Progressive Residual Warmup for Language Model Pretraining
Published 5 Mar 2026 in cs.CL | (2603.05369v1)
Abstract: Transformer architectures serve as the backbone for most modern LLMs, therefore their pretraining stability and convergence speed are of central concern. Motivated by the logical dependency of sequentially stacked layers, we propose Progressive Residual Warmup (ProRes) for LLM pretraining. ProRes implements an "early layer learns first" philosophy by multiplying each layer's residual with a scalar that gradually warms up from 0 to 1, with deeper layers taking longer warmup steps. In this way, deeper layers wait for early layers to settle into a more stable regime before contributing to learning. We demonstrate the effectiveness of ProRes through pretraining experiments across various model scales, as well as normalization and initialization schemes. Comprehensive analysis shows that ProRes not only stabilizes pretraining but also introduces a unique optimization trajectory, leading to faster convergence, stronger generalization and better downstream performance. Our code is available at https://github.com/dandingsky/ProRes.
The paper introduces a dynamic scheduling method that progressively activates residual layers to stabilize transformer pretraining.
It demonstrates significant improvements in evaluation perplexity and reduced gradient spikes across multiple scales and architectures.
ProRes outperforms static methods by enforcing a structured, depth-first residual activation that enhances both training stability and generalization.
Progressive Residual Warmup for Transformer Pretraining
Motivation and Methodology
Scaling Transformer-based LLMs exacerbates optimization instabilities, especially as model depth increases. The Progressive Residual Warmup (ProRes) scheme introduces a training-phase-aware solution by dynamically scaling each layer’s residual branch using a schedule α(l,t) that increases from 0 to 1 throughout training, with deeper layers warming up more slowly. This sequential activation reflects the dependency structure inherent to stacked transformer layers: shallow layers stabilize their representations first, and only then are deeper layers allowed to contribute (cf. Eq. 3; Table 1).
ProRes builds on three foundational principles: (1) explicit identity mapping at initialization, (2) dynamic bounding of model updates across depth and training time, and (3) enforcing a depth-first learning order for residual contribution. This approach circumvents the limitations of static or initialization-only methods such as Pre-LN [xiong2020layernorm], LayerNorm Scaling [sun2025lns], DS-Init [zhang2019dsinit], and DeepNorm [wang2022deepnet], which either uniformly constrain residuals or lack schedule-awareness.
Empirical Results: Convergence and Depth Scaling
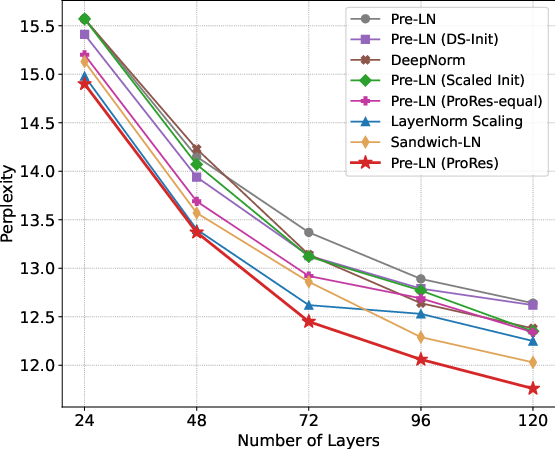
Across multiple scales (130M–7B parameters), ProRes significantly reduces evaluation perplexity on both in-distribution and out-of-distribution corpora. For Pre-LN architectures, ProRes reduces C4-en test perplexity by 0.47–0.62 and achieves an average improvement of 1.27% on general reasoning benchmarks (e.g., ARC, HellaSwag, LAMBADA). The perplexity gains are even more pronounced on datasets like LAMBADA, with a reduction of 4.86.
Figure 1: Evaluation perplexity (↓) of different methods as model depth increases.
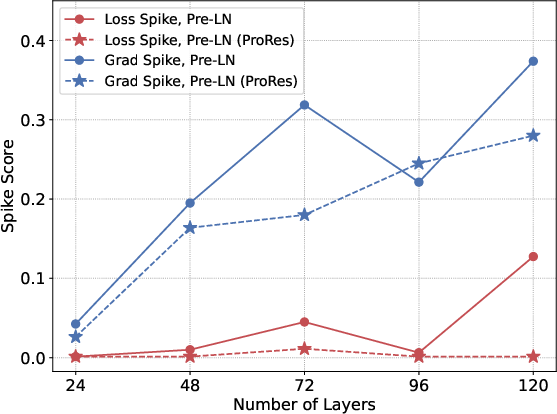
ProRes also yields enhanced training stability as measured by loss and gradient spike scores. On models trained with depths ranging from 12 to 120 layers, ProRes maintains superior performance, with the gap to Pre-LN and static scaling methods increasing with depth. The spike score (fraction of outlier updates) stays near zero, demonstrating strong control over activation and gradient blow-up.
Figure 2: Spike score (↓) of loss and gradient norm as model depth increases.
Analysis of Training Dynamics
Activation Control and Representation Evolution
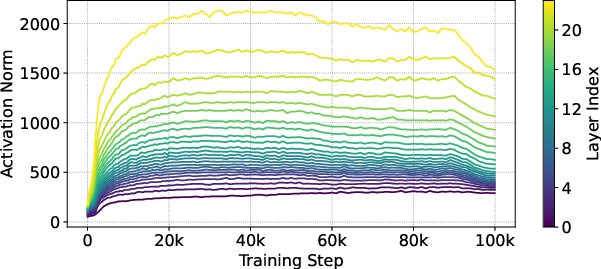
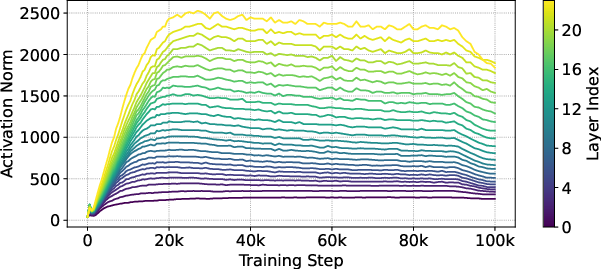
ProRes effectively mitigates the exponential activation growth documented in prior literature. Layerwise activation norms grow more linearly with ProRes, especially during early training stages, preventing deeper layers from dominating too early and causing vanishing gradients or noisy updates.
Figure 3: Layerwise activation norm of Pre-LN, with and without ProRes.
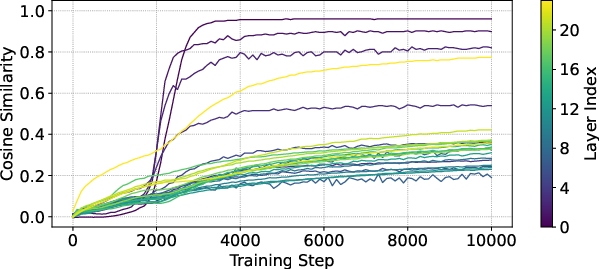
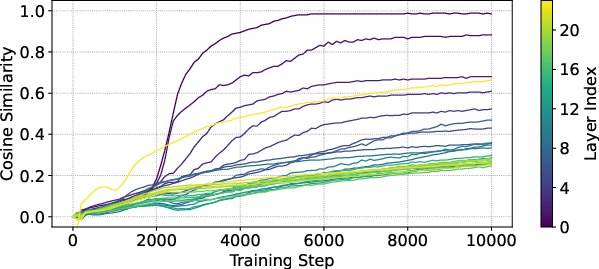
Additionally, the temporal evolution of residual outputs is smoother with ProRes, as demonstrated by the higher cosine similarity between intermediate and final layer activations for shallow and deep layers alike. This structured convergence trajectory reduces the turbulent phase transitions seen in vanilla Pre-LN.
Figure 4: Cosine similarity of layerwise residuals between intermediate (first 10\% steps) and final checkpoint.
Optimization Trajectory and Downstream Performance
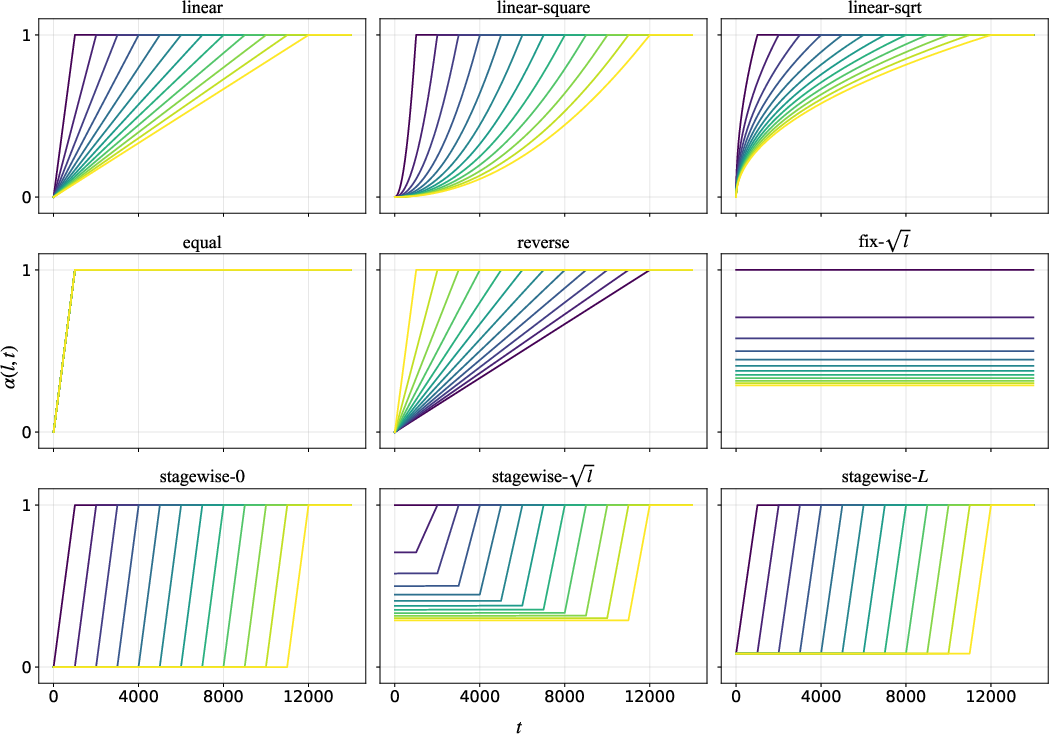
With residual branches activated sequentially, ProRes maintains bounded model updates during warmup and transitions into unconstrained optimization as layers are unlocked. Ablation studies confirm that schedules respecting the shallow-to-deep activation order vastly outperform simultaneous or reversed activation (cf. Table 2). Static constraints (e.g., fix-l) underperform dynamic schedules, indicating that training-phase-aware relaxation is essential for both stable optimization and full utilization of deep representations.
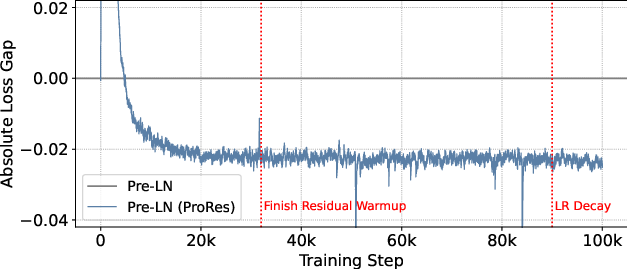
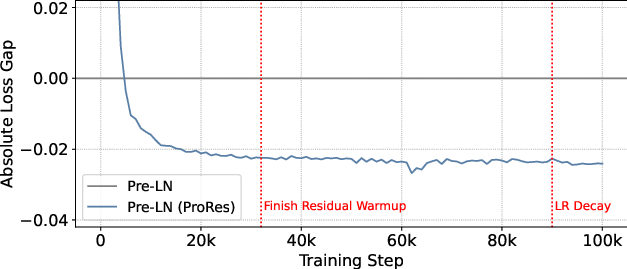
Figure 5: Loss gap across training steps of 7B models. Left: training loss gap (0.99 EMA smoothed) between Pre-LN and its ProRes variant. Right: evaluation loss gap calculated every 1000 steps.
Schedule Design and Architectural Implications
ProRes is a plug-in module applicable to Pre-LN, Post-LN, Sandwich-LN, DeepNorm, and LayerNorm Scaling transformers. The optimal warmup schedule is architecture-dependent, but linear schedules (α(l,t)=min(T⋅lt,1)) provide robust improvements across initialization schemes and model sizes without requiring extensive tuning.
Schedule ablations further show that activating deeper layers prematurely (reverse schedule) or statically constraining residuals (fix schedules) harms convergence and final performance. Stagewise relaxation schemes that unlock layer contributions in sequence reliably improve perplexity and stability.
Figure 6: Visualization of various schedules in Table 2.
Theoretical and Practical Implications
ProRes advances the optimization of deep transformers by introducing explicit temporal coordination across layers, resolving longstanding depth-scaling bottlenecks. Practically, this enables stable pretraining for deeper models, enhanced convergence, and improved generalization—critical for the continued scaling of LLMs. Theoretically, ProRes highlights the importance of training-phase-aware architectural modifications, suggesting future research directions in scheduled layer activation, dynamic constraint relaxation, and staged representation learning. It also opens avenues for integrating ProRes-style scheduling with other architectures employing residual branches beyond transformers.
Conclusion
Progressive Residual Warmup (ProRes) offers a simple yet effective paradigm for orchestrating layerwise residual learning in transformers. By scheduling residual activation from shallow to deep—rather than static or initialization-only methods—ProRes achieves lower perplexity, improved reasoning performance, and training stability across scales and normalization schemes. Its training-phase-aware design is a promising general tool for optimizing and scaling transformer models, with substantial implications for both empirical model performance and theoretical understanding of deep sequential architectures (2603.05369).