid efficiency stacks (MoE + sparsity + low-bit + KV compression)
- Sectors: cloud, software
- What: Combine Sparse-BitNet with mixture-of-experts routing, KV cache compression, and operator fusion for compounded gains.
- Tools/workflows: Scheduling that coordinates expert sparsity with per-layer N:M; memory planners aware of ternary weights and sparse metadata.
- Dependencies/assumptions: Complex interactions may affect stability and quality; extensive profiling and new algorithms required.
- Procurement and policy that incentivize energy-efficient AI
- Sectors: policy, public sector, enterprise governance
- What: Guidelines and incentives for using semi-structured sparsity and low-bit quantization in public tenders and ESG frameworks.
- Tools/workflows: Compliance checklists (tokens/J, CO2e/task), third-party verification of sparse/low-bit claims.
- Dependencies/assumptions: Standardized metrics and auditing; market availability of compliant models and hardware.
Notes on feasibility:
- Hardware alignment matters: 2:4 sparsity is widely supported by NVIDIA; 6:8 requires custom kernels (as in the paper) or future vendor support.
- Training stability depends on recipe details: compute masks from dense master weights, quant-then-mask in forward, and allow dense gradient flow (dual STE).
- Accuracy trade-offs are task-dependent: BitNet has higher baseline PPL than dense BF16 but degrades less under sparsity; validate on your tasks before migration.
- Results are shown on 0.5B–3B Qwen2.5-like models and specific datasets; extrapolation to larger or different models requires additional testing.
Glossary
- 1.58-bit BitNet: An extremely low-bit LLM architecture that constrains weights to three values (−1, 0, +1), achieving about 1.58 bits per parameter. "1.58-bit BitNet is naturally more compatible with N:M sparsity than full-precision models."
- 2:4 pattern: A semi-structured sparsity scheme that keeps at most 2 non-zero weights in every group of 4. "Semi-structured N:M sparsity, particularly the widely supported 2:4 pattern"
- 6:8 pattern: A semi-structured sparsity scheme that keeps 6 non-zero weights in every group of 8 (25% sparsity). "In this work, we focus on the pattern ( sparsity)"
- absmax scaling: A method that scales activations by their maximum absolute value to map them into an 8-bit range for quantization. "Activations are quantized to 8-bit integers using absmax scaling: $\tilde{\mathbf{x} = \mathrm{Quant}(\mathbf{x}) = \mathrm{Clip}(\mathbf{x} \cdot \frac{127}{\max(|\mathbf{x}|) + \epsilon}, -128, 127)$."
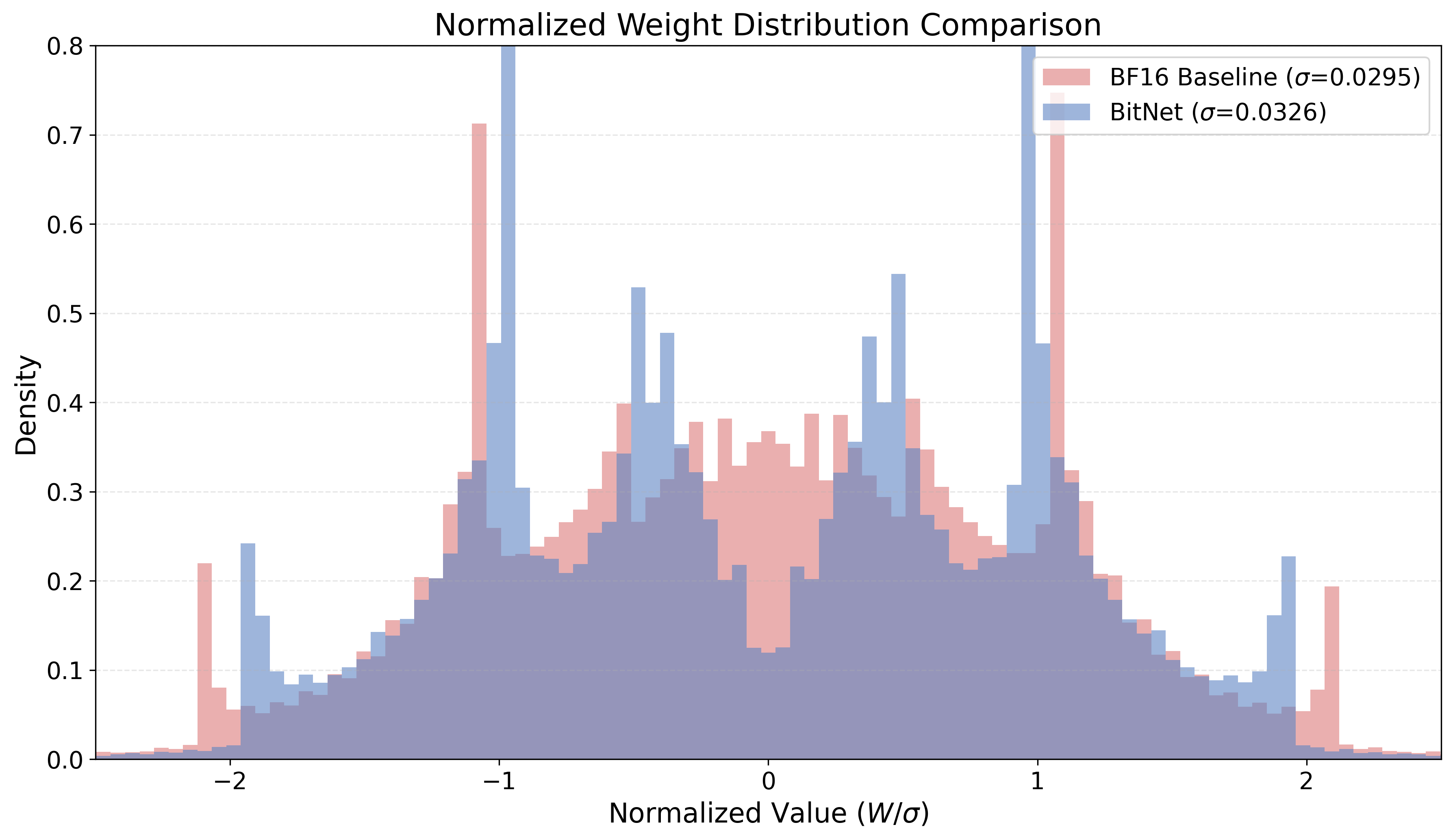
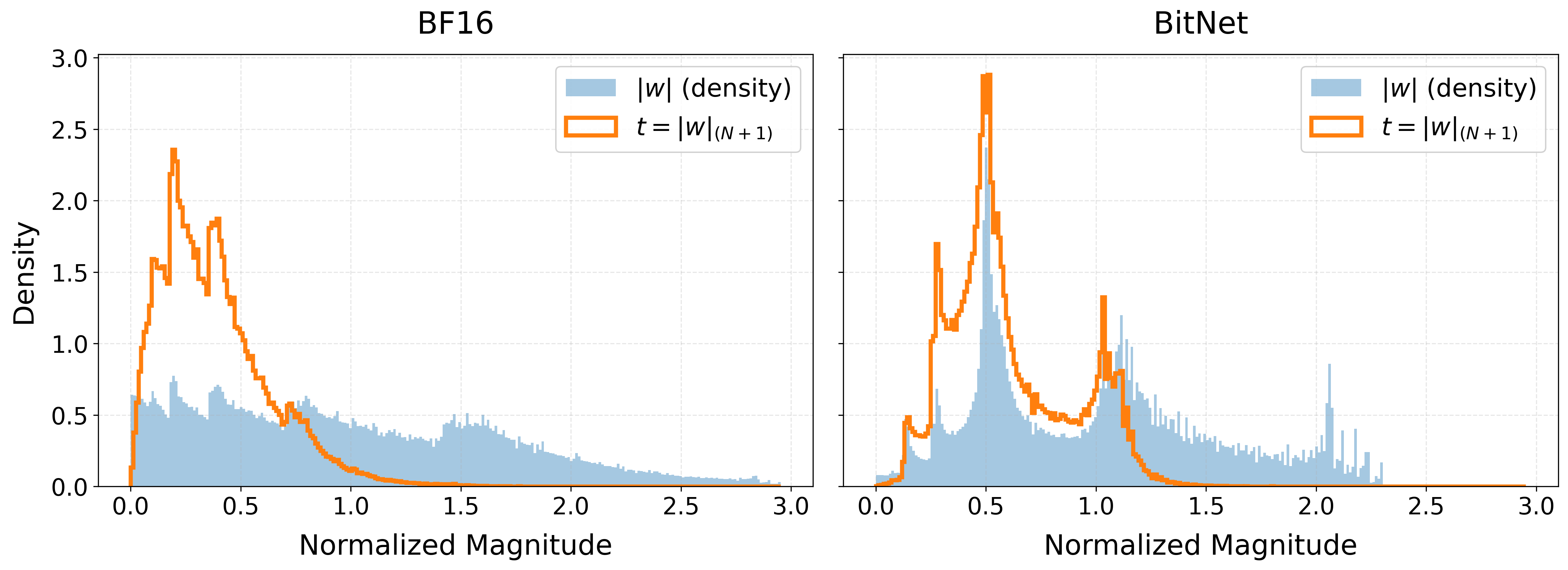
- BF16: A 16-bit floating-point format (bfloat16) used for reduced-precision training and inference. "we compare the sparsity-friendliness of 1.58-bit BitNet and BF16 models under two settings:"
- BitLinear: The quantized linear layer used as the fundamental building block in BitNet architectures. "The fundamental building block is the BitLinear layer."
- causal language modeling: A training objective where a model predicts the next token given previous tokens. "The training objective is standard causal language modeling (next-token prediction)."
- dense-to-sparse training schedule: A training regime that begins with dense weights and later switches to an N:M sparse regime. "and (2) dense-to-sparse training schedules that switch from dense to N:M sparse training at different stages."
- Dual Straight-Through Estimator (STE): A gradient approximation technique that passes gradients through both the quantizer and the non-differentiable mask. "We employ a Dual Straight-Through Estimator (STE) approach."
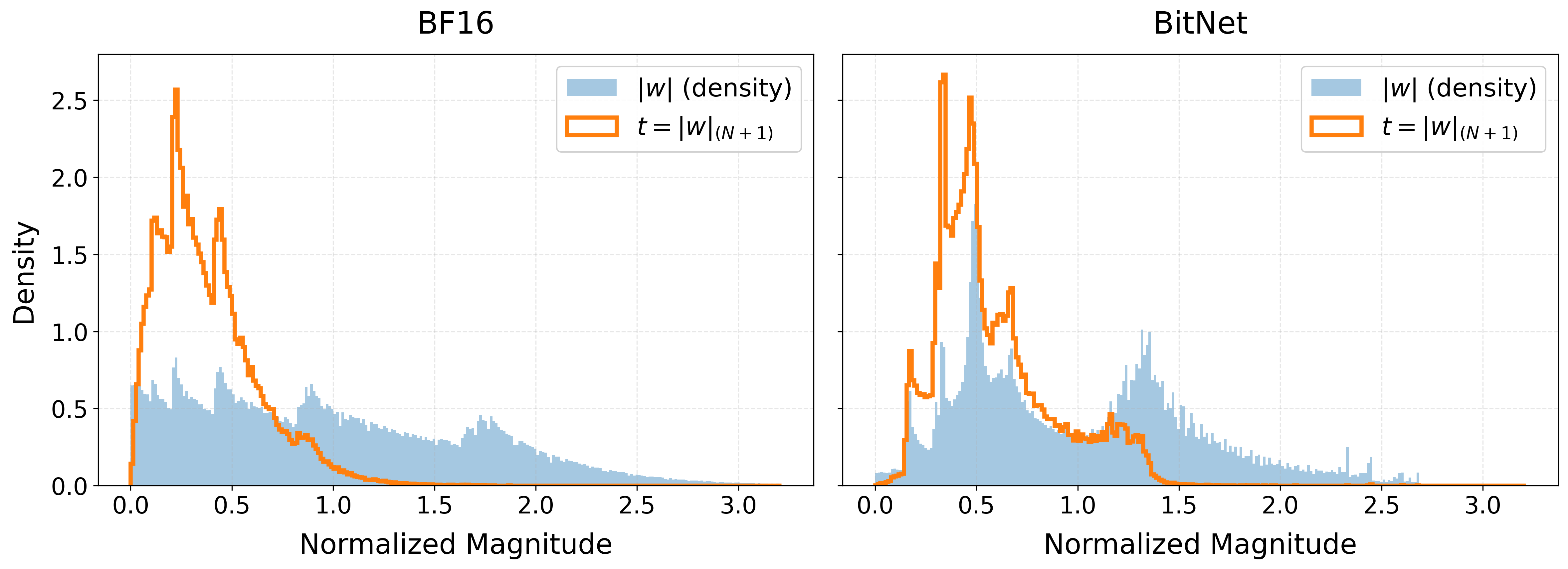
- magnitude pruning: Pruning that retains the highest-magnitude weights within each group while zeroing the rest. "We employ magnitude pruning: for every contiguous group of size , we select the indices of the largest absolute values."
- magnitude stratification: The separation of weights into distinct magnitude bands (e.g., near-zero vs. high-magnitude), aiding stable sparsification. "exhibits a phenomenon we term magnitude stratification."
- mask flip rate: The fraction of mask entries that change between consecutive training steps, indicating sparsity pattern dynamics. "we monitor the mask flip rate following prior work~\cite{hu2024accelerating}."
- NVIDIA Sparse Tensor Cores: Specialized GPU units that accelerate matrix multiplications under supported structured sparsity patterns. "accelerate matrix multiplication on NVIDIA Sparse Tensor Cores"
- Perplexity (PPL): A standard language modeling metric indicating how well a model predicts a sample; lower is better. "Perplexity (PPL) degradation analysis."
- prefill phase: The initial inference stage that processes the input sequence to build key–value caches before token-by-token decoding. "report performance metrics for the prefill phase on an NVIDIA A100 GPU and the decoding phase on a B200 GPU."
- projected optimization approach: An optimization method that repeatedly projects parameters onto a constraint set (e.g., N:M sparsity) during training. "This corresponds to a projected optimization approach where the discrete constraint is re-evaluated continuously,"
- quantization-valley structure: A weight distribution pattern with a dominant low-magnitude “valley” induced by quantization. "The distribution of normalized latent weights exhibits a distinct quantization-valley structure"
- Semi-structured N:M sparsity: A fine-grained sparsity constraint allowing at most N non-zeros in every group of M consecutive weights. "Semi-structured N:M sparsity, particularly the widely supported 2:4 pattern"
- Sparse-BitLinear: A linear layer that composes ternary quantization with N:M masking into a single trainable operator. "Sparse-BitNet replaces standard linear projections with the Sparse-BitLinear layer."
- Sparse-BitNet: The paper’s framework that jointly enforces ternary (1.58-bit) quantization and semi-structured N:M sparsity during training. "we propose Sparse-BitNet, a unified framework that jointly applies 1.58-bit quantization and dynamic N:M sparsification"
- ternary quantization: Quantizing weights to three discrete values (−1, 0, +1) to reduce precision and computation. "integrates semi-structured sparsity into the ternary quantization training landscape."
- Top-N selection: Selecting the N largest-magnitude elements within each group to determine which weights remain unpruned. "both ternary quantization and dynamic top- selection are non-differentiable"
Collections
Sign up for free to add this paper to one or more collections.