Harnessing Synthetic Data from Generative AI for Statistical Inference
Abstract: The emergence of generative AI models has dramatically expanded the availability and use of synthetic data across scientific, industrial, and policy domains. While these developments open new possibilities for data analysis, they also raise fundamental statistical questions about when synthetic data can be used in a valid, reliable, and principled manner. This paper reviews the current landscape of synthetic data generation and use from a statistical perspective, with the goal of clarifying the assumptions under which synthetic data can meaningfully support downstream discovery, inference, and prediction. We survey major classes of modern generative models, their intended use cases, and the benefits they offer, while also highlighting their limitations and characteristic failure modes. We additionally examine common pitfalls that arise when synthetic data are treated as surrogates for real observations, including biases from model misspecification, attenuated uncertainty, and difficulties in generalization. Building on these insights, we discuss emerging frameworks for the principled use of synthetic data. We conclude with practical recommendations, open problems, and cautions intended to guide both method developers and applied researchers.
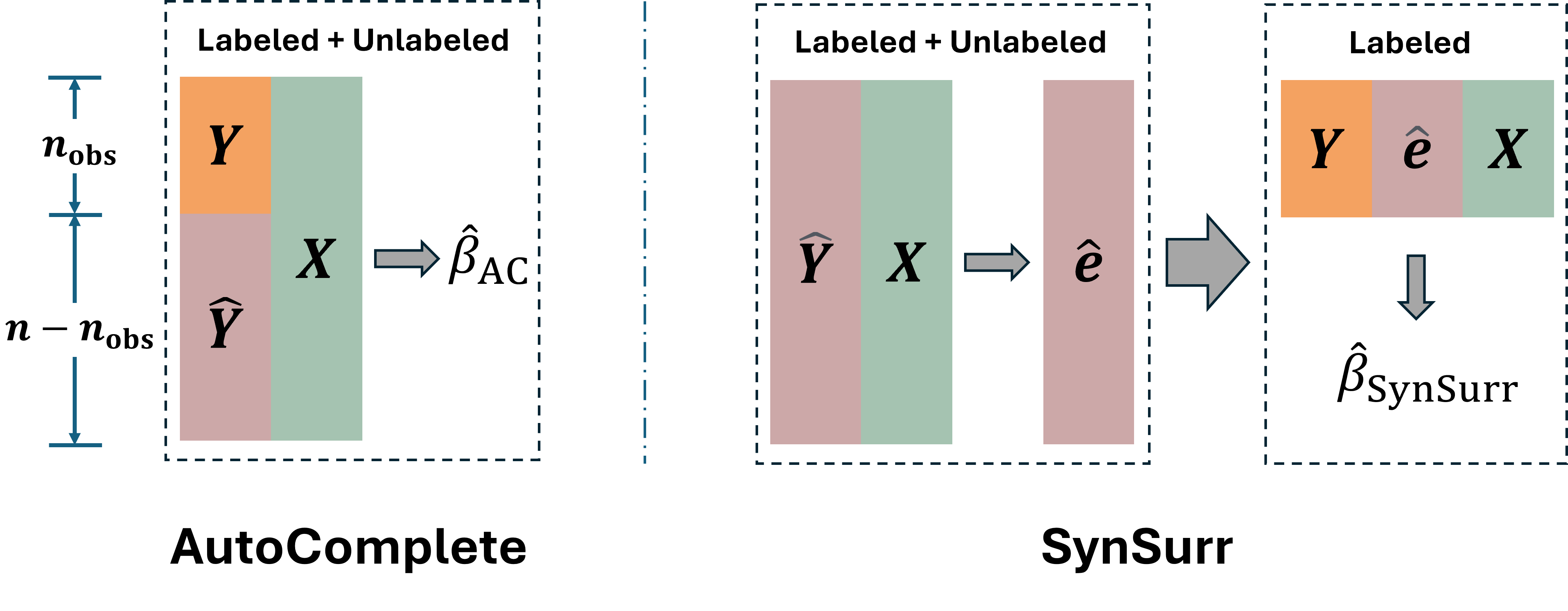
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is about “synthetic data” — data that are fake but realistic, created by AI to look like real data. Think of it like movie props: they’re not real, but they look convincing enough to practice with. The authors ask a simple but important question: When is it okay to use synthetic data to do serious science — like testing ideas, making predictions, or drawing conclusions — and when is it risky?
They review modern AI tools that make synthetic data (like GANs, Transformers, and Diffusion models), explain what these tools are good for, where they fail, and lay out rules of thumb so people can use synthetic data safely and fairly.
Key objectives and questions
The paper tries to answer, in plain terms:
- When can synthetic data replace or support real data without leading us to the wrong answers?
- What are the typical reasons people generate synthetic data, and how do those goals change what “good” synthetic data means?
- What kinds of AI models make synthetic data, and what are their strengths and weaknesses?
- What can go wrong — like bias, overconfidence, privacy problems, or models “forgetting” rare but important cases?
- What practical steps should researchers follow to get trustworthy results when synthetic data are involved?
How the authors approach the topic
This is a review and guide, not a single experiment. The authors:
- Build a simple framework to sort the main reasons people generate synthetic data.
- Survey the major AI model families used to create synthetic data and explain how they work at a high level (with everyday analogies).
- Map common pitfalls to the reasons they happen (for example, “treating synthetic data like real data” can make results look more certain than they really are).
- Collect practical strategies and guardrails so that scientists can use synthetic data without breaking important statistical rules.
Here are the main reasons people generate synthetic data, explained with examples:
- Privacy-preserving release: Share a fake-but-realistic dataset so others can analyze patterns (like trends in hospital data) without exposing anyone’s personal information. Here, we care about privacy guarantees and honest uncertainty estimates, not maximum realism at any cost.
- Data augmentation: Add more data points to help a model learn better — for instance, making extra examples of a rare disease so a medical model doesn’t miss it. The goal is better performance, but you still keep and use the original data.
- Fairness: Adjust the data so a model stops treating protected groups unfairly (for example, to reduce bias against a race or gender). The synthetic data is designed to satisfy a fairness rule while keeping usefulness.
- Domain transfer: Make source data “look like” target data from a different world (like moving from one hospital’s patients to another’s) so models work better in the new place.
- Missing data or trajectory completion: Fill in blanks (like unrecorded test results) or continue time series into the future (like forecasting) by generating likely values that fit what you’ve already observed.
And here are the main model families, described simply:
- GANs (Generative Adversarial Networks): Like an artist (generator) trying to fool a critic (discriminator). Great at making realistic samples, but training can be unstable and they may miss diversity.
- VAEs (Variational Autoencoders): Like compressing and then reconstructing data. Stable, interpretable “latent” features, but samples can look a bit “blurry” or plain.
- Normalizing Flows: Reversible transformations that turn simple noise into complex data and back. Exact math, but can be hard to scale or apply to mixed data types (numbers + categories).
- Autoregressive Transformers: Generate one piece at a time (like writing one word after another), using attention to look back at everything generated so far. Excellent for text and conditional generation, but slower at sampling and hungry for data.
- Diffusion Models: Add noise to data, then learn to remove it step by step (like un-scrambling a noisy photo). They produce some of the most realistic images and samples today but can be slow to sample.
Main findings and why they matter
Big picture: Synthetic data can be powerful, but only when used with care. The paper’s major takeaways are:
- Purpose first: The “right” kind of synthetic data depends on your goal. Privacy releases need privacy guarantees and multiple synthetic versions to reflect uncertainty. Augmentation for rare cases should target those cases specifically. Fairness-focused synthesis should aim for fairness constraints, not just realism.
- Don’t treat synthetic as real: If you mix synthetic and real data without acknowledging what’s fake, you can get biased answers and overconfident results. Your conclusions might look too “certain” because the synthetic data repeats the model’s beliefs, not new truth.
- Model misspecification is common: Generators learn an approximation of reality. If the model misses key patterns (especially rare or extreme cases), synthetic data can erase or distort important signals. This is a big risk for scientific inference.
- Privacy has a cost: Strong privacy methods (like differential privacy, which adds noise to protect individuals) reduce the chance of identifying someone — but they also reduce accuracy. This is a trade-off you must plan for.
- Beware feedback loops: Training new models only on older models’ outputs can cause “model collapse” — less diversity and worse coverage of rare events over time.
- Conditional and targeted synthesis works better: When you know what you’re missing (e.g., a rare class or a specific subgroup), generating synthetic examples targeted to that region often helps more than just making a lot of generic synthetic data.
- Good practice exists: Approaches like multiple imputation (make several synthetic versions and combine results), careful calibration/weighting, and holding out real test sets for evaluation help keep inference valid.
Why this matters: Many fields — healthcare, economics, policy, education, and more — are starting to rely on synthetic data to move faster, protect privacy, and improve models. These findings help ensure decisions made with synthetic data are fair, accurate, and trustworthy.
Implications and impact
Here’s what this means for researchers and practitioners:
- Match your method to your goal: Pick how you generate and use synthetic data based on what you need (privacy, power, fairness, transfer, or completion). There is no one-size-fits-all solution.
- Keep uncertainty honest: Use strategies that reflect uncertainty from both real sampling and the synthetic generation process (for example, multiple synthetic releases and proper combination rules).
- Validate with real data: Always check key results on a real held-out set if possible. Don’t only rely on synthetic performance.
- Target where it helps most: For imbalanced problems, focus synthetic data where you lack coverage (rare labels or underrepresented groups) rather than generating more of everything.
- Be transparent about trade-offs: Privacy, fairness, and accuracy can push in different directions. Make the trade-offs explicit and documented.
- Watch for bias and drift: Monitor whether synthetic pipelines underrepresent rare events, distort tails, or lead to feedback loops that reduce diversity over time.
Open challenges the paper highlights include: better ways to measure synthesis error; theories and tools for valid inference with modern generators; methods that stay robust when models are wrong; clearer fairness goals tied to real-world causes; and practical standards for evaluating synthetic data beyond just “looks real.”
In short, synthetic data can be a helpful assistant — not a substitute teacher. Used thoughtfully, it can protect privacy, boost performance, and improve fairness. Used carelessly, it can confidently lead you in the wrong direction. The paper gives a roadmap to get the benefits while avoiding the traps.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper and warrant future research.
- Conditions for valid inference with synthetic data: Precise assumptions on the relationship between the true data-generating distribution P, the learned generator , and the synthetic sampling law Q under which estimators, confidence intervals, and tests remain valid when is combined with .
- Quantifying synthesis error and misspecification: General frameworks to measure and control the impact of (e.g., divergence, support mismatch, tail misrepresentation) on bias, variance, and risk for downstream tasks.
- Uncertainty calibration with deep generators: Practical, generalizable procedures for uncertainty propagation (beyond classical MI) when generators are non-Bayesian or trained with complex objectives (GANs, diffusion), including how to derive valid standard errors, CIs, and p-values.
- Safe protocols for combining real and synthetic data: Design and theory for weighting, calibration, or sample-splitting schemes that prevent bias and overfitting when the same data train the generator and the downstream estimator.
- How much synthetic data to use: Non-asymptotic rules for selecting the number and allocation of synthetic samples (overall and conditionally targeted) to optimize inferential efficiency without inflating bias or variance.
- Utility–fidelity metrics tied to inference: Standardized evaluation benchmarks and metrics linking generative fidelity (e.g., coverage of rare events, long tails) to concrete gains/losses in downstream estimation and prediction tasks, especially in tabular biomedical settings.
- Distribution shift diagnostics during augmentation: Methods to detect and correct unintended shifts introduced by Q when the target is to approximate P (e.g., due to mode collapse, memorization, or undercoverage), and to adjust analyses accordingly.
- DP synthetic release and statistical validity: General methods to debias or adjust inference after -DP synthesis (e.g., correcting clipping-induced bias) and to characterize privacy–utility trade-offs for deep generators in finite samples.
- Multiple release aggregation under privacy: Optimal ways to pool multiple DP (or MI) synthetic releases for valid and powerful inference, including dependence-aware variance estimation and finite-sample guarantees.
- Interplay between privacy and fairness: How DP constraints interact with fairness-targeted synthesis (Q⋆), including conditions under which both can be satisfied without unacceptable utility loss and how to audit trade-offs.
- Fairness-aware generation with causal guarantees: Identification assumptions and procedures that ensure fairness constraints (e.g., path-specific effects) are satisfied in generated data without compromising calibration or predictive performance.
- Targeted augmentation for rare events: Theory and methods to decide when conditional synthesis (e.g., oversampling ) helps or hurts, optimal allocation across scarcity regions, and safeguards against spurious patterns in the minority class.
- Domain transfer via synthetic data: Guarantees for learning (target distribution) from limited target information; robustness of OT-based and GAN-based transfer to misspecification (e.g., covariate vs label shift) and small-sample regimes.
- Validation under covariate/label shift: Diagnostic tools and correction strategies when covariate shift assumptions (e.g., ) fail, and principled ways to integrate labeled/unlabeled target data with synthetic transfer samples.
- Imputation and trajectory completion validity: Assumptions (e.g., MCAR/MAR/MNAR) under which deep generative imputations yield unbiased estimators; methods for variance calibration and sensitivity analyses when imputations come from misspecified high-capacity models.
- Digital twins and counterfactual trajectories: Identification and validation strategies for intervention-conditioned trajectory synthesis (e.g., in healthcare), including causal assumptions, uncertainty quantification, and external benchmarking.
- Tabular generation challenges: Architectures and training protocols that robustly handle mixed types, extreme skew, and sparsity; theory explaining when diffusion or transformer-based tabular generators improve downstream inference over GAN/VAE baselines.
- Sampling efficiency vs statistical properties: Methods to accelerate diffusion/score-based sampling without degrading the statistical characteristics (e.g., tail behavior, dependency structure) critical for inference.
- Tokenization and ordering for autoregressive tabular models: Best practices and theory for sequence orderings, discretization, and encoding choices that preserve statistical relationships needed for valid inference.
- Recursive training and model collapse in LLMs: Conditions and safeguards for using synthetic data in pretraining (e.g., filtering, weighting, refresh rates) to avoid diversity loss and tail misestimation; diagnostics to detect early collapse.
- Auditing privacy leakage and memorization: Practical tests and certification protocols for assessing membership inference risk and record leakage in synthetic releases, especially for small-n/high-d settings.
- Multi-modal synthetic data coherence: Methods to ensure cross-modality consistency (e.g., image–text–tabular) when used for joint inference, and metrics that reflect cross-modal causal/associational structure.
- Robust causal inference with synthetic outcomes: Generalization of strategies like SynSurr to broader causal estimands and settings (nonlinear models, time-to-event data), including double-robust or semiparametric procedures that remain valid under generator misspecification.
- Benchmarking and reproducibility: Open, standardized benchmarks that pair real data with clearly specified inferential targets to compare synthetic generation and usage protocols under controlled misspecification and shift scenarios.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, grounded in the paper’s reviewed frameworks, assumptions, and tools.
- Privacy-preserving data sharing and analytics (Healthcare, Finance, Government Statistics, Education)
- What to do: Release synthetic datasets that approximate real data while protecting individuals, then analyze only the synthetic releases.
- Tools/workflows: Multiple synthetic releases with Bayesian MI combining rules; DP mechanisms (DP-SGD for training private generators, PATE/PATE-GAN for label/query privatization, PrivBayes for private graphical models).
- Example outcomes: Share hospital registries for external research; publish public-use microdata; build public leaderboards for competitions without exposing private data.
- Assumptions/dependencies:
- MI approach assumes reasonable generative model and correct uncertainty propagation across multiple releases.
- DP approach requires selecting an (ε, δ) privacy budget; expect a privacy–utility trade-off and potential bias from clipping/noise.
- Data augmentation for improved learning and evaluation (Healthcare diagnostics, Fraud detection, Manufacturing QA, Marketing/CRM, Software QA)
- What to do: Merge synthetic and real data to increase sample size/diversity, or target rare/underserved regions (e.g., minority classes).
- Tools/workflows: Tabular generators (CTGAN, CTAB-GAN, TabDDPM, TabEBM); targeted/conditional augmentation for rare classes (SMOTE; CoDSA with conditional diffusion/finetuning); hold-out splits to avoid leakage.
- Example outcomes: Better risk models with rare adverse events; balanced fraud datasets; faster model selection via more stable CV.
- Assumptions/dependencies:
- Generative model fidelity in targeted regions; if misspecified, augmentation can harm performance.
- For valid inference (not just prediction), analysts should calibrate/weight synthetic samples or use frameworks that account for synthesis error.
- Fairness-aware training via constrained synthetic data (Financial services/lending, Insurance, Hiring/HR tech, Public sector decision support)
- What to do: Generate training data that attenuate or remove unwanted dependence on protected attributes to meet fairness metrics (e.g., demographic parity, equalized odds).
- Tools/workflows: FairGAN/TabFairGAN (adversarial generation with fairness constraints); DECAF (causally aware synthetic generation respecting permissible pathways); evaluation on fairness and utility metrics.
- Example outcomes: Train credit scoring or hiring models with reduced group disparities while maintaining performance.
- Assumptions/dependencies:
- Fairness definition choice (trade-offs are unavoidable and context-specific).
- Measurement and availability of protected attributes; causal methods require credible causal assumptions.
- Domain transfer using synthetic target-domain samples (Multi-site clinical deployment, Retail demand forecasting across geographies, Edge ML deployments)
- What to do: Use generative mappings to produce target-like samples for training/tuning when deployment population differs from training population.
- Tools/workflows: OT-based domain adaptation (couplings/mappings); RadialGAN for cross-domain translation; importance-weighted cross-validation under covariate shift.
- Example outcomes: Transport models trained at Hospital A to Hospital B; tune models with target covariates but limited labels.
- Assumptions/dependencies:
- Covariate shift assumptions (e.g., stable P(Y|X)); adequate support overlap between source and target.
- For OT mappings, quality of transport plan and preservation of predictive structure.
- Missing data imputation and trajectory completion/forecasting (EHRs and registries, IoT/sensor networks, Energy and finance time series, Public health surveillance)
- What to do: Impute missing entries or generate plausible continuations conditioned on observed history; use completions for analysis with propagated uncertainty.
- Tools/workflows: BRITS (bidirectional RNN imputation); CSDI (diffusion-based imputation with uncertainty); TimeGAN (trajectory synthesis); SynSurr for outcome synthesis from surrogates to improve inference power; “digital twin” forecasting prototypes for patient trajectories.
- Example outcomes: More complete patient datasets for association modeling; robust forecasting with uncertainty for sensor gaps; efficient regression with partially observed outcomes.
- Assumptions/dependencies:
- Missingness mechanism (MAR assumed for many methods; MNAR needs explicit modeling).
- For SynSurr-like inference, auxiliary variables must be predictive and observed for all; downstream analyses must account for synthesis uncertainty.
- Safe and effective use of synthetic data in LLM/ML pipelines (Software/AI product development, Education/data science training)
- What to do: Use synthetic data for instruction-tuning, evaluation scaffolds, and unit testing; avoid recursive pretraining on synthetic-only data.
- Tools/workflows: Synthetic instruction data generation with quality filters; hold-out real validation sets; guardrails to detect distributional drift and mode collapse.
- Example outcomes: Rapidly create task-specific instruction sets; privacy-safe testing of analytics pipelines.
- Assumptions/dependencies:
- Quality controls to prevent drift; do not treat synthetic as real for pretraining at scale.
- Maintain real-data validation to monitor performance and diversity.
Long-Term Applications
These applications are promising but depend on further methodological advances, scaling, validation, or regulatory acceptance.
- Regulatory-grade synthetic controls and digital twins for clinical trials and real-world evidence (Healthcare, Biopharma)
- What it could enable: Synthetic control arms; individualized disease progression simulations to support trial design and decision making.
- Needed advances: Validated uncertainty quantification and bias controls under misspecification; transparent audit trails; regulatory guidance on acceptability.
- Scalable, high-fidelity differentially private generative modeling for complex multimodal data (Healthcare imaging + EHRs, Financial transactions)
- What it could enable: Public release of rich multimodal datasets with rigorous privacy guarantees and minimal utility loss.
- Needed advances: Better DP training algorithms with lower bias, stability on small-to-medium datasets, and formal utility bounds.
- Causally grounded fairness synthesis for high-stakes decisions (Finance, Hiring, Criminal justice, Public policy)
- What it could enable: Training data that satisfy fairness criteria aligned with causal pathways (e.g., blocking impermissible paths while retaining permissible ones).
- Needed advances: Elicitation/learning of causal graphs; methods robust to causal ambiguity; measurement of downstream causal fairness and utility trade-offs.
- Certified inference with synthetic augmentation under model misspecification (Cross-sector statistics and ML)
- What it could enable: Off-the-shelf procedures that add synthetic data while guaranteeing unbiased estimation, calibrated confidence intervals, and correct error control.
- Needed advances: General-purpose estimators that combine real and synthetic samples with valid variance estimation; diagnostics for synthesis error; robust theory for high-dimensional and nonparametric settings.
- Automated domain transfer pipelines with guarantees (Healthcare multi-site generalization, Retail/marketing geo-transfer, Edge devices)
- What it could enable: Turnkey systems that learn mappings, generate target-like samples, and adapt models with certified generalization bounds.
- Needed advances: OT and generative translations that preserve task-relevant structure; adaptive selection under covariate/label shift; monitoring for target drift.
- Federated and cross-organization collaboration via synthetic intermediaries (Healthcare networks, Finance consortia, Government agencies)
- What it could enable: Sharing synthetic “proxies” instead of raw data to facilitate joint modeling without revealing sensitive records.
- Needed advances: Proven protections against membership/attribute inference beyond DP; interoperability standards; governance frameworks for shared synthetic assets.
- Safety-critical edge case synthesis for autonomy and robotics (Autonomous driving, Robotics, Aviation)
- What it could enable: Conditional generators that create rare but critical scenarios for training and evaluation.
- Needed advances: Faithful modeling of physics and sensor characteristics; validation protocols; standardized scenario taxonomies; integration with simulation engines.
- Synthetic curricula and tasks for in-context/meta-learning (Education technology, Enterprise training, AI R&D)
- What it could enable: Automatically generated task families to train models for rapid adaptation and reasoning (e.g., tabular/problem generators for LLMs).
- Needed advances: Benchmarked task generators tied to measurable downstream gains; controls to avoid overfitting to synthetic task distributions.
- Energy grid and financial systems forecasting with full uncertainty via diffusion/score-based imputation (Energy, Finance)
- What it could enable: Probabilistic forecasts that propagate missingness and model uncertainty through to decision-making.
- Needed advances: Scalable diffusion-based forecasters for multivariate, nonstationary series; robust calibration; decision-theoretic integration.
- Stable use of synthetic data for pretraining foundation models (Software/AI platforms, Multimodal AI)
- What it could enable: Cost-effective pretraining with synthetic corpora without losing diversity or realism.
- Needed advances: Anti-collapse training curricula; mixture strategies combining real and synthetic data; diversity metrics and safeguards.
Each long-term application depends on methodological guardrails emphasized in the paper: explicitly modeling and auditing synthesis uncertainty, stress-testing under misspecification, avoiding treating synthetic as equivalent to real data without calibration, and aligning generation targets (Q) with the downstream objective (privacy, augmentation, fairness, transfer, or completion).
Glossary
- Autoregressive models: Probabilistic models that factorize a joint distribution into a product of conditional distributions over an ordered sequence. "Autoregressive models provide an alternative route to tractable likelihoods by factorizing the joint distribution over an ordered sequence representation , namely "
- BRITS: A deep-learning method for time-series imputation that infers missing values using bidirectional recurrent dynamics. "BRITS is a canonical deep-learning imputation approach that uses bidirectional recurrent modeling"
- Causally-aware generators: Generative models that incorporate causal structure to enforce fairness or mechanism-level constraints. "causally-aware generators such as DECAF"
- Covariate shift: A distribution shift where the marginal distribution of inputs changes between domains, but the conditional outcome model remains the same. "A common special case is covariate shift, where the conditional outcome model is assumed stable across domains while the covariate distribution changes,"
- CSDI: A score-based diffusion approach for probabilistic imputation of missing time-series values. "Probabilistic imputation via score-based diffusion has also been implemented in approaches like CSDI"
- DDPM: Denoising Diffusion Probabilistic Models; a discrete-time diffusion framework that learns to reverse a gradual noising process for generation. "In the discrete-time DDPM formulation"
- Demographic parity: A group fairness criterion requiring equal positive prediction rates across protected groups. "parity constraints on prediction rates across groups (demographic parity)"
- Differential privacy (DP): A formal privacy framework requiring that outputs of a randomized mechanism be statistically indistinguishable under single-record changes. "In modern differential privacy (DP) formulations, is regarded as the output law of a randomized mechanism ,"
- Digital twin: A generative model–based simulation of an individual’s future trajectory under observed history and potential interventions. "emerging ``digital twin'' formulations frame trajectory completion and forecasting through large generative models"
- Domain adaptation: Techniques for learning models that generalize from a source distribution to a different target distribution. "develop OT as a practical tool for domain adaptation under distribution mismatch"
- Domain transfer: Using generative or mapping mechanisms to produce target-like samples from source data for learning under distribution shift. "Domain transfer refers to settings in which the target population differs from the available training population."
- DP-SGD: A differentially private variant of stochastic gradient descent that adds noise and clips gradients to provide privacy guarantees. "such as DP-SGD"
- ELBO (evidence lower bound): A variational objective optimized in VAEs that lower-bounds the log-likelihood by combining reconstruction and regularization terms. "ELBO objective"
- f-GAN: A GAN training framework interpreting adversarial learning as minimization of an f-divergence. "-GAN"
- Generative Adversarial Network (GAN): A framework with a generator and discriminator trained adversarially to produce realistic samples. "Generative adversarial networks (GANs)"
- Importance weighting: Reweighting source-domain samples to approximate target-domain expectations under covariate shift. "importance weighting and related model-selection criteria"
- Importance-weighted cross-validation (IWCV): A cross-validation method that uses importance weights to estimate target-domain risk under covariate shift. "importance-weighted cross-validation"
- Jacobian determinant: The determinant of the Jacobian of an invertible transformation, used for exact likelihood computation in normalizing flows. "with via Jacobian determinant"
- Mode collapse: A GAN failure mode where the generator produces limited or repetitive outputs, reducing diversity. "susceptible to mode collapse"
- Model collapse: Degradation in generative model diversity when trained recursively on synthetic data, misrepresenting distribution tails over time. "“model collapse”, where learned models progressively lose diversity and misrepresent tails of the original data distribution"
- Multiple-imputation (MI): A procedure generating multiple synthetic datasets from a posterior predictive to account for uncertainty in missing or synthesized values. "multiple-imputation (MI)"
- Normalizing flows: Generative models that learn invertible transformations from a simple base distribution to the data distribution with exact likelihoods. "Normalizing Flows"
- Optimal transport (OT): A mathematical framework to align distributions by learning a transport plan or mapping between source and target. "uses optimal transport (OT) to align source and target distributions"
- PATE: A teacher-ensemble approach that aggregates multiple models to provide differential privacy, often used in private synthesis. "teacher ensemble approaches such as PATE"
- PATE-GAN: A GAN framework combining PATE with adversarial generation to produce differentially private synthetic data. "PATE-GAN"
- PixelRNN: An autoregressive model for images that models pixel-wise conditional distributions in a scan order. "PixelRNN image models"
- Posterior collapse: A VAE issue where the posterior ignores latent variables due to an overly powerful decoder. "posterior collapse"
- Posterior predictive mixture: The predictive distribution obtained by averaging a model’s predictions over the posterior of its parameters. "posterior predictive mixture"
- Probability flow ODE: A deterministic ordinary differential equation whose solution shares the same marginals as the diffusion model’s stochastic reverse process. "a deterministic probability flow ODE"
- PrivBayes: A differentially private synthetic data generator that fits a private graphical model and samples from it. "PrivBayes"
- RadialGAN: A GAN-based framework that learns cross-dataset mappings to transport samples into a target domain. "RadialGAN"
- Reverse-time SDE: The stochastic differential equation describing the generative (denoising) dynamics in diffusion models when run backward in time. "the corresponding reverse-time SDE depends explicitly on the score:"
- Score-based diffusion models: Generative models that learn the score (gradient of log-density) at different noise levels to drive reverse-time sampling. "score-based diffusion models"
- Self-attention: A mechanism that computes weighted interactions among all positions in a sequence, enabling long-range dependencies. "This self-attention mechanism enables stable training and efficient learning of long-range dependencies"
- SMOTE: A classical oversampling method that synthesizes minority-class examples by interpolating between neighbors. "SMOTE is a canonical baseline"
- Stein’s score: The gradient of the log-density, central to score matching and diffusion-based generative sampling. "the Stein's score "
- TimeGAN: A GAN framework tailored for time-series, combining adversarial training with dynamics-preserving objectives. "TimeGAN"
- Training-by-sampling: A CTGAN strategy that samples conditioning values during training to better learn rare categories. "(``training-by-sampling'')"
- Variational autoencoders (VAEs): Latent variable models trained via variational inference to reconstruct data while regularizing latent distributions. "variational autoencoders (VAEs)"
- Wasserstein GAN: A GAN variant optimizing the Wasserstein distance to improve training stability and sample quality. "Wasserstein GAN"
- WaveNet: An autoregressive model for audio that generates raw waveforms via causal convolutions. "WaveNet for audio"
- Wiener process: A continuous-time stochastic process (Brownian motion) used to model noise in SDE-based diffusion frameworks. "Wiener process (Brownian motion)"
Collections
Sign up for free to add this paper to one or more collections.