Dark3R: Learning Structure from Motion in the Dark
Abstract: We introduce Dark3R, a framework for structure from motion in the dark that operates directly on raw images with signal-to-noise ratios (SNRs) below $-4$ dB -- a regime where conventional feature- and learning-based methods break down. Our key insight is to adapt large-scale 3D foundation models to extreme low-light conditions through a teacher--student distillation process, enabling robust feature matching and camera pose estimation in low light. Dark3R requires no 3D supervision; it is trained solely on noisy--clean raw image pairs, which can be either captured directly or synthesized using a simple Poisson--Gaussian noise model applied to well-exposed raw images. To train and evaluate our approach, we introduce a new, exposure-bracketed dataset that includes $\sim$42,000 multi-view raw images with ground-truth 3D annotations, and we demonstrate that Dark3R achieves state-of-the-art structure from motion in the low-SNR regime. Further, we demonstrate state-of-the-art novel view synthesis in the dark using Dark3R's predicted poses and a coarse-to-fine radiance field optimization procedure.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Dark3R, a method that helps computers build 3D models and figure out where a camera moved—using photos taken in very dark places. It works directly on “raw” camera data that looks extremely noisy to us and is almost useless for regular 3D methods. Dark3R can also create new, realistic views of a scene from angles where no photo was taken.
What questions were they trying to answer?
The researchers focused on three simple questions:
- Can we make 3D reconstruction and camera pose estimation work when photos are so dark and noisy that most methods fail?
- Can we adapt powerful existing 3D vision models to handle low-light images without needing expensive 3D labels?
- Once we have camera poses from very dark images, can we also synthesize high-quality new views of the scene?
How did they do it?
First, a few ideas in everyday language:
- Structure from Motion (SfM): Imagine you walk around an object taking lots of photos. SfM figures out how your camera moved (its “pose”) and where points in the scene are in 3D, just by comparing the photos.
- Raw images: These are the camera’s unprocessed measurements, like the “ingredients” before the camera cooks them into a normal photo. Raw images keep more information, which helps in the dark.
- SNR (Signal-to-Noise Ratio): Think of signal as the real picture and noise as TV static. Low SNR means the static is louder than the picture. The paper tackles very low SNR—so dark that the “static” beats the signal.
Here’s their approach in simple steps:
- They start from a large, pre-trained 3D vision model (called MASt3R) that’s very good at finding matching points between image pairs and estimating geometry—but only in normal lighting.
- They use a “teacher–student” learning idea:
- Teacher: runs on clean, well-exposed image pairs and produces high-quality internal features and matches.
- Student: sees the same scene but in low-light, noisy images. It learns to produce features and matches that look like the teacher’s, even though its inputs are much noisier.
- Why this helps: The student learns how to “see through” noise by copying the teacher’s behavior, without needing 3D ground-truth labels.
- Training data:
- They use pairs of clean and noisy raw images. The noisy ones come either from real low-light captures or by simulating realistic camera noise on bright images (using a simple noise model).
- After training, Dark3R:
- Finds matching points and estimates camera poses from very noisy raw images.
- Feeds those into a standard global optimization step (like bundle adjustment) to refine the 3D structure and camera paths.
They also show how to create new views (novel view synthesis) in the dark:
- They use a NeRF-like method (a neural “radiance field”) that learns how light and color exist throughout the scene.
- To avoid fitting to noise, they:
- Start coarse and get finer over time.
- Add small randomness to sampling (“stochastic preconditioning”) so the model doesn’t cling to noisy pixels.
- Guide the NeRF with the rough depth estimates from Dark3R, then gradually rely less on that guidance as details improve.
- They keep everything in raw format (no clipping away faint signals), which preserves useful information in very dark conditions.
What did they find, and why is it important?
The main findings:
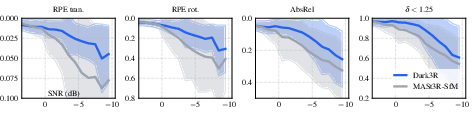
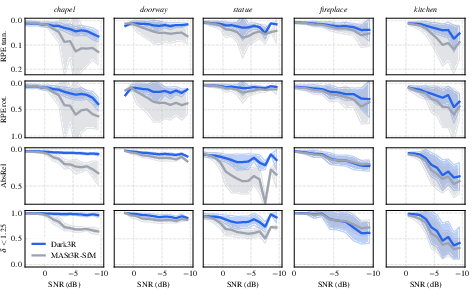
- Better camera poses in the dark: When images are extremely noisy (SNR below 0 dB, even around −4 to −5 dB), many methods break. Dark3R still recovers camera motion and 3D structure much more reliably.
- Stronger feature matching: Dark3R can find corresponding points between views in both bright and very dark images, where earlier methods fail.
- High-quality novel views: Using Dark3R’s poses and their coarse-to-fine NeRF training, they produce cleaner, more detailed new views from dark image sets than competing methods.
- No 3D labels needed: Dark3R learns from clean–noisy image pairs and a simple noise model—no costly 3D supervision required.
- New dataset: They collected about 42,000 multi-view raw images with exposure bracketing (multiple brightness levels per viewpoint) and accurate references, plus ~20,000 additional high-quality images. This helps others evaluate and train low-light 3D methods.
Why this matters:
- Most 3D vision pipelines depend on finding features in images. In the dark, those features vanish in the noise. Dark3R adapts a big 3D model to handle darkness, which keeps the whole 3D pipeline working when light is scarce.
What could this mean for the future?
Dark3R opens up 3D vision in places where it was previously unreliable:
- Nighttime robotics or drones that need to map and navigate with little light.
- Film, photography, and VR/AR capturing sets or scenes in low light without extra lighting.
- Cultural heritage or scientific fieldwork where you can’t add strong lighting.
- Smartphones and consumer cameras capturing better 3D in dim conditions.
The authors suggest future directions like adapting other large models to raw, low-light images, handling dynamic (moving) scenes in the dark, and combining with generative AI to improve quality even further. Overall, this research shows that with the right training strategy, we can push passive 3D vision into lighting conditions that used to be off-limits.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, written to help future researchers act on it:
- Sensor generalization: Validate robustness across a broader set of sensors, lenses, and CFA patterns (e.g., different Bayer layouts, Quad Bayer, X-Trans), including compact cameras and diverse smartphones, beyond a Sony Alpha I and one iPhone device.
- Noise model fidelity: Assess sensitivity to noise-model mismatch (training uses Poisson–Gaussian) and incorporate additional real low-light artifacts (fixed-pattern noise, PRNU, dark current drift, hot pixels, amplifier glow, quantization, column noise, heteroscedasticity).
- Raw-domain preprocessing: Replace the crude “subsampled Bayer + averaged greens” demosaicing with a learnable mosaic-to-feature front-end; evaluate how full-resolution demosaicing, joint demosaicing-feature learning, or per-sensor ISP emulation affect matching and pose accuracy.
- Photometric calibration in the raw domain: Integrate estimation of per-frame black level, gain, and white balance in the pipeline to avoid post-hoc per-channel scale/shift alignment and improve cross-scene consistency.
- Teacher supervision reliability: Detect and down-weight erroneous MASt3R teacher features on clean images (e.g., textureless, repetitive, or reflective regions); quantify how teacher errors propagate to the student and downstream SfM.
- Dependence on clean–noisy pairs: Reduce reliance on paired clean/noisy views by exploring self-supervised or multi-view geometric consistency losses that learn directly from only noisy sequences.
- Confidence/uncertainty distillation: MASt3R provides confidence maps, but the training objective distills only features/correspondences; investigate distilling uncertainty and using it to weight bundle adjustment (BA) and NeRF losses under noise.
- Assumed known intrinsics and distortion: Improve robustness when intrinsics are unknown or time-varying (zoom, focus breathing), and explicitly model lens distortion and rolling-shutter effects during pose estimation and BA.
- Motion blur and rolling shutter: Evaluate and extend the method to low-light conditions with handshake-induced blur and rolling-shutter distortions, including training with blur/noise augmentation and blur-aware feature matching.
- Dynamic scenes: Extend to scenes with independently moving objects and nonrigid motion (dynamic SfM/SLAM in the dark), including motion segmentation and time-varying radiance-field modeling.
- SNR limits and sample complexity: Characterize the minimal SNR and number of views needed for reliable pose/structure recovery; provide theoretical/empirical failure thresholds and performance–SNR trade-off curves across scene types.
- Scalability to large image sets: The pairwise similarity graph and BA scale poorly; develop hierarchical, keyframe-based, or amortized strategies for thousands of images with bounded memory/compute.
- Real-time/edge deployment: Profile and reduce inference cost (feature extraction, graph building, BA), and investigate lighter backbones, quantization, or distillation for on-device or real-time operation.
- Resolution vs. SNR trade-offs: All experiments downsample to 512×352 (16× binning increases SNR); evaluate performance at native resolutions (up to 50 MP), and study how different binning factors alter feature quality and pose accuracy.
- Covisibility and pair selection under noise: Design more robust, low-SNR-aware image-pair selection/covisibility heuristics to reduce outliers and unnecessary pairwise comparisons in graph construction.
- NeRF under low-light noise: Go beyond a standard photometric loss by incorporating heteroscedastic, per-ray noise models and uncertainty-weighted rendering; explore joint denoising–rendering objectives.
- 3D representation choice: Investigate noise-aware adaptations of 3D Gaussian Splatting (3DGS) or hybrid NeRF–3DGS methods specifically for low SNR, addressing the reported optimization difficulties.
- Joint optimization: Move from a sequential (poses → NeRF) to a joint, end-to-end optimization of poses, depths, and radiance under low-light noise, leveraging both geometric and photometric constraints.
- Out-of-distribution lighting: Evaluate robustness on outdoor night scenes with point light sources, severe HDR, lens flare/ghosting, and strong specularities, and incorporate flare/ghost models if needed.
- Exposure variability: Handle per-frame exposure/ISO changes (auto-exposure/gain) within a sequence by explicitly modeling exposure metadata or learning exposure-invariant features.
- Low-texture and repeated patterns: Devise feature priors or generative shape/texture priors to disambiguate correspondences on texture-poor or repetitive surfaces under heavy noise.
- LoRA design and adaptation strategy: Systematically study the effect of LoRA rank, which layers to adapt, and catastrophic forgetting across SNRs; compare to full fine-tuning and adapter-based alternatives.
- Ground-truth limitations: Current evaluation uses COLMAP on clean exposures as “reference”; collect or align to metric ground truth (e.g., LiDAR/laser tracker) to quantify absolute accuracy and scale.
- Dataset scope and availability: Increase diversity (outdoor/nighttime, materials, motion, sensors), document public release status, and provide standardized benchmarks for low-light SfM and view synthesis.
- Robustness to ISP-heavy inputs: Although the method operates on raw, many real deployments may lack raw access; assess how to adapt/compensate for unknown ISP pipelines or learn to “unprocess” sRGB under extreme low light.
- Failure-mode analysis: Provide detailed diagnostics for typical failure cases (e.g., extreme darkness, heavy blur, low texture, incorrect intrinsics), enabling targeted improvements and robust fallback strategies.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, given access to raw image data and offline compute.
- Low-light photogrammetry for film/TV and VFX (media/entertainment)
- What: Recover camera poses and sparse depth from dimly lit handheld takes where markers are hard to see; improve matchmoving and scene layout for compositing.
- Tools/products/workflows: Integrate Dark3R-SfM as a pose-estimation preprocessor feeding existing pipelines (e.g., MASt3R-SfM/ COLMAP for BA; export to Unreal/Unity or DCCs). Use Dark3R-NeRF for view synthesis and HDR plates.
- Assumptions/dependencies: Access to RAW or minimally processed linear data; static sets or controlled actor motion; known camera intrinsics or good calibration; offline processing time.
- Forensic and security scene reconstruction (public safety, legal tech)
- What: Build 3D reconstructions from low-light CCTV/body-cam sequences without additional illumination that could contaminate scenes.
- Tools/products/workflows: A “Forensic Low-Light Reconstruction” module that ingests RAW/high-bit-depth frames, applies Dark3R for poses, then runs BA and NeRF for photorealistic novel views; export scaled point clouds for measurement.
- Assumptions/dependencies: Chain-of-custody workflows; camera intrinsics availability or calibration targets; RAW or minimally processed data availability; static scenes or careful frame selection.
- Cultural heritage and archaeology scanning (museums, non-profits)
- What: Non-invasive 3D digitization in caves, tombs, or fragile interiors with minimal illumination; HDR reconstructions.
- Tools/products/workflows: DSLR/mirrorless RAW capture with exposure bracketing; Dark3R for pose/depth; Dark3R-NeRF for HDR view synthesis; tone mapping for publication.
- Assumptions/dependencies: Static scenes; tripod support preferred; RAW capture; institutional approval for low-light capture.
- Industrial inspection in dark environments (energy, manufacturing, mining)
- What: Map equipment and infrastructure in tunnels, shafts, or unlit zones where bright lighting is costly or unsafe.
- Tools/products/workflows: Rugged cameras capturing RAW; Dark3R for pose graph and sparse geometry; NeRF or 3DGS back-ends for textured models; integration with CAD/BIM and CMMS.
- Assumptions/dependencies: Minimal motion in scene; sensor access to RAW; operator safety; offline compute on-prem or cloud.
- Smartphone “Night 3D Scan” mode (consumer software/AR)
- What: Capture 3D assets and room scans at night from handheld phones that support RAW (e.g., ProRAW/DNG).
- Tools/products/workflows: Mobile app capturing RAW bursts, cloud/off-device processing with Dark3R for poses and Dark3R-NeRF for textured assets; export to USDZ/glTF for AR.
- Assumptions/dependencies: Device RAW support; privacy controls for cloud processing; static scenes; battery/network constraints.
- Novel view synthesis for low-light real estate and event marketing (media/marketing)
- What: Produce twilight/ambient-light walkthroughs and hero images from minimally lit captures.
- Tools/products/workflows: Dark3R for poses and Dark3R-NeRF for photorealistic renderings; deliver HDR/tone-mapped sRGB for listings and promos.
- Assumptions/dependencies: RAW capture; static interiors; time for iterative optimization.
- Academic benchmarking and training (academia)
- What: Use the ~63k-image low-light multi-view dataset and Poisson–Gaussian noise strategy to benchmark and train low-light SfM/NeRF.
- Tools/products/workflows: Teacher–student distillation on noisy–clean RAW pairs; LoRA finetuning of 3D foundation models; standardized metrics (ATE, RPE, AbsRel, PSNR/SSIM/LPIPS).
- Assumptions/dependencies: Dataset license/availability; compute (multi-GPU) for training and BA.
- Offline mapping from low-light mission logs (robotics)
- What: Improve post-mission maps from dim camera logs (UGVs/UAVs in mines, tunnels, or after-hours warehouses).
- Tools/products/workflows: Run Dark3R on recorded RAW frames to produce a refined pose graph and sparse geometry; feed into existing SLAM back-ends for loop closures and map refinement.
- Assumptions/dependencies: Availability of RAW or linear camera logs; offline processing acceptable; static environments or careful selection of frames minimizing dynamic content.
- HDR reconstruction from RAW in the dark (imaging/software)
- What: Generate HDR radiance-field reconstructions directly from RAW inputs without black-level clipping, preserving scene DR.
- Tools/products/workflows: Dark3R-NeRF with depth supervision and stochastic preconditioning; tone mapping; export HDR panoramas.
- Assumptions/dependencies: RAW access; static scenes; ISP bypass or linearized pipeline.
Long-Term Applications
These applications require further research, engineering, or ecosystem adoption (e.g., real-time performance, dynamic scenes, embedded deployment).
- Real-time low-light visual SLAM for robots and AR (robotics, XR)
- What: Online, low-latency pose and mapping under extreme darkness for navigation and AR occlusion.
- Tools/products/workflows: Streamable, incremental versions of Dark3R with IMU fusion; embedded inference on mobile/edge; fast BA or factor-graph optimization.
- Assumptions/dependencies: Algorithmic changes for incremental updates; model compression/distillation; robustness to motion blur and dynamic objects.
- Night-time autonomous operation and delivery (mobility/logistics)
- What: Robust low-light camera-based localization and mapping to complement LiDAR/radar for cost/energy savings.
- Tools/products/workflows: Multi-sensor fusion stacks; low-light-adapted 3D foundation models; certifiable performance monitoring.
- Assumptions/dependencies: High-speed motion handling; automotive-grade sensors and RAW access; safety certification and validation.
- In-camera low-light SfM and 3D capture (camera/phone OEMs)
- What: ISP/firmware integration for on-device “dark photogrammetry”—poses, sparse depth, and 3D assets captured in-camera.
- Tools/products/workflows: Vendor access to RAW pipeline; NPU/ISP co-design; LoRA-adapted backbones for power-latency budgets.
- Assumptions/dependencies: OEM adoption; thermal/power constraints; privacy and storage management.
- Low-photon 3D in underwater, planetary, or space settings (aerospace, marine)
- What: Passive 3D reconstruction with severe photon budgets and distinct noise/color physics.
- Tools/products/workflows: Domain-adapted noise models; training on mission-specific sensors; radiation-/pressure-hardened hardware.
- Assumptions/dependencies: Access to domain data for distillation; specialized calibrations; modified photometric models.
- Dynamic-scene low-light reconstruction (software, research)
- What: Handle moving people/objects in the dark with dynamic radiance fields and correspondence models.
- Tools/products/workflows: Dynamic NeRFs/GS, segmentation and motion compensation, temporal consistency losses.
- Assumptions/dependencies: New datasets with low-light dynamics; computational budget; robust feature tracking under noise.
- Privacy- and energy-conscious monitoring (policy, smart buildings)
- What: Reduce illumination needs for compliant monitoring and documentation, lowering energy use and light pollution.
- Tools/products/workflows: Facility standards that allow passive low-light 3D documentation; procedures to minimize identifiable detail and ensure data governance.
- Assumptions/dependencies: Independent accuracy validation; privacy impact assessments; updates to building/energy codes.
- Low-light 3D in medical and scientific imaging (healthcare, life sciences)
- What: 3D reconstruction under phototoxicity constraints (e.g., multi-view microscopy) or minimally lit endoscopy.
- Tools/products/workflows: Adaptation to microscope/endoscope RAW data and optics; model-based priors exploiting instrument geometry.
- Assumptions/dependencies: Different noise/PSF characteristics; clinical validation; regulatory approval.
- Edge analytics for security cameras (security/IoT)
- What: Real-time 3D context from dim scenes for improved tracking, PTZ control, and incident localization.
- Tools/products/workflows: Low-light SfM inference on camera SoCs; pose-graph services for VMS backends; optional NeRF snapshots for evidence review.
- Assumptions/dependencies: Hardware accelerators on cameras; vendor APIs for RAW; legal/compliance requirements.
- Mass digitization with minimal lighting (museums, archives)
- What: After-hours fleet capture of galleries and storage rooms with very low illumination to protect artifacts.
- Tools/products/workflows: Coordinated capture rigs; batched Dark3R processing; museum DAM integration.
- Assumptions/dependencies: Operational policy changes; capture scheduling; quality control workflows.
Cross-cutting assumptions and dependencies
- RAW access and linear data: Dark3R operates in RAW; many consumer devices limit RAW or apply non-linear processing. Domain gaps may require per-sensor adaptation or noise-model calibration.
- Known intrinsics: The method assumes calibrated intrinsics (bundle adjustment regularizes to calibrated values). Unknown intrinsics reduce accuracy unless estimated reliably.
- Static scenes: Current results assume static scenes; dynamic content requires future extensions.
- Compute and latency: Inference relies on global reconstruction and BA; NeRF optimization takes tens of thousands of iterations. Many use cases are offline today; real-time variants need engineering.
- Generalization: The team shows promising cross-device generalization (e.g., iPhone 16), but broad deployment benefits from light per-sensor finetuning using noisy–clean RAW pairs or simulated noise aligned with each camera’s Poisson–Gaussian model.
- Ethical and legal: For surveillance/forensics, ensure lawful use, privacy protection, and auditability; for heritage, adhere to non-invasive capture policies.
Glossary
- 3D foundation models: Large pretrained vision models that provide strong priors for 3D geometry and correspondence. "3D foundation models"
- Absolute relative depth error (AbsRel): A depth metric measuring average relative error between predicted and reference depths. "absolute relative depth error (AbsRel)"
- Absolute translation error (ATE): A metric evaluating global translation drift between estimated and reference camera trajectories. "absolute translation error (ATE)"
- Bayer mosaic: The color filter array pattern on image sensors used to capture raw color data. "Bayer mosaic"
- Black-level subtraction: Removing the sensor’s baseline offset from raw data before further processing. "black-level subtraction"
- Brightness constancy: The assumption that pixel intensities of the same scene point remain constant across frames. "brightness constancy"
- Bundle adjustment: Joint optimization of camera poses and 3D points to minimize reprojection errors. "bundle adjustment"
- Burst denoising: Denoising technique that jointly processes rapid image sequences to improve quality. "burst denoising"
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) used for calibration. "camera intrinsics"
- Co-visibility graph: A graph linking image pairs likely to observe overlapping scene regions for reconstruction. "co-visibility graph"
- Coarse-to-fine optimization: An optimization strategy that starts with coarse approximations and refines details progressively. "coarse-to-fine optimization"
- COLMAP: A widely used structure-from-motion and multi-view stereo pipeline for pose and geometry estimation. "COLMAP"
- Correspondence map: A per-pixel feature representation used to establish matches between image pairs. "correspondence map"
- Demosaiced: The process of reconstructing full-color images from mosaic sensor measurements. "demosaiced"
- Depth regularization: A loss or constraint encouraging reconstructed depths to agree with prior or auxiliary depth information. "depth regularization"
- Differentiable RANSAC: A version of RANSAC that allows gradient-based learning for robust model estimation. "differentiable RANSAC"
- Epipolar geometry: The geometric relationship between two calibrated views governing where matches must lie. "epipolar geometry"
- Essential matrix: A matrix encoding relative rotation and translation between two calibrated cameras. "essential matrix"
- Exposure bracketing: Capturing multiple exposures per viewpoint to span a wide dynamic range. "exposure bracketing"
- EV (exposure value): A logarithmic measure of exposure steps used in bracketing and camera settings. "0.7\,EV per step"
- Gaussian splatting: A rendering/reconstruction technique representing scenes with 3D Gaussians. "Gaussian splatting"
- Image signal processor (ISP): The processing pipeline that converts raw sensor data to display-ready images. "image signal processor (ISP)"
- LPIPS (learned perceptual image patch similarity): A perceptual metric using deep features to assess visual similarity. "learned perceptual image patch similarity (LPIPS)"
- Lux: A unit of illuminance indicating scene lighting levels. "1--15 lux"
- Low-rank adaptation (LoRA): A parameter-efficient fine-tuning method using low-rank updates to pretrained weights. "low-rank adaptation"
- Monocular depth estimators: Models that predict depth from a single image using learned priors. "monocular depth estimators"
- Neural radiance field (NeRF): A volumetric function mapping position and view direction to color and density for rendering. "NeRF-based representation"
- Novel view synthesis: Rendering images from new camera viewpoints given a learned scene representation. "novel view synthesis"
- Parallax: Apparent displacement of scene points due to camera motion, enabling depth perception. "substantial parallax"
- PSNR (peak signal-to-noise ratio): A logarithmic image quality metric comparing reconstruction to a reference. "peak signal-to-noise ratio (PSNR)"
- Photometric consistency cost: An objective that aligns images by minimizing intensity differences across views. "optimize a photometric consistency cost"
- Poisson–Gaussian noise model: A noise model combining photon shot noise (Poisson) and read noise (Gaussian). "PoissonâGaussian noise model"
- Putative matches: Tentative correspondences identified before geometric verification and filtering. "putative matches"
- Radiance field: A continuous representation of how light is emitted or transmitted through 3D space. "radiance field"
- Relative pose error (RPE): A metric measuring frame-to-frame pose errors, often split into translation and rotation. "relative pose error in translation (RPE~tran.), relative pose error in rotation (RPE~rot.)"
- Reprojection error: The 2D discrepancy between observed image points and projections of estimated 3D points. "the reprojection error"
- Scene graph: A graph structure encoding relationships between images (views) for global reconstruction. "construct a scene graph"
- Siamese ViT decoder: A weight-sharing decoder architecture that processes paired inputs jointly. "Siamese ViT decoder"
- Signal-to-noise ratio (SNR): The ratio of signal strength to noise, often in decibels, indicating image quality. "signal-to-noise ratio (SNR)"
- Sim(3) alignment: Alignment under a similarity transform (rotation, translation, and global scale). "after Sim(3) alignment"
- Stochastic preconditioning: Adding controlled noise to optimization (e.g., ray samples) to improve convergence. "stochastic preconditioning"
- Structure from motion (SfM): Recovering 3D structure and camera motion from multiple images. "structure from motion (SfM)"
- Symmetric epipolar distance (SED): A measure of how well correspondences satisfy epipolar constraints in both directions. "symmetric epipolar distance (SED)"
- Teacher–student knowledge distillation: Training a student model to mimic a teacher’s features or outputs. "teacherâstudent knowledge distillation"
- Triangulation: Computing 3D point positions by intersecting rays from multiple calibrated views. "triangulation"
- Vision transformer (ViT): A transformer-based architecture applied to images for feature extraction. "vision transformer (ViT)"
Collections
Sign up for free to add this paper to one or more collections.